目錄
背景:
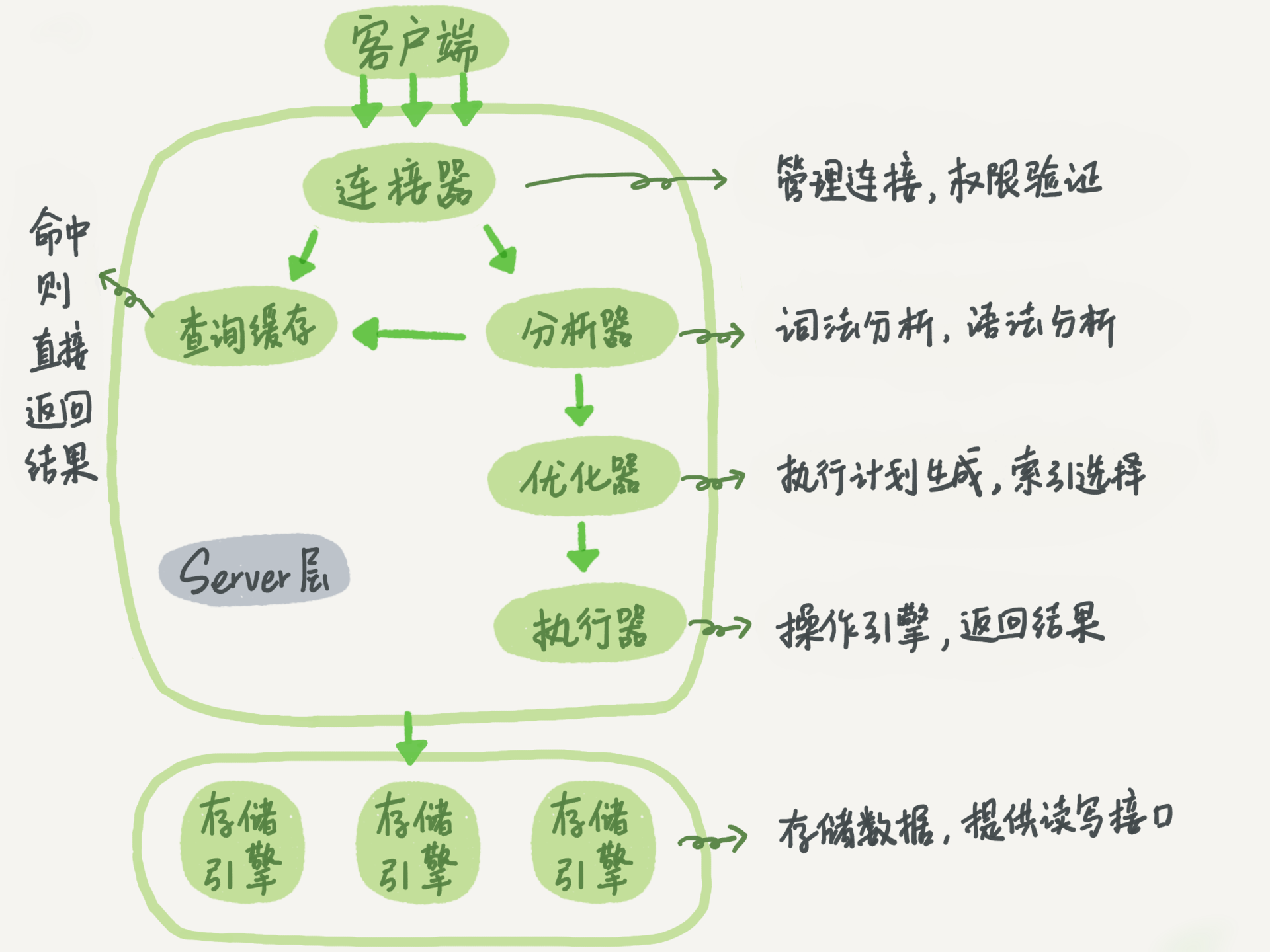
mysql 整體結構:
SQL查詢語句執行過程是怎樣的:
? 知道了mysql的整體架構,那么一條查詢語句是怎么被執行的呢:
什么是索引:?
