點擊上方藍字
關注我們
(本文閱讀時間:18分鐘)
Microsoft Azure Machine Learning Studio 是微軟強大的機器學習平臺,在設計器中,微軟內置了15個場景案例,但網上似乎沒有對這15個案例深度刨析的分析資料,所以我就計劃寫一個系列來完成。
既然是深度刨析,就不再是簡單的介紹操作,而是深入每一個細節,寧愿過度詳細擴展,也不簡單掃過。
這次我們刨析的案例是:基于廣泛和深入的推薦 - 餐廳評級預測。
微軟MVP實驗室研究員


王豫翔,Leo
微軟圈內人稱王公子。微軟10年+MVP,大齡程序員。目前核心工作是使用微軟AI技術設計可以落地的解決方案,也就是寫PPT。雖然熱愛代碼,但只有午夜時分才是自由敲代碼的時間。喜歡微軟技術,不喜歡無腦照抄。?

預備知識

▍Wide & Deep 模型
2016年,Google 提出了一種兼具模型記憶性和模型泛化性的神經網絡——wide & deep for recommender systems。這篇文章是推薦系統中的經典,被應用于 Google Play 中的應用推薦。文章的主要貢獻就是提出了兼顧模型記憶性和泛化性的通用模型結構。
記憶性簡單的說就是根據用戶之前的行為,推薦類似的信息。這種模式計算簡單,統計頻率的計算量相對較小,但是缺陷也很明顯,就是用戶的信息繭房越來越封閉,除非用戶主動的了解了新類型的信息,否則不太會推薦給用戶新類型資訊。
泛化性是指延申用戶的行為,推薦其興趣點有關的信息。但顯然這種模式雖然好,但計算肯定復雜了。
Google 將這兩個模型結合起來,得到了 wide&deep 模型,其中 wide 部分就是簡單的線性模型,deep 部分就是深度學習模型,它同時具有“記憶能力”和“泛化能力”。
▍數據集
該數據集是 Restaurant & consumer data Data Set 的部分。
原生數據:
http://archive.ics.uci.edu/ml/datasets/Restaurant+%26+consumer+data
原始數據分三類共9份文件:
| 分類 | 文件 |
| Restaurants | chefmozaccepts.csv |
| chefmozcuisine.csv | |
| chefmozhours4.csv | |
| chefmozparking.csv | |
| geoplaces2.csv | |
| Consumers | usercuisine.csv |
| userpayment.csv | |
| userprofile.csv | |
| User-Item-Rating | rating_final.csv |
經過對比和分析后,本次案例用了以下三個文件
rating_final.csv | 采納 | ||
列名 | 含義 | 值描述 | |
userID | |||
placeID | |||
rating | 總體評價 | 0,1,2 | |
food_rating | 食物評價 | 0,1,2 | 否 |
service_rating | 服務評價 | 0,1,2 | 否 |
userprofile.csv | |||
userID | |||
Latitude | 經度 | ||
longitude | 維度 | ||
Smoker | 吸煙 | ||
drink_leve | 飲酒 | 酗酒, 社交飲酒者, 休閑飲酒者 | |
dress_preference | 著裝偏好 | 非正式,正式,沒有偏好, 優雅 | |
ambience | 氛圍 | 家庭,朋友, 孤獨 | |
transport | 交通 | 步行, 公共, 車主 | |
marital status | 婚姻狀態 | 單身, 已婚, 喪偶 | |
hijos | 子女 | 獨立, 孩子, 依賴 | |
birth_year | |||
interest | 興趣 | 多樣性,技術,無,復古,環保 | |
personality | 性格 | 節儉保護者, 獵人炫耀, 勤奮工作者, 墨守成規者 | |
religion | 宗教 | 天主教, 基督教, 摩門教, 猶太人 | |
activity | 學生, 專業, 失業, 工人階級 | ||
color | 黑色, 紅色, 藍色, 綠色, 紫色, 橙色, 黃色, 白色 | ||
weight | 體重 | ||
budget | 預算 | 中,低,高 | |
height | 身高 | ||
geoplaces2.csv | |||
placeID | |||
latitude | |||
longitude | |||
the_geom_meter | 地理空間 | ||
name | 名字 | ||
address | 地址 | ||
city | 城市 | ||
state | 州 | ||
country | 國家 | ||
zip | 郵編 | ||
Alcohol | 含酒精飲料 | 不含酒精,葡萄酒,啤酒,酒吧 | |
smoking_area | 吸煙區 | 無,僅吧臺,允許,部分,不允許 | |
dress_code | 著裝要求 | 非正式,休閑, 正式 | |
Accessibility | |||
price | 價格 | 中,低, 高 | |
url | 網址 | ||
Rambience | 氛圍 | ||
franchise | 特許經營權 | 是,否 | |
area | 區域 | 開放, 關閉 | |
other_services | 其他服務 | 無,互聯網,品種 | |
▍Vowpal Wabbit 數據格式
Vowpal Wabbit,簡稱 VW,是一個功能強大的開源,在線(online)和外存學習(out-of-core machine learning)系統,由微軟研究院的John Langford及其同事創建。Azure ML 通過 Train VW 和 Score VW 模塊對 VW 提供本機支持。可以使用它來訓練大于 10 GB 的數據集,這通常是 Azure ML 中學習算法允許的上限。它支持許多學習算法,包括 OLS 回歸(OLS regression),矩陣分解(matrix factorization),單層神經網絡(single layer neural network),隱狄利克雷分配模型(Latent Dirichlet Allocation),上下文賭博機(Contextual Bandits)等。
VW 的輸入數據每行表示一個樣本,每個樣本的格式必須如下
label | feature1:value1 feature2:value2 ...
