xxl-job
系統說明
安裝
安裝部署參考文檔:分布式任務調度平臺xxl-job
功能
定時調度、服務解耦、靈活控制跑批時間(停止、開啟、重新設定時間、手動觸發)
XXL-JOB是一個輕量級分布式任務調度平臺,其核心設計目標是開發迅速、學習簡單、輕量級、易擴展。現已開放源代碼并接入多家公司線上產品線,開箱即用
概念
執行器列表:一個執行器是一個項目
任務:一個任務是一個項目中的 JobHandler
一個xxl-job服務可以有多個執行器(項目),一個項目下可以有多個任務(JobHandler),他們是如何關聯的?
頁面操作:
- 在管理平臺可以新增執行器(項目)
- 在任務列表可以指定執行器(項目)下新增多個任務(JobHandler)
代碼操作:
- 項目配置中增加 xxl.job.executor.appname = "執行器名稱"
- 在實現類中增加 @JobHandler(value="xxl-job-demo") 注解,并繼承 IJobHandler
架構圖
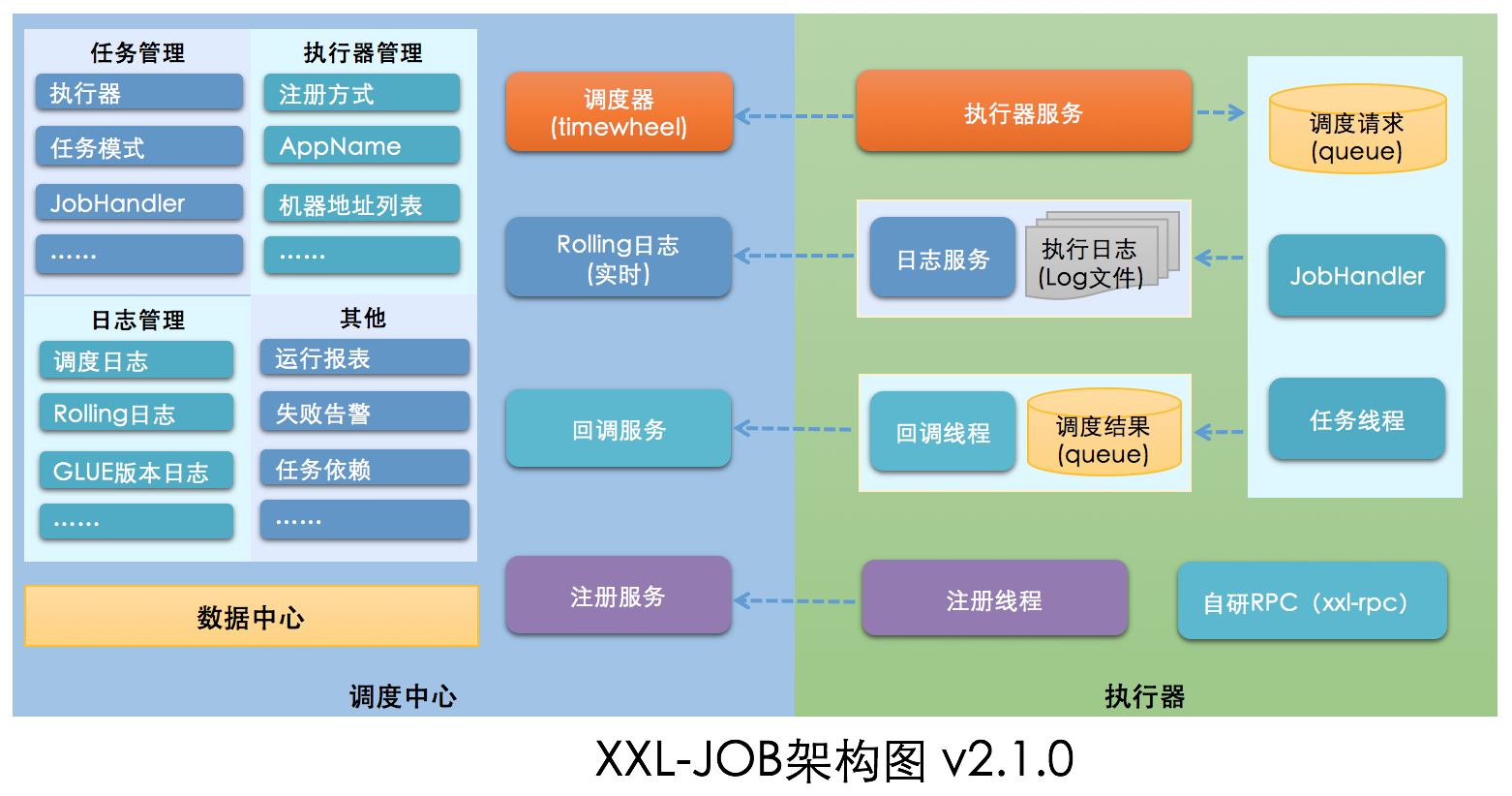
拋出疑問
- 調度中心啟動過程?
