一.lucene原理
??? Lucene 是apache軟件基金會一個開放源代碼的全文檢索引擎工具包,是一個全文檢索引擎的架構,提供了完整的查詢引擎和索引引擎,部分文本分析引擎。它不是一個完整的搜索應用程序,而是為你的應用程序提供索引和搜索功能。lucene 能夠為文本類型的數據建立索引,所以你只要能把你要索引的數據格式轉化的文本的,Lucene 就能對你的文檔進行索引和搜索。比如你要對一些 HTML 文檔,PDF 文檔進行索引的話你就首先需要把 HTML 文檔和 PDF 文檔轉化成文本格式的,然后將轉化后的內容交給 Lucene 進行索引,然后把創建好的索引文件保存到磁盤或者內存中,最后根據用戶輸入的查詢條件在索引文件上進行查詢。
搜索應用程序和 Lucene?之間的關系,也反映了利用 Lucene 構建搜索應用程序的流程:
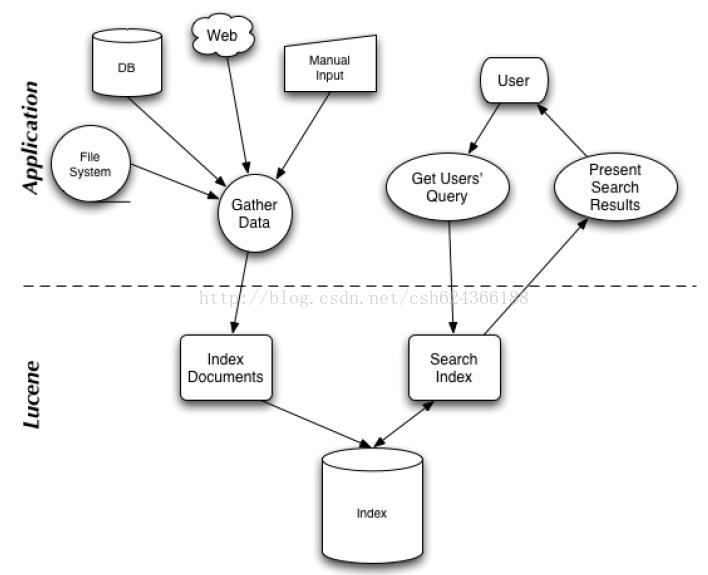
二. 索引和搜索
?? 索引是現代搜索引擎的核心,建立索引的過程就是把源數據處理成非常方便查詢的索引文件的過程。為什么索引這么重要呢,試想你現在要在大量的文檔中搜索含有某個關鍵詞的文檔,那么如果不建立索引的話你就需要把這些文檔順序的讀入內存,然后檢查這個文章中是不是含有要查找的關鍵詞,這樣的話就會耗費非常多的時間,想想搜索引擎可是在毫秒級的時間內查找出要搜索的結果的。這就是由于建立了索引的原因,你可以把索引想象成這樣一種數據結構,他能夠使你快速的隨機訪問存儲在索引中的關鍵詞,進而找到該關鍵詞所關聯的文檔。Lucene?采用的是一種稱為反向索引(inverted index)的機制。反向索引就是說我們維護了一個詞 / 短語表,對于這個表中的每個詞 / 短語,都有一個鏈表描述了有哪些文檔包含了這個詞 / 短語。這樣在用戶輸入查詢條件的時候,就能非常快的得到搜索結果。搜索引擎首先會對搜索的關鍵詞進行解析,然后再在建立好的索引上面進行查找,最終返回和用戶輸入的關鍵詞相關聯的文檔。對于中文用戶來說,最關心的問題是其是否支持中文的全文檢索。由于Lucene良好架構設計,對中文的支持只需對其語言詞法分析接口進行擴展就能實現對中文檢索的支持。
三. 索引步驟
- 獲取內容:?Lucene本身沒有提供獲取內容的工具或者組件,內容是要開發者自己提供相應的程序。這一步包括使用網絡爬蟲或蜘蛛程序來搜索和界定需要索引的內容。當然,數據來源可能包括數據庫、分布式文件系統、本地xml等等。lucene作為一款核心搜索庫,不提供任何功能來實現內容獲取。目前有大量的開源爬蟲軟件可以實現這個功能,例如:Solr,lucene的子項;Nutch,apache項目,包含大規模的爬蟲工具,抓取和分辨web站點數據;Grub,比較流行的開源web爬蟲工具;Heritrix,一款開源的Internet文檔搜索程序;Aperture,支持從web站點、文件系統和郵箱中抓取,并解析和索引其中的文本數據。
- 建立文檔:獲取原始內容后,需要對這些內容進行索引,必須將這些內容轉換成部件(文檔)。文檔主要包括幾個帶值的域,比如標題,正文,摘要,作者和鏈接。如果文檔和域比較重要的話,還可以添加權值。設計完方案后,需要將原始內容中的文本提取出來寫入各個文檔,這一步可以使用文檔過濾器,開源項目如Tika,實現很好的文檔過濾。如果要獲取的原始內容存儲于數據庫中,有一些項目通過無縫鏈接內容獲取步驟和文檔建立步驟就能輕易地對數據庫表進行航所以操作和搜索操作,例如DBSight,Hibernate Search,LuSQL,Compass和Oracle/Lucene集成項目。
- 文檔分析:?搜索引擎不能直接對文本進行索引:必須將文本分割成一系列被稱為語匯單元的獨立的原子元素。每一個語匯單元能大致與語言中的“單詞”對應起來,這個步驟決定文檔中的文本域如何分割成語匯單元系列。lucene提供了大量內嵌的分析器可以輕松控制這步操作。
- 文檔索引:?將文檔加入到索引列表中。Lucene在這一步驟中提供了強檔的API,只需簡單調用提供的幾個方法就可以實現出文檔索引的建立。為了提供好的用戶體驗,索引是必須要處理好的一環:在設計和定制索引程序時必須圍繞如何提高用戶的搜索體驗來進行。
