一、什么是對象
在 Pyth 中,對象就是經過實例化的,具體可以操作的一組代碼的組合;
對象一般包含數據(變量,更習慣稱之為屬性 attribute),也包含代碼(函數,也稱之為方法)
當你想要創建一個別人從來都沒有創建過的新對象時,首先必須定義一個類,用以指明該類型的對象所包含的內容(屬性和方法)
可以把對象想象成 名詞 ,那么方法就是動詞。對象代表著一個獨立的實物,它的方法則定義了它是如何和其他事物互相作用的。
和模塊不同,你可以同時創建許多屬于同一個類的對象,但每個對象又可以有各自的獨特的屬性。
?
編程的集中方式
- 面向過程:根據業務邏輯從上到下寫代碼
- 函數式:將某功能代碼封裝到函數中,日后便無需重復編寫,僅調用函數即可
- 面向對象:對函數進行分類和封裝,讓開發“更快更好更強...”
面向對象編程
- 面向對象是一種編程方式,此編程方式的實現是基于對 類 和 對象 的使用
- 類 是一個模板,模板中包裝了多個“函數”供使用(可以講多函數中公用的變量封裝到對象中)
- 對象,根據模板創建的實例(即:對象),實例用于調用被包裝在類中的函數
- 面向對象三大特性:封裝、繼承和多態
?
二、使用 class 定義類 &? 創建(實例化)一個對象
面向對象編程是一種編程方式,此編程方式的落地需要使用 “類” 和 “對象” 來實現,所以,面向對象編程其實就是對 “類” 和 “對象” 的使用。
???? 類是對現實世界的某些對象的共性的抽象化。比如球就是對藍球,足球,乒乓球的抽象化,大部分都有圓形的特征,都是體育用具。
類就是一個模板,模板里可以包含多個函數和變量(屬性),函數里實現一些功能(方法)
對象則是根據模板創建的實例,通過實例化過的對象可以執行類中的函數(即對象的方法)

圖中沒有指明的地方下面一一闡述:
__init__? 是Python中一個特殊的函數名,是一個類的初始化實例的一個方法,用于根據類的定義去創建實例對象;
self 參數也是python的一個特殊參數的名稱,固定格式,self 實際上指的就是正在被創建的對象本身;它是在定義方法的時候的第一個參數,這是必須的。詳解見下圖:

?
上圖中:
doctor=Person('shark')??? 就是實例化一個對象,這個對象就是 doctor
當創建這個對象時候,Python做了以下幾件事:
- 查看 Person 類的定義;
- 在內存中實例化(創建)一個新的對象 doctor;
- 調用對象的 __init__ 方法,將這個新創建的對象 doctor 作為形參 self 的實參傳進去,并將 'shark' 作為形參 name 的實參傳入;
- 將 name? 的值 'shark' 賦值給 這個對象 doctor的 Name 變量(即屬性);
- 將以上的操作結果返回給這個新對象;
- 給這個新對象賦值給 dockor ;
這個新對象和其他的對象一樣,可以把它當做列表、元組、字典的一個元素,也可以當做參數傳給函數,或者當做函數的返回值
當創建了一個實例的對象后,可以用下面的方式訪問到它的屬性或者方法
>>> doctor.Name
'shark'?
特性(property)
-
什么是 property
property是一種特殊的屬性,訪問它時會執行一段功能(函數)然后返回值
下面的例子中首先定義一個Duck類,它僅包含一個 hidden_name 屬性,我們不希望比人直接訪問到這個屬性,因此需要定義兩個方法,
在每個方法中添加一個 print() 函數。最后把這些方法設置為 name 屬性:
>>> class Duck():
... def __init__(self,input_name):
... self.hidden_name = input_name
... def get_name(self):
... print('inside the getter')
... return self.hidden_name
... def set_name(self,input_name):
... print('inside the setter')
... self.hidden_name = input_name
... name = property(get_name,set_name)
...
>>> fowl = Duck('Howard')
>>> fowl.name # 當調用 name 屬性時,get_name() 方法會自動被調用
inside the getter
'Howard'
>>> fowl.get_name() # 當然這里可以顯示調用
inside the getter
'Howard'
>>> fowl.name = 'Daffy' # 當對 name 進行設置時,set_name() 方法會自動被調用
inside the setter
>>> fowl.set_name('Daffy') # 當然也這里可以顯示調用
inside the setter
>>> fowl.name
inside the getter
'Daffy'
>>> # 下面來使用Python應有的風格來實現,就是用裝飾器的方式:
#@property, 用于指示getter方法
#@name.setter, 用于指示setter方法>>> class Duck():
... def __init__(self,input_name):
... self.hidden_name = input_name
... @property
... def name(self):
... print('inside the getter')
... return self.hidden_name
... @name.setter
... def name(self,input_name):
... print('inside the setter')
... self.hidden_name = input_name
...
