🐱作者:一只大喵咪1201
🐱專欄:《網絡》
🔥格言:你只管努力,剩下的交給時間!

上篇文章對TCP可靠性機制講解了一部分,這篇文章接著繼續講解。
🎨滑動窗口
在上篇文章中,本喵講解了TCP的確認應答機制:
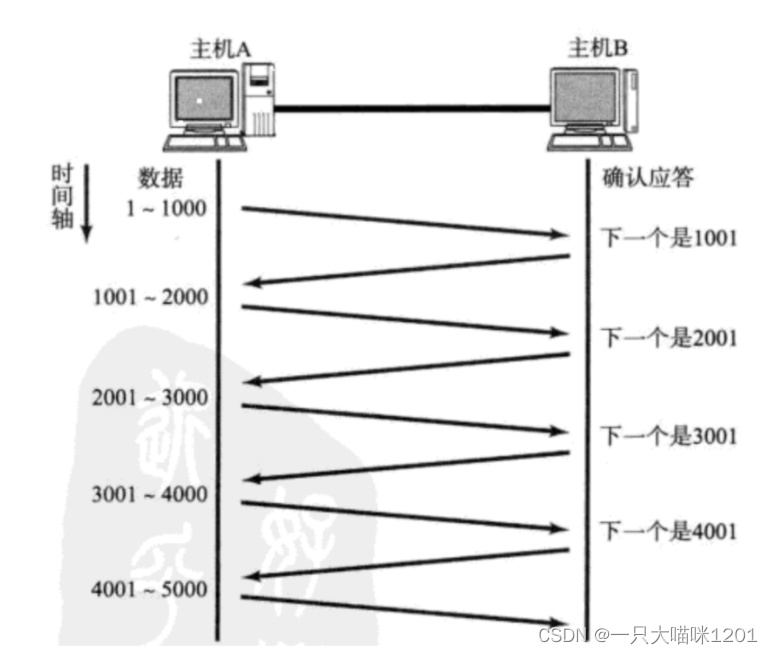
如上圖所示,主機A每發送一個數據段,主機B都要給一個ACK確認應答, 主機A收到ACK后再發送下一個數據段。
這樣做有一個比較大的缺點, 就是性能較差,數據段和數據段之間的發送就變成了串行的了,尤其是數據往返的時間較長的時候,效率更低。
為了提高效率,采用一次發送多條數據的方式:
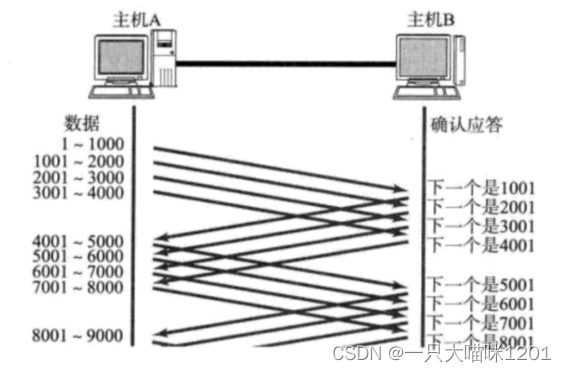
如上圖所示,假設一個數據段的大小是1000字節,主機A一次性發送四個數據段,主機B一次給主機A四個ACK確認應答。
我們知道,TCP協議中有超時重傳機制,如果主機A在一定的時間內沒有收到主機B的確認應答,那么就會觸發超時重傳,再次將剛剛的數據段發送一遍。
- 所以,數據段被發送出去以后,不能立馬清除,需要再保存一段時間,直到收到對端的確認應答,這樣是為了以防超時重傳時再次發送。
那么在收到確認應答之前這些暫存的數據段是存放在哪里的呢?答案是存放在發送緩沖區中。
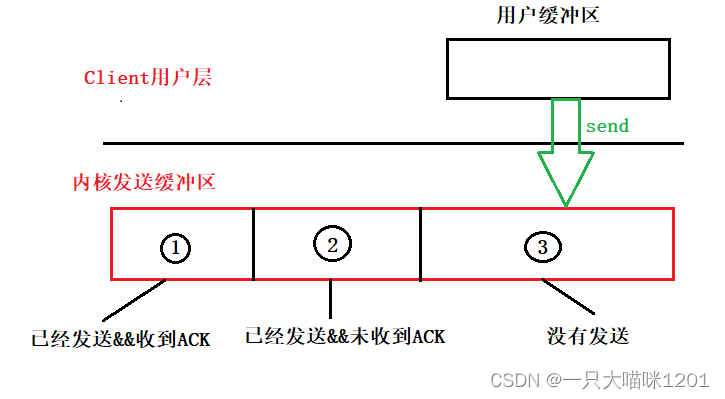
如上圖所示,用戶層將數據send到TCP的發送緩沖區,發送緩沖區會存在大量的數據,需要操作系統在合適的時候發出去,由于TCP是面向字節流的,所以勢必不會一次性將發送緩沖區中的數據都發出去。
此時就會導致發送緩沖區中的數據有三種不同的狀態,同時也將發送緩沖區分成了三部分:
- 已經發送并且收到
ACK的數據。
如上圖序號1所示,這個區域的數據是已經發送了,并且收到了ACK確認應答的數據,說明這些數據對方完全收到了,就沒有存在的必要了,所以新數據來了以后會將其覆蓋。
- 已經發送但是沒有收到
ACK的數據。
如上圖序號2所示,這個區域的數據是已經發送了,但是還沒有收到ACK確認應答,說明這部分數據對方可能沒有收到,也可能對方的ACK確認應答信號自己沒有收到。
當觸發超時重傳后,這部數據會被再次發送,所以這部分數據不能被覆蓋,也不能被清除。
- 發送緩沖區中,存放已經發送但是沒有收到
ACK數據的區域就是滑動窗口。
- 沒有發送的數據。
如上如序號3所示,這個區域的數據還沒有發送,更談不上有沒有ACK確認應答。
🧵理解滑動窗口
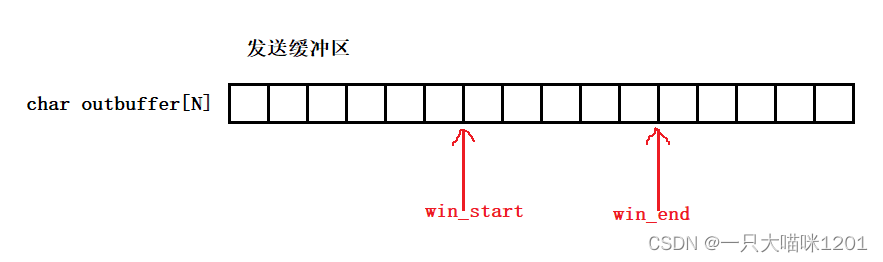
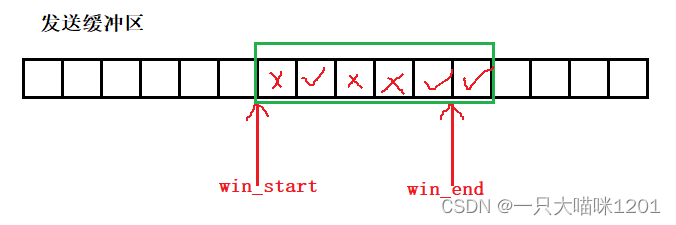
如上圖所示,內核中的發送緩沖區可以看成是一個char outbuffer[N]數組,存在win_start和win_end兩個指針來標識滑動窗口的范圍,窗口滑動的本質就是數組下標的更新。
- 窗口最開始的大小是如何設定的?
