首先通過論文中所給的圖片了解網絡的整體架構:
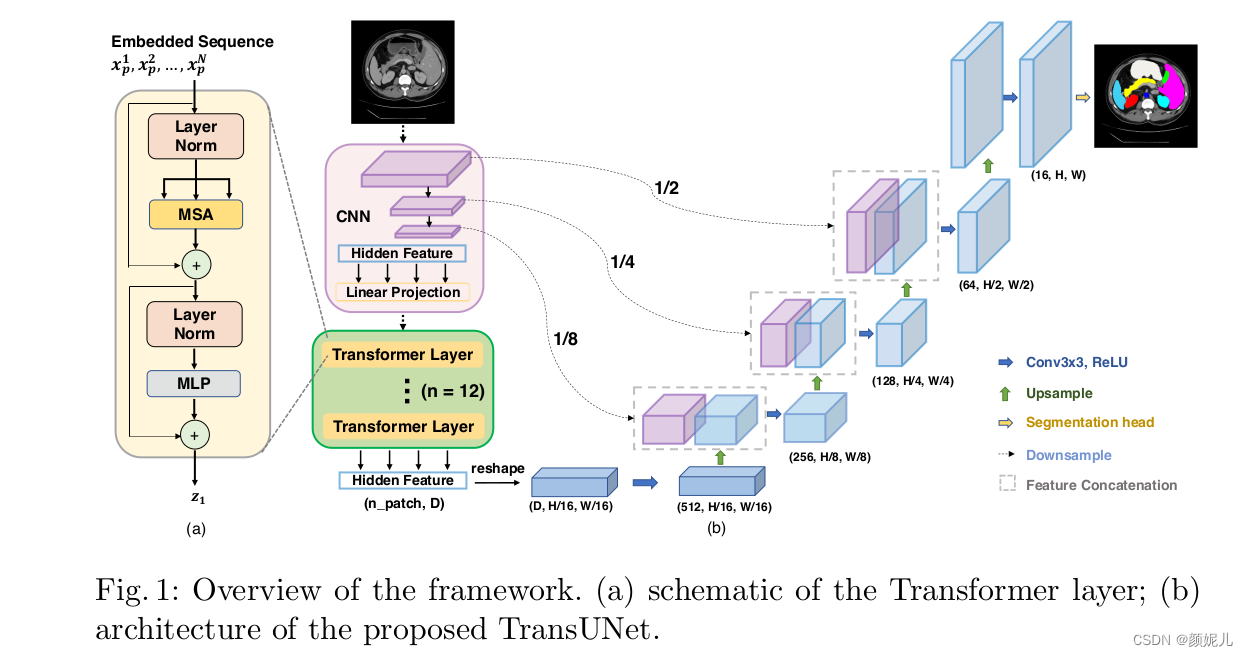
vit_seg_modeling部分
模塊引入和定義相關量:
# coding=utf-8
# __future__ 在老版本的Python代碼中兼顧新特性的一種方法
from __future__ import absolute_import
from __future__ import division
from __future__ import print_functionimport copy
import logging
import mathfrom os.path import join as pjoinimport torch
import torch.nn as nn
import numpy as npfrom torch.nn import CrossEntropyLoss, Dropout, Softmax, Linear, Conv2d, LayerNorm
from torch.nn.modules.utils import _pair
from scipy import ndimage
from . import vit_seg_configs as configs
from .vit_seg_modeling_resnet_skip import ResNetV2logger = logging.getLogger(__name__)ATTENTION_Q = "MultiHeadDotProductAttention_1/query"
ATTENTION_K = "MultiHeadDotProductAttention_1/key"
ATTENTION_V = "MultiHeadDotProductAttention_1/value"
ATTENTION_OUT = "MultiHeadDotProductAttention_1/out"
FC_0 = "MlpBlock_3/Dense_0"
FC_1 = "MlpBlock_3/Dense_1"
ATTENTION_NORM = "LayerNorm_0"
MLP_NORM = "LayerNorm_2"# 獲取超參
CONFIGS = {'ViT-B_16': configs.get_b16_config(),'ViT-B_32': configs.get_b32_config(),'ViT-L_16': configs.get_l16_config(),'ViT-L_32': configs.get_l32_config(),'ViT-H_14': configs.get_h14_config(),'R50-ViT-B_16': configs.get_r50_b16_config(),'R50-ViT-L_16': configs.get_r50_l16_config(),'testing': configs.get_testing(),
}
工具函數的定義:
np2th用于將numpy格式的數據改為tensor。
def np2th(weights, conv=False):"""Possibly convert HWIO to OIHW."""if conv:weights = weights.transpose([3, 2, 0, 1])return torch.from_numpy(weights)
swish時由谷歌團隊提出來的激活函數,他們實驗表明,在一些具有挑戰性的數據集上,它的效果比relu更好。
def swish(x):return x * torch.sigmoid(x)ACT2FN = {"gelu": torch.nn.functional.gelu, "relu": torch.nn.functional.relu, "swish": swish}
采用自頂向下的結構來理解代碼
VisionTransformer就是模型的整個結構,其中調用了Transformer,DecoderCup,SegmentationHead,load_from用于加載訓練好的參數。
class VisionTransformer(nn.Module):def __init__(self, config, img_size=224, num_classes=21843, zero_head=False, vis=False):super(VisionTransformer, self).__init__()self.num_classes = num_classesself.zero_head = zero_headself.classifier = config.classifierself.transformer = Transformer(config, img_size, vis)self.decoder = DecoderCup(config)self.segmentation_head = SegmentationHead(in_channels=config['decoder_channels'][-1],out_channels=config['n_classes'],kernel_size=3,)self.config = configdef forward(self, x):if x.size()[1] == 1:x = x.repeat(1, 3, 1, 1)x, attn_weights, features = self.transformer(x) # (B, n_patch, hidden)x = self.decoder(x, features)logits = self.segmentation_head(x)return logitsdef load_from(self, weights):# with torch.no_grad()將所有require_grad臨時設置為False,這樣可以只更新變量的值with torch.no_grad():res_weight = weightsself.transformer.embeddings.patch_embeddings.weight.copy_(np2th(weights["embedding/kernel"], conv=True))self.transformer.embeddings.patch_embeddings.bias.copy_(np2th(weights["embedding/bias"]))self.transformer.encoder.encoder_norm.weight.copy_(np2th(weights["Transformer/encoder_norm/scale"]))self.transformer.encoder.encoder_norm.bias.copy_(np2th(weights["Transformer/encoder_norm/bias"]))posemb = np2th(weights["Transformer/posembed_input/pos_embedding"])posemb_new = self.transformer.embeddings.position_embeddingsif posemb.size() == posemb_new.size():self.transformer.embeddings.position_embeddings.copy_(posemb)elif posemb.size()[1] - 1 == posemb_new.size()[1]:posemb = posemb[:, 1:]self.transformer.embeddings.position_embeddings.copy_(posemb)else:logger.info("load_pretrained: resized variant: %s to %s" % (posemb.size(), posemb_new.size()))ntok_new = posemb_new.size(1)if self.classifier == "seg":_, posemb_grid = posemb[:, :1], posemb[0, 1:]gs_old = int(np.sqrt(len(posemb_grid)))gs_new = int(np.sqrt(ntok_new))print('load_pretrained: grid-size from %s to %s' % (gs_old, gs_new))posemb_grid = posemb_grid.reshape(gs_old, gs_old, -1)zoom = (gs_new / gs_old, gs_new / gs_old, 1)posemb_grid = ndimage.zoom(posemb_grid, zoom, order=1) # th2npposemb_grid = posemb_grid.reshape(1, gs_new * gs_new, -1)posemb = posemb_gridself.transformer.embeddings.position_embeddings.copy_(np2th(posemb))# Encoder wholefor bname, block in self.transformer.encoder.named_children():for uname, unit in block.named_children():unit.load_from(weights, n_block=uname)if self.transformer.embeddings.hybrid:self.transformer.embeddings.hybrid_model.root.conv.weight.copy_(np2th(res_weight["conv_root/kernel"], conv=True))# .view(-1)將tensor展開為一維張量,但不改變該對象本身的形狀gn_weight = np2th(res_weight["gn_root/scale"]).view(-1)gn_bias = np2th(res_weight["gn_root/bias"]).view(-1)self.transformer.embeddings.hybrid_model.root.gn.weight.copy_(gn_weight)self.transformer.embeddings.hybrid_model.root.gn.bias.copy_(gn_bias)for bname, block in self.transformer.embeddings.hybrid_model.body.named_children():for uname, unit in block.named_children():unit.load_from(res_weight, n_block=bname, n_unit=uname)接下來是Transformer的代碼:
Transformer包括了Embeddings和Encoder:
class Transformer(nn.Module):def __init__(self, config, img_size, vis):super(Transformer, self).__init__()self.embeddings = Embeddings(config, img_size=img_size)self.encoder = Encoder(config, vis)def forward(self, input_ids):embedding_output, features = self.embeddings(input_ids)encoded, attn_weights = self.encoder(embedding_output) # (B, n_patch, hidden)return encoded, attn_weights, features
Embeddings的功能對應于圖片中的:
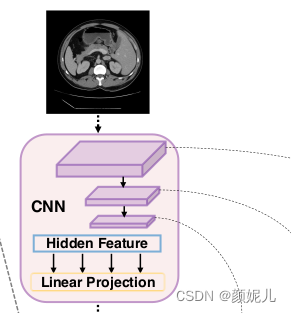
ResNetV2(這部分的代碼放在最后一個部分)對圖片通過卷積操作提取特征,然后將提取到的各層特征返回到Embeddings。
拿到ResNetV2返回的特征后,將最后一層的特征分割為多個切片,并將各個切片映射成長度為patch_size*patch_size*channels的向量,并且加上位置序列信息,對應于圖片的這個部分:

