1、算法思想
QLearning是強化學習算法中value-based的算法,Q即為在某一環境下,Q(state,action)在某一時刻的 s 狀態下(s∈S),采取 動作a (a∈A)動作能夠獲得收益的期望,環境會根據agent的動作反饋相應的回報reward r(分數)。
所以算法的主要思想就是將State與Action構建成一張Q-table來存儲Q值,然后根據Q值來選取能夠獲得最大的收益的動作。

2、實例與核心公式

實例:從起點出發到達終點圓圈為勝利——加分,碰到三角為失敗——扣分。第一輪是隨機走,直到有了得分就會高概率按照高分走。
- 智能體(Agent)——正方體
- 環境狀態(environment)——這里以tk窗體模擬
- 獎勵(reward)——對動作的獎懲分數
- 動作(action)——上下左右
可以將問題抽象成一個馬爾科夫決策過程。
在每個格子都算是一個狀態s
q(a | s)是在s狀態下采取動作a策略
p(s’ | s,a)為在s狀態下選擇a動作轉換到下一個狀態s’的概率
R(s’ | s,a)表示在s狀態下采取a動作轉移到s’的獎勵reward
目標就是找到一條能夠到達終點獲得最大獎賞的策略,獲取最大獎賞公式:
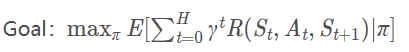
Qlearning的主要優勢就是使用了時間差分法TD(融合了蒙特卡洛和動態規劃)能夠進行離線學習, 使用貝爾曼(bellman)方程可以對馬爾科夫過程求解最優策略。
詳見:時間差分法
核心公式:
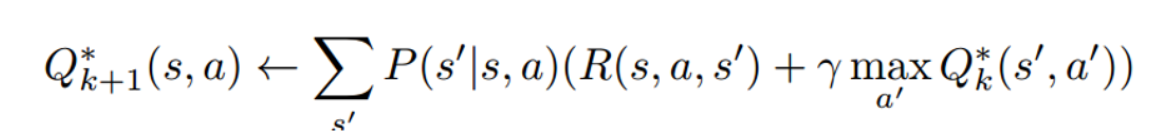
更新公式:
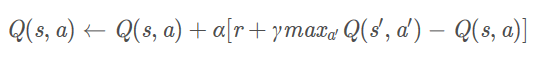
核心代碼:
import numpy as np
import random
from environment import Env
from collections import defaultdictclass QLearningAgent:def __init__(self, actions):# actions = [0, 1, 2, 3]self.actions = actions # 動作self.learning_rate = 0.01 # 學習率self.discount_factor = 0.9 # 折扣因子self.epsilon = 0.1 # [?eps?l?n]self.q_table = defaultdict(lambda: [0.0, 0.0, 0.0, 0.0])# 采樣 <s, a, r, s'>def learn(self, state, action, reward, next_state):current_q = self.q_table[state][action]# 貝爾曼方程更新new_q = reward + self.discount_factor * max(self.q_table[next_state])self.q_table[state][action] += self.learning_rate * (new_q - current_q)# 從Q-table中選取動作def get_action(self, state):if np.random.rand() < self.epsilon:# 貪婪策略隨機探索動作action = np.random.choice(self.actions)else:# 從q表中選擇state_action = self.q_table[state]action = self.arg_max(state_action) # 選組最大效益動作return action# 選取最大分數@staticmethoddef arg_max(state_action):max_index_list = []max_value = state_action[0]for index, value in enumerate(state_action):if value > max_value:max_index_list.clear()max_value = valuemax_index_list.append(index)elif value == max_value:max_index_list.append(index)return random.choice(max_index_list)if __name__ == "__main__":env = Env() # 初始化tk窗口agent = QLearningAgent(actions=list(range(env.n_actions))) # 初始化物體實例for episode in range(1000):state = env.reset()while True:env.render()# agent產生動作action = agent.get_action(str(state))next_state, reward, done = env.step(action)# 更新Q表 -- 核心更新公式agent.learn(str(state), action, reward, str(next_state))state = next_stateenv.print_value_all(agent.q_table)# 當到達終點就終止游戲開始新一輪訓練if done:break另一Q learning 實例:Flappy Bird(飛揚的小鳥 )
Q learning實例:Flappy Bird
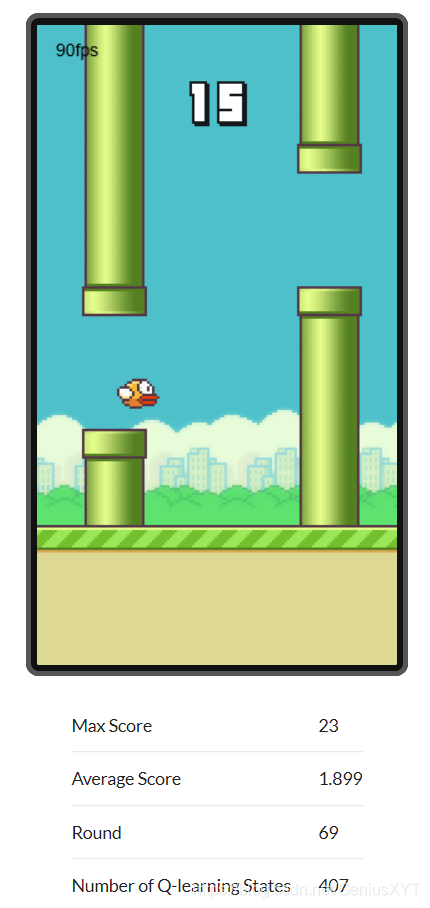







)



)

【轉】)

)

)
)
