jsoup解析html之table表格
jsoup說明
一款Java 的HTML解析器
jsoup 是一款Java 的HTML解析器,可直接解析某個URL地址、HTML文本內容。它提供了一套非常省力的API,可通過DOM,CSS以及類似于jQuery的操作方法來取出和操作數據。
主要功能
- 從一個URL,文件或字符串中解析HTML;
- 使用DOM或CSS選擇器來查找、取出數據;
- 可操作HTML元素、屬性、文本;
需求說明
現在需要從上游過來一批數據,我們解析之后做一些邏輯處理,批量錄入數據庫;這些數據就是excel,一條一條的,只不過它不是標準的xls或者xlsx形式,而是處理過的html格式加工成xls格式,如果我們使用easypoi或者easyexcel解析會出現錯誤提示java.io.IOException: Your InputStream was neither an OLE2 stream, nor an OOXML stream,簡而言之就是,這兩個解析框架不識別,不是標準的xls或者xlsx,解決方法就是從上游導出的數據,先保存為標準的xls后者xlsx形式不會出現問題,但是,但是,現在需要從程序上進行控制。
代碼操作
核心api
Jsoup
The core public access point to the jsoup functionality.
Parse HTML into a Document. The parser will make a sensible, balanced document tree out of any HTML.
Document :文檔對象。每份HTML頁面都是一個文檔對象,Document 是 jsoup 體系中最頂層的結構。
Element:元素對象。一個 Document 中可以著包含著多個 Element 對象,可以使用 Element 對象來遍歷節點提取數據或者直接操作HTML。
Elements:元素對象集合,類似于List。
核心方法
eachText()
/*** Get the text content of each of the matched elements. If an element has no text, then it is not included in the* result.* @return A list of each matched element's text content.* @see Element#text()* @see Element#hasText()* @see #text()*/public List<String> eachText() {ArrayList<String> texts = new ArrayList<>(size());for (Element el: this) {if (el.hasText())texts.add(el.text());}return texts;}
select()
/*** Find matching elements within this element list.* @param query A {@link Selector} query* @return the filtered list of elements, or an empty list if none match.*/public Elements select(String query) {return Selector.select(query, this);}
1.select()方法在Document、Element或Elements對象中都可以使用,而且是上下文相關的,因此可實現指定元素的過濾,或者采用鏈式訪問。
2.select() 方法將返回一個Elements集合,并提供一組方法來抽取和處理結果。
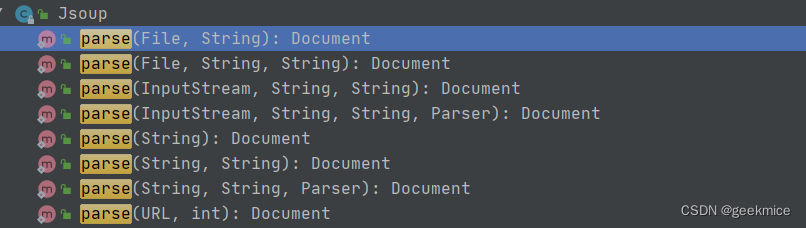
// 從文件流中獲取html解析public static Document parse(InputStream in, String charsetName, String baseUri) throws IOException {return DataUtil.load(in, charsetName, baseUri);}// 從文件中獲取html解析public static Document parse(File in, String charsetName) throws IOException {return DataUtil.load(in, charsetName, in.getAbsolutePath());}public static Document parse(File in, String charsetName, String baseUri) throws IOException {return DataUtil.load(in, charsetName, baseUri);}public static Document parse(InputStream in, String charsetName, String baseUri, Parser parser) throws IOException {return DataUtil.load(in, charsetName, baseUri, parser);}package com.geekmice.springbootselfexercise.utils;import java.io.IOException;
import java.io.InputStream;
import java.nio.charset.StandardCharsets;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Objects;import com.geekmice.springbootselfexercise.exception.UserDefinedException;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections4.CollectionUtils;
import org.apache.poi.ss.formula.functions.T;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;/*** @BelongsProject: spring-boot-self-exercise* @BelongsPackage: com.geekmice.springbootselfexercise.utils* @Author: pingmingbo* @CreateTime: 2023-08-13 17:16* @Description: 解析html* @Version: 1.0*/
@Slf4j
public class ParseHtmlUtil {public static final String ERROR_MSG = "error mg:【{}】";/*** @param inputStream 文件流* @return 解析好的數據list* @throws IOException* @description 根據文件流解析html格式的excel* 問題說明:去除第一行標題,空行,空格,空指針問題*/public static List<String> parseHandle(InputStream inputStream) {Document document;try {document = Jsoup.parse(inputStream, StandardCharsets.UTF_8.toString(), "");} catch (IOException e) {log.error(ERROR_MSG, e);throw new UserDefinedException(e.toString());}Elements trList = document.select("table").select("tr");List<String> abcList = trList.eachText();if (CollectionUtils.isEmpty(abcList)) {throw new UserDefinedException("解析文件:文件內容不存在");}abcList.remove(0);return abcList;}}
效果展示
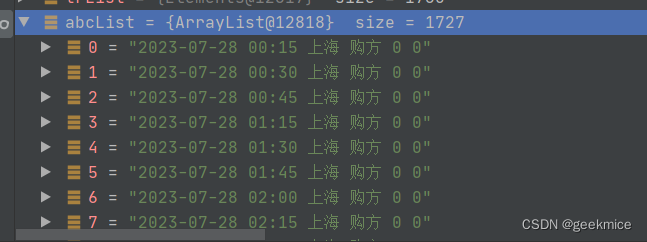
{"msg": "操作成功","code": 200,"data": ["2023-07-28 00:15 上海 購方 0 0","2023-07-28 00:30 上海 購方 0 0",...."2023-07-28 23:00 四川主網 售方 333.25 225.94","2023-07-28 23:15 四川主網 售方 463.25 224.16","2023-07-28 23:30 四川主網 售方 463.25 224.16","2023-07-28 23:45 四川主網 售方 463.25 224.16","2023-07-28 24:00 四川主網 售方 587.79 213.53"]
}






)











函數與lambda表達式)
![[PaddlePaddle] [學習筆記] [上] 計算機視覺(卷積、卷積核、卷積計算、padding計算、BN、縮放、平移、Dropout)](http://pic.xiahunao.cn/[PaddlePaddle] [學習筆記] [上] 計算機視覺(卷積、卷積核、卷積計算、padding計算、BN、縮放、平移、Dropout))