03|模型I/O:輸入提示、調用模型、解析輸出
從這節課開始,我們將對 LangChain 中的六大核心組件一一進行詳細的剖析。
模型,位于 LangChain 框架的最底層,它是基于語言模型構建的應用的核心元素,因為所謂 LangChain 應用開發,就是以 LangChain 作為框架,通過 API 調用大模型來解決具體問題的過程。
可以說,整個 LangChain 框架的邏輯都是由 LLM 這個發動機來驅動的。沒有模型,LangChain 這個框架也就失去了它存在的意義。那么這節課我們就詳細講講模型,最后你會收獲一個能夠自動生成鮮花文案的應用程序。
Model I/O
我們可以把對模型的使用過程拆解成三塊,分別是輸入提示(對應圖中的 Format)、調用模型(對應圖中的 Predict)和輸出解析(對應圖中的 Parse)。這三塊形成了一個整體,因此在 LangChain 中這個過程被統稱為 Model I/O(Input/Output)。
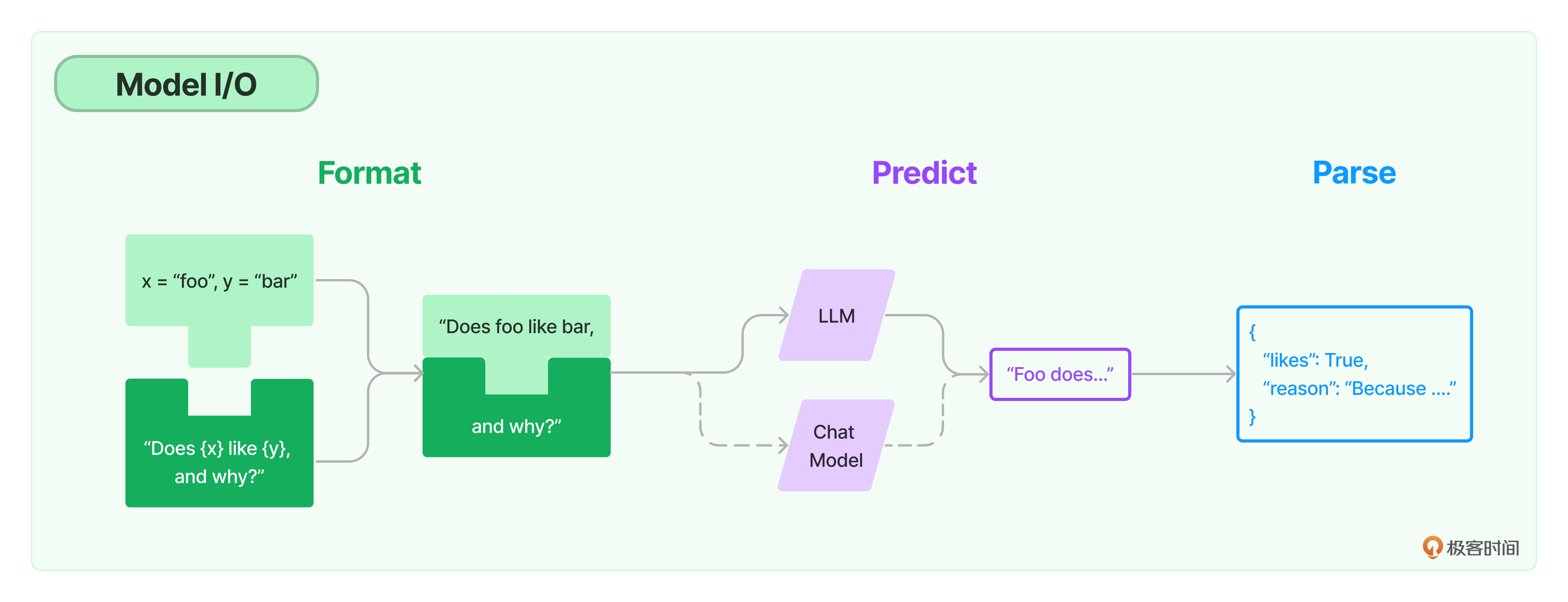
Model I/O:從輸入到輸出
在模型 I/O 的每個環節,LangChain 都為咱們提供了模板和工具,快捷地形成調用各種語言模型的接口。
- 提示模板:使用模型的第一個環節是把提示信息輸入到模型中,你可以創建 LangChain 模板,根據實際需求動態選擇不同的輸入,針對特定的任務和應用調整輸入。
- 語言模型:LangChain 允許你通過通用接口來調用語言模型。這意味著無論你要使用的是哪種語言模型,都可以通過同一種方式進行調用,這樣就提高了靈活性和便利性。
- 輸出解析:LangChain 還提供了從模型輸出中提取信息的功能。通過輸出解析器,你可以精確地從模型的輸出中獲取需要的信息,而不需要處理冗余或不相關的數據,更重要的是還可以把大模型給回的非結構化文本,轉換成程序可以處理的結構化數據。
下面我們用示例的方式來深挖一下這三個環節。先來看看 LangChain 中提示模板的構建。
提示模板
語言模型是個無窮無盡的寶藏,人類的知識和智慧,好像都封裝在了這個“魔盒”里面了。但是,怎樣才能解鎖其中的奧秘,那可就是仁者見仁智者見智了。所以,現在“提示工程”這個詞特別流行,所謂 Prompt Engineering,就是專門研究對大語言模型的提示構建。
我的觀點是,使用大模型的場景千差萬別,因此肯定不存在那么一兩個神奇的模板,能夠騙過所有模型,讓它總能給你最想要的回答。然而,好的提示(其實也就是好的問題或指示啦),肯定能夠讓你在調用語言模型的時候事半功倍。
那其中的具體原則,不外乎吳恩達老師在他的提示工程課程中所說的:
- 給予模型清晰明確的指示
- 讓模型慢慢地思考
說起來很簡單,對吧?是的,道理總是簡單,但是如何具體實踐這些原則,又是個大問題。讓我從創建一個簡單的 LangChain 提示模板開始。
這里,我們希望為銷售的每一種鮮花生成一段簡介文案,那么每當你的員工或者顧客想了解某種鮮花時,調用該模板就會生成適合的文字。
這個提示模板的生成方式如下:
# 導入LangChain中的提示模板
from langchain import PromptTemplate
# 創建原始模板
template = """您是一位專業的鮮花店文案撰寫員。\n
對于售價為 {price} 元的 {flower_name} ,您能提供一個吸引人的簡短描述嗎?
"""
# 根據原始模板創建LangChain提示模板
prompt = PromptTemplate.from_template(template)
# 打印LangChain提示模板的內容
print(prompt)提示模板的具體內容如下:
input_variables=['flower_name', 'price']
