
一、說明
????????眾所周知,變壓器架構是自然語言處理(NLP)領域的突破。它克服了 seq-to-seq 模型(如 RNN 等)無法捕獲文本中的長期依賴性的局限性。變壓器架構被證明是革命性架構(如 BERT、GPT 和 T5 及其變體)的基石。正如許多人所說,NLP正處于黃金時代,說變壓器模型是一切開始的地方并沒有錯。
二、對變壓器架構的需求
????????如前所述,需求是發明之母。傳統的 seq-to-seq 模型在處理長文本時并不好。這意味著模型在處理輸入序列的后半部分時,往往會忘記輸入序列前半部分的學習。這種信息丟失是不可取的。
????????盡管像 LSTM 和 GRU 這樣的門控架構通過丟棄在記住重要信息的過程中無用的信息,在處理長期依賴關系方面表現出一些改進,但這仍然不夠。世界需要更強大的東西,2015年,Bahdanau等人引入了“注意力機制”。?它們與RNN / LSTM結合使用,以模仿人類行為,專注于選擇性事物,而忽略其余事物。Bahdanau建議為句子中的每個單詞分配相對重要性,以便模型專注于重要的單詞而忽略其余單詞。它被認為是對神經機器翻譯任務的編碼器-解碼器模型的巨大改進,很快,注意力機制的應用也在其他任務中推廣。
變壓器模型時代
????????變壓器模型完全基于一種注意力機制,也稱為“自我注意”。這種架構在 2017 年的論文“注意力是你所需要的一切”中向世界介紹。它由編碼器-解碼器架構組成。
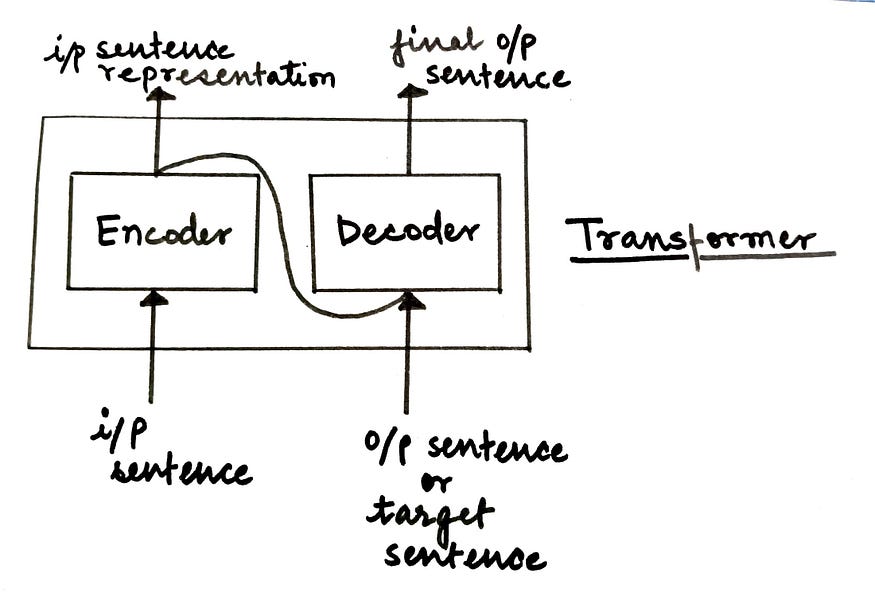
無花果。高級轉換器模型體系結構(來源:作者)
在高層次上,
- 編碼器負責接受輸入的句子并將其轉換為隱藏的表示形式,丟棄所有無用的信息。
- 解碼器接受此隱藏表示形式并嘗試生成目標句子。
在本文中,我們將深入研究變壓器模型的編碼器組件的詳細細分。在下一篇文章中,我們將詳細介紹解碼器組件。讓我們開始吧!
三、變壓器編碼器
????????變壓器的編碼器塊由一堆按順序工作的N個編碼器組成。一個編碼器的輸出是下一個編碼器的輸入,依此類推。最后一個編碼器的輸出是饋送到解碼器塊的輸入句子的最終表示形式。

