auto、范圍for、內聯函數、宏函數和nullptr
- 一、auto — 類型推導的魔法(C++ 11)
- 1、auto 是什么?
- 2、工作原理
- 3、優勢
- 4、限制和注意事項
- 二、范圍for (C++11)
- 1、基本語法
- 2、優勢
- 3、工作原理
- 4、注意事項
- 5、C++11: 范圍 for 循環的擴展:
- 三、宏函數
- 1、優勢
- 2、宏函數的危險
- 四、內聯函數
- 1、基本概念
- 2、工作原理
- 3、優勢
- 4、注意事項
- 5、內聯函數與編譯器優化
一、auto — 類型推導的魔法(C++ 11)
C++11 引入的 auto 關鍵字在現代 C++ 編程中扮演著重要的角色。它不僅使代碼更加簡潔,還提供了更好的可讀性和靈活性
1、auto 是什么?
auto 是 C++ 中的一個關鍵字,用于實現類型推導。它允許編譯器在變量聲明時根據初始化表達式的類型自動推導變量的類型。
→ 這樣,我們可以避免顯式指定變量類型,減少代碼冗余,同時保持類型安全。
typeid 可以查看對象類型,需要#include<typeinfo>
用法: typeid(c).name(),c是變量名
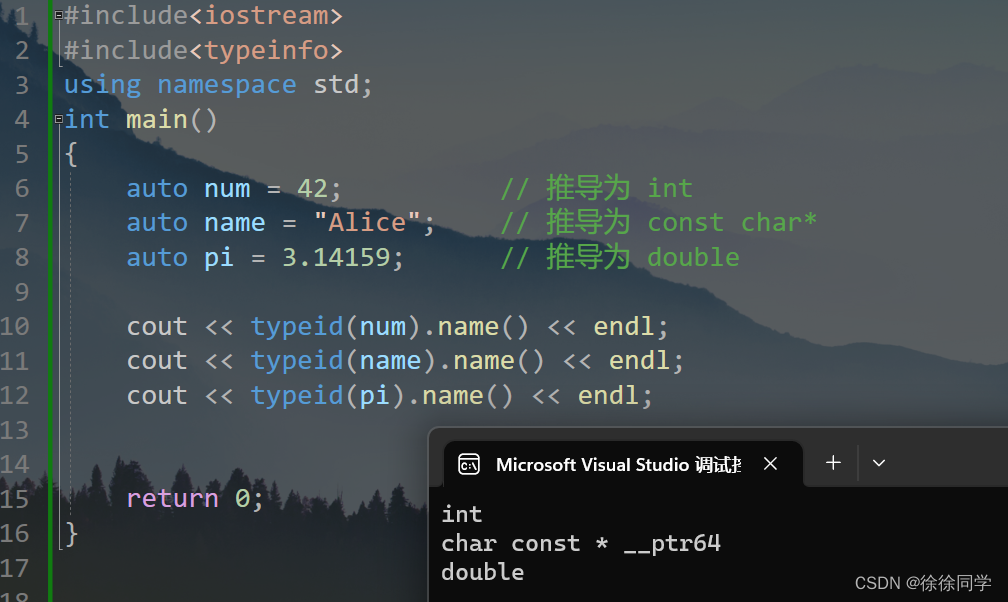
2、工作原理
在編譯過程中,auto 關鍵字的使用會被編譯器替換為實際的類型。
編譯器會通過初始化表達式來推導變量的類型,然后將推導出的類型替換到 auto 處。這意味著 auto 并不是一個新的數據類型,而只是一種方便的聲明方式。
3、優勢
-
a. 簡潔: 使用 auto 可以省略變量類型的冗長聲明,使代碼更加簡潔。
-
b. 可讀性: auto 提供了更清晰的代碼,讀者可以更容易地理解代碼的含義,而不必深入研究類型。
-
c. 容器迭代: 在遍歷容器時,auto 的使用可以避免手動指定容器類型,從而提高可讀性和靈活性。
-
d. 跨平臺性: auto 在一些情況下可以幫助提高代碼的可移植性,因為它減少了對特定數據類型大小的依賴。
4、限制和注意事項
-
a. 必須在聲明時進行初始化: auto 變量必須在聲明時進行初始化,以便編譯器能夠推導出其類型。
-
b. 不適用于函數參數和返回值: auto 通常用于聲明變量,而不適用于函數參數和返回值的類型。
-
c. 可能導致意外推導: 對于某些表達式,auto 的推導可能與預期不符,需要小心處理。
-
d. 不適用于非靜態成員變量: auto 不適用于非靜態成員變量的聲明。
-
e.不能定義數組 :※
auto arr[ ] = {1,2,2,1}; //wrong
? 數組是一種比較特殊的數據結構,其大小和元素類型都是數組類型的一部分,而不是表達式的一部分
auto 關鍵字不能直接用于定義數組,是因為數組的大小和元素類型是數組類型的一部分,而 auto 只關注初始化表達式的類型推導,無法同時推導數組的大小和元素類型。