output_parser=None partial_variables={}
template='/\n您是一位專業的鮮花店文案撰寫員。
\n對于售價為 {price} 元的 {flower_name} ,您能提供一個吸引人的簡短描述嗎?\n'
template_format='f-string'
validate_template=True在這里,所謂“模板”就是一段描述某種鮮花的文本格式,它是一個 f-string,其中有兩個變量 {flower_name} 和 {price} 表示花的名稱和價格,這兩個值是模板里面的占位符,在實際使用模板生成提示時會被具體的值替換。
代碼中的 from_template 是一個類方法,它允許我們直接從一個字符串模板中創建一個 PromptTemplate 對象。打印出這個 PromptTemplate 對象,你可以看到這個對象中的信息包括輸入的變量(在這個例子中就是 flower_name 和 price)、輸出解析器(這個例子中沒有指定)、模板的格式(這個例子中為'f-string')、是否驗證模板(這個例子中設置為 True)。
因此 PromptTemplate 的 from_template 方法就是將一個原始的模板字符串轉化為一個更豐富、更方便操作的 PromptTemplate 對象,這個對象就是 LangChain 中的提示模板。LangChain 提供了多個類和函數,也為各種應用場景設計了很多內置模板,使構建和使用提示變得容易。我們下節課還會對提示工程的基本原理和 LangChain 中的各種提示模板做更深入的講解。
下面,我們將會使用這個剛剛構建好的提示模板來生成提示,并把提示輸入到大語言模型中。
語言模型
LangChain 中支持的模型有三大類。
- 大語言模型(LLM) ,也叫 Text Model,這些模型將文本字符串作為輸入,并返回文本字符串作為輸出。Open AI 的 text-davinci-003、Facebook 的 LLaMA、ANTHROPIC 的 Claude,都是典型的 LLM。
- 聊天模型(Chat Model),主要代表 Open AI 的 ChatGPT 系列模型。這些模型通常由語言模型支持,但它們的 API 更加結構化。具體來說,這些模型將聊天消息列表作為輸入,并返回聊天消息。
- 文本嵌入模型(Embedding Model),這些模型將文本作為輸入并返回浮點數列表,也就是 Embedding。而文本嵌入模型如 OpenAI 的 text-embedding-ada-002,我們之前已經見過了。文本嵌入模型負責把文檔存入向量數據庫,和我們這里探討的提示工程關系不大。
然后,我們將調用語言模型,讓模型幫我們寫文案,并且返回文案的結果。
# 設置OpenAI API Key
import os
os.environ["OPENAI_API_KEY"] = '你的Open AI API Key'# 導入LangChain中的OpenAI模型接口
from langchain import OpenAI
# 創建模型實例
model = OpenAI(model_name='text-davinci-003')
# 輸入提示
input = prompt.format(flower_name=["玫瑰"], price='50')
# 得到模型的輸出
output = model(input)
# 打印輸出內容
print(output) input = prompt.format(flower_name=["玫瑰"], price='50') 這行代碼的作用是將模板實例化,此時將 {flower_name} 替換為 "玫瑰",{price} 替換為 '50',形成了具體的提示:“您是一位專業的鮮花店文案撰寫員。對于售價為 50 元的玫瑰,您能提供一個吸引人的簡短描述嗎?”
