NLP文本匹配任務Text Matching [無監督訓練]:SimCSE、ESimCSE、DiffCSE 項目實踐
文本匹配多用于計算兩個文本之間的相似度,該示例會基于 ESimCSE 實現一個無監督的文本匹配模型的訓練流程。文本匹配多用于計算兩段「自然文本」之間的「相似度」。
例如,在搜索引擎中,我們通常需要判斷用戶的搜索內容是否相似:
A:蛋黃吃多了有什么壞處 B:吃雞蛋白過多有什么壞處 -> 不相似
A:蛋黃吃多了有什么壞處 B:蛋黃可以多吃嗎 -> 相似
...那最直覺的思路就是讓人工去標注文本對,再喂給模型去學習,這種方法稱為基于「監督學習」訓練出的模型:
但是,如果我們今天沒有這么多的標注數據,只有一大堆的「未標注」數據,我們還能訓練一個匹配模型嗎?這種不依賴于「人工標注數據」的方式,就叫做「無監督」(或自監督)學習方式。我們今天要講的 SimCSE, 就是一種「無監督」訓練模型。
SimCSE: Simple Contrastive Learning of Sentence Embeddings
1.SimCSE 是如何做到無監督的?
SimCSE 將對比學習(Contrastive Learning)的思想引入到文本匹配中。對比學習的核心思想就是:將相似的樣本拉近,將不相似的樣本推遠。
