w命令:
用于查看系統負載、顯示已經登陸系統的用戶列表,并顯示用戶正在執行的指令等信息

第一行從左面開始顯示的信息依次為:時間,系統運行時間,登錄用戶數,平均負載。第二行開始以及下面所有的行,告訴我們的信息是,當前登錄的都有哪些用戶,以及他們是從哪里登錄的等等
我們主要關注的load average后面的3個數值:第①個數值表示1分鐘內系統的平均負載值;第②個數值表示5分鐘內系統的平均負載值;第③個數值表示15分鐘系統的平均負載值。這個值的意義是,單位時間段內CPU活動進程數。當然這個值越大就說明你的服務器壓力越大。一般情況下這個值只要不超過服務器的cpu數量就沒有關系。
如何查看CPU數量:grep -c "processor" /proc/cpuinfo;?????/proc/cpuinfo文件記錄了cpu的詳細信息。
uptime命令:
能夠打印系統總共運行了多長時間和系統的平均負載。uptime命令可以顯示的信息顯示依次為:現在時間、系統已經運行了多長時間、目前有多少登陸用戶、系統在過去的1分鐘、5分鐘和15分鐘內的平均負載。

vmstat命令:
顯示虛擬內存狀態,包括進程、內存、I/O等系統整體的運行狀態。

w 查看的是系統整體上的負載,通過看那個數值可以知道當前系統有沒有壓力,但是具體是哪里(CPU, 內存,磁盤等)有壓力就無法判斷了。通過 vmstat 就可以知道具體是哪里有壓力。vmstat命令打印的結果共分為6部分:procs, memory, swap, io, system, cpu. 請重點關注一下r b?swpd si so bi bo us wa幾列
1)procs 顯示進程相關信息
r :表示運行和等待cpu時間片的進程數,如果長期大于服務器cpu的個數,則說明cpu不夠用了;
b :表示等待資源的進程數,比如等待I/O, 內存等,這列的值如果長時間大于1,則需要關注一下了;
2)memory 內存相關信息
swpd :表示切換到交換分區中的內存數量 ,單位為KB;
free :當前空閑的內存數量,單位為KB;
buff :緩沖大小,(即將寫入磁盤的);?? ?例子:0000(CPU數據) -->?內存(buffer) -->磁盤