無花果。帶堆疊編碼器的Enoder模塊(來源:作者)
如下圖所示,每個編碼器塊可以進一步分成兩個組件。

? ? ? ? 無花果。編碼器層的組件(來源:作者)
????????讓我們逐一詳細研究這些組件中的每一個,以了解編碼器塊的工作原理。編碼器模塊中的第一個組成部分是多頭注意力,但在我們進入細節之前,讓我們先了解一個基本概念:自我注意。
3. 1 自我注意機制
????????每個人腦海中可能出現的第一個問題:注意力和自我注意力是不同的概念嗎??是的,他們是。(咄!
????????傳統上,注意力機制是為神經機器翻譯任務而存在的,如上一節所述。因此,本質上應用了注意力機制來映射源句和目標句。當 seq-to-seq 模型逐個令牌執行翻譯任務時,注意機制可幫助我們在為目標句子生成標記 x 時識別源句子中的哪些標記需要更多關注。為此,它利用編碼器和解碼器的隱藏狀態表示來計算注意力分數,并根據這些分數生成上下文向量作為解碼器的輸入。如果您想了解有關注意力機制的更多信息,請跳到這篇文章(精彩的解釋!
????????回到自我注意,主要思想是計算注意力分數,同時將源句子映射到自身。如果你有這樣的句子,
“男孩沒有過馬路,因為它太寬了。
????????我們人類很容易理解上面句子中的“它”一詞指的是“道路”,但是我們如何使我們的語言模型也理解這種關系呢?這就是自我關注的地方!
在高層次上,將句子中的每個單詞與句子中的每個其他單詞進行比較,以量化關系并理解上下文。出于表示目的,您可以參考下圖。
讓我們詳細看看這種自我注意是如何計算的(真實)。
- 為輸入句子生成嵌入
查找所有單詞的嵌入并將它們轉換為輸入矩陣。這些嵌入可以通過簡單的標記化和獨熱編碼生成,也可以通過嵌入算法(如BERT等)生成。輸入矩陣的維度將等于句子長度 x 嵌入維度。我們稱此輸入矩陣為 X?以供將來參考。
- 將輸入矩陣轉換為Q,K和V
為了計算自我注意,我們需要將X(輸入矩陣)轉換為三個新矩陣:
- 查詢 (Q)- 鍵 (K)- 值 (V)
?
為了計算這三個矩陣,我們將隨機初始化三個權重矩陣,即Wq,Wk和Wv。輸入矩陣X將與這些權重矩陣Wq,Wk和Wv相乘,分別獲得Q,K和V的值。在此過程中將學習權重矩陣的最佳值,以獲得更準確的Q,K和V值。
- 計算 Q 和 K 轉置的點積
從上圖中,我們可以暗示 qi、ki 和 vi 表示句子中第 i 個單詞的 Q、K 和 V 的值。