- 執行器啟動過程?
- 執行器如何注冊到調度中心?
- 調度中心怎么調用執行器?
- 集群調度時如何控制一個任務在該時刻不會重復執行
- 集群部署應該注意什么?
系統分析
執行器依賴jar包
com.xuxueli:xxl-job-core:2.1.0
com.xuxueli:xxl-registry-client:1.0.2
com.xuxueli:xxl-rpc-core:1.4.1
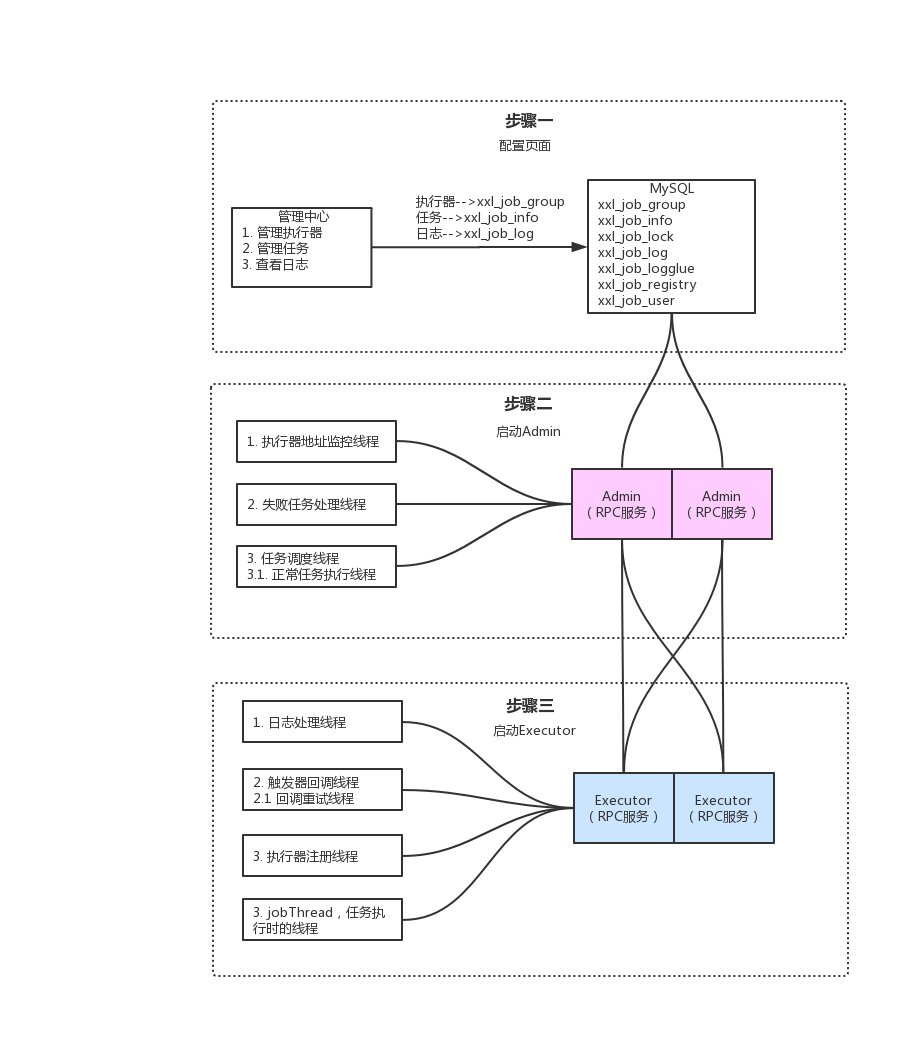
調度中心啟動過程
// 1. 加載 XxlJobAdminConfig,adminConfig = this
XxlJobAdminConfig.java// 啟動過程代碼
@Component
public class XxlJobScheduler implements InitializingBean, DisposableBean {private static final Logger logger = LoggerFactory.getLogger(XxlJobScheduler.class);@Overridepublic void afterPropertiesSet() throws Exception {// init i18ninitI18n();// admin registry monitor run// 2. 啟動注冊監控器(將注冊到register表中的IP加載到group表)/ 30執行一次JobRegistryMonitorHelper.getInstance().start();// admin monitor run// 3. 啟動失敗日志監控器(失敗重試,失敗郵件發送)JobFailMonitorHelper.getInstance().start();// admin-server// 4. 初始化RPC服務initRpcProvider();// start-schedule// 5. 啟動定時任務調度器(執行任務,緩存任務)JobScheduleHelper.getInstance().start();logger.info(">>>>>>>>> init xxl-job admin success.");}......
}執行器啟動過程
@Override
public void start() throws Exception {// init JobHandler Repository// 將執行 JobHandler 注冊到緩存中 jobHandlerRepository(ConcurrentMap)initJobHandlerRepository(applicationContext);// refresh GlueFactory// 刷新GLUEGlueFactory.refreshInstance(1);// super start// 核心啟動項super.start();
}public void start() throws Exception {// 初始化日志路徑 // private static String logBasePath = "/data/applogs/xxl-job/jobhandler";XxlJobFileAppender.initLogPath(this.logPath);// 初始化注冊中心列表 (把注冊地址放到 List)this.initAdminBizList(this.adminAddresses, this.accessToken);// 啟動日志文件清理線程 (一天清理一次)// 每天清理一次過期日志,配置參數必須大于3才有效JobLogFileCleanThread.getInstance().start((long)this.logRetentionDays);// 開啟觸發器回調線程TriggerCallbackThread.getInstance().start();// 指定端口this.port = this.port > 0 ? this.port : NetUtil.findAvailablePort(9999);// 指定IPthis.ip = this.ip != null && this.ip.trim().length() > 0 ? this.ip : IpUtil.getIp();// 初始化RPC 將執行器注冊到調度中心 30秒一次this.initRpcProvider(this.ip, this.port, this.appName, this.accessToken);
