作者:Philipp Kahr

Elasticsearch Service 用戶的重要注意事項:目前,本文中描述的 Kibana 設置更改僅限于 Cloud 控制臺,如果沒有我們支持團隊的手動干預,則無法進行配置。 我們的工程團隊正在努力消除對這些設置的限制,以便我們的所有用戶都可以啟用內部 APM。 本地部署不受此問題的影響。?
不久前,我們在 Elasticsearch? 中引入了檢測,讓你能夠識別它在幕后所做的事情。 通過在 Elasticsearch 中進行追蹤,我們獲得了前所未有的見解。
當我們想要利用 Elastic 的學習稀疏編碼器模型進行語義搜索時,本博客將引導你了解各種 API 和 transaction。 該博客本身可以應用于 Elasticsearch 內運行的任何機器學習模型- 你只需相應地更改命令和搜索即可。 本指南中的說明使用我們的稀疏編碼器模型(請參閱文檔)。
對于以下測試,我們的數據語料庫是 OpenWebText,它提供大約 40GB 的純文本和大約 800 萬個單獨的文檔。 此設置在具有 32GB RAM 的 M1 Max Macbook 上本地運行。 以下任何交易持續時間、查詢時間和其他參數僅適用于本博文。 不應對生產用途或你的安裝進行任何推斷。
讓我們動手吧!
在 Elasticsearch 中激活跟蹤是通過靜態設置(在 elasticsearch.yml 中配置)和動態設置來完成的,動態設置可以在運行時使用 PUT _cluster/settings 命令進行切換(動態設置之一是采樣率)。 某些設置可以在 runtime 時切換,例如采樣率。 在elasticsearch.yml中,我們要設置以下內容:
tracing.apm.enabled: true
tracing.apm.agent.server_url: "url of the APM server"秘密令牌(或 API 密鑰)必須位于 Elasticsearch 密鑰庫中。 使用以下命令 elasticsearch-keystore add Tracing.apm.secret_token 或 tracing.apm.api_key ,密鑰庫工具應該可以在 <你的 elasticsearch 安裝目錄>/bin/elasticsearch-keystore 中使用。 之后,你需要重新啟動 Elasticsearch。 有關跟蹤的更多信息可以在我們的跟蹤文檔中找到。
激活后,我們可以在 APM 視圖中看到 Elasticsearch 自動捕獲各種 API 端點。 GET、POST、PUT、DELETE 調用。 整理好之后,讓我們創建索引:
PUT openwebtext-analyzed
{"settings": {"number_of_replicas": 0,"number_of_shards": 1,"index": {"default_pipeline": "openwebtext"}},"mappings": {"properties": {"ml.tokens": {"type": "rank_features"},"text": {"type": "text","analyzer": "english"}}}
}這應該給我們一個名為 PUT /{index} 的單個 transaction。 正如我們所看到的,當我們創建索引時發生了很多事情。 我們有創建調用,我們需要將其發布到集群狀態并啟動分片。

我們需要做的下一件事是創建一個攝取管道 —— 我們稱之為 openwebtext。 管道名稱必須在上面的索引創建調用中引用,因為我們將其設置為默認管道。 這可確保如果請求中未指定其他管道,則針對索引發送的每個文檔都將自動通過此管道運行。
PUT _ingest/pipeline/openwebtext
{"description": "Elser","processors": [{"inference": {"model_id": ".elser_model_1","target_field": "ml","field_map": {"text": "text_field"},"inference_config": {"text_expansion": {"results_field": "tokens"}}}}]
}我們得到一個 PUT /_ingest/pipeline/{id} transaction。 我們看到集群狀態更新和一些內部調用。 至此,所有準備工作都已完成,我們可以開始使用 openwebtext 數據集運行批量索引。

在開始批量攝入之前,我們需要啟動 ELSER 模型。 轉到 “Maching Learning(機器學習)”、“Trained Models(訓練模型)”,然后單擊 “Play(播放)”。 你可以在此處選擇分配和線程的數量。
模型啟動被捕獲為 POST /_ml/trained_models/{model_id}/deployment/_start。 它包含一些內部調用,可能不如其他事務那么有趣。