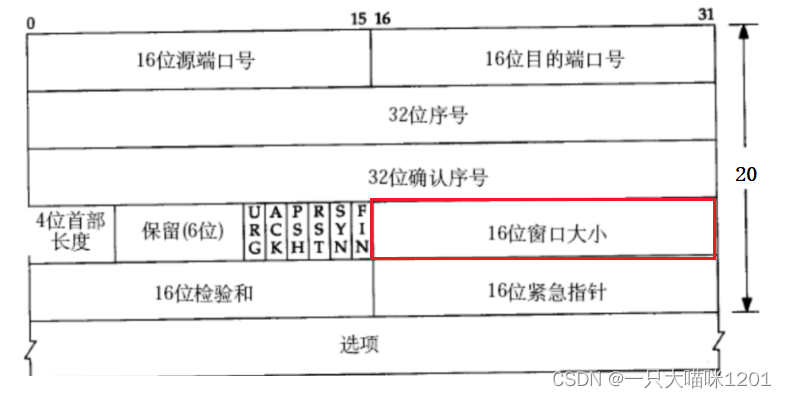
如上圖紅色框中所示,在TCP協議的報頭中有一個16位的窗口大小,該值就是滑動窗口的大小。
在通信雙方進行三次握手建立連接的過程中,接收方將自己的接收能力告訴了發送方(起初是整個接收緩沖區的大小),也就是發送方在發送數據之前就確定了滑動窗口tcp_win的大小。
偽代碼:
win_start = 0;
win_end = win_start = tcp_win;
所以最開始,滑動窗口的大小是從發送緩沖區起始位置開始的tcp_win個字節,也就是對方通告給我的接收能力大小。
- 窗口一定是向右滑動嗎?會不會向左滑動?
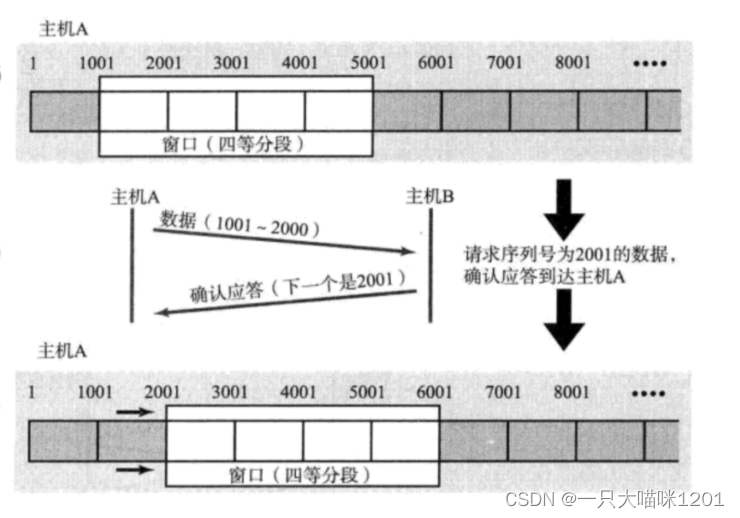
如上圖所示,假設現在滑動窗口的大小是4個數據段,也就是4000個字節,主機A先發送一個數據段(1001~2000),當主機B收到并且返回ACK時,其中確認序號是2001。
- 確認序號表示發送端下次發送從這個序號的位置開始發送即可。
此時原本滑動窗口中的第一個數據段就變成了已經發送并且收到ACK的數據,可以被覆蓋了,所以滑動窗口繼續向右滑動,第一個數據變成了原本的第二個數據段(2001~3000)。
- 由于數據的發送是從左到右的,數據滑動窗口的滑動方向也是從左到右的,不會向左滑動。
- 窗口大小會一直不變嗎?變的依據是什么?
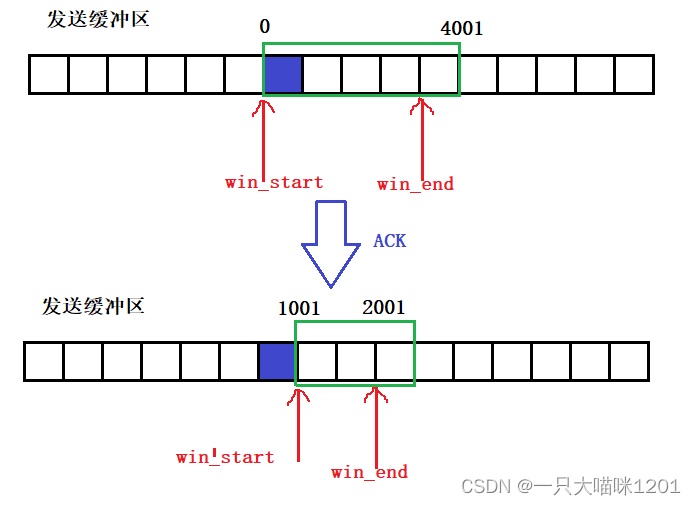
如上圖所示,假設發送緩沖區中一個黑色小框是一個數據段(大小是1000字節),在沒有收到ACK前,滑動窗口的大小是5個數據段。
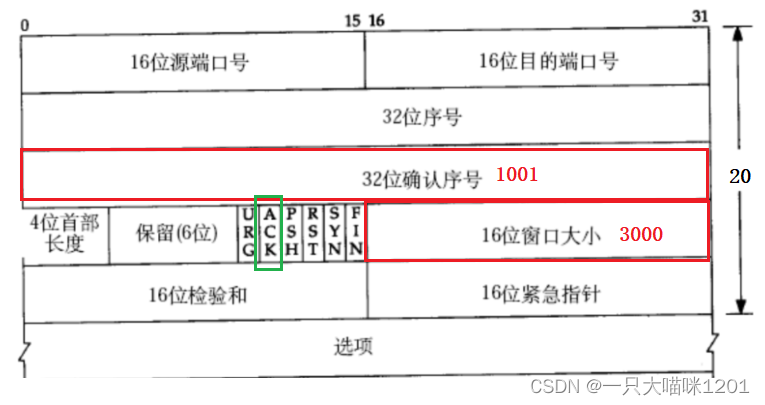
收到ACK確認應答如上圖所示,確認序號是1001,說明0~1000的數據段對方收到了,下次從1001處開始發送,所以滑動窗口的win_start向右滑動一個數據段,指向1001處。
除此之外,由于對方的接收緩沖區應用層沒有讀數據,再加上又有新數據到來,所以接收能力下降了,應答信號中的16位窗口大小表示對方此時的接收能力是3000,所以此時滑動窗口的大小就要發生變化。
win_end = win_start + tcp_win(3000)得到的就是新滑動窗口的結束位置,此時滑動窗口相比原來變小了。
同樣的,也有可能對方在發送這次ACK確認應答的時候,應用層恰好把整個接收緩沖區的數據都讀走了,此時接收能力就變大了,確認應答信號中表示接收能力的16位窗口大小的值也比之前要大。
雖然win_start在向右移動,但是win_end = win_start + tcp_win向右移動的更多,所以此時滑動窗口和原來相比變的更大了。
- 滑動窗口變化大小的依據是對方接收能力的大小。
- 收到的確認應答不是滑動窗口最左邊數據的確認應答,而是中間的,或者結尾的,要滑動嗎?