>>> fowl = Duck('Howard')
>>> fowl.name
inside the getter
'Howard'
>>> fowl.name = 'Donald'
inside the setter
>>> fowl.name
inside the getter
'Donald'
>>>
# 這里顯然就沒有顯示的調用了使用 property 的一個巨大優勢:如果你改變某個屬性的定義,只需要在類的定義里修改即可,不需要再每一個調用處修改
下面還是接著上面的例子來操作一下
>>> fowl.hidden_name
'Donald'
>>>
發生了什么?你本來是知道有這個屬性的,還是可以直接訪問到的。假如被人也知道這個屬性,也同樣能訪問到,是不是就沒有起到最初隱藏某些屬性的目的了。其實在Python中有專門的方法來定義一個需要隱藏的屬性,就是在變量名前加兩個下劃線(__),看下面我們改下過的 Duck 類>>> class Duck():
... def __init__(self,input_name):
... self.__name = input_name
... @property
... def name(self):
... print('inside the getter')
... return self.__name
... @name.setter
... def name(self,input_name):
... print('inside the setter')
... self.__name = input_name
...
>>> fowl = Duck('Howard')
>>> fowl.name # 代碼同樣有效
inside the getter
'Howard'
>>> fowl.name = 'Donald'
inside the setter
>>> fowl.name
inside the getter
'Donald'
>>> fowl.__name # 這時訪問不到 __name 屬性了
Traceback (most recent call last):File "<stdin>", line 1, in <module>
AttributeError: 'Duck' object has no attribute '__name'
>>> ?其實這種命名規范并沒有把屬性變成真正的私有,但Python確實將它重整了,讓外部的代碼無法使用。其實還是可以訪問到的>>> fowl._Duck__name
'Donald'
>>>
-
上面的情況有時候也叫數據的封裝
封裝不但有上面提到的數據封裝,也有關于方法的封裝
為啥要用封裝呢?
封裝數據的主要原因是:保護隱私
封裝方法的主要原因是:隔離復雜度,就是把復雜的代碼邏輯實現過程封裝起來,對于使用者是透明的;給用戶用到的只是一個簡單的接口。
封裝其實分為兩個層面,但無論哪種層面的封裝,都要對外界提供好訪問你內部隱藏內容的接口(接口可以理解為入口,有了這個入口,使用者無需且不能夠直接訪問到內部隱藏的細節,只能走接口,并且我們可以在接口的實現上附加更多的處理邏輯,從而嚴格控制使用者的訪問)
第一個層面的封裝(什么都不用做):創建類和對象會分別創建二者的名稱空間,我們只能用類名.或者obj.的方式去訪問里面的名字,這本身就是一種封裝
>>> fowl.name
inside the getter 'Donald'
>>>
注意:對于這一層面的封裝(隱藏),類名.和實例名.就是訪問隱藏屬性的接口
第二個層面的封裝:類中把某些屬性和方法隱藏起來(或者說定義成私有的),只在類的內部使用、外部無法訪問,或者留下少量接口(函數)供外部訪問。
同上面提到的 隱藏屬性的方法一樣,在python中用雙下劃線的方式實現隱藏屬性(設置成私有的)
在繼承中,父類如果不想讓子類覆蓋自己的方法,可以將方法定義為私有的#把fa定義成私有的,即__fa
>>> class A:
... def __fa(self): #在定義時就變形為_A__fa
... print('from A')
... def test(self):
... self.__fa() #只會與自己所在的類為準,即調用_A__fa
...
>>> class B(A):
... def __fa(self):
... print('from B')
...
