
前言:Hello大家好,我是小哥談。數據集標注完成之后,下一步就是對這些數據集進行劃分了。面對繁雜的數據集,如果手動劃分的話,不僅麻煩而且不能保持隨機性。本節課就給大家介紹一種方法,即使用代碼去劃分數據集。那現在就讓我們開始今天的學習吧!🌈?
?![]() 前期回顧:
前期回顧:
? ? ? ? ? ??YOLOv5入門實踐(1)— 手把手教你使用labelimg標注數據集(附安裝包+使用教程)
? ? ? ? ? ??YOLOv5入門實踐(2)— 手把手教你使用make sense標注數據集(附工具地址+使用教程)
? ? ? ? ?? ?目錄
🚀1.訓練集、驗證集和測試集
🚀2.數據集劃分原則
🚀3.準備數據集
步驟1:創建數據集文件夾
步驟2:標注數據集
步驟3:創建劃分后數據集的文件夾
🚀4.劃分代碼
步驟1:在YOLOv5項目目錄下創建split.py文件
步驟2:將代碼復制到split.py文件中
步驟3:設置路徑并設置劃分比例

🚀1.訓練集、驗證集和測試集
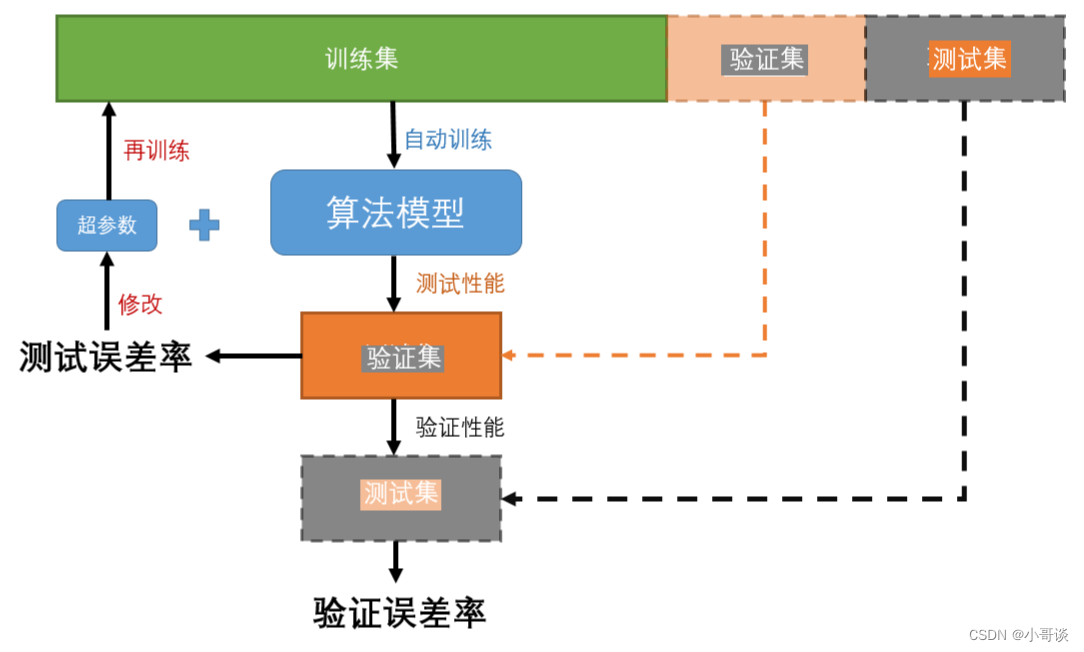
數據集標注完成之后,我們通常需要把數據集劃分為三類:訓練集、驗證集和測試集。🌺
舉個例子:模型的訓練與學習,類似于老師教學生知識的過程。
訓練集(train set):用于訓練模型(擬合參數),即模型擬合的數據樣本集合。相當于老師上課教學生知識的過程。
驗證集(validation set):用于確定網絡結構或者控制模型復雜程度的超參數(擬合超參數),是模型訓練過程中單獨留出的樣本集,它可以用于調整模型的超參數和用于對模型的能力進行初步評估。 通常用來在模型迭代訓練時,用以驗證當前模型泛化能力(準確率,召回率等),防止過擬合的現象出現,以決定如何調整超參數。相當于上完課后的課后練習題,用于幫助學生查漏補缺。
測試集(test set):用來評估最終模型的性能如何(評價模型好壞),測試集沒有參于訓練,主要是測試訓練好的模型的準確能力等,但不能作為調參、選擇特征等算法相關的選擇的依據,說白了就只是用于評價模型好壞的一個數據集。相當于期末考試,真正地去檢驗學生的學習效果。