}執行器注冊到調度中心
執行器
// 注冊執行器入口
XxlJobExecutor.java->initRpcProvider()->xxlRpcProviderFactory.start();// 開啟注冊
XxlRpcProviderFactory.java->start();// 執行注冊
ExecutorRegistryThread.java->start();
// RPC 注冊代碼
for (AdminBiz adminBiz: XxlJobExecutor.getAdminBizList()) {try {ReturnT<String> registryResult = adminBiz.registry(registryParam);if (registryResult!=null && ReturnT.SUCCESS_CODE == registryResult.getCode()) {registryResult = ReturnT.SUCCESS;logger.debug(">>>>>>>>>>> xxl-job registry success, registryParam:{}, registryResult:{}", new Object[]{registryParam, registryResult});break;} else {logger.info(">>>>>>>>>>> xxl-job registry fail, registryParam:{}, registryResult:{}", new Object[]{registryParam, registryResult});}} catch (Exception e) {logger.info(">>>>>>>>>>> xxl-job registry error, registryParam:{}", registryParam, e);}}調度中心
// RPC 注冊服務
AdminBizImpl.java->registry();數據庫

調度中心調用執行器
/* 調度中心執行步驟 */
// 1. 調用執行器
XxlJobTrigger.java->runExecutor();// 2. 獲取執行器
XxlJobScheduler.java->getExecutorBiz();// 3. 調用
ExecutorBizImpl.java->run();/* 執行器執行步驟 */
// 1. 執行器接口
ExecutorBiz.java->run();// 2. 執行器實現
ExecutorBizImpl.java->run();// 3. 把jobInfo 從 jobThreadRepository (ConcurrentMap) 中獲取一個新線程,并開啟新線程
XxlJobExecutor.java->registJobThread();// 4. 保存到當前線程隊列
JobThread.java->pushTriggerQueue();// 5. 執行
JobThread.java->handler.execute(triggerParam.getExecutorParams());調度中心(Admin)
實現 org.springframework.beans.factory.InitializingBean類,重寫 afterPropertiesSet 方法,在初始化bean的時候都會執行該方法
DisposableBean spring停止時執行
結束加載項
- 停止定時任務調度器(中斷scheduleThread,中斷ringThread)
- 停止觸發線程池(JobTriggerPoolHelper)
- 停止注冊監控器(registryThread)
- 停止失敗日志監控器(monitorThread)
- 停止RPC服務(stopRpcProvider)
手動執行方式
JobInfoController.java
@RequestMapping("/trigger")
@ResponseBody
//@PermissionLimit(limit = false)
public ReturnT<String> triggerJob(int id, String executorParam) {// force cover job paramif (executorParam == null) {executorParam = "";}JobTriggerPoolHelper.trigger(id, TriggerTypeEnum.MANUAL, -1, null, executorParam);return ReturnT.SUCCESS;
