除了前面講過的rpn與fast rcnn交替訓練外,faster rcnn還提供了一種近乎聯合的訓練,姑且稱為end2end訓練。
根據論文所講,end2end的訓練一氣呵成,對于前向傳播,rpn可以作為預設的網絡提供proposal.而在后向傳播中,rpn,與fast rcnn分別傳導,而匯聚到shared layer.,但是沒有考慮掉roi pooling層對于predicted bounding box的導數。如下圖:
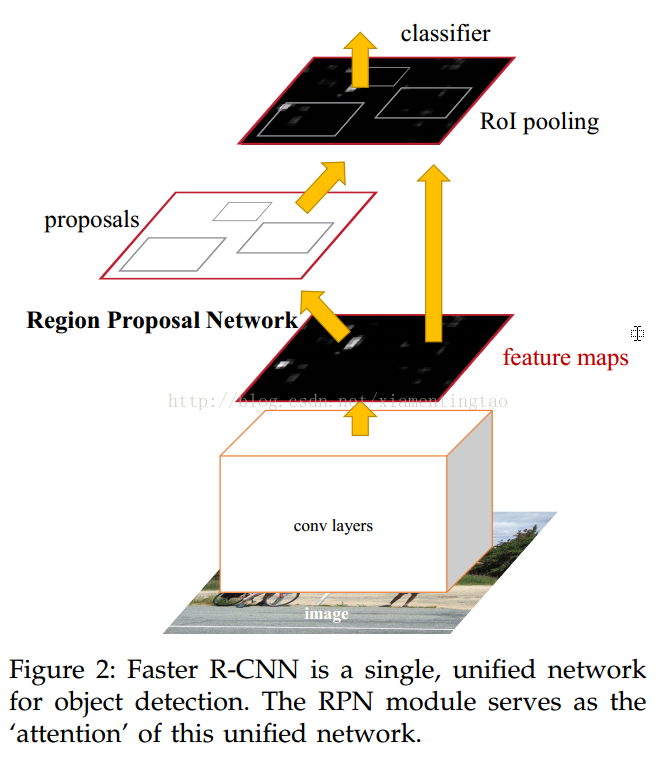
我們這里截取Ross'Girshick?在ICCV15上的ppt<Training'R-CNNs' ?of ?'various ?'velocities ? Slow, fast, and faster>??
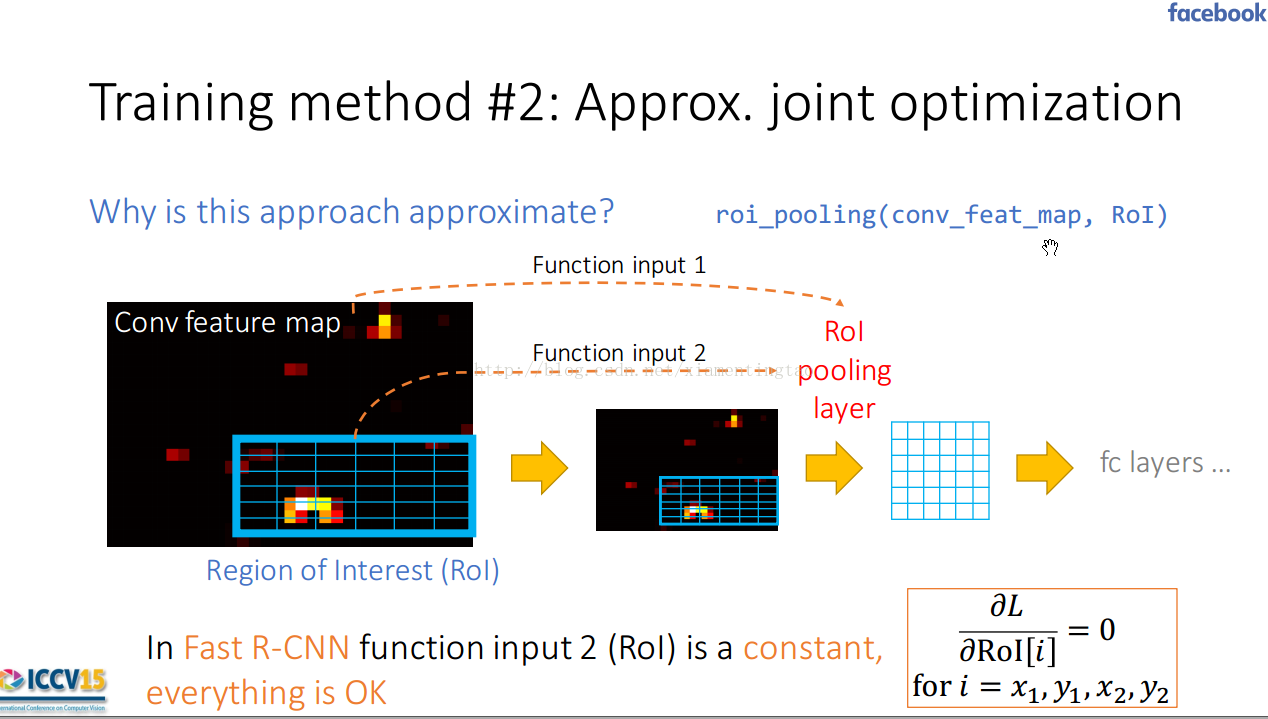
對于roi pooling層,顯然依賴于圖像本身,和roi區域。對于fast rcnn來講,roi是固定的,而對于faster rcnn來說,roi是通過rpn產生的,rpn不定,所以roi的生成依賴于
圖像。