簡單的說,每一條樣本的第一個是標簽(Label),后面是特征(Feature)。也就是每一條樣本都是有標簽樣本(labeled)。
▍Parquet 列式存儲格式
Parquet 是 Hadoop 生態圈中主流的列式存儲格式,最早是由 Twitter 和 Cloudera 合作開發,2015 年 5 月從 Apache 孵化器里畢業成為 Apache 頂級項目。
有這樣一句話流傳:如果說 HDFS 是大數據時代文件系統的事實標準,Parquet 就是大數據時代存儲格式的事實標準。Parquet 列式存儲格式的壓縮比很高,所以 IO 操作更小。
Parquet 是與語言無關的,而且不與任何一種數據處理框架綁定在一起,適配多種語言和組件,能夠與 Parquet 適配的查詢引擎包括 Hive, Impala, Pig, Presto, Drill, Tajo, HAWQ, IBM Big SQL 等,計算框架包括 MapReduce, Spark, Cascading, Crunch, Scalding, Kite 等,數據模型包括 Avro, Thrift, Protocol Buffer, POJOs 等。所以 Parquet 就是一個數據存儲,提供引擎快速查詢數據的格式。
▍優化器
優化的目標是希望找到一組模型參數,使模型在所有訓練數據上的平均損失最小。
優化器 | 能力 | 優點 |
SGD | 用單個訓練樣本的損失來近似平均損失,即每次隨機采樣一個樣本來估計當前梯度,對模型參數進行一次更新 | 訓練速度快,內存開銷小 |
AdaGrad(Adaptive ?Gradient Algorithm) | 自適應地確定參數的學習速度,對更新頻率低的參數做較大的更新,對更新頻率高的參數做較小的更新 | 減少學習率的手動調整,更適用于稀疏數據,提高 SGD 的魯棒性 |
AdaDelta | 針對 AdaGrad 改進,采用指數衰減平均的計算方法,用過去梯度平方的衰減平均值代替他們的求和 | 不需要提取設定學習速率,使用指數衰減平均計算,防止學習速率衰減過快 |
RMSProp | 是 Geoff Hinton 提出的一種自適應學習率方法。結合了 Momentum 的慣性原則,加上 AdaGrad 對錯誤方向的阻力 | 解決 AdaGrad 學習率急劇下降 |
Adam | 結合 Momentum 和 AdaGrad 的優點,還包含了偏置修正 | 為不同參數產生自適應的學習速率 |
FTRL(Follow the ?Regularized Leader) | 能學習出有效的且稀疏的模型 | FTRL 算法融合了 RDA 算法能產生稀疏模型的特性和 SGD 算法能產生更有效模型的特性。它在處理諸如 LR 之類的帶非光滑正則化項(例如1范數,做模型復雜度控制和稀疏化)的凸優化問題上性能非常出色,國內各大互聯網公司都已將該算法應用到實際產品中 |
▍激活函數(Activation Function)
在神經網絡中,輸入經過權值加權計算并求和之后,需要經過一個函數的作用,這個函數就是激活函數。如果在神經網絡中不引入激活函數,那么在該網絡中,每一層的輸出都是上一層輸入的線性函數,無論最終的神經網絡有多少層,輸出都是輸入的線性組合。也就是說如果沒有激活函數,那么再多層的神經網絡也只能處理線性可分問題。
激活函數 | 說明 | 類型 |
