2022年5月31日,在CSDN云原生系列在線峰會第6期“K8s大規模應用和深度實踐峰會”,火山引擎資深云原生架構師李玉光分享了《字節跳動大規模K8s集群管理實踐》。

?

字節跳動云原生體系
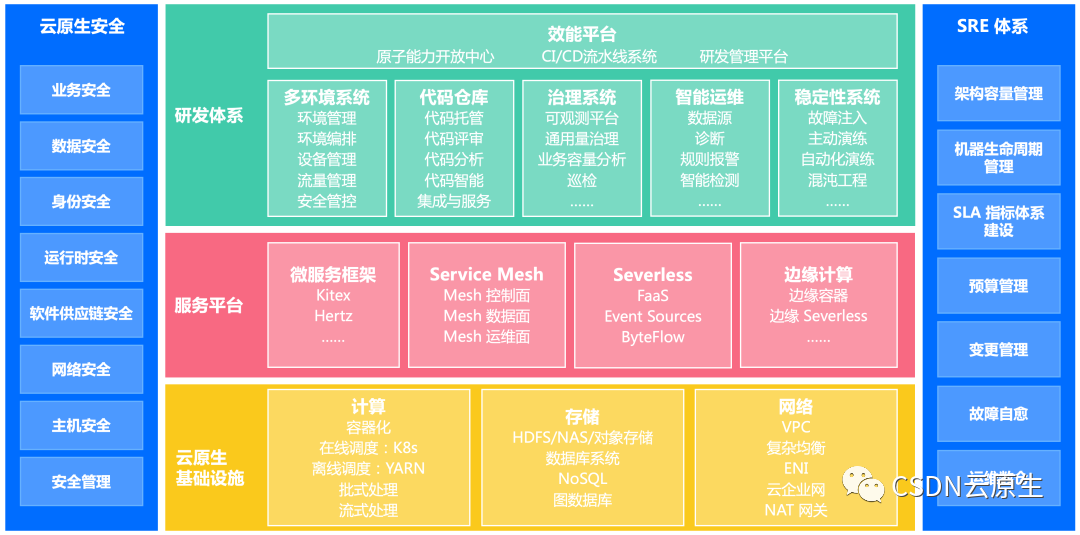
字節跳動內部云原生技術的使用貫穿組織技術體系各層面,整體如下圖所示。
-
研發體系層:包括CI/CD流水線、可觀測平臺、研發效能平臺、混沌工程平臺等。
-
服務平臺層:包括云原生框架體系、服務網格、無服務器計算以及邊緣計算等。
-
基礎設施層:包括容器管理平臺、計算存儲和網絡的PaaS平臺。
-
SRE體系:通過SRE整體能力的建設把研發體系到基礎設施管理流程串聯起來。
-
云原生安全:涵蓋業務安全、身份安全、網絡安全等云原生安全能力。
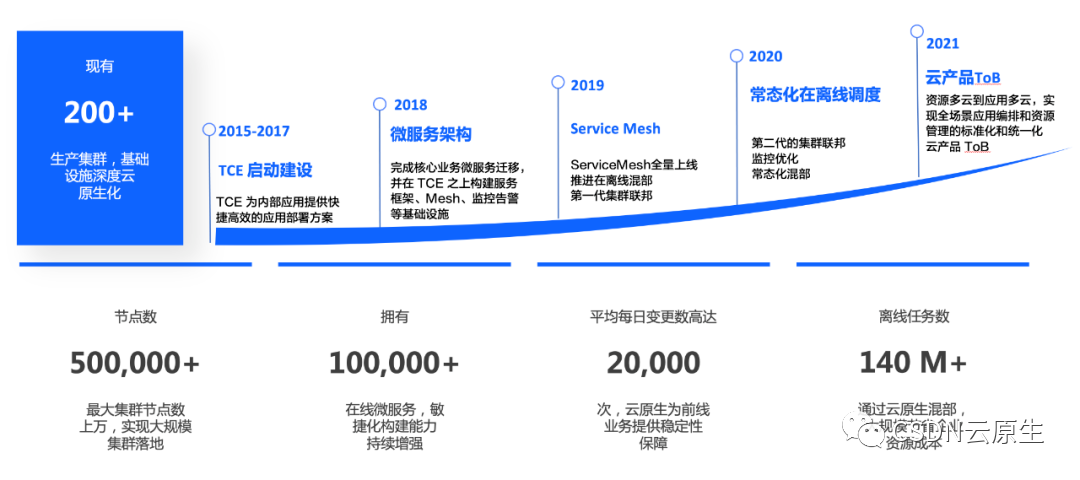
這些能力的建設主要根據業務需求逐步推進,演進過程如下圖所示。
-
2015-2017年:主要業務為今日頭條,面對各種新聞客戶端應用的激烈競爭,敏捷迭代盡快將產品的功能推向市場十分重要。為了提供快捷高效的應用部署方案,公司在2016年啟動TCE平臺的建設。當時TCE專注于服務的生命周期管理,如新建、升級、回滾、高可用、彈性擴展的容器服務,如今TCE發展成龐大的私有云平臺。
-
2018年:啟動了Service Mesh的原型開發。當時字節跳動內部多語言版本造成微服務治理框架不一樣,既無法做到統一管理,又會有很多重復造輪子的工作。為了統一公司內的工具體系,同時啟動了計算PaaS和存儲PaaS的建設,開始統一公司級別的SRE體系和監控中心建設。
-
