👨?🎓作者簡介:一位即將上大四,正專攻機器學習的保研er
🌌上期文章:機器學習&&深度學習——seq2seq實現機器翻譯(數據集處理)
📚訂閱專欄:機器學習&&深度學習
希望文章對你們有所幫助
之前已經講解過了seq2seq,且已經將機器翻譯的數據集導入和預處理好了,接下來就要利用該數據集進行訓練。
seq2seq實現機器翻譯(詳細實現與原理推導)
- 引入
- 編碼器
- 解碼器
- 損失函數
- 訓練
- 預測
- 預測序列的評估
- 小結
引入
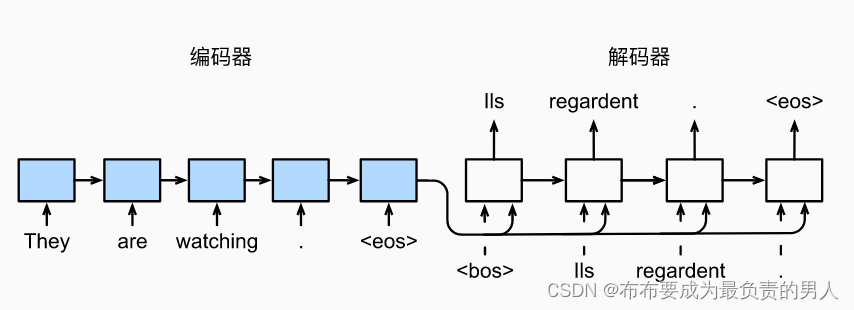
我們的任務就是構建上面的設計,并將之前的數據集用來訓練這個模型。
import collections
import math
import torch
from torch import nn
from d2l import torch as d2l
編碼器
技術上說,編碼器就是將長度可變的輸入序列轉換成形狀固定的上下文變量c,并將輸入序列的信息在該上下文變量中進行編碼。
考慮由一個序列組成的樣本(批量大小為1)。假設輸入序列是:
x 1 , . . . , x T 其中 x t 是輸入文本序列中的第 t 個詞元 x_1,...,x_T\\ 其中x_t是輸入文本序列中的第t個詞元 x1?,...,xT?其中xt?是輸入文本序列中的第t個詞元
在時間步t,循環神經網絡將詞元xt的輸入特征向量和上一時間步的隱狀態轉換為當前步的隱狀態,使用函數f來描述循環神經網絡的循環層所做的變換:
h t = f ( x t , h t ? 1 ) h_t=f(x_t,h_{t-1}) ht?=f(xt?,ht?1?)
總之,編碼器通過選定的函數q, 將所有時間步的隱狀態轉換為上下文變量:
c = q ( h 1 , . . . , h T ) c=q(h_1,...,h_T) c=q(h1?,...,hT?)
比如,當
q ( h 1 , . . . , h T ) = h T q(h_1,...,h_T)=h_T q(h1?,...,hT?)=hT?
