
大家好,這是專欄《TensorFlow2.0》的第五篇文章,我們對專欄《TensorFlow2.0》進行一個總結。
我們知道全新的TensorFlow2.0 Alpha已經于2019年3月被發布,新版本對TensorFLow的使用方式進行了重大改進,為了滿足各位AI人對TensorFlow2.0的需求,我們推出了專欄《TensorFlow2.0》,前四篇文章帶大家領略了全新的TensorFlow2.0的變化及具體的使用方法。今天就帶大家總結下TensorFlow2.0的一些變化。
作者 | 湯興旺
編輯 | 言有三
1 默認動態圖機制
在tensorflow2.0中,動態圖是默認的不需要自己主動啟用它。
import tensorflow as tf
a = tf.constant([1,2,3])
b = tf.constant([4,5,6])
print(a+b)上面的結果是tf.Tensor([5 7 9], shape=(3,), dtype=int32)
可以說有了動態圖,計算是非常方便的了,再也不需要理解復雜的graph和Session了。
另外我們在對比看下Pytorch中是如何計算上面的結果的。
import torch
a = torch.Tensor([1,2,3])
b = torch.Tensor([4,5,6])
print(a+b)可以發現TensorFlow2.0和Pytorch一樣簡單了,而且代碼基本一樣。
2 棄用collections
我們知道在TensorFlow1.X中可以通過集合 (collection) 來管理不同類別的資源。例如使用tf.add_to_collection 函數可以將資源加入一個或多個集合。使用tf.get_collection獲取一個集合里面的所有資源。這些資源可以是張量、變量或者運行 Tensorflow程序所需要的資源。我們在訓練神經網絡時會大量使用集合管理技術。如通過tf.add_n(tf.get_collection("losses")獲得總損失。
由于collection控制變量很不友好,在TensorFlow2.0中,棄用了collections,這樣代碼會更加清晰。
我們知道TensorFlow2.0非常依賴Keras API,因此如果你使用tf.keras,每個層都會處理自己的變量,當你需要獲取可訓練變量的列表,可直接查詢每個層。
from tensorflow import keras
from tensorflow.keras import Sequential
model = Sequential([keras.layers.Dense(100,activation="relu",input_shape=[2]),keras.layers.Dense(100,activation="relu"),keras.layers.Dense(1)
])我們通過model.weights,就可以查詢每一層的可訓練的變量。結果如下面這種形式。
<tf.Variable'dense/kernel:0' shape=(2,100) dtype=float32, numpy=array([[...]]), dtype=float32)>,另外在TensorFlow2.0中,也刪除了Variable_scopes和tf.get_variable(),需要用面向對象的方式來處理變量共享。
3 刪除雜亂的API,重用Keras
之前TensorFlow1.X中包含了很多重復的API或者不推薦使用的 API,雜亂無章,例如可以使用 tf.layers或tf.keras.layers創建圖層,這樣會造成很多重復和混亂的代碼。
如今TensorFlow 2.0正在擺脫tf.layers,重用Keras 層,可以說如果你使用TensorFlow2.0,那么使用Keras構建深度學習模型是你的不二選擇。
詳細介紹請看文后第二篇文章《以后我們再也離不開Kera了》。
另外tf.contrib的各種項目也已經被合并到Keras等核心API 中,或者移動到單獨的項目中,還有一些將被刪除。
可以說TensorFlow 2.0會更好地組織API,使編碼更簡潔。
4 學習TensorFlow2.0的建議
不管你是AI小白,還是已經學習很久的大神,對于TensorFlow2.0,我們或許都需要重新學,因為它的變化太多了。當你學習TensorFlow2.0時,有如下建議供你參考:
首先不要上來就是import tensorflow as tf。其實沒有必要,我建議大家先把數據預處理先學會了。比如數據你怎么read,怎么數據增強。
這個可以查看文后第三篇文章《數據讀取與使用方式》。
這篇文章介紹了Tensorflow2.0讀取數據的二種方式,分別是Keras API和Dataset類對數據預處理。
另外對于數據導入方式,最好使用Dataset類,個人認為這個比較方便。一個簡單的例子如下:
import tensorflow as tf
import tensorflow_datasets as tfds
dataset, metadata = tfds.load('fashion_mnist', as_supervised=True, with_info=True)
train_dataset, test_dataset = dataset['train'], dataset['test']
train_dataset = train_dataset.shuffle(100).batch(12).repeat()
for img, label in train_dataset.take(1):img = img.numpy()print(img.shape)print(img)從上面的代碼我們可以看出在2.0中導入數據沒有make_one_shot_iter() 這樣的方法了。這個方法已經被棄用了,直接用 take(1)。