2019年:公司級服務樹實現統一,后續可以基于服務維度出賬單,以應用視角管理資源。Service Mesh經過開發及試用階段,有了全量推廣。云基礎視角來看,抖音在2018-2020年間發展快速,成本不斷增加,服務器規模體量越來越大,團隊關注重點轉向資源利用率的提升,推進在離線混部架構;為應對大規模集群問題,第一代的集群聯邦解決方案實施。從SRE的視角來看,平臺集成了各種PaaS能力,包括數據、運維、監控等能力,構建了統一的部署監控、報警治理一體化的工具矩陣;“推廣搜”的物理機服務與在線微服務進行全面融合,實現統一容器化調度并達到全量托管。
-
2020年:由于業務天然依賴邊緣渲染,團隊強化了邊緣計算能力;各種底層軟硬件也進行了優化,比如打造智能網卡、自研DPU、優化SSD控制器等;其次,為更好地在離線融合以及解決第一代集群聯邦的問題,團隊構建了第二代的集群聯邦。繼續推進在離線混部架構,通過自研的融合調度器豐富了混部調度能力和資源管控,進一步提升資源調度效率,實現了常態化混部。完成數據庫、緩存等存儲系統云原生化改造。在SRE體系上,由于已經有了工具基礎,會關注如何更快速定位問題,因此進行了底層的容器監控優化,如利用eBPF實現內核級別的監控。同時對容器隔離進行了優化。
-
2021年:除了針對微服務框架、服務治理、編排調度、監控運維等方面架構的繼續優化,最重要的是:云基礎產品開始面向ToB,火山引擎正式推出公有云服務。
截至2021年底,字節跳動已經建設了完善的云原生基礎設施:擁有200多個生產集群,共計50萬節點,容器數超過1000萬;擁有10萬多在線微服務,平均每日變更數達2萬次,離線任務數超過1.4億。

字節跳動大規模K8s混合部署實踐
字節跳動私有云平臺TCE的底層使用K8s作為編排調度的系統,字節內部幾乎所有無狀態服務都以容器的形式部署在TCE上,無狀態服務主要包括各種微服務和算法服務等。隨著業務的增長,TCE上接管的服務數量越來越多,集群規模越來越龐大,導致了資源成本的不斷增長,因此必然要關注集群的整體資源利用率的問題。
