??
python近兩年似乎已經很熱了,不了解一下怎么能行呢,似乎python最大的優點就是簡潔、易懂、優雅。目前豆瓣、知乎等后臺服務使用的也都是python語言。 python一般可以用于網站服務、小工具、數據分析等工作。它作為高級語言,和js一樣,是解釋型語言,所以運行速度上會比較慢,但是在網絡服務上,相對于網速的緩慢,運行速度也就不是很大的問題了。?
python環境安裝
在windows環境下,我們可以進入這里下載安裝,安裝的過程中需要勾選添加到環境變量,這樣,在命令行操作過程中就不會出現問題了。 安裝完成后,打開命令行,輸入python,就進入交互模式了,輸入exit(),即可退出python環境。 另外,這個安裝的python環境就是最為通用的python解釋器cpython,之所以稱為cpython,是因為這個解釋器是通過c語言編寫的。

?
?
簡單的例子
我們在運行中,輸入cmd進入的是命令行模式,而如果輸入python,就可以進入python交互模式,因此如果我們希望運行python代碼,就需要進入python交互模式,上面的圖片也就是python交互模式。
我們還可以在進入python交互模式后,輸入 print('hello world!') ,即這是python的輸出字符串的語法,當然,我們也可以使用print輸出多個字符串,需要使用逗號隔開,如 print('hello', 'world', 'wayne'),并且其中也是可以接受數字的,如print(200)。?
另外,我們可以編輯一個.py后綴的python文件,然后在命令行下運行,即 python foo.py就可以執行這個foo.py文件了。
?
如上,我在sublime編輯器中新建一個foo.py,其中python語句是沒有分號和花括號的,因為這樣更加接近于自然語言。 然后在命令行中運行:

這樣,一個簡單的python程序就出來了。?
?
?
輸入輸出
python中的輸入輸出也是非常簡單的。?
輸出就是使用print,可以接受多個參數,參數的類型可以是數字也可是字符串,當然字符串中可以有\t和\n等。
輸入當然也是交互中必不可少的,為name(),這個在執行之后,會提示用戶輸入,name()函數可以接受一個字符串作為參數,如name('請輸入你的名字:'),舉例如下:
name = input('請輸入你的名字:') print('你好,', name)
?

python基礎知識
? python作為計算機語言,那么語言就必須要計算機理解,必須有一定的規則,而不是像自然語言很隨意。python的語法是比較簡單的,采用的時特有的縮進的方式,并且沒有像js那樣分號作為語句的結束,且語句在使用 : (冒號)結尾時,縮進的語句視為代碼塊,縮進沒有特定的要求,但是一般以4個空格為準,且python是大小寫敏感的。?python中使用#作為注釋的標志。且python中不需要聲明變量,直接使用就可以了。如下所示:
num = input('請輸入一個數字') if int(num) > 0:print('您輸入的數字大于0') elif int(num) < 0:print('您輸入的數字小于0') else:print('您輸入的數字等于0')
我們可以看到python中的else if需要寫成elif,否則會報錯,這樣也正是python簡潔的體現,而通過input()函數輸入的是一個字符串,在直接判斷與0的大小時會出錯,所以我們可以使用int()來講字符串強制轉化為數字,就可以進一步的比較了。 如下:
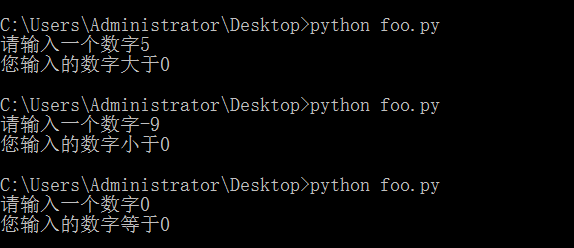
?
python中的數據類型和其他語言都是大同小異的,包括整數、浮點數、字符串、布爾值以及運算。其中布爾值有些許不同,如True表示真,而False表示假,第一個字母需要大寫,另外,我們可以使用 and、 or、 not 來表示布爾值的與、或、非運算,這使得python更加接近自然語言。python中使用None表示空值。 它的變量同樣是大小寫英文、數字和_組合,且不能使用數字作為開頭 。?python是動態語言,因為他的變量類型和js一樣是可以變動的,而不像java。 另外,python中的除法有兩種,一種是普通的 / ,這種方法不管除數和被除數為整數或者浮點數,得到的結果都是浮點數;而 // 這種除法得到的結果總是整數。同樣,python使用 % 作為求余的操作符。?
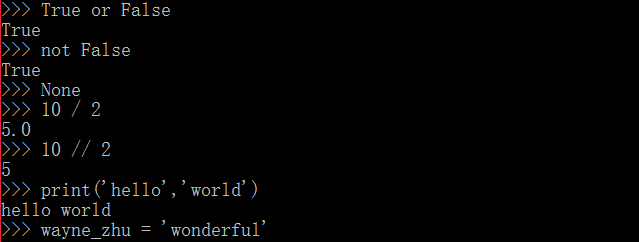
?