class Embeddings(nn.Module):"""Construct the embeddings from patch, position embeddings."""def __init__(self, config, img_size, in_channels=3):super(Embeddings, self).__init__()self.hybrid = Noneself.config = config# 應該是把參數中的img_size,轉換為元組形式即:img_size = (value,value)這里的value即為參數的img_size。img_size = _pair(img_size)if config.patches.get("grid") is not None: # ResNetgrid_size = config.patches["grid"] # grid 是一個元組,值為:輸入圖片大小//切片大小patch_size = (img_size[0] // 16 // grid_size[0], img_size[1] // 16 // grid_size[1])patch_size_real = (patch_size[0] * 16, patch_size[1] * 16)n_patches = (img_size[0] // patch_size_real[0]) * (img_size[1] // patch_size_real[1])self.hybrid = Trueelse:patch_size = _pair(config.patches["size"])n_patches = (img_size[0] // patch_size[0]) * (img_size[1] // patch_size[1])self.hybrid = Falseif self.hybrid:self.hybrid_model = ResNetV2(block_units=config.resnet.num_layers, width_factor=config.resnet.width_factor)in_channels = self.hybrid_model.width * 16# patch_embeddings通過卷積操作將輸入轉變為(B, hidden_size, n_patches^(1/2), n_patches^(1/2))# hidden_size是一個token(相當于輸入的一個詞)的長度self.patch_embeddings = Conv2d(in_channels=in_channels,out_channels=config.hidden_size,kernel_size=patch_size,stride=patch_size)# 各個向量的位置序列self.position_embeddings = nn.Parameter(torch.zeros(1, n_patches, config.hidden_size))self.dropout = Dropout(config.transformer["dropout_rate"])def forward(self, x):if self.hybrid:x, features = self.hybrid_model(x)else:features = Nonex = self.patch_embeddings(x) # (B, hidden, n_patches^(1/2), n_patches^(1/2))x = x.flatten(2) # 表示從2維開始壓縮,得到(B, hidden, n_patches)x = x.transpose(-1, -2) # 對最后兩個維度進行轉置(B, n_patches, hidden)embeddings = x + self.position_embeddings # 加上位置序列embeddings = self.dropout(embeddings)return embeddings, featuresEncoder是圖像的編碼部分,根據num_layers生成多個Block模塊
class Encoder(nn.Module):def __init__(self, config, vis):super(Encoder, self).__init__()self.vis = vis# nn.ModuleList()一個module列表,與普通的list相比,它繼承了nn.Module的網絡模型class,因此可以識別其中的parameters,# 即該列表中記錄的module可以被主module識別,但它只是一個list,不會自動實現forward方法。self.layer = nn.ModuleList()self.encoder_norm = LayerNorm(config.hidden_size, eps=1e-6)for _ in range(config.transformer["num_layers"]):layer = Block(config, vis)self.layer.append(copy.deepcopy(layer))def forward(self, hidden_states):attn_weights = []for layer_block in self.layer:hidden_states, weights = layer_block(hidden_states)if self.vis:attn_weights.append(weights)encoded = self.encoder_norm(hidden_states)return encoded, attn_weights
Block包括了MSA(Multihead Self-Attention)和MSA(Multi-Layer Perceptron)兩個結構,對應于圖像中的:
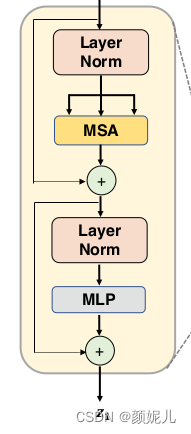
class Block(nn.Module):def __init__(self, config, vis):super(Block, self).