}定時調度策略
調度策略執行圖
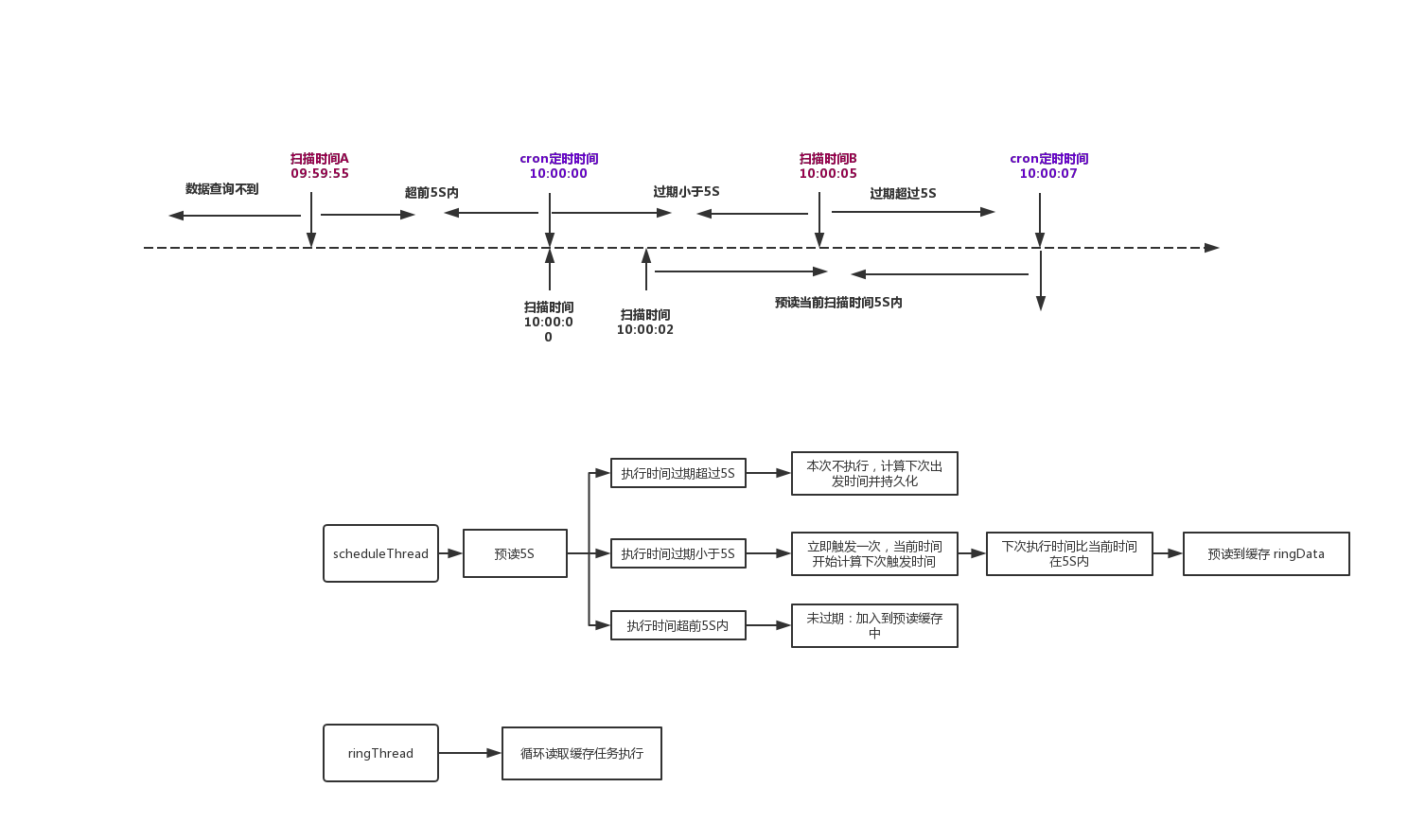
調度策略源碼
JobScheduleHelper.java->start();路由策略
第一個
固定選擇第一個機器
ExecutorRouteFirst.java->route();最后一個
固定選擇最后一個機器
ExecutorRouteLast.java->route();輪詢
隨機選擇在線的機器
ExecutorRouteRound.java->route();private static int count(int jobId) {// cache clearif (System.currentTimeMillis() > CACHE_VALID_TIME) {routeCountEachJob.clear();CACHE_VALID_TIME = System.currentTimeMillis() + 1000*60*60*24;}// count++Integer count = routeCountEachJob.get(jobId);count = (count==null || count>1000000)?(new Random().nextInt(100)):++count; // 初始化時主動Random一次,緩解首次壓力routeCountEachJob.put(jobId, count);return count;
}隨機
隨機獲取地址列表中的一個
ExecutorRouteRandom.java->route();一致性HASH
一個job通過hash算法固定使用一臺機器,且所有任務均勻散列在不同機器
ExecutorRouteConsistentHash.java->route();public String hashJob(int jobId, List<String> addressList) {// ------A1------A2-------A3------// -----------J1------------------TreeMap<Long, String> addressRing = new TreeMap<Long, String>();for (String address: addressList) {for (int i = 0; i < VIRTUAL_NODE_NUM; i++) {long addressHash = hash("SHARD-" + address + "-NODE-" + i);addressRing.put(addressHash, address);}}long jobHash = hash(String.valueOf(jobId));// 取出鍵值 >= jobHashSortedMap<Long, String> lastRing = addressRing.tailMap(jobHash);if (!lastRing.isEmpty()) {return lastRing.get(lastRing.firstKey());}return addressRing.firstEntry().getValue();
}最不經常使用
使用頻率最低的機器優先被選舉
把地址列表加入到內存中,等下次執行時剔除無效的地址,判斷地址列表中執行次數最少的地址取出
頻率、次數
ExecutorRouteLFU.java->route();public String route(int jobId, List<String> addressList) {// cache clearif (System.currentTimeMillis() > CACHE_VALID_TIME) {jobLfuMap.clear();CACHE_VALID_TIME = System.currentTimeMillis() + 1000*60*60*24;}// lfu item initHashMap<String, Integer> lfuItemMap = jobLfuMap.get(jobId); // Key排序可以用TreeMap+構造入參Compare;Value排序暫時只能通過ArrayList;if (lfuItemMap == null) {lfuItemMap = new HashMap<String, Integer>();jobLfuMap.putIfAbsent(jobId, lfuItemMap); // 避免重復覆蓋}// put