發送數據的順序是從左到右的,理論上收到確認應答的順序也是從左到右的,收到不是最左邊數據的確認應答的情況,一定是丟包了。
丟包又有兩種情況,一種情況是發送的數據沒有丟,對方也收到了,只是對方的確認應答信號丟了,沒有發送過來,如下圖:
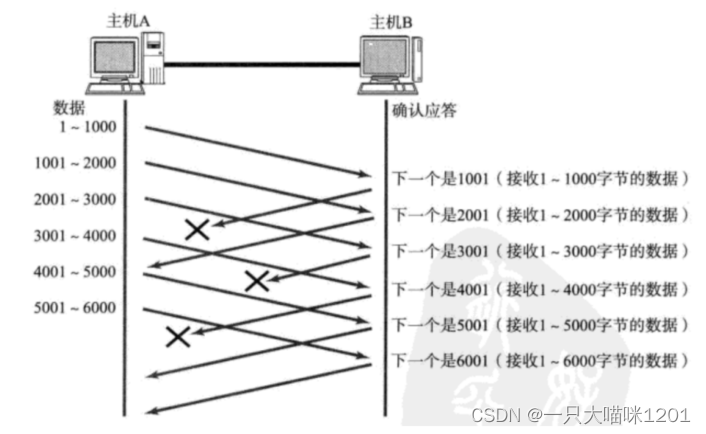
這種情況下,部分ACK丟了并不要緊,因為可以通過后續的ACK進行確認。
- ACK確認序號:該序號前的所有數據全部都收到了,下次從該序號處開始發送。
如上圖所示的情況中,即使確認序號為1001的ACK丟了,但是確認序號為2001的ACK沒有丟。收到2001的ACK后就知道1~1000的數據也收到了,滑動窗口可以直接向右移動兩個數據段。
第二種情況就是發送的數據丟了,對方沒有收到,如下圖:
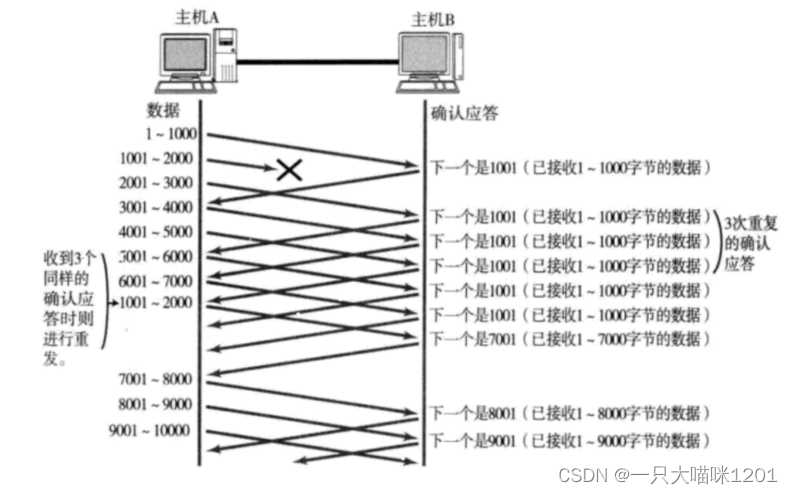
如上圖所示的情況中,1~1000的數據段丟失之后,發送端會一直收到確認序號為1001 的ACK,就像是在提醒發送端 “我想要的是1001” 一樣。
如果主機A連續三次收到了同樣一個確認序號是1001的應答,就會將包含1001的數據段(1001~2000)重新發送。
這個時候收到了1001~2000的數據段之后,返回ACK的確認序號就是7001了。因為2001 - 7000其實之前就已經收到了,并且被放到了接收端操作系統的內核接收緩沖區中。
- 這種重傳機制被稱為高速重發控制。
- 也被叫做快重傳。
- 滑動窗口必須要滑動嗎?會不會不動?大小會不會變為0?
- 滑動窗口是否滑動的依據是
ACK中的確認序號。
當發生丟包等情況時,滑動窗口是不會發生滑動的,因為無法確定對方是否收到了發生的數據,此時就會保持不動,等待下一步策略執行。
當對方的接收緩沖區滿了,并且應用層沒有讀走數據時,此時接收能力就是0,所以ACK確認應答中的16為窗口大小也是0,此時發生方滑動窗口大小就會變成0。
- 一直向右滑動嗎?如果空間不夠了怎么辦?
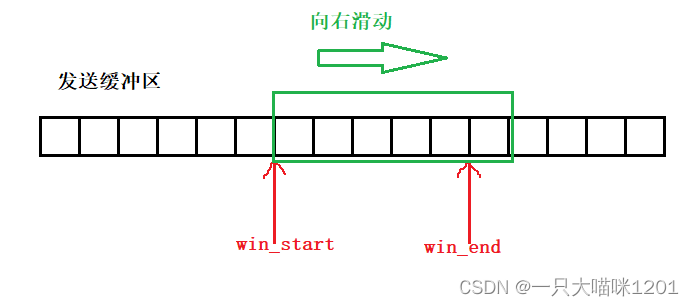
滑動窗口如果一直向右滑動,當發生緩沖區的空間不夠時,滑動窗口會不會越界呢?答案是不會的。
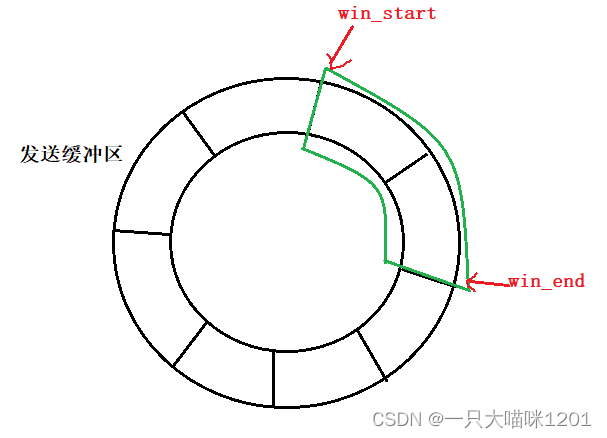
因為發送緩沖區被操作系統組織成了環狀結構,所以滑動窗口無論怎么滑動都不會越界。
🎨流量控制
接收端處理數據的速度是有限的,如果發送端發的太快,導致接收端的緩沖區被打滿,這個時候如果發送端繼續發送,就會造成丟包,繼而引起超時重傳等等一系列連鎖反應。
- TCP支持根據接收端的接收能力來決定發送端的發送速度。這個機制就叫做流量控制(Flow Control)。
和滑動窗口中發送端知道接收端接收能力一樣,接收端將自己可以接收的緩沖區大小放入TCP首部中的16位窗口大小中,再通過ACK端告訴發送端自己的接收能力。
- 窗口大小字段越大,說明網絡的吞吐量越高。
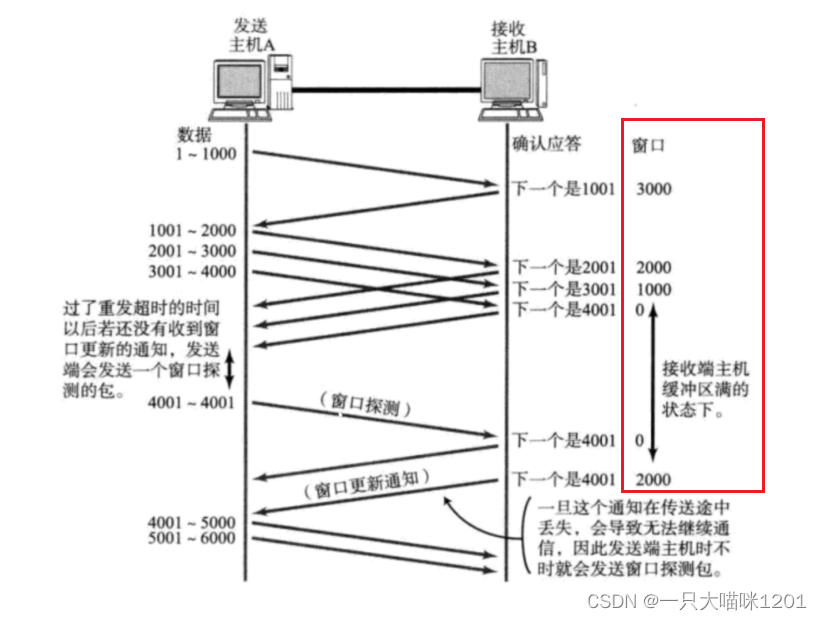
如上圖所示,主機A先發送了一個數據段,得到的ACK中,窗口大小是3000,表示主機B有三個數據段的接收能力,主機A下次發送數據時,調整為一次發送三個數據段。
由于應用層讀取數據緩慢等原因,接收端一旦發現自己的緩沖區快滿了, 就會將窗口大小設置成一個更小的值通知給發送端,發送端接受到這個窗口之后,就會減慢自己的發送速度。
