介紹
我們知道,把神經網絡拆解,可以把它歸結為幾個元素的排列組合而成,例如,以卷積神經網絡為例,其主要由卷積層,池化層,殘差連接,注意力層,全連接層等組成,如果我們把它們抽象,就可抽象為一個個cell塊拼接而成。每個cell塊內部可由卷積操作(例如分組卷積,分組數為2或者4),卷積后通道數,卷積核大小,內部殘差連接,復制前面模塊的數量等參數構成。而cell塊之間又可相互連接構成稀疏或者稠密連接構成整體的網絡。
神經結構搜索(NAS)能夠自動搜索構建神經網絡結構,它以上述的cell塊組成部分以及cell塊之間的關聯關系作為搜索空間,自動探測符合任務的神經網絡結構。這篇論文就是基于神經結構搜索自動搜索構建出超分辨率網絡結構,主要以遺傳算法進行建模優化。
模型建立
模型的結構示意圖如下:
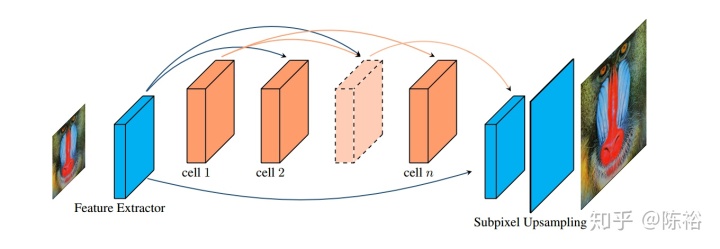
輸入為低分辨率圖像,中間特征抽取由一個個cell模塊組成,最后輸出利用亞像素上采樣獲取。亞像素采樣可由如下圖操作方式處理:
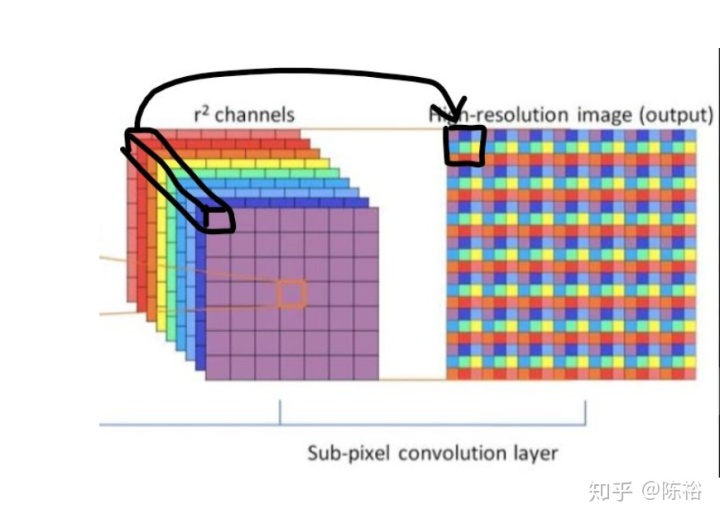
將最后一層卷積層輸出的通道平鋪開來,得到最終的高分辨率圖像。
神經架構搜索主要是自動搜索出特征抽取層。從宏觀上看,搜索空間主要為cell間的連接關系。定義
從微觀上看,先從cell內部上看,設計由以下幾個部分組成搜索空間:
1.卷積,其中卷積采用分組卷積,分組數可選為[2,4]。輸出的形狀類似于倒置的瓶狀,擴展率為2
2.通道數選擇為:[16,32,48,64]
3.卷積核大小選擇為:[1,3]
4.是否帶有內部的殘差連接:[true,false]
5.重復的塊數:[1,2,4]
那么,總共會有:
ps:論文中說有192種,論文中選擇的搜索空間組成如下圖,沒理解出怎么會有192種,而且卷積的選擇inverted bottleneck block with an expansion rate of 2也不確定到底怎么處理,具體代碼也沒放出來。這些不影響我們對整體算法思想的理解,如果有了解的,請評論講解下。。。

總共有
故整體網絡的編碼由
模型生成
模型生成過程以遺傳算法為主,具體為帶精英策略的非支配排序的遺傳算法(NSGA-II)。具體算法步驟如下:
1.初始化。初始化種群
2.得到新父種群。對
這里介紹下Paerot支配關系。
對于最小化多目標問題,對于多目標向量
若對于
若對于
若對于
而快速支配排序算法步驟如下:
(1)依次遍歷每個個體,記錄下非支配個體數量
(2)取
(3)對序號為
支配排序用到下面這三個量組成的向量:
(1)PSNR(峰值信噪比),對于兩幅圖像,計算方法如下:
其中n為每像素的比特數.
(2)計算的花費
(3)參數的數量
之后計算擁擠度距離,這里的擁擠度距離計算方法如下:
(1):對于排序號為
(2):針對目標函數排序,如果排序后個體在邊界,則設置擁擠度距離為inf,否則按下式計算:
具體看參見論文Improved Crowding Distance for NSGA-II。
先按
3.選擇。選擇使用二進制錦標賽法,即從種群中隨機選擇2個個體,更優的留下。
4.交叉。選擇得到的個體,隨機選擇位置交互編碼的元素,例如,
對于模型A,其編碼為
對于模型B,其編碼為
而生成的模型C,則分別對
5.變異。
對于個體中的每個需要變異的cell塊,隨機生成一個隨機數
若
$S$中選擇一個cell。若
若
而對于整體的cell組成連接結構,則利用RNN構成的控制器作為強化模型進行選擇變異。結構圖如下:
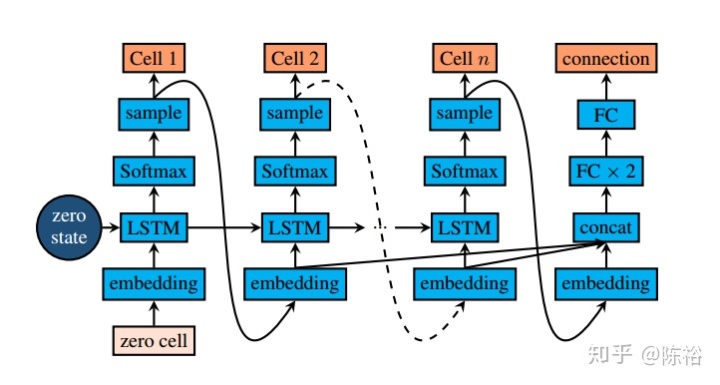
最后一層輸入由前面所有的嵌入層向量拼接而成,通過一個三層的全連接網絡輸出,最后輸出的全連接神經元數量為
模型由兩個參數組成,LSTM參數
其中
訓練得到的網絡分別對宏觀結構進行變異。
6.令
總結
NAS可以幫助我們自動構建神經網絡結構,只要數據足夠,就能夠得到足夠優秀的網絡。人也不失為經歷這一過程,通過數據,自動識別各種物體,然后最后把識別的知識綜合起來做推理。
這篇論文提供了NAS的一種設計方式,以cell塊為主,從微觀和宏觀空間上,定義搜索空間,并對其進行編碼,以NSGA-II算法作為優化算法,之后組合得到理想的網絡結構。
參考文獻
Fast, Accurate and Lightweight Super-Resolution with Neural Architecture Search
https://www.jianshu.com/p/ae5157c26af9
https://www.cnblogs.com/bnuvincent/p/5268786.html
https://blog.csdn.net/weixin_43202635/article/details/82708916
Improved Crowding Distance for NSGA-II

 - 寫給小白看的Clang編譯過程原理)




)
)


)