newfor (String address: addressList) {if (!lfuItemMap.containsKey(address) || lfuItemMap.get(address) >1000000 ) {// 0-n隨機數,包括0不包括nlfuItemMap.put(address, new Random().nextInt(addressList.size())); // 初始化時主動Random一次,緩解首次壓力}}// remove oldList<String> delKeys = new ArrayList<>();for (String existKey: lfuItemMap.keySet()) {if (!addressList.contains(existKey)) {delKeys.add(existKey);}}if (delKeys.size() > 0) {for (String delKey: delKeys) {lfuItemMap.remove(delKey);}}/*********************** 優化 START ***********************/// 優化 remove old部分Iterator<String> iterable = lfuItemMap.keySet().iterator();while (iterable.hasNext()) {String address = iterable.next();if (!addressList.contains(address)) {iterable.remove();}}/*********************** 優化 START ***********************/// load least userd count address// 從小到大排序List<Map.Entry<String, Integer>> lfuItemList = new ArrayList<Map.Entry<String, Integer>>(lfuItemMap.entrySet());Collections.sort(lfuItemList, new Comparator<Map.Entry<String, Integer>>() {@Overridepublic int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {return o1.getValue().compareTo(o2.getValue());}});Map.Entry<String, Integer> addressItem = lfuItemList.get(0);String minAddress = addressItem.getKey();addressItem.setValue(addressItem.getValue() + 1);return addressItem.getKey();
}最近最久未使用
最久未使用的機器優先被選舉
用鏈表的方式存儲地址,第一個地址使用后下次該任務過來使用第二個地址,依次類推(PS:有點類似輪詢策略)
與輪詢策略的區別:
- 輪詢策略是第一次隨機找一臺機器執行,后續執行會將索引加1取余
- 輪詢策略依賴 addressList 的順序,如果這個順序變了,索引到下一次的機器可能不是期望的順序
- LRU算法第一次執行會把所有地址加載進來并緩存,從第一個地址開始執行,即使 addressList 地址順序變了也不影響
次數
ExecutorRouteLRU.java->route();public String route(int jobId, List<String> addressList) {// cache clearif (System.currentTimeMillis() > CACHE_VALID_TIME) {jobLRUMap.clear();CACHE_VALID_TIME = System.currentTimeMillis() + 1000*60*60*24;}// init lruLinkedHashMap<String, String> lruItem = jobLRUMap.get(jobId);if (lruItem == null) {/*** LinkedHashMap* a、accessOrder:ture=訪問順序排序(get/put時排序);false=插入順序排期;* b、removeEldestEntry:新增元素時將會調用,返回true時會刪除最老元素;可封裝LinkedHashMap并重寫該方法,比如定義最大容量,超出是返回true即可實現固定長度的LRU算法;*/lruItem = new LinkedHashMap<String, String>(16, 0.75f, true);jobLRUMap.putIfAbsent(jobId, lruItem);}/*********************** 舉個例子 START ***********************/// 如果accessOrder為true的話,則會把訪問過的元素放在鏈表后面,放置順序是訪問的順序 // 如果accessOrder為flase的話,則按插入順序來遍歷LinkedHashMap<String, String> lruItem = new LinkedHashMap<String, String>(16, 0.75f, true);jobLRUMap.putIfAbsent(1, lruItem);lruItem.put("192.168.0.1", "192.168.0.1");lruItem.put("192.168.0.2", "192.168.0.2");lruItem.put("192.168.0.3", "192.168.0.3");String eldestKey = lruItem.entrySet().iterator().next().getKey();String eldestValue = lruItem.get(eldestKey);System.out.println(eldestValue + ": " + lruItem);eldestKey = lruItem.entrySet().iterator().next().getKey();eldestValue = lruItem.get(eldestKey);System.out.println(eldestValue + ": " + lruItem);// 輸出結果:192.168.0.1: {192.168.0.2=192.168.0.2, 192.168.0.3=192.168.0.3, 192.168.0.1=192.168.0.1}
192.168.0.2: {192.168.0.3=192.168.0.3, 192.168.0.1=192.168.0.1, 192.168.0.2=192.168.0.2}/*********************** 舉個例子 END ***********************/// put newfor (String address: addressList) {if (!lruItem.containsKey(address)) {lruItem.put(address, address);}}// remove oldList<String> delKeys = new ArrayList<>();for (String existKey: lruItem.keySet()) {if (!addressList.contains(existKey)) {delKeys.add(existKey);}}if (delKeys.size() > 0) {for (String delKey: delKeys) {lruItem.remove(delKey);}}// loadString eldestKey = lruItem.entrySet().iterator().next().getKey();String eldestValue = lruItem.get(eldestKey);return eldestValue;
}故障轉移
按照順序依次進行心跳檢測,第一個心跳檢測成功的機器選定為目標執行器并發起調度
ExecutorRouteFailover.java->route();忙碌轉移
按照順序依次進行空閑檢測,第一個空閑檢測成功的機器選定為目標執行器并發起調度
ExecutorRouteBusyover.java->route();分片廣播
廣播觸發對應集群中所有機器執行一次任務,同時傳遞分片參數;可根據分片參數開發分片任務
阻塞處理策略
為了解決執行線程因并發問題、執行效率慢、任務多等原因而做的一種線程處理機制,主要包括 串行、丟棄后續調度、覆蓋之前調度,一般常用策略是串行機制
ExecutorBlockStrategyEnum.javaSERIAL_EXECUTION("Serial execution"), // 串行
DISCARD_LATER("Discard Later"), // 丟棄后續調度