例如,一個 int 數組和一個 double 數組的類型是不同的,即使它們的大小相同。而 auto 關鍵字在推導類型時只關注初始化表達式的類型,無法同時推導出數組的大小和元素類型。
然而,在 C++11 引入的標準中,我們可以使用 decltype 關鍵字來間接推導數組類型:
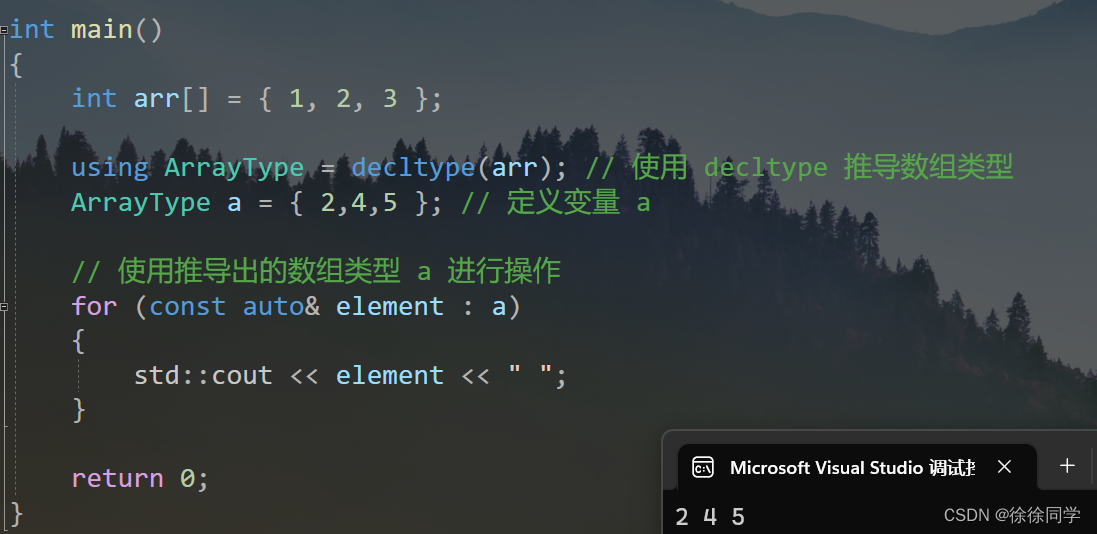
- 注意定義變量a的時候就不可以加[ ]
使用 decltype 可以將數組的類型精確地推導出來,但是仍然無法推導數組的大小
二、范圍for (C++11)
1、基本語法
范圍 for 循環是一種用于遍歷容器的現代方式,它的基本語法如下:
for (element_declaration : container)
{// 循環體
}
在這里,element_declaration 是一個聲明,用于指定在每次迭代中存儲容器中的元素。container 則是要遍歷的容器,可以是數組、標準容器(如 vector、list、map 等)或用戶自定義的容器類型。
2、優勢
-
a. 可讀性提高: 語法上更加簡潔,將遍歷的核心邏輯更突出,減少了迭代器和索引的干擾。
-
b. 避免越界錯誤: 避免了手動管理迭代器或索引的問題,從而減少了越界錯誤和其他低級錯誤的可能性。
-
c. 自動推導元素類型: 自動推導出容器中的元素類型,無需顯式指定,減少冗余信息。
3、工作原理
范圍 for 循環實際上是使用迭代器來遍歷容器的。編譯器會在幕后自動生成迭代器的代碼,以便訪問容器中的每個元素。對于不同類型的容器,編譯器會使用適當的迭代器,因此開發者無需擔心不同容器類型的迭代器實現。
4、注意事項
-
a. 不適用于修改元素: 范圍 for 循環在遍歷容器時只能讀取元素,不能修改元素的值。如果需要修改元素,應該使用傳統的 for 循環或迭代器。chu
-
b. 自動推導類型限制: 范圍 for 循環中的元素類型是自動推導的,因此可能會受到類型推導的限制。對于需要精確類型控制的場景,可能需要使用傳統 for 循環。
-
c. for循環迭代的范圍必須是確定的:對于數組而言,第一個元素 -> 最后一個元素 即是數組的范圍;但是對于函數傳參而言,傳遞數組的時候是以指針傳過去的,無法確定范圍。
5、C++11: 范圍 for 循環的擴展:
在 C++11 以后的版本中,范圍 for 循環的功能得到了擴展。
除了遍歷容器,還可以遍歷初始化列表、數組、字符串等。甚至可以使用 auto 關鍵字來自動推導元素類型。
遍歷的原理:自動取遍歷目標的每一個元素,再放到給定的臨時變量中,自動判斷結束。
auto 會根據遍歷目標的元素類型自動推導
std::initializer_list<int> numbers = {1, 2, 3, 4, 5};
for (auto num : numbers)
{// ...