__init__()self.hidden_size = config.hidden_sizeself.attention_norm = LayerNorm(config.hidden_size, eps=1e-6)self.ffn_norm = LayerNorm(config.hidden_size, eps=1e-6)self.ffn = Mlp(config)self.attn = Attention(config, vis)def forward(self, x):h = xx = self.attention_norm(x)x, weights = self.attn(x)x = x + hh = xx = self.ffn_norm(x)x = self.ffn(x)x = x + hreturn x, weightsdef load_from(self, weights, n_block):ROOT = f"Transformer/encoderblock_{n_block}"with torch.no_grad():query_weight = np2th(weights[pjoin(ROOT, ATTENTION_Q, "kernel")]).view(self.hidden_size,self.hidden_size).t()key_weight = np2th(weights[pjoin(ROOT, ATTENTION_K, "kernel")]).view(self.hidden_size, self.hidden_size).t()value_weight = np2th(weights[pjoin(ROOT, ATTENTION_V, "kernel")]).view(self.hidden_size,self.hidden_size).t()out_weight = np2th(weights[pjoin(ROOT, ATTENTION_OUT, "kernel")]).view(self.hidden_size,self.hidden_size).t()query_bias = np2th(weights[pjoin(ROOT, ATTENTION_Q, "bias")]).view(-1)key_bias = np2th(weights[pjoin(ROOT, ATTENTION_K, "bias")]).view(-1)value_bias = np2th(weights[pjoin(ROOT, ATTENTION_V, "bias")]).view(-1)out_bias = np2th(weights[pjoin(ROOT, ATTENTION_OUT, "bias")]).view(-1)self.attn.query.weight.copy_(query_weight)self.attn.key.weight.copy_(key_weight)self.attn.value.weight.copy_(value_weight)self.attn.out.weight.copy_(out_weight)self.attn.query.bias.copy_(query_bias)self.attn.key.bias.copy_(key_bias)self.attn.value.bias.copy_(value_bias)self.attn.out.bias.copy_(out_bias)mlp_weight_0 = np2th(weights[pjoin(ROOT, FC_0, "kernel")]).t()mlp_weight_1 = np2th(weights[pjoin(ROOT, FC_1, "kernel")]).t()mlp_bias_0 = np2th(weights[pjoin(ROOT, FC_0, "bias")]).t()mlp_bias_1 = np2th(weights[pjoin(ROOT, FC_1, "bias")]).t()self.ffn.fc1.weight.copy_(mlp_weight_0)self.ffn.fc2.weight.copy_(mlp_weight_1)self.ffn.fc1.bias.copy_(mlp_bias_0)self.ffn.fc2.bias.copy_(mlp_bias_1)self.attention_norm.weight.copy_(np2th(weights[pjoin(ROOT, ATTENTION_NORM, "scale")]))self.attention_norm.bias.copy_(np2th(weights[pjoin(ROOT, ATTENTION_NORM, "bias")]))self.ffn_norm.weight.copy_(np2th(weights[pjoin(ROOT, MLP_NORM, "scale")]))self.ffn_norm.bias.copy_(np2th(weights[pjoin(ROOT, MLP_NORM, "bias")]))Attention對應圖中的MSA部分,num_heads即為多頭注意力機制的數量,attention_head_size為每個注意力機制的輸出大小。Multihead self-attention 就是采用多個注意力機制來預測,但實現時并不是采用循環來實現多次,由于每個注意力機制采用相同的策略,他們只存在學習到的參數的差異,所以可以直接學習一個大的參數矩陣,我的理解如下圖所示:
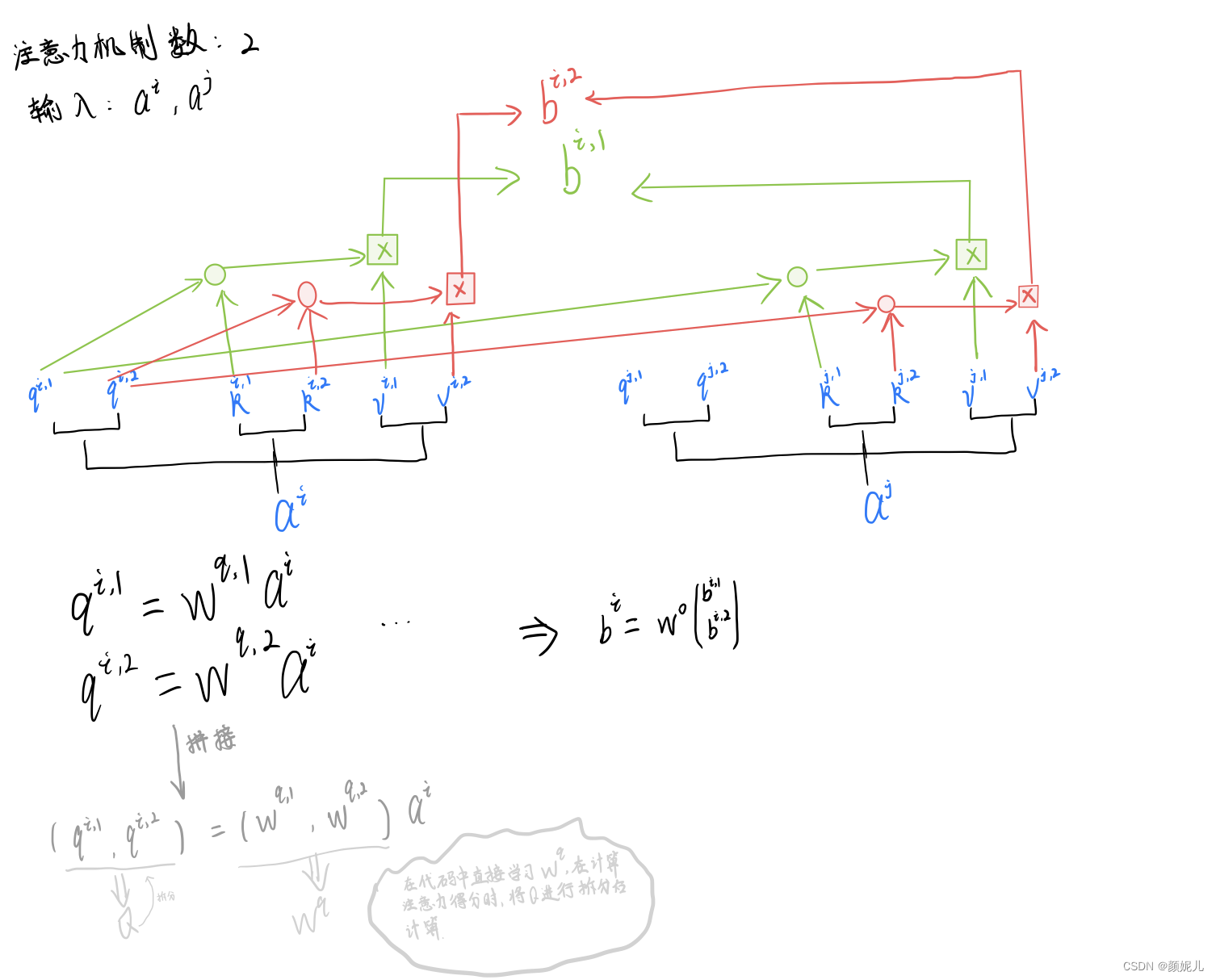
class Attention(nn.Module):def __init__(self, config, vis):super(Attention, self).__init__()self.vis = visself.num_attention_heads = config.transformer["num_heads"]self.attention_head_size = int(config.hidden_size / self.num_attention_heads)self.all_head_size = self.num_attention_heads * self.attention_head_sizeself.query = Linear(config.hidden_size, self.all_head_size)self.key = Linear(config.hidden_size, self.all_head_size)self.value = Linear(config.hidden_size, self.all_head_size)self.out = Linear(config.hidden_size, config.hidden_size)self.attn_dropout = Dropout(config.transformer["attention_dropout_rate"])self.proj_dropout = Dropout(config.transformer["attention_dropout_rate"])self.softmax = Softmax(dim=-1)def transpose_for_scores(self, x):# new_x_shape (B, n_patch, num_attention_heads, attention_head_size)new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)# view()方法主要用于Tensor維度的重構,即返回一個有相同數據但不同維度的Tensorx = x.view(*new_x_shape)# permute可以對任意高維矩陣進行轉置,transpose只能操作2D矩陣的轉置return x.permute(0, 2, 1, 3) # return (B, num_attention_heads, n_patch, attention_head_size)def forward(self, hidden_states):# hidden_states (B, n_patch, hidden)# mixed_* (B, n_patch, all_head_size)mixed_query_layer = self.query(hidden_states)mixed_key_layer = self.key(hidden_states)mixed_value_layer = self.value(hidden_states)query_layer = self.transpose_for_scores(mixed_query_layer)key_layer = self.transpose_for_scores(mixed_key_layer)value_layer = self.transpose_for_scores(mixed_value_layer)# torch.matmul矩陣相乘# key_layer.transpose(-1, -2): (B, num_attention_heads, attention_head_size, n_patch)# attention_scores: (B, num_attention_heads, n_patch, n_patch)attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))attention_scores = attention_scores / math.sqrt(self.attention_head_size)attention_probs = self.softmax(attention_scores)weights = attention_probs if self.vis else Noneattention_probs = self.attn_dropout(attention_probs)# context_layer (B, num_attention_heads, n_patch, attention_head_size)context_layer = torch.matmul(attention_probs, value_layer)# context_layer (B, n_patch, num_attention_heads, attention_head_size)# contiguous一般與transpose,permute,view搭配使用:使用transpose或permute進行維度變換后,調用contiguous,然后方可使用view對維度進行變形context_layer = context_layer.permute(0, 2, 1, 3).contiguous()# new_context_layer_shape (B, n_patch,all_head_size)new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)context_layer = context_layer.view(*new_context_layer_shape)attention_output = self.out(context_layer)# attention_output (B, n_patch,hidden_size)# 小細節 attention_head_size = int(hidden_size / num_attention_heads),all_head_size = num_attention_heads * attention_head_size# 所以應該滿足hidden_size能被num_attention_heads整除attention_output = self.proj_dropout(attention_output)return attention_output, weights
Mlp也就是一個前饋神經網絡
class Mlp(nn.Module):"""Multi-Layer Perceptron: 多層感知器"""def __init__(self, config):super(Mlp, self).__init__()self.fc1 = Linear(config.hidden_size, config.transformer["mlp_dim"])self.fc2 = Linear(config.transformer["mlp_dim"], config.hidden_size)self.act_fn = ACT2FN["gelu"]self.dropout = Dropout(config.transformer["dropout_rate"])self._init_weights()def _init_weights(self):# nn.init.xavier_uniform_初始化權重,避免深度神經網絡訓練過程中的梯度消失和梯度爆炸問題nn.init.xavier_uniform_(self.fc1.weight)nn.init.xavier_uniform_(self.fc2.weight)# nn.init.normal_是正態初始化函數nn.init.normal_(self.fc1.bias, std=1e-6)nn.init.normal_(self.fc2.bias, std=1e-6)def forward(self, x):x = self.fc1(x)x = self.act_fn(x)x = self.dropout(x)x = self.fc2(x)x = self.dropout(x)return x
至此,Transformer所調用的模塊結束了。
DecoderCup 對對應圖片向上解碼的部分:
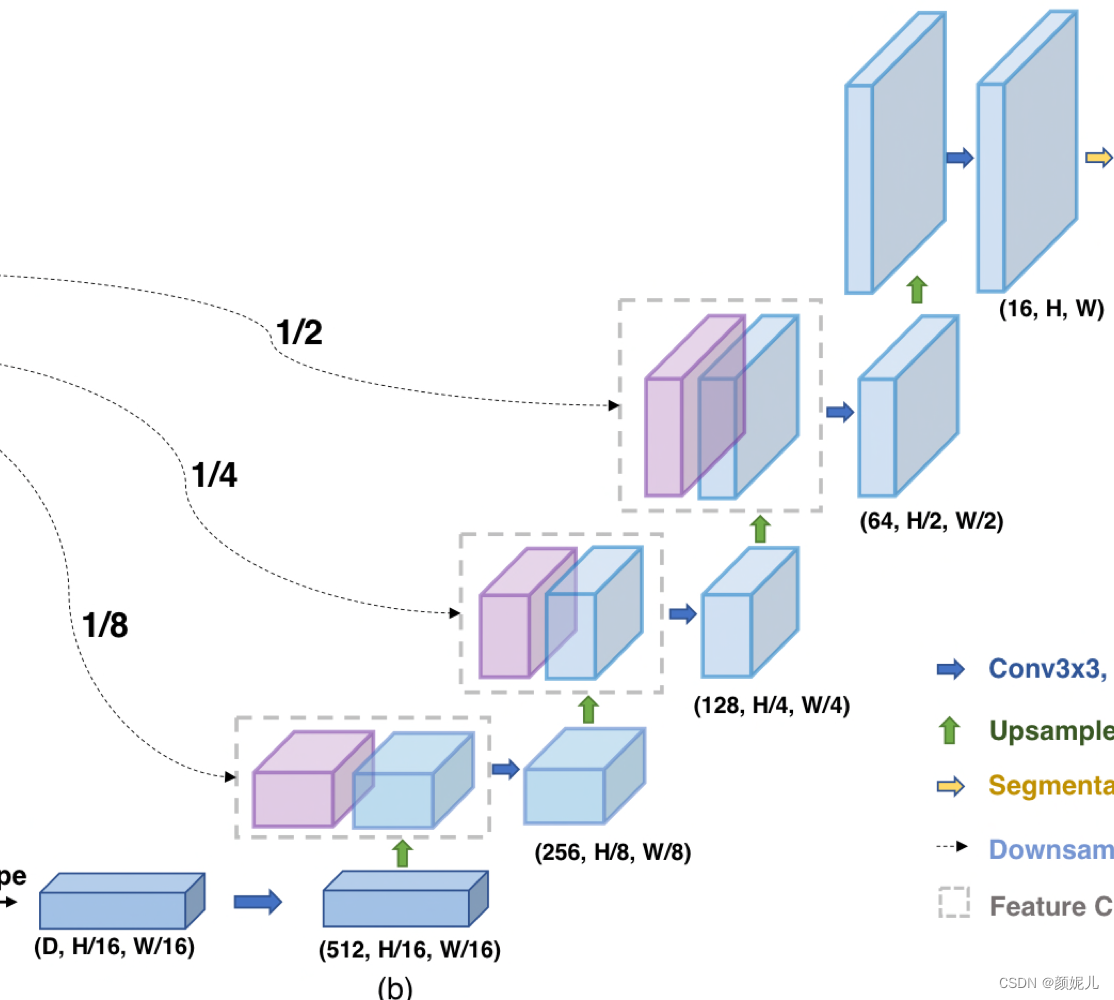
在forward函數中的
B, n_patch, hidden = hidden_states.size() # hidden_states: (B, n_patch, hidden)
