
Natural language processing enables computers to process what we’re saying into commands that it can execute. Find out how the basics of how it works, and how it’s being used to improve our lives.
自然語言處理使計算機能夠將我們所說的內容處理成可以執行的命令。 了解其運作方式的基礎知識,以及如何將其用于改善我們的生活。
什么是自然語言處理? (What Is Natural Language Processing?)
Whether it’s Alexa, Siri, Google Assistant, Bixby, or Cortana, everyone with a smartphone or smart speaker has a voice-activated assistant nowadays. Every year, these voice assistants seem to get better at recognizing and executing the things we tell them to do. But have you ever wondered how these assistants process the things we’re saying? They manage to do this thanks to Natural Language Processing, or NLP.
無論是Alexa,Siri,Google Assistant,Bixby還是Cortana,如今每個擁有智能手機或智能揚聲器的人都可以使用聲控助手。 每年,這些語音助手在識別和執行我們告訴他們要做的事情上似乎都變得更好。 但是您是否想知道這些助手如何處理我們所說的話? 他們借助自然語言處理(NLP)設法做到了這一點。
Historically, most software has only been able to respond to a fixed set of specific commands. A file will open because you clicked Open, or a spreadsheet will compute a formula based on certain symbols and formula names. A program communicates using the programming language that it was coded in, and will thus produce an output when it is given input that it recognizes. In this context, words are like a set of different mechanical levers that always provide the desired output.
從歷史上看,大多數軟件只能響應一組固定的特定命令。 一個文件將打開,因為你點擊打開,或電子表格將計算公式基于一定的符號和公式的名稱。 程序使用其編碼所用的編程語言進行通信,因此當獲得可識別的輸入時,它將產生輸出。 在這種情況下,詞語就像總是提供所需輸出的一組不同的機械桿。
This is in contrast to human languages, which are complex, unstructured, and have a multitude of meanings based on sentence structure, tone, accent, timing, punctuation, and context.?Natural Language Processing is a branch of artificial intelligence that attempts to bridge that gap between what a machine recognizes as input and the human language. This is so that when we speak or type naturally, the machine produces an output in line with what we said.
這與人類語言相反,人類語言復雜,無結構,并且具有基于句子結構,語調,重音,時間,標點和上下文的多種含義。 自然語言處理是人工智能的一個分支,它試圖彌合機器識別為輸入的語言與人類語言之間的鴻溝。 這樣一來,當我們自然說話或打字時,機器會產生與我們所說的一致的輸出。
This is done by taking vast amounts of data points to derive meaning from the various elements of the human language, on top of the meanings of the actual words. This process is closely tied with the concept known as machine learning, which enables computers to learn more as they obtain more points of data. That is the reason why most of the natural language processing machines we interact with frequently seem to get better over time.
這是通過在實際單詞的含義之上,通過獲取大量數據點來從人類語言的各個元素中獲取含義來實現的。 該過程與稱為機器學習的概念緊密相關,后者使計算機在獲取更多數據點時可以學習更多。 這就是為什么我們經常與之交互的大多數自然語言處理機器隨著時間的推移而變得越來越好的原因。
To illuminate the concept better, let’s have a look at two of the most top-level techniques used in NLP to process language and information.
為了更好地闡明這一概念,讓我們看一下NLP中用于處理語言和信息的兩種最高級技術。
代幣化 (Tokenization)