時,上下文變量僅僅是輸入序列在最后時間步的隱狀態。
到目前,我們使用的是一個單向循環神經網絡來設計編碼器,隱狀態只依賴于輸入子序列,這個子序列是由輸入序列的開始位置到隱狀態所在的時間步的位置(包括隱狀態所在的時間步)組成。我們也可以使用雙向循環神經網絡構造編碼器,隱狀態對整個序列的信息都進行了編碼。
現在開始實現循環神經網絡編碼器,我們使用了嵌入層來獲得輸入序列的每個詞元的特征向量。嵌入層的權重是一個矩陣,其行數等于輸入詞表的大小(vocab_size),其列數等于特征向量的維度(embed_size)。這里選擇了一個多層門控循環單元來實現編碼器:
#@save
class Seq2SeqEncoder(d2l.Encoder):"""用于序列到序列學習的循環神經網絡編碼器"""def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,dropout=0, **kwargs):super(Seq2SeqEncoder, self).__init__(**kwargs)# 嵌入層self.embedding = nn.Embedding(vocab_size, embed_size)self.rnn = nn.GRU(embed_size, num_hiddens, num_layers,dropout=dropout)def forward(self, X, *args):# 輸出'X'的形狀:(batch_size,num_steps,embed_size)X = self.embedding(X)# 在循環神經網絡模型中,第一個軸對應于時間步X = X.permute(1, 0, 2)# 如果未提及狀態,則默認為0output, state = self.rnn(X)# output的形狀:(num_steps,batch_size,num_hiddens)# state的形狀:(num_layers,batch_size,num_hiddens)return output, state
接著我們實例化上述編碼器的實現,使用一個兩層門控循環單元編碼器,其隱藏單元數為16。給定一小批量的輸入序列X(批量大小為4,時間步為7)。在完成所有時間步后,最后一層的隱狀態的輸出是一個張量(output由編碼器的循環層返回),形狀為(時間步數,批量大小,隱藏單元數)。
encoder = Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,num_layers=2)
encoder.eval()
X = torch.zeros((4, 7), dtype=torch.long)
output, state = encoder(X)
print(output.shape)
運行結果:
torch.Size([7, 4, 16])
解碼器
編碼器輸出的上下文變量c對整個輸入序列進行編碼。而來自訓練數據集的輸出序列
y 1 , y 2 , . . . , y T ′ y_1,y_2,...,y_{T^{'}} y1?,y2?,...,yT′?
對于每個時間步t’(與輸入序列或編碼器的時間步t不同),解碼器輸出的概率取決于先前的輸出子序列
y 1 , . . . , y t ′ ? 1 y_1,...,y_{t^{'}-1} y1?,...,yt′?1?
和上下文變量c,即
P ( y t ′ ∣ y 1 , . . . , y t ′ ? 1 , c ) P(y_{t^{'}}|y_1,...,y_{t^{'}-1},c) P(yt′?∣y1?,...,yt′?1?,c)
為了在序列上模型化這種概率,我們可以使用另一個循環神經網絡作為解碼器。在輸出序列上的任意時間步t’,循環神經網絡將來自上一時間步的輸出和上下文c作為輸入,然后再當前時間步將它們和上一隱狀態轉換為當前時間步的隱狀態。可用g表示解碼器的隱藏層的變換:
s t ′ = g ( y t ′ ? 1 , c , s t ′ ? 1 ) s_{t^{'}}=g(y_{t^{'}-1},c,s_{t^{'}-1}) st′?=g(yt′?1?,c,st′?1?)
獲得解碼器隱狀態后,我們可以使用輸出層和softmax操作來計算在時間步t’時輸出y_{t^{'}}的條件概率分布:
P ( y t ′ ∣ y 1 , . . . , y t ′ ? 1 , c ) P(y_{t^{'}}|y_1,...,y_{t^{'}-1},c) P(yt′?∣y1?,...,yt′?1?,c)
當實現解碼器時,我們直接使用編碼器的最后一個時間步的隱狀態來初始化解碼器的隱狀態。這就要求使用編碼器和解碼器要有相同數量的層和隱藏單元。
為了進一步包含經過編碼的輸入序列的信息,上下文變量在所有的時間步與解碼器的輸入進行拼接。為了預測輸出詞元的概率分布,在循環神經網絡解碼器的最后一層使用全連接層來變換隱狀態。
class Seq2SeqDecoder(d2l.Decoder):"""用于序列到序列學習的循環神經網絡解碼器"""def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,dropout=0, **kwargs):super(Seq2SeqDecoder, self).__init__(**kwargs)self.embedding = nn.Embedding(vocab_size, embed_size)self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,dropout=dropout)self.dense = nn.Linear(num_hiddens, vocab_size)def init_state(self, enc_outputs, *args):return enc_outputs[1]def forward(self, X, state):# 輸出'X'的形狀:(batch_size,num_steps,embed_size)X = self.embedding(X).permute(1, 0, 2)# 廣播context,使其具有與X相同的num_stepscontext = state[-1].repeat(X.shape[0], 1, 1)X_and_context = torch.cat((X, context), 2)output, state = self.rnn(X_and_context, state)output = self.dense(output).permute(1, 0, 2)# output的形狀:(batch_size,num_steps,vocab_size)# state的形狀:(num_layers,batch_size,num_hiddens)return output, state