?
python字符串和編碼
對于字符串而言,最為復雜的就是編碼問題了,因為計算機只能處理0/1數字,所以要處理文本,就必須先把文本轉換為數字才能處理。
1個字節是8個bit,所以一個字節能表示的最大的整數是255,也就是說用一個字節編碼的方式可以最多表示255種字符。而最早是美國人發明了計算機,他們使用的語言只有a-zA-Z和其他字符一共127個,即ASCII編碼。但對于十萬個漢字的編碼,顯然ASCII編碼是做不到,而兩個字節可以表示6萬多種字符,所以,中文的編碼至少需要2個字節,于是中國制定了GB2312編碼。 但世界上有上百種文字,日本要把日文編到Shift_jis中,韓國把韓文編到Euc-kr中,顯然,這樣就沒有了統一的標準,而使得有多種文字編碼的文本中,很可能出現亂碼的情況。
因此,Unicode編碼應運而生,即union code,統一的編碼,這種編碼包含了各國文字,使得文本可以通用,而不必擔心出現亂碼的情況,Unicode編碼一般是兩個字節,但兩個字節只能表示6萬多字符,所以有時也會有四個字節的情況,但對于常用的文字,一般都是兩個字節。但如果一直使用Unicode編碼,問題是如果通篇英文,Unicode編碼會比ASCII編碼多出一倍的存儲空間,這是非常浪費的,于是,又出現了 UTF-8編碼,這種編碼把一個unicode字符根據不同的數字大小編為1 - 6個字節,常用的英文字母還是1個字節(可以將ASCII編碼看做UTF-8編碼的一部分),而漢字通常是3個字節,所以如果傳輸中包含了大量的英文字符,使用UTF-8編碼會更加節省空間。 
實際上,在計算機內存中,統一使用Unicode編碼,當需要保存到硬盤或者傳輸的時候,就轉換成UTF-8編碼,如瀏覽網頁的時候,服務器會把動態生成的Unicode內容轉換成UTF-8再傳輸到瀏覽器。這樣我們也就理解HTML文件中 <meta charset="UTF-8"/>的含義了。
而python中字符串也是Unicode編碼的,即它支持多種語言,而不會出現亂碼。對于單個字符的編碼,python提供了ord()函數獲取字符的整數表示(Unicode編碼的整數表示),chr()函數把編碼轉換為對應的字符。?
而如果我們知道字符的整數編碼,還可以用十六進制來寫str,如
>>> '\u4e2d\u6587' '中文'
其中,\u這個轉義字符表示Unicode編碼,而4e2d是十六進制的編碼,即中這個漢子用了兩個字節來表示,同樣文也用了兩個字節來表示。
另外,Python中提供了encode()函數和decode()函數來進行編碼和解碼,len()函數來返回字符長度。

?
? 在python中,也經常需要格式化,和c語言是非常類似的,%s為字符串,%d為整數,%f為浮點數,%x為十六進制數,并且如果在表示中有%我們需要進行轉義%%,另外,如果不知道該用哪個占位符,統一使用%s就可以了。format()函數也是同樣的表達方式,但相對于前者還是稍顯復雜,如下所示:
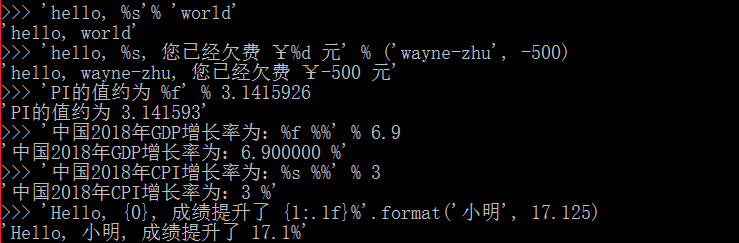
?
?
使用list和tuple
在c++中有List和tuple這兩種數據類型,而在python中同樣也有。 list比tuple有更多的操作方法,但是tupple一旦定義不能被改變,因而更加安全,下面做簡單介紹。?

如上所示,我們可以直接定義rel = ['wayne', 'hedy', 'baby']這個list,使用len()函數可以獲取這個list的長度,使用rel[0]這種下標可以獲取其中的元素,通過append()可以將元素添加到末尾,通過pop()可以彈出(刪除)最后一個元素,我們還可以通過insert()將元素插入到指定位置,使用pop(num)將指定位置的元素刪除,并且使用 rel[num] = str的方式直接替換list中的某個元素。 因此,list數據類型還是非常方便,操作起來更為簡單、強大。?
?
?
tupple和list非常類似,只是在定義的時候使用的時()而非[],并且最為本質的區別在于tupple一旦定義只能訪問不能修改,當然也就沒有append、insert、pop這些方法了,優點就是更安全,如果可以使用tupple就盡量不要使用list。?

可以看到,我們定義了rel之后,只能進行訪問,而在試圖修改時發生了錯誤。?
?
循環
python中有兩種循環。一種是使用for...in循環,另外一種便是while循環。
rel = ['wayne', 'hedy', 'baby'] for name in rel:print(name, '\n')
以上是使用for...in循環rel這個list,注意,以為for下一行縮進,所以for語句后有 : (冒號)。
另外,python中提供了range函數,如list(range(50))?可以生成一個0到49的list,而不需要我們手寫了。同樣,for...in也可以使用range,如下:
max = int(input('請輸入一個正整數:')) sum = 0 for a in range(max + 1):sum = sum + a print('1到%d' % max, '的和為:',sum )
運行結果如下所示:

?