但現在問題是:我們沒有標注數據,怎么知道哪些文本是相似的,哪些是不相似的呢?SimCSE 相出了一種很妙的辦法,由于預訓練模型在訓練的時候通常都會使用 dropout 機制。這就意味著:即使是同一個樣本過兩次模型也會得到兩個不同的 embedding。而因為同樣的樣本,那一定是相似的,模型輸出的這兩個 embedding 距離就應當盡可能的相近;反之,那些不同的輸入樣本過模型后得到的 embedding 就應當盡可能的被推遠。
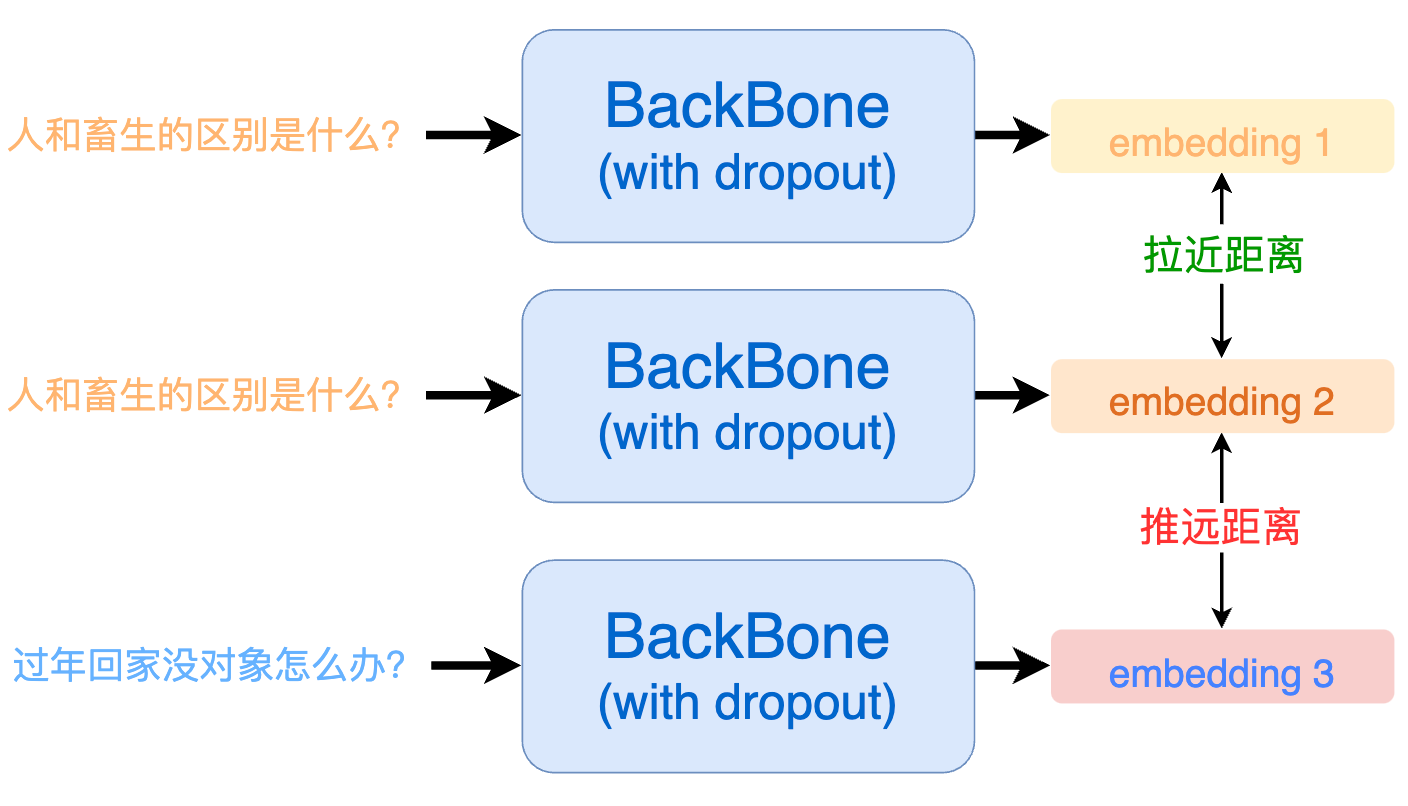
具體來講,一個 batch 內每個句子會過 2 次模型,得到 2 * batch 個向量,將這些句子中通過同樣句子得到的向量設置為正例,其他設置為負例。
假設 a1 和 a2 是由句子 a 過兩次模型得到的結果,那么一個 batch 內的正負例構建如下所示:
| a1 | a2 | b1 | b2 | c1 | c2 | |
|---|---|---|---|---|---|---|
| a1 | -100 | 1 | 0 | 0 | 0 | 0 |
| a2 | 1 | -100 | 0 | 0 | 0 | 0 |
| b1 | 0 | 0 | -100 | 1 | 0 | 0 |
