BS4
Beautiful Soup,Beautiful Soup?是一個可以從HTML或XML文件中提取數據的Python庫.它能夠通過你喜歡的轉換器實現慣用的文檔導航,查找,修改文檔的方式。
安裝
pip3 install beautifulsoup4
使用
from bs4 import BeautifulSoup#html_doc為網頁內容
soup = BeautifulSoup(html_doc, 'html.parser')tags=soup.find_all()
#獲取所有標簽
for tag in tags:print(tag.name)#針對 scriptif tag.name='script'#刪除標簽tag.decompose()#過濾后的soup
content=str(soup)# 截取文本內容前150字符 .text表示文本
desc=soup.text[0:150]note:
其實還是需要解析器的,但是這里用自帶的。如下:
pip install html5lib
解析器對比:
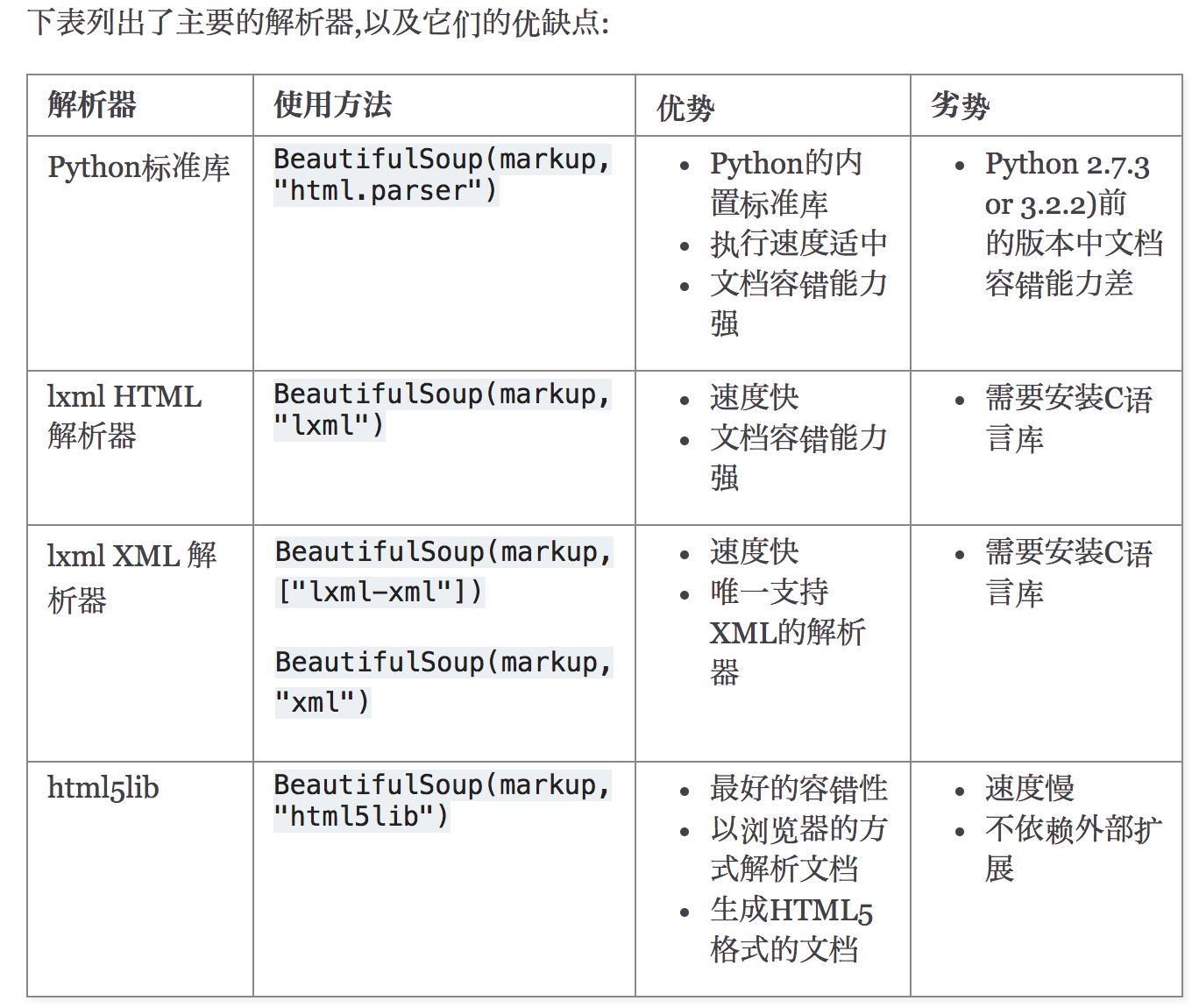
官方文檔
編輯器kindeditor
官方查看資料:http://kindeditor.net/docs/option.html#extrafileuploadparams
編輯器上傳圖片
1.網頁
<script charset="utf-8" src="/static/kindeditor/kindeditor.js"></script><script>KindEditor.ready(function (K) {window.editor = K.create('#id_content',{width : '100%',height : '700px',resizeType: '1',uploadJson : '/upload_image/',extraFileUploadParams : {'csrfmiddlewaretoken':'{{ csrf_token }}'}});});</script>uploadJson :設置圖片url,圖片往url發送,所以增加路由url處理 extraFileUploadParams : 額外參數,這里是post發送,所以需要發送校驗。
2.url.py
# 編輯器上傳圖片借口re_path(r'^upload_image/',views.upload_image),3.視圖層views.py
# 上傳圖片
import os
from BBS_Virtualenvs import settings
def upload_image(request):"""//成功時{"error" : 0,"url" : "http://www.example.com/path/to/file.ext"}//失敗時{"error" : 1,"message" : "錯誤信息"}:param request::return:"""back_dic = {'error': 0, } # 先定義返回給編輯器的數據形式# 用戶上傳圖片 也算是靜態資源 應該放在防盜media文件夾下if request.method == 'POST':# 獲取用戶上傳圖片對象print(request.FILES) #打印查看鍵名字 imgFilefile_obj =request.FILES.get('imgFile')# 手動拼接存儲文件的路徑file_dir=os.path.join(settings.BASE_DIR,'media','article_img')# 優化操作 先判斷當前文件是否存在 如果不存在 自動創建if not os.path.isdir(file_dir):os.mkdir(file_dir) #創建目錄 article_imgfile_path=os.path.join(file_dir,file_obj.name)with open(file_path,'wb') as f:for line in file_obj:f.write(line)# 返回文件路徑名字 也需要手動拼接# 為什么不用file_path? /BBS_Virtualenvs/media 不能作為網頁連接,沒有暴露資源back_dic['url']='/media/article_img/%s'%file_obj.namereturn JsonResponse(back_dic)參考:https://www.cnblogs.com/Dominic-Ji/p/9637705.html



















