1. 前言
反反復復搗鼓了很久,終于開始學習Spark的源碼了,果不其然,那真的很有趣。這里我打算一本正經的胡說八道來講一下Spark作業的提交過程。
基礎mac系統基礎環境如下:
- JDK 1.8
- IDEA 2019.3
- 源碼Spark 2.3.3
- Scala 2.11.8
- 提交腳本
- # 事先準備好的Spark任務(源碼example LocalPi)基于local模式
bash spark-submit
--class com.lp.test.app.LocalPi
--master local
/Users/lipan/Desktop/spark-local/original-spark-local-train-1.0.jar
10
2. 提交流程
我們在提交Spark任務時都是從spark-submit(或者spark-shell)來提交一個作業的,從spark-submit腳本一步步深入進去看看任務的整體提交流程。首先看一下整體的流程概要圖:
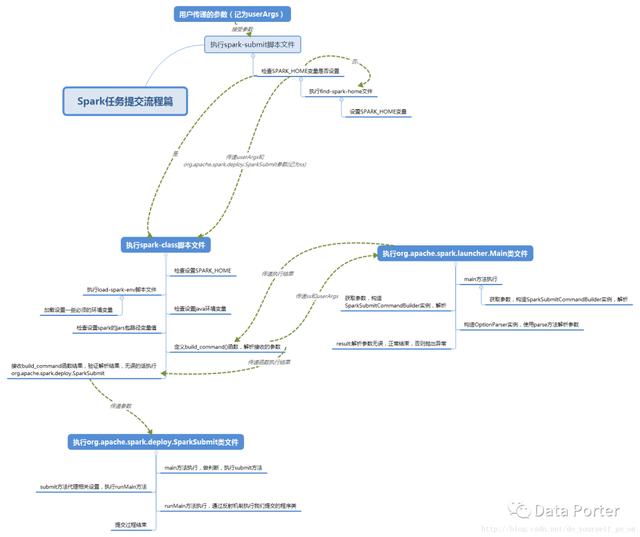
根據上圖中的整體流程,接下來我們對里面的每一個流程的源碼進行一一剖析跟蹤。
2.1 spark-submit腳本
#!/usr/bin/env bash## 如果SPARK_HOME變量沒有設置值,則執行當前目錄下的find-spark-home腳本文件,設置SPARK_HOME值if [ -z "${SPARK_HOME}" ]; then source "$(dirname "$0")"/find-spark-homefiecho "${SPARK_HOME}"# disable randomized hash for string in Python 3.3+export PYTHONHASHSEED=0# 這里可以看到將接收到的參數提交到了spark-class腳本執行exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"2.2 spark-class腳本
#!/usr/bin/env bashif [ -z "${SPARK_HOME}" ]; then source "$(dirname "$0")"/find-spark-homefi# 配置一些環境變量,它會將conf/spark-env.sh中的環境變量加載進來:. "${SPARK_HOME}"/bin/load-spark-env.sh# Find the java binary 如果有java_home環境變量會將java_home/bin/java給RUNNERif [ -n "${JAVA_HOME}" ]; then RUNNER="${JAVA_HOME}/bin/java"else if [ "$(command -v java)" ]; then RUNNER="java" else echo "JAVA_HOME is not set" >&2 exit 1 fifi# Find Spark jars.# 這一段,主要是尋找java命令 尋找spark的jar包# 這里如果我們的jar包數量多,而且內容大,可以事先放到每個機器的對應目錄下,這里是一個優化點if [ -d "${SPARK_HOME}/jars" ]; then SPARK_JARS_DIR="${SPARK_HOME}/jars"else SPARK_JARS_DIR="${SPARK_HOME}/assembly/target/scala-$SPARK_SCALA_VERSION/jars"fiif [ ! -d "$SPARK_JARS_DIR" ] && [ -z "$SPARK_TESTING$SPARK_SQL_TESTING" ]; then echo "Failed to find Spark jars directory ($SPARK_JARS_DIR)." 1>&2 echo "You need to build Spark with the target "package" before running this program." 1>&2 exit 1else LAUNCH_CLASSPATH="$SPARK_JARS_DIR/*"fi# Add the launcher build dir to the classpath if requested.if [ -n "$SPARK_PREPEND_CLASSES" ]; then LAUNCH_CLASSPATH="${SPARK_HOME}/launcher/target/scala-$SPARK_SCALA_VERSION/classes:$LAUNCH_CLASSPATH"fi# For testsif [[ -n "$SPARK_TESTING" ]]; then unset YARN_CONF_DIR unset HADOOP_CONF_DIRfi# The launcher library will print arguments separated by a NULL character, to allow arguments with# characters that would be otherwise interpreted by the shell. Read that in a while loop, populating# an array that will be used to exec the final command.# 啟動程序庫將打印由NULL字符分隔的參數,以允許與shell進行其他解釋的字符進行參數。在while循環中讀取它,填充將用于執行最終命令的數組。## The exit code of the launcher is appended to the output, so the parent shell removes it from the# command array and checks the value to see if the launcher succeeded.# 啟動程序的退出代碼被追加到輸出,因此父shell從命令數組中刪除它,并檢查其值,看看啟動器是否成功。# 這里spark啟動了以SparkSubmit為主類的JVM進程。build_command() { "$RUNNER" -Xmx128m -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@" printf "%d0" $?}# Turn off posix mode since it does not allow process substitution# 關閉posix模式,因為它不允許進程替換。# 調用build_command org.apache.spark.launcher.Main拼接提交命令set +o posixCMD=()while IFS= read -d '' -r ARG; do CMD+=("$ARG")done < &2 exit 1fiif [ $LAUNCHER_EXIT_CODE != 0 ]; then exit $LAUNCHER_EXIT_CODEfiCMD=("${CMD[@]:0:$LAST}")# ${CMD[@]} 參數如下# /Library/Java/JavaVirtualMachines/jdk1.8.0_172.jdk/Contents/Home/bin/java -cp /Users/lipan/workspace/source_code/spark-2.3.3/conf/:/Users/lipan/workspace/source_code/spark-2.3.3/assembly/target/scala-2.11/jars/* -Xmx1g org.apache.spark.deploy.SparkSubmit --master local --class com.lp.test.app.LocalPi /Users/lipan/Desktop/spark-local/original-spark-local-train-1.0.jar 10exec "${CMD[@]}"相對于spark-submit,spark-class文件的執行邏輯稍顯復雜,總體如下:
- 檢查SPARK_HOME執行環境
- 執行load-spark-env.sh文件,加載一些默認的環境變量(包括加載spark-env.sh文件)
- 檢查JAVA_HOME執行環境
- 尋找Spark相關的jar包
- 執行org.apache.spark.launcher.Main解析參數,構建CMD命令
- CMD命令判斷
- 執行org.apache.spark.deploy.SparkSubmit這個類。
2.3 org.apache.spark.launcher.Main
java -Xmx128m -cp ...jars org.apache.spark.launcher.Main "$@"也就是說org.apache.spark.launcher.Main是被spark-class調用,從spark-class接收參數。這個類是提供spark內部腳本調用的工具類,并不是真正的執行入口。它負責調用其他類,對參數進行解析,并生成執行命令,最后將命令返回給spark-class的 exec “${CMD[@]}”執行。
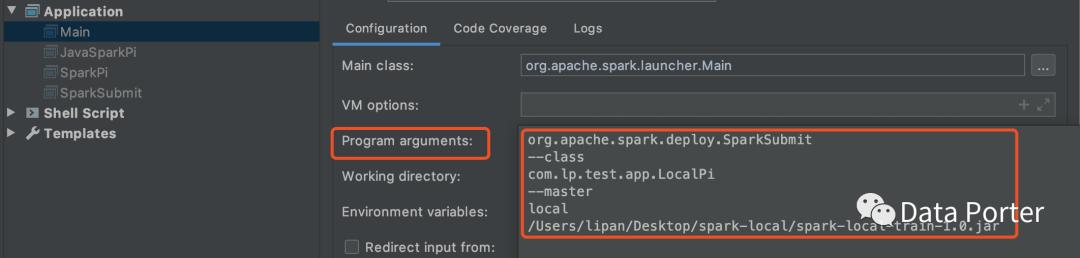
可以把”$@”執行相關參數帶入IDEA中的org.apache.spark.launcher.Main方法中執行,操作參考如下:
package org.apache.spark.launcher;import java.util.ArrayList;import java.util.Arrays;import java.util.HashMap;import java.util.List;import java.util.Map;import static org.apache.spark.launcher.CommandBuilderUtils.*;/** * Command line interface for the Spark launcher. Used internally by Spark scripts. * 這是提供spark內部腳本使用工具類 */ class Main { /** * Usage: Main [class] [class args] * 分為spark-submit和spark-class兩種模式 * 如果提交的是class類的話,會包含其他如:master/worker/history等等 * unix系統的輸出的參數是集合,而windows參數是空格分隔 * * spark-class提交過來的參數如下: * org.apache.spark.deploy.SparkSubmit * --class com.lp.test.app.LocalPi * --master local * /Users/lipan/Desktop/spark-local/spark-local-train-1.0.jar */ public static void main(String[] argsArray) throws Exception { checkArgument(argsArray.length > 0, "Not enough arguments: missing class name."); // 判斷參數列表 List args = new ArrayList<>(Arrays.asList(argsArray)); String className = args.remove(0); // 判斷是否打印執行信息 boolean printLaunchCommand = !isEmpty(System.getenv("SPARK_PRINT_LAUNCH_COMMAND")); // 創建命令解析器 AbstractCommandBuilder builder; /** * 構建執行程序對象:spark-submit/spark-class * 把參數都取出并解析,放入執行程序對象中 * 意思是,submit還是master和worker等程序在這里拆分,并獲取對應的執行參數 */ if (className.equals("org.apache.spark.deploy.SparkSubmit")) { try { // 構建spark-submit命令對象 builder = new SparkSubmitCommandBuilder(args); } catch (IllegalArgumentException e) { printLaunchCommand = false; System.err.println("Error: " + e.getMessage()); System.err.println(); // 類名解析--class org.apache.spark.repl.Main MainClassOptionParser parser = new MainClassOptionParser(); try { parser.parse(args); } catch (Exception ignored) { // Ignore parsing exceptions. } // 幫助信息 List help = new ArrayList<>(); if (parser.className != null) { help.add(parser.CLASS); help.add(parser.className); } help.add(parser.USAGE_ERROR); // 構建spark-submit幫助信息對象 builder = new SparkSubmitCommandBuilder(help); } } else { // 構建spark-class命令對象 // 主要是在這個類里解析了命令對象和參數 builder = new SparkClassCommandBuilder(className, args); } /** * 這里才真正構建了執行命令 * 調用了SparkClassCommandBuilder的buildCommand方法 * 把執行參數解析成了k/v格式 */ Map env = new HashMap<>(); List cmd = builder.buildCommand(env); if (printLaunchCommand) { System.err.println("Spark Command: " + join(" ", cmd)); System.err.println("========================================"); } if (isWindows()) { System.out.println(prepareWindowsCommand(cmd, env)); } else { // In bash, use NULL as the arg separator since it cannot be used in an argument. /** * 輸出參數:/Library/Java/JavaVirtualMachines/jdk1.8.0_172.jdk/Contents/Home/bin/java * -cp /Users/lipan/workspace/source_code/spark-2.3.3/conf/:/Users/lipan/workspace/source_code/spark-2.3.3/assembly/target/scala-2.11/jars/* * -Xmx1g org.apache.spark.deploy.SparkSubmit * --master local * --class com.lp.test.app.LocalPi * /Users/lipan/Desktop/spark-local/original-spark-local-train-1.0.jar 10 * java -cp / org.apache.spark.deploy.SparkSubmit啟動該類 */ List bashCmd = prepareBashCommand(cmd, env); for (String c : bashCmd) { System.out.print(c); System.out.print('0'); } } } /** * windows環境下 */ private static String prepareWindowsCommand(List cmd, Map childEnv) { StringBuilder cmdline = new StringBuilder(); for (Map.Entry e : childEnv.entrySet()) { cmdline.append(String.format("set %s=%s", e.getKey(), e.getValue())); cmdline.append(" && "); } for (String arg : cmd) { cmdline.append(quoteForBatchScript(arg)); cmdline.append(" "); } return cmdline.toString(); } /** * bash環境,如:Linux */ private static List prepareBashCommand(List cmd, Map childEnv) { if (childEnv.isEmpty()) { return cmd; } List newCmd = new ArrayList<>(); newCmd.add("env"); for (Map.Entry e : childEnv.entrySet()) { newCmd.add(String.format("%s=%s", e.getKey(), e.getValue())); } newCmd.addAll(cmd); return newCmd; } /** * 當spark-submit提交失敗時,這里會再進行一次解析,再不行才會提示用法 */ private static class MainClassOptionParser extends SparkSubmitOptionParser { String className; @Override protected boolean handle(String opt, String value) { if (CLASS.equals(opt)) { className = value; } return false; } @Override protected boolean handleUnknown(String opt) { return false; } @Override protected void handleExtraArgs(List extra) { } } }Main中主要涉及到的一些類SparkSubmitCommandBuilder、SparkClassCommandBuilder 和 buildCommand都是在對參數和構建命令進行處理,這里不一一展開詳解。
2.4 org.apache.spark.deploy.SparkSubmit
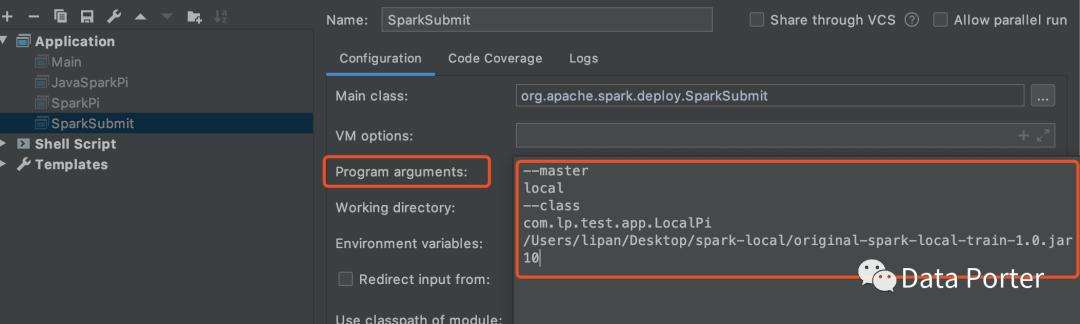
org.apache.spark.launcher.Main中會解析過濾參數,構建執行命令,返回給spark-class腳本,最后通過 exec “${CMD[@]}” 真正調用SparkSubmit類。
可通過解析后提交的參數”$@”設置在IDEA中逐步跟蹤源碼,操作參考如下:
2.4.1 SparkSubmitAction
在org.apache.spark.launcher.Main類的最前面定義了一個類SparkSubmitAction枚舉狀態類。
/** * Whether to submit, kill, or request the status of an application. * The latter two operations are currently supported only for standalone and Mesos cluster modes. * 這個類主要是提交app,終止和請求狀態,但目前終止和請求只能在standalone和mesos模式下 */// 繼承了枚舉類,定義了4個屬性,多了一個打印spark版本private[deploy] object SparkSubmitAction extends Enumeration { type SparkSubmitAction = Value val SUBMIT, KILL, REQUEST_STATUS, PRINT_VERSION = Value}2.4.2 SparkSubmit
在SparkSubmit類中的方法執行可參考如下,在每個方法中都有詳細的注釋。具體細節也可以根據文末的鏈接地址中載源碼斷進行斷點調試。
2.4.2.1 Main
override def main(args: Array[String]): Unit = { // 初始化logging系統,并跟日志判斷是否需要在app啟動時重啟 val uninitLog = initializeLogIfNecessary(true, silent = true) /** * 構建spark提交需要的參數并進行賦值 SparkSubmitArguments * 1.解析參數 * 2.從屬性文件填充“sparkProperties”映射(未指定默認情況下未:spark-defaults.conf) * 3.移除不是以"spark." 開頭的變量 * 4.參數填充對應到實體屬性上 * 5.action參數驗證 */ val appArgs = new SparkSubmitArguments(args) // 參數不重復則輸出配置 if (appArgs.verbose) { printStream.println(appArgs) } appArgs.action match { case SparkSubmitAction.SUBMIT => submit(appArgs, uninitLog) case SparkSubmitAction.KILL => kill(appArgs) case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs) } }2.4.2.2 submit