h, w = int(np.sqrt(n_patch)), int(np.sqrt(n_patch))
x = hidden_states.permute(0, 2, 1) # x: (B, hidden, n_patch)
x = x.contiguous().view(B, hidden, h, w) # x: (B, hidden, h, w)
x = self.conv_more(x) # (B, hidden, h, w) ===> (B, 512, h', w')
將Transformer的輸出(B, n_patch, hidden),先轉化為(B, hidden, h, w),其中 h , w = n _ p a t c h = H 16 = W 16 h,w = \sqrt{n\_patch} = \frac{H}{16}= \frac{W}{16} h,w=n_patch?=16H?=16W? ,即:
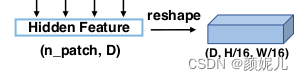
然后通過卷積操作conv_more得到(512, hidden, h, w):

class DecoderCup(nn.Module):def __init__(self, config):super().__init__()self.config = confighead_channels = 512self.conv_more = Conv2dReLU(config.hidden_size,head_channels,kernel_size=3,padding=1,use_batchnorm=True,)decoder_channels = config.decoder_channels # decoder_channels (256, 128, 64, 16)in_channels = [head_channels] + list(decoder_channels[:-1]) # in_channels = [512, 256, 128, 64]out_channels = decoder_channels# config.n_skip = 3if self.config.n_skip != 0:skip_channels = self.config.skip_channels # config.skip_channels = [512, 256, 64, 16]for i in range(4 - self.config.n_skip): # re-select the skip channels according to n_skipskip_channels[3 - i] = 0 # ===》skip_channels = [512, 256, 64, 0]else:skip_channels = [0, 0, 0, 0]# in_channels = [512, 256, 128, 64] out_channels = (256, 128, 64, 16)blocks = [DecoderBlock(in_ch, out_ch, sk_ch) for in_ch, out_ch, sk_ch in zip(in_channels, out_channels, skip_channels)]self.blocks = nn.ModuleList(blocks)def forward(self, hidden_states, features=None):B, n_patch, hidden = hidden_states.size() # hidden_states: (B, n_patch, hidden)h, w = int(np.sqrt(n_patch)), int(np.sqrt(n_patch))x = hidden_states.permute(0, 2, 1) # x: (B, hidden, n_patch)x = x.contiguous().view(B, hidden, h, w) # x: (B, hidden, h, w)x = self.conv_more(x) # (B, hidden, h, w) ===> (B, 512, h, w)for i, decoder_block in enumerate(self.blocks):if features is not None:skip = features[i] if (i < self.config.n_skip) else Noneelse:skip = Nonex = decoder_block(x, skip=skip)return x
DecoderBlock就是逐層向上解碼的過程,首先通過插值上采樣UpsamplingBilinear2d擴大H和W,隨后與對應的feature進行拼接后進行卷積,即:
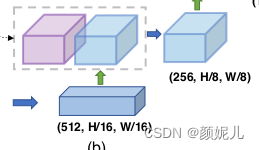
class DecoderBlock(nn.Module):def __init__(self,in_channels,out_channels,skip_channels=0,use_batchnorm=True,):super().__init__()self.conv1 = Conv2dReLU(in_channels + skip_channels,out_channels,kernel_size=3,padding=1,use_batchnorm=use_batchnorm,)self.conv2 = Conv2dReLU(out_channels,out_channels,kernel_size=3,padding=1,use_batchnorm=use_batchnorm,)self.up = nn.UpsamplingBilinear2d(scale_factor=2)def forward(self, x, skip=None):x = self.up(x)if skip is not None:x = torch.cat([x, skip], dim=1)x = self.conv1(x)x = self.conv2(x)return x
SegmentationHead對應于圖像分割部分:
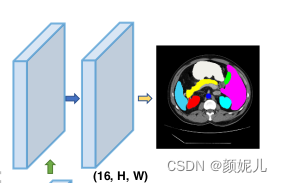
nn.Identity()不對輸入進行任何操作,常在分類任務中替換最后一層,得到分類前得到的特征,常用于遷移學習,用法舉例:
model = models.resnet18()