>>> b=B()
>>> b.test()
from A?python并不會真的阻止你訪問私有的屬性,模塊也遵循這種約定,如果模塊名以單下劃線開頭,那么from module import *時不能被導入,但是你from module import _private_module依然是可以導入的
其實很多時候你去調用一個模塊的功能時會遇到單下劃線開頭的(socket._socket,sys._home,sys._clear_type_cache),這些都是私有的,原則上是供內部調用的,作為外部的你,一意孤行也是可以用的,只不過顯得稍微傻逼一點點
接口與歸一化設計
繼承有兩種用途:
一:繼承基類的方法,并且做出自己的改變或者擴展(代碼重用)
二:聲明某個子類兼容于某基類,定義一個接口類Interface,接口類中定義了一些接口名(就是函數名)且并未實現接口的功能,子類繼承接口類,并且實現接口中的功能
class Interface:#定義接口Interface類來模仿接口的概念,python中壓根就沒有interface關鍵字來定義一個接口。def read(self): #定接口函數readpassdef write(self): #定義接口函數writepassclass Txt(Interface): #文本,具體實現read和writedef read(self):print('文本數據的讀取方法')def write(self):print('文本數據的讀取方法')class Sata(Interface): #磁盤,具體實現read和writedef read(self):print('硬盤數據的讀取方法')def write(self):print('硬盤數據的讀取方法')class Process(All_file):def read(self):print('進程數據的讀取方法')def write(self):print('進程數據的讀取方法')?
實踐中,繼承的第一種含義意義并不很大,甚至常常是有害的。因為它使得子類與基類出現強耦合。
繼承的第二種含義非常重要。它又叫“接口繼承”。
接口繼承實質上是要求“做出一個良好的抽象,這個抽象規定了一個兼容接口,使得外部調用者無需關心具體細節,可一視同仁的處理實現了特定接口的所有對象”——這在程序設計上,叫做歸一化。
歸一化使得高層的外部使用者可以不加區分的處理所有接口兼容的對象集合——就好象linux的泛文件概念一樣,所有東西都可以當文件處理,不必關心它是內存、磁盤、網絡還是屏幕(當然,對底層設計者,當然也可以區分出“字符設備”和“塊設備”,然后做出針對性的設計:細致到什么程度,視需求而定)。
在python中根本就沒有一個叫做interface的關鍵字,上面的代碼只是看起來像接口,其實并沒有起到接口的作用,子類完全可以不用去實現接口 ,如果非要去模仿接口的概念,可以借助第三方模塊:
http://pypi.python.org/pypi/zope.interface
twisted的twisted\internet\interface.py里使用zope.interface
文檔https://zopeinterface.readthedocs.io/en/latest/
-
為何要用接口
接口提取了一群類共同的函數,可以把接口當做一個函數的集合。
然后讓子類去實現接口中的函數。
這么做的意義在于歸一化,什么叫歸一化,就是只要是基于同一個接口實現的類,那么所有的這些類產生的對象在使用時,從用法上來說都一樣。
歸一化,讓使用者無需關心對象的類是什么,只需要的知道這些對象都具備某些功能就可以了,這極大地降低了使用者的使用難度。
比如:我們定義一個動物接口,接口里定義了有跑、吃、呼吸等接口函數,這樣老鼠的類去實現了該接口,松鼠的類也去實現了該接口,由二者分別產生一只老鼠和一只松鼠送到你面前,即便是你分別不到底哪只是什么鼠你肯定知道他倆都會跑,都會吃,都能呼吸。
再比如:我們有一個汽車接口,里面定義了汽車所有的功能,然后由本田汽車的類,奧迪汽車的類,大眾汽車的類,他們都實現了汽車接口,這樣就好辦了,大家只需要學會了怎么開汽車,那么無論是本田,還是奧迪,還是大眾我們都會開了,開的時候根本無需關心我開的是哪一類車,操作手法(函數調用)都一樣
?
?
