在linux下一般用while read line與for循環按行讀取文件。這兩種方法有什么區別呢?
現有如下test.txt文件:
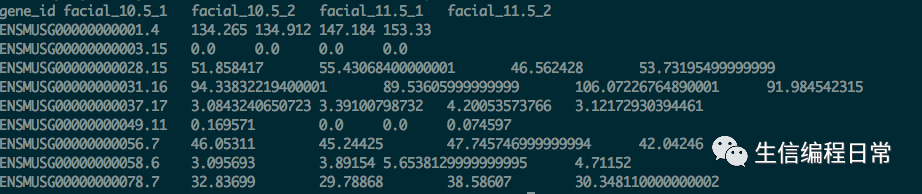
1
while read line
while?read?line; do
??echo?$line
done?< test.txt輸出結果與上圖一致。
這里也可以寫為:
cat test.txt | while?read?line; do
??echo?$line
done輸出結果一致,但是需要注意一點,就是在如下情況下結果是不同的:
# 第一種情況
while?read?line; do?
??name1=$line;
done?< test.txt
echo?$name1
# 第二種情況:
cat test.txt | while?read?line; do
??name2=$line
done
echo?$name2在第一種情況下輸出:
ENSMUSG00000000078.7 32.83699 29.78868 38.58607 30.348110000000002
第二種情況則無輸出。
出現這種不同,是因為管道的機制,這個使用管道之后while read line是在子shell中進行的,所以退出之后$name2就沒有值了。并且,cat 會一次性地把test.txt的所有內容都輸入到內存,假如文件很大,則會占用很大的內存。但是第二種重定向的方法,是一行一行的讀入,更省內存。
2
for循環
for?i in?`cat test.txt`;do
??echo?$i
done但是輸出了這樣的結果(部分結果):
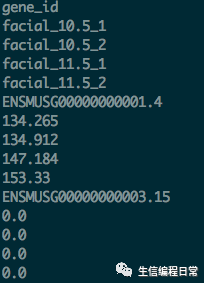
這是因為,在for循環中,每次是以空格/制表符為分割符輸出。可以寫成以下形式輸出:
# 可以先將空格轉為別的字符
for?i in?`sed 's/\t/#/g'?test.txt`;do
??echo?$i?| sed 's/#/\t/g'
done先將空格或者制表符替換為其他字符,輸出的時候再替換回來即可。








)









 - 每天5分鐘玩轉 OpenStack(53))