| b2 | 0 | 0 | 1 | -100 | 0 | 0 |
| c1 | 0 | 0 | 0 | 0 | -100 | 1 |
| c2 | 0 | 0 | 0 | 0 | 1 | -100 |
其中,對角線上的 - 100 表示自身和自身不做相似度比較。
2. SimCSE 的缺點?
從 SimCSE 的正例構建中我們可以看出來,所有的正例都是由「同一個句子」過了兩次模型得到的。這就會造成一個問題:模型會更傾向于認為,長度相同的句子就代表一樣的意思。由于數據樣本是隨機選取的,那么很有可能在一個 batch 內采樣到的句子長度是不相同的。
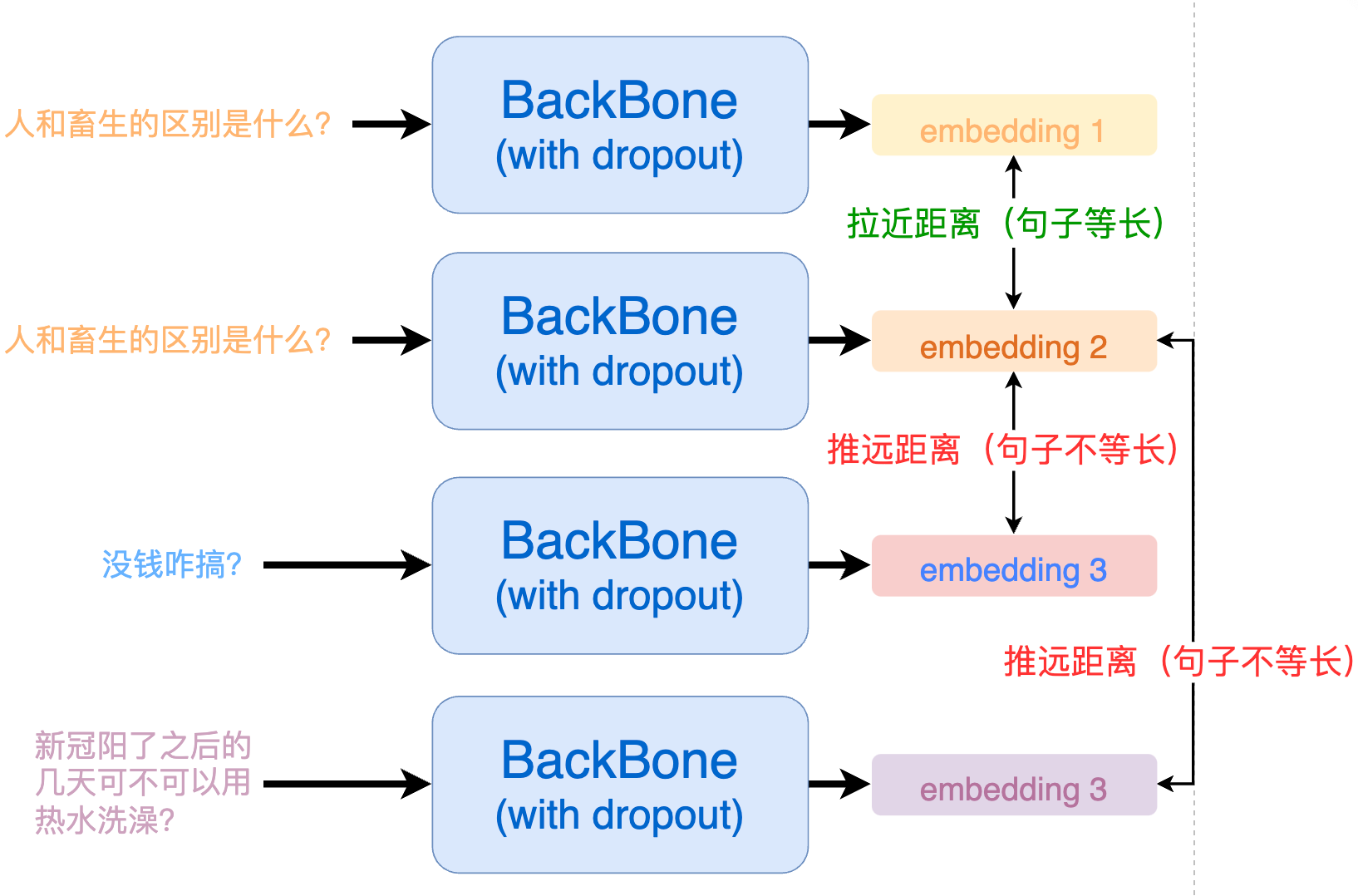
為了解決這個問題,我們最終采取的實現方式為 ESimCSE。
3. ESimCSE 解決模型對文本長度的敏感問題
ESimCSE 通過隨機重復單詞(Word Repetition)的方式來構建正例,巧妙的解決了句子長度敏感性的問題:
ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding
要想消除模型對句子長度的敏感,我們就需要在構建正例的時候讓輸入句子的長度發生改變,如下所示:
