文章目錄
- 1. 常用機器學習模型
- 1.1 回歸模型
- 1.2 分類模型
- 1.2.1 SVC介紹
- 1.2.2 SVC在量化策略中的應用
- 2. 機器學習量化策略實現的基本步驟
- 3. 策略實現
1. 常用機器學習模型
1.1 回歸模型
- 線性回歸
- 多層感知器回歸
- 自適應提升樹回歸
- 隨機森林回歸
1.2 分類模型
- 線性分類
- 支持向量機
- XGBoost分類
- K近鄰分類
1.2.1 SVC介紹
SVC(Support Vector Classifier)是一種在機器學習中常用的分類算法,它基于支持向量機(Support Vector Machine)算法。SVC通過尋找最佳的超平面來實現分類任務,在數據平面上進行線性或非線性的劃分。
1.2.2 SVC在量化策略中的應用
在量化策略中,SVC(Support Vector Classifier)可以用于股票預測和交易決策。以下是SVC在量化策略中的應用步驟:
-
數據準備:首先,需要準備訓練數據和測試數據。訓練數據包括歷史股票價格和相關特征,以及對應的標簽(例如漲跌幅度)。測試數據包括最新的股票價格和特征,用于進行預測。
-
特征工程:根據歷史股票數據,使用技術指標或其他特征工程方法構建特征。這些特征可能包括移動平均線、波動性指標、成交量等。
-
數據預處理:將訓練數據和測試數據進行標準化,使其均值為0,方差為1。這可以提高分類算法的性能。
-
訓練模型:使用訓練數據訓練SVC模型。在訓練過程中,SVC將學習股票的價格模式和特征之間的關系。
-
模型預測:使用訓練好的SVC模型對測試數據進行預測。根據預測結果,判斷股票是漲還是跌。
-
交易決策:根據預測結果進行交易決策。例如,如果SVC預測股票會漲,可以選擇買入;如果SVC預測股票會跌,可以選擇賣出或不做操作。
-
交易執行:根據交易決策執行相應的交易操作。這可能涉及到下單、調整倉位等操作。
-
盈虧評估:根據交易結果評估策略的盈虧情況。可以計算交易收益、回撤等指標,進行策略的優化和調整。
需要注意的是,SVC作為機器學習算法,對數據的準備和特征工程至關重要。合理選擇特征和調整參數可以顯著影響SVC的預測性能。此外,量化策略中還需要考慮交易成本、風險管理和市場流動性等因素,以構建更加完整和可靠的策略。
2. 機器學習量化策略實現的基本步驟
- 加載數據
- 標注數據
- 特征工程,分割訓練集和測試集
- 選擇機器學習模型并配置適當的參數
- 訓練模型
- 利用模型數據樣本之外的數據進行回測
- 對回測結果進行可視化
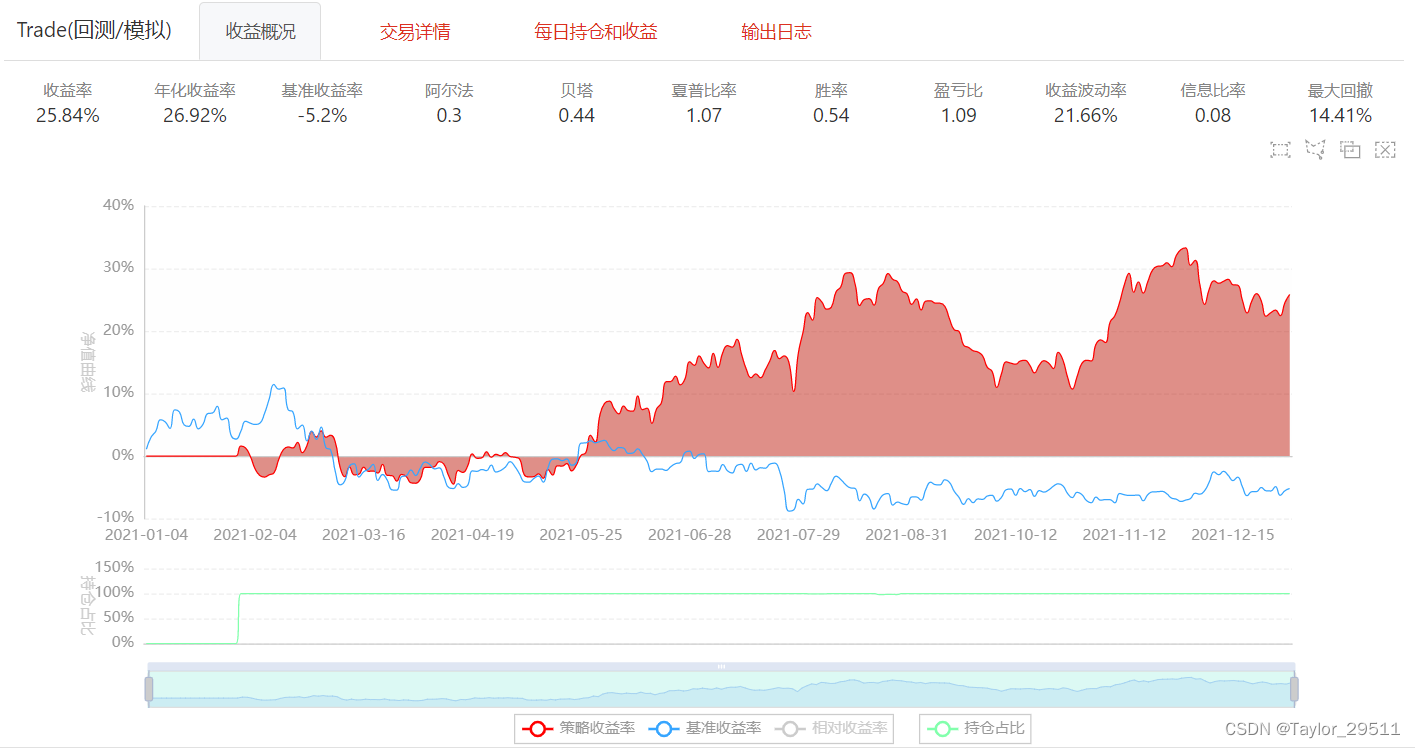
3. 策略實現
本部分將介紹如何在BigQuant實現一個基于支持向量機模型的選股策略
from biglearning.api import M
from biglearning.api import tools as T
from bigdatasource.api import DataSource
from biglearning.module2.common.data import Outputs
from zipline.finance.commission import PerOrder# 對訓練數據和測試數據進行標準化處理
def m6_run_bigquant_run(input_1, input_2, input_3):train_df = input_1.read()features = input_2.read()feature_min = train_df[features].quantile(0.005)feature_max = train_df[features].quantile(0.995)train_df[features] = train_df[features].clip(feature_min,feature_max,axis=1) data_1 = DataSource.write_df(train_df)test_df = input_3.read()test_df[features] = test_df[features].clip(feature_min,feature_max,axis=1)data_2 = DataSource.write_df(test_df)return Outputs(data_1=data_1, data_2=data_2, data_3=None)# 后處理函數
def m6_post_run_bigquant_run(outputs):return outputs# 處理每個交易日的數據
