簡介
在之前的文章中,我們多次提到 Vector - SIMD 技術,也答應大家在后面分享更多.NET7 中優化的例子,今天就帶來一個使用 SIMD 優化Guid.Equals()方法性能的例子。
為什么 Guid 能使用 SIMD 優化?
首先就需要介紹一些背景知識,那就是Guid它是什么,在我們人類眼中,Guid就是一串字符串,如下方所示的那樣。
"D313CD46-2724-7359-84A0-9E73C861CCD2"而在定義中,全局唯一標識符(GUID,Globally Unique Identifier)是一種由算法生成的二進制長度為128 位的數字標識符。GUID 主要用于在擁有多個節點、多臺計算機的網絡或系統中。在理想情況下,任何計算機和計算機集群都不會生成兩個相同的 GUID。GUID 的總數達到了 2^128(3.4×10^38)個,所以隨機生成兩個相同 GUID 的可能性非常小,但并不為 0。GUID 一詞有時也專指微軟對 UUID 標準的實現。
大家可以看到我著重標記了它的位數是128 位,128 位意味著什么?就是如果比較兩個 Guid 是否相等的話,不管是 64 位 CPU 還是 32 位的 CPU 需要多條指令比較多次。如果我們用上了 Vector?是不是會有更好的性能呢?
首先我們來看看 Guid 是如何定義的,看看能不能直接讀取 128 位數據,從而用上 Vector。Guid 它是值類型的,是一個結構體。代碼如下所示,我省略了部分信息。
public?readonly?partial?struct?Guid{...private?readonly?int?_a;???//?Do?not?rename?(binary?serialization)private?readonly?short?_b;?//?Do?not?rename?(binary?serialization)private?readonly?short?_c;?//?Do?not?rename?(binary?serialization)private?readonly?byte?_d;??//?Do?not?rename?(binary?serialization)private?readonly?byte?_e;??//?Do?not?rename?(binary?serialization)private?readonly?byte?_f;??//?Do?not?rename?(binary?serialization)private?readonly?byte?_g;??//?Do?not?rename?(binary?serialization)private?readonly?byte?_h;??//?Do?not?rename?(binary?serialization)private?readonly?byte?_i;??//?Do?not?rename?(binary?serialization)private?readonly?byte?_j;??//?Do?not?rename?(binary?serialization)private?readonly?byte?_k;??//?Do?not?rename?(binary?serialization)...}可以看到它由 1 個 32 位 int,2 個 16 位的 short 和 8 個 8 位的 byte 組成,至于為什么需要這樣組成,其實是一個標準化的東西,為了在生成和序列化時更快。