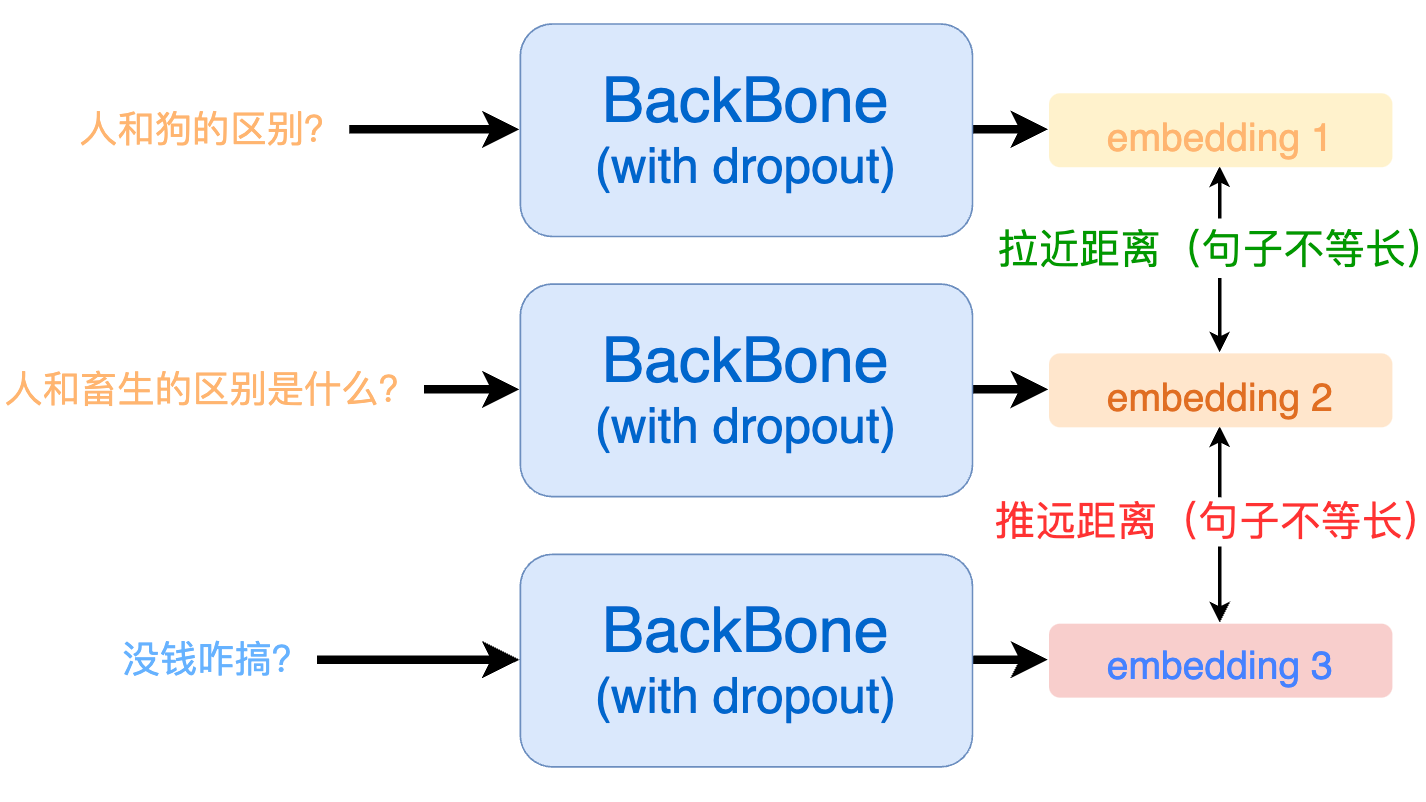
那么,改變句子長度通常有 3 種方法:隨機刪除、隨機添加、同義詞替換,但它們均存在句意變化的風險:
| 方法 | 原句子 | 變換后的句子 | 句意是否改變 |
|---|---|---|---|
| 隨機刪除 | 我 [不] 喜歡你 | 我喜歡你 | 是 |
| 隨機添加 | 今天的飯好吃 | 今天的飯 [不] 好吃 | 是 |
| 同義詞替換 | 小明長得像一只 [狼] | 小明長得像一只 [狗] | 是 |
用語義變換后的句子去構建正例,模型效果自然會受到影響。
那如果我們隨機重復一些單詞呢?
| 方法 | 原句子 | 變換后的句子 | 句意是否改變 |
|---|---|---|---|
| 隨機重復單詞 | 今天天氣很好 | 今今天天氣很好好 | 否 |
| 隨機重復單詞 | 我喜歡你 | 我我喜歡歡你 | 否 |
可以看到,通過隨機重復單詞,既能夠改變句子長度,又不會輕易改變語義。
實現上,假設我們有一個 batch 的句子,我們先依次將每一個句子都進行隨機單詞重復(產生正例),如下:
origin -> ['人和畜生的區別', '今天天氣很好', '三星手機屏幕是不是最好的?']
