
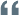
數據庫,簡而言之可視為電子化的文件柜——存儲電子文件的處所,用戶可以對文件中的數據進行新增、查詢、更新、刪除等操作。
所謂“數據庫”是以一定方式儲存在一起、能與多個用戶共享、具有盡可能小的冗余度、與應用程序彼此獨立的數據集合。
MySQL
MariaDB(MySQL的代替品,英文維基百科從MySQL轉向MariaDB)
Percona Server(MySQL的代替品·)
PostgreSQL
Microsoft Access
Microsoft SQL Server
Google Fusion Tables
FileMaker
Oracle數據庫
Sybase
dBASE
Clipper
FoxPro
foshub
幾乎所有的數據庫管理系統都配備了一個開放式數據庫連接(ODBC)驅動程序,令各個數據庫之間得以互相集成。
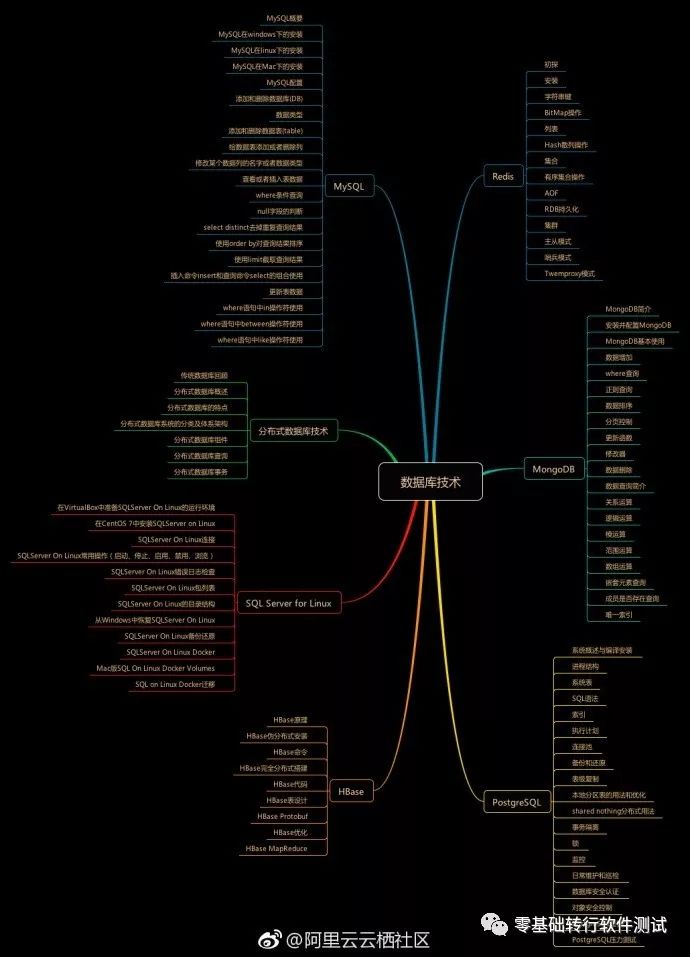
非關系型數據庫(NoSQL)主條目:NoSQL
BigTable(Google)
Cassandra
MongoDB
CouchDB
鍵值(key-value)數據庫
Apache Cassandra(為Facebook所使用):高度可擴展
Dynamo
LevelDB(Google)
數據庫模型對象模型
層次模型(輕量級數據訪問協議)
網狀模型(大型數據儲存)
關系模型
面向對象模型
半結構化模型
平面模型(表格模型,一般在形式上是一個二維數組。如表格模型數據Excel)
架構數據庫的架構可以大致區分為三個概括層次:內層、概念層和外層。
數據庫管理系統(DBMS)是為管理數據庫而設計的計算機軟件系統,一般具有存儲、截取、安全保障、備份等基礎功能,目前主流的數據庫管理系統有:Oracle、MySQL、SQL Server、DB2和Sybase。下面給大家介紹一下這幾款主流的數據庫以及它們之間的區別。
一、OracleOracle數據庫是甲骨文公司推出的一款關系數據庫管理系統,是當前數據庫領域最有名、應用最廣泛的數據庫管理系統之一,Oracle產品覆蓋了大、中、小型機等幾十種機型。
Oracle數據庫具有以下特點:
1、Oracle數據庫可運行于大部分硬件平臺與操作系統上。
2、Oracle能與多種通訊網絡相連,支持多種網絡協議。
3、Oracle的操作較為復雜,對數據庫管理人員要求較高。
4、Oracle具有良好的兼容性、可移植性、可連接性和高生產率。
5、Oracle的安全性非常高,安全可靠。
二、MySQLMySQL也是一款關系型數據庫管理系統,由MySQL AB 公司開發,目前屬于 Oracle 旗下產品,MySQL 是最流行的關系型數據庫管理系統之一。MySQL也是一款開源的SQL數據庫管理系統,是眾多小型網站作為網站數據庫的選擇。
首先概覽下mysql的知識體系:
基礎:
sql語句
表結構設計
調優:
索引、慢查詢優化
配置參數調優
核心原理:
InnoDb存儲引擎 (包括隔離級別、事務、鎖、緩存池、回滾日志等等)
Mysqld ?(包括連接管理、進程管理、查詢緩存、查詢優化、日志等等)
架構與運維:
用戶與權限、安全
備份與恢復
日志
分布式與高可用
MySQL數據庫具有以下特點:
1、MySQL是開源的,可供用戶免費使用。
2、MySQL支持多線程,充分利用CPU資源。
3、MySQL對 PHP有很好的支持,PHP是比較流行的 Web 開發語言,搭配 PHP 和 Apache 可組成良好的開發環境。
4、MySQL提供TCP/IP、ODBC和JDBC等多種數據庫連接途徑。