為了解決資源利用率的問題,首先要對業務的流量特點進行分析。
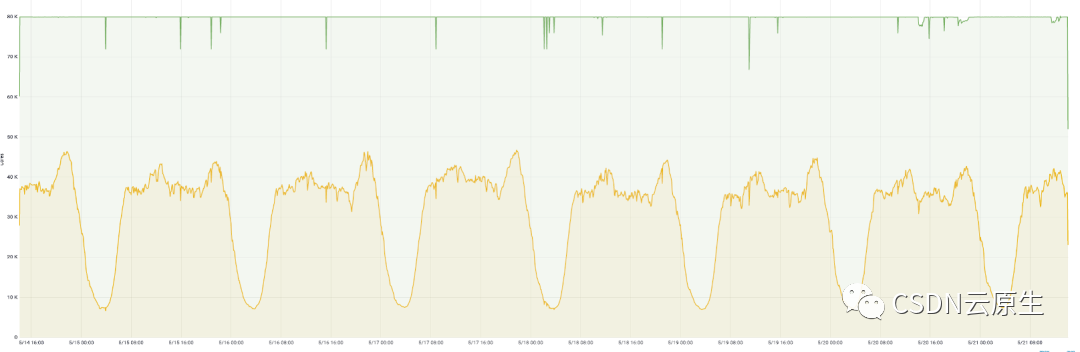
如上圖所示,在線業務的一個特點是每天請求量有明顯波峰波谷;同時,業務會傾向于申請比實際需求更多的資源以確保服務的穩定性,但這也會導致集群的整體資源利用率特別低,造成大量的資源浪費。
解決思路
在線業務動態超售
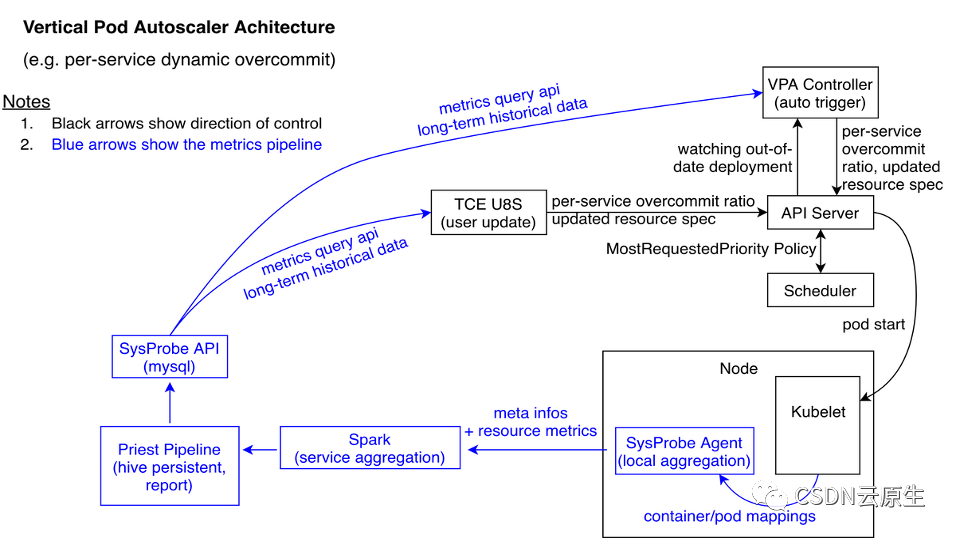
針對上述發現,實際做法是實現在線業務的動態超售。動態超售是指動態控制和調整服務的資源申請量以減少冗余資源,服務級別動態超售的目標是在不影響業務QoS的前提下提升服務的資源利用率。實現方式主要包含以下幾方面。
-
資源控制:通過SysProbe組件,收集實例級別的容器資源利用率Metrics和Pod的meta信息,并將這些推送到Spark里面做聚合分析。之后每次服務上線,業務會通過TCE Platform提交一個DeploymentRequest,包含了業務配置的資源申請,TCE U8S組件會去查詢SysProbe提供的API,根據每個應用的歷史數據計算出其實際需求的資源并作出相應的控制。
-
資源調整:集群里很多長期不升級的服務占用了不少資源,而且資源利用率非常低,但無法通過第一種方式對其調整。因此通過VPA Controller watch所有的deployment,一旦發現有長期沒有更新的deployment,就會主動修改其request并進行更新。
-
彈性伸縮:最后結合Pod的彈性伸縮來回收流量低谷時期的資源,從而大幅提升資源利用率。
在離線業務混部