repetition -> ['人人和畜生的的區別', '今今天天氣很好好', '三星星手機屏屏幕是不是最最好好的?']隨后,我們將 origin 的 embedding(batch,768) 和 repetition 的 embedding(batch,768)做矩陣乘法,可以得到一個矩陣(batch,batch),矩陣對角線上就是正例,其余的均是負例:
| 句子 a | 句子 b | 句子 c | |
|---|---|---|---|
| 句子 a | 0.9248 | 0.2342 | 0.4242 |
| 句子 b | 0.3142 | 0.9123 | 0.1422 |
| 句子 c | 0.2903 | 0.1857 | 0.9983 |
矩陣中第(i,j)個元素代表 origin 列表中的第 i 個元素和 repetition 列表中第 j 個元素的相似度。
接下來就好構建訓練標簽了,因為 label 都在對角線上,所以第 n 行的 label 就是 n 。
labels = [i for i in range(len(origin))] # labels = [0, 1, 2]之后就用 CrossEntropyLoss 去計算并梯度回傳就能開始訓練啦。
def forward(self,query_input_ids: torch.tensor,query_token_type_ids: torch.tensor,doc_input_ids: torch.tensor,doc_token_type_ids: torch.tensor,device='cpu') -> torch.tensor:"""傳入query/doc對,構建正/負例并計算contrastive loss。Args:query_input_ids (torch.LongTensor): (batch, seq_len)query_token_type_ids (torch.LongTensor): (batch, seq_len)doc_input_ids (torch.LongTensor): (batch, seq_len)doc_token_type_ids (torch.LongTensor): (batch, seq_len)device (str): 使用設備Returns:torch.tensor: (1)"""query_embedding = self.get_pooled_embedding(input_ids=query_input_ids,token_type_ids=query_token_type_ids) # (batch, self.output_embedding_dim)doc_embedding = self.get_pooled_embedding(input_ids=doc_input_ids,token_type_ids=doc_token_type_ids) # (batch, self.output_embedding_dim)cos_sim = torch.matmul(query_embedding, doc_embedding.T) # (batch, batch)margin_diag = torch.diag(torch.full( # (batch, batch), 只有對角線等于margin值的對角矩陣size=[query_embedding.size()[0]], fill_value=self.margin)).to(device)cos_sim = cos_sim - margin_diag # 主對角線(正例)的余弦相似度都減掉 margincos_sim *= self.scale # 縮放相似度,便于收斂labels = torch.arange( # 只有對角上為正例,其余全是負例,所以這個batch樣本標簽為 -> [0, 1, 2, ...]0, query_embedding.size()[0], dtype=torch.int64).to(device)loss = self.criterion(cos_sim, labels)return loss4.DiffCSE
結合句子間差異的無監督句子嵌入對比學習方法——DiffCSE主要還是在SimCSE上進行優化(可見SimCSE的重要性),通過ELECTRA模型的生成偽造樣本和RTD(Replaced Token Detection)任務,來學習原始句子與偽造句子之間的差異,以提高句向量表征模型的效果。
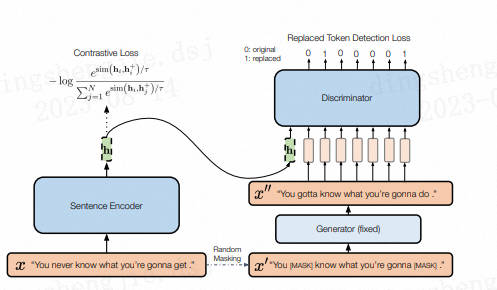
其思想同樣來自于CV領域(采用不變對比學習和可變對比學習相結合的方法可以提高圖像表征的效果)。作者提出使用基于dropout masks機制的增強作為不敏感轉換學習對比學習損失和基于MLM語言模型進行詞語替換的方法作為敏感轉換學習「原始句子與編輯句子」之間的差異,共同優化句向量表征。
在SimCSE模型中,采用pooler層(一個帶有tanh激活函數的全連接層)作為句子向量輸出。該論文發現,采用帶有BN的兩層pooler效果更為突出,BN在SimCSE模型上依然有效。
①對于掩碼概率,經實驗發現,在掩碼概率為30%時,模型效果最優。
②針對兩個損失之間的權重值,經實驗發現,對比學習損失為RTD損失200倍時,模型效果最優。
參考鏈接:https://blog.csdn.net/PX2012007/article/details/127696477
5. 數據集準備
項目中提供了一部分示例數據,我們使用未標注的用戶搜索記錄數據來訓練一個文本匹配模型,數據在 data/LCQMC 。
若想使用自定義數據訓練,只需要仿照示例數據構建數據集即可:
- 訓練集:
喜歡打籃球的男生喜歡什么樣的女生
我手機丟了,我想換個手機
大家覺得她好看嗎
晚上睡覺帶著耳機聽音樂有什么害處嗎?