def m4_handle_data_bigquant_run(context, data):context.extension['index'] += 1if context.extension['index'] % context.rebalance_days != 0:return date = data.current_dt.strftime('%Y-%m-%d')cur_data = context.indicator_data[context.indicator_data['date'] == date]cur_data = cur_data[cur_data['pred_label'] == 1.0]stock_to_buy = list(cur_data.sort_values('instrument',ascending=False).instrument)[:context.stock_num]if date == '2017-02-06':print(date, len(stock_to_buy), stock_to_buy)# 獲取當前持倉股票stock_hold_now = [equity.symbol for equity in context.portfolio.positions]# 需要保留的股票no_need_to_sell = [i for i in stock_hold_now if i in stock_to_buy]# 需要賣出的股票stock_to_sell = [i for i in stock_hold_now if i not in no_need_to_sell]for stock in stock_to_sell:if data.can_trade(context.symbol(stock)):context.order_target_percent(context.symbol(stock), 0)if len(stock_to_buy) == 0:returnweight = 1 / len(stock_to_buy)for stock in stock_to_buy:if data.can_trade(context.symbol(stock)):context.order_target_percent(context.symbol(stock), weight)# 準備工作
def m4_prepare_bigquant_run(context):pass# 初始化策略
def m4_initialize_bigquant_run(context):context.indicator_data = context.options['data'].read_df()context.set_commission(PerOrder(buy_cost=0.0003, sell_cost=0.0013, min_cost=5))context.rebalance_days = 5context.stock_num = 50if 'index' not in context.extension:context.extension['index'] = 0# 開盤前處理函數
def m4_before_trading_start_bigquant_run(context, data):pass# 獲取2020年至2021年股票數據
m1 = M.instruments.v2(start_date='2020-01-01',end_date='2021-01-01',market='CN_STOCK_A',instrument_list='',max_count=0
)# 使用高級自動標注器獲取標簽
m2 = M.advanced_auto_labeler.v2(instruments=m1.data,label_expr="""shift(close, -5) / shift(open, -1)-1
rank(label)
where(label>=0.95,1,0)""",start_date='',end_date='',benchmark='000300.SHA',drop_na_label=False,cast_label_int=False
)# 輸入特征
m3 = M.input_features.v1(features="""(close_0-mean(close_0,12))/mean(close_0,12)*100
rank(std(amount_0,15))
rank_avg_amount_0/rank_avg_amount_8
ts_argmin(low_0,20)
rank_return_30
(low_1-close_0)/close_0
ta_bbands_lowerband_14_0
mean(mf_net_pct_s_0,4)
amount_0/avg_amount_3
return_0/return_5
return_1/return_5
rank_avg_amount_7/rank_avg_amount_10
ta_sma_10_0/close_0
sqrt(high_0*low_0)-amount_0/volume_0*adjust_factor_0
avg_turn_15/(turn_0+1e-5)
return_10
mf_net_pct_s_0
(close_0-open_0)/close_1"""
)# 抽取基礎特征
