點擊上方藍字
關注我們
(本文閱讀時間:7分鐘)
語言是人類智能發展的基石。鑒于語言擁有普遍性,幾乎沒有特定的技術或 AI 技術得以顛覆整個社會。微軟的使命是賦能地球上的每個人和每個組織,幫助他們取得更多成就。立足于該使命,Azure 語言認知服務團隊將繼續為世界各地的客戶提供自然語言處理服務,打破語言障礙。我們的 AI 語言產品提供最先進的語言模型,讓客戶能從各種文本中提取、分析和檢索有意義的見解。
Azure 語言認知服務產品提供靈活性,以滿足您在多個能力領域的業務需求。無論您是一家處于高速增長期的初創公司,希望在與客戶通話后立即獲得一份簡明摘要以提高團隊的生產力,還是一家希望了解國外客戶情感的美國公司,亦或是一家希望實現智能、個性化會話服務的客服中心。?
近期,我們很高興地推出了 Azure 語言認知服務的新特性和功能,包括對會話進行敘述總結和分章、對文檔進行抽象化總結、增強型客服中心語言 AI 功能、針對情感分析、意見挖掘和關鍵詞提取提供90多種語言支持服務、提供針對命名實體提取的24多種語言支持服務、文檔翻譯工作室新體驗、自定義文本分類資產版本管理支持服務、自定義 NER 和對話語言理解,以及動態模型版本管理服務,以簡化模型制作過程。
通過文本摘要服務加快業務發展
由于一天只有24小時,難道您不希望在工作時可以隨時使用 TL; DR 嗎?請試想一下,如果不只是對一份文件,而是對數千份文件,進行 TL; DR 操作! 還有,如果您能在每次通話結束時都能獲得一份簡明扼要的通話總結,那么您就不必做大量的筆記,并閱讀所有的內容來獲取關鍵信息。為了解決這一問題,我們提供新工具,進一步提高總結文本和會話信息的能力。
統一的 API 語音服務允許客戶對文檔進行抽象化總結,對會話信息進行敘述性總結以及分章,以便客戶快速了解所有的工作內容,在幾分鐘內找到關鍵信息。這三個新的預覽功能是在 Z-Code++ 環境下運行的,它是微軟最新最先進的預訓練編碼器語言模型。
會話信息敘事式總結和分章
通過使用這兩個新功能,客戶可以總結自己的聊天記錄和語音記錄,并劃分章節。這些新功能適用于日常會話和會議場景,是對適用于客戶支持和呼叫中心場景的現有產品(允許客戶對會話期間產生的問題和決議進行總結)的一個補充。
抽象式文檔總結
作為現有抽取式總結功能的補充,抽象式文檔總結功能使用自然語言,對文檔進行總結。這些智能總結服務通過從原始文檔中提取最重要或最相關的信息,而不是簡單地從原始文檔中提取相關句子,使客戶能夠從長文本文檔中獲取最有價值的信息。
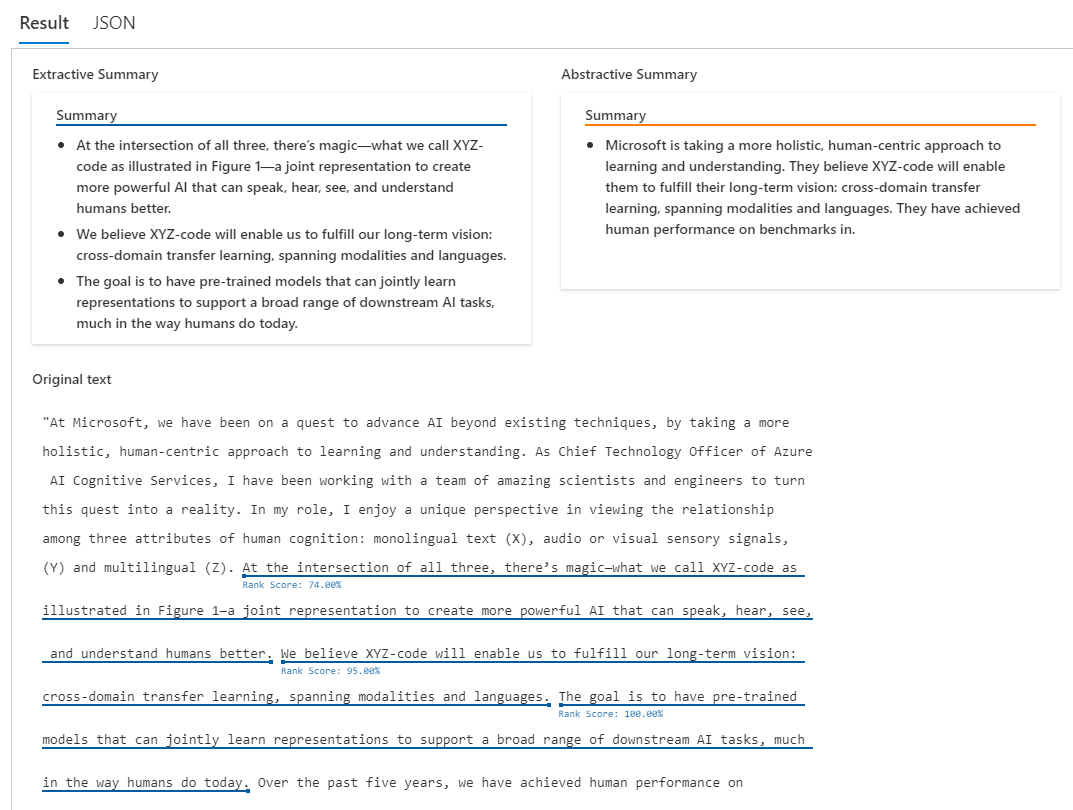
通過擴展的語言支持服務,了解您的客戶,無論他們身在何處
無論您所在的公司是一家在全球范圍內開展業務的大型跨國公司,還是一家希望在國際市場競爭中獲勝的中小型創業公司,了解您的客戶,并提供定制化解決方案,往往需要使用許多工具來處理和了解客戶的意見。由于企業用戶正變得越來越全球化,因此我們擴大了對多語言技能的語言服務支持。
情感分析將支持94種語言(10月15日開始)。
關鍵詞提取將支持94種語言(從10月15日開始)。
命名實體識別將支持24種語言(從10月15日開始)。