ReLU(Rectified linear unit,修正線性單元) | 深度學習目前最常用的激活函數,減輕了神經網絡的梯度消失問題。ReLU 函數有很多變體,如 LeakyReLU,pReLU 等。使用梯度下降(GD)法時,收斂速度更快 。只需要一個門限值,即可以得到激活值,計算速度更快。但如果輸入值為負的時候,輸出始終為0,也就是神經元不學習了,這種現象叫做“Dead Neuron”。 | 非飽和 |
Leaky Relu | 針對 Relu 函數中存在的 Dead ?Relu Problem,Leaky Relu 函數在輸入為負值時,給予輸入值一個很小的斜率,在解決了負輸入情況下的0梯度問題的基礎上,也很好的緩解了 Dead Relu 問題。但實測不穩定,所以現在用的也不多。 | 非飽和 |
sigmoid | sigmoid 將一個實值輸入壓縮至[0,1]的范圍,也可用于二分類的輸出層。以前很常用,現在用的少了。它在?部分時候被更簡單、更容易訓練的 ReLU 所取代。 | 飽和 |
tanh (Hyperbolic tangent function,雙曲正切函數) | 將 一個實值輸入壓縮至 [-1, 1]的范圍,這類函數具有平滑和漸近性,并保持單調性。 | 飽和 |
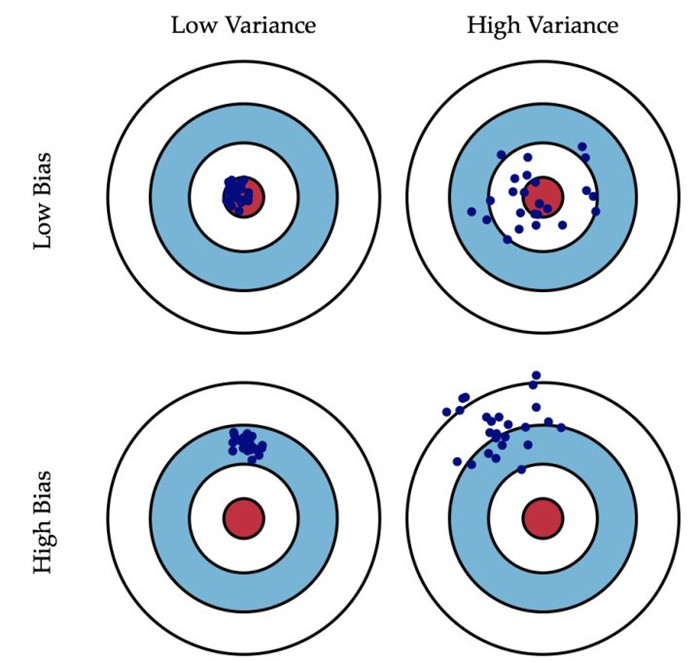
▍偏差和方差
偏差:描述的是預測值的期望與真實值之間的差距。偏差越大,越偏離真實數據。
方差:描述的是預測值的變化范圍,離散程度,也就是離其期望值的距離。方差越大,數據的分布越分散。
下面這張圖非常生動的描述了偏差和方差的含義:
深入分析

這套案例一共九個工作節點,但其中有兩組六個節點是一樣的。這個案例中不需要我們進行編碼,但提供了我們關于非常經典的廣告推薦訓練的最佳實踐,值得我們認真了解。我們逐個分析每一個節點中值得關注的細節和核心信息。
▍數據源輸入節點
這一組節點有三個,分別是:Restaurant Ratings、Restaurant Customer Data、Restaurant Feature Data。這些節點的數據可以在節點屬性中看到有兩個核心信息。
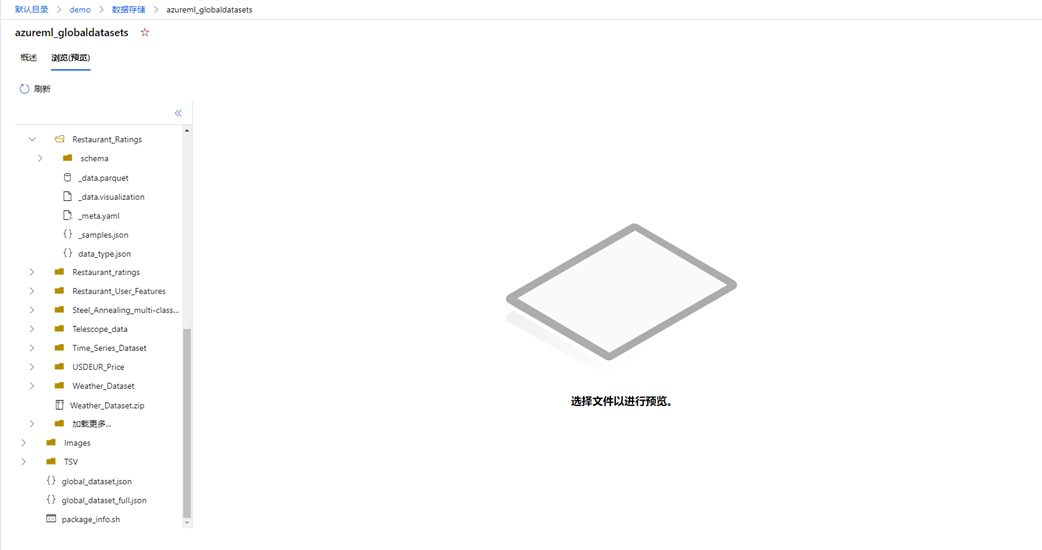
Datastore name:azureml_globaldatasets 是一個鏈接,點擊可以跳轉到數據存儲的位置;
Relative path:描述在 Datastore 中當前文件的位置。
點擊 azureml_globaldatasets 將跳轉到 Datastore 瀏覽器,您可以在這個瀏覽器下觀察到您存儲的數據。大致的界面如下
以下表格可以幫助您快速對這三個節點數據有全局的了解。
節點 | 含義 | 相對路徑 | 對應RCD數據 |
Restaurant Ratings | 餐廳評級 | Restaurant_Ratings | rating_final.csv |
Restaurant Customer Data | 就餐的客戶特征 | Restaurant_User_Features | userprofile.csv |
Restaurant?Feature Data | 餐廳特征 | Restaurant_Item_Features | geoplaces2.csv |
▍Split Data 節點
這個節點比較簡單,按行將 Restaurant Ratings 數據集分為50%和50%,目的是將數據集分成兩個不同的集。拆分的方式有三種:
拆分行:就是簡單的講輸入的數據集拆分為兩個部分。默認是對半拆分,并且是隨機選定內容。
正則表達式拆分:如果我們需要把數據集按某些特征,分為符合和不符合,就可以用這個選項進行拆分。