COVER_EARLY("Cover Early"); // 覆蓋之前調度ExecutorBizImpl.java->run();// executor block strategy
if (jobThread != null) {ExecutorBlockStrategyEnum blockStrategy = ExecutorBlockStrategyEnum.match(triggerParam.getExecutorBlockStrategy(), null);if (ExecutorBlockStrategyEnum.DISCARD_LATER == blockStrategy) {// discard when runningif (jobThread.isRunningOrHasQueue()) {return new ReturnT<String>(ReturnT.FAIL_CODE, "block strategy effect:"+ExecutorBlockStrategyEnum.DISCARD_LATER.getTitle());}} else if (ExecutorBlockStrategyEnum.COVER_EARLY == blockStrategy) {// kill running jobThreadif (jobThread.isRunningOrHasQueue()) {removeOldReason = "block strategy effect:" + ExecutorBlockStrategyEnum.COVER_EARLY.getTitle();jobThread = null;}} else {// just queue trigger}
}單機串行
對當前線程不做任何處理,并在當前線程的隊列里增加一個執行任務
丟棄后續調度
如果當前線程阻塞,后續任務不再執行,直接返回失敗
覆蓋之前調度
創建一個移除原因,新建一個線程去執行后續任務
運行模式
ExecutorBizImpl.java->run();BEAN
java里的bean對象
GLUE(Java)
利用java的反射機制,通過代碼字符串生成實體類
IJobHandler originJobHandler = GlueFactory.getInstance().loadNewInstance(triggerParam.getGlueSource());GroovyClassLoaderGLUE(Shell Python PHP Nodejs PowerShell)
按照文件命名規則創建一個執行腳本文件和一個日志輸出文件,通過腳本執行器執行
失敗重試次數
任務失敗后記錄到 xxl_job_log 中,由失敗監控線程查詢處理失敗的任務且失敗次數大于0,繼續執行
任務超時時間
把超時時間給 triggerParam 觸發參數,在調用執行器的任務時超時時間,有點類似HttpClient的超時時間
執行器(Exector)
注冊自己的機器地址
注冊項目中的 JobHandler
提供被調度中心調用的接口
public interface ExecutorBiz {/*** 供調度中心檢測機器是否存活** beat* @return*/public ReturnT<String> beat();/*** 供調度中心檢測機器是否空閑** @param jobId* @return*/public ReturnT<String> idleBeat(int jobId);/*** kill* @param jobId* @return*/public ReturnT<String> kill(int jobId);/*** log* @param logDateTim* @param logId* @param fromLineNum* @return*/public ReturnT<LogResult> log(long logDateTim, long logId, int fromLineNum);/*** 執行觸發器* * @param triggerParam* @return*/public ReturnT<String> run(TriggerParam triggerParam);}
總結
學到了什么
- 算法(LFU、LRU、輪詢等)
- JDK動態代理對象(詳細研究)
- 用到了Netty(詳細研究)
- FutureTask
- GroovyClassLoader



)

控件背景色更改)





)





中的backlog含義)