四. 搜索組件
? 搜索組件即為輸入搜索短語,然后進行分詞,然從索引中查找單詞,從而找到包含該單詞的文檔。搜索質量由查準率和查全率來衡量。搜索組件主要包括以下內容:
- 用戶搜索界面:主要是和用戶進行交互的頁面,也就是呈現在瀏覽器中能看到的東西,這里主要考慮的就是頁面UI設計了。一個良好的UI設計是吸引用戶的重要組成部分。
- 建立查詢:建立查詢主要是指用戶輸入所要查詢的短語,以普通HTML表單或者ajax的方式提交到后臺服務器端。然后把詞語傳遞給后臺搜索引擎。這就是一個簡單建立查詢的過程。
- 搜索查詢:即為查詢檢索索引然后返回與查詢詞語匹配的文檔。然后把返回來的結構按照查詢請求來排序。搜索查詢組件覆蓋了搜索引擎中大部分的復雜內容。
- 展現結果:所謂展現結果,和第一個搜索界面類似。都是一個與用戶交互的前端展示頁面,作為一個搜索引擎,用戶體驗永遠是第一位。其中前端展示在用戶體現上占據了重要地位。
五. 官網實例解析
Lucene的使用主要體現在兩個步驟:
- 創建索引,通過IndexWriter對不同的文件進行索引的創建,并將其保存在索引相關文件存儲的位置中。
- 通過索引查尋關鍵字相關文檔。
下面針對官網上面給出的一個例子,進行分析:
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_CURRENT);// Store the index in memory:Directory directory = new RAMDirectory();// To store an index on disk, use this instead://Directory directory = FSDirectory.open("/tmp/testindex");IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_CURRENT, analyzer);IndexWriter iwriter = new IndexWriter(directory, config);Document doc = new Document();String text = "This is the text to be indexed.";doc.add(new Field("fieldname", text, TextField.TYPE_STORED));iwriter.addDocument(doc);iwriter.close();// Now search the index:DirectoryReader ireader = DirectoryReader.open(directory);IndexSearcher isearcher = new IndexSearcher(ireader);// Parse a simple query that searches for "text":QueryParser parser = new QueryParser(Version.LUCENE_CURRENT, "fieldname", analyzer);Query query = parser.parse("text");ScoreDoc[] hits = isearcher.search(query, null, 1000).scoreDocs;assertEquals(1, hits.length);// Iterate through the results:for (int i = 0; i < hits.length; i++) {Document hitDoc = isearcher.doc(hits[i].doc);assertEquals("This is the text to be indexed.", hitDoc.get("fieldname"));}ireader.close();directory.close();
索引的創建
首先,我們需要定義一個詞法分析器。