相對表達式拆分:如果我們希望對數據集按某些范圍進行拆分,比如日期范圍,數據范圍,就可以用這個選項。
當前案例采用了對半隨機拆分行。
▍Select Columns in Dataset 節點
這個組件節點有兩個,分別是?Restaurant Customer Data 和 Restaurant Feature Data 做數據處理。
Select Columns in Dataset 節點的目的是得到一個輸入數據集的子集,過濾一些原始數據集的干擾列。
數據集 | 原始集合 | 子集 |
Restaurant Customer Data | userID、latitude、longitude、smoker、drink_level、dress_preference、ambience、transport、marital_status、hijos、birth_year、interest、personality、religion、activity、color、weight、budget、height | userID、latitude、longitude、interest、personality |
Restaurant Feature Data | placeID、latitude、longitude、the_geom_meter、name、address、city、state、country、zip、alcohol、smoking_area、dress_code、accessibility、price、url、Rambience、franchise、area、other_services | placeID、latitude、longitude、price |
明顯可以看出 Select Columns in Dataset 節點將設計者認為不必要的特征都排除了。
▍Train Wide and Deep Recommender 節點
這個節點是本次案例的核心。Wide & Deep 推薦器需要接受三個輸入:訓練集、用戶特征集、評價目標特征集。特別要注意,Wide & Deep 對訓練集的格式是有約定的:
訓練集:是一個用戶-目標-評分的標準結構,也就是說,這個集合只能有三個列,并且依次是:用戶標識、目標標識、對目標的評級。
用戶特征集合:必須包含用戶的標識符,并使用訓練集第一列中提供的相同標識符。其余列可以包含任意數量的用于描述用戶的特征。
目標特征數據集:必須在其第一列中包含目標標識符,并使用訓練集第二列中提供的相同標識符。其余列可以包含任意數量的項目的描述性特征。
對應上面的概念,下表可以全面的了解 Wide & Deep 的輸入:
輸入參數 | 對應數據集 | 關鍵特征 |
Training_dataset_of_user_item_rating_triples | Restaurant Ratings | userID placeID rating |
User_features | Restaurant?Customer Data | userID |
Item_features | Restaurant Feature Data | placeID |
配置這個組件我們需要關注的參數有:
時期(Epochs):算法應處理整個訓練數據的次數。這個數字越高,訓練就越充分;但是,訓練會花費更多的時間,并可能導致過度擬合。