三、SQL ServerSQL Server是美國微軟公司推出的一款關系型數據庫管理系統,是一款可擴展的、高性能的、為分布式客戶機/服務器計算所設計的數據庫管理系統,實現了與WindowsNT的有機結合,提供了基于事務的企業級信息管理系統方案。
SQL Server數據庫具有以下特點:
1、SQL Server采用圖形界面,操作簡單,管理方便。
2、SQL Server開放性不足,只能在Windows平臺上運行。
3、SQL Server可以用ADO,DAO,OLEDB,ODBC連接。
4、SQL Server是幾大需要收費的主流數據庫中收費最低的,維護費用也較低。
5、SQL Server具有強壯的事務處理功能,采用各種方法保證數據的完整性。
SQL包括了所有對數據庫的操作,主要是由4個部分組成:
1.數據定義:這一部分又稱為“SQL DDL”,定義數據庫的邏輯結構,包括定義數據庫、基本表、視圖和索引4部分。
2.數據操縱:這一部分又稱為“SQL DML”,其中包括數據查詢和數據更新兩大類操作,其中數據更新又包括插入、刪除和更新三種操作。
3.數據控制:對用戶訪問數據的控制有基本表和視圖的授權、完整性規則的描述,事務控制語句等。
4.嵌入式SQL語言的使用規定:規定SQL語句在宿主語言的程序中使用的規則。
下面我們將分別介紹:
數據定義
SQL數據定義功能包括定義數據庫、基本表、索引和視圖。
首先,讓我們了解一下SQL所提供的基本數據類型:(如^00100009b^)
1.數據庫的建立與刪除
(1)建立數據庫:數據庫是一個包括了多個基本表的數據集,其語句格式為:
CREATE DATABASE 〔其它參數〕
其中,在系統中必須是唯一的,不能重復,不然將導致數據存取失誤。〔其它參數〕因具體數據庫實現系統不同而異。
例:要建立項目管理數據庫(xmmanage),其語句應為:
CREATE DATABASE xmmanage
(2)數據庫的刪除:將數據庫及其全部內容從系統中刪除。
其語句格式為:DROP DATABASE
例:刪除項目管理數據庫(xmmanage),其語句應為:DROP DATABASE xmmanage
2.基本表的定義及變更
本身獨立存在的表稱為基本表,在SQL語言中一個關系唯一對應一個基本表。基本表的定義指建立基本關系模式,而變更則是指對數據庫中已存在的基本表進行刪除與修改。
數據查詢
SQL是一種查詢功能很強的語言,只要是數據庫存在的數據,總能通過適當的方法將它從數據庫中查找出來。SQL中的查詢語句只有一個:SELECT,它可與其它語句配合完成所有的查詢功能。SELECT語句的完整語法,可以有6個子句。完整的語法如下:
SELECT 目標表的列名或列表達式集合
FROM 基本表或(和)視圖集合
〔WHERE條件表達式〕
〔GROUP BY列名集合
〔HAVING組條件表達式〕〕
〔ORDER BY列名〔集合〕…〕
簡單查詢,使用TOP子句
查詢結果排序order by
帶條件的查詢where,使用算術表達式,使用邏輯表達式,使用between關鍵字,使用in關鍵字,
模糊查詢like
整個語句的語義如下:從FROM子句中列出的表中,選擇滿足WHERE子句中給出的條件表達式的元組,然后按GROUPBY子句(分組子句)中指定列的值分組,再提取滿足HAVING子句中組條件表達式的那些組,按SELECT子句給出的列名或列表達式求值輸出。ORDER子句(排序子句)是對輸出的目標表進行重新排序,并可附加說明ASC(升序)或DESC(降序)排列。
在WHERE子句中的條件表達式F中可出現下列操作符和運算函數:
算術比較運算符:,>=,=,<>。
邏輯運算符:AND,OR,NOT。