# replace last linar layer with nn.Identity
model.fc = nn.Identity()# get features for input
x = torch.randn(1, 3, 224, 224)
out = model(x)
print(out.shape)
> torch.Size([1, 512])
SegmentationHead模塊:
class SegmentationHead(nn.Sequential):def __init__(self, in_channels, out_channels, kernel_size=3, upsampling=1):conv2d = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=kernel_size // 2)upsampling = nn.UpsamplingBilinear2d(scale_factor=upsampling) if upsampling > 1 else nn.Identity()super().__init__(conv2d, upsampling)
最后是ResNetV2模塊,該模塊在vit_seg_modeling_resnet_skip文件中,對應圖片中的:
該模塊的相關包及其工具函數:
import mathfrom os.path import join as pjoin
from collections import OrderedDictimport torch
import torch.nn as nn
import torch.nn.functional as Fdef np2th(weights, conv=False):"""Possibly convert HWIO to OIHW."""if conv:weights = weights.transpose([3, 2, 0, 1])return torch.from_numpy(weights)class StdConv2d(nn.Conv2d):def forward(self, x):w = self.weightv, m = torch.var_mean(w, dim=[1, 2, 3], keepdim=True, unbiased=False)w = (w - m) / torch.sqrt(v + 1e-5)return F.conv2d(x, w, self.bias, self.stride, self.padding,self.dilation, self.groups)def conv3x3(cin, cout, stride=1, groups=1, bias=False):return StdConv2d(cin, cout, kernel_size=3, stride=stride,padding=1, bias=bias, groups=groups)def conv1x1(cin, cout, stride=1, bias=False):return StdConv2d(cin, cout, kernel_size=1, stride=stride,padding=0, bias=bias)
class ResNetV2(nn.Module):"""Implementation of Pre-activation (v2) ResNet mode."""def __init__(self, block_units, width_factor):super().__init__()width = int(64 * width_factor)self.width = widthself.root = nn.Sequential(OrderedDict([('conv', StdConv2d(3, width, kernel_size=7, stride=2, bias=False, padding=3)),('gn', nn.GroupNorm(32, width, eps=1e-6)),('relu', nn.ReLU(inplace=True)),# ('pool', nn.MaxPool2d(kernel_size=3, stride=2, padding=0))]))self.body = nn.Sequential(OrderedDict([('block1', nn.Sequential(OrderedDict([('unit1', PreActBottleneck(cin=width, cout=width*4, cmid=width))] +[(f'unit{i:d}', PreActBottleneck(cin=width*4, cout=width*4, cmid=width)) for i in range(2, block_units[0] + 1)],))),('block2', nn.Sequential(OrderedDict([('unit1', PreActBottleneck(cin=width*4, cout=width*8, cmid=width*2, stride=2))] +[(f'unit{i:d}', PreActBottleneck(cin=width*8, cout=width*8, cmid=width*2)) for i in range(2, block_units[1] + 1)],))),('block3', nn.Sequential(OrderedDict([('unit1', PreActBottleneck(cin=width*8, cout=width*16, cmid=width*4, stride=2))] +[(f'unit{i:d}', PreActBottleneck(cin=width*16, cout=width*16, cmid=width*4)) for i in range(2, block_units[2] + 1)],))),]))def forward(self, x):features = []b, c, in_size, _ = x.size()x = self.root(x)features.append(x)x = nn.MaxPool2d(kernel_size=3, stride=2, padding=0)(x)for i in range(len(self.body)-1):x = self.body[i](x)right_size = int(in_size / 4 / (i+1))if x.size()[2] != right_size:pad = right_size - x.size()[2]assert pad < 3 and pad > 0, "x {} should {}".format(x.size(), right_size)feat = torch.zeros((b, x.size()[1], right_size, right_size), device=x.device)feat[:, :, 0:x.size()[2], 0:x.size()[3]] = x[:]else:feat = xfeatures.append(feat)x = self.body[-1](x)return x, features[::-1]