下一步需要考慮的是如何利用這部分在線業務節省下來的資源。因為所有在線業務的低谷時段幾乎都是吻合的,比如在凌晨之后,一般所有在線APP的使用頻率都會減少,因此不能通過擴容在線業務的方式來消耗這部分資源。但字節內部存在很多離線任務需要大量的計算資源去進行處理,例如視頻轉碼、模型訓練等。這些離線任務對資源的需求與時間無關,天然適合使用在線閑置資源,開啟在離線混部架構,能夠把在線業務的閑置資源出讓給離線業務使用。

字節的大數據業務都是基于Yarn體系的,在線應用和一些AI應用部署在K8s上,最開始的時候我們把Node manager做了一些修改之后和Kubelet一起部署在了K8s的node上。總體來說,整個平臺是由以K8s核心控制面為主的在線編排調度系統,以Yarn為主的離線調度系統,以及SysProbe組件為中心Hybrid Controller構成。離線業務混部示意圖如下:
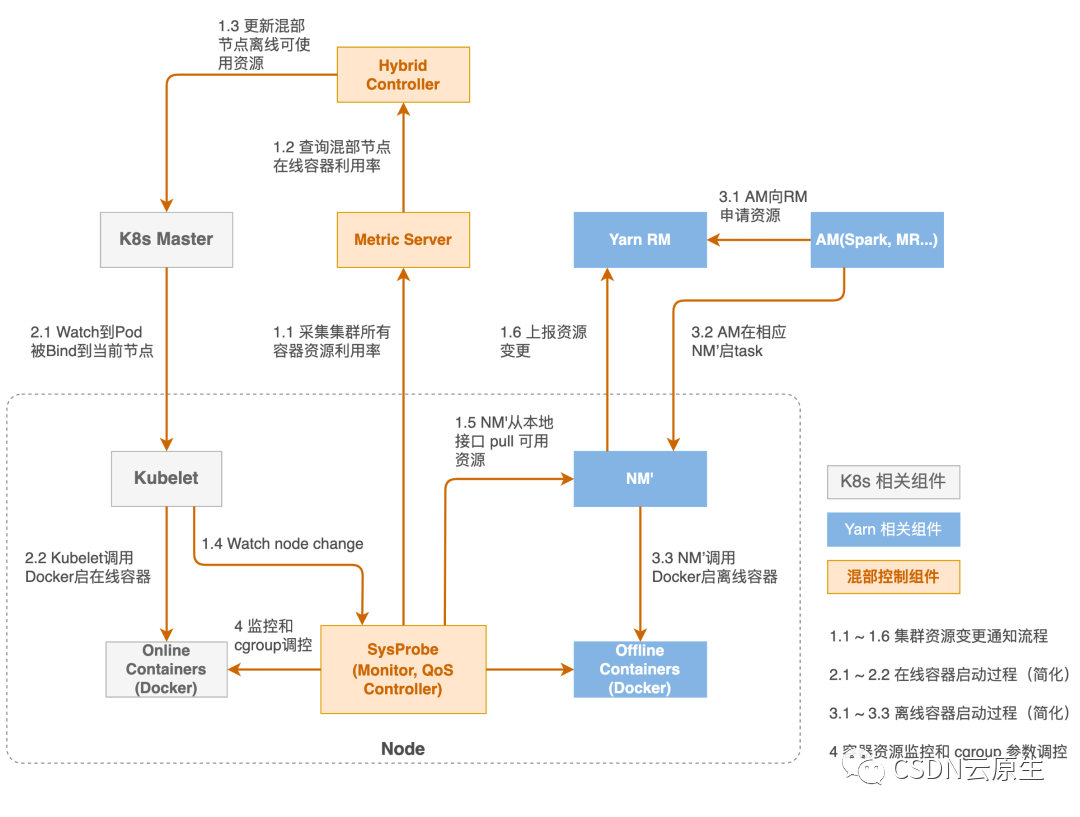
在離線業務混部要實現的效果是:在優先滿足在線微服務需求的前提下,把剩余資源盡可能多地供給離線業務使用;當在線業務需要更多資源時,可以快速地調回離線側的資源。
從具體實現角度來說,通過SysProbe系統監控,獲取單機層面的各種容器的資源使用情況;通過機器學習算法,推導出該集群上可以出讓給離線側去使用的資源;將這些信息傳給Node manager,動態上報到中心的RM進行資源的統一展示。Hybrid Controller主要是負責集群整體的容災降級策略和水位控制相關的事務。
整個調度系統分為三個層面構建:集群層面、節點層面和內核層面,分別承擔了三種資源調度的角色。
-
集群層面:K8s Scheduler和Yarn的ResourceManager負責完成集群層面的調度,把容器調度到合適的節點。
-
