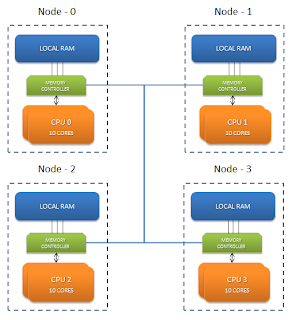
這些具有巨大內核的盒子帶有非統一內存訪問(NUMA)架構。 NUMA是一種可提高本地節點的內存訪問性能的體系結構。 這些新的硬件盒分為稱為節點的不同區域。 這些節點具有一定數量的核心,并分配有一部分內存。 因此,對于具有1 TB RAM和80個核心的機箱,我們有4個節點,每個節點具有20個核心和256 GB的內存分配。
您可以使用命令numactl --hardware
>numactl --hardware
available: 4 nodes (0-3)
node 0 size: 258508 MB
node 0 free: 186566 MB
node 1 size: 258560 MB
node 1 free: 237408 MB
node 2 size: 258560 MB
node 2 free: 234198 MB
node 3 size: 256540 MB
node 3 free: 237182 MB
node distances:
node 0 1 2 3 0: 10 20 20 20 1: 20 10 20 20 2: 20 20 10 20 3: 20 20 20 10JVM啟動時,它將啟動線程,這些線程是在某些隨機節點的內核上調度的。 每個線程都盡可能快地使用其本地內存。 線程可能在某個時候處于WAITING狀態,并在CPU上重新調度。 這次不能保證它將在同一節點上。 現在這一次,它必須訪問一個遠程存儲位置,這會增加延遲。 遠程存儲器訪問速度較慢,因為指令必須遍歷互連鏈路,從而引入額外的躍點。
Linux命令numactl提供了一種僅將進程綁定到某些節點的方法。 它將進程鎖定到特定節點,以執行和分配內存。 如果將JVM實例鎖定到單個節點,則將刪除節點間的流量,并且所有內存訪問都將在快速本地內存上進行。
numactl --cpunodebind=nodes, -c nodes
Only execute process on the CPUs of nodes.創建了一個小型測試,該測試試圖序列化一個大對象并計算每秒的事務和延遲。
要執行綁定到一個節點的Java進程,請執行
numactl --cpunodebind=0 java -Dthreads=10 -jar serializationTest.jar將此測試運行在兩個不同的盒子上。
盒子A
4個CPU x 10核x 2(超線程)=總共80核
節點:0,1,2,3
方塊B
2個CPU x 10個內核x 2個(超線程)=總共40個內核
節點:0,1
CPU速度:兩者均為2.4 GHz。
默認設置也使用框中可用的所有節點。
| 框 | NUMA政策 | TPS | 延遲 (平均) | 延遲 (分鐘) |
| 一個 | 默認 | 261 | 37 | 18歲 |
| 乙 | 默認 | 387 | 25 | 5 |
| 一個 | –cpunodebind = 0,1 | 405 | 23 | 3 |
| 乙 | –cpunodebind = 0 | 1,613 | 5 | 3 |
| 一個 | –cpunodebind = 0 | 1,619 | 5 | 3 |
因此,我們可以推斷出,與“ 2個節點” Box B上的默認設置相比,“節點較多”的Box A上的默認設置在“ CPU密集型”測試中的性能較低。更好。 可能是因為它的節點跳數更少,并且線程被重新調度的概率增加到50%。
當--cpunodebind=0 ,它的表現要優于所有情況。
注意:以上測試是在10個內核上使用10個線程運行的。
測試罐: 下載
測試源: 下載
參考:來自我們的JCG合作伙伴 Himadri Singh的NUMA和Java ,在Billions&Terabytes博客上。
翻譯自: https://www.javacodegeeks.com/2012/09/numa-architecture-and-java.html









與內存分配)








)
![洛谷P1937 [USACO10MAR]倉配置Barn Allocation](http://pic.xiahunao.cn/洛谷P1937 [USACO10MAR]倉配置Barn Allocation)