而while循環和其他語言的循環也是類似的,如下所示:
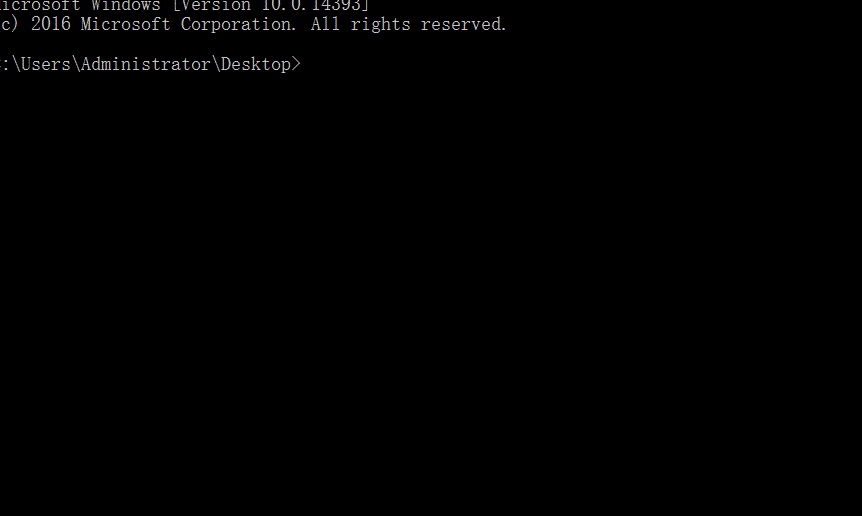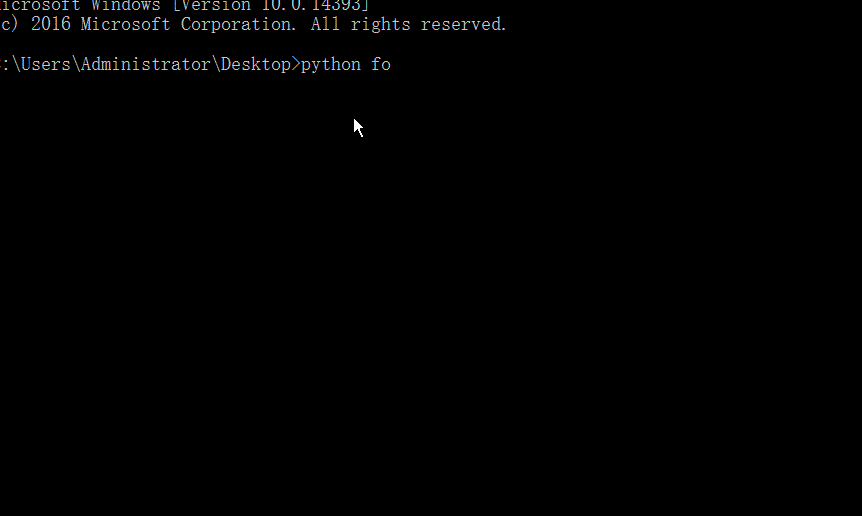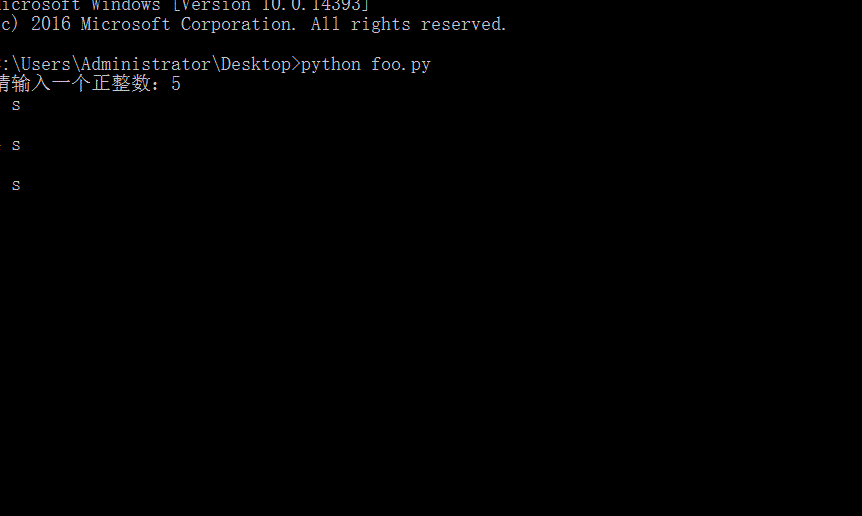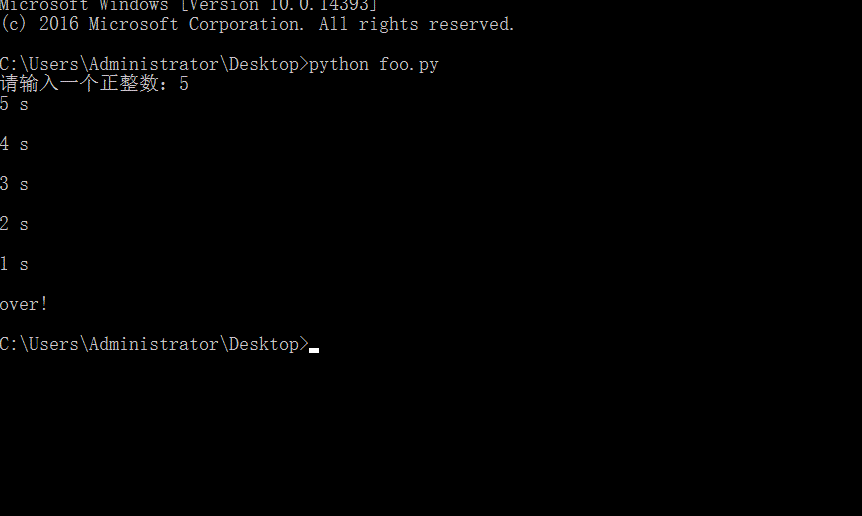
import time n = int(input('請輸入一個正整數:')) while n > 0:print(n, 's\n')time.sleep(1)n = n - 1 print('over!')
?這里我們在python文件中直接引入了time模塊,通過time模塊的sleep函數使得程序在運行到這一語句時暫停1s中而繼續運行。
同樣的,在python中也可以正常使用break和continue關鍵詞。
?