現在,我們想通過運行以下命令來驗證一切是否正常。 Kibana 開發工具有一個很酷的小技巧,你可以在文本的開頭和結尾使用三引號(如”””),告訴 Kibana? 將其視為字符串并在必要時轉義。 不再需要手動轉義 JSON 或處理換行符。 只需輸入你的文字即可。 這應該返回一個文本和一個顯示所有令牌的 ml.tokens 字段。?
POST _ingest/pipeline/openwebtext/_simulate
{"docs": [{"_source": {"text": """This is a sample text"""}}]
}此調用也被捕獲為 transaction POST _ingest/pipeline/{id}/_simulate。 有趣的是,我們看到推理調用花費了 338 毫秒。 這是模型創建向量所需的時間。
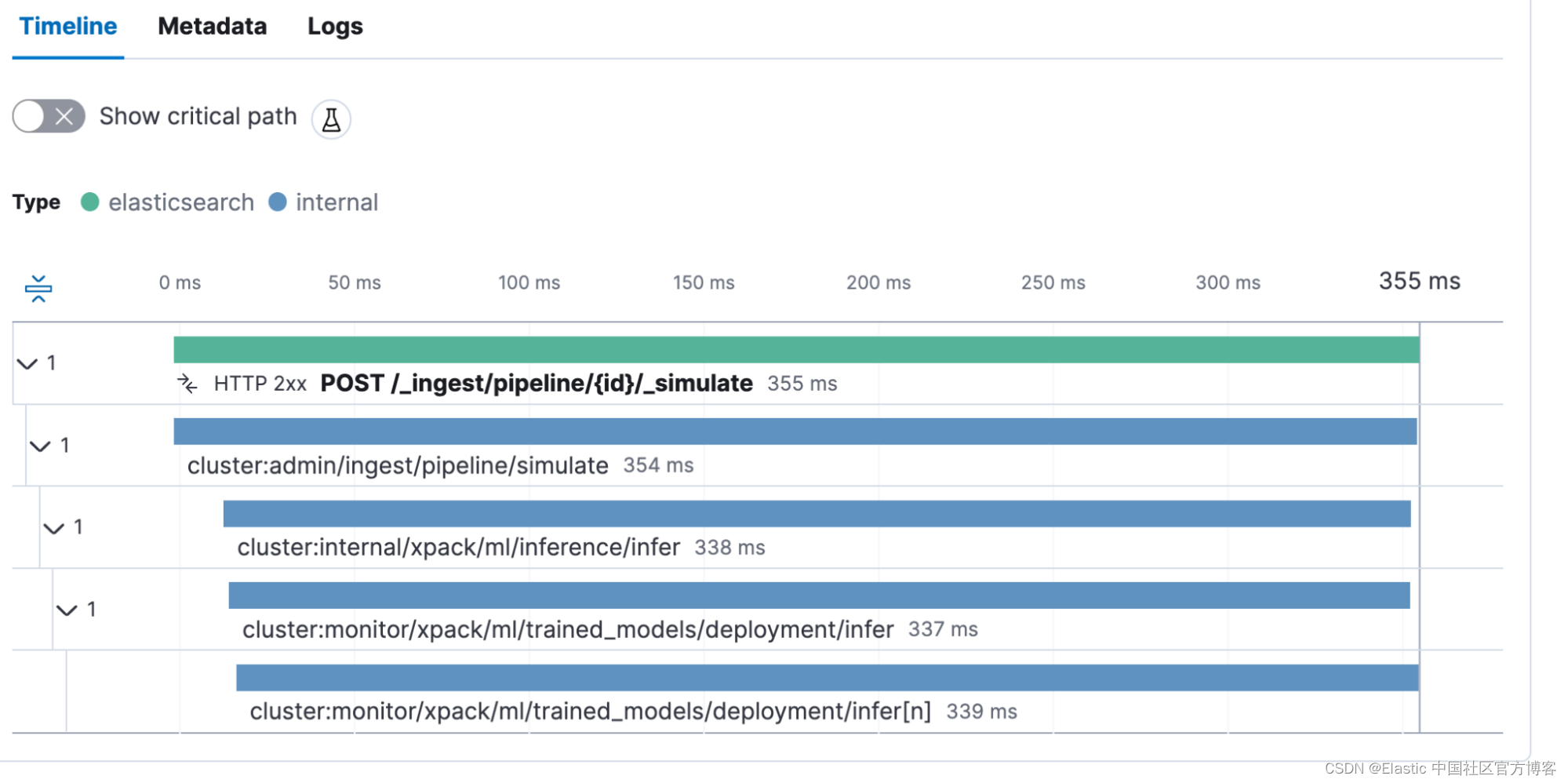
Bulk 攝入
openwebtext 數據集有一個文本文件,代表 Elasticsearch 中的單個文檔。 這個相當 hack 的 Python 代碼讀取所有文件并使用簡單的批量助手將它們發送到 Elasticsearch。 請注意,你不想在生產中使用它,因為它以序列化方式運行,因此速度相對較慢。 我們有并行批量幫助程序,允許你一次運行多個批量請求。
import os
from elasticsearch import Elasticsearch, helpers# Elasticsearch connection settings
ES_HOST = 'https://localhost:9200' # Replace with your Elasticsearch host
ES_INDEX = 'openwebtext-analyzed' # Replace with the desired Elasticsearch index name# Path to the folder containing your text files
TEXT_FILES_FOLDER = 'openwebtext'# Elasticsearch client
es = Elasticsearch(hosts=ES_HOST, basic_auth=('elastic', 'password'))def read_text_files(folder_path):for root, _, files in os.walk(folder_path):for filename in files:if filename.endswith('.txt'):file_path = os.path.join(root, filename)with open(file_path, 'r', encoding='utf-8') as file:content = file.read()yield {'_index': ES_INDEX,'_source': {'text': content,}}def index_to_elasticsearch():try:helpers.bulk(es, read_text_files(TEXT_FILES_FOLDER), chunk_size=25)print("Indexing to Elasticsearch completed successfully.")except Exception as e:print(f"Error occurred while indexing to Elasticsearch: {e}")if __name__ == "__main__":index_to_elasticsearch()我們看到這 25 個文檔需要 11 秒才能被索引。 每次攝取管道調用推理處理器(進而調用機器學習模型)時,我們都會看到該特定處理器需要多長時間。 在本例中,大約需要 500 毫秒 — 25 個文檔,每個文檔約 500 毫秒,總共需約?12.5 秒來完成處理。 一般來說,這是一個有趣的觀點,因為較長的文件可能會花費更多的時間,因為與較短的文件相比,需要分析的內容更多。 總體而言,整個批量請求持續時間還包括返回給 Python 代理的答案以及 “確定” 索引。 現在,我們可以創建一個儀表板并計算平均批量請求持續時間。 我們將在 Lens 中使用一些小技巧來計算每個文檔的平均時間。 我會告訴你如何做。
首先,在事務中捕獲了一個有趣的元數據 - 該字段稱為 labels.http_request_headers_content_length。 該字段可能被映射為關鍵字,因此不允許我們運行求和、求平均值和除法等數學運算。 但由于運行時字段,我們不介意這一點。 我們可以將其轉換為 Double。 在 Kibana 中,轉到包含 traces-apm 數據流的數據視圖,并執行以下操作作為值:
emit(Double.parseDouble($('labels.http_request_headers_content_length','0.0')))如果該字段不存在和/或丟失,則將現有值作為 Double 發出(emit),并將報告為 0.0。 此外,將格式設置為 Bytes。 這將使它自動美化! 它應該看起來像這樣:

創建一個新的儀表板,并從新的可視化開始。 我們想要選擇指標可視化并使用此 KQL 過濾器:data_stream.type: "traces" AND service.name: "elasticsearch" AND transaction.name: "PUT /_bulk"。 在數據視圖中,選擇包含 traces-apm 的那個,與我們在上面添加字段的位置基本相同。 單擊 Prmary metric 和 fomula:?
sum(labels.http_request_headers_content_length_double)/(count()*25)由于我們知道每個批量請求包含 25 個文檔,因此我們只需將記錄數(transaction 數)乘以 25,然后除以字節總和即可確定單個文檔有多大。 但有一些注意事項 - 首先,批量請求會產生開銷。 批量看起來像這樣:
{ "index": { "_index": "openwebtext" }
{ "_source": { "text": "this is a sample" } }對于要索引的每個文檔,你都會獲得 JSON 中的第二行,該行會影響總體大小。 更重要的是,第二個警告是壓縮。 當使用任何壓縮時,我們只能說 “這批文檔的大小為 x”,因為壓縮的工作方式會根據批量內容而有所不同。 當使用高壓縮值時,我們發送 500 個文檔時可能會得到與現在發送 25 個文檔相同的大小。 盡管如此,這是一個有趣的指標。
 ?
?
我們可以使用 transaction.duration.us 提示! 將 Kibana 數據視圖中的格式更改為 Duration 并選擇 microseconds,確保其渲染良好。 很快,我們可以看到,批量請求的平均大小約為 125kb,每個文檔約為 5kb,耗時 9.6 秒,其中 95% 的批量請求在 11.8 秒內完成。