批處理大小(Batch size):訓練步驟中使用的訓練示例數。此超參數會影響訓練速度。批處理越大,時間成本時期越短,但可能會增加收斂時間。如果批太大,不適合 GPU/CPU,可能會引發內存錯誤。
Wide 部分優化器(Wide part optimizer):選擇一個優化器,對模型的 wide 部分應用梯度,可以從 AdaGrad 優化器開始多次測試。
Wide 優化器學習速率(Wide optimizer learning rate):輸入 0.0 和 2.0 之間的數字,該數字定義 wide 部分優化器的學習速率。此超參數確定每個訓練步驟的步驟大小,同時不斷接近損失函數的最小值。學習速過高可能導致學習跳升超過最小值,而學習率過小可能會導致收斂問題。
交叉特征維度(Crossed feature dimension):通過輸入所需的用戶 ID 和項目 ID 特征來鍵入此維度。默認情況下,Wide & Deep 推薦器會針對用戶 ID 和項目 ID 特征執行跨產品轉換。將根據此數字對交叉結果進行哈希處理,以確保維持該維度。
Deep 部分優化器(Deep part optimizer):選擇一個優化器,對模型的 deep 部分應用梯度。
Deep 優化器學習速率(Deep optimizer learning rate):輸入介于 0.0 和 2.0 之間的數字,該數字定義 deep 部分優化器的學習速率。
用戶嵌套維度(User embedding dimension):鍵入整數以指定用戶 ID 嵌套的維度。Wide & Deep 推薦器會為 Wide 部分和 Deep 部分創建共享的用戶 ID 嵌套和項目 ID 嵌套。
嵌套維度(Item embedding dimension):鍵入整數以指定項目 ID 嵌套的維度。
分類特征嵌套維度(Categorical features embedding dimension):輸入整數以指定分類特征嵌套的維度。在 Wide & Deep 推薦器的 deep 組件中,會針對每個分類特征習得一個嵌套矢量。這些嵌套矢量具有相同的維度。
隱藏單位(Hidden units):鍵入 deep 組件的隱藏節點數。每個層中的節點數用逗號分隔。例如,可以通過類型“1000,500,100”指定 deep 組件有三個層,第一層到最后一層分別有1000個節點、500個節點和100個節點。
激活函數(Activation function):選擇一個應用于每個層的激活函數,基本上就選 ReLU 就對了。
丟棄(Dropout):輸入 0.0 和 1.0 之間的數字,以確定訓練期間每個層中丟棄輸出的概率。丟棄是一種可以防止神經網絡過度擬合的正則化方法。關于此值的一個常見決策是從 0.5 開始,對于許多網絡和任務而言,這一值似乎都接近最優值。
批標準化(Batch Normalization):選擇此選項可在 deep 組件中的每個隱藏層之后使用批標準化。批標準化是應對網絡訓練中內部協變量偏移問題的一種技術。一般來說,它可以幫助提高網絡的速度、性能和穩定性。
▍Score Wide and Deep Recommender 節點
Wide and Deep 推薦器評分有兩種選擇
對用戶給出評級的預測:對輸入的用戶的特征,尋找和他相近用戶對目標的評價。
給用戶推薦:提供用戶和項目列表作為輸入。在此數據中,該模型利用其關于現有項目和用戶的知識來生成可能對每個用戶都具有吸引力的項目列表。可以自定義返回的建議數,并為生成建議所需的先前建議數設置閾值。
▍Evaluate Recommender 節點
我們會得到幾個回歸問題常用的評估指標:
MAE(Mean Absolute Error,平均絕對誤差),這個指標通常用來反映預測值誤差的實際情況(風險度)。
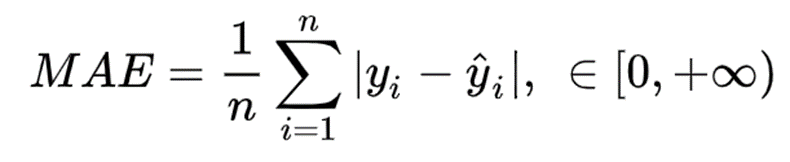
通常用于在連續變量數據上測量性能。它對異常值不是很敏感,因為它不會懲罰錯誤。
RMSE(Root Mean Square Error,均方根誤差) 是回歸模型的典型指標,常用于衡量模型預測結果的標準。
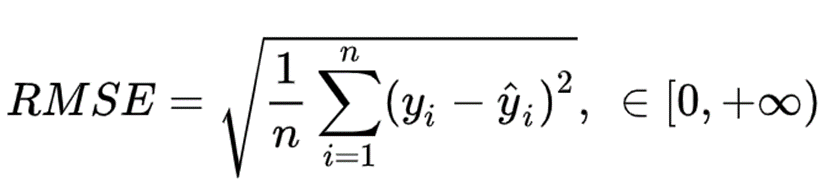
在 RMSE 中,誤差在平均之前先平方,這意味著 RMSE 為更大的錯誤分配更高的權重。這表明當存在大錯誤并且它們會極大地影響模型的性能時,RMSE 更有用。RMSE 比 MSE 更廣泛用于評估回歸模型于其他隨機模型的性能,因為它的因變量(Y軸)具有相同的單位。
R2 判別系數。對于回歸類算法而言,只探索數據預測是否準確是不足夠的。除了數據本身的數值大小之外,我們還希望我們的模型能夠捕捉到數據的“規律”,比如數據的分布規律,單調性等等,而是否捕獲了這些信息并無法使用 MSE 來衡量。R2 測量了回歸直線對預測數據擬合的程度。
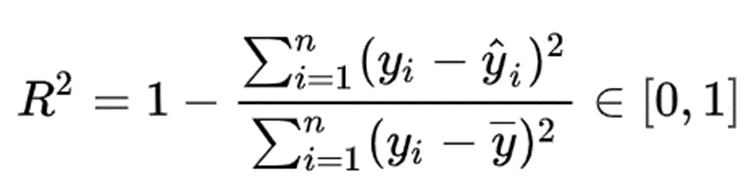
分子是真實值和預測值之差的差值,也就是我們的模型沒有捕獲到的信息總量,分母是真實標簽所帶的信息量,所以兩者都衡量 1 - 我們的模型沒有捕獲到的信息量占真實標簽中所帶的信息量的比例,所以,兩者都是越接近1越好。
如果結果是0,說明模型擬合效果很差;
如果結果是1,說明模型無錯誤。
Explained Variance(可解釋變異)用方差來量化變異,故又稱為可解釋方差(explained variance)。
結束語

到這里,Wide & Deep based Recommendation - Restaurant Rating Prediction 案例的分析我們完成了,在這個過程中,我們詳細的了解到各個節點的核心信息和相關的概念。從數據源、數據處理到模型質量報告,也同時接觸到了大量的機器學習概念,本篇非常值得推薦作為 Microsoft Azure Machine Learning Studio 和機器學習的入門和深入讀物。
在這之后,我將繼續編寫其他 Microsoft Azure Machine Learning Studio 案例。每一篇案例都可以獨立閱讀,因此有些概念會重復出現在每一篇中。
微軟最有價值專家(MVP)

微軟最有價值專家是微軟公司授予第三方技術專業人士的一個全球獎項。29年來,世界各地的技術社區領導者,因其在線上和線下的技術社區中分享專業知識和經驗而獲得此獎項。
MVP是經過嚴格挑選的專家團隊,他們代表著技術最精湛且最具智慧的人,是對社區投入極大的熱情并樂于助人的專家。MVP致力于通過演講、論壇問答、創建網站、撰寫博客、分享視頻、開源項目、組織會議等方式來幫助他人,并最大程度地幫助微軟技術社區用戶使用 Microsoft 技術。
更多詳情請登錄官方網站:
https://mvp.microsoft.com/zh-cn
![]()
了解如何使用 Azure 機器學習訓練和部署模型以及管理 ML 生命周期 (MLOps)。教程、代碼示例、API 參考和其他資源。


點擊「閱讀原文」獲取相關文檔~








yi_meng linux 下 ifcfg-eth0 配置 以及ifconfig、ifup、ifdown區別)





)