學日語軟件手機上的
...
- 測試集:
開初婚未育證明怎么弄? 初婚未育情況證明怎么開? 1
誰知道她是網絡美女嗎? 愛情這杯酒誰喝都會醉是什么歌 0
人和畜生的區別是什么? 人與畜生的區別是什么! 1
男孩喝女孩的尿的故事 怎樣才知道是生男孩還是女孩 0
...
由于是無監督訓練,因此訓練集(train.txt)中不需要記錄標簽,只需要大量的文本即可。
測試集(dev.tsv)用于測試無監督模型的效果,因此需要包含真實標簽。
每一行用 \t 分隔符分開,第一部分部分為句子A,中間部分為句子B,最后一部分為兩個句子是否相似(label)。
6.模型訓練
修改訓練腳本 train.sh 里的對應參數, 開啟模型訓練:
python train.py \--model "nghuyong/ernie-3.0-base-zh" \--train_path "data/LCQMC/train.txt" \--dev_path "data/LCQMC/dev.tsv" \--save_dir "checkpoints/LCQMC" \--img_log_dir "logs/LCQMC" \--img_log_name "ERNIE-ESimCSE" \--learning_rate 1e-5 \--dropout 0.3 \--batch_size 64 \--max_seq_len 64 \--valid_steps 400 \--logging_steps 50 \--num_train_epochs 8 \--device "cuda:0"
正確開啟訓練后,終端會打印以下信息:
...
0%| | 0/2 [00:00<?, ?it/s]
100%|██████████| 2/2 [00:00<00:00, 226.41it/s]
DatasetDict({train: Dataset({features: ['text'],num_rows: 477532})dev: Dataset({features: ['text'],num_rows: 8802})
})
global step 50, epoch: 1, loss: 0.34367, speed: 2.01 step/s
global step 100, epoch: 1, loss: 0.19121, speed: 2.02 step/s
global step 150, epoch: 1, loss: 0.13498, speed: 2.00 step/s
global step 200, epoch: 1, loss: 0.10696, speed: 1.99 step/s
global step 250, epoch: 1, loss: 0.08858, speed: 2.02 step/s
global step 300, epoch: 1, loss: 0.07613, speed: 2.02 step/s
global step 350, epoch: 1, loss: 0.06673, speed: 2.01 step/s
global step 400, epoch: 1, loss: 0.05954, speed: 1.99 step/s
Evaluation precision: 0.58459, recall: 0.87210, F1: 0.69997, spearman_corr:
0.36698
best F1 performence has been updated: 0.00000 --> 0.69997
global step 450, epoch: 1, loss: 0.25825, speed: 2.01 step/s
global step 500, epoch: 1, loss: 0.27889, speed: 1.99 step/s
global step 550, epoch: 1, loss: 0.28029, speed: 1.98 step/s
global step 600, epoch: 1, loss: 0.27571, speed: 1.98 step/s
global step 650, epoch: 1, loss: 0.26931, speed: 2.00 step/s
...