如果接收端緩沖區滿了,就會將窗口置為0,這時發送方不再發送數據,接收方也不再有ACK確認應答了。
- 發送端定期發送一個窗口探測數據段,讓接收端把窗口大小告訴發送端,一但窗口值不再是0了,發送端就可以額繼續發送數據。
- 否則通信就會暫停在這里了。
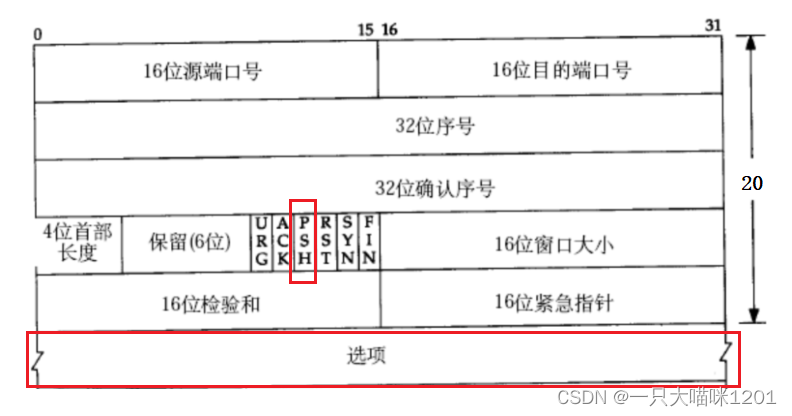
16位變量的最大值65535,那么TCP窗口最大就是65535字節么?
實際上,TCP首部40字節選項中還包含了一個窗口擴大因子M,實際窗口大小是窗口字段的值左移M位。有興趣的小伙伴自行研究首部中的選項。
在TCP首部的6個標志位中有一個PSH標志位,該標志位的作用是催促接收端應用層盡快從接收緩沖區中將數據讀走。
當接收端的接收能力快為0的時候,在發送數據的時候可以將PSH置一,接收方收到后發現PSH為一,就會盡快將接收緩沖區中的數據拿走,好盡快提高接收能力。
🎨擁塞控制
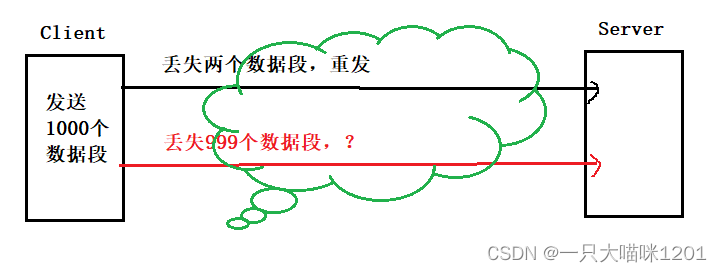
如上圖所示,此時客戶端要發送1000個數據段,服務端接收到以后返回了ACK確認應答,客戶端根據確認序號發現丟了兩個數據段,直接使用快重傳或者超時重傳機制重新發送這兩個數據段即可。
但是如果有999個數據段丟了,服務端只收到一個數據段,那么此時就是網絡出問題了,所以導致大量數據沒有發出去。
- 少量的丟包,僅僅是觸發超時重傳,大量的丟包,就認為網絡擁塞。
- 客戶端對于這999個發送失敗的數據該如何處理呢?
如果也進行重傳,那么就會讓已經出現問題的網絡雪上加霜。并且一個局域網中不止你一個客戶端在發數據,如果都采用這種重傳方式,那么整個網絡中就會存在大量擁塞的數據,使網絡問題更加嚴重。
- 遇到網絡擁塞時,不能使用超時重傳機制,而應該使用擁塞控制的策略。
先不管擁塞控制是什么,從TCP有這一機制就可以看出,TCP的可靠性不僅僅考慮了雙方主機的問題,還考慮了路上網絡的問題!。
- TCP引入慢啟動機制來實現擁塞控制:
- 當發送網絡擁塞后,先發少量的數據探探路,摸清當前的網絡擁堵狀態,再決定按照多大的速度傳輸數據。
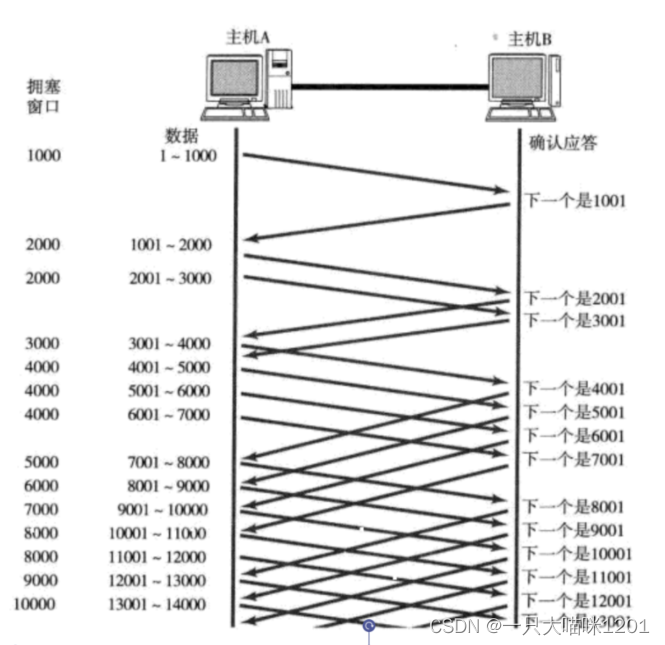
如上圖所示,當網絡發生擁塞時,主機A先發送一個數據段探探路,如果收到這個數據段的ACK,再將發送數據段個數增加。
- 此處引入一個擁塞窗口的概念。
- 表示會產生網絡擁塞的數據量。
在網絡擁塞后,第一次發送數據時,將擁塞窗口的大小設置為1,即一個數據段(1000)的大小,每次收到一個ACK應答,擁塞窗口加1。
再次發送時按照擁塞窗口的大小來發,這一就會導致發送數據段的個數按照指數級來增長,每次都是前一次的二倍。
之所以稱這種方式是慢啟動,是因為最開始只發送一個數據段,開始數據量的增長確實慢,但是這是指數級增長,后面數據量的增長就會越來越快。
- 慢啟動的方式,可以讓發送方發送的數據量快速恢復到正常水平。
- 這種快速恢復提高了網絡通信的效率。
但是不能讓這種增長速度不斷增加下去,否則就導致非常恐怖的數據量,所以不能使擁塞窗口單純的加倍。
- 再引入一個概念:慢啟動的閾值。
當以指數增長的擁塞窗口大小大于這個閾值的時候,擁塞窗口不再按照指數級增長,而是按照線性方式增長。
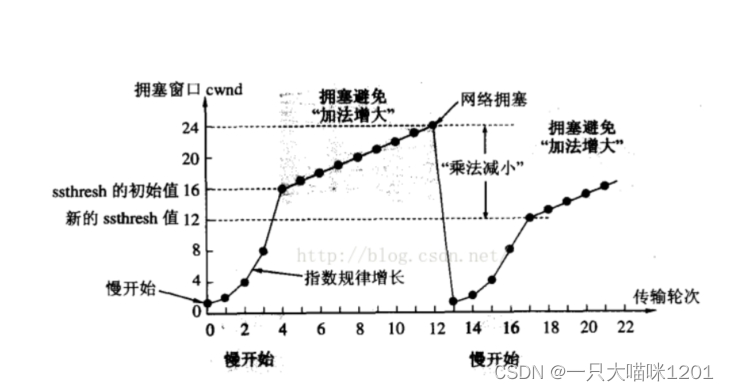
如上圖所示便是擁塞窗口隨傳輸輪次變化的示意圖。
網絡擁塞控制機制觸發,勢必是因為已經發生了網絡擁塞,當上一次網絡擁塞發生時,閾值大小為16,當發送方以慢啟動方式開始發送數據后,擁塞窗口按照指數級增長到16后變成了線性增長。