接收到這個輸入,調用模型之后,得到的輸出如下:
讓你心動!50元就可以擁有這支充滿浪漫氣息的玫瑰花束,讓TA感受你的真心愛意。
復用提示模板,我們可以同時生成多個鮮花的文案。
# 導入LangChain中的提示模板
from langchain import PromptTemplate
# 創建原始模板
template = """您是一位專業的鮮花店文案撰寫員。\n
對于售價為 {price} 元的 {flower_name} ,您能提供一個吸引人的簡短描述嗎?
"""
# 根據原始模板創建LangChain提示模板
prompt = PromptTemplate.from_template(template)
# 打印LangChain提示模板的內容
print(prompt)# 設置OpenAI API Key
import os
os.environ["OPENAI_API_KEY"] = '你的Open AI API Key'# 導入LangChain中的OpenAI模型接口
from langchain import OpenAI
# 創建模型實例
model = OpenAI(model_name='text-davinci-003')# 多種花的列表
flowers = ["玫瑰", "百合", "康乃馨"]
prices = ["50", "30", "20"]# 生成多種花的文案
for flower, price in zip(flowers, prices):# 使用提示模板生成輸入input_prompt = prompt.format(flower_name=flower, price=price)# 得到模型的輸出output = model(input_prompt)# 打印輸出內容print(output)模型的輸出如下:
這支玫瑰,深邃的紅色,傳遞著濃濃的深情與浪漫,令人回味無窮!百合:美麗的花朵,多彩的愛戀!30元讓你擁有它!康乃馨—20元,象征愛的祝福,送給你最真摯的祝福。
你也許會問我,在這個過程中,使用 LangChain 的意義究竟何在呢?我直接調用 Open AI 的 API,不是完全可以實現相同的功能嗎?
的確如此,讓我們來看看直接使用 Open AI API 來完成上述功能的代碼。
import openai # 導入OpenAI
openai.api_key = 'Your-OpenAI-API-Key' # API Keyprompt_text = "您是一位專業的鮮花店文案撰寫員。對于售價為{}元的{},您能提供一個吸引人的簡短描述嗎?" # 設置提示flowers = ["玫瑰", "百合", "康乃馨"]
prices = ["50", "30", "20"]# 循環調用Text模型的Completion方法,生成文案
for flower, price in zip(flowers, prices):prompt = prompt_text.format(price, flower)response = openai.Completion.create(engine="text-davinci-003",prompt=prompt,max_tokens=100)print(response.choices[0].text.strip()) # 輸出文案上面的代碼是直接使用 Open AI 和帶有 {} 占位符的提示語,同時生成了三種鮮花的文案。看起來也是相當簡潔。
不過,如果你深入思考一下,你就會發現 LangChain 的優勢所在。**我們只需要定義一次模板,就可以用它來生成各種不同的提示。**對比單純使用 f-string 來格式化文本,這種方法更加簡潔,也更容易維護。而 LangChain 在提示模板中,還整合了 output_parser、template_format 以及是否需要 validate_template 等功能。
更重要的是,使用 LangChain 提示模板,我們還可以很方便地把程序切換到不同的模型,而不需要修改任何提示相關的代碼。
下面,我們用完全相同的提示模板來生成提示,并發送給 HuggingFaceHub 中的開源模型來創建文案。(注意:需要注冊 HUGGINGFACEHUB_API_TOKEN)
# 導入LangChain中的提示模板
from langchain import PromptTemplate
# 創建原始模板
template = """You are a flower shop assitiant。\n
For {price} of {flower_name} ,can you write something for me?