?
dict和set
在c++中提供了map這樣的數據結構,這種數據結構是含有多個k-v對,具有一一映射的特點,而在python中也提供了同樣的數據結構,只是名稱為dict,即dictionary字典,使用起來非常簡單。且list使用的時[],tuple使用的時(),這里的dict使用的是{},如下:
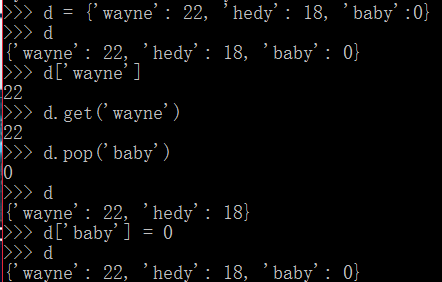
如上所示,我們使用{}來定義這個dict,并且可以使用d[key]的方式獲取到它的值,另外dict提供了get方法來查找相應的value,當然,如果不存在,則什么也不會返回。 且可以通過d[key]的方式來添加映射。 通過pop()函數來刪除其中的某個k-v對。注意:dict中的key是不能重復的。
?
那么set是怎么樣定義的呢?set和dict非常類似,但是set中只有key而沒有value,相同點在于key都是不能重復的,如果重復,則也會自動過濾, set有add方法添加key, 通過remove方法刪除,?set可以看成數學意義上的無序和無重復元素的集合,因此,兩個set可以做數學意義上的交集、并集等操作。 如下所示:

如上所示:我們可以看到,set()函數中實際上就是一個list,通過add添加key,通過remove刪除key,通過s1 = s來賦值,且兩個set之間可以進行并集和交集的運算。
? ? ? ?
另外,我們可以看到,這里s3本來是有重復數字的,但在建立后生成時,重復數字會自動被刪除,這便是set的一大特點。
python函數
python中內置了很多函數,比如之前的chr()等,這些函數是可以直接調用的,文檔中查看更多內置函數。https://docs.python.org/3/library/functions.html#abs
比如abs即求絕對值的函數、max函數返回多個參數中最大的一個、min函數等等。 更多示范可以看另外一篇文章。
python切片
即和js中的slice方法是類似的,但是python中是沒有slice的,而是使用了更為簡單的方式,如下:
>>> L = [0,1,2,3,4,5,6,7,8,9,10] >>> L[0:3] [0, 1, 2] >>> L[:3] [0, 1, 2] >>> L[2:4] [2, 3] >>> L[-2:] [9, 10] >>> L = list(range(20)) >>> L [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19] >>> L[0::2] [0, 2, 4, 6, 8, 10, 12, 14, 16, 18] >>> L[::2] [0, 2, 4, 6, 8, 10, 12, 14, 16, 18] >>> "wayne-zhu"[0:5] 'wayne' >>> t = (1, 56, 74, 85, 9) >>> t[0:3] (1, 56, 74)
即對于list而言,指定開始和結束的后一個位置,即可進行切片;
? ? ? ?如果是從0開始,則數字0是可以省略的;
? ? ? ?如果是負數,就是從倒數第幾個開始,最后一個是-1;
? ? ? ?我們還可以指定每隔幾個數取出一個數出來;
? ? ? ?字符串也可以看成一種list,也是可以用類似的方法的;
tupple和list一樣,只是tupple不可變,但也是可以使用這樣的方法。?
?
下面是使用python定義的trim函數,實現方式如下:
def trim(str):old = stri = 0while True:if str[i] == ' ':str = str[1:]else:breakj = len(str) - 1while True:if str[j] == ' ':str = str[0:j]j = len(str) - 1else:breakprint(old,'trim之后為:',str,'trim之后的字符長度為', len(str))trim(' wayne ')
我們首先將str保存起來,然后對字符串的前半部分進行處理 - 如果第一個字符是空格就slice; 對于字符串的后半部分做出同樣的處理。 結果如下:
C:\Users\Administrator\Desktop>python foo.pywayne trim之后為: wayne trim之后的字符長度為 5
?
?
python迭代
在js、c、c++等編程語言中,for循環都是大同小異的,如for(int i = 0; i < 10; i++),而在python中,for循環變得更加抽象了,如下所示:
d = {'wayne': 22, 'hedy': 18, 'baby': 0}
print('key:')
for key in d:print(key)print('\nvalue')for value in d.values():print(value)print('\nkey and value')
for k,v in d.items():print(k, v) 結果如下:
key: wayne hedy babyvalue 22 18 0key and value wayne 22 hedy 18 baby 0
另外,字符串也是可迭代對象。?
print('\n 字符串的迭代:') s = 'wayne-zhu' for ch in s:print(ch)
這樣,可以依次將字符打印出來。
那么我們如何判斷一個對象是否為可迭代對象呢?可以通過collections模塊的Iterable類型判斷:
from collections import Iterable print(isinstance('wayne', Iterable)) #True print(isinstance([1, 2, 3], Iterable)) #True print(isinstance(888, Iterable)) #False
如上所示,我們通過isinstance就可以判斷了。這里其實是判斷'wayne'、[1, 2, 3]、888是否是Iterable這個類的實例。?該函數返回一個布爾值,True或者False。
?
另外,list是沒有下標的,我們怎么實現呢?可以使用enumerate()函數,如下所示:
L = [666, 888, 520, 521, 1314] for k,v in enumerate(L):print(k, v)
最終結果如下所示:
0 666 1 888 2 520 3 521 4 1314
可以看到,這樣我們就可以獲得下標了。?
?
練習: 使用迭代的方法獲得一個list中的最大值和最小值,并返回這個list的tupple:
L = [666, 888, 520, 521, 1314] max = L[0] min = L[0] for k,v in enumerate(L):if L[k] > max:max = L[k]if L[k] < min:min = L[k]print(max, min) print(tuple(L))
結果如下;
1314 520 (666, 888, 520, 521, 1314)
?
?
?
python列表生成式
生成1到10的列表,使用下面的語法:
>>> list(range(1, 11)) [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
如果要生成[1 * 1, ... 10 * 10]的列表呢?
>>> [x * x for x in range(1, 11)] [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
上面這種語法是常見的,即直接將迭代式子寫在[]中,前半部分是我們所需要的表達式 。
?