擁塞窗口線性增長到24以后,再次發生了網絡擁塞,因為在這個過程中,發送的數據量也在不斷增加。此時將閾值更新為24的一半12。
然后發送方再以慢啟動的方式發送數據,擁塞窗口變成12以后再線性增長,直到發送網絡擁塞,再次更新閾值。
如此反復,不斷更新閾值和擁塞窗口的最大值,以便試探出當前網絡狀況下效率最高的數據傳輸量(閾值和擁塞窗口最大值不再變化)。
如果說在擁塞控制的過程中,網絡狀況恢復了,那么擁塞窗口就會一直增長下去,發送數據量也在增長,直到當前良好網絡狀況極限嗎?
接收方也是有接收能力限制的,就算網絡情況再好,發送方也不以超出接收方接收能力數據量來通信。
- 發送方在每次發送數據的時候,會將擁塞窗口的大小和接收端反饋接受能力大小作比較,取較小值作為實際發送的數據量。
- 滑動窗口大小 = min(擁塞窗口大小,對方接收能力大小)。
所以在網絡狀況良好的情況下,發送方的滑動窗口大小取決于接收方的接收能力,在網絡擁塞的情況下,發送方的滑動窗口大小取決于擁塞窗口的大小。
當TCP開始啟動的時候,慢啟動的閾值等于滑動窗口的最大值,如果網絡狀況良好,那么擁塞窗口在增加到大于接收方的接收能力后變不再增加。
如果發送了網絡擁塞后,慢啟動閾值就會變成原來的一半,同時擁塞窗口置回1(最小值),逐漸找到最合適的擁塞窗口值和閾值。
- 當TCP通信開始后,網絡吞吐量會逐漸上升。
- 隨著網絡發生擁堵,吞吐量會立刻下降。
🎨延遲應答
假設接收端緩沖區大小為1MB,一次收到了500KB的數據,如果立刻應答,返回的窗口大小就是500KB。
但實際上可能接收端處理接收緩沖區中數據的速度很快, 10ms之內就把500KB數據從緩沖區消費掉了,并且接收端處理速度還遠沒有達到自己的極限,即使窗口再放大一些,也能處理過來。
如果接收端稍微等一會再應答,比如等待200ms再應答,那么這個時候返回的窗口大小就是1MB了。
- 窗口越大,網絡吞吐量就越大,傳輸效率就越高。
- 我們的目標是在保證網絡不擁塞的情況下盡量提高傳輸效率。
所有的數據報都采用延遲應答的方案嗎?肯定不是。
常用的方案有兩種:
- 數量限制:每隔N個包就應答一次。
- 時間限制:超過最大延遲時間就應答一次。
具體的數量和超時時間,依操作系統不同也有差異。一般N取2,超時時間取200ms。
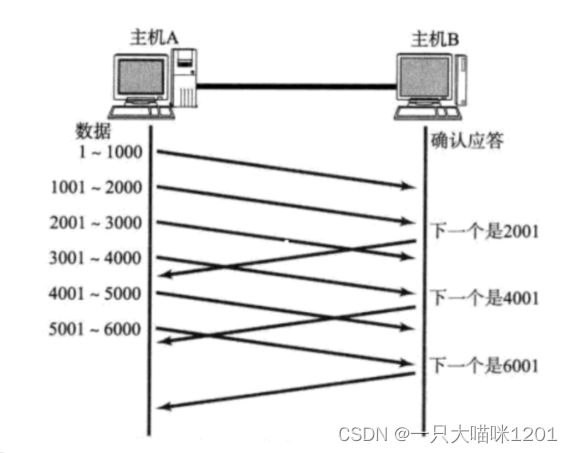
如上圖所示,延遲應答的最終表現,就是隔幾個數據段確認應答一次。
🎨捎帶應答
本喵再講解協議格式的時候,說協議首部中有兩個序號是為了實現全雙工,也就是讓應答和數據在一個數據段內。
即使有延遲應答,但是很多情況下,通信雙方 “一發一收” 的,雖然是收到多個數據段應答一次,但是應答終究還是只有應答,也就是只有確認序號和ACK標志位,沒有數據。
為了通信效率更高,完全可以將確認應答和接收端要發送的數據放在一個數據段中發送出去,發送端收到后既可以知道接收端收到了自己數據,又收到了接收端發送的數據。
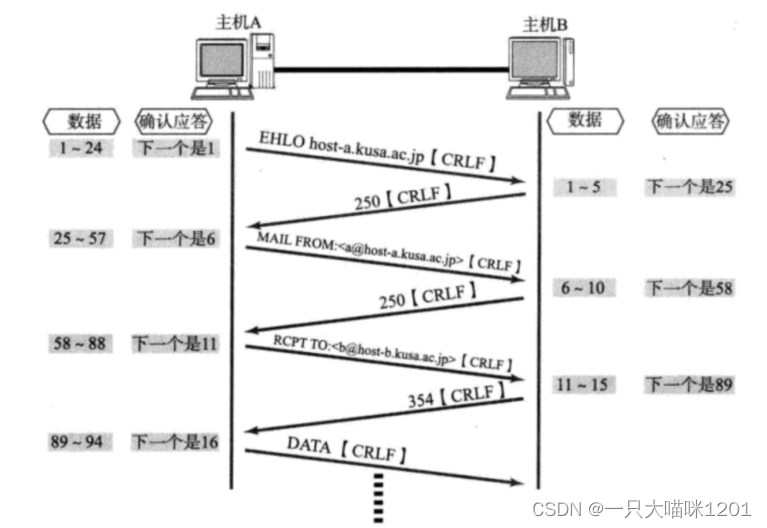
如上圖所示,確認應答信號中的確認序號和ACK標志位,坐著數據的順風車就發送出去了,也就是在通信的過程中,確認應答就被捎帶給對方了。
🎨面向字節流
在學C語言文件操作的時候,就聽到過面向字節流,在學C++的時候同樣也聽到過面向字節流,在UDP和TCP的學習中,更是多次見到面向字節流,那么面向字節流到底是什么?