集合運算符:UNION(并),INTERSECT(交),EXCEPT(差)。
集合成員資格運算符:IN,NOT IN
謂詞:EXISTS(存在量詞),ALL,SOME,UNIQUE。
聚合函數:AVG(平均值),MIN(最小值),MAX(最大值),SUM(和),COUNT(計數)。
F中運算對象還可以是另一個SELECT語句,即SELECT語句可以嵌套。
上面只是列出了WHERE子句中可出現的幾種主要操作,由于WHERE子句中的條件表達式可以很復雜,因此SELECT句型能表達的語義遠比其數學原形要復雜得多。
下面,我們以上面所建立的三個基本表為例,演示一下SELECT的應用:
1.無條件查詢
例:找出所有學生的的選課情況
SELECT st_no,su_no
FROM score
例:找出所有學生的情況
SELECT*
FROM student
“*”為通配符,表示查找FROM中所指出關系的所有屬性的值。
2.條件查詢
條件查詢即帶有WHERE子句的查詢,所要查詢的對象必須滿足WHERE子句給出的條件。
例:找出任何一門課成績在70以上的學生情況、課號及分數
SELECT UNIQUE student.st_class,student.st_no,student.st_name,student.st_sex,student.st_age,score.su_no,score.score
FROM student,score
WHERE score.score>=70 AND score.stno=student,st_no
這里使用UNIQUE是不從查詢結果集中去掉重復行,如果使用DISTINCT則會去掉重復行。另外邏輯運算符的優先順序為NOT→AND→OR。
例:找出課程號為c02的,考試成績不及格的學生
SELECT st_no
FROM score
WHERE su_no=‘c02’AND score<60
3.排序查詢
排序查詢是指將查詢結果按指定屬性的升序(ASC)或降序(DESC)排列,由ORDER BY子句指明。
例:查找不及格的課程,并將結果按課程號從大到小排列
SELECT UNIQUE su_no
FROM score
WHERE score<60
ORDER BY su_no DESC
4.嵌套查詢
嵌套查詢是指WHERE子句中又包含SELECT子句,它用于較復雜的跨多個基本表查詢的情況。
例:查找課程編號為c03且課程成績在80分以上的學生的學號、姓名
SELECT st_no,st_name
FROM student
WHERE stno IN (SELECT st_no
FROM score
WHERE su_no=‘c03’ AND score>80 )
這里需要明確的是:當查詢涉及多個基本表時用嵌套查詢逐次求解層次分明,具有結構程序設計特點。在嵌套查詢中,IN是常用到的謂詞。若用戶能確切知道內層查詢返回的是單值,那么也可用算術比較運算符表示用戶的要求。
5.計算查詢
計算查詢是指通過系統提供的特定函數(聚合函數)在語句中的直接使用而獲得某些只有經過計算才能得到的結果。常用的函數有:
COUNT(*) 計算元組的個數
COUNT(列名) 對某一列中的值計算個數
SUM(列名) 求某一列值的總和(此列值是數值型)
AVG(列名) 求某一列值的平均值(此列值是數值型)
MAX(列名) 求某一列值中的最大值
MIN(列名) 求某一列值中的最小值
例:求男學生的總人數和平均年齡
SELECT COUNT(*),AVG(st_age)
FROM student
WHERE st_sex=‘男’
例:統計選修了課程的學生的人數
SELECT COUNT(DISTINCT st_no)