另外,對于字符串而言,我們通常需要生成某個字符的全排列,可以這樣:
>>> [m + n for m in 'xyz' for n in 'xyz'] ['xx', 'xy', 'xz', 'yx', 'yy', 'yz', 'zx', 'zy', 'zz']
上面的式子就生成了xyz的全排列,xx、xy、xz、yx、yy、yz、zx、zy、zz, 當然我們還可以生成不同字符串之間的全排列,這是非常有用的。
?
下面的代碼還可以將list中的所有字母編程小寫:
>>> L = ['WAYNE', 'HEDY', 'BABY'] >>> [s.lower() for s in L] ['wayne', 'hedy', 'baby']
其中 lower() 函數是將字符串轉化為小寫, 而upper()函數可以將字符串轉化為大寫,如下所示:
>>> wayne = ['wayne', 'hedy', 'baby'] >>> [s.upper() for s in wayne] ['WAYNE', 'HEDY', 'BABY']
注意:上面的s.upper()也可以寫成 str.upper(s), lower同理。
?
另外,如果我們的L為['Wayne', 'Hedy', 18, None]如果直接使用列表生成式會因為18不是字符串而出錯:
>>> L = ['Wayne', 'Hedy', 18, None] >>> [str.lower(i) for i in L] Traceback (most recent call last):File "<stdin>", line 1, in <module>File "<stdin>", line 1, in <listcomp> TypeError: descriptor 'lower' requires a 'str' object but received a 'int'
我們試著使用if語句以及isinstance來修改:
>>> [str.lower(i) for i in L if isinstance(i, str)] ['wayne', 'hedy']
即在這個列表生成式中直接加入if語句,然后使用isinstance判斷i是否是str(字符串)類型即可。
?
?
python生成器
??? 創建一個列表就會打印出所有的元素,而如果這個列表的元素很多而我們僅僅需要訪問其中的前幾個元素,那么生成整個列表就會造成浪費。 而如果列表元素可以按照某種方法算法推算出來,那么我們是否可以在循環的過程中不斷地推算出后續的元素呢?這樣就不必創建完整的list,而節省了大量的空間。 在python中一邊循環一邊計算后續元素的機制,就稱為生成器。
比如,我們創建了一個1到100的list,如下:
>>> list(range(1, 100)) [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99]
但如果我們只需要1到100的前幾個元素,那么后續元素占用的內存就造成了浪費。 而生成器(generator)是下面這樣的:
>>> g = (x for x in range(1, 100)) >>> g <generator object <genexpr> at 0x02C41E70>
如果我們希望訪問其元素,可以使用next()進行訪問,next函數接受一個參數,即這個生成器g,如下所示:
>>> next(g) 1 >>> next(g) 2 >>> next(g) 3 >>> next(g) 4 >>> next(g) 5
如上所示,每調用一次next()函數,就會返回生成器的下一個元素,生成之后,才會給這個元素分配內存,這樣便大大節省了內存空間,即做到按需分配。
又比如下面的生成器:
>>> g = (x for x in range(1, 5)) >>> g <generator object <genexpr> at 0x02C6F0F0> >>> next(g) 1 >>> next(g) 2 >>> next(g) 3 >>> next(g) 4 >>> next(g) Traceback (most recent call last):File "<stdin>", line 1, in <module> StopIteration
可以看到,這里我們定義了元素從1到4的生成器,打印g,顯示g為一個generator,然后調用next()函數,返回generator的元素,每調用一次,返回下一個元素,但是當最后一個元素4已經打印出來后,再調用next(),就會報錯:即stopIteration,停止遍歷。
當然,更多情況下,我們還可以使用for來遍歷生成器,因為生成器是可遍歷的,如下:
g = (x * x for x in range(1, 5)) for n in g:print(n)
打印出的結果如下所示:
C:\Users\Administrator\Desktop>python foo.py 1 4 9 16
上面,我們都是直接使用()加表達式生成了一個生成器,但如果推算較為復雜的情況下,我們還可以使用函數的方式。 首先,我們可以看到如果斐波那契數列的函數生成:
def fib(max):n, a, b = 0, 0, 1while (n < max):print(b)a, b = b, a + bn = n + 1return 'done'fib(5) # 1 1 2 3 5
- 這里需要注意:python中定義變量更為簡潔,即這里的n, a, b = 0, 0, 1簡潔的一句代碼便定義了三個變量
- a, b = b, a + b的定義也是非常簡潔,這里沒有使用中間變量保存a,而是使用了tupple的數據結構,即t = (b, a + b)、 a = t[0]、 b = t[1]。
?
而如果我們這里將 print(b) 修改為 yield(b), 就是一個生成器了。 對于生成器來說,每次yield的時候,都會暫停,必須使用next()才能繼續執行下面的程序。所以就成了生成器了。而對于生成器來說,我們使用for..in來調用會更加方便一些:
def fib(max):n, a, b = 0, 0, 1while (n < max):yield(b)a, b = b, a + bn = n + 1return 'done'g = fib(5) # 1 1 2 3 5for x in g:print(x)
如上所示:我們可以看到這時的fib就是一個生成器了,且可以使用for...in遍歷。
?
python迭代器
之前我們提到過:"abc"、[]等都是Iterable(可迭代的),但是他們并不是迭代器,如下所示:
>>> from collections import Iterable >>> isinstance([], Iterable) True >>> isinstance({}, Iterable) True >>> isinstance('abc', Iterable) True >>> isinstance((x for x in range(1, 10)), Iterable) True >>> isinstance(628, Iterable) False
我們可以看到:[]、{}、'abc'、(x for x in range(1, 10))都是可迭代的,只有628這個數字肯定不是的。如果換做迭代器呢?
from collections import Iterator # 注意:這里import要換做Iterator print(isinstance({}, Iterator)) #False print(isinstance('abc', Iterator)) #False print(isinstance((x for x in range(1, 10)), Iterator)) #True print(isinstance(628, Iterator)) #False
這里,我們可以看到,只有(x for x in range(1, 10))是迭代器,其他都不是迭代器,這是為什么呢?