cache :緩存大小,(從磁盤中讀取的); 例子:0000(磁盤數據) -->?內存(cache) --> CPU
3)swap 內存交換情況
si :由交換區寫入到內存的數據量;
so :由內存寫入到交換區的數據量;
4)io 磁盤使用情況
bi :從塊設備讀取數據的量(讀磁盤);
bo: 從塊設備寫入數據的量(寫磁盤);
5)system 顯示采集間隔內發生的中斷次數
in :表示在某一時間間隔中觀測到的每秒設備中斷數;
cs :表示每秒產生的上下文切換次數;
6)CPU 顯示cpu的使用狀態(us+sy+id=100%)
us :顯示了用戶下所花費 cpu 時間的百分比;
sy :顯示系統花費cpu時間百分比;
id :表示cpu處于空閑狀態的時間百分比;
wa :表示I/O等待所占用cpu時間百分比;
st :表示被偷走的cpu所占百分比(一般都為0,不用關注)
vmstat常見用法:vmstat 1 5;????表示每隔1s打印一次,共打印5次;當然你也可以使用vmstat 1持續打印,Ctrl + c 結束。
top命令:
可以實時動態地查看系統的整體運行情況,是一個綜合了多方信息監測系統性能和運行信息的實用工具。
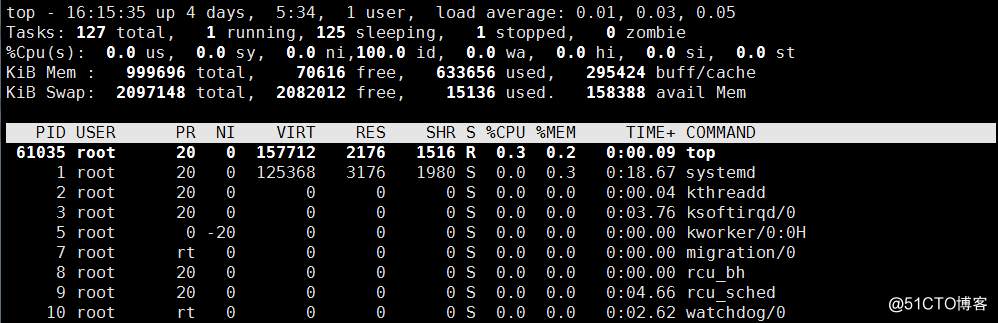
top命令打印出了很多信息,包括系統負載(loadaverage)、進程數(Tasks)、cpu使用情況、內存使用情況以及交換分區使用情況。如上圖所示,有些內容可以通過其他命令也能查看,這里關注:RES %CPU, %MEM, COMMAND
RES?進程所占內存大小
%CPU 使用CPU百分比
%MEM 使用內存百分比
COMMAND?進程啟動命令名稱
按 shift + m: 可以按照內存使用大小排序;shift + p:可以切回按照cpu使用大小排序;按數字 1: 可以列出各顆cpu的使用狀態。字母q:退出!
一次性全部把所有信息輸出出來而非動態顯示:top -bn1? ;? ? 一般使用在shell腳本。
sar命令:
sar 命令很強大,它可以監控系統所有資源狀態,比如平均負載、網卡流量、磁盤狀態、內存使用等等;這里介紹如何監控網卡流量
sar安裝:yum install -y sysstat