節點層面:但當節點層面在線業務發生QoS抖動時,需要做出更快的響應,此時分鐘級的調度響應延遲通常是不能接受的。因此,系統在節點層面進行處理,提供了Sysprobe的QoS Controller組件,動態實時地調整節點的實際資源分配。當在線業務發生QoS抖動,需要更多資源時,能夠快速將離線資源回收回來,實現秒級響應。
-
內核層面:由于SysProbe是處于用戶態的角色,通常也會受到單機層面高負載等異常情況的影響,因此需要在內核級別,比如在CPU的調度器、IO的調度器上做更深度的定制。這樣能夠實現更強的系統層面的能力,更好地兼顧延遲敏感型的在線微服務和吞吐型離線任務對于計算資源和網絡帶寬資源的需求,達到整體效能的最大化。
由此,初步的在離線混部完成,但還有一些需要繼續優化的內容。比如對于系統而言,資源抽象還不夠完整,只有部分類型的離線業務利用了這些不穩定的資源;系統各自獨立,在一個node上既部署了Kubelet負責在線業務,又部署了Node manager負責離線任務,資源管理體系分離,上層平臺獨立建設,底層服務器供給運維分開,導致更大范圍的共池復用比較困難。
統一資源池,常態混部
為應對上述挑戰,新的融合調度器被開發出來。其能統一管理在離線資源,后續也能支持更多資源的管理和更多類型任務的調度,如下圖所示。

首先需要通過K8s管理離線應用,這就需要支持Yarn的Gang Scheduler以及其他調度算法。因此選擇去掉Yarn的Slave節點相關的管控邏輯,將其Resource Manager Operator化;相應的調度邏輯下沉到自研K8s調度器Godel Scheduler,只保留對應的離線作業生命周期管理以及周邊功能,進而實現離在線無縫遷移和并池的能力;將公司所有Yarn上的存量大數據業務無縫遷移至新的調度平臺,來實現在離線資源池的統一。最后,獲取了單集群的在離線統一調度能力后,就可以通過集群聯邦對多個集群的在離線資源進行統一管理。