無花果。Q 和 K 轉置的點積示例(來源:作者)
輸出矩陣的第一行將告訴您由 q1 表示的 word1 如何與使用點積的句子中的其余單詞相關。點積的值越高,單詞越相關。為了直觀地了解計算此點積的原因,您可以在信息檢索方面理解 Q(查詢)和 K(鍵)矩陣。所以在這里,
- Q 或查詢 = 您正在搜索的術語
- K 或 Key = 搜索引擎中的一組關鍵字,與 Q 進行比較和匹配。
- 縮放點積
與上一步一樣,我們正在計算兩個矩陣的點積,即執行乘法運算,該值有可能爆炸。為了確保這種情況不會發生并且梯度穩定,我們將 Q 和 K 轉置的點積除以嵌入維度 (dk) 的平方根。
- 使用 softmax 規范化值
使用 softmax 函數進行歸一化將產生介于 0 和 1 之間的值。具有高比例點積的單元格將進一步升高,而低值將減少,使匹配的單詞對之間的區別更加清晰。生成的輸出矩陣可以視為分數矩陣S。
- 計算注意力矩陣 Z
????????將值矩陣或V乘以從上一步獲得的分數矩陣S,以計算注意力矩陣Z。
????????但是等等,為什么要乘法?
????????假設 Si = [0.9, 0.07, 0.03] 是句子中第 i 個單詞的分數矩陣值。將此向量與 V 矩陣相乘以計算 Zi(第 i 個單詞的注意力矩陣)。
Zi = [0.9 * V1 + 0.07 * V2 + 0.03 * V3]
????????我們是否可以說,為了理解第 i 個單詞的上下文,我們應該只關注 word1(即 V1),因為注意力分數值的 90% 來自 V1?我們可以清楚地定義重要的單詞,在這些單詞中,應該更加注意理解第i個單詞的上下文。
????????因此,我們可以得出結論,一個詞在Zi表示中的貢獻越高,單詞之間的批判性和相關性就越大。
????????現在我們知道了如何計算自我注意力矩陣,讓我們了解多頭注意力機制的概念。
3.2 多頭注意力機制
????????如果您的分數矩陣偏向于特定的單詞表示,會發生什么?它會誤導您的模型,結果不會像我們預期的那樣準確。讓我們看一個例子來更好地理解這一點。
????????S1:“一切都很好”
????????Z(井) = 0.6 * V(全部) + 0.0 * v(是) + 0.4 * V(井)
????????S2:“狗吃了食物,因為它餓了”
????????Z(它) = 0.0 * V(的) + 1.0 * V(狗) + 0.0 * V(吃) + ...... + 0.0 * V(饑餓)
????????在 S1 情況下,在計算 Z(well) 時,對 V(all) 給予了更多的重要性。它甚至比V(好吧)本身還要多。無法保證這有多準確。
????????在 S2 的情況下,在計算 Z(it) 時,所有的重要性都給了 V(dog),而其余單詞的分數也是 0.0,包括 V(it)。這看起來可以接受,因為“it”這個詞是模棱兩可的。將它更多地與另一個詞聯系起來而不是將這個詞本身聯系起來是有意義的。這就是計算自我注意力的全部目的。處理輸入句子中歧義單詞的上下文。
????????換句話說,我們可以說,如果當前單詞是模棱兩可的,那么在計算自我注意時可以更加重視其他單詞,但在其他情況下,這可能會對模型產生誤導。那么,我們現在該怎么辦?
????????如果我們計算多個注意力矩陣而不是計算一個注意力矩陣并從中導出最終的注意力矩陣會怎樣?
????????這正是多頭注意力的全部意義所在!我們計算注意力矩陣z1,z2,z3,.....,zm的多個版本,并將它們連接起來以得出最終的注意力矩陣。這樣我們就可以對自己的注意力矩陣更有信心。
????????轉到下一個重要概念,
3.3 位置編碼
????????在seq-to-seq模型中,輸入的句子被逐字輸入到網絡,這允許模型跟蹤單詞相對于其他單詞的位置。
????????但在變壓器模型中,我們遵循不同的方法。它們不是逐字逐句地輸入,而是并行饋送,這有助于減少訓練時間和學習長期依賴性。但是使用這種方法,單詞順序就丟失了。但是,要正確理解句子的含義,詞序非常重要。為了克服這個問題,引入了一種稱為“位置編碼”(P)的新矩陣。
????????該矩陣 P 與輸入矩陣 X 一起發送,以包含與詞序相關的信息。出于顯而易見的原因,X 和 P 矩陣的維度是相同的。
????????為了計算位置編碼,使用下面給出的公式。
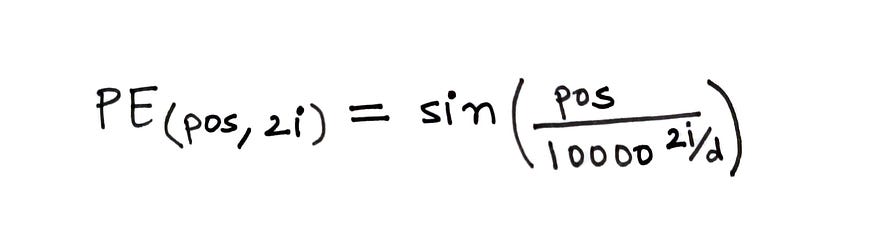
? ? ? ? fig。計算位置編碼的公式(來源:作者)
在上面的公式中,
- pos?= 單詞在句子中的位置
- d?= 字/標記嵌入的維度
- i?= 表示嵌入中的每個維度
在計算中,d 是固定的,但 pos 和 i 會有所不同。如果 d=512,則 i ∈ [0, 255],因為我們取 2i。
如果您想了解更多信息,本視頻將深入介紹位置編碼。
轉換器神經網絡可視化指南 — (第 1 部分)位置嵌入
我正在使用上述視頻中的一些視覺效果來用我的話來解釋這個概念。

無花果。位置編碼向量表示(來源:作者)
上圖顯示了位置編碼向量的示例以及不同的變量值。

無花果。具有常數 i 和 d 的位置編碼向量(來源:作者)
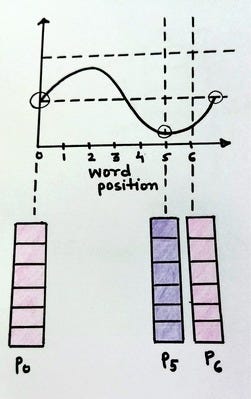
fig。具有常數 i 和 d 的位置編碼向量(來源:作者)
上圖顯示了如果 i 是常量并且只有?pos 變化,PE(pos, 2i)?的值將如何變化。眾所周知,正弦波是一個周期函數,傾向于在固定間隔后重復。我們可以看到 pos = 0 和 pos = 6 的編碼向量是相同的。這是不可取的,因為我們需要不同的位置編碼向量來表示不同的 pos 值。
這可以通過改變正弦波的頻率來實現。