"""
# 根據原始模板創建LangChain提示模板
prompt = PromptTemplate.from_template(template)
# 打印LangChain提示模板的內容
print(prompt)
import os
os.environ['HUGGINGFACEHUB_API_TOKEN'] = '你的HuggingFace API Token'
# 導入LangChain中的OpenAI模型接口
from langchain import HuggingFaceHub
# 創建模型實例
model= HuggingFaceHub(repo_id="google/flan-t5-large")
# 輸入提示
input = prompt.format(flower_name=["rose"], price='50')
# 得到模型的輸出
output = model(input)
# 打印輸出內容
print(output)輸出:
i love you
真是一分錢一分貨,當我使用較早期的開源模型 T5,得到了很粗糙的文案 “i love you”(哦,還要注意 T5 還沒有支持中文的能力,我把提示文字換成英文句子,結構其實都沒變)。
當然,這里我想要向你傳遞的信息是:你可以重用模板,重用程序結構,通過 LangChain 框架調用任何模型。如果你熟悉機器學習的訓練流程的話,這 LangChain 是不是讓你聯想到 PyTorch 和 TensorFlow 這樣的框架——模型可以自由選擇、自主訓練,而調用模型的框架往往是有章法、而且可復用的。
因此,使用 LangChain 和提示模板的好處是:
- 代碼的可讀性:使用模板的話,提示文本更易于閱讀和理解,特別是對于復雜的提示或多變量的情況。
- 可復用性:模板可以在多個地方被復用,讓你的代碼更簡潔,不需要在每個需要生成提示的地方重新構造提示字符串。
- 維護:如果你在后續需要修改提示,使用模板的話,只需要修改模板就可以了,而不需要在代碼中查找所有使用到該提示的地方進行修改。
- 變量處理:如果你的提示中涉及到多個變量,模板可以自動處理變量的插入,不需要手動拼接字符串。
- 參數化:模板可以根據不同的參數生成不同的提示,這對于個性化生成文本非常有用。
那我們就接著介紹模型 I/O 的最后一步,輸出解析。
輸出解析
LangChain 提供的解析模型輸出的功能,使你能夠更容易地從模型輸出中獲取結構化的信息,這將大大加快基于語言模型進行應用開發的效率。
為什么這么說呢?請你思考一下剛才的例子,你只是讓模型生成了一個文案。這段文字是一段字符串,正是你所需要的。但是,在開發具體應用的過程中,很明顯我們不僅僅需要文字,更多情況下我們需要的是程序能夠直接處理的、結構化的數據。
比如說,在這個文案中,如果你希望模型返回兩個字段:
- description:鮮花的說明文本
- reason:解釋一下為何要這樣寫上面的文案
那么,模型可能返回的一種結果是:
A:“文案是:讓你心動!50 元就可以擁有這支充滿浪漫氣息的玫瑰花束,讓 TA 感受你的真心愛意。為什么這樣說呢?因為愛情是無價的,50 元對應熱戀中的情侶也會覺得值得。”
上面的回答并不是我們在處理數據時所需要的,我們需要的是一個類似于下面的 Python 字典。
B:{description: “讓你心動!50 元就可以擁有這支充滿浪漫氣息的玫瑰花束,讓 TA 感受你的真心愛意。” ; reason: “因為愛情是無價的,50 元對應熱戀中的情侶也會覺得值得。”}
那么從 A 的籠統言語,到 B 這種結構清晰的數據結構,如何自動實現?這就需要 LangChain 中的輸出解析器上場了。
下面,我們就通過 LangChain 的輸出解析器來重構程序,讓模型有能力生成結構化的回應,同時對其進行解析,直接將解析好的數據存入 CSV 文檔。
# 通過LangChain調用模型
from langchain import PromptTemplate, OpenAI# 導入OpenAI Key
import os
os.environ["OPENAI_API_KEY"] = '你的OpenAI API Key'# 創建原始提示模板
prompt_template = """您是一位專業的鮮花店文案撰寫員。
對于售價為 {price} 元的 {flower_name} ,您能提供一個吸引人的簡短描述嗎?