抽象類
-
1 什么是抽象類
??? 與java一樣,python也有抽象類的概念但是同樣需要借助模塊實現,抽象類是一個特殊的類,它的特殊之處在于只能被繼承,不能被實例化
-
2 為什么要有抽象類
??? 如果說類是從一堆對象中抽取相同的內容而來的,那么抽象類就是從一堆類中抽取相同的內容而來的,內容包括數據屬性和函數屬性。
比如我們有香蕉的類,有蘋果的類,有桃子的類,從這些類抽取相同的內容就是水果這個抽象的類,你吃水果時,要么是吃一個具體的香蕉,要么是吃一個具體的桃子。。。。。。你永遠無法吃到一個叫做水果的東西。
??? 從設計角度去看,如果類是從現實對象抽象而來的,那么抽象類就是基于類抽象而來的。
從實現角度來看,抽象類與普通類的不同之處在于:抽象類中只能有抽象方法(沒有實現功能),該類不能被實例化,只能被繼承,且子類必須實現抽象方法。這一點與接口有點類似,但其實是不同的,即將揭曉答案
-
3. 在python中實現抽象類
import abc #利用abc模塊實現抽象類class All_file(metaclass=abc.ABCMeta):all_type='file'@abc.abstractmethod #定義抽象方法,無需實現功能def read(self):'子類必須定義讀功能'pass@abc.abstractmethod #定義抽象方法,無需實現功能def write(self):'子類必須定義寫功能'pass# class Txt(All_file):
# pass
#
# t1=Txt() #報錯,子類沒有定義抽象方法class Txt(All_file): #子類繼承抽象類,但是必須定義read和write方法def read(self):print('文本數據的讀取方法')def write(self):print('文本數據的讀取方法')class Sata(All_file): #子類繼承抽象類,但是必須定義read和write方法def read(self):print('硬盤數據的讀取方法')def write(self):print('硬盤數據的讀取方法')class Process(All_file): #子類繼承抽象類,但是必須定義read和write方法def read(self):print('進程數據的讀取方法')def write(self):print('進程數據的讀取方法')wenbenwenjian=Txt()yingpanwenjian=Sata()jinchengwenjian=Process()#這樣大家都是被歸一化了,也就是一切皆文件的思想
wenbenwenjian.read()
yingpanwenjian.write()
jinchengwenjian.read()print(wenbenwenjian.all_type)
print(yingpanwenjian.all_type)
print(jinchengwenjian.all_type)?
-
4. 抽象類與接口
抽象類的本質還是類,指的是一組類的相似性,包括數據屬性(如all_type)和函數屬性(如read、write),而接口只強調函數屬性的相似性。
抽象類是一個介于類和接口直接的一個概念,同時具備類和接口的部分特性,可以用來實現歸一化設計?
?
三、繼承
在你編寫代碼解決實際問題的時候,經常能找到一些已有的類,這些類可以幫你實現大部分功能,但不是全部。這時該怎么辦?
對這個已有的類進行修改,但這么做,會使代碼變的更加復雜,一不小心就可能破壞原來類的可用的功能。
這時就可以用到類的一個特性: 繼承
類的繼承就是可以從一個已有的類中衍生出以個新的類,這個新的類可以不需要再做任何代碼的復制重寫,就可以擁有原有類的所有屬性和方法。
并且你也可以對這個新的類進行添加新屬性和你需要的新方法;甚至把原來類的方法進行重寫,即重寫實現,并不改變原來方法的名稱,這種重寫方法,我們習慣稱為覆蓋方法,下面會一一介紹。
我們習慣把新類稱為子類,把原來的類稱為基類、父類或者超類。
具體實現的方法就是,在定義新類時,在類的名稱后面的小括號中寫入要繼承的父類的名稱即可
比如說,汽車(Car),自行車(Bicycle)的共性,大部分都是有品牌、出廠日期等屬性(變量)的,都可以行駛(方法)。
這些都是屬于車(Vehicle)這個類的屬性和方法。下面我們就來演示一下如何實現繼承的。
?
# 先定義一個父類 :車
class Vehicle():def __init__(self,name,brand,date):self.name = nameself.brand = brandself.date = datedef run(self):print('The {} is running'.format(self.name) )# 再定義兩個子類,對父類車進行繼承
class Car(Vehicle): # 汽車類passclass Bicycle(Vehicle): # 自行車類pass# 現在都繼承了父類,但是在子類中什么代碼也沒寫,
# 但是會有服了的所以屬性和方法my_car = Car('x6','bmw','20170106') # 實例化一個汽車對象
my_bicycle = Bicycle('roam_xr2','giant','20170305') # 實例化一個自行車對象# 直接通過實例化的對象對其屬性和方法進行調用
print(my_car.name)
my_car.run()print(my_bicycle.name)
my_bicycle.run()# 輸出結果
x6
The x6 is running
roam_xr2
The roam_xr2 is running?
四、多態和多態性
有很多人可能會把二者混為一談,然后就會容易亂,甚至懵逼。其實只要分開看,就會很明朗
-
多態
多態就是一類事物有多種形態的表現形式。(一個抽象類有多個子類,因而多態的概念依賴于繼承,就像上面的例子一樣)
車是有多重形態存在于這個世界上的,如,自行車、汽車、火車等;
在 Python 中序列就有多重形態:字符串、列表、元組
這就不寫代碼了,參考上面的即可
-
多態性??
那么什么優勢多態性哪?