FROM score
注意:這里一定要加入DISTINCT,因為有的學生可能選修了多門課程,但統計時只能按1人統計,所以要使用DISTINCT進行過濾。
數據更新
數據更新包括數據插入、刪除和修改操作。它們分別由INSERT語句,DELETE語句及UPDATE語句完成。這些操作都可在任何基本表上進行,但在視圖上有所限制。其中,當視圖是由單個基本表導出時,可進行插入和修改操作,但不能進行刪除操作;當視圖是從多個基本表中導出時,上述三種操作都不能進行。
1.數據插入
將數據插入SQL的基本表有兩種方式:一種是單元組的插入,另一種是多元組的插入。
單元組的插入:向基本表score中插入一個成績元組(100002,c02,95),可使用以下語句:
INSERT INTO score(st_no,su_no,score) VALUES(‘100002’,‘c02’,95)
由此,可以給出單元組的插入語句格式:
INSERT INTO表名(列名1〔,列名2〕…) VALUES(列值1〔,列值2〕…)
其中,列名序列為要插入值的列名集合,列值序列為要插入的對應值。若插入的是一個表的全部列值,則列名可以省略不寫如上面的(st_no,su_no,score)可以省去;若插入的是表的部分列值,則必須列出相應列名,此時,該關系中未列出的列名取空值。
多元組的插入:這是一種把SELECT語句查詢結果插入到某個已知的基本表中的方法。
例如:需要在表score中求出每個學生的平均成績,并保留在某個表中。此時可以先創建一個新的基本表stu_avggrade,再用INSERT語句把表score中求得的每一個學生的平均成績(用SELECT求得)插入至stu_avggrade中。
CREATE TABLE stu_avggrade
(st_no CHAR(10) NOT NULL,//定義列st_no學號,類型為10位定長字符串,非空
age_grade SMALLINT NOT NULL )// 定義列age_grade平均分,類型為短整形,非空
INSERT INTO stu_avggrade(st_no,age_grade)
SELECT st_no,AVG(score)
FROM score
GROUP BY st_no //因為要求每一個學生所有課程的平均成績,必須按學號分組進行計算。
2.數據刪除
SQL的刪除操作是指從基本表中刪除滿足WHERE的記錄。如果沒有WHERE子句,則刪除表中全部記錄,但表結構依然存在。其語句格式為:
DELETE FROM表名〔WHERE 條件表達式〕
下面舉例說明:
單元組的刪除:把學號為100002的學生從表student中刪除,可用以下語句:
DELETE FROM student
WHERE st_no=‘100002’//因為學號為100002的學生在表student中只有一個,所以為單元組的刪除
多元組的刪除:學號為100002的成績從表score中刪除,可用以下語句:
DELETE FROM score
WHERE st_no=‘100002’//由于學號為100002的元組在表score中可能有多個,所以為多元組刪除
帶有子查詢的刪除操作:刪除所有不及格的學生記錄,可用以下語句
DELETE FROM student
WHERE st_no IN
(SELETE st_no
FROM score
WHERE score<60)
3.數據修改
修改語句是按SET子句中的表達式,在指定表中修改滿足條件表達式的記錄的相應列值。其語句格式如下:
UPDATE 表名 SET 列名=列改變值〔WHERE 條件表達式〕
例:把c02的課程名改為英語,可以用下列語句:
UPDATE subject
