前言:
今天為大家帶來的內容是:用python解決動態的定義變量名(并給其賦值方法:大數據處理)具有很好的參考價值,希望對大家有所幫助。喜歡本文內容的記得點贊轉發收藏不迷路哦!!!
最近消費kafka數據到磁盤的時候遇到了這樣的問題:
需求:每天大概有1千萬條數據,每條數據包含19個字段信息,需要將數據寫到服務器磁盤,以第二個字段作為大類建立目錄,第7個字段作為小類配合時間戳作為文件名,臨時文件后綴tmp,當每個文件的寫入條數(可配置,比如100條)達到要求條數時,將后綴tmp改為out。
問題:大類共有30個,小類不計其數而且未知,比如大類為A,小類為a
時間戳為20180606095835234則A目錄下的文件名為20180606095835234_a.tmp這樣一來需要在此文件寫滿100條時,更新時間戳生成第二個文件名,如果此時有1000個文件都在寫則需要有1000個時間戳,和1000個計數器記錄每個文件當前的條數,如果分別定義1000個變量顯然是不劃算的。
嘗試:中間過程想到了動態定義變量名,即
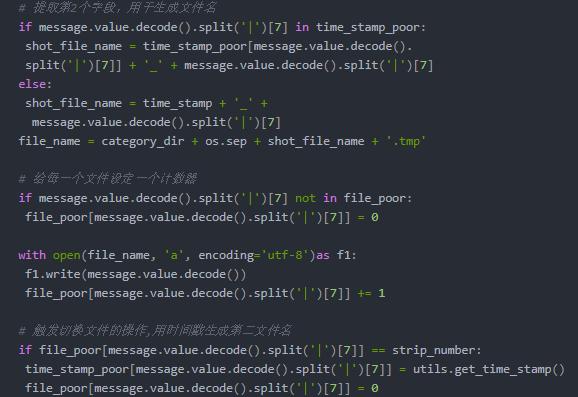
- 定義第七個字段:seven = data.split('|')[7]
- 定義文件名:filename = time_stamp + '_' + seven+'.tmp',
- 定義文件計數器:seven + ‘_num' = 0
- 定義文件時間戳:seven + '_stamp' = time.time( )
- 想法其實是沒問題的,但是這里用到了一個不常用的語法:用一個變量名和一個字符串拼接出來一個新的變量名,并繼續賦值(不知道我的表述是否清楚),試過了用local()函數、global()函數、exec()函數都沒有達到預期效果,也許是把問題想的太復雜了
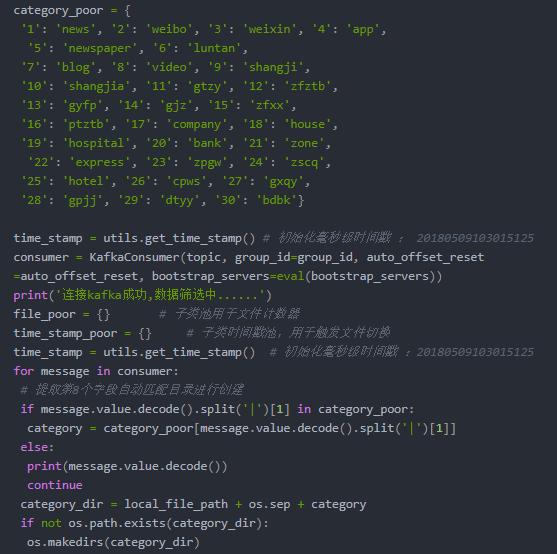
- 解決:最后使用三個字典將這個問題完美解決,
- 定義一個字典用來存計數器,字典的每一個鍵對應一個文件名,值對應當前計數,并實時更新;
- 定義一個字典用來存時間戳,鍵對應一個文件名,值對應時間戳,達到100條就更新一次;
- 定義一個字典用來存大類,鍵對應代號,值對應分類;
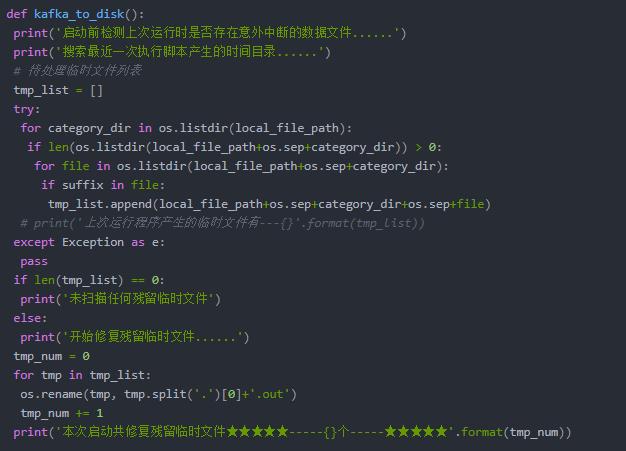
局部功能代碼如下:
結尾:
以上這篇python 解決動態的定義變量名,并給其賦值的方法(大數據處理)就是小編分享給大家的全部內容了。
最后多說一句,小編是一名python開發工程師,這里有我自己整理了一套最新的python系統學習教程,包括從基礎的python腳本到web開發、爬蟲、數據分析、數據可視化、機器學習等。想要這些資料的可以關注小編,并在后臺私信小編:“07”即可領取。


)




)









)
![筆記45 | 代碼性能優化建議[轉]](http://pic.xiahunao.cn/筆記45 | 代碼性能優化建議[轉])