下面我們輸出一下解碼器的輸出形狀:
decoder = Seq2SeqDecoder(vocab_size=10, embed_size=8, num_hiddens=16,num_layers=2)
decoder.eval()
state = decoder.init_state(encoder(X))
output, state = decoder(X, state)
print(output.shape, state.shape)
輸出結果:
torch.Size([4, 7, 10]) torch.Size([2, 4, 16])
顯然,解碼器的輸出形狀變為(批量大小,時間步數,詞表大小),其中張量的最后一個維度存儲預測的詞元分布。
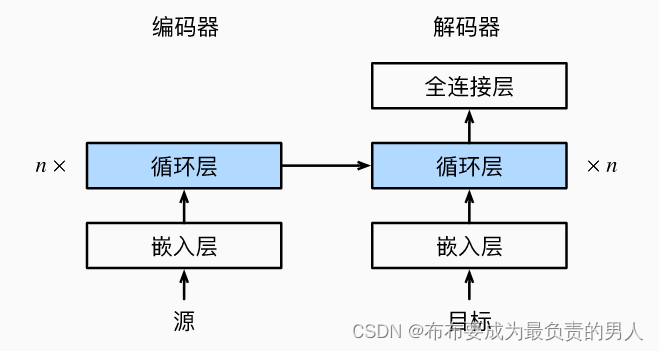
上述循環神經網絡“編碼器-解碼器”模型中的各層如下所示:
損失函數
在每個時間步,解碼器預測了輸出詞元的概率分布,可以使用softmax來獲得分布, 并通過計算交叉熵損失函數來進行優化,數據集中的詞元可能是被填充過的,因此,我們應該將填充詞元的預測排除在損失函數的計算之外。
我們使用sequence_mask函數,通過零值化屏蔽不相關的項, 以便后面任何不相關預測的計算都是與零的乘積,結果都等于零。
#@save
def sequence_mask(X, valid_len, value=0):"""在序列中屏蔽不相關的項"""maxlen = X.size(1)mask = torch.arange((maxlen), dtype=torch.float32,device=X.device)[None, :] < valid_len[:, None]X[~mask] = valuereturn X
現在,我們可以通過擴展softmax交叉熵損失函數來遮蔽不相關的預測。最初,所有預測詞元的掩碼都設置為1。一旦給定了有效長度,與填充詞元對應的掩碼將被設置為0。最后,將所有詞元的損失乘以掩碼,以過濾掉損失中填充詞元產生的不相關預測。
#@save
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):"""帶遮蔽的softmax交叉熵損失函數"""# pred的形狀:(batch_size,num_steps,vocab_size)# label的形狀:(batch_size,num_steps)# valid_len的形狀:(batch_size,)def forward(self, pred, label, valid_len):weights = torch.ones_like(label)weights = sequence_mask(weights, valid_len)self.reduction='none'unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(pred.permute(0, 2, 1), label)weighted_loss = (unweighted_loss * weights).mean(dim=1)return weighted_loss
訓練
#@save
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):"""訓練序列到序列模型"""def xavier_init_weights(m):if type(m) == nn.Linear:nn.init.xavier_uniform_(m.weight)if type(m) == nn.GRU:for param in m._flat_weights_names:if "weight" in param:nn.init.xavier_uniform_(m._parameters[param])net.apply(xavier_init_weights)net.to(device)optimizer = torch.optim.Adam(net.parameters(), lr=lr)loss = MaskedSoftmaxCELoss()net.train()animator = d2l.Animator(xlabel='epoch', ylabel='loss',xlim=[10, num_epochs])for epoch in range(num_epochs):timer = d2l.Timer()metric = d2l.Accumulator(2) # 訓練損失總和,詞元數量for batch in data_iter:optimizer.zero_grad()X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0],device=device).reshape(-1, 1)dec_input = torch.cat([bos, Y[:, :-1]], 1) # 強制教學Y_hat, _ = net(X, dec_input, X_valid_len)l = loss(Y_hat, Y, Y_valid_len)l.sum().backward() # 損失函數的標量進行“反向傳播”d2l.grad_clipping(net, 1)num_tokens = Y_valid_len.sum()optimizer.step()with torch.no_grad():metric.add(l.sum(), num_tokens)if (epoch + 1) % 10 == 0:animator.add(epoch + 1, (metric[0] / metric[1],))print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} 'f'tokens/sec on {str(device)}')