SET su_subject=‘英語’
WHERE su_no=‘c02’
例:將課程成績達到70分的學生成績,再提高10%
UPDATE score
SET score=1.1*score
WHERE score>=70
SQL的刪除語句和修改語句中的WHERE子句用法與SELECT中WHERE子句用法相同。數據的刪除和修改操作,實際上要先做SELECT查詢操作,然后再把找到的元組刪除或修改。
數據控制
由于數據庫管理系統是一個多用戶系統,為了控制用戶對數據的存取權利,保持數據的共享及完全性,SQL語言提供了一系列的數據控制功能。其中,主要包括安全性控制、完整性控制、事務控制和并發控制。
1.安全性控制
數據的安全性是指保護數據庫,以防非法使用造成數據泄露和破壞。保證數據安全性的主要方法是通過對數據庫存取權力的控制來防止非法使用數據庫中的數據。即限定不同用戶操作不同的數據對象的權限。
存取權控制包括權力的授予、檢查和撤消。權力授予和撤消命令由數據庫管理員或特定應用人員使用。系統在對數據庫操作前,先核實相應用戶是否有權在相應數據上進行所要求的操作。
(1)權力授予:權力授有數據庫管理員專用的授權和用戶可用的授權兩種形式。數據庫管理員專用授權命令格式如下:
|CONNECT |
GRANT|RESOURCE|TO 用戶名〔IDENTIFED BY 口令〕
|DBA |
其中,CONNECT表示數據庫管理員允許指定的用戶具有連接到數據庫的權力,這種授權是針對新用戶;RESOURCE表示允許用戶建立自己的新關系模式,用戶獲得CONNECT權力后,必須獲得RESOURCE權力才能創建自己的新表;DBA表示數據庫管理員將自己的特權授予指定的用戶。若要同時授予某用戶上述三種授權中的多種權力,則必須通過三個相應的GRANT命令指定。
另外,具有CONNECT和RESOURCE授權的用戶可以建立自己的表,并在自己建立的表和視圖上具有查詢、插入、修改和刪除的權力。但通常不能使用其他用戶的關系,除非能獲得其他用戶轉授給他的相應權力。
例:若允許用戶SSE連接到數據庫并可以建立他自己的關系,則可通過如下命令授予權力:
GRANT CONNECT TO SSE IDENTIFIED BY BD1928
GRANT RESOURCE TO SSE
用戶可用的授權是指用戶將自己擁有的部分或全部權力轉授給其他用戶的命令形式,其命令格式如下:
|SELECT |
|INSERT |
|DELETE |
GRANT|UPDATE(列名1[,列名2]…)|ON|表名 |TO|用戶名|〔WITH GRANT OPTION〕
|ALTER | |視圖名| |PUBLIC|
|NDEX |
|ALL |
若對某一用戶同時授予多種操作權力,則操作命令符號可用“,”相隔。
PUBLIC 表示將權力授予數據庫的所有用戶,使用時要注意:
任選項WITH GRANT OPTION表示接到授權的用戶,具有將其所得到的同時權力再轉授給其他用戶權力。
例:如果將表student的查詢權授予所有用戶,可使用以下命令:
GRANT SELECT ON student TO PUBLIC
例:若將表subject的插入及修改權力授予用戶SSE并使得他具有將這種權力轉授他人的權力,則可使用以下命令:
GRANT INSERT,UPDATE(su_subject) ON subject TO SSE WITH GRANT OPTION
這里,UPDATE后面跟su_subject是指出其所能修改的列。
(2)權力回收:權力回收是指回收指定用戶原已授予的某些權力。與權力授予命令相匹配,權力回收也有數據庫管理員專用和用戶可用的兩種形式。
