一、說明
????????這個故事介紹了使用這種類型的數據來訓練機器學習3D模型。特別是,我們討論了Kaggle中可用的MNIST數據集的3D版本,以及如何使用Keras訓練模型識別3D數字。
????????3D 數據無處不在。由于我們希望構建AI來與我們的物理世界進行交互,因此使用3D數據來訓練我們的模型非常有意義。
二、3D 數據從何而來?
????????現在看看你周圍的物體。它們是占據三維房間的三維實體,您 - 也是一個3D實體 - 此時此刻。如果這個房間里的所有東西都是靜態的,我們可以將此環境建模為 3D 空間數據。

????????????????????????????????????????????????????????????????建筑掃描 —?來源
????????3D 數據有多種來源,例如 2D 圖像序列和 3D 掃描儀數據。在這個故事中,我們開始使用來自流行MNIST數據集的合成生成的3D版本的點云來處理3D數據。
三、3D MNIST 數據集
????????以防萬一您還不知道,MNIST是著名的2D手寫數字圖像集。MNIST 中的元素是小型 28x28 灰度圖像。在這個故事中,我們將使用MNIST的3D版本:
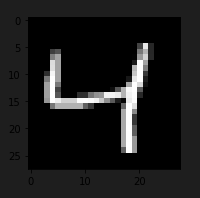
MNIST 中的原始數字
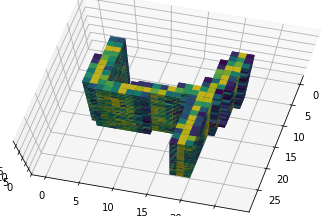
????????????????????????????????????????????????????????修改后的3D版本
????????可以使用此 jupyter 筆記本生成此數據集。
????????增強型 MNIST 3D 中的 3D 圖像是從 MNIST 中的原始 2D 圖像中獲得的,這些圖像經過一組轉換修改:
1 -?膨脹:這是堆疊?N?次相同數字圖像以從 3D 數字獲得 2D 身體的過程。

????????????????????????????????????????手寫數字的放大版本 3
2 - 噪聲:對每個 3D 點應用顯著的高斯噪聲
????????????????????????????????????????????????????????具有高斯噪聲的相同圖像
3 -?著色:MNIST 中的寄存器是灰度圖像。為了使事情更具挑戰性,讓我們將它們轉換為包含隨機顏色
4 - 旋轉:一旦它們是 3D 對象,我們就可以旋轉它們,這就是我們要做的

????????????????????????????????????????具有不同旋轉的相同圖像
????????有關3D MNIST數據集的更多詳細信息可以在Kaggle中找到。現在,讓我們直接跳到分步過程:
四、獲取和加載數據
????????首先要做的是:從Kaggle下載數據集文件。解壓縮文件以獲取?3d-mnist.h5。然后,加載數據集
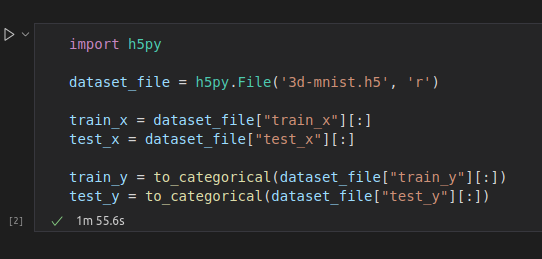
????????簡而言之,train_x 或 test_x 中的每個寄存器都是一個 16x16x16 的立方體。每個立方體保存一個 3D 數字的點云數據。您可以輕松地從數據集中提取任何寄存器:
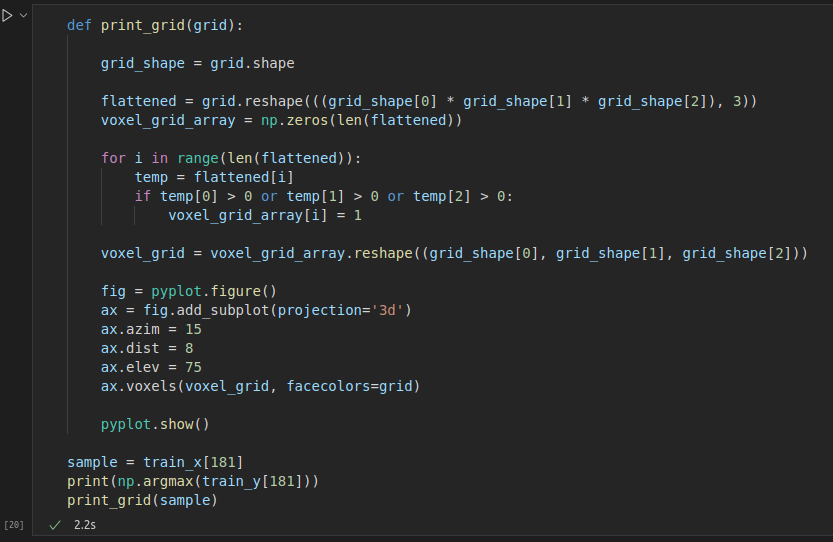
????????結果如下:

事實上,這是MNIST中第3個元素的增強181D版本:

現在我們已經加載了數據集,我們可以使用它來訓練我們的模型。
4.1 定義模型
????????我們希望訓練一個模型來識別立方體中數字的 3D 表示。在規范 2D 版本的 MNIST 中用于識別手寫數字的模型不適合 3D 數據集版本。因此,為了處理3D數據,有必要使用3D轉換,例如卷積3D和3D最大池化。實際上,Keras支持這種類型的過濾器。
定義一個3D模型來處理我們的3D數據確實非常簡單:
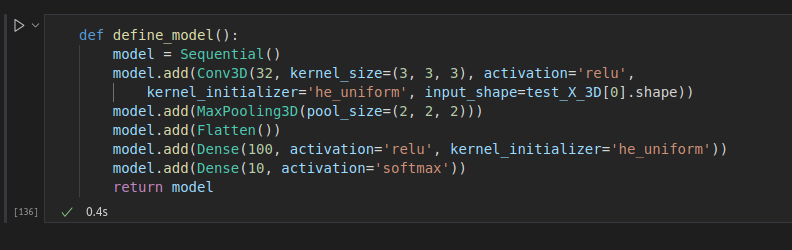
????????這是一個非常簡單的模型,但可以完成這項工作。請記住,您可以在此處獲取完整的源代碼。
4.2 訓練模型
讓我們使用隨機梯度下降來訓練模型。隨意使用您喜歡的另一個優化器(adam,RMSProp等):
model = define_model()
model.compile(loss=tensorflow.keras.losses.categorical_crossentropy,optimizer=tensorflow.keras.optimizers.SGD(learning_rate=0.01, momentum=0.9), metrics=['accuracy'])
history = model.fit(train_X_3D, train_y, batch_size=32, epochs=4, verbose=1, validation_split=0.2)我剛剛運行了這段代碼,這是我的輸出:

4.3 訓練結果
????????這是我們的第一次審判。僅經過 4 個 epoch,我們在驗證集上獲得了 96.34% 的準確率!當然,對混淆矩陣進行適當的分析可以更好地理解這種性能。但是,至少在第一次運行中,這些結果是鼓舞人心的!
????????請注意,驗證損失在 4 個 epoch 中一直在減少。顯然,這列火車比必要的時間更早完成。下一次,我們可能會設置更高的紀元數量并使用更詳細的停止條件。
讓我們看看它在測試數據上的表現如何!
4.4 評估模型
????????以下是我們將如何檢查性能:
score = model.evaluate(test_X_3D, test_y, verbose=0)
print('Test accuracy: %.2f%% Test loss: %.3f' % (score[1]*100, score[0])) ????????這是我們目前的結果:
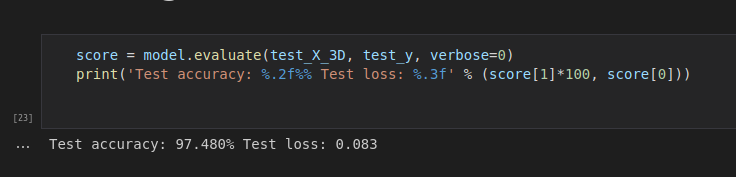
????????我不得不說我真的很驚訝。這個簡單的模型實現了良好的性能,即使數據幾乎沒有被噪聲、旋轉和隨機顏色映射所修改。
????????此外,考慮到數據量和不使用 GPU,訓練速度太快了!涼!
????????我們可以調整超參數和訓練優化器,以輕松獲得更好的結果。然而,高性能并不是我們的目標。
????????我們學習了如何使用3D卷積,現在我們知道如何創建簡單但功能強大的CNN網絡來處理我們的3D數據。
五、下一步是
下一步是訓練模型以識別從 4D 圖像時間序列生成的 3D 數據中的事件。敬請期待!

)






)
)