現在就可以創建和訓練一個循環神經網絡“編碼器-解碼器”模型用于序列到序列的學習。
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 300, d2l.try_gpu()train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers,dropout)
decoder = Seq2SeqDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers,dropout)
net = d2l.EncoderDecoder(encoder, decoder)
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
d2l.plt.show()
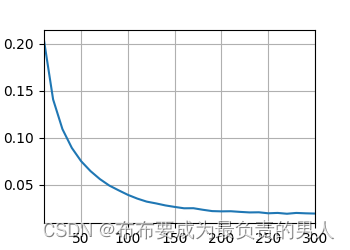
輸出結果:
loss 0.020, 9040.7 tokens/sec on cpu
運行圖片:
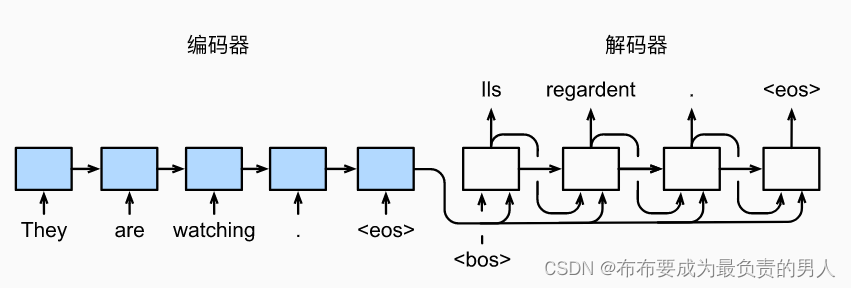
預測
與訓練類似,序列開始詞元bos在初始時間步被輸入到解碼器中。 當輸出序列的預測遇到序列結束詞元eos時,預測就結束了。
#@save
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,device, save_attention_weights=False):"""序列到序列模型的預測"""# 在預測時將net設置為評估模式net.eval()src_tokens = src_vocab[src_sentence.lower().split(' ')] + [src_vocab['<eos>']]enc_valid_len = torch.tensor([len(src_tokens)], device=device)src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>'])# 添加批量軸enc_X = torch.unsqueeze(torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0)enc_outputs = net.encoder(enc_X, enc_valid_len)dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)# 添加批量軸dec_X = torch.unsqueeze(torch.tensor([tgt_vocab['<bos>']], dtype=torch.long, device=device), dim=0)output_seq, attention_weight_seq = [], []for _ in range(num_steps):Y, dec_state = net.decoder(dec_X, dec_state)# 我們使用具有預測最高可能性的詞元,作為解碼器在下一時間步的輸入dec_X = Y.argmax(dim=2)pred = dec_X.squeeze(dim=0).type(torch.int32).item()# 保存注意力權重(稍后討論)if save_attention_weights:attention_weight_seq.append(net.decoder.attention_weights)# 一旦序列結束詞元被預測,輸出序列的生成就完成了if pred == tgt_vocab['<eos>']:breakoutput_seq.append(pred)return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
預測序列的評估
原則上,對預測序列中的任意n元語法,BLEU的評估都是這個n元語法是否出現在序列標簽中。
我們將BLEU定義為:
e x p ( m i n ( 0 , 1 ? l e n l a b e l l e n p r e d ) ) ∏ n = 1 k p n 1 / 2 n 其中, l e n l a b e l 是標簽序列的詞元數, l e n p r e d 表示序列預測中的詞元數 , k 是用于匹配的最長 n 元語法 p n 表示 n 元語法的精確度, p n = 預測序列與標簽序列中匹配的 n 元語法的數量 預測序列中 n 元語法的數量 exp(min(0,1-\frac{len_{label}}{len_{pred}}))\prod_{n=1}^kp_n^{1/2^n}\\ 其中,len_{label}是標簽序列的詞元數,len_{pred}表示序列預測中的詞元數,k是用于匹配的最長n元語法\\ p_n表示n元語法的精確度,p_n=\frac{預測序列與標簽序列中匹配的n元語法的數量}{預測序列中n元語法的數量} exp(min(0,1?lenpred?lenlabel??))n=1∏k?pn1/2n?其中,lenlabel?是標簽序列的詞元數,lenpred?表示序列預測中的詞元數,k是用于匹配的最長n元語法pn?表示n元語法的精確度,pn?=預測序列中n元語法的數量預測序列與標簽序列中匹配的n元語法的數量?