多態性就是在現實生活中具有不同功能的多個事物(對象),也就是每個對象去實現的方法不一樣,而對這些功能的叫法,即名稱是一樣的,比如自行和汽車都能行駛,但是自行車是通過人力為驅動力,2個輪子去行駛;而汽車是使用發動機為驅動力,至少4個輪去行駛(不要給我提摩托車!!!)。
再比如,人都會說話,但是,中國人說的是普通話,而美國人和英國人說的英語;但這并不能妨礙他們同一種語言之間的正常交流,都叫說話。
?
多態性在面向對象編程(OOP)中指的是不同的對象可以使用相同的函數名,但這些函數體卻不一樣,去實現的方法也自然不一樣了;這樣就可以用一個函數名調用不同內容的函數,從而去實現不同的方法。
在面向對象方法中一般是這樣表述多態性:向不同的對象發送同一條消息,不同的對象在接收時會產生不同的行為(即方法)。也就是說,每個對象可以用自己的方式去響應共同的消息。所謂消息,就是調用函數,不同的行為就是指不同的實現,即執行不同的函數。
多態性分為:靜態多態性和動態多態性
靜態多態性:如任何類型都可以用運算符+進行運算
如下圖總所實現的一樣,字符串、列表、和元組都有一樣的方法名稱 __len__() 但是內部是實現一定不同。
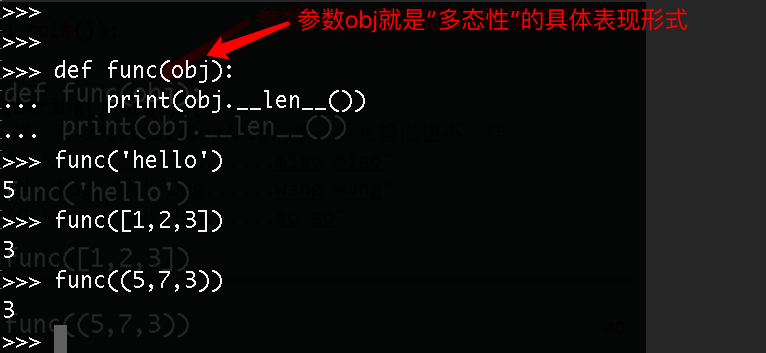
?
我們可以對之前車的例子進行稍微的改動一下
class Vehicle():def __init__(self,name,brand,date):self.name = nameself.brand = brandself.date = datedef run(self):print('The {} is running'.format(self.name) )
class Car(Vehicle): # 汽車類def run(self):print('{}正在用四個輪子行駛,平均速度是 80km/h'.format(self.name))
class Bicycle(Vehicle): # 自行車類def run(self):print('{}正在用兩個輪子行駛,平均速度是 20km/h'.format(self.name))my_car = Car('x6','bmw','20170106') # 實例化一個汽車對象
my_bicycle = Bicycle('roam_xr2','giant','20170305') # 實例化一個自行車對象# 為了很好的展示多態性,還有再借助一個函數
def func(obj):obj.run() #這里明確的調用了一個函數,函數名就是:run
#將不同的對象傳進這個函數
func(my_car)
func(my_bicycle)
# 輸出了不同的結果
x6正在用四個輪子行駛,平均速度是 80km/h
roam_xr2正在用兩個輪子行駛,平均速度是 20km/h-
為什么要用多態性(多態性的好處)
其實大家從上面多態性的例子可以看出,我們并沒有增加什么新的知識,也就是說python本身就是支持多態性的,這么做的好處是什么呢?
1.增加了程序的靈活性和使用者的透明性或者易用性
以不變應萬變,不論對象千變萬化,使用者都是同一種形式去調用,如func(obj)
2.增加了程序額可擴展性
通過繼承Vehicle類創建了一個新的類,使用者無需更改自己的代碼,還是用func(animal)去調用?