建立索引越多越好嗎:
如何發現慢查詢:
如何優化滿查詢:
背景:
性能測試過程中,數據庫往往是造成性能瓶頸之一,而數據庫瓶頸中sql 語句又是值得探究分析的一環,其中慢查詢是重點優化對象,在MySQL中,慢查詢是指查詢執行時間較長或者消耗
較多資源的查詢語句。具體來說,MySQL中可以通過設置一個閾值來定義慢查詢,通常默認情況下是超過2秒鐘的查詢會被認為是慢查詢,但是這個閾值可以根據具體情況進行調整。
慢查詢的存在可能會對MySQL數據庫的性能產生負面影響,因為它會占用大量的計算資源和I/O資源,導致其他查詢的響應時間變慢。因此,及時發現并優化慢查詢非常重要。
mysql 整體結構:
MySQL是一個典型的客戶端-服務器(Client-Server)架構系統,它主要由以下幾個組件構成:
-
客戶端(Client):客戶端是指連接到MySQL服務器的程序或工具,它們可以通過網絡或本地套接字與MySQL服務器通信。MySQL提供了多種客戶端工具,如mysql命令行工具、MySQL Workbench、phpMyAdmin等。
-
連接管理器(Connection Manager):連接管理器負責管理客戶端連接和會話。它接收客戶端的連接請求,并根據配置文件中的參數來限制連接數、最大并發數等,確保MySQL服務器的穩定性和安全性。
-
查詢解析器(Query Parser):查詢解析器負責解析客戶端提交的SQL查詢語句,并將其轉換成MySQL服務器可理解的內部數據結構。在此過程中,查詢解析器會檢查查詢語句的語法和語義是否正確,以及權限是否足夠執行該查詢。
-
優化器(Optimizer):優化器是MySQL查詢執行的關鍵組件,它負責優化查詢執行計劃,以獲得最佳的執行效率。優化器會分析查詢語句,選擇最優的索引、表的訪問順序、連接方式等來執行查詢。MySQL提供了多種優化器,如基于規則的優化器、基于成本的優化器等。
-
存儲引擎(Storage Engine):存儲引擎是MySQL數據庫中存儲和管理數據的核心組件。MySQL支持多種存儲引擎,如InnoDB、MyISAM、MEMORY等。每個存儲引擎都有其獨特的特性和適用場景,如InnoDB適合于高并發、事務性操作,MyISAM適合于讀密集型操作等。
-
緩存(Cache):緩存是MySQL性能優化的重要手段之一。MySQL提供了多種緩存機制,如查詢緩存、表緩存、緩沖池等。查詢緩存可以緩存查詢結果,以減少重復查詢的開銷;表緩存可以緩存表結構,以加速表的訪問;緩沖池可以緩存磁盤上的數據,以提高數據訪問的速度。
總的來說,MySQL架構是由客戶端、連接管理器、查詢解析器、優化器、存儲引擎和緩存等組件構成的。每個組件都有其獨特的作用和功能,共同協作來實現MySQL數據庫系統的高效穩定運行。
SQL查詢語句執行過程是怎樣的:
? 知道了mysql的整體架構,那么一條查詢語句是怎么被執行的呢:
你會先連接到這個數據庫上,這時候接待你的就是連接器,連接建立完成后,執行邏輯就會來到查詢緩存。如果開啟來了查詢緩存,之前執行過的語句及其結果可能會以 key-value 對的形
式,被直接緩存在內存中。如果命中,value直接返回給客戶端。沒有命中,則繼續。執行完成后,執行結果會被存入查詢緩存中。如果沒有命中查詢緩存,進入分析器,通過詞法分析+語法分
析對 SQL 語句做解析,語法錯誤是從這個環節報出的。優化器是為了提升SQL的執行性能。經過了分析器,MySQL 就知道要做什么了。在開始執行之前,還要先經過優化器的處理。在表里面
有多個索引的時候,決定使用哪個索引;或者在一個語句有多表關聯(join)的時候,決定各個表的連接順序。優化器優化后進入了執行器階段,執行器跟存儲層進行交互,取得執行結果并返
回。
什么是索引:?
索引是一種用于加速數據庫查詢的數據結構。它可以快速定位到滿足查詢條件的記錄,從而提高查詢效率和性能。簡單來講,索引的出現其實就是為了提高數據查詢的效率,就像書的目錄
一樣,如果你想快速找到其中的某一個知識點,在不借助目錄的情況下,那我估計你可得找一會兒。同樣,對于數據庫的表而言,索引其實就是它的“目錄”。在MySQL中,索引通常是基于B-
Tree(B樹)或哈希表實現的。
索引主要包括主鍵索引和和非主鍵索引,主鍵索引是建立在表的主鍵列上的索引,而非主鍵索引則是建立在其他列或列組合上的索引。在查詢過程中,主鍵索引和非主鍵索引的查詢方式和效率有所不同。對于主鍵索引,MySQL可以通過B-Tree索引結構快速定位到指定的行記錄,因為主鍵索引唯一,每個值都對應一個行記錄,因此可以直接找到匹配的行記錄。例如,如果需要查詢id為10的學生記錄,可以使用如下的SQL語句:
SELECT * FROM students WHERE id = 10;
MySQL會利用主鍵索引快速定位到id為10的行記錄,效率非常高。而對于非主鍵索引,MySQL也可以通過B-Tree索引結構定位到滿足查詢條件的行記錄,但是需要額外的步驟。首先,MySQL會根據非主鍵索引找到滿足查詢條件的行記錄的主鍵值,然后再通過主鍵索引定位到實際的行記錄。例如,如果需要查詢姓名為“Tom”的學生記錄,可以使用如下的SQL語句:
SELECT * FROM students WHERE name = 'Tom';
MySQL會利用非主鍵索引idx_students_name找到所有姓名為“Tom”的行記錄的主鍵值,然后再根據主鍵索引定位到實際的行記錄。這個過程稱為“回表查詢”,需要額外的IO操作和CPU計
算,因此效率相對較低。如果表中的數據量很大,回表查詢的開銷會更加顯著。
建立索引越多越好嗎:
建立索引并不是越多越好,反而可能會對數據庫性能產生負面影響。首先,索引會占用存儲空間,如果過多地建立索引,會導致數據庫占用更多的磁盤空間,對于大型數據庫來說,這可能