m15 = M.general_feature_extractor.v7(instruments=m1.data,features=m3.data,start_date='',end_date='',before_start_days=0
)# 提取派生特征
m16 = M.derived_feature_extractor.v3(input_data=m15.data,features=m3.data,date_col='date',instrument_col='instrument',drop_na=False,remove_extra_columns=False
)# 合并標簽和特征
m7 = M.join.v3(data1=m2.data,data2=m16.data,on='date,instrument',how='inner',sort=False
)# 刪除缺失值
m13 = M.dropnan.v1(input_data=m7.data
)# 獲取2021年至2022年股票數據
m9 = M.instruments.v2(start_date=T.live_run_param('trading_date', '2021-01-01'),end_date=T.live_run_param('trading_date', '2022-01-01'),market='CN_STOCK_A',instrument_list='',max_count=0
)# 抽取基礎特征
m17 = M.general_feature_extractor.v7(instruments=m9.data,features=m3.data,start_date='',end_date='',before_start_days=0
)# 提取派生特征
m18 = M.derived_feature_extractor.v3(input_data=m17.data,features=m3.data,date_col='date',instrument_col='instrument',drop_na=False,remove_extra_columns=False
)# 刪除缺失值
m14 = M.dropnan.v1(input_data=m18.data
)# 標準化訓練數據和測試數據
m6 = M.cached.v3(input_1=m13.data,input_2=m3.data,input_3=m14.data,run=m6_run_bigquant_run,post_run=m6_post_run_bigquant_run,input_ports='',params='{}',output_ports=''
)# 對數據進行RobustScaler標準化處理
m8 = M.RobustScaler.v13(train_ds=m6.data_1,features=m3.data,test_ds=m6.data_2,scale_type='standard',quantile_range_min=0.01,quantile_range_max=0.99,global_scale=True
)# 使用SVC進行訓練和預測
m10 = M.svc.v1(training_ds=m8.train_data,features=m3.data,predict_ds=m8.test_data,C=1,kernel='rbf',degree=3,gamma=-1,coef0=0,tol=0.1,max_iter=100,key_cols='date,instrument',other_train_parameters={}
)# 創建交易策略實例
m4 = M.trade.v4(instruments=m9.data,options_data=m10.predictions,start_date='',end_date='',handle_data=m4_handle_data_bigquant_run,prepare=m4_prepare_bigquant_run,initialize=m4_initialize_bigquant_run,before_trading_start=m4_before_trading_start_bigquant_run,volume_limit=0,order_price_field_buy='open',order_price_field_sell='open',capital_base=10000000,auto_cancel_non_tradable_orders=True,data_frequency='daily',price_type='后復權',product_type='股票',plot_charts=True,backtest_only=False,benchmark=''
)









![[tidb] tiup升級tidb的版本到 v7.1.1](http://pic.xiahunao.cn/[tidb] tiup升級tidb的版本到 v7.1.1)




大數據實戰——Hive的metastore元數據服務安裝)



)