說明:??????
參數:指由模型通過學習得到的變量,如權重和偏置。?
超參數:指根據經驗設定的參數,如迭代次數、隱藏層數、每層神經元的個數、學習率等。?
🚀2.數據集劃分原則
數據集劃分的方法并沒有明確的規定,不過可以參考3個原則:
1.對于小規模樣本集(幾萬量級),常用的分配比例是 70% 訓練集、20% 驗證集、10% 測試集。
2.對于大規模樣本集(百萬級以上),只要驗證集和測試集的數量足夠即可,例如有 100w 條數據,那么留 1w 驗證集,1w 測試集即可。1000w 的數據,同樣留 1w 驗證集和 1w 測試集。
3.超參數越少,或者超參數很容易調整,那么可以減少驗證集的比例,更多的分配給訓練集。

🚀3.準備數據集
步驟1:創建數據集文件夾
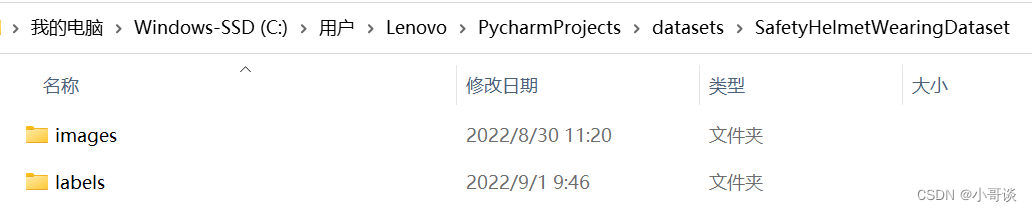
在與項目文件同級目錄的datasets文件夾中,創建SafetyHelmetWearingDataset文件夾接著在該文件夾下創建images和labels文件夾。
- images:存放需要打標簽的圖片文件
- labels:存放標注的標簽文件
說明:??????
1.也可以在YOLOv5項目目錄下創建數據集文件夾并命名,其性質是一樣的。?
2.datasets?和?SafetyHelmetWearingDataset是我自己命名的,是為后期訓練安全帽佩戴檢測模型做準備,此處名字可以自定義。?
步驟2:標注數據集
說明:
關于數據集的標注,可以參考我的另外兩篇標注數據集的文章。??????
YOLOv5入門實踐(1)— 手把手教你使用labelimg標注數據集(附安裝包+使用教程)
YOLOv5入門實踐(2)— 手把手教你使用make sense標注數據集(附工具地址+使用教程)
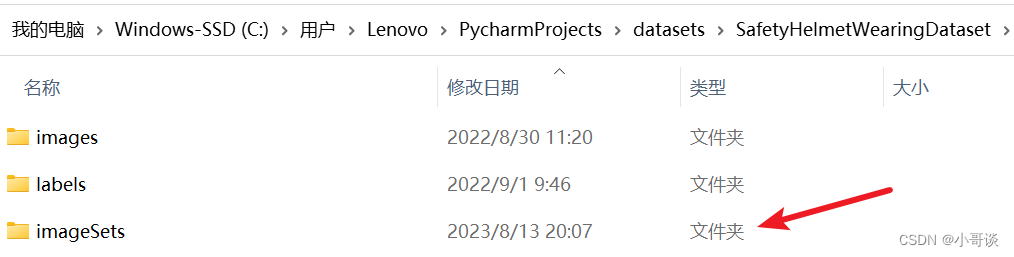
步驟3:創建劃分后數據集的文件夾
創建一個名為imageSets的文件夾,用來保存稍后劃分好的訓練集、驗證集和測試集。🌱
說明:??????
1.所有訓練所需的圖片存于一個文件夾中(指images),所有訓練所需的標簽存于一個文件夾中(指labels)。?
2.圖片名與標簽名要一一對應。?
🚀4.劃分代碼
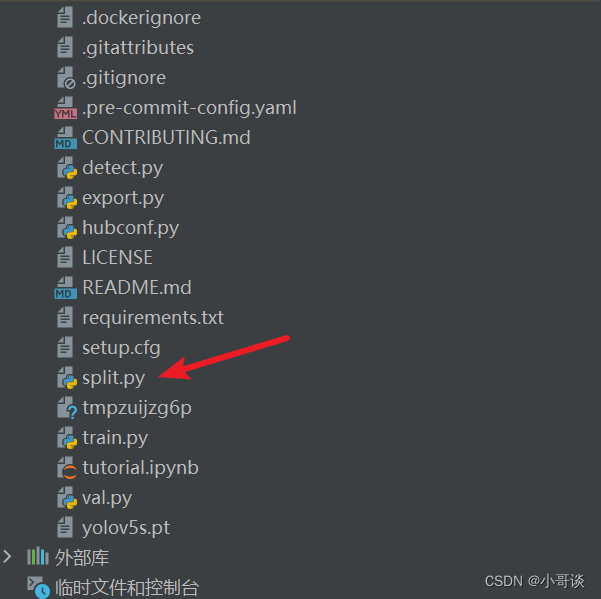
步驟1:在YOLOv5項目目錄下創建split.py文件
步驟2:將代碼復制到split.py文件中
import os
import shutil
import randomrandom.seed(0)def split_data(file_path,xml_path, new_file_path, train_rate, val_rate, test_rate):each_class_image = []each_class_label = []for image in os.listdir(file_path):each_class_image.append(image)for label in os.listdir(xml_path):each_class_label.append(label)data=list(zip(each_class_image,each_class_label))total = len(each_class_image)random.shuffle(data)each_class_image,each_class_label=zip(*data)train_images = each_class_image[0:int(train_rate * total)]val_images = each_class_image[int(train_rate * total):int((train_rate + val_rate) * total)]test_images = each_class_image[int((train_rate + val_rate) * total):]train_labels = each_class_label[0:int(train_rate * total)]val_labels = each_class_label[int(train_rate * total):int((train_rate + val_rate) * total)]test_labels = each_class_label[int((train_rate + val_rate) * total):]for image in train_images:print(image)old_path = file_path + '/' + imagenew_path1 = new_file_path + '/' + 'train' + '/' + 'images'if not os.path.exists(new_path1):os.makedirs(new_path1)new_path = new_path1 + '/' + imageshutil.copy(old_path, new_path)for label in train_labels:print(label)old_path = xml_path + '/' + labelnew_path1 = new_file_path + '/' + 'train' + '/' + 'labels'if not os.path.exists(new_path1):os.makedirs(new_path1)new_path = new_path1 + '/' + labelshutil.copy(old_path, new_path)for image in val_images:old_path = file_path + '/' + imagenew_path1 = new_file_path + '/' + 'val' + '/' + 'images'if not os.path.exists(new_path1):os.makedirs(new_path1)new_path = new_path1 + '/' + imageshutil.copy(old_path, new_path)for label in val_labels:old_path = xml_path + '/' + labelnew_path1 = new_file_path + '/' + 'val' + '/' + 'labels'if not os.path.exists(new_path1):os.makedirs(new_path1)new_path = new_path1 + '/' + labelshutil.copy(old_path, new_path)for image in test_images:old_path = file_path + '/' + imagenew_path1 = new_file_path + '/' + 'test' + '/' + 'images'if not os.path.exists(new_path1):os.makedirs(new_path1)new_path = new_path1 + '/' + imageshutil.copy(old_path, new_path)for label in test_labels:old_path = xml_path + '/' + labelnew_path1 = new_file_path + '/' + 'test' + '/' + 'labels'if not os.path.exists(new_path1):os.makedirs(new_path1)new_path = new_path1 + '/' + labelshutil.copy(old_path, new_path)if __name__ == '__main__':file_path = "C:\Users\Lenovo\PycharmProjects\datasets\SafetyHelmetWearingDataset\images"xml_path = "C:\Users\Lenovo\PycharmProjects\datasets\SafetyHelmetWearingDataset\labels"new_file_path = "C:\Users\Lenovo\PycharmProjects\datasets\SafetyHelmetWearingDataset\imageSets"split_data(file_path,xml_path, new_file_path, train_rate=0.7, val_rate=0.2, test_rate=0.1)步驟3:設置路徑并設置劃分比例
file_path:圖片所在位置的絕對路徑,即?images。
xml_path:標簽所在位置的絕對路徑,即?labels。
new_file_path:劃分后三個文件的保存位置,即 imageSets。
最后一行是劃分比例,大家可以根據實際情況來劃分,這里我劃分的是7:2:1。






)
)



)