class PreActBottleneck(nn.Module):"""Pre-activation (v2) bottleneck block."""def __init__(self, cin, cout=None, cmid=None, stride=1):super().__init__()cout = cout or cincmid = cmid or cout//4self.gn1 = nn.GroupNorm(32, cmid, eps=1e-6)self.conv1 = conv1x1(cin, cmid, bias=False)self.gn2 = nn.GroupNorm(32, cmid, eps=1e-6)self.conv2 = conv3x3(cmid, cmid, stride, bias=False) # Original code has it on conv1!!self.gn3 = nn.GroupNorm(32, cout, eps=1e-6)self.conv3 = conv1x1(cmid, cout, bias=False)self.relu = nn.ReLU(inplace=True)if (stride != 1 or cin != cout):# Projection also with pre-activation according to paper.self.downsample = conv1x1(cin, cout, stride, bias=False)self.gn_proj = nn.GroupNorm(cout, cout)def forward(self, x):# Residual branchresidual = xif hasattr(self, 'downsample'):residual = self.downsample(x)residual = self.gn_proj(residual)# Unit's branchy = self.relu(self.gn1(self.conv1(x)))y = self.relu(self.gn2(self.conv2(y)))y = self.gn3(self.conv3(y))y = self.relu(residual + y)return ydef load_from(self, weights, n_block, n_unit):conv1_weight = np2th(weights[pjoin(n_block, n_unit, "conv1/kernel")], conv=True)conv2_weight = np2th(weights[pjoin(n_block, n_unit, "conv2/kernel")], conv=True)conv3_weight = np2th(weights[pjoin(n_block, n_unit, "conv3/kernel")], conv=True)gn1_weight = np2th(weights[pjoin(n_block, n_unit, "gn1/scale")])gn1_bias = np2th(weights[pjoin(n_block, n_unit, "gn1/bias")])gn2_weight = np2th(weights[pjoin(n_block, n_unit, "gn2/scale")])gn2_bias = np2th(weights[pjoin(n_block, n_unit, "gn2/bias")])gn3_weight = np2th(weights[pjoin(n_block, n_unit, "gn3/scale")])gn3_bias = np2th(weights[pjoin(n_block, n_unit, "gn3/bias")])self.conv1.weight.copy_(conv1_weight)self.conv2.weight.copy_(conv2_weight)self.conv3.weight.copy_(conv3_weight)self.gn1.weight.copy_(gn1_weight.view(-1))self.gn1.bias.copy_(gn1_bias.view(-1))self.gn2.weight.copy_(gn2_weight.view(-1))self.gn2.bias.copy_(gn2_bias.view(-1))self.gn3.weight.copy_(gn3_weight.view(-1))self.gn3.bias.copy_(gn3_bias.view(-1))if hasattr(self, 'downsample'):proj_conv_weight = np2th(weights[pjoin(n_block, n_unit, "conv_proj/kernel")], conv=True)proj_gn_weight = np2th(weights[pjoin(n_block, n_unit, "gn_proj/scale")])proj_gn_bias = np2th(weights[pjoin(n_block, n_unit, "gn_proj/bias")])self.downsample.weight.copy_(proj_conv_weight)self.gn_proj.weight.copy_(proj_gn_weight.view(-1))self.gn_proj.bias.copy_(proj_gn_bias.view(-1))
由于只有在hybrid模式下才用到這部分的代碼,所以目前并沒有去了解為什么采用StdConv2d和GroupNorm,后面再去ViT里面找答案吧。










)

-CAM自定義銑加工的出口環境)

)