?
查詢時間!
現在,我們已經對許多文檔建立了索引,終于準備好對其進行查詢了。 讓我們執行以下查詢:
GET /openwebtext/_search
{"query":{"text_expansion":{"ml.tokens":{"model_id":".elser_model_1","model_text":"How can I give my cat medication?"}}}
}我正在向 openwebtext 數據集詢問有關給我的貓喂藥的文章。 我的 REST 客戶端告訴我,整個搜索(從開始到解析響應)花費了:94.4 毫秒。 響應中的語句為 91 毫秒,這意味著在 Elasticsearch 上的搜索花費了 91 毫秒(不包括一些內容)。 現在讓我們看看 GET /{index}/_search transaction。
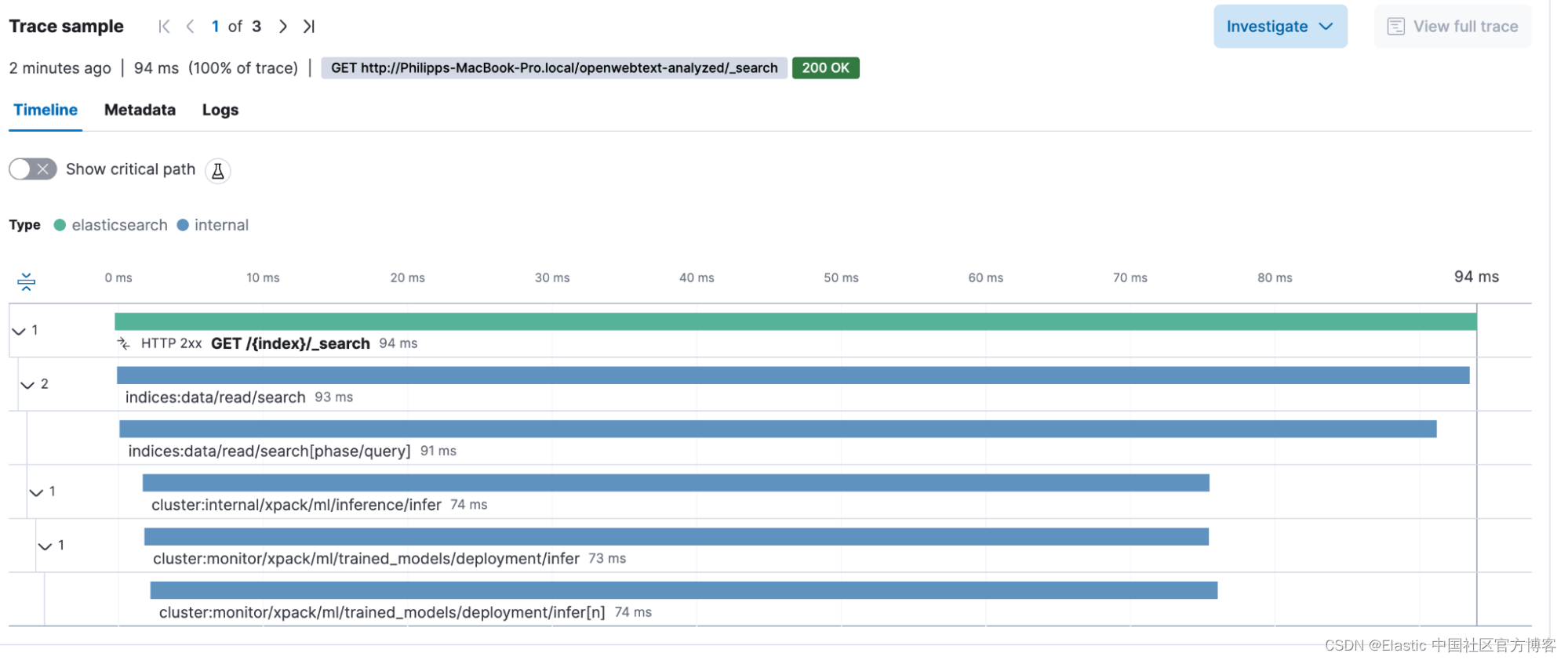
我們可以發現,機器學習(基本上是動態創建令牌)的影響占總請求的 74 毫秒。 是的,這大約占整個交易持續時間的 3/4。 有了這些信息,我們就可以就如何擴展機器學習節點以縮短查詢時間做出明智的決策。
結論
這篇博文向你展示了將 Elasticsearch 作為儀表化應用程序并更輕松地識別瓶頸是多么重要。 此外,你還可以使用事務持續時間作為異常檢測的指標,為你的應用程序進行 A/B 測試,并且再也不用懷疑 Elasticsearch 現在是否感覺更快了。 你有數據支持這一點。 此外,這廣泛地關注了機器學習方面的問題。 查看一般慢日志查詢調查博客文章以獲取更多想法。
儀表板和數據視圖可以從我的 Github 存儲庫導入。
原文:Identify slow queries in generative AI search experiences | Elastic Blog


經典題型)

題解)
 異常處理 命令行參數解析 日志記錄 socket模塊 類的私有方法 字節字符串)
)

{網絡通信設計①})
)
MyEclipse2019創建項目修改pom文件,加載springboot 及swagger-ui jar包)