/** * 通過匹配SUBMIT執行的submit() * * 首先是根據不同調度模式和yarn不同模式,導入調用類的路徑,默認配置及輸入參數,準備相應的啟動環境 * 然后通過對應的環境來調用相應子類的main方法 * 這里因為涉及到重復調用,所以采用了@tailrec尾遞歸,即重復調用方法的最后一句并返回結果 * 即:runMain(childArgs, childClasspath, sparkConf, childMainClass, args.verbose) */ @tailrec private def submit(args: SparkSubmitArguments, uninitLog: Boolean): Unit = { /** * 先準備運行環境,傳入解析的各種參數 * 這里會先進入 * lazy val secMgr = new SecurityManager(sparkConf) * 先初始化SecurityManager后,再進入prepareSubmitEnvironment() * prepareSubmitEnvironment()代碼比較長,放到最下面去解析 */ val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args) // 主要是調用runMain()啟動相應環境的main()的方法 // 環境準備好以后,會先往下運行判斷,這里是在等著調用 def doRunMain(): Unit = { // 提交時可以指定--proxy-user,如果沒有指定,則獲取當前用戶 if (args.proxyUser != null) { val proxyUser = UserGroupInformation.createProxyUser(args.proxyUser, UserGroupInformation.getCurrentUser()) try { proxyUser.doAs(new PrivilegedExceptionAction[Unit]() { override def run(): Unit = { // 這里是真正的執行,runMain() runMain(childArgs, childClasspath, sparkConf, childMainClass, args.verbose) } }) } catch { case e: Exception => // Hadoop's AuthorizationException suppresses the exception's stack trace, which // makes the message printed to the output by the JVM not very helpful. Instead, // detect exceptions with empty stack traces here, and treat them differently. if (e.getStackTrace().length == 0) { // scalastyle:off println printStream.println(s"ERROR: ${e.getClass().getName()}: ${e.getMessage()}") // scalastyle:on println exitFn(1) } else { throw e } } } else { // 沒有指定用戶時執行 runMain(childArgs, childClasspath, sparkConf, childMainClass, args.verbose) } } // 啟動main后重新初始化logging if (uninitLog) { Logging.uninitialize() } // standalone模式有兩種提交網關, // (1)使用o.a.s.apply.client作為包裝器的傳統RPC網關和基于REST服務的網關 // (2)spark1.3后默認使用REST // 如果master終端沒有使用REST服務,spark會故障切換到RPC 這里判斷standalone模式和使用REST服務 if (args.isStandaloneCluster && args.useRest) { // 異常捕獲,判斷正確的話輸出信息,進入doRunMain() try { logInfo("Running Spark using the REST application submission protocol.") doRunMain() } catch { // Fail over to use the legacy submission gateway // 否則異常輸出信息,并設置submit失敗 case e: SubmitRestConnectionException => logWarning(s"Master endpoint ${args.master} was not a REST server. " + "Falling back to legacy submission gateway instead.") args.useRest = false submit(args, false) } // In all other modes, just run the main class as prepared // 其他模式,按準備的環境調用上面的doRunMain()運行相應的main() // 在進入前,初始化了SparkContext和SparkSession } else { doRunMain() } }2.4.2.3 prepareSubmitEnvironment
/** * 準備各種模式的配置參數 * * @param args 用于環境準備的已分析SparkSubmitArguments * @param conf 在Hadoop配置中,僅在單元測試中設置此參數。 * @return a 4-tuple: * (1) the arguments for the child process, * (2) a list of classpath entries for the child, * (3) a map of system properties, and * (4) the main class for the child * 返回一個4元組(childArgs, childClasspath, sparkConf, childMainClass) * childArgs:子進程的參數 * childClasspath:子級的類路徑條目列表 * sparkConf:系統參數map集合 * childMainClass:子級的主類 * * Exposed for testing. * * 由于不同的部署方式其賣弄函數是不一樣的,主要是由spark的提交參數決定 */ private[deploy] def prepareSubmitEnvironment( args: SparkSubmitArguments, conf: Option[HadoopConfiguration] = None) : (Seq[String], Seq[String], SparkConf, String) = { try { doPrepareSubmitEnvironment(args, conf) } catch { case e: SparkException => printErrorAndExit(e.getMessage) throw e } } private def doPrepareSubmitEnvironment( args: SparkSubmitArguments, conf: Option[HadoopConfiguration] = None) : (Seq[String], Seq[String], SparkConf, String) = { // Return values val childArgs = new ArrayBuffer[String]() val childClasspath = new ArrayBuffer[String]() // SparkConf 會默認加一些系統參數 val sparkConf = new SparkConf() var childMainClass = "" // 設置集群模式 // 也就是提交時指定--master local/yarn/yarn-client/yarn-cluster/spark://192.168.2.1:7077或者 mesos,k8s等運行模式 val clusterManager: Int = args.master match { case "yarn" => YARN case "yarn-client" | "yarn-cluster" => printWarning(s"Master ${args.master} is deprecated since 2.0." + " Please use master "yarn" with specified deploy mode instead.") YARN case m if m.startsWith("spark") => STANDALONE case m if m.startsWith("mesos") => MESOS case m if m.startsWith("k8s") => KUBERNETES case m if m.startsWith("local") => LOCAL case _ => printErrorAndExit("Master must either be yarn or start with spark, mesos, k8s, or local") -1 } // 設置部署模式 --deploy-mode var deployMode: Int = args.deployMode match { case "client" | null => CLIENT case "cluster" => CLUSTER case _ => printErrorAndExit("Deploy mode must be either client or