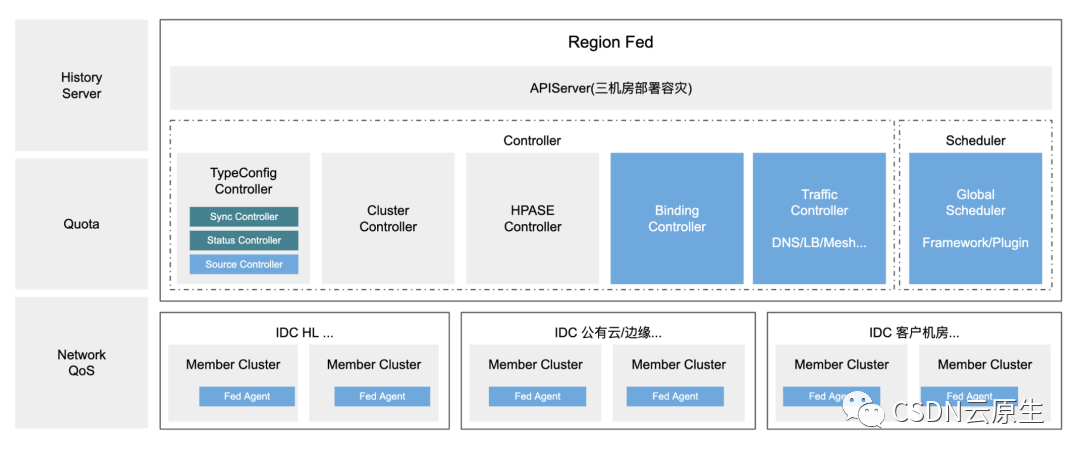
聯邦化:Global Scheduling和Quota
在2019年引入了第一代聯邦系統,實現了超大規模集群管理,提供了以下能力:
-
用戶體驗:通過資源池化,SRE團隊不需要管理自己的集群節點,降低維護成本;集群版本升級在mumber集群層面實現,用戶無感知;
-
自動容災:集群或者機房故障時,自動實現全量容器的遷移;
-
運維效率:支持集群快速升級換代、上線下線;
-
多云多集群:自建IDC和公有云IaaS快速接入。
隨著更大范圍的離線和在線的融合需求,聯邦系統演進到了第二代。第二代聯邦系統的升級主要體現在:
-
輕量級多集群管理:用戶看到的是單集群的視角,又能夠保證member集群層面的資源復用。實現了原生Cluster和Namespace范圍的資源訪問隔離,以及K8s原生對象和CRD對象的創建和訪問的隔離。
-
聯邦化Workload:能夠實現全場景應用聯邦化,一般社區的聯邦方案,通常只能接入有限的負載類型;而字節內部實現了各種離線大數據場景、機器學習場景等業務的統一接入,結合全局的資源管控和優化,能夠實現進一步的調度;同時,方案融合了離線和在線的容災體系,進一步實現整個數據中心層面的資源共享和復用。
調度系統終態視圖
基于上述的調整和升級,調度系統最終演進成如下圖所示的分層架構。
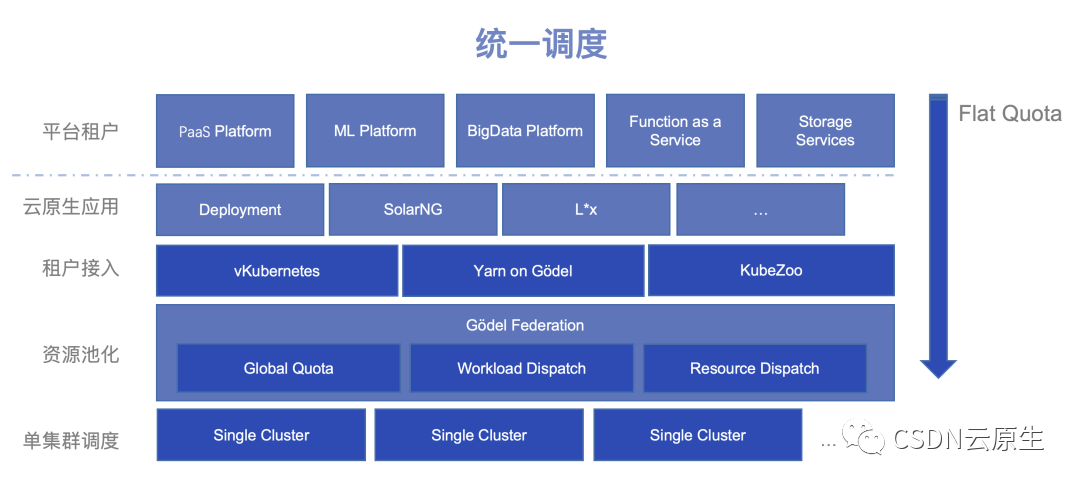
首先,單集群調度層面會運行承載所有的資源,運用統一的調度器、統一的資源管理、統一的隔離能力來實現資源的共享和復用;其次,聯邦層實現整個數據中心層面任務的統一編排調度和資源管理;再對接到上層,實現不同的租戶隔離能力和接入手段;最后,對接上層的PaaS平臺、機器學習平臺和大數據平臺等不同的業務系統。