# 開發者,修改代碼,衍生的新子類:火車
class Train(Vehicle):def run(self):print('{}正在用多個輪子行駛,平均速度是 150km/h'.format(self.name))
# 實例化一個新的火車對象 t1
t1 = Train('hexiehao','China CSR','20000706')
# 給使用者的函數代碼不變
def func(obj):obj.run()
# 使用者使用同樣的方式去調用
func(t1)# 輸出結果
hexiehao正在用多個輪子行駛,平均速度是 150km/h?組合
如果你想創建的子類在大多數情況下的行為都和父類相似的話,使用基礎是非常不錯的選擇。
它們之間的關系是屬于的關系。但有些時候是有組合 (composition)更加符合現實的邏輯。比如 x 含有 y ,他們之間是 has-a 的關系。
汽車是(屬于)車的一種(is-a),它有(含有)四個輪子(has-a),輪子是汽車的組成部分,但不是汽車的一種。
class Vehicle():def __init__(self,brand):self.brand = brand
class Wheel():def __init__(self,num):self.num = num
class Car():def __init__(self,car_brand,num_wheel):self.car_brand = car_brandself.num_wheel = num_wheeldef run(self):print('The %s car is running on %s wheels' %(v1.brand,w1.num))
v1 = Vehicle('BMW')
w1 = Wheel(4)
car1 = Car(v1,w1)
car1.run()
# 輸出結果
The BMW car is running on 4 wheels五、對象相關知識補充
?
-
對象/實例只有一種作用:屬性引用(變量引用)
>>> class Person():
... def __init__(self,name,age):
... self.name = name
... self.age = age
... def run(self):
... print('{} is running'.format(self.name))
...
>>> person = Person('Fudd',23) #實例化一個人的對象
# 對象調用了自己的數據屬性
>>> print('name:',person.name)
name: Fudd
>>> print('age :',person.age)
age : 23
>>>
對象本身只有數據屬性,但是python的class機制會將類的函數綁定到對象上,稱為對象的方法,或者叫綁定方法
>>> person.run #對象的綁定方法
<bound method Person.run of <__main__.Person object at 0x7f80cc575c50>>>>> Person.run # 對象的綁定方法 run 本質就是調用類的函數 run 的功能,二者是一種綁定關系
<function Person.run at 0x7f80cc571620>
>>>
對象的綁定方法的特別之處在于:obj.func()會把obj傳給func的第一個參數。也就是通常見到的在類里定義的任何函數,self 都是第一個參數,這是 Python的機制所必需的。-
類的初始化實例流程圖
")
?
根據上圖我們得知,再次指明了其實self,就是實例本身!你實例化時python會自動把這個實例本身通過self參數傳進去
六、覆蓋方法
?
類的覆蓋方法,就上上面的例子中的 run() 方法一樣,子類可以父類里的這個方法繼續完全覆蓋。
其實子類可以覆蓋父類的所以方法,包括__init__()本身,下面就開展示一個覆蓋父類__init__()的例子
class Person():def __init__(self,name,age):self.name = nameself.age = ageclass MDPerson(Person):def __init__(self,name,age):self.name = "Doctor" + nameself.age = age
person = Person('Fudd',23)
doctor = MDPerson('Fudd',23)print('name:',person.name ,'age :',person.age)
print('name:',doctor.name ,'age:',doctor.age)
# 輸出內容
name: Fudd age : 23
name: DoctorFudd age: 23?
七、添加新方法
添加新方法很簡單
比如還拿上面的 人 這個類來說,現在衍生一個老師類,并且在這個新的類里,添加一個新的屬性 老師的認證級別和一個新的方法講課
class Person():def __init__(self,name,age):self.name = nameself.age = agedef run(self):print('{} is running'.format(self.name))
class Teacher(Person):def __init__(self,name,age,level): #添加了新的屬性Person.__init__(self,name,age) # 上面重構了__init__(),再要使用父類的屬性,就需要這樣寫self.level = leveldef lecture(self): # 添加的新方法print('%s teacher =>%s teacher is lecturing' %(self.level,self.name))
t1 = Teacher('shark',23,'Senior ')
print(t1.level)
t1.lecture()
# 輸出結果
Senior
Senior teacher =>shark teacher is lecturing?