DBA專用的權力回收命令格式為:
|CONNECT |
REVOKE|RESOURCE|FROM用戶名
|DBA |
用戶可用的權力回收命令格式為:
|SELECT |
|INSERT |
|DELETE |
REVOKE|UPDATE(列名1〔,列名2〕…) |ON|表名 |FROM |用戶名|
|ALTER | |視圖名| |PUBLIC|
|INDEX |
|ALL |
例:回收用戶SSE的DBA權力:
REVOKE DBA FROM SSE
2.完整性控制
數據庫的完整性是指數據的正確性和相容性,這是數據庫理論中的重要概念。完整性控制的主要目的是防止語義上不正確的數據進入數據庫。關系系統中的完整性約束條件包括實體完整性、參照完整性和用戶定義完整性。而完整性約束條件的定義主要是通過CREATE TABLE語句中的〔CHECK〕子句來完成。另外,還有一些輔助命令可以進行數據完整性保護。如UNIQUE和NOT NULL,前者用于防止重復值進入數據庫,后者用于防止空值。
3.事務控制
事務是并發控制的基本單位,也是恢復的基本單位。在SQL中支持事務的概念。所謂事務,是用戶定義的一個操作序列(集合),這些操作要么都做,要么一個都不做,是一個不可分割的整體。一個事務通常以BEGIN TRANSACTION開始,以COMMIT或ROLLBACK結束。
SQL提供了事務提交和事務撤消兩種命令:
(1)事務提交:事務提交的命令為:
COMMIT 〔WORK〕
事務提交標志著對數據庫的某種應用操作成功地完成,所有對數據庫的操作都必須作為事務提交給系統時才有效。事務一經提交就不能撤消。
(2)事務撤消:事務撤消的命令是:
ROLLBACK 〔WORK〕
事務撤消標志著相應事務對數據庫操作失敗,因而要撤消對數據庫的改變,即要“回滾”到相應事務開始時的狀態。
當系統非正常結束時(如掉電、系統死機),將自動執行ROLLBACK命令。
DB2是美國IBM公司開發的一款關系型數據庫管理系統,主要應用于大型應用系統,具有較好的可伸縮性,可支持從大型機到單用戶環境,應用于所有常見的服務器操作系統平臺下。
DB2數據庫具有以下特點:
1、DB2采用了數據分級技術,能夠使大型機數據很方便地下載到LAN數據庫服務器,使得客戶機/服務器用戶和基于LAN的應用程序可以訪問大型機數據,并使數據庫本地化及遠程連接透明化。
2、DB2適用于數據倉庫和在線事物處理,性能高。
3、DB2廣泛應用于大型軟件系統,向下兼容性較好。
4、DB2擁有一個非常完備的查詢優化器,為外部連接改善了查詢性能。
5、DB2具有很好的網絡支持能力,可同時激活上千個活動線程。
五、SybaseSybase數據庫是由美國Sybase公司推出的一種關系數據庫系統,是一種典型的UNIX或WindowsNT平臺上客戶機/服務器環境下的大型數據庫系統,由于基于客戶機/服務器體系結構,Sybase支持共享資源且在多臺設備間平衡負載。
Sybase數據庫具有以下特點:
1、Sybase是基于客戶/服務器體系結構的數據庫,支持共享資源且在多臺設備間平衡負載。
2、Sybase操作較為復雜,對數據庫管理員的要求較高。
3、Sybase有非常好的開放性,能在幾乎所有主流平臺上運行。
4、Sybase是一款高性能、安全性非常高的數據庫。
最后給出我的核心觀點:學習,無論你是學什么,也無論你有沒有基礎。思考永遠是第一位的,有些知識你沒接觸過不要緊,用不著害怕,也沒必要害怕。重要的是一秒鐘也不要停止思考,問題要想透徹,正所謂磨刀不誤砍柴工。尤其是作為工程師,要有打破砂鍋問到底的精神,否則你怎么學都不得其所以然。
















——SVN 提交、更新、解決沖突等操作步驟)