在 logs/LCQMC 文件下將會保存訓練曲線圖:
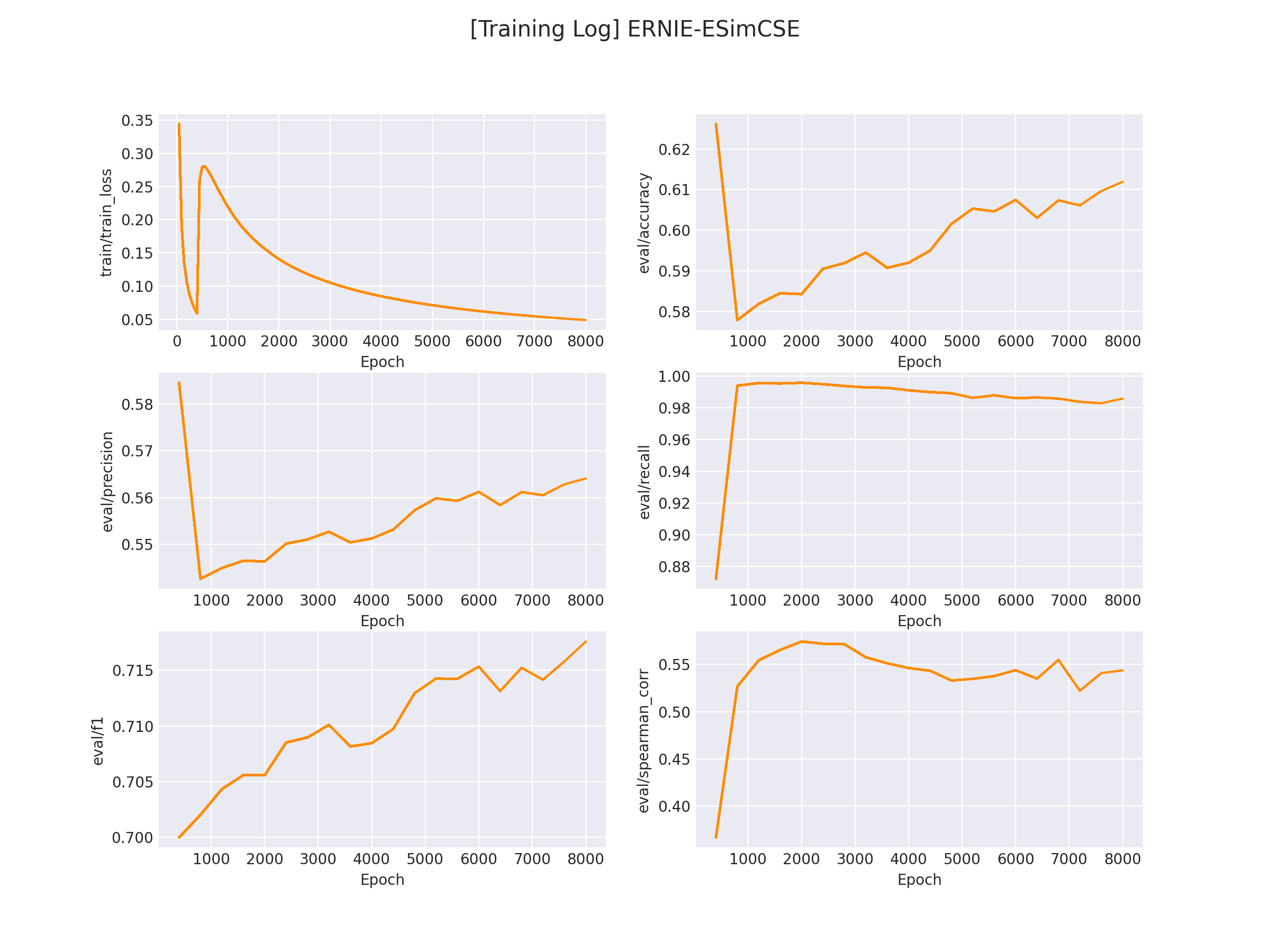
7.模型推理
完成模型訓練后,運行 inference.py 以加載訓練好的模型并應用:
...if __name__ == '__main__':...sentence_pair = [('男孩喝女孩的故事', '怎樣才知道是生男孩還是女孩'),('這種圖片是用什么軟件制作的?', '這種圖片制作是用什么軟件呢?')]...res = inference(query_list, doc_list, model, tokenizer, device)print(res)
運行推理程序:
python inference.py
得到以下推理結果:
[0.1527191698551178, 0.9263839721679688] # 第一對文本相似分數較低,第二對文本相似分數較高
參考鏈接:https://github.com/HarderThenHarder/transformers_tasks/blob/main/text_matching/supervised
github無法連接的可以在:https://download.csdn.net/download/sinat_39620217/88214437 下載
更多優質內容請關注公號:汀丶人工智能;會提供一些相關的資源和優質文章,免費獲取閱讀。
)
)





)





)





:簡單介紹)