>>> g = (x for x in range(1, 10)) >>> next(g) 1 >>> next(g) 2 >>> next(g) 3 >>> next(g) 4
我們可以看到,(x for x in range(1, 10))這個表達式可以調用next函數,知道最后元素迭代完成,會報錯:stopIteration。?
而'abc'呢?如下所示:
>>> g = 'abc' >>> g 'abc' >>> next(g) Traceback (most recent call last):File "<stdin>", line 1, in <module> TypeError: 'str' object is not an iterator
如上所示:使用'abc'的next函數時,會直接報錯:'str' object is not an iterator。即字符串不是一個迭代器。 對于list、disc也同樣如此,所以這里只有tupple才是Iterator。
>>> g = {'wayne':22, 'hedy': 18}
>>> g
{'wayne': 22, 'hedy': 18}
>>> next(g)
Traceback (most recent call last):File "<stdin>", line 1, in <module>
TypeError: 'dict' object is not an iterator ? ? ? ? ?于是有:?可以被next()函數調用并不斷返回下一個值的對象稱為迭代器:Iterator。
但是,我們是可以將非Iterator強制轉換為Iterator的。使用iter()函數即可。但前提是它們必須是Iterable,對于628這樣的not Iterable的類型,使用iter()也是無濟于事的。 如下所示:
>>> s = 'abc' >>> s 'abc' >>> i = iter(s) >>> i <str_iterator object at 0x039F4670> >>> next(i) 'a' >>> next(i) 'b' >>> next(i) 'c'
628不是Iterable,如下:
>>> n = 628 >>> i = iter(n) Traceback (most recent call last):File "<stdin>", line 1, in <module> TypeError: 'int' object is not iterable
可以看到,對于int類型的628,如果使用iter,也是會報錯的 ---?'int' object is not iterable
?
那為什么list不是Iterator呢? 這是因為Iterator是惰性的,并沒有一次性獲取到所有的數據,是無限制的,而list是一開始就存儲了數據。
?
?
高階函數
即函數中接受函數作為參數的函數就是高階函數。 如map、filter等。又如sorted函數,如下:
>>> sorted([35, -56, 85, 69]) [-56, 35, 69, 85] # 如上,這里沒有接受函數作為參數,只是按照從小到大的排序
>>> sorted([35, -56, 85, 69], key=abs) [35, -56, 69, 85] # 這里我們接受了abs函數作為第二個參數,即按照其絕對值大小進行排序
>>> sorted(['bob', 'about', 'Zoo', 'Credit']) ['Credit', 'Zoo', 'about', 'bob'] #這里我們直接對字符串進行排序
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower) ['about', 'bob', 'Credit', 'Zoo'] #這里我們將所有的字符串按照轉化為小寫字母之后進行排序
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True) ['Zoo', 'Credit', 'bob', 'about']
#如果我們希望反向,只需要再添加一個參數 -- reverse = True
?
在python中,也是存在匿名函數的概念的,如下:
>>> f = lambda x: x * x >>> f(5) 25
如上所示: 等式右邊的就是一個匿名函數,而 lambda 關鍵詞就表示在聲明一個匿名函數,冒號之前的x表示接受的參數,之后表示返回的值。
?
?python裝飾器
如下所示:定義一個now函數,因為函數是一個對象,所以可以賦值給f(另外一個變量),然后我們再調用這個函數即可。
>>> def now(): ... print('20180324') ... >>> f = now >>> f() 20180324
在python中,我們可以調用now或者f的__name__屬性,以獲取到該函數的函數名:如下:
>>> now.__name__ 'now' >>> f.__name__ 'now'
那什么是裝飾器呢?比如,我們希望函數調用前后自動打印日志, 但是又不希望修改now()函數的定義,這種在代碼運行期間動態增加功能的方式,稱之為裝飾器。并需要用到@的Python語法。
下面我就定義一個裝飾器函數用于打印日志:
def log(func):def wrapper(*args, **kw):print('call %s():' % func.__name__)return func(*args, **kw)return wrapper
這個裝飾器函數就是一個高階函數(接受一個函數作為參數),然后定義了一個wrapper函數返回fun()執行后的結果。然后我們將Log置于函數的定義處:
def log(func):def wrapper(*args, **kw):print('call %s():' % func.__name__)return func(*args, **kw)return wrapper@log def now():print('20180324')now()
我們執行之后,得到如下結果:
call now(): 20180324
至于上面的格式,即將@log放在了now函數的定義之前,相當于在定義之后執行了函數 now = log(now),即把這個now函數從新進行了包裝、修飾,即為裝飾器函數。因此,我們寫成下面的方式也是可以的:
def log(func):def wrapper():print('call %s():' % func.__name__)return func()return wrapper@log def now():print('20180324')now()
之前添加了的一些參數是為了更多的使用擴展性。即now()函數執行之后,即調用了這個裝飾器函數@log,返回了wrapper函數,最后我們調用now(),就執行了這個wrapper函數,并返回結果。
這里,我們可以將@log解釋為如下的執行方式:
def log(func):def wrapper():print('call %s' % func.__name__)return func()return wrapperdef now():print('20180324')now = log(now) # 這樣,會fanhuiwrapper函數,然后調用now,就是執行了wrapper函數,首先打印了內容,再執行真正的now函數。now()
上面是最簡單的方式,而如果這個裝飾器自身需要接受參數,那么如果使用上面的這種方式就無法滿足了,我們必須再包裹一層函數,如下所示:
def log(text):def decorator(func):def wrapper():print('call %s %s' % (text, func.__name__))return func()return wrapperreturn decorator @log('extro') def now():print('20180324')now()
思路非常明確,即包含了一層decorator函數,我們將text傳給裝飾器,實際上,@log('extro')的另外一種真是的寫法如下:
def log(text):def decorator(func):def wrapper():print('call %s %s' % (text, func.__name__))return func()return wrapperreturn decorator def now():print('20180324')now = log('extor')(now)now()
最終的結果如下:
call extor now 20180324
但這里還是有問題的,當我們在程序的最后加上 print(now.__name__)的時候,我們可以發現最終輸出的時 wrapper 而不是 now,這不是我們希望看到的,而我們修改之后最終的結果如下:
import functoolsdef log(text):def decorator(func):@functools.wraps(func)def wrapper():print('call %s %s' % (text, func.__name__))return func()return wrapperreturn decorator def now():print('20180324')now = log('extor')(now)now()print(now.__name__)
?
