
筆記整理:張沈昱,東南大學碩士,研究方向為自然語言處理
鏈接:https://github.com/FranxYao/FlanT5-CoT-Specialization
動機
本文的動機是探索如何在多步推理任務中通過大型語言模型提升較小的語言模型的性能。作者認為,大型語言模型模型(如GPT-3.5系列模型)雖然具有強大的建模能力,但是它們通常需要大量的計算資源和時間來訓練和部署。相比之下,小規模語言模型雖然容量有限,但它們可以更快地訓練和部署,并且在某些任務上有更優異的表現。因此,作者希望通過專業化較小的語言模型來解決多步推理任務,以獲得更好的性能。作者提出了一種從大型教師模型中提取思維鏈(Chain-of-Thought, CoT)路徑來微調指令微調模型(Instruction-Tuned?Model,本文使用Flan-T5),以將其能力集中在目標任務上的方法。通過這種做法,作者證明了小型語言模型可以在多步推理任務中獲得不錯的性能提升,且這種性能提升隨著模型體量的提升穩定增長。
貢獻
本文的主要貢獻包括:
1)提出了一種專業化較小語言模型的方法,將其能力集中在目標任務上,從而獲得更好的性能和更快的訓練和部署速度。
2)通過從大型教師模型中提取思維鏈路徑,并用其來微調指令微調模型,在多步推理任務中,小型語言模型可以獲得不錯的性能提升,并且可以在特定任務上表現出與大型語言模型相當的性能。
3)通過實驗證明隨著模型規模的增大,小型語言模型可以呈現出穩定的性能提升。
4)通過實驗證明使用指令微調的模型(Flan-T5)作為基礎模型比使用原始的預訓練模型(T5)具有更好的泛化性能。
方法
給定一個訓練問題,作者使用code-davinci-002(Codex)來生成40個針對該問題的CoT解決方案,然后選擇其中正確解答了問題的回答作為訓練語料。解決方案包括答案和解釋答案的中間步驟的思維鏈。除了將問題作為輸入并將[CoT, answer]對作為輸出的標準微調設置(圖1?B4)外,作者還考慮了三種額外的數據格式:1) in-context answer-only(圖1?B1),不使用CoT數據,并在問題前添加4個in-context樣本,采用這種設置的原因是先前的工作表明用in-context樣本進行微調可以提高模型的上下文學習能力;2)in-context chain-of-thought(圖1 B2),在輸入和輸出中都添加了CoT;3)zero-shot?and?answer-only(圖1?B3),直接輸入問題并輸出答案,使用僅包含答案的數據是因為以前的工作表明它們能提高模型性能。在本文實驗中,作者表明,in-context樣本能引發模型zero-shot的能力,而zero-shot的數據則會犧牲模型上下文學習的能力。
就訓練目標而言,本文采用了基于分布匹配的蒸餾方法,即最小化學生模型與老師模型輸出的概率分布之間的KL散度(在本文中為模型自回歸解碼過程中每步的輸出分布)。