用于健康文本分析將支持7種語言(從10月15日開始)。
觀點挖掘將支持94種語言(從11月1日開始)。
強大的 AI 功能為客服中心的運營提供驅動力
優秀的客戶服務體驗對公司的成功至關重要,從銷量到客戶忠誠度等方方面面均受到客戶服務的影響。為了幫助您加快改善客服中心客服專員和客戶之間的互動,我們改進了我們的會話系列產品,包括對話語言理解(該功能允許用戶自定義自然語言理解模型,以預測輸入語音的整體意圖),以及回答問題(該功能允許用戶建立對話式客戶端應用程序,如社交媒體應用程序和聊天機器人)。
在今年的微軟 Build 開發者大會上,我們推出了對話中的個人身份信息(PII)檢測功能(允許客戶提取預定義對話中的敏感信息(PII),對其進行編輯),以及對話中遇到的問題和解決方案總結功能(對客服專員與客戶之間的網絡聊天記錄和通話記錄中產生問題和解決方案進行總結)。
為了使您從與客戶溝通中獲得對客戶的可操作的洞察力,我們繼續加強產品的情感分析能力,以支持會話文本。語言工作室呼叫中心分析工具目前推出了試用版,您只需要點擊幾個按鈕,即可體驗語言模型的力量。
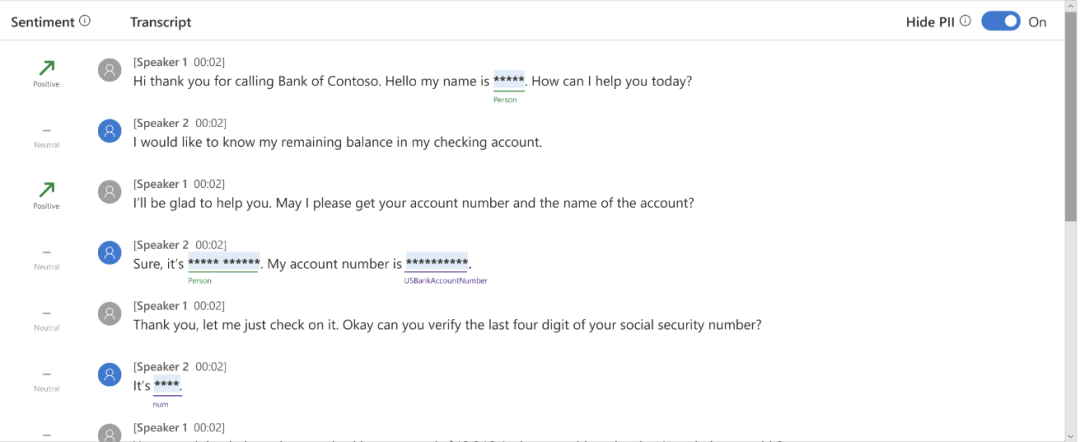
通過新的文檔翻譯工作室,輕松實現文檔的錄入和翻譯
翻譯是實現全球自由溝通的核心所在,而文件包含了大量的關鍵信息。通過使用文檔翻譯器,可以輕松翻譯大多數常見的文檔格式,包括 Word 文檔、PowerPoint 演示文稿、PDF 文件、Excel 表格和純文本。通過 REST APIs 和客戶端庫 SDKs,我們提供100種語言的翻譯服務。從11月1日起,您可以在語言工作室嘗試文檔翻譯的新體驗。只需連接存儲賬戶,上傳文件,并指定翻譯參數,即可實現批量文件翻譯,而無需進行編程或開發操作。
新的服務功能
我們將持續改善今年6月份推出的自定義文本分類、自定義命名實體識別和對話語言理解(CLU)服務。目前,我們的資產版本管理服務可以追蹤模型訓練中所用的不同的數據迭代過程。我們還推出了多區域部署服務,允許客戶在全球范圍內部署模型,并實現多地訪問。此外,CLU 還引入了正則表達式實體組件,來提取自定義模式。命名實體識別服務也將引入實體解析技術,以返回量化類型的其他標準格式,如將 "八十七 "解析為整數87。
API調用更新與通用(GA)版預構建性能
目前的靜態模型版本管理方案無法靈活地提供動態 AI 解決方案。此外,跟蹤模型的版本號和模型廢棄的最后期限是一個復雜的過程。為了解決這個問題,從11月1日起,您無需在 API 調用期間指定 GA 模型的版本號。相反,您可以選擇模型版本參數的“最新”,確保您始終使用最新、最高質量的模型,而不會中斷 API 調用這一進程。對于預覽模型,您可以繼續指定模型版本號。與模型版本不同,API 版本仍可通過 API 調用獲得支持,以確保應用程序的可靠性和穩定性。
*未經授權請勿私自轉載此文章及圖片。
![]()
??掃描下方二維碼,了解更多相關信息


點擊「閱讀原文」了解更多~







)
)




)


![char data[0]在struct末尾的用法](http://pic.xiahunao.cn/char data[0]在struct末尾的用法)