創建一個TCP的socket時,操作系統會同時在內核中創建一個發送緩沖區 和一個接收緩沖區。
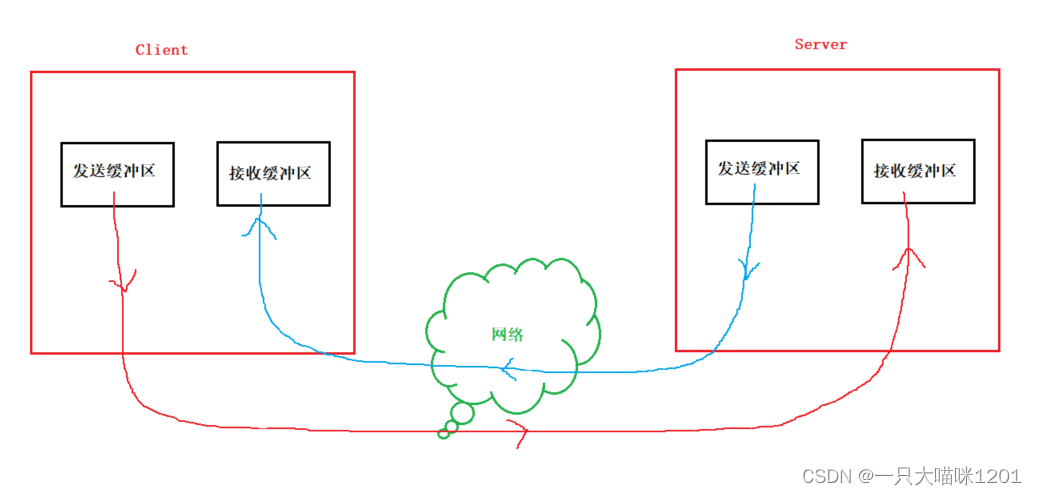
應用層在調用write或者send時,數據會先寫入發送緩沖區中,如果發送的字節數太長,會被拆分成多個TCP的數據包發出。
如果發送的字節數太短,就會先在緩沖區里等待,等到緩沖區長度差不多了,或者其他合適的時機發送出去。
接收數據的時候,數據也是從網卡驅動程序到達內核的接收緩沖區,然后應用層可以調用read或者recv從接收緩沖區拿數據。
- 由于緩沖區的存在,TCP程序的讀和寫不需要一一匹配,如:
- 寫100個字節數據時,可以調用一次write寫100個字節,也可以調用100次write,每次寫一個字節。
- 讀100個字節數據時,也完全不需要考慮寫的時候是怎么寫的,既可以一次read100個字節,也可以一次read一個字節,重復100次。
簡而言之就是,應用層和TCP層是完全獨立的,應用層寫的時候不用考慮TCP層的緩沖區是否滿,應用層讀的時候,也不需要考慮緩沖區中的數據是怎么樣的,直接讀就可以。
- 至于應用層寫入或者讀取的是否是一個完整的報文,TCP層的緩沖區無法保證,需要由用戶層自己處理。
與面向字節流相對的就是面向用戶數據報的UDP,UDP協議用戶層寫入就是一個完整的報文然后給到UDP層,UDP層并不會緩存,而且增加相應的首部后直接發送出去,發送的上一個完整的數據段。
接收方應用層讀取的時候,從接收緩存區中讀取到的內容也是一個完整的數據段,不能分多次讀。
粘包問題:
- 首先要明確,粘包問題中的 “包”,是指的應用層的數據包。
在TCP的協議頭中,沒有如同UDP一樣的 “報文長度” 這樣的字段,但是有一個32位序號的字段。站在傳輸層的角度,TCP是一個一個數據段過來的,按照序號排好序放在緩沖區中。
站在應用層的角度,看到的只是一串連續的字節數據,那么應用程序看到了這么一連串的字節數據,就不知道從哪個部分開始到哪個部分,是一個完整的應用層數據包,此時應用層在讀取數據的時候就會產生粘包問題,可能讀取的不是一個完整報文,也可能是一個半報文等等情況。
解決這個問題,歸根到底就是要明確兩個包之間的邊界。
在之前的文章協議定制中,采用的是TCP協議,本喵在應用層讀取接收緩沖區數據的時候,通過用戶層代碼來保證每次讀取到的是一個完整報文。
- 每個報文都有一個報頭,報頭中的內容就是有效載荷的長度,這是由本喵定義的用戶層協議。
對于UDP協議來說,就不存在粘包問題:
- 如果還沒有上層交付數據,UDP的報文長度仍然在(在首部中)。同時,UDP是一個一個把數據報交付給應用層就有很明確的數據邊界。
- 站在應用層的站在應用層的角度,使用UDP的時候,要么收到完整的UDP報文,要么不收,不會出現"半個"的情況。
🎨TCP小結
TCP異常情況:
- 進程終止:進程終止會釋放文件描述符,仍然可以發送
FIN,和正常關閉沒有什么區別。
一個進程終止后,操作系統會釋放這個進程的所有資源,包括文件描述符表,會自動調用close關閉對應的文件,當TCP套接字被關閉時,同樣會發起四次揮手請求,和正常關閉沒有區別。
- 機器重啟:和進程終止的情況相同。
我們平時在關機的時候,會提示有什么什么進程沒有結束,要我們強制結束,這個時候也是在終止進程,也會發起四次揮手請求。
- 機器掉電/網線斷開:此時就是一種真正異常情況。
發送端來不及發起四次揮手請求,接收端認為連接還在,一旦接收端有寫入操作,接收端發現連接已經不在了, 就會進行RST。
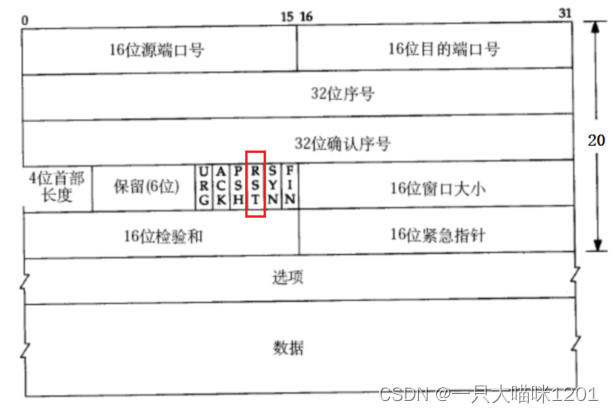
如上圖所示,首部的六個標志位中有一個RST標志位,該標志位是用來請求重連的。當發送端在觸發超時重發機制后,仍然無法將數據發送到對方,就會發送一個帶有RST的數據段請求,請求和對方重新發起三次握手建立連接。