?
?
python偏函數
偏函數還是很好理解的,我們從一個簡單的例子說起。
比如我們可以使用int('1000')將字符串'1000'轉化為數字,這個轉化過程默認是十進制的。 而如果我們希望轉化為2進制的,我們可以這樣調用:int('1000', base=2)或者是int('1000', 2)。?但是如果我們需要大量的轉化為二進制數字的調用,每次都int('1000', 2)難免比較麻煩,所以我們可以封裝為一個函數再調用,如下:
def int2(str):return int(str, base=2)print(int2('100')) #4 print(int2('10')) #2 print(int2('1')) #1
如上所示,這樣,我們就可以很輕松的進行轉化了。但python中的functools模塊本身有這個作用,如下:
import functools int2 = functools.partial(int, base=2)print(int2('100')) #4 print(int2('10')) #2 print(int2('1')) #1
即這里我們使用了functools.partial函數,這就是偏函數,即把一個函數的某些參數給固定住(也就是設置為默認值),返回一個新的函數,調用這個函數會更加簡答。而我們也可以繼續個性化,如下:
import functools int2 = functools.partial(int, base=2)print(int2('100',base=10)) #100 print(int2('10')) #2 print(int2('1')) #1
如上,可以看出來,這個和我們上面自己定義的int2是相同的,總之,偏函數可以固定住某些參數,使我們的操作更加簡單。
?
?
?
?
python模塊
和JavaScript是類似的,大多數編程語言都是要進行模塊化開發的,因為當工程越來越復雜的時候,不可能始終使用一個文件,而是根據程序塊的不同作用分配到模塊中,這樣,有利于開發的高效性,另外,同一個模塊還可以在多處使用,這樣有利于提高程序的重用性,python也不例外。?
python中,一個.py文件就可以看做一個python模塊,模塊很好地解決了變量命名沖突的問題,并且通過模塊,但當模塊多時,也不可避免出現重名,在python中也就有了包的概念,如一個mymodule包,下面有util.py模塊、anto.py模塊,并且一定還有一個__init__.py模塊,如果沒有,Python將不認為mymodule是一個包,通過這個包,我們的模塊名稱更具辨識性,如util.py模塊又稱為mymodule.util模塊等等。
使用模塊我們很清楚,直接import 即可,但是如果自定義一個自己的模塊呢?如下所示(該文件名為hello.py):
'my first module'__author__ = 'Wayne Zhu'import sysdef test():args = sys.argvif len(args) == 1:print('hello world!')elif len(args) == 2:print('hello %s' % args[1])else:print('Too many arguments!')if __name__ == '__main__':test()
Ok! 這就是一個標準的模塊了,其中'my first module'是這個py文件的第一個字符串,默認為該文件的說明性注釋; 而__author__ = 'Wayne Zhu'中的__author__是專有變量,是聲明這個文件的作者,接下來我們引入了sys模塊,通過這個模塊我們可以獲得用戶在命令行輸入的參數;最后我們判斷__name__是否為__main__,如果是執行當前文件,則是,作為入口文件,當然是main,如果是被其他Python文件調用,則不是。
其中,sys的argv參數是命令行的參數,如python hello,則argv是一個list,且數量至少為1,這里就是['hello'],而如果用戶執行時是 python hello wayne-zhu,則sys.argv的元素個數為2,即['hello', 'wayne-zhu']。
該模塊如果被直接調用,最終的結果如下:
C:\Users\Administrator\Desktop>python hello.py hello world!C:\Users\Administrator\Desktop>python hello.py wayne-zhu hello wayne-zhuC:\Users\Administrator\Desktop>python hello.py wayne hedy Too many arguments!
而如果我們是在python交互環境中引入hello模塊,則不會有輸出,如下:
>>> import hello >>> hello.test() hello world!
但是我們可以直接通過hello調用test函數。?
?
?
python變量
這里主要說的還是變量的可訪問性。
- 公開變量,abc/foo等,這些變量是公開的,允許被模塊內外訪問的。
- 模塊內變量/私有變量,_abc、_foo等,即簡單的通過_來確定,但實際上語法并沒有限制,只是方便程序員觀察使用。
- 特殊變量,__name__、__author__等,這些變量和公開變量并沒有什么區別,只是他們有特殊的用途,如__author__表示當前模塊的作者名; __name__和'__main__'判斷是否相等來判斷是直接執行還是間接調用。
def _private_1(name):return 'Hello, %s' % namedef _private_2(name):return 'Hi, %s' % namedef greeting(name):if len(name) > 3:return _private_1(name)else:return _private_2(name)
比如上面的例子中,_private_1和_private2是模塊內使用的,而greeting是暴露出去的,可以被其他的模塊使用。
hello.py如下:


'my first module'__author__ = 'Wayne Zhu'import sysdef test():args = sys.argvif len(args) == 1:print('hello world!')elif len(args) == 2:print('hello %s' % args[1])else:print('Too many arguments!')def speak(str='great!'):print(str)if __name__ == '__main__':test()
foo.py如下:
import hello hello.test() hello.speak('I am handsome')
當我們執行foo.py時,最終的結果如下:
hello world!