sar查看網卡流量:sar -n DEV
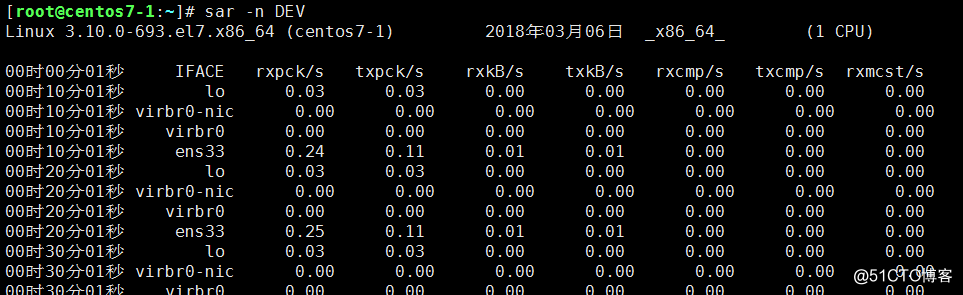
IFACE這列表示設備名稱
rxpck/s 表示每秒進入收取的包的數量
txpck/s 表示每秒發送出去的包的數量
rxbyt/s 表示每秒收取的數據量(單位Byte)
txbyt/s表示每秒發送的數據量。
后面幾列不用關注。如果rxpck/s 那一列的數值大于4000,或者rxbyt/s那列大于5,000,000則很有可能是被***了,正常的服務器網卡流量不會高于這么多,除非是你自己在拷貝數據。
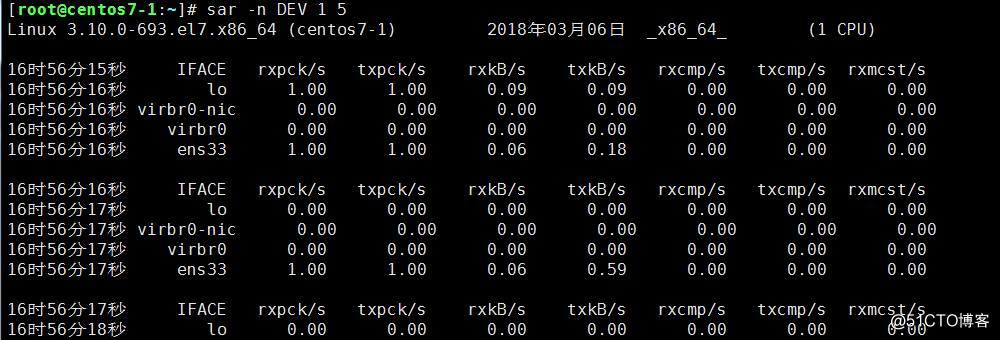
上面的命令是查看網卡流量歷史的,如何時時查看網卡流量呢?? 輸入命令:sar -n DEV 1 5 即可;
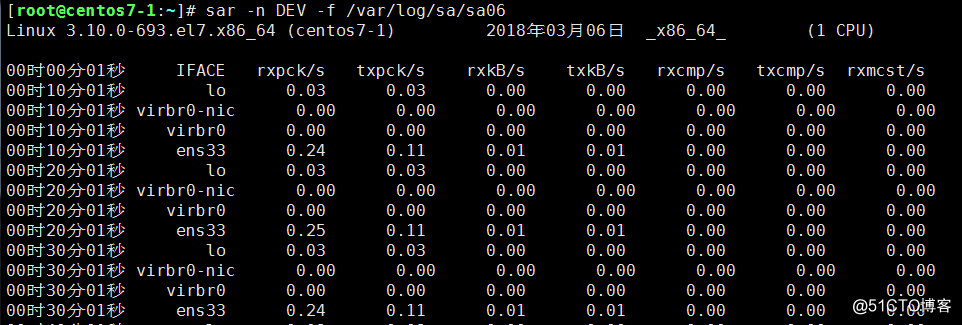
也可以查看某一天的網卡流量歷史,歷史文件存放在/var/log/sa/目錄下,如命令:sar -n DEV -f /var/log/sa/sa06;
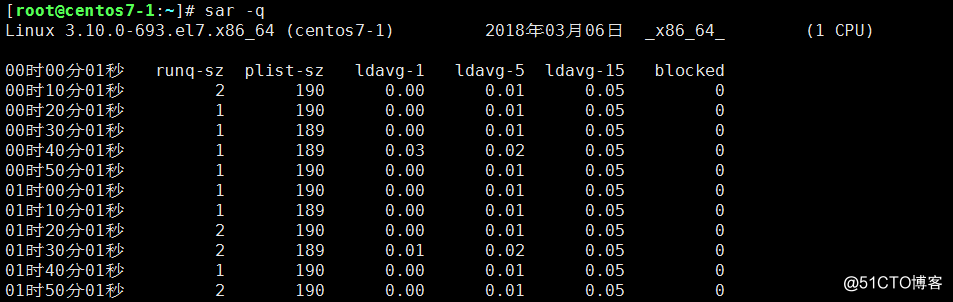
查看系統歷史負載:sar -q;
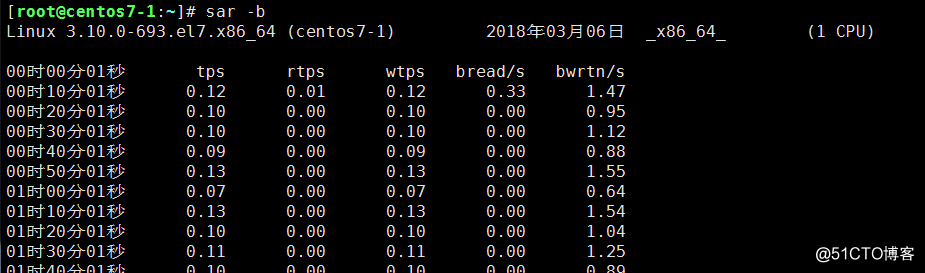
查看磁盤讀寫:sar -b
nload命令:
用來即時監看網路狀態和各ip所使用的頻寬
安裝:yum?install -y?epel-release; yum install -y nload;
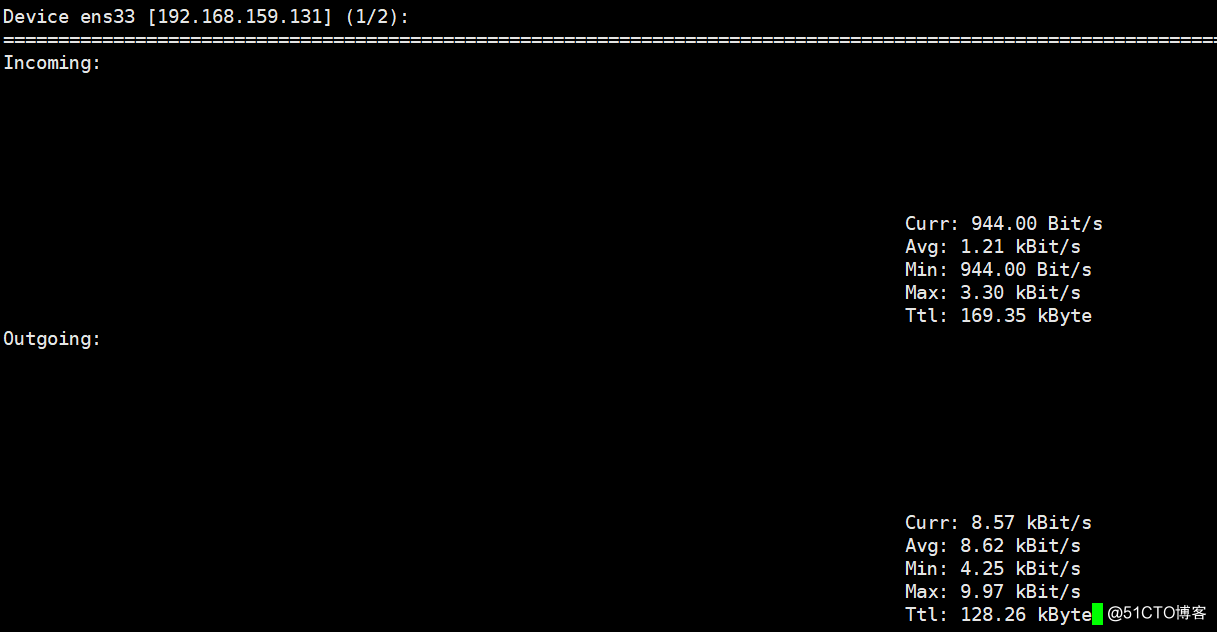
Incoming:進入網卡的流量; Outgoing:網卡出去的流量;?我們關注的當然是Curr這行的實時數據了。
監控io性能:
iostat命令:
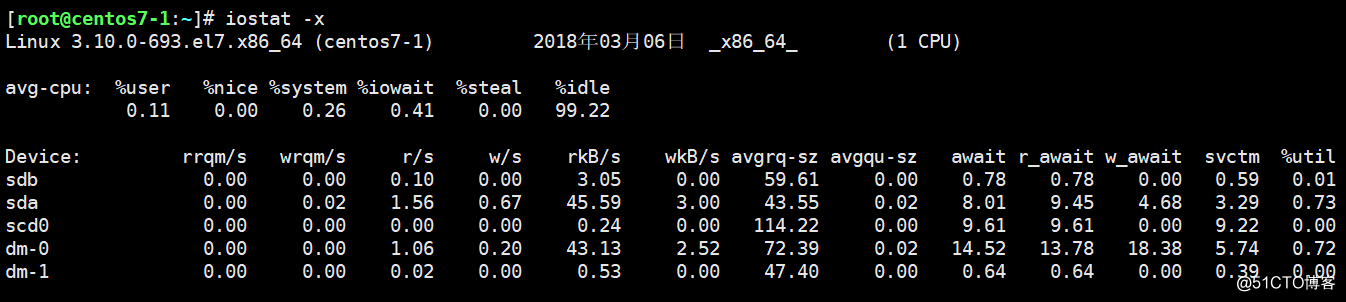
關注%util這一列,表示占用CPU時間百分比;如果數值很大的話(50%+),說明磁盤IO很忙。
iotop命令:yum?install -y?iotop
能查看進程占用磁盤IO信息
free命令:
用于查看內存使用情況