cluster"); -1 } //由于指定“yarn-cluster”和“yarn-client”的不受支持的方式封裝了主模式和部署模式, // 因此我們有一些邏輯來推斷master和部署模式(如果只指定一種模式),或者在它們不一致時提前退出 if (clusterManager == YARN) { (args.master, args.deployMode) match { case ("yarn-cluster", null) => deployMode = CLUSTER args.master = "yarn" case ("yarn-cluster", "client") => printErrorAndExit("Client deploy mode is not compatible with master "yarn-cluster"") case ("yarn-client", "cluster") => printErrorAndExit("Cluster deploy mode is not compatible with master "yarn-client"") case (_, mode) => args.master = "yarn" } // Make sure YARN is included in our build if we're trying to use it if (!Utils.classIsLoadable(YARN_CLUSTER_SUBMIT_CLASS) && !Utils.isTesting) { printErrorAndExit( "Could not load YARN classes. " + "This copy of Spark may not have been compiled with YARN support.") } } // 判斷k8s模式master和非testing模式 if (clusterManager == KUBERNETES) { args.master = Utils.checkAndGetK8sMasterUrl(args.master) // Make sure KUBERNETES is included in our build if we're trying to use it if (!Utils.classIsLoadable(KUBERNETES_CLUSTER_SUBMIT_CLASS) && !Utils.isTesting) { printErrorAndExit( "Could not load KUBERNETES classes. " + "This copy of Spark may not have been compiled with KUBERNETES support.") } } // 錯判斷不可用模式 (clusterManager, deployMode) match { case (STANDALONE, CLUSTER) if args.isPython => printErrorAndExit("Cluster deploy mode is currently not supported for python " + "applications on standalone clusters.") case (STANDALONE, CLUSTER) if args.isR => printErrorAndExit("Cluster deploy mode is currently not supported for R " + "applications on standalone clusters.") case (KUBERNETES, _) if args.isPython => printErrorAndExit("Python applications are currently not supported for Kubernetes.") case (KUBERNETES, _) if args.isR => printErrorAndExit("R applications are currently not supported for Kubernetes.") case (KUBERNETES, CLIENT) => printErrorAndExit("Client mode is currently not supported for Kubernetes.") case (LOCAL, CLUSTER) => printErrorAndExit("Cluster deploy mode is not compatible with master "local"") case (_, CLUSTER) if isShell(args.primaryResource) => printErrorAndExit("Cluster deploy mode is not applicable to Spark shells.") case (_, CLUSTER) if isSqlShell(args.mainClass) => printErrorAndExit("Cluster deploy mode is not applicable to Spark SQL shell.") case (_, CLUSTER) if isThriftServer(args.mainClass) => printErrorAndExit("Cluster deploy mode is not applicable to Spark Thrift server.") case _ => } // args.deployMode為空則設置deployMode值為參數,因為上面判斷了args.deployMode為空deployMode為client (args.deployMode, deployMode) match { case (null, CLIENT) => args.deployMode = "client" case (null, CLUSTER) => args.deployMode = "cluster" case _ => } // 根據資源管理器和部署模式,進行邏輯判斷出幾種特殊運行方式。 val isYarnCluster = clusterManager == YARN && deployMode == CLUSTER val isMesosCluster = clusterManager == MESOS && deployMode == CLUSTER val isStandAloneCluster = clusterManager == STANDALONE && deployMode == CLUSTER val isKubernetesCluster = clusterManager == KUBERNETES && deployMode == CLUSTER // 這里主要是添加相關的依賴 if (!isMesosCluster && !isStandAloneCluster) { // 如果有maven依賴項,則解析它們,并將類路徑添加到jar中。對于包含Python代碼的包,也將它們添加到py文件中 val resolvedMavenCoordinates = DependencyUtils.resolveMavenDependencies( args.packagesExclusions, args.packages, args.repositories, args.ivyRepoPath, args.ivySettingsPath) if (!StringUtils.isBlank(resolvedMavenCoordinates)) { args.jars = mergeFileLists(args.jars, resolvedMavenCoordinates) if (args.isPython || isInternal(args.primaryResource)) { args.pyFiles = mergeFileLists(args.pyFiles, resolvedMavenCoordinates) } } // 安裝任何可能通過--jar或--packages傳遞的R包。Spark包可能在jar中包含R源代碼。 if (args.isR && !StringUtils.isBlank(args.jars)) { RPackageUtils.checkAndBuildRPackage(args.jars, printStream, args.verbose) } } args.sparkProperties.foreach { case (k, v) => sparkConf.set(k, v) } // sparkConf 加載Hadoop相關配置文件 val hadoopConf = conf.getOrElse(SparkHadoopUtil.newConfiguration(sparkConf)) // 工作臨時目錄 val targetDir = Utils.createTempDir() // 判斷當前模式下sparkConf的k/v鍵值對中key是否在JVM中全局可用 // 確保keytab在JVM中的任何位置都可用(keytab是Kerberos的身份認證,詳情可參考:http://ftuto.lofter.com/post/31e97f_6ad659f) if (clusterManager == YARN || clusterManager == LOCAL || clusterManager == MESOS) { // 當前運行環境的用戶不為空,args中yarn模式參數key列表不為空,則提示key列表文件不存在 if (args.principal != null) { if (args.keytab != null) { require(new File(args.keytab).exists(), s"Keytab file: ${args.keytab} does not exist") // 在sysProps中添加keytab和主體配置,以供以后使用;例如,在spark sql中,用于與HiveMetastore對話的隔離類裝入器將使用這些設置。 // 它們將被設置為Java系統屬性,然后由SparkConf加載 sparkConf.set(KEYTAB, args.keytab) sparkConf.set(PRINCIPAL, args.principal) UserGroupInformation.loginUserFromKeytab(args.principal, args.keytab) } } } // Resolve glob path for different resources. // 設置全局資源,也就是合并各種模式依賴的路徑的資源和hadoopConf中設置路徑的資源,各種jars,file,pyfile和壓縮包 args.jars = Option(args.jars).map(resolveGlobPaths(_, hadoopConf)).orNull args.files = Option(args.files).map(resolveGlobPaths(_, hadoopConf)).orNull args.pyFiles = Option(args.pyFiles).map(resolveGlobPaths(_, hadoopConf)).orNull args.archives = Option(args.archives).map(resolveGlobPaths(_, hadoopConf)).orNull // 創建SecurityManager實例 lazy val secMgr = new SecurityManager(sparkConf) // 在Client模式下,下載遠程資源文件。 var localPrimaryResource: String = null var localJars: String = null var localPyFiles: String = null if (deployMode == CLIENT) { localPrimaryResource = Option(args.primaryResource).map { downloadFile(_, targetDir, sparkConf, hadoopConf, secMgr) }.orNull localJars = Option(args.jars).map { downloadFileList(_, targetDir, sparkConf, hadoopConf, secMgr) }.orNull localPyFiles = Option(args.pyFiles).map { downloadFileList(_, targetDir, sparkConf, hadoopConf, secMgr) }.orNull } // When running in YARN, for some remote resources with scheme: // 1. Hadoop FileSystem doesn't support them. // 2. We explicitly bypass Hadoop FileSystem with "spark.yarn.dist.forceDownloadSchemes". // We will download them to local disk prior to add to YARN's distributed cache. // For yarn client mode, since we already download them with above code, so we only need to // figure out the local path and replace the remote one. // yarn模式下,hdfs不支持加載到內存,所以采用"spark.yarn.dist.forceDownloadSchemes"方案(在添加到YARN分布式緩存之前,文件將被下載到本地磁盤的逗號分隔列表。用于YARN服務不支持Spark支持的方案的情況) // 所以先把方案列表文件下載到本地,再通過相應方案加載資源到分布式內存中 // 在yarn-client模式中,上面的代碼中已經把遠程文件下載到了本地,只需要獲取本地路徑替換掉遠程路徑即可 if (clusterManager == YARN) { // 加載方案列表 val forceDownloadSchemes = sparkConf.get(FORCE_DOWNLOAD_SCHEMES) // 判斷是否需要下載的方法 def shouldDownload(scheme: String): Boolean = { forceDownloadSchemes.contains("*") || forceDownloadSchemes.contains(scheme) || Try { FileSystem.getFileSystemClass(scheme, hadoopConf) }.isFailure } // 下載資源的方法 def downloadResource(resource: String): String = { val uri = Utils.resolveURI(resource) uri.getScheme match { case "local" | "file" => resource case e if shouldDownload(e) => val file = new File(targetDir, new Path(uri).getName) if (file.exists()) { file.toURI.toString } else { downloadFile(resource, targetDir, sparkConf, hadoopConf, secMgr) } case _ => uri.toString } } // 下載主要運行資源 args.primaryResource = Option(args.primaryResource).map { downloadResource }.orNull // 下載文件 args.files = Option(args.files).map { files => Utils.stringToSeq(files).map(downloadResource).mkString(",") }.orNull args.pyFiles = Option(args.pyFiles).map { pyFiles => Utils.stringToSeq(pyFiles).map(downloadResource).mkString(",") }.orNull // 下載jars args.jars = Option(args.jars).map { jars => Utils.stringToSeq(jars).map(downloadResource).mkString(",") }.orNull // 下載壓縮文件 args.archives = Option(args.archives).map { archives => Utils.stringToSeq(archives).map(downloadResource).mkString(",") }.orNull } // 如果我們正在運行python應用,請將主類設置為特定的python運行器 if (args.isPython && deployMode == CLIENT) { if (args.primaryResource == PYSPARK_SHELL) { args.mainClass = "org.apache.spark.api.python.PythonGatewayServer" } else { // If a python file is provided, add it to the child arguments and list of files to deploy. // Usage: PythonAppRunner [app arguments] args.mainClass = "org.apache.spark.deploy.PythonRunner" args.childArgs = ArrayBuffer(localPrimaryResource, localPyFiles) ++ args.childArgs if (clusterManager != YARN) { // The YARN backend distributes the primary file differently, so don't merge it. args.files = mergeFileLists(args.files, args.primaryResource) } } if (clusterManager != YARN) { // The YARN backend handles python files differently, so don't merge the lists. args.files = mergeFileLists(args.files, args.pyFiles) } if (localPyFiles != null) { sparkConf.set("spark.submit.pyFiles", localPyFiles) } } // 在R應用程序的yarn模式中,添加SparkR包存檔和包含所有構建的R庫的R包存檔到存檔中,以便它們可以隨作業一起分發 if (args.isR && clusterManager == YARN) { val sparkRPackagePath = RUtils.localSparkRPackagePath if (sparkRPackagePath.isEmpty) { printErrorAndExit("SPARK_HOME does not exist for R application in YARN mode.") } val sparkRPackageFile = new File(sparkRPackagePath.get, SPARKR_PACKAGE_ARCHIVE) if (!sparkRPackageFile.exists()) { printErrorAndExit(s"$SPARKR_PACKAGE_ARCHIVE does not exist for R application in YARN mode.") } val sparkRPackageURI = Utils.resolveURI(sparkRPackageFile.getAbsolutePath).toString // Distribute the SparkR package. // Assigns a symbol link name "sparkr" to the shipped package. args.archives = mergeFileLists(args.archives, sparkRPackageURI + "#sparkr") // Distribute the R package archive containing all the built R packages. if (!RUtils.rPackages.isEmpty) { val rPackageFile = RPackageUtils.zipRLibraries(new File(RUtils.rPackages.get), R_PACKAGE_ARCHIVE) if (!rPackageFile.exists()) { printErrorAndExit("Failed to zip