即使沒有寫入操作,TCP自己也內置了一個保活定時器,會定期詢問對方是否還在,如果對方不在,也會把連接釋放。
另外,應用層的某些協議,也有一些這樣的檢測機制。例如HTTP長連接中,也會定期檢測對方的狀態,例如QQ,在QQ斷線之后,也會定期嘗試重新連接。
緊急指針:
我們知道,TCP協議中緩沖區的數據是按照順序發送的,接收緩沖區也是按照順序來接收的,但是如果我們想讓某個數據插隊呢?讓這個數據提前被接收端處理,而不是按照順序來,此時就用到了緊急指針。
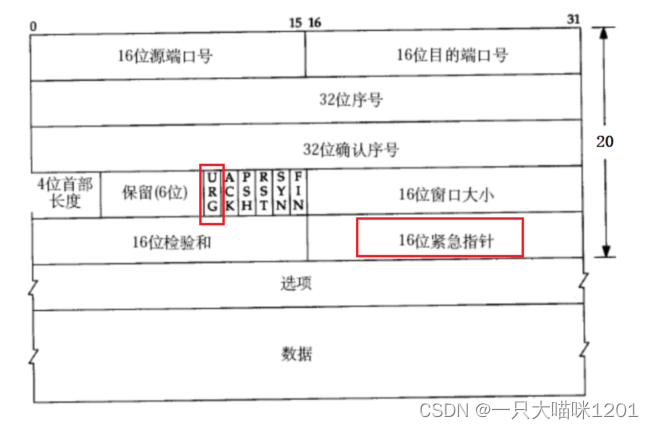
如上圖所示,六個標志位中的URG表示緊急指針是否有效,16位緊急指針指向數據段中具體的某個數。
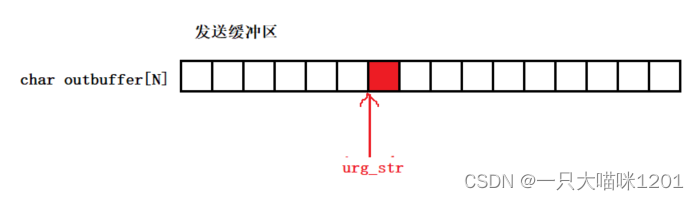
我們知道緩沖區本質上就是一個char類型的數組,如上圖所示,而緊急指針是一個16位的變量,所以它也是一個值,范圍是0~65535,這個值其實就是緩沖區中有效載荷的偏移量。
- 一個緊急指針只能指向緩存區中一個數據。
當發送端想讓某個數據插隊時,就將URG標志位置一,然后讓16位緊急指針指向這個緊急數據,再將數據段發送出去。
當接收端收到數據段后,發現URG置一了,說明有緊急指針,有數據需要優先處理,然后再去16位緊急指針字段中拿到緊急數據的位置,然后先讀取這個緊急數據。
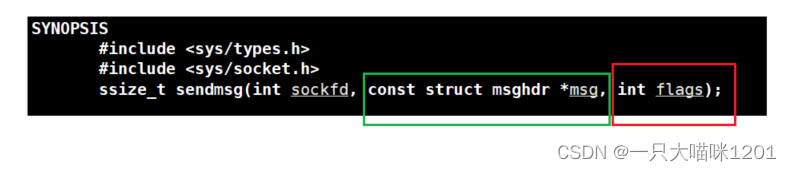
在之前我們使用send以及recv的時候,最后一個參數是flags,之前我們都是設為0的,如果將其設置為MSG_OOB就表示發送或者接收的數據中存在緊急指針,也就是將URG標志位置一了。
在發送或者接收的時候,需要調用第二個參數是msg結構體指針的系統調用,這個結構體中包含緊急指針的位置,也就是16為緊急指針位段。
緊急指針的應用場景非常少,一般應用在緊急獲取對端狀態的場景,比如說客戶端給服務端發送了很多條TCP請求,服務端都沒有給回應答,客戶端就可以發一個緊急數據確認服務端的狀態。
TCP機制總結:
TCP非常的復雜,有眾多的機制來保證它的可靠性和提高性能。
保證可靠性機制:校驗和,序列號,確認應答,超時重傳,連接管理,流量控制,擁塞控制。
提高性能的機制:滑動窗口,快速重傳,延遲應答,捎帶應答。
其他機制:超時重傳定時器,保活定時器,TIME_WAIT定時器。
常見的基于TCP的應用協議:HTTP,HTTPS,SSH,Telient,FTP,SMTP,以及前面本喵自己定制的應用層協議。
🎨理解listen的第二個參數
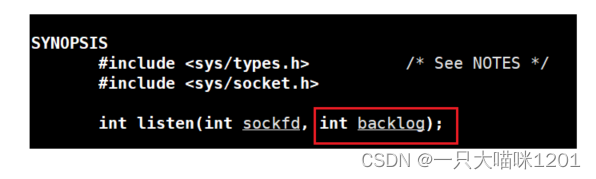
前面本喵在創建TCP套接字的時候,沒有講解listen系統調用的第二個參數backlog,只是說隨便設置一個數,不要太大。
int backlog表示全連接長度。
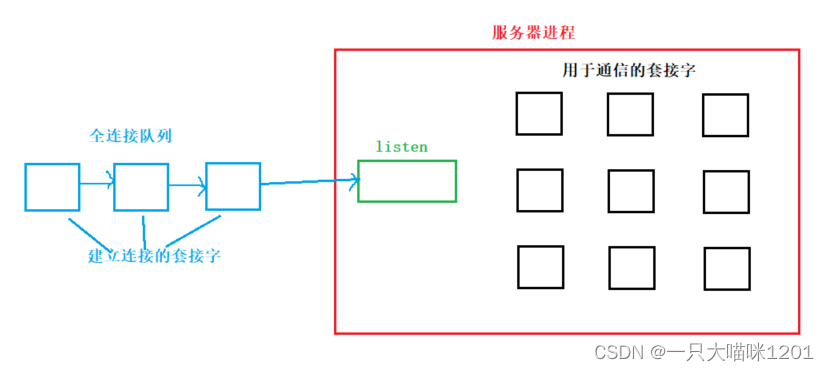
如上圖所示,服務器進程中有一個listen狀態的套接字用來監聽,還有多個recv后的套接字來進行真正的通信。
系統資源是有限的,當用于通信的套接字數量達到限制以后,系統就無法再維護更多套接字了,新來的已經建立連接的套接字就會由于資源不足而被關閉。
當服務中某個或者幾個用于通信的套接字使用完畢后,就會釋放出一部分系統資源,此時也沒有新的連接到來,那么這部分系統資源就會空閑著。
所以TCP協議維護了一個全連接隊列,如上圖藍色部分所示,這個隊列中放的是處于等待狀態的并且已經完成三次握手建立連接的套接字。
當系統資源不足時,就在全連接隊列中等待,當系統資源有空余時,全連接隊列中的一個套接字就會被系統維護,進行網絡通信。
- 此時系統資源一空閑出來就會立刻被全連接隊列中的套接字使用,不會再出現空閑狀態,充分利用了系統資源,提高了效率。
- 而
listen的第二個參數backlog就是用來指定全連接隊列的長度,具體長度等于backlog +1。
為什么說backlog值不能太大又不能沒有呢?