I am handsome 可見,我們成功的在foo.py中引用了hello模塊,并使用了hello模塊暴露的speak函數和test函數,但是根據hello模塊test編寫形式而言,test主要是為了作模塊內測試的,并非暴露給其他模塊使用。但語法上并沒有任何問題。
?
安裝第三方模塊
? 我們在命令行中輸入pip,如果正常,則說明可以通過pip安裝第三方模塊,這個和前端中的npm是類似的,并且,一般的開發者如果要提供自己的模塊,需要到pypi.python.org中注冊,和前端需要到npm.org中注冊時一樣的,比如我們要安裝該庫的名稱是 Pillow,那么安裝Pillow的命令就是:
pip install Pillow
如下所示:
C:\Users\Administrator\Desktop>pip install Pillow Collecting PillowDownloading Pillow-5.0.0-cp36-cp36m-win32.whl (1.4MB)100% |████████████████████████████████| 1.4MB 655kB/s Installing collected packages: Pillow Successfully installed Pillow-5.0.0 You are using pip version 9.0.1, however version 9.0.3 is available. You should consider upgrading via the 'python -m pip install --upgrade pip' command.
但是,這里下載的位置在C:\Users\Administrator\AppData\Local\Programs\Python\Python36-32\Lib\site-packages,所以,如果我們希望自己新建一個py文件可以import Pillow,就必須要將Pillow這個文件夾放在和當前py文件的同級目錄下,否則就引入不了。
同樣的,Flask這個web框架就是python框架,安裝如下:
pip install flask
然后,我們再新建下面這個文件:
from flask import Flaskapp = Flask(__name__)@app.route('/') def hello_world():return 'Hello Flask!'if __name__ == '__main__':app.run()
然后在命令行中執行這個文件:
C:\Users\Administrator\Desktop>python foo.py* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
于是我們就可以看到瀏覽器如下:
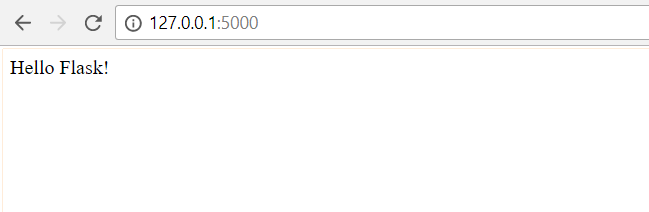
即通過這個Flask庫,我們就自己快速搭建了一個服務器。但是我們可以發現一個問題,就是每次在我們修改文件內容時,比如返回 Hello Wayne!,然后我們去刷新瀏覽器,但顯示內容并沒有刷新,這是因為我們沒有開啟DEBUG模式,如果要開啟,我們需要在環境變量中添加 FLASK_DEBUG, 值為1,如下:
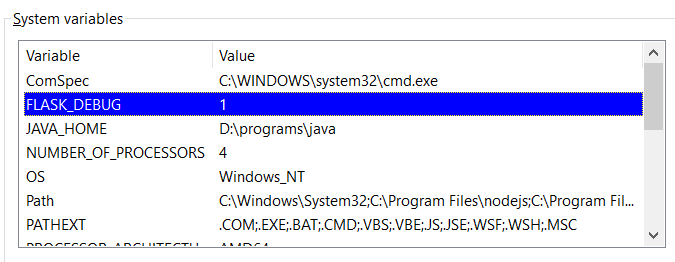
這樣,我們在運行該文件時,內容時這樣的:
C:\Users\Administrator\Desktop>python foo.py* Restarting with stat* Debugger is active!* Debugger PIN: 109-984-470* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
即調試模式開啟,我們就可以進行調試了。且每次我們修改文件并保存后,服務器就會重啟,然后我們刷新瀏覽器,內容就會發生改變了!這方面的使用還是比node更加方便一些。
另外還有很多有用的模塊,如果我們都這樣下載,未免太慢,所以推薦使用Anaconda,這個平臺一旦下載就意味著下載了數十個庫文件,這樣是非常有用的,我們可以在這里下載。
安裝完成之后,輸入python,我們就可以看到Anaconda的相關信息了。然后,對于一些常見的模塊我們就不需要再自己下載,而是直接使用即可。但有些情況下,安裝之后輸入python還是沒用,這時我們可以將anaconda的安裝路徑加入到path中即可,如:

?
?
注意:現在,不下載也是可以的,最多全部下載一遍,不適用Anaconada也是一樣的,不必過分糾結。
?
另外,之前我們說過:每次install一個模塊之后,可以通過everything這個工具找到該文件,然后將當前python文件和庫文件放在同級目錄下才可以使用,但這樣比較麻煩,我們可以將存放install的庫的路徑加入到sys模塊的path變量中,這樣我們就不用每次都把下載到的文件再手動放在一起了。
import sys >>> sys.path ['', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36-32\\python36.zip', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36-32\\DLLs', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36-32\\lib', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36-32', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36-32\\lib\\site-packages'] >>> sys.path.append('C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36-32\\Lib\\site-packages')
我們可以看到: 這里的sys.path是一個list,所以可以使用append方法來添加元素。
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
參考文章:廖雪峰博客、python文檔

)




![[轉]以終為始,詳細分析高考志愿該怎么填](http://pic.xiahunao.cn/[轉]以終為始,詳細分析高考志愿該怎么填)









)
![[轉]2022 年 Java 行業分析報告](http://pic.xiahunao.cn/[轉]2022 年 Java 行業分析報告)