比如一句話,“我愛我們的中國!”,如何對他拆分,扣掉停頓詞“的”,提取關鍵字“我”“我們”“中國”等等。這就要借助的詞法分析器Analyzer來實現。這里面使用的是標準的詞法分析器,如果專門針對漢語,還可以搭配paoding,進行使用。
1 Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_CURRENT);參數中的Version.LUCENE_CURRENT,代表使用當前的Lucene版本,本文環境中也可以寫成Version.LUCENE_40。
第二步,確定索引文件存儲的位置,Lucene提供給我們兩種方式:
1 本地文件存儲?
Directory directory = FSDirectory.open("/tmp/testindex");2 內存存儲
Directory directory = new RAMDirectory();可以根據自己的需要進行設定。
第三步,創建IndexWriter,進行索引文件的寫入。
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_CURRENT, analyzer);
IndexWriter iwriter = new IndexWriter(directory, config);這里的IndexWriterConfig,據官方文檔介紹,是對indexWriter的配置,其中包含了兩個參數,第一個是目前的版本,第二個是詞法分析器Analyzer。
第四步,內容提取,進行索引的存儲。
Document doc = new Document();
String text = "This is the text to be indexed.";
doc.add(new Field("fieldname", text, TextField.TYPE_STORED));
iwriter.addDocument(doc);
iwriter.close();第一行,申請了一個document對象,這個類似于數據庫中的表中的一行。
第二行,是我們即將索引的字符串。
第三行,把字符串存儲起來(因為設置了TextField.TYPE_STORED,如果不想存儲,可以使用其他參數,詳情參考官方文檔),并存儲“表明”為"fieldname".
第四行,把doc對象加入到索引創建中。
第五行,關閉IndexWriter,提交創建內容。
這就是索引創建的過程。
關鍵字查詢:
第一步,打開存儲位置
DirectoryReader ireader = DirectoryReader.open(directory);第二步,創建搜索器
IndexSearcher isearcher = new IndexSearcher(ireader);第三步,類似SQL,進行關鍵字查詢

QueryParser parser = new QueryParser(Version.LUCENE_CURRENT, "fieldname", analyzer);
Query query = parser.parse("text");
ScoreDoc[] hits = isearcher.search(query, null, 1000).scoreDocs;
assertEquals(1, hits.length);
for (int i = 0; i < hits.length; i++) {Document hitDoc = isearcher.doc(hits[i].doc);assertEquals("This is the text to be indexed.",hitDoc.get("fieldname"));
}這里,我們創建了一個查詢器,并設置其詞法分析器,以及查詢的“表名“為”fieldname“。查詢結果會返回一個集合,類似SQL的ResultSet,我們可以提取其中存儲的內容。
關于各種不同的查詢方式,可以參考官方手冊,或者推薦的PPT
第四步,關閉查詢器等。
ireader.close();
directory.close();自己實現的一個小實例:對一個文件夾內的內容進行索引的創建,并根據關鍵字篩選文件,并讀取其中的內容。
?