我們使用ObjectLayoutInspector可以打印出 Guid 的數據結構,數據結果如下圖所示,和我們源碼里面看到的一致:
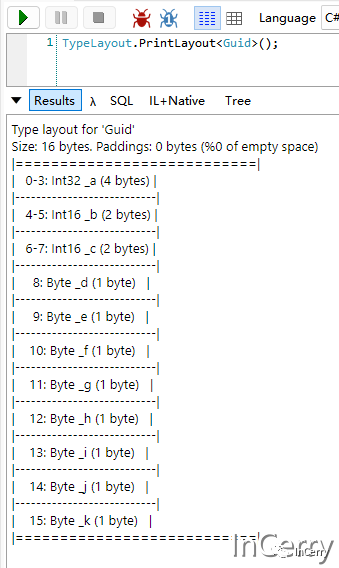
那么 Guid 是否能使用 SIMD 優化的結論顯而易見:
Guid 有 128 位,現在 CPU 都是 64 位或者 32 位,還存在提升空間
Guid 是結構體類型,結構體類型在內存中是連續存儲,我們可以直接讀取內存來訪問整個結構體
SIMD 優化代碼
根據我們前面文章中,Min 和 Max 方法在.NET7 被優化的經驗,我們可以直接寫下面這樣的代碼。
[MethodImpl(MethodImplOptions.AggressiveInlining)]
private?static?bool?EqualsCore(in?Guid?left,?in?Guid?right)
{//?檢測硬件是否支持Vector128if?(Vector128.IsHardwareAccelerated){//?支持Vector128就好辦了,直接加載比較return?Vector128.LoadUnsafe(ref?Unsafe.As<Guid,?byte>(ref?Unsafe.AsRef(in?left)))?==?Vector128.LoadUnsafe(ref?Unsafe.As<Guid,?byte>(ref?Unsafe.AsRef(in?right)));}//?如果不支持,那么從Guid頭部讀取內存//?32位比較四次ref?int?rA?=?ref?Unsafe.AsRef(in?left._a);ref?int?rB?=?ref?Unsafe.AsRef(in?right._a);return?rA?==?rB&&?Unsafe.Add(ref?rA,?1)?==?Unsafe.Add(ref?rB,?1)&&?Unsafe.Add(ref?rA,?2)?==?Unsafe.Add(ref?rB,?2)&&?Unsafe.Add(ref?rA,?3)?==?Unsafe.Add(ref?rB,?3);
}在上面的代碼中,我們可以看到不僅提供了 Vector 加速的方案,還有不支持回退的場景。不過那段 Vector 代碼是不是不太好理解?我們逐個部分來解析一下。我們首先看左右的部分,右邊也是同樣的意思Vector128.LoadUnsafe(ref Unsafe.As<Guid, byte>(ref Unsafe.AsRef(in left)))。
ref Unsafe.AsRef(in left)是獲取 left Guid 它的首地址指針,此時返回的其實是Guid*ref Unsafe.As<Guid, byte>(...)將Guid*指針轉換為byte*指針Vector128.LoadUnsafe(...)由于 Guid 已經變為 Byte 指針,所以就能直接 LoadUnsafe 了