八、子類里使用 super 調用父類的屬性
其實對于上面的例子中已經用到了父類屬性,只是方法看著有點 low,下面就演示一下,稍微高逼格的方法
class Person():def __init__(self,name,age):self.name = nameself.age = agedef run(self):print('{} is running'.format(self.name))
class Teacher(Person):def __init__(self,name,age,level):super().__init__(name,age) # 注意這里使用super() 替代了父類名,并且參數中沒有 self # 上面是 Pyhon3 的方式,Python2 中的方式是:super(Teacher,self).__init__(name,age)self.level = leveldef lecture(self):print('%s teacher =>%s teacher is lecturing' %(self.level,self.name))
t1 = Teacher('shark',23,'Senior ')
print(t1.level)
t1.lecture()
# 輸出結果
Senior
Senior teacher =>shark teacher is lecturing 九、靜態方法 & 類的方法
通常情況下,在類中定義的所有函數都是對象的綁定方法。
(注意了,這里說的就是所有,跟self啥的沒關系,self也只是一個再普通不過的參數而已)
在類的定義中,以self作為第一個參數的方法都是實例方法(instance method)。
這種在創建自定義類是最常用,實例方法的首個參數是 self ,當這種方法被調用時,
Python 會把調用此方法的對象作為 self 參數傳入。
除此之外還有兩種常見的方法:靜態方法和類方法,二者是為類量身定制的,
但是實例非要使用,也不會報錯,后續將介紹。
-
靜態方法
靜態方法是一種普通函數,位于類定義的命名空間中,不會對任何實例類型進行操作,
python為我們內置了函數staticmethod來把類中的函數定義成靜態方法
class Foo:def spam(x,y,z): #類中的一個函數,千萬不要懵逼,self和x啥的沒有不同都是參數名print(x,y,z)spam=staticmethod(spam) #把spam函數做成靜態方法基于之前所學裝飾器的知識,@staticmethod 等同于spam=staticmethod(spam),于是class Foo:@staticmethod #裝飾器def spam(x,y,z):print(x,y,z)使用演示print(type(Foo.spam)) #類型本質就是函數
Foo.spam(1,2,3) #調用函數應該有幾個參數就傳幾個參數f1=Foo()
f1.spam(3,3,3) #實例也可以使用,但通常靜態方法都是給類用的,實例在使用時喪失了自動傳值的機制'''
<class 'function'>
1 2 3
3 3 3
'''應用場景:編寫類時需要采用很多不同的方式來創建實例,而我們只有一個__init__函數,此時靜態方法就派上用場了
class Date:def __init__(self,year,month,day):self.year=yearself.month=monthself.day=day@staticmethoddef now(): #用Date.now()的形式去產生實例,該實例用的是當前時間t=time.localtime() #獲取結構化的時間格式return Date(t.tm_year,t.tm_mon,t.tm_mday) #上面的意思是 新建一個實例,實例名沒有起,但是返回了,也就是,當調用 now() 時,就會得到一個新的實例 @staticmethoddef tomorrow():#用Date.tomorrow()的形式去產生實例,該實例用的是明天的時間t=time.localtime(time.time()+86400)return Date(t.tm_year,t.tm_mon,t.tm_mday)a=Date('1987',11,27) #自己定義時間
b=Date.now() #采用當前時間
c=Date.tomorrow() #采用明天的時間print(a.year,a.month,a.day)
print(b.year,b.month,b.day)
print(c.year,c.month,c.day)-
類方法
與之實例方法相對,類方法(class method)會作用于整個類,
在類定義的內部,用裝飾器 @classmethod 修飾的方法都是類方法。
與實例方法類似,類方法第一個參數是類本身。在Python中,這個參數常被寫作 clsimport time
class Date:def __init__(self,year,month,day):self.year=yearself.month=monthself.day=day@classmethoddef now(cls): #用Date.now()的形式去產生實例,該實例用的是當前時間t=time.localtime() #獲取結構化的時間格式return cls(t.tm_year,t.tm_mon,t.tm_mday) #上面的意思是 新建一個實例,實例名沒有起,但是返回了,也就是,當調用 now() 時,就會得到一個新的實例 @staticmethoda=Date(1983,'07',28) #自己定義時間
b=Date.now() #采用當前時間print(a.year,a.month,a.day) # 輸出自定義的實例化時間
print(b.year,b.month,b.day) # 輸出調用類方法 now()即當前的時間的實例化時間
# 輸出結果
1983 07 28
2017 3 5 - 靜態方法和類方法的區別
1. staticmethod 與類只是名義上的歸屬關系
2. classmethod 只能訪問類變量,不能訪問實例變量
- 應用場景
import time
class Date:def __init__(self,year,mon,day):self.year=yearself.mon=monself.day=day@classmethoddef now(cls):t=time.localtime()return cls(t.tm_year,t.tm_mon,t.tm_mday)# 下面是使用靜態方法去實現的情況,請注意看后面的圖片說明# @staticmethod # def now():# t=time.localtime()# return Date(t.tm_year,t.tm_mon,t.tm_mday)class EuroDate(Date):def __str__(self):return 'year:%s mon:%s day:%s' %(self.year,self.mon,self.day)e = EuroDate.now()
print(e) # 打印這個對象,當打印這個對象是會自動調用對象的類的 __str__()方法
?