package cn.lnu.edu.yxk;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;import jxl.Cell;
import jxl.Sheet;
import jxl.Workbook;
import jxl.read.biff.BiffException;import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.poi.hwpf.HWPFDocument;
import org.apache.poi.hwpf.usermodel.Range;
/*** 對一個文件夾內的內容進行索引的創建,并根據關鍵字篩選文件,讀取其中的內容。* @author yxk**/
public class IndexManager {private static String content = "";//文件里面的內容private static String INDEX_DIR = "D:\\test\\luceneIndex";//索引創建的存儲目錄private static String DATA_DIR = "D:\\test\\luceneData";//文件夾的目錄private static Analyzer analyzer = null;//詞法分析器private static Directory directory = null;//索引文件存儲的位置private static IndexWriter indexWriter = null;//創建索引器,索引文件的寫入/*** 創建當前文件目錄的索引* @param path當前目錄的文件* @return 返回是否創建成功*/public static Boolean createIndex(String path) {Date date1 = new Date();//創建需要的時間List<File> files = listFile(path);// 獲取指定目錄下得所有符合條件的文件// 獲取文件的內容for (File file : files) {content = "";//通過文件類型獲取文件的內容String type = file.getName().substring(file.getName().lastIndexOf(".") + 1);if ("txt".equalsIgnoreCase(type)) {content += txt2String(file);} else if ("doc".equalsIgnoreCase(type)) {content += doc2String(file);} else if ("xls".equalsIgnoreCase(type)) {content += xls2String(file);}System.out.println("name"+file.getName());System.out.println("path"+file.getPath());//System.out.println(file.getName().getBytes().toString());System.out.println();try {analyzer = new StandardAnalyzer();//詞法分析器directory = FSDirectory.open(new File(INDEX_DIR).toPath());//索引創建存儲的位置// System.out.println("ssss"// + new File(INDEX_DIR).toPath().toString());//自動創建索引目錄File indexFile = new File(INDEX_DIR);if (!indexFile.exists()) {indexFile.mkdirs();}//索引文件的寫入IndexWriterConfig config = new IndexWriterConfig(analyzer);indexWriter = new IndexWriter(directory, config);/** 內容提取,進行索引的存儲*///申請了一個document對象,這個類似于數據庫中的表中的一行。Document document = new Document();//把字符串存儲起來(因為設置了TextField.TYPE_STORED,如果不想存儲,可以使用其他參數,詳情參考官方文檔),并存儲“表明”為"fieldname".document.add(new org.apache.lucene.document.TextField("filename", file.getName(), Field.Store.YES));//文件名索引創建document.add(new org.apache.lucene.document.TextField("content", content, Field.Store.YES));//文件內容索引創建document.add(new org.apache.lucene.document.TextField("path",file.getPath(), Field.Store.YES));//文件路徑索引的創建//把document對象加入到索引創建中indexWriter.addDocument(document);//關閉IndexWriter,提交創建內容。indexWriter.commit();closeWriter();} catch (IOException e) {e.printStackTrace();}content = "";}Date date2 = new Date();System.out.println("創建索引-----耗時:" + (date2.getTime() - date1.getTime())+ "ms\n");return true;}/*** 查詢索引,返回符合條件的文件* * @param 查詢的字符串* @return 符合條件的結果* @throws IOException*/public static void serarchIndex(String text) {Date date1 = new Date();try {//打開存儲位置directory = FSDirectory.open(new File(INDEX_DIR).toPath());analyzer = new StandardAnalyzer();DirectoryReader ireader = DirectoryReader.open(directory);//創建搜索器IndexSearcher isearcher = new IndexSearcher(ireader);/** 類似SQL,進行關鍵字查詢*/QueryParser parser = new QueryParser("content", analyzer);Query query = parser.parse(text);//創建了一個查詢器,并設置其詞法分析器,以及查詢的“表名“為”fieldname“。查詢結果會返回一個集合,類似SQL的ResultSet,我們可以提取其中存儲的內容。