最后 right Guid 也使用相同的方式加載,最后使用==比較兩個Vector是否相等就好了。其實==還使用了CompareEqual和MoveMask兩個指令,只是在.NET7 中 JIT 會把兩個向量的比較給優化。看下方圖片中紅色框標記的部分,就是這兩個指令。
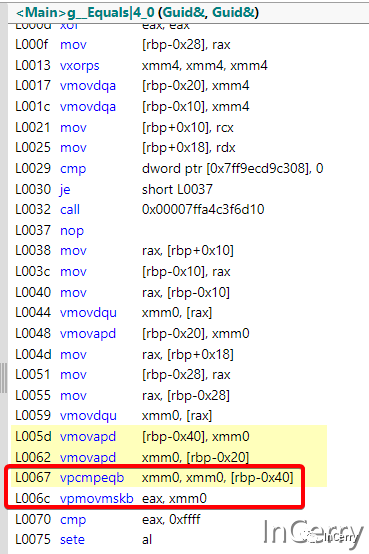
那么.NET6 下==沒有優化,那該怎么辦呢?根據這里的匯編指令,Meziantou[1]大佬給出了.NET6 下同樣功效的優化代碼:
static?class?GuidExtensions
{public?static?bool?OptimizedGuidEquals(in?Guid?left,?in?Guid?right){if?(Sse2.IsSupported){Vector128<byte>?leftVector?=?Unsafe.ReadUnaligned<Vector128<byte>>(ref?Unsafe.As<Guid,?byte>(ref?Unsafe.AsRef(in?left)));Vector128<byte>?rightVector?=?Unsafe.ReadUnaligned<Vector128<byte>>(ref?Unsafe.As<Guid,?byte>(ref?Unsafe.AsRef(in?right)));//?使用Sse2.CompareEqual()比較是否相等,它的返回值是一個128位向量,如果相等,該位置返回0xffff,否則返回0x0//?CompareEqual的結果是128位的,我們可以通過Sse2.MoveMask()來重新排列成16位,最終看是否等于0xffff就好var?equals?=?Sse2.CompareEqual(leftVector,?rightVector);var?result?=?Sse2.MoveMask(equals);return?(result?&?0xFFFF)?==?0xFFFF;}return?left?==?right;}
}從下圖的匯編代碼中,可以看到是一樣的效果: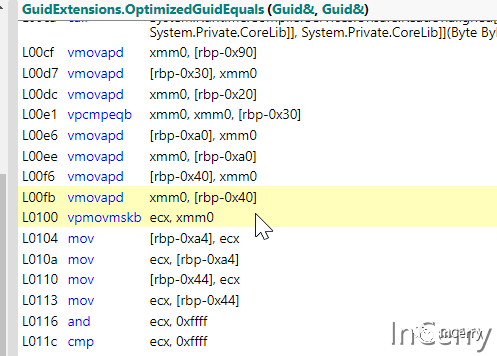
總結
最終這一波操作下來,我們可以看到Guid.Equals的性能提升了 30%。如果你的程序中使用 Guid 作為數據庫、對象主鍵的,只需要升級.NET7 或者用上面的GuidExtensions就能獲得這樣的性能提升。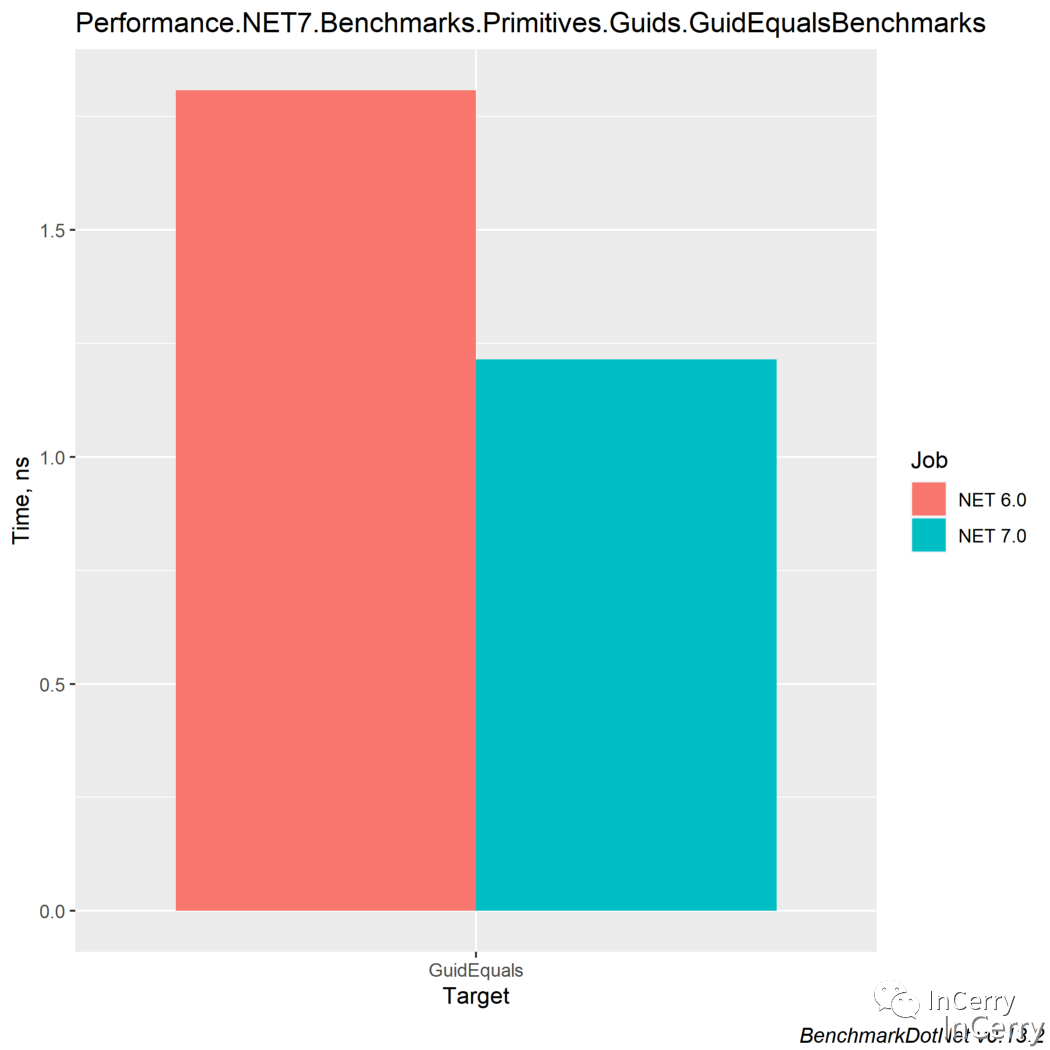
參考資料
[1]
Meziantou: https://www.meziantou.net/faster-guid-comparisons-using-vectors-simd-in-dotnet.htm


 用 distance 和 advance 把 const_iterator 轉化成 iterator...)


第四篇)




錄屏軟件正式發布)


。A.計算機及相關設備制造業B.稀有...)