all the built R packages.") } val rPackageURI = Utils.resolveURI(rPackageFile.getAbsolutePath).toString // Assigns a symbol link name "rpkg" to the shipped package. args.archives = mergeFileLists(args.archives, rPackageURI + "#rpkg") } } // TODO: Support distributing R packages with standalone cluster if (args.isR && clusterManager == STANDALONE && !RUtils.rPackages.isEmpty) { printErrorAndExit("Distributing R packages with standalone cluster is not supported.") } // TODO: Support distributing R packages with mesos cluster if (args.isR && clusterManager == MESOS && !RUtils.rPackages.isEmpty) { printErrorAndExit("Distributing R packages with mesos cluster is not supported.") } // 如果我們正在運行R應用,請將主類設置為特定的R運行器 if (args.isR && deployMode == CLIENT) { if (args.primaryResource == SPARKR_SHELL) { args.mainClass = "org.apache.spark.api.r.RBackend" } else { // If an R file is provided, add it to the child arguments and list of files to deploy. // Usage: RRunner [app arguments] args.mainClass = "org.apache.spark.deploy.RRunner" args.childArgs = ArrayBuffer(localPrimaryResource) ++ args.childArgs args.files = mergeFileLists(args.files, args.primaryResource) } } if (isYarnCluster && args.isR) { // In yarn-cluster mode for an R app, add primary resource to files // that can be distributed with the job args.files = mergeFileLists(args.files, args.primaryResource) } // Special flag to avoid deprecation warnings at the client sys.props("SPARK_SUBMIT") = "true" // 為各種部署模式設置相應參數這里返回的是元組OptionAssigner類沒有方法,只是設置了參數類型 val options = List[OptionAssigner]( // All cluster managers OptionAssigner(args.master, ALL_CLUSTER_MGRS, ALL_DEPLOY_MODES, confKey = "spark.master"), OptionAssigner(args.deployMode, ALL_CLUSTER_MGRS, ALL_DEPLOY_MODES, confKey = "spark.submit.deployMode"), OptionAssigner(args.name, ALL_CLUSTER_MGRS, ALL_DEPLOY_MODES, confKey = "spark.app.name"), OptionAssigner(args.ivyRepoPath, ALL_CLUSTER_MGRS, CLIENT, confKey = "spark.jars.ivy"), OptionAssigner(args.driverMemory, ALL_CLUSTER_MGRS, CLIENT, confKey = "spark.driver.memory"), OptionAssigner(args.driverExtraClassPath, ALL_CLUSTER_MGRS, ALL_DEPLOY_MODES, confKey = "spark.driver.extraClassPath"), OptionAssigner(args.driverExtraJavaOptions, ALL_CLUSTER_MGRS, ALL_DEPLOY_MODES, confKey = "spark.driver.extraJavaOptions"), OptionAssigner(args.driverExtraLibraryPath, ALL_CLUSTER_MGRS, ALL_DEPLOY_MODES, confKey = "spark.driver.extraLibraryPath"), // Propagate attributes for dependency resolution at the driver side OptionAssigner(args.packages, STANDALONE | MESOS, CLUSTER, confKey = "spark.jars.packages"), OptionAssigner(args.repositories, STANDALONE | MESOS, CLUSTER, confKey = "spark.jars.repositories"), OptionAssigner(args.ivyRepoPath, STANDALONE | MESOS, CLUSTER, confKey = "spark.jars.ivy"), OptionAssigner(args.packagesExclusions, STANDALONE | MESOS, CLUSTER, confKey = "spark.jars.excludes"), // Yarn only OptionAssigner(args.queue, YARN, ALL_DEPLOY_MODES, confKey = "spark.yarn.queue"), OptionAssigner(args.numExecutors, YARN, ALL_DEPLOY_MODES, confKey = "spark.executor.instances"), OptionAssigner(args.pyFiles, YARN, ALL_DEPLOY_MODES, confKey = "spark.yarn.dist.pyFiles"), OptionAssigner(args.jars, YARN, ALL_DEPLOY_MODES, confKey = "spark.yarn.dist.jars"), OptionAssigner(args.files, YARN, ALL_DEPLOY_MODES, confKey = "spark.yarn.dist.files"), OptionAssigner(args.archives, YARN, ALL_DEPLOY_MODES, confKey = "spark.yarn.dist.archives"), OptionAssigner(args.principal, YARN, ALL_DEPLOY_MODES, confKey = "spark.yarn.principal"), OptionAssigner(args.keytab, YARN, ALL_DEPLOY_MODES, confKey = "spark.yarn.keytab"), // Other options OptionAssigner(args.executorCores, STANDALONE | YARN | KUBERNETES, ALL_DEPLOY_MODES, confKey = "spark.executor.cores"), OptionAssigner(args.executorMemory, STANDALONE | MESOS | YARN | KUBERNETES, ALL_DEPLOY_MODES, confKey = "spark.executor.memory"), OptionAssigner(args.totalExecutorCores, STANDALONE | MESOS | KUBERNETES, ALL_DEPLOY_MODES, confKey = "spark.cores.max"), OptionAssigner(args.files, LOCAL | STANDALONE | MESOS | KUBERNETES, ALL_DEPLOY_MODES, confKey = "spark.files"), OptionAssigner(args.jars, LOCAL, CLIENT, confKey = "spark.jars"), OptionAssigner(args.jars, STANDALONE | MESOS | KUBERNETES, ALL_DEPLOY_MODES, confKey = "spark.jars"), OptionAssigner(args.driverMemory, STANDALONE | MESOS | YARN | KUBERNETES, CLUSTER, confKey = "spark.driver.memory"), OptionAssigner(args.driverCores, STANDALONE | MESOS | YARN | KUBERNETES, CLUSTER, confKey = "spark.driver.cores"), OptionAssigner(args.supervise.toString, STANDALONE | MESOS, CLUSTER, confKey = "spark.driver.supervise"), OptionAssigner(args.ivyRepoPath, STANDALONE, CLUSTER, confKey = "spark.jars.ivy"), // An internal option used only for spark-shell to add user jars to repl's classloader, // previously it uses "spark.jars" or "spark.yarn.dist.jars" which now may be pointed to // remote jars, so adding a new option to only specify local jars for spark-shell internally. OptionAssigner(localJars, ALL_CLUSTER_MGRS, CLIENT, confKey = "spark.repl.local.jars") ) // 在客戶端模式下,直接啟動應用程序主類 // 另外,將主應用程序jar和所有添加的jar(如果有)添加到classpath if (deployMode == CLIENT) { childMainClass = args.mainClass if (localPrimaryResource != null && isUserJar(localPrimaryResource)) { childClasspath += localPrimaryResource } if (localJars != null) { childClasspath ++= localJars.split(",") } } // 添加主應用程序jar和任何添加到類路徑的jar,以yarn客戶端需要這些jar。 // 這里假設primaryResource和user jar都是本地jar,否則它不會被添加到yarn客戶端的類路徑中。 if (isYarnCluster) { if (isUserJar(args.primaryResource)) { childClasspath += args.primaryResource } if (args.jars != null) { childClasspath ++= args.jars.split(",") } } if (deployMode == CLIENT) { if (args.childArgs != null) { childArgs ++= args.childArgs } } // 將所有參數映射到我們選擇的模式的命令行選項或系統屬性 for (opt x.split(",").toSeq).getOrElse(Seq.empty) if (isUserJar(args.primaryResource)) { jars = jars ++ Seq(args.primaryResource) } sparkConf.set("spark.jars", jars.mkString(",")) } // 在standalone cluster模式下,使用REST客戶端提交應用程序(Spark 1.3+)。所有Spark參數都將通過系統屬性傳遞給客戶端。 if (args.isStandaloneCluster) { if (args.useRest) { childMainClass = REST_CLUSTER_SUBMIT_CLASS childArgs += (args.primaryResource, args.mainClass) } else { // In legacy standalone cluster mode, use Client as a wrapper around the user class childMainClass = STANDALONE_CLUSTER_SUBMIT_CLASS if (args.supervise) { childArgs += "--supervise" } Option(args.driverMemory).foreach { m => childArgs += ("--memory", m) } Option(args.driverCores).foreach { c => childArgs += ("--cores", c) } childArgs += "launch" childArgs += (args.master, args.primaryResource, args.mainClass) } if (args.childArgs != null) { childArgs ++= args.childArgs } } // 讓YARN知道這是一個pyspark應用程序,因此它將分發所需的庫。 if (clusterManager == YARN) { if (args.isPython) { sparkConf.set("spark.yarn.isPython", "true") } } if (clusterManager == MESOS && UserGroupInformation.isSecurityEnabled) { setRMPrincipal(sparkConf) } // 在yarn-cluster模式下,將yarn.Client用作用戶類的包裝器 if (isYarnCluster) { childMainClass = YARN_CLUSTER_SUBMIT_CLASS if (args.isPython) { childArgs += ("--primary-py-file", args.primaryResource) childArgs += ("--class", "org.apache.spark.deploy.PythonRunner") } else if (args.isR) { val mainFile = new Path(args.primaryResource).getName childArgs += ("--primary-r-file", mainFile) childArgs += ("--class", "org.apache.spark.deploy.RRunner") } else { if (args.primaryResource != SparkLauncher.NO_RESOURCE) { childArgs += ("--jar", args.primaryResource) } childArgs += ("--class", args.mainClass) } if (args.childArgs != null) { args.childArgs.foreach { arg => childArgs += ("--arg", arg) } } } if (isMesosCluster) { assert(args.useRest, "Mesos cluster mode is only supported through the REST submission API") childMainClass = REST_CLUSTER_SUBMIT_CLASS if (args.isPython) { // Second argument is main class childArgs += (args.primaryResource, "") if (args.pyFiles != null) { sparkConf.set("spark.submit.pyFiles", args.pyFiles) } } else if (args.isR) { // Second argument is main class childArgs += (args.primaryResource, "") } else { childArgs += (args.primaryResource, args.mainClass) } if (args.childArgs != null) { childArgs ++= args.childArgs } } if (isKubernetesCluster) { childMainClass = KUBERNETES_CLUSTER_SUBMIT_CLASS if (args.primaryResource != SparkLauncher.NO_RESOURCE) { childArgs ++= Array("--primary-java-resource", args.primaryResource) } childArgs ++= Array("--main-class", args.mainClass) if (args.childArgs != null) { args.childArgs.foreach { arg => childArgs += ("--arg", arg) } } } // 加載通過--conf和默認屬性文件指定的所有屬性 for ((k, v) // 如果存在,用解析的URI替換舊的URI sparkConf.getOption(config).foreach { oldValue => sparkConf.set(config, Utils.resolveURIs(oldValue)) } } // 清理和格式化python文件的路徑 // 如果默認配置中有設置spark.submit.pyFiles,name--py-files不用添加 sparkConf.getOption("spark.submit.pyFiles").foreach { pyFiles => val resolvedPyFiles = Utils.resolveURIs(pyFiles) val formattedPyFiles = if (!isYarnCluster && !isMesosCluster) { PythonRunner.formatPaths(resolvedPyFiles).mkString(",") } else { // 返回清理和格式化后的python文件路徑 resolvedPyFiles } sparkConf.set("spark.submit.pyFiles", formattedPyFiles) } // 最終prepareSubmitEnvironment()返回的元組,對應了(mainclass args, jars classpath, sparkConf, mainclass path) (childArgs, childClasspath, sparkConf, childMainClass) }2.4.2.4 doRunMain