ScoreDoc[] hits = isearcher.search(query, 1000).scoreDocs;for (int i = 0; i < hits.length; i++) {Document hitDoc = isearcher.doc(hits[i].doc);System.out.println("-----------");System.out.println(hitDoc.get("filename"));System.out.println(hitDoc.get("content"));System.out.println(hitDoc.get("path"));System.out.println("------------");}//關閉查詢器ireader.close();directory.close();} catch (IOException e) {e.printStackTrace();} catch (ParseException e) {e.printStackTrace();}Date date2 = new Date();System.out.println("關鍵字查詢-----耗時:" + (date2.getTime() - date1.getTime())+ "ms\n");}/*** * @throws IOException*/private static void closeWriter() throws IOException {if (indexWriter != null)indexWriter.close();}/*** 讀取xls文件內容,引入jxl.jar類型的包* @param file* @return 返回內容*/private static String xls2String(File file) {String result = "";try {FileInputStream fis = new FileInputStream(file);StringBuilder sb = new StringBuilder();jxl.Workbook rwb = Workbook.getWorkbook(fis);Sheet[] sheet = rwb.getSheets();for (int i = 0; i < sheet.length; i++) {Sheet rs = rwb.getSheet(i);for (int j = 0; i < rs.getRows(); j++) {Cell[] cells = rs.getRow(j);for (int k = 0; k < cells.length; k++) {sb.append(cells[k].getContents());}}}fis.close();result += sb.toString();} catch (FileNotFoundException e) {e.printStackTrace();} catch (BiffException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}return result;}/*** 讀取doc類型文件的內容,通過poi.jar* @param file的類型* @return 返回文件的內容*/private static String doc2String(File file) {String result = "";try {FileInputStream fis = new FileInputStream(file);//文件輸入流HWPFDocument document = new HWPFDocument(fis);Range range = document.getRange();result += range.text();fis.close();} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}return result;}/*** 讀取txt文件的內容* * @param file想要讀取的文件類型* @return 返回文件內容*/private static String txt2String(File file) {String result = "";try {BufferedReader reader = new BufferedReader(new FileReader(file));String s = "";while ((s = reader.readLine()) != null) {result += result + "\n" + s;}reader.close();} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}return result;}/*** 過濾當前目錄下得文件* @param path 當前目錄下得文件* @return 返回符合條件的文件*/private static List<File> listFile(String path) {File[] files = new File(path).listFiles();List<File> fileList = new ArrayList<File>();for (File file : files) {if (isTxtFile(file.getName())) {fileList.add(file);}}return fileList;}/*** 判斷是否為目標文件,支持的格式為.txt,.doc,.xls文件格式 如果是文件類型滿足過濾條件,返回true;否則返回false* @param name 根據文件名的后綴* @return 是否符合格式規范*/private static boolean isTxtFile(String name) {if (name.lastIndexOf(".txt") > 0)return true;else if (name.lastIndexOf(".doc") > 0)return true;else if (name.lastIndexOf(".xls") > 0)return true;return false;}public static void main(String[] args) {//創建索引目錄,運行一次,重新創建一次File fileIndex = new File(INDEX_DIR);if (deleteIndex(fileIndex)) {fileIndex.mkdir();} else {fileIndex.mkdir();}//創建索引文件createIndex(DATA_DIR);//通過關鍵字查詢serarchIndex("中華");}/*** 刪除文件目錄下得所有文件* * @param fileIndex 當前索引目錄下得文件* @return 返回是否刪除重新創建*/private static boolean deleteIndex(File fileIndex) {if (fileIndex.isDirectory()) {File[] files = fileIndex.listFiles();for (int i = 0; i < files.length; i++) {deleteIndex(files[i]);}}fileIndex.delete();return true;}}
原文博客出自:http://blog.csdn.net/csh624366188/article/category/895342
和https://www.cnblogs.com/xing901022/p/3933675.html
---------------------
作者:jofjhh
來源:CSDN
原文:https://blog.csdn.net/m0_37913549/article/details/78989078
版權聲明:本文為作者原創文章,轉載請附上博文鏈接!
內容解析By:CSDN,CNBLOG博客文章一鍵轉載插件


簡介)

JavaScript 互操作 —— 更新 document title)







)




——應用服務和數據服務分離)