圖1?A.?專業模型的總體流程 B.?本文所使用的4種數據格式
實驗
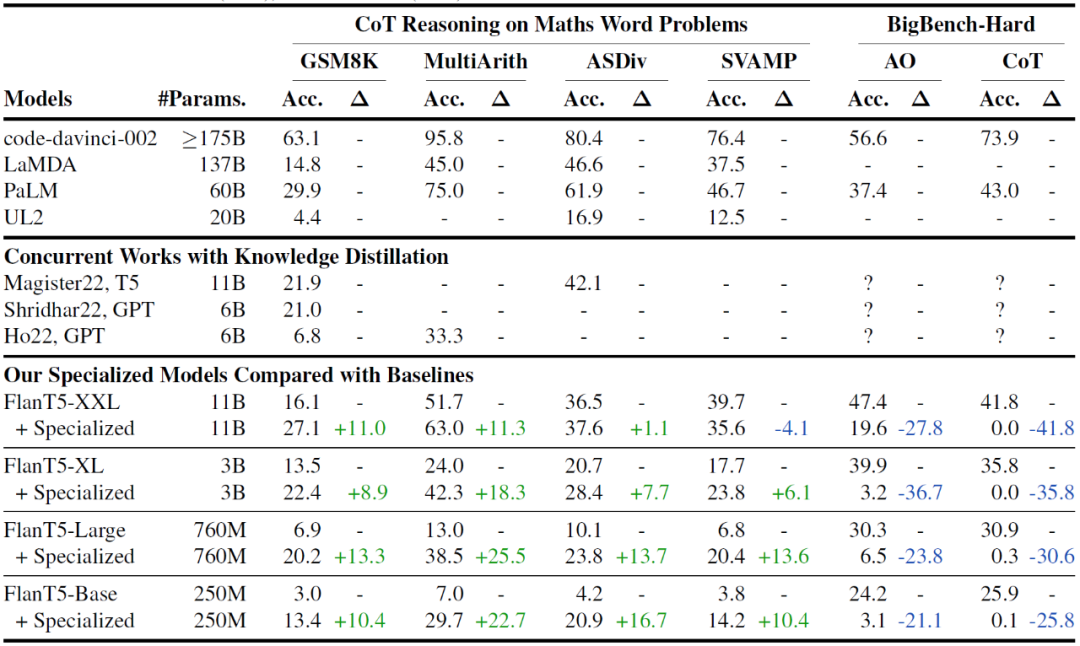
本文針對模型的數學推理能力和通用能力進行了實驗。對于數學推理能力,作者使用code-davinci-002增強的GSM8K數據集作為訓練數據集。GSM8K有7個訓練問題,對于每個問題,作者要求大型模型生成40個不同的解決方案,從生成的解決方案中提取正確的解決方案,共計獲得了有13萬條訓練數據。作者在MultiArith、ASDiv和SVAMP(合稱M-A-S)數據集上測試了模型的分布外性能。M-A-S和GSM8K的區別在于它們都是小學水平的算術推理問題,但是數據集中涉及的實體是不同的。例如,GSM8K可以考慮對食物進行算術推理(例如,5個蘋果+8個香蕉=13個水果),而MultiArith可以考慮動物(例如,2只狗+3只貓=5只動物)。這種類型的分布外泛化通常被稱為詞法級組合泛化(即兩者都是加法,但詞法不同)。對于通用能力,作者使用BigBench Hard(BBH)測試套件,這是一個由26個具有挑戰性的數據集組成的列表,從多個維度測試模型的推理能力(例如日期理解、因果判斷、參考游戲等)。由于其難度和廣泛的覆蓋面,BBH是測試模型通用能力的理想基準。
對于基線模型,作者考慮了通用的大型模型和蒸餾過的小型模型,具體包括:1) 通用的大型模型,根據模型規模排序為:code-davinci-002,LaMDA 137B和PaLM 60B(兩者都是強大的CoT推理的通用模型),UL2(一個具有良好CoT能力的20B模型);2)同期的知識蒸餾模型。實驗表明,本文模型表現明顯優于其他對比方法,主要是因為本文使用了經過指令微調的Flan-T5作為基礎模型,而不是原始預訓練模型(T5),實驗結果如表1。
表1?總體實驗結果
總結
在這項工作中,作者研究了利用思維鏈提示學習使較小的語言模型在多步驟推理任務上專業化。實驗表明,本文方法能將小模型的能力從通用方向集中到目標數學推理任務。在進行專業化之后,模型性能隨著模型規模的增加而平滑增加。同時,本文實驗顯示了使用指令微調過的模型作為基礎模型的重要性,因為它們的泛化性能比原始預訓練過的檢查點更好。在模型專業化過程中需要做出多種權衡,包括模型泛化性能的損失,分布內和分布外泛化的平衡,以及上下文學習和zero-shot泛化能力的平衡。本文方法是在當下基于大模型的新研究范式中,專業化小模型的重要嘗試。
OpenKG
OpenKG(中文開放知識圖譜)旨在推動以中文為核心的知識圖譜數據的開放、互聯及眾包,并促進知識圖譜算法、工具及平臺的開源開放。

點擊閱讀原文,進入 OpenKG 網站。












庫)