無花果。具有不同 pos 和 i 的位置編碼向量(來源:作者)
隨著i的值變化,正弦波的頻率也隨之變化,導致不同的波,因此,導致每個位置編碼向量的值不同。這正是我們想要實現的目標。
位置編碼矩陣(P)被添加到輸入矩陣(X)并饋送到編碼器。
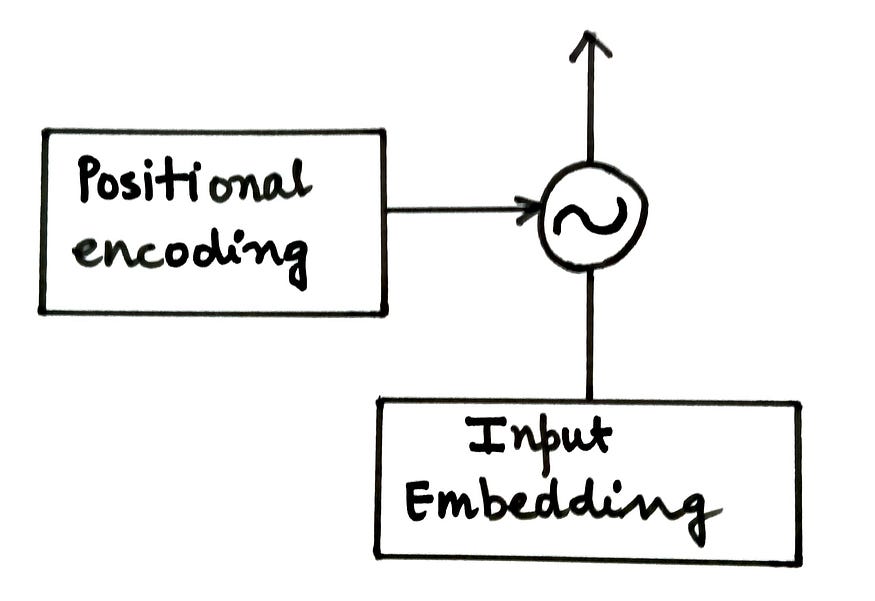
無花果。將位置編碼添加到輸入嵌入(來源:作者)
編碼器的下一個組件是前饋網絡。
3.4 前饋網絡
????????編碼器塊中的這個子層是具有兩個密集層和 ReLU 激活的經典神經網絡。它接受來自多頭注意力層的輸入,對同一層執行一些非線性變換,最后生成上下文化向量。全連接層負責考慮每個注意力頭并從中學習相關信息。由于注意力向量彼此獨立,因此它們可以以并行方式傳遞到變壓器網絡。
????????編碼器塊的最后一個也是最后一個組件是Add&Norm組件。
3.5 添加和規范組件
這是一個殘差層,然后是層歸一化。殘差層確保在處理過程中不會丟失與子層輸入相關的重要信息。而規范化層可促進更快的模型訓練并防止值發生大量變化。
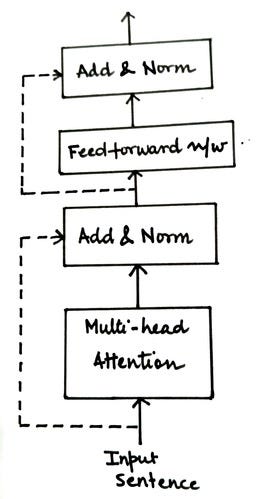
無花果。包含添加和規范層的編碼器組件(來源:作者)
????????在編碼器中,有兩個添加層和規范層:
- 將多頭注意力子層的輸入連接到其輸出
- 將前饋網絡子圖層的輸入連接到其輸出
????????至此,我們總結編碼器的內部工作。總結本文,讓我們快速回顧一下編碼器使用的步驟:
- 生成輸入句子的嵌入或標記化表示。這將是我們的輸入矩陣 X。
- 生成位置嵌入以保留與輸入句子的詞序相關的信息,并將其添加到輸入矩陣 X 中。
- 隨機初始化三個矩陣:Wq,Wk和Wv,即查詢,鍵和值的權重。這些權重將在變壓器模型訓練期間更新。
- 將輸入矩陣X與Wq,Wk和Wv中的每一個相乘,以生成Q(查詢),K(鍵)和V(值)矩陣。
- 計算 Q 和 K 轉置的點積,通過將其除以 dk 的平方根或嵌入維數來縮放乘積,最后使用 softmax 函數對其進行歸一化。
- 通過將 V 或值矩陣乘以 softmax 函數的輸出來計算注意力矩陣 Z。
- 將此注意力矩陣傳遞給前饋網絡以執行非線性轉換并生成上下文化嵌入。
四、后記?
????????在下一篇文章中,我們將了解轉換器模型的解碼器組件的工作原理。這就是本文的全部內容。我希望你覺得它有用。如果你這樣做了,請不要忘記鼓掌并與您的朋友分享。
 研究(Matlab代碼實現))



)


霍夫線檢測+找出輪廓和外接矩形+改進旋轉)
內嵌網頁以實現WEB配網以及數據交互)



)



在linux上(CentOS7)部署與啟動)