Tokenization means splitting up speech into words or sentences. Each piece of text is a token, and these tokens are what show up when your speech is processed. It sounds simple, but in practice, it’s a tricky process.
標記化是指將語音分為單詞或句子。 每一段文本都是一個標記,這些標記是在處理語音時顯示的標記。 聽起來很簡單,但是實際上,這是一個棘手的過程。
Let’s say that you are using text-to-speech software, such as the Google Keyboard, to send a message to a friend. You want to message, “Meet me at the park.” When your phone takes that recording and processes it through Google’s text-to-speech algorithm, Google must then split what you just said into tokens. These tokens would be?“meet,” “me,” “at,” “the,” and “park”.
假設您正在使用文字轉語音軟件(例如Google鍵盤)向朋友發送消息。 您想留言,“在公園認識我”。 當您的手機錄制該記錄并通過Google的語音合成算法對其進行處理時,Google必須將您剛才所說的內容拆分為令牌。 這些標記將是“滿足”,“我”,“在”,“該”和“停放”。
People have different lengths of pauses between words, and other languages may not have very little in the way of an audible pause between words. The tokenization process varies drastically between languages and dialects.
人們在單詞之間的停頓時間長短不同,而其他語言在單詞之間的可聽停頓方面可能不會少。 語言和方言之間的分詞過程大不相同。
詞干和詞法化 (Stemming and Lemmatization)
Stemming and lemmatization both involve the process of removing additions or variations to a root word that the machine can recognize. This is done to make interpretation of speech consistent across different words that all mean essentially the same thing, which makes NLP processing faster.
詞干和詞根去除均涉及刪除機器可以識別的根詞的附加內容或變體的過程。 這樣做的目的是使語音解釋在不同的詞之間保持一致,而這些詞本質上都是同一件事,這使得NLP處理更快。
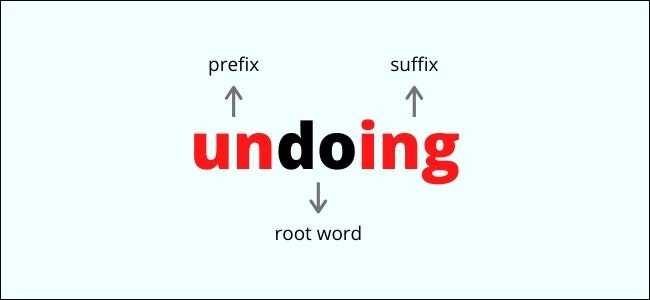
Stemming is a crude fast process that involves removing affixes from a root word, which are additions to a word attached before or after the root. This turns the word into the simplest base form by simply removing letters. For example:
詞干處理是一個粗略的快速過程,涉及從詞根詞中刪除詞綴,詞綴是詞根之前或之后附加詞的附加詞。 只需刪除字母,即可將單詞變成最簡單的基本形式。 例如:
- “Walking” turns into “walk” “走路”變成“走路”
- “Faster” turns into “fast” “更快”變成“快速”
- “Severity” turns into “sever” “嚴重程度”變成“嚴重程度”
As you can see, stemming may have the adverse effect of changing the meaning of a word entirely. “Severity” and “sever” do not mean the same thing, but the suffix “ity” was removed in the process of stemming.
如您所見,詞干可能會對完全改變單詞的含義產生不利影響。 “嚴重性”和“嚴重性”并不相同,但是在詞干處理過程中刪除了后綴“ ity”。
On the other hand, lemmatization is a more sophisticated process that involves reducing a word to their base, known as the?lemma.?This takes into consideration the context of the word and how it’s used in a sentence. It also involves looking up a term in a database of words and their respective lemma. For example:
另一方面,詞義化是一個更復雜的過程,涉及將單詞減少為詞根,即詞義。 這考慮了單詞的上下文及其在句子中的使用方式。 它還涉及在單詞及其各自的引理的數據庫中查找術語。 例如:
- “Are” turns into “be” “是”變成“是”
- “Operation” turns into “operate” “經營”變成“經營”
- “Severity” turns into “severe” “嚴重程度”變成“嚴重程度”
In this example, lemmatization managed to turn the term “severity” into “severe,” which is its lemma form and root word.
在此示例中,詞形化成功將術語“嚴重性”轉換為“嚴重”,這是其詞綴形式和詞根。
NLP用例和未來 (NLP Use Cases and the Future)
The previous examples only begin to scratch the surface of what Natural Language Processing is. It encompasses a wide range of practices and usage scenarios, many of which we use in our daily lives. These are a few examples of where NLP is currently in use:
前面的示例僅開始介紹自然語言處理的內容。 它涵蓋了廣泛的實踐和使用場景,我們在日常生活中使用了許多實踐和使用場景。 以下是一些當前使用NLP的示例:
Predictive Text:?When you type a message on your smartphone, it automatically suggests you words that fit into the sentence or that you’ve used before.
預想文字:當您在智能手機上鍵入信息時,它會自動為您推薦適合該句子或您以前使用過的單詞。
Machine Translation:?Widely used consumer translating services, such as Google Translate, to incorporate a high-level form of NLP to process language and translate it.
機器翻譯:廣泛使用的消費者翻譯服務,例如Google Translate,可以結合高級形式的NLP來處理語言并進行翻譯。
Chatbots:?NLP is the foundation for intelligent chatbots, especially in customer service, where they can assist customers and process their requests before they face a real person.
聊天機器人: NLP是智能聊天機器人的基礎,尤其是在客戶服務中,他們可以在面對真正的人之前幫助客戶并處理他們的請求。
There’s more to come. NLP uses are currently being developed and deployed in fields such as news media, medical technology, workplace management, and finance. There’s a chance we may be able to have a full-fledged sophisticated conversation with a robot in the future.
還有更多。 NLP用途目前正在新聞媒體,醫療技術,工作場所管理和金融等領域開發和部署。 將來,我們有可能與機器人進行全面的復雜對話。
If you’re interested in learning more about NLP, there are a lot of fantastic resources on the Towards Data Science blog or the Standford National Langauge Processing Group that you can check out.
如果您有興趣了解有關NLP的更多信息,可以在Towards Data Science博客或Standford National Langauge Processing Group上找到很多精彩的資源,可以查閱。
翻譯自: https://www.howtogeek.com/665702/what-is-natural-language-processing-and-how-does-it-work/













)


)

)