total:內存總大小
used:真正使用的實際內存大小
free:剩余物理內存大小(沒有被分配的內存)
shared:共享內存大小,不用關注
buff/cache:分配給buffer和cache的內存總共有多大。(區分兩者!)
available:系統可使用的內存有多大
【total=used + free + buffer/cache】【available=free + buffer/cache剩余的部分】
ps命令:
用于查看系統進程。常用:ps -elf ;? 或者 ps aux;兩個命令顯示的信息大同小異!

PID:表示進程的ID。有了pid,可以終止進程:kill?pid;查看pid進程在哪里啟動的:ls -l /proc/[pid]/? 就可以看到某pid在哪里啟動的。
這里主要解釋一下STAT列:表示進程的狀態;如下;
D 不能中斷的進程(通常為IO)
R 正在運行中的進程
S 已經中斷的進程,通常情況下,系統中大部分進程都是這個狀態
T 已經停止或者暫停的進程,如果我們正在運行一個命令,比如說 sleep 10 如果我們按一下ctrl -z 讓他暫停,那么我們用ps查看就會顯示T這個狀態
W 這個好像是說,從內核2.6xx 以后,表示為沒有足夠的內存頁分配
X 已經死掉的進程(這個好像從來不會出現)
Z 僵尸進程,殺不掉,打不死的垃圾進程,占系統一小點資源,不過沒有關系。如果太多,就有問題了。一般不會出現。
< 高優先級進程
N 低優先級進程
L 在內存中被鎖了內存分頁
s 主進程
l 多線程進程
+ 代表在前臺運行的進程
)



與特殊的卷積)




)
用法及代碼示例)