類的繼承順序和原理
-
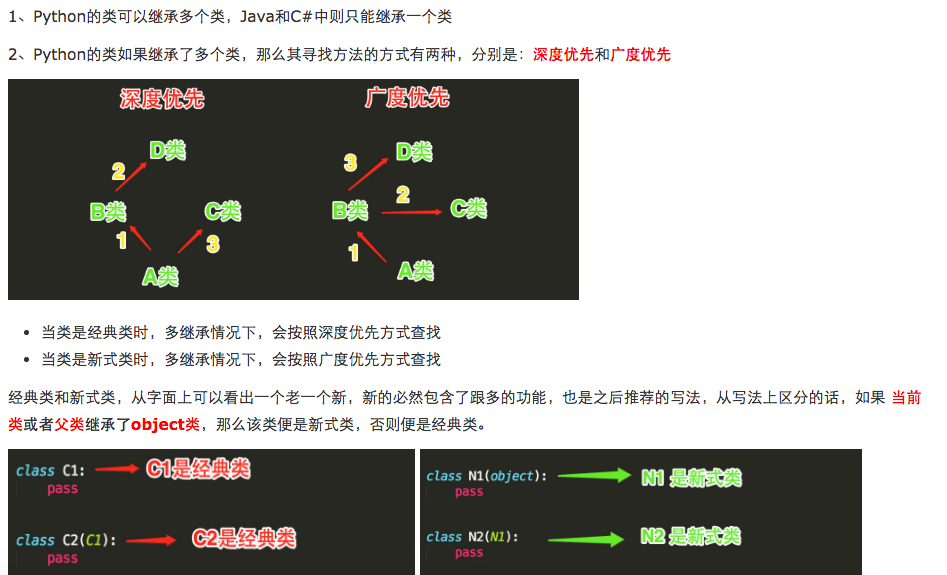
首先來說一下什么是經典類和新式類
pyth2.x中默認都是經典類,Python3.x不是默認,是都是新式類
# Python3.6 定義類
>>> class A:
... pass
...
>>> class B():
... pass
...
>>> class C(object):
... pass
...
# 打印類以及其類型
>>> print(A,type(A))
<class '__main__.A'> <class 'type'>
>>> print(B,type(B))
<class '__main__.B'> <class 'type'>
>>> print(C,type(C))
<class '__main__.C'> <class 'type'>
>>> # Python2.7 定義類
>>> class A:
... pass
...
>>> class B():
... pass
...
>>> class C(object): # 在Python2.x 中定義新式類必須顯式的定義
... pass
...
# 打印類以及其類型
>>> print(A,type(A))
(<class __main__.A at 0x7f5e2344c258>, <type 'classobj'>) # 經典類
>>> print(B,type(B))
(<class __main__.B at 0x7f5e2344c2c0>, <type 'classobj'>)
>>> print(C,type(C))
(<class '__main__.C'>, <type 'type'>) # 新式類
>>> -
1 繼承順序
class A(object):def test(self):print('from A')class B(A):def test(self):print('from B')class C(A):def test(self):print('from C')class D(B):def test(self):print('from D')class E(C):def test(self):print('from E')class F(D,E):# def test(self):# print('from F')pass
f1=F()
f1.test()
print(F.__mro__) #只有新式才有這個屬性可以查看線性列表,經典類沒有這個屬性#新式類繼承順序:F->D->B->E->C->A
#經典類繼承順序:F->D->B->A->E->C
#python3中統一都是新式類
#pyhon2中才分新式類與經典類
-
繼承原理(python如何實現的繼承)
?
python到底是如何實現繼承的,對于你定義的每一個類,python會計算出一個方法解析順序(MRO)列表,這個MRO列表就是一個簡單的所有基類的線性順序列表,例如
>>> F.mro() #等同于 F.__mro__
[<class '__main__.F'>, <class '__main__.D'>, <class '__main__.B'>,<class '__main__.E'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
>>>?
為了實現繼承,python會在MRO列表上從左到右開始查找基類,直到找到第一個匹配這個屬性的類為止。
而這個MRO列表的構造是通過一個C3線性化算法來實現的。我們不去深究這個算法的數學原理,
它實際上就是合并所有父類的MRO列表并遵循如下三條準則:
1.子類會先于父類被檢查
2.多個父類會根據它們在列表中的順序被檢查
3.如果對下一個類存在兩個合法的選擇,選擇第一個父類

)



)