比如,我們給定標簽序列為ABCDEF,預測序列為ABBCD,顯然p1=4/5,p2=3/4,p3=1/3,p4=0。
我們可以再次剖析一下上式的細節,可以發現上式有多“妙”:
1、我們知道,n元語法越長,匹配難度越大,所以我們如果對于越長的且匹配了的n元語法,應該給與更大的支持,而BLEU正是這樣,為更長的n元語法的精確度分配了更大的權重:
當 p n 固定時, p n 1 / 2 n 會隨著 n 的增長而增加(注意 p n 顯然恒小于 1 ) 當p_n固定時,p_n^{1/2^n}會隨著n的增長而增加(注意p_n顯然恒小于1) 當pn?固定時,pn1/2n?會隨著n的增長而增加(注意pn?顯然恒小于1)
2、由于預測的序列越短,獲得的pn值會越高,因此我們需要對其進行懲罰:
m i n ( 0 , 1 ? l e n l a b e l l e n p r e d ) min(0,1-\frac{len_{label}}{len_{pred}}) min(0,1?lenpred?lenlabel??)
可以看出,序列很短的時候,利用這個式子也會使得exp更小,從而降低BLEU。
BLEU的代碼實現如下:
def bleu(pred_seq, label_seq, k): #@save"""計算BLEU"""pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')len_pred, len_label = len(pred_tokens), len(label_tokens)score = math.exp(min(0, 1 - len_label / len_pred))for n in range(1, k + 1):num_matches, label_subs = 0, collections.defaultdict(int)for i in range(len_label - n + 1):label_subs[' '.join(label_tokens[i: i + n])] += 1for i in range(len_pred - n + 1):if label_subs[' '.join(pred_tokens[i: i + n])] > 0:num_matches += 1label_subs[' '.join(pred_tokens[i: i + n])] -= 1score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))return score
現在,利用訓練好的循環神經網絡“編碼器-解碼器”模型, 將幾個英語句子翻譯成法語,并和訓練數據中的法語比較,計算BLEU的最終結果:
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):translation, attention_weight_seq = predict_seq2seq(net, eng, src_vocab, tgt_vocab, num_steps, device)print(f'{eng} => {translation}, bleu {bleu(translation, fra, k=2):.3f}')
運行結果:
go . => va le foutre bras !, bleu 0.000
i lost . => j’ai perdu ., bleu 1.000
he’s calm . => il est paresseux ., bleu 0.658
i’m home . => je suis chez moi porte qui suis ., bleu 0.640
看起來這次的效果并不好,第一個翻譯出來的BLEU是0。
一個原因是我們的使用方法還是太原始了(seq2seq使用貪心的方式,下一個詞元直接選概率高的,學過動態規劃就知道這個不一定為最優)。
一個很好的序列生成策略是束搜索,將在之后講解。
小結
1、根據“編碼器-解碼器”架構的設計, 我們可以使用兩個循環神經網絡來設計一個序列到序列學習的模型。
2、在實現編碼器和解碼器時,我們可以使用多層循環神經網絡。
3、我們可以使用遮蔽來過濾不相關的計算,例如在計算損失時。
4、在“編碼器-解碼器”訓練中,強制教學方法將原始輸出序列(而非預測結果)輸入解碼器。
5、BLEU是一種常用的評估方法,它通過測量預測序列和標簽序列之間的元語法的匹配度來評估預測。



)






)
)