服務QoS保障
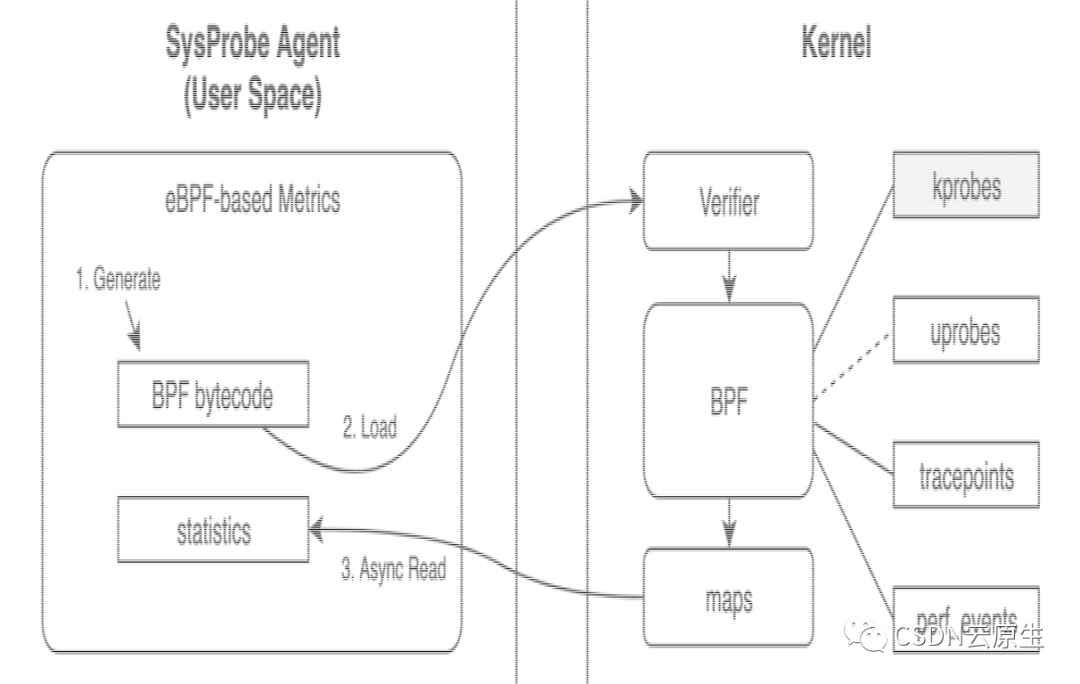
對于大規模的混部集群而言,需要注意的是服務的QoS保障,因此監控非常必要。
-
基于eBPF內核機制,在SysProbe系統中集成了內核監控的能力;
-
在CPU和內存層,復用了Cgroups的數據,同時擴展增加了throttle、組線程數和狀態,以及實例Load等更能反映實例負載真實情況的一些指標;
-
在BlockIO層,通過識別Hook的VFS層關鍵的函數以及系統的調用,實現了準確識別實例的讀寫行為;
-
在網絡IO層,探測服務的Socket級別的連接的狀態,以及實時的SLA,比如SRTT的抖動。
基于這些監控機制,能夠不斷發現并且解決混部過程中遇到的影響業務QoS的問題,最終實現完善的隔離機制。
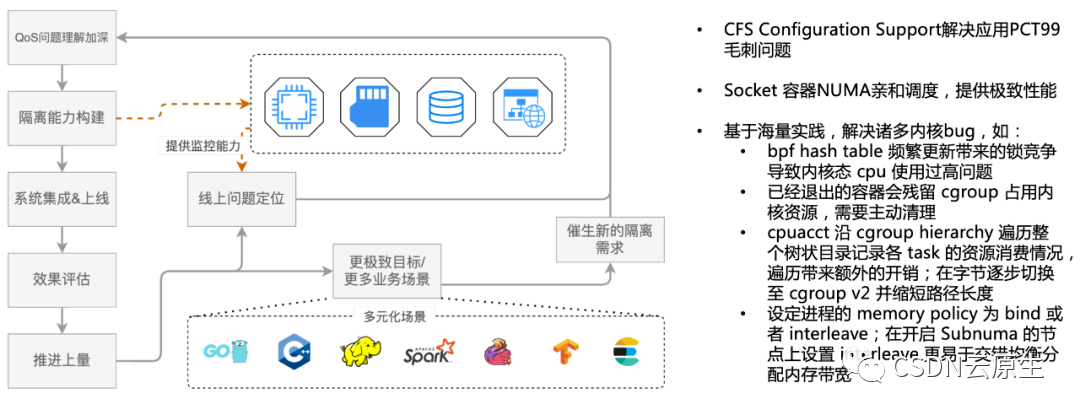
上圖中左側流程是發現問題并且解決問題的飛輪模型,右邊為實際解決的問題,如CFS調參的擴展解決應用PCT99毛刺,以及其他內核bug等,都是通過這種機制發現并不斷優化。
業務效果
在常態場景下,業務效果如下圖所示。
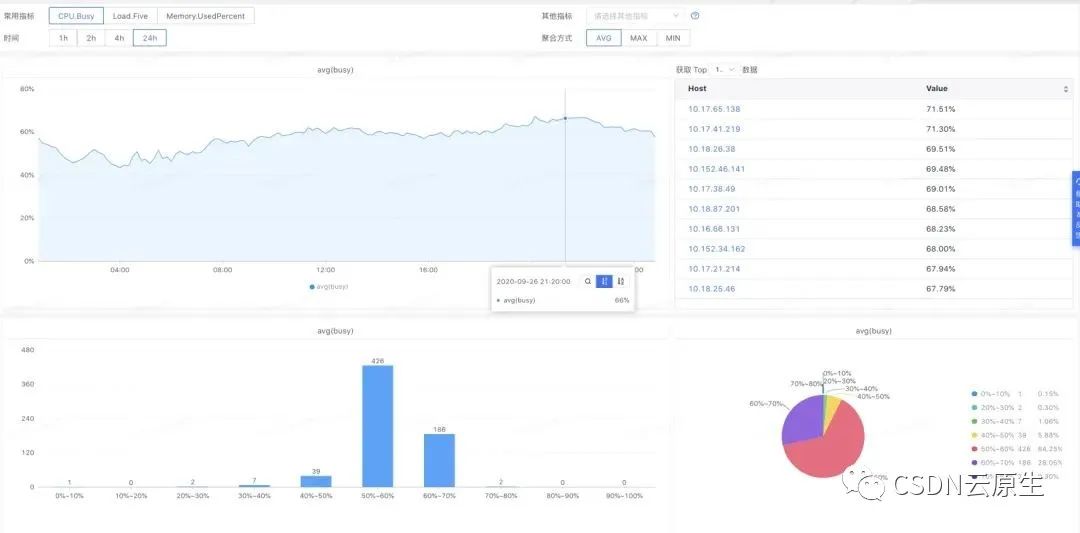
資源利用率情況,在線集群和離線集群的資源利用率從原來的平均23%提升到63%,節省40%左右的服務器成本。
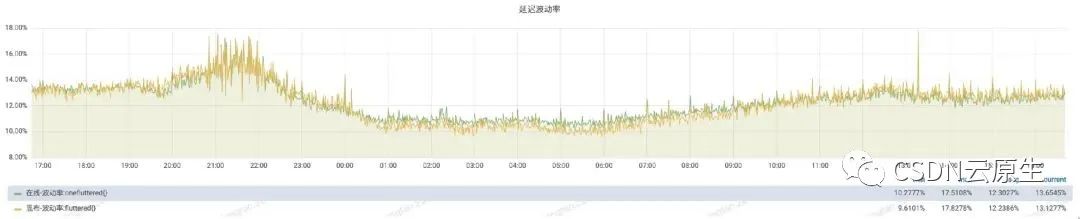
業務QPS指標,即在離線混部對業務QPS的影響,整體影響很小。

在保證在線業務資源需求的情況下,離線任務被驅逐的概率很低。