}
👆 就是取 numbers 的元素放到 num 中,自動判斷循環結束。(直接寫數組的類型也可以 )
三、宏函數
宏函數是 C++ 中的一種預處理技術,使用預定義的宏名稱將代碼片段替換為文本。
這種替換在編譯前進行(→ 不會在運行時引入額外的開銷),不進行類型檢查或語法分析。
例如,我們可以使用 #define 來定義宏函數:
#define Add(x, y) ((x) + (y))
但是如果寫成#define Add(x, y) (x + y) 就麻煩了,因為是“替換”而不是“調用”,x和y有可能是表達式,計算結果就有可能與期望值不符
1、優勢
-
a. 強大的代碼生成能力: 宏函數可以生成復雜的代碼片段,減少重復性工作,提高開發效率。
-
b. 參數靈活: 宏函數可以接受任意數量和類型的參數,使其在某些情況下比普通函數更靈活。
-
c. 編譯前處理: 宏函數的替換發生在編譯前,因此不會在運行時引入額外的開銷。
2、宏函數的危險
-
a. 缺乏類型安全: 宏函數的替換是文本級別的,不進行類型檢查。這可能導致意外的類型問題。
-
b. 難以調試: 宏函數的錯誤可能在編譯后才會暴露,難以追蹤和修復。
-
c. 可讀性和維護性: 復雜的宏函數可能會降低代碼的可讀性和可維護性,因為它們隱藏了實際的邏輯。
隨著現代 C++ 的發展,許多宏函數的使用場景已經被更安全和可讀性更好的特性取代,比如:內聯函數可以提供類似宏函數的性能優勢,同時也會進行類型檢查,增加代碼的安全性。
四、內聯函數
內聯說明:只是向編譯器發出的一個請求,編譯器可以選擇忽略這個請求
1、基本概念
內聯函數是通過在函數聲明前加上 inline 關鍵字來定義的函數。
它告訴編譯器,在每次函數調用處將函數體直接插入,而不是傳統的函數調用-返回過程。這樣可以避免函數調用的開銷,提高程序的性能。
inline int square(int x)
{return x * x;
}
2、工作原理
內聯函數的核心思想是 在編譯器將函數調用處的代碼直接替換為函數體,類似于代碼的復制粘貼。 → 空間換時間的思想
這樣,避免了函數調用和返回的開銷,但也可能會增加代碼的體積。編譯器會在合適的情況下自動進行內聯,不過也可以使用 inline 關鍵字來顯式指示。
3、優勢
-
a. 減少函數調用開銷: 可以大幅減少函數調用時的開銷,特別是對于短小、需要頻繁調用的函數
-
b. 提高程序性能: 能夠在一定程度上減少函數調用的開銷,從而提高程序的執行速度。
-
c. 代碼可讀性: 將函數體直接嵌入到調用處,使代碼更加緊湊,特別是對于簡單的計算型函數。
4、注意事項
-
a. 適用范圍: 內聯函數適用于函數體簡單且函數調用頻繁的情況。對于復雜的函數體,內聯可能會導致代碼體積增大,影響緩存效率。
-
b. 編譯器決策: 編譯器會根據代碼的復雜度和上下文來決定是否內聯函數。可以使用編譯器指示來強制內聯,但也需要權衡代碼大小和性能。
-
c. 大型函數不適合內聯: 大型函數的內聯可能會導致代碼膨脹,甚至適得其反。在這種情況下,更適合使用傳統的函數調用方式。
5、內聯函數與編譯器優化
現代編譯器在優化代碼時會考慮是否將函數內聯。然而,編譯器的優化決策可能因編譯器版本、編譯選項和具體代碼而異。因此,我們應該了解編譯器的優化行為,可以使用編譯器特定的指示來控制內聯行為~~

 的使用及場景)

)









)