{format_instructions}"""# 創建模型實例
model = OpenAI(model_name='text-davinci-003')# 導入結構化輸出解析器和ResponseSchema
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
# 定義我們想要接收的響應模式
response_schemas = [ResponseSchema(name="description", description="鮮花的描述文案"),ResponseSchema(name="reason", description="問什么要這樣寫這個文案")
]
# 創建輸出解析器
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)# 獲取格式指示
format_instructions = output_parser.get_format_instructions()
# 根據原始模板創建提示,同時在提示中加入輸出解析器的說明
prompt = PromptTemplate.from_template(prompt_template, partial_variables={"format_instructions": format_instructions}) # 數據準備
flowers = ["玫瑰", "百合", "康乃馨"]
prices = ["50", "30", "20"]# 創建一個空的DataFrame用于存儲結果
import pandas as pd
df = pd.DataFrame(columns=["flower", "price", "description", "reason"]) # 先聲明列名for flower, price in zip(flowers, prices):# 根據提示準備模型的輸入input = prompt.format(flower_name=flower, price=price)# 獲取模型的輸出output = model(input)# 解析模型的輸出(這是一個字典結構)parsed_output = output_parser.parse(output)# 在解析后的輸出中添加“flower”和“price”parsed_output['flower'] = flowerparsed_output['price'] = price# 將解析后的輸出添加到DataFrame中df.loc[len(df)] = parsed_output # 打印字典
print(df.to_dict(orient='records'))# 保存DataFrame到CSV文件
df.to_csv("flowers_with_descriptions.csv", index=False)輸出:
[{'flower': '玫瑰', 'price': '50', 'description': 'Luxuriate in the beauty of this 50 yuan rose, with its deep red petals and delicate aroma.', 'reason': 'This description emphasizes the elegance and beauty of the rose, which will be sure to draw attention.'},
{'flower': '百合', 'price': '30', 'description': '30元的百合,象征著堅定的愛情,帶給你的是溫暖而持久的情感!', 'reason': '百合是象征愛情的花,寫出這樣的描述能讓顧客更容易感受到百合所帶來的愛意。'},
{'flower': '康乃馨', 'price': '20', 'description': 'This beautiful carnation is the perfect way to show your love and appreciation. Its vibrant pink color is sure to brighten up any room!', 'reason': 'The description is short, clear and appealing, emphasizing the beauty and color of the carnation while also invoking a sense of love and appreciation.'}]
這段代碼中,首先定義輸出結構,我們希望模型生成的答案包含兩部分:鮮花的描述文案(description)和撰寫這個文案的原因(reason)。所以我們定義了一個名為 response_schemas 的列表,其中包含兩個 ResponseSchema 對象,分別對應這兩部分的輸出。
根據這個列表,我通過 StructuredOutputParser.from_response_schemas 方法創建了一個輸出解析器。
然后,我們通過輸出解析器對象的 get_format_instructions() 方法獲取輸出的格式說明(format_instructions),再根據原始的字符串模板和輸出解析器格式說明創建新的提示模板(這個模板就整合了輸出解析結構信息)。再通過新的模板生成模型的輸入,得到模型的輸出。此時模型的輸出結構將盡最大可能遵循我們的指示,以便于輸出解析器進行解析。
對于每一個鮮花和價格組合,我們都用 output_parser.parse(output) 把模型輸出的文案解析成之前定義好的數據格式,也就是一個 Python 字典,這個字典中包含了 description 和 reason 這兩個字段的值。
parsed_output
{'description': 'This 50-yuan rose is... feelings.', 'reason': 'The description is s...y emotion.'}
len(): 2最后,把所有信息整合到一個 pandas DataFrame 對象中(需要安裝 Pandas 庫)。這個 DataFrame 對象中包含了 flower、price、description 和 reason 這四個字段的值。其中,description 和 reason 是由 output_parser 從模型的輸出中解析出來的,flower 和 price 是我們自己添加的。
我們可以打印出 DataFrame 的內容,也方便地在程序中處理它,比如保存為下面的 CSV 文件。因為此時數據不再是模糊的、無結構的文本,而是結構清晰的有格式的數據。輸出解析器在這個過程中的功勞很大。



)









)


 ssh的解決辦法)