有了穩定的在離線資源調度系統,在需要應急資源的情況下,可以通過系統進行調配。比如2021年春晚抖音紅包雨活動,活動期間需要大量的服務器來支持。但如果僅為支撐春晚活動而去采購過多計算資源,活動結束后肯定會浪費,所以團隊除少量采購服務器之外,通過采用離線資源拆借和在線混部出讓的方案解決了臨時資源問題。
-
離線資源拆借。字節跳動內部有很多離線任務,例如模型訓練等,這些任務在時間上并沒有特殊約束。所以春晚活動就對這部分業務所占用的服務器進行了拆借,設置離線出讓策略后,這些服務器可以在5分鐘內轉換成在線紅包活動的可用狀態。
-
在線資源出讓。春晚當天,字節跳動還有大量服務器在支撐其他在線服務。所謂在線混部出讓,即在保證其他業務穩定不受影響的前提下,在服務器上插入部分春晚作業。
基于這兩種技術方案,在硬件設備有限的情況下,為春晚活動提供了充足的算力。

火山引擎云原生服務
火山引擎云原生服務的產品矩陣示意圖如下所示。

2021年12月,火山引擎發布公有云服務,對外輸出字節多年來積累的技術和經驗,云原生方向也以PaaS的形態上線了很多服務。
-
容器服務:包括托管的K8s管理平臺VKE、彈性容器平臺VCI和邊緣容器服務以及多云混合云的產品veStack;
-
敏捷開發:包括持續交付、鏡像倉庫等產品;
-
服務治理:包括服務網格、混沌工程等產品。
上述產品共同組成了云原生產品基礎矩陣,火山引擎云原生服務不僅僅提供了托管應用的能力,也融入了字節跳動在多年的實踐過程中沉淀的K8s的穩定性、可觀測性、服務網格等方面的技術積累和最佳實踐,方便用戶快速地使用相關技術。

END
關于margin的一些想法2.0)




)




![[轉]以終為始,詳細分析高考志愿該怎么填](http://pic.xiahunao.cn/[轉]以終為始,詳細分析高考志愿該怎么填)