當你學會了讀取數據和數據增強后,你就需要學會如何使用TensorFlow2.0構建網絡模型,在TensorFlow2.0中搭建網絡模型主要使用的就是Keras高級API。
如果你想要學會這個本領,可以參考文后的第四篇文章《如何搭建網絡模型》。
在這篇文章我們詳細介紹了如何使用Keras API搭建線性模型VGG16和非線性模型Resnet。如果你是AI小白,想要更好的掌握TensorFlow2.0,建議你使用TensorFlow2.0完成搭建VGG、GoogLeNet、Resnet等模型,這樣對你掌握深度學習框架和網絡結構更有幫助。
當你完成了數據讀取和模型搭建后,現在你需要做的就是訓練模型和可視化了。一個簡單的示例如下:
import tensorflow as tf
from tensorflow.keras.callbacks import TensorBoard
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.preprocessing.image import ImageDataGeneratormodel = tf.keras.models.Sequential([tf.keras.layers.Conv2D(12, (3,3), activation='relu', input_shape=(48, 48, 3),strides=(2, 2), padding='same'),tf.keras.layers.BatchNormalization(axis=3),tf.keras.layers.Conv2D(24, (3,3), activation='relu',strides=(2, 2), padding='same'),tf.keras.layers.BatchNormalization(axis=3),tf.keras.layers.Conv2D(48, (3,3), activation='relu',strides=(2, 2), padding='same'),tf.keras.layers.BatchNormalization(axis=3),tf.keras.layers.Flatten(),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dense(1, activation='sigmoid')
])model.compile(loss='binary_crossentropy',optimizer = SGD(lr=0.001, decay=1e-6, momentum=0.9),metrics=['acc'])
train_datagen = ImageDataGenerator(rescale=1/255, shear_range=0.2,zoom_range=0.2, horizontal_flip=True)
validation_datagen = ImageDataGenerator(rescale=1/255)
train_generator = train_datagen.flow_from_directory(r"D://Learning//tensorflow_2.0//data//train", # 訓練集的根目錄target_size=(48, 48), # 所有圖像的分辨率將被調整為48x48batch_size=32, # 每次讀取32個圖像# 類別模式設為二分類class_mode='binary')# 對驗證集做同樣的操作
validation_generator = validation_datagen.flow_from_directory(r"D://Learning//tensorflow_2.0//data//val",target_size=(48, 48),batch_size=16,class_mode='binary')
history = model.fit_generator(train_generator,steps_per_epoch=28,epochs=500,verbose=1,validation_data = validation_generator,callbacks=[TensorBoard(log_dir=(r"D:Learninglogs"))],validation_steps=6)上面簡單示例的數據集是我們框架系列文章一直所用的表情二分類數據集。從上面的代碼我們可以看出從數據讀取到模型定義再到訓練和可視化基本用的都是Keras 高級API,這里不再贅述。需要下載數據集的請移步github。
acc和loss可視化結果如下兩圖,可以看出效果還是比較可以的,上面的代碼已經同步到有三AI的GitHub項目,如下第一個。
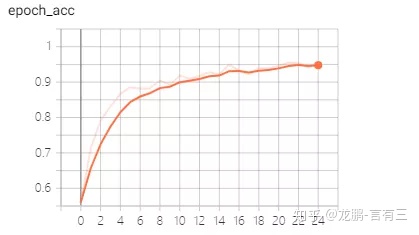
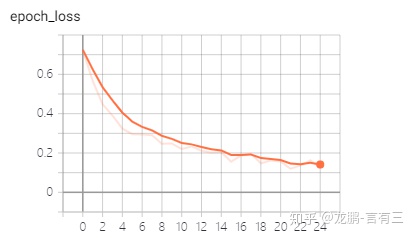
5 TensorFlow2.0優秀的github
1、https://github.com/tangxingwang/yousan.ai
1、https://github.com/czy36mengfei/tensorflow2_tutorials_chinese
3、https://github.com/jinfagang/yolov3_tf2總結
本期我們總結了TensorFlow2.0的變化及使用方法,而且還介紹了學習它的方法和一些比較好的Github。希望您盡快能掌握它!
往期
- 有三AI一周年了,說說我們的初衷,生態和愿景
- 【TensorFlow2.0】TensorFlow2.0專欄上線,你來嗎?
- 【TensorFlow2.0】以后我們再也離不開Keras了?
- 【TensorFlow2.0】數據讀取與使用方式
- 【TensorFlow2.0】如何搭建網絡模型?
)



)

環境配置)


)