會導致磁盤空間不足。其次,索引會影響插入、更新和刪除操作的性能。當進行插入、更新和刪除操作時,MySQL需要更新數據和索引,如果過多地建立索引,就會使這些操作花費更多的時
間,從而降低數據庫的性能。
最后,索引會影響查詢操作的效率。雖然索引可以加速查詢操作,但是如果過多地建立索引,就會導致MySQL需要在多個索引中選擇最優的索引,這會增加查詢的開銷,并且可能會導致
MySQL選擇不合適的索引,從而降低查詢的效率。因此,在建立索引時,需要根據具體情況進行選擇,避免過多地建立索引。通常情況下,可以考慮在經常使用的列上建立索引,或者在需要優
化查詢的列上建立索引。同時,可以通過監控索引的使用情況,來確定哪些索引需要優化或刪除,以提高數據庫的性能和效率。
如何發現慢查詢:
1.? 通過設置slow_query_log參數來開啟慢查詢日志,對慢查詢日志進行監控,如果新增慢查詢便立即發送通知。(推薦)
2.?慢查詢日志分析工具:MySQL提供了一些工具,如mysqldumpslow和mysqlsla,可以根據查詢日志來分析慢查詢,找出執行時間最長的查詢和最頻繁的查詢等信息。
如何優化滿查詢:
情況1 :通過explain你可能會發現,SQL壓根沒走任何索引,而且現在表中的數據量巨大無比。
解決:建合適索引
情況2 :?通過explain查看SQL執行計劃中的key字段。如果發現優化器選擇的Key和你預期的Key不一樣。那顯然是優化器選錯了索引
解決:?最快的解決方案就是:force index ,強制指定索引,或通過增加索引、優化索引、重構查詢語句等方式來提高查詢效率
情況3 :查詢語句復雜或者存在大量子查詢
解決:查詢語句復雜或者存在大量子查詢會影響查詢性能,可以考慮通過優化SQL語句來提高查詢效率。例如,可以使用JOIN語句替換多個子查詢,或者使用WHERE子句限制返回的行數。
分析優化實踐:
假設有一個名為“orders”的表,包含以下列:
- id: INT,主鍵列
- customer_id: INT,顧客編號
- status: ENUM('pending', 'completed', 'cancelled'),訂單狀態
- order_date: DATETIME,訂單日期
- amount: DECIMAL(10,2),訂單金額
現在需要查詢所有訂單金額大于1000元的未完成訂單,查詢語句如下:
?SELECT * FROM orders WHERE status = 'pending' AND amount > 1000;
首先,可以通過使用EXPLAIN語句來查看查詢計劃,以了解查詢的執行情況:
EXPLAIN SELECT * FROM orders WHERE status = 'pending' AND amount > 1000;
執行后發現?type列的值是ALL,走的全表掃描;key字段是NULL,沒有使用任何索。接下來,可以在status和amount列上建立索引,建立索引的語句如下:
CREATE INDEX idx_orders_status ON orders (status);
CREATE INDEX idx_orders_amount ON orders (amount);
然后再次執行查詢語句,可以看到查詢效率有了顯著提升,查詢速度大大加快。
優化前的查詢計劃如下所示:
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | orders| NULL | ALL | NULL | NULL | NULL | NULL | 10 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+優化后的查詢計劃如下所示:
+----+-------------+-------+------------+------+---------------------------+------------------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------------------+------------------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | orders| NULL | ref | idx_orders_status,idx_orders_amount | idx_orders_status | 2 | const | 5 | 50.00 | Using index condition |
+----+-------------+-------+------------+------+---------------------------+------------------+---------+-------+------+----------+-----------------------+
可以看到,優化后的查詢計劃使用了idx_orders_status索引,查詢效率大大提高。
因此,通過在status和amount列上建立索引的方式,可以提高查詢效率,降低數據庫的負載和響應時間。但需要注意的是,索引的建立需要根據具體情況進行選擇和應用,過多的索引會影響插
入、更新和刪除操作的性能,因此需要謹慎考慮索引的建立數量和方式。
?以下是我收集到的比較好的學習教程資源,雖然不是什么很值錢的東西,如果你剛好需要,可以評論區,留言【777】直接拿走就好了


各位想獲取資料的朋友請點贊 + 評論 + 收藏,三連!
三連之后我會在評論區挨個私信發給你們~


【前后端不分離】自定義View)
