// 主要是調用runMain()啟動相應環境的main()的方法 // 環境準備好以后,會先往下運行判斷,這里是在等著調用 def doRunMain(): Unit = { // 提交時可以指定--proxy-user,如果沒有指定,則獲取當前用戶 if (args.proxyUser != null) { val proxyUser = UserGroupInformation.createProxyUser(args.proxyUser, UserGroupInformation.getCurrentUser()) try { proxyUser.doAs(new PrivilegedExceptionAction[Unit]() { override def run(): Unit = { // 這里是真正的執行,runMain() runMain(childArgs, childClasspath, sparkConf, childMainClass, args.verbose) } }) } catch { case e: Exception => // Hadoop's AuthorizationException suppresses the exception's stack trace, which // makes the message printed to the output by the JVM not very helpful. Instead, // detect exceptions with empty stack traces here, and treat them differently. if (e.getStackTrace().length == 0) { // scalastyle:off println printStream.println(s"ERROR: ${e.getClass().getName()}: ${e.getMessage()}") // scalastyle:on println exitFn(1) } else { throw e } } } else { // 沒有指定用戶時執行 runMain(childArgs, childClasspath, sparkConf, childMainClass, args.verbose) } }2.4.2.5 runMain
/** * 使用提供的啟動環境運行子類的main方法。 * 請注意,如果我們正在運行集群部署模式或python應用程序,則該主類將不是用戶提供的主類。 * * 這里的參數有子類需要的參數,子類路徑,sparkConf,子類main()路徑,參數重復判斷 */private def runMain( childArgs: Seq[String], childClasspath: Seq[String], sparkConf: SparkConf, childMainClass: String, verbose: Boolean): Unit = { if (verbose) { printStream.println(s"Main class:$childMainClass") printStream.println(s"Arguments:${childArgs.mkString("")}") printStream.println(s"Spark config:${Utils.redact(sparkConf.getAll.toMap).mkString("")}") printStream.println(s"Classpath elements:${childClasspath.mkString("")}") printStream.println("") } // 初始化類加載器 val loader = if (sparkConf.get(DRIVER_USER_CLASS_PATH_FIRST)) { // 如果用戶設置了class,通過ChildFirstURLClassLoader來加載 new ChildFirstURLClassLoader(new Array[URL](0), Thread.currentThread.getContextClassLoader) } else { // 如果用戶沒有設置,通過MutableURLClassLoader來加載 new MutableURLClassLoader(new Array[URL](0), Thread.currentThread.getContextClassLoader) } // 設置由上面自定義的類加載器來加載class到JVM Thread.currentThread.setContextClassLoader(loader) // 從Classpath中添加jars for (jar e.printStackTrace(printStream) if (childMainClass.contains("thriftserver")) { printStream.println(s"Failed to load main class $childMainClass.") printStream.println("You need to build Spark with -Phive and -Phive-thriftserver.") } System.exit(CLASS_NOT_FOUND_EXIT_STATUS) case e: NoClassDefFoundError => e.printStackTrace(printStream) if (e.getMessage.contains("org/apache/hadoop/hive")) { printStream.println(s"Failed to load hive class.") printStream.println("You need to build Spark with -Phive and -Phive-thriftserver.") } System.exit(CLASS_NOT_FOUND_EXIT_STATUS) } /** * 通過classOf[]構建從屬于mainClass的SparkApplication對象 * 然后通過mainclass實例化了SparkApplication * SparkApplication是一個抽象類,這里主要是實現它的start() */ val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) { mainClass.newInstance().asInstanceOf[SparkApplication] } else { // SPARK-4170 if (classOf[scala.App].isAssignableFrom(mainClass)) { printWarning("Subclasses of scala.App may not work correctly. Use a main() method instead.") } // 如果mainclass無法實例化SparkApplication,則使用替代構建子類JavaMainApplication實例 new JavaMainApplication(mainClass) } @tailrec def findCause(t: Throwable): Throwable = t match { case e: UndeclaredThrowableException => if (e.getCause() != null) findCause(e.getCause()) else e case e: InvocationTargetException => if (e.getCause() != null) findCause(e.getCause()) else e case e: Throwable => e } try { // 啟動實例 app.start(childArgs.toArray, sparkConf) } catch { case t: Throwable => findCause(t) match { case SparkUserAppException(exitCode) => System.exit(exitCode) case t: Throwable => throw t } }}2.4.3 SparkApplication
package org.apache.spark.deployimport java.lang.reflect.Modifierimport org.apache.spark.SparkConf/** * 這是spark任務的入口抽象類,需要實現它的無參構造 */private[spark] trait SparkApplication { def start(args: Array[String], conf: SparkConf): Unit}/** * 用main方法包裝標準java類的SparkApplication實現 * * 用main方法包裝標準java類的SparkApplication實現配置是通過系統配置文件傳遞,在同一個JVM中加載太多配置會可能導致配置溢出 */private[deploy] class JavaMainApplication(klass: Class[_]) extends SparkApplication { override def start(args: Array[String], conf: SparkConf): Unit = { val mainMethod = klass.getMethod("main", new Array[String](0).getClass) if (!Modifier.isStatic(mainMethod.getModifiers)) { throw new IllegalStateException("The main method in the given main class must be static") } val sysProps = conf.getAll.toMap sysProps.foreach { case (k, v) => sys.props(k) = v } mainMethod.invoke(null, args) }}如果是在本地模式,到SparkApplication這個類這里已經運行結束。
但是如果是yarn cluster模式,它創建的實例是不同的,也就是start()啟動的類其實是YarnClusterApplication,同樣繼承了SparkApplication,在后續的文章中回繼續跟進。
3. 源碼地址
https://github.com/perkinls/spark-2.3.3
4. 參考文獻
《Spark內核設計藝術》 關注公眾號Data Porter 回復: Spark內核設計藝術免費領取
https://github.com/apache/spark
https://github.com/CrestOfWave/Spark-2.3.1
https://blog.csdn.net/do_yourself_go_on/article/details/75005204
https://blog.csdn.net/lingeio/article/details/96900714
歡迎公眾號:Data Porter 免費獲取數據結構、Java、Scala、Python、大數據、區塊鏈、機器學習等學習資料。好手不敵雙拳,雙拳不如四手!希望認識更多的朋友一起成長、共同進步!


)
)












)