不能沒有的原因就是本喵上面所說的,要讓系統資源一有空余就有新的套接字被系統維護,提高系統資源利用率。
不能太大是因為,維護全連接隊列也要消耗系統資源,如果全連接隊列太長,所耗費的資源完全夠系統再維護一個套接字用來通信了,屬于是撿了芝麻丟了西瓜的做法。
除此之外,全連接隊列太長,里面的套接字等待的時間也會很長,此時又會觸發超時重傳機制等,進而導致其他問題。

將之前寫的TCP網絡通信代碼的backlog值設置為1,也就是將listen的第二個參數設置為1,此時全連接的長度為2。
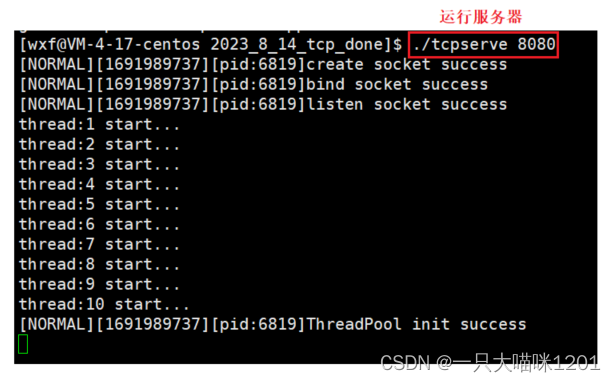
將服務器運行起來,此時服務器不會accept新的連接,所以當新的連接到來時,被會放入全連接隊列中等待,而設置的全連接隊列長度是2,所以最多放兩個建立連接的套接字。
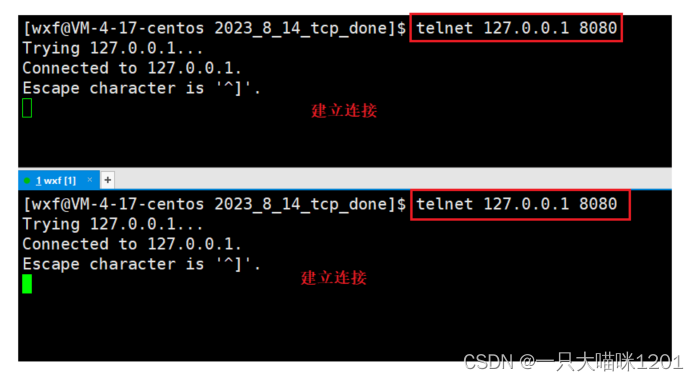
再創建兩個Xshell窗口,充當兩個服務端,使用telnet工具充當兩個客戶端與服務器進行連接。

使用netstat查看當前主機上和8080端口有關的網絡進程,如上圖所示。
上面兩行中表示兩個客戶端telnet,它們的端口號分別是48406和48410,對端都是服務器,端口號是8080。
下面兩行中表示服務器和兩個客戶端telnet,第一行和第三行組成一對通信,通信的端口號是48406 <-> 8080,第二行和第四行組成一對通信,通信的端口號是48410 <-> 8080。
此時全連接隊列中放的就是端口號為48406和48410的兩個客戶端telnet進程。
- 全連接隊列中的套接字狀態是
ESTABLISHED,說明是完成了三次握手的,已經和服務器建立了連接,只是服務器沒有進行維護進行通信。
此時再增加一個客戶端,如上圖所示,此時一共有3個telnet和服務器建立連接。
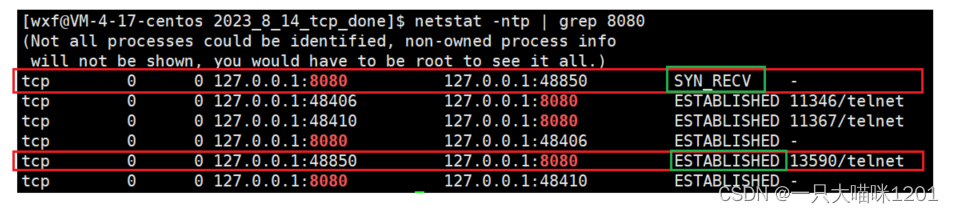
再次查看網絡狀態,發現多了兩個套接字,上面紅色框那行表示服務器,下面紅色框表示客戶端。
- 服務器端套接字的狀態是
SYN_RECV。 - 客戶端
telnet套接字的狀態是ESTABLISHED。
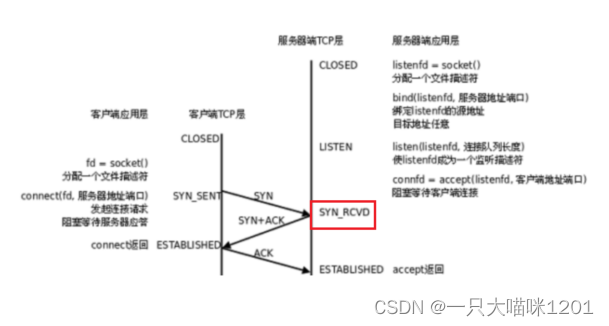
如上圖所示,再三次握手的過程中,服務端第一次收到客戶端的SYN請求以后,服務端套接字的狀態就變成了SYN_RECV,只有服務端也發送SYN+ACK以后,再收到客戶端的ACK以后,服務端才會變成ESTABLISHED,表示連接建立。
而上面過程中,第三個客戶端發起連接請求后,服務端套接字停在了SYN_RECV狀態,說明服務端已經收到了客戶端的三次握手請求,但是此時全連接隊列已經滿了,服務端沒有更多資源來維護這個套接字了,所以不祥客戶端發起SYN連接請求。
- 處于
SYN_RECV狀態的套接字叫做半連接狀態。
對于半連接狀態的套接字,操作系統同樣維護著一個半連接隊列,里面放著的是處于SYN_SNET和SYN_RECV等半連接狀態的套接字。
但是可以看到,客戶端telnet的狀態是ESTABLISHED,也就是說客戶端是認為建立了連接的,但是服務端沒有建立,所以這次通信的建立是失敗的。
當客戶端發送數據的時候,發現服務端沒有對應的套接字,就會發起RST,請求重新建立連接。
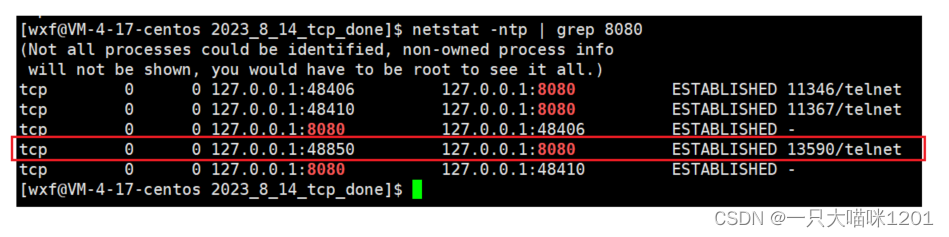
等待一段時間后再次查看網絡狀態,發現服務器端處于SYN_RECV狀態的半連接套接字沒有了,而客戶端的ESTABLISHED狀態的套接字仍然存在。
- 處于半連接狀態的套接字,在一定時間內沒有建立連接變成
ESTABLISHED狀態,操作系統就會將這個套接字釋放掉。
-
半鏈接隊列:用來保存處于
SYN_SENT和SYN_RECV狀態的套接字。 -
全連接隊列:用來保存處于
ESTABLISHED狀態的套接字,但是應用層沒有調用accept獲取。 -
全連接隊列滿了的時候,就無法繼續讓當前連接的狀態進入
ESTABLISH狀態了。
🎨總結
TCP協議到此就結束了,可以看到它比起UDP來復雜很多,因為TCP比UDP更加可靠,可靠性的維護是需要付出代價的,增加了序列化,確認應答機制,三次握手四次揮手機制等等很多機制。
MyEclipse2019創建項目修改pom文件,加載springboot 及swagger-ui jar包)









)








![[保研/考研機試] KY96 Fibonacci 上海交通大學復試上機題 C++實現](http://pic.xiahunao.cn/[保研/考研機試] KY96 Fibonacci 上海交通大學復試上機題 C++實現)