但是由于最大池化的作用,所以沒有辦法對roi的四個位置求導。
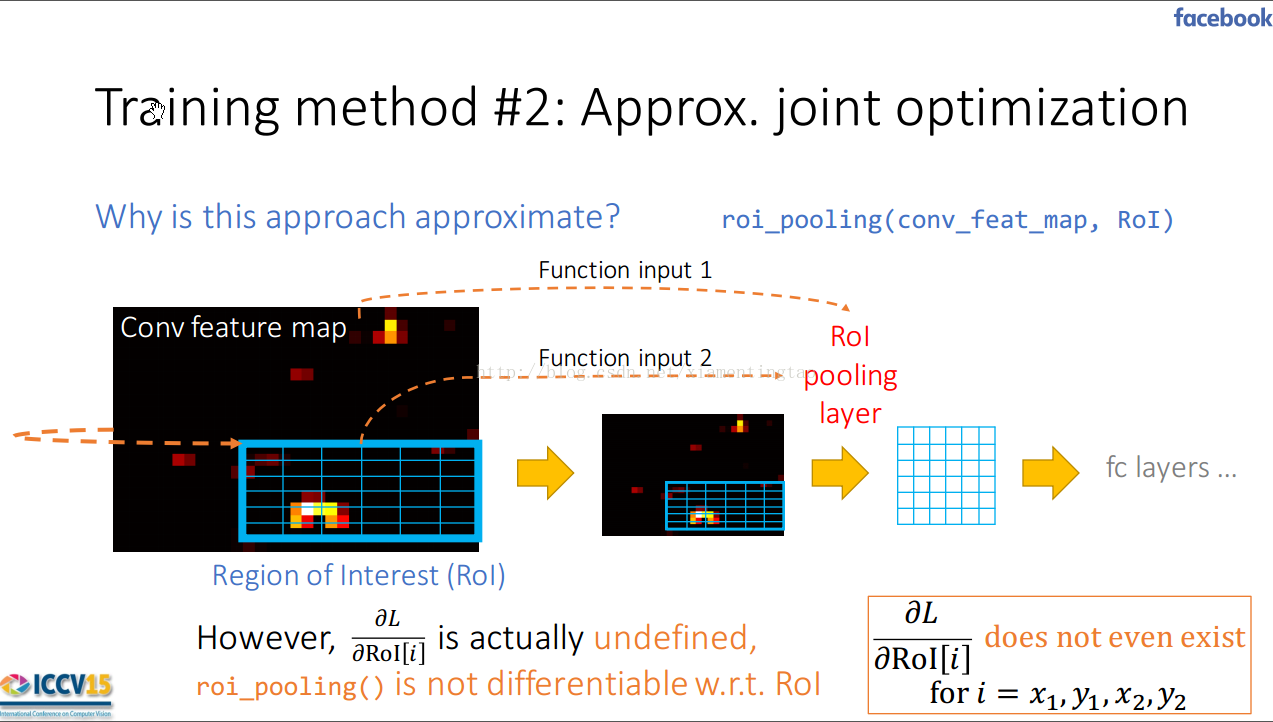

所以忽略掉對于roi的導數,當然了如果改變max pooling的方式,比如如下所說采取雙線性插值,這樣輸出既有roi的坐標也有圖像像素值,則可以關于roi求導。


根據github上py-faster-rcnn描述
- For training smaller networks (ZF, VGG_CNN_M_1024) a good GPU (e.g., Titan, K20, K40, ...) with at least 3G of memory suffices
- For training Fast R-CNN with VGG16, you'll need a K40 (~11G of memory)
- For training the end-to-end version of Faster R-CNN with VGG16, 3G of GPU memory is sufficient (using CUDNN)
使用end2end的訓練方式,顯存也減少了,從原先的11g減少到3g.我覺得主要的原因是在原先的交替訓練中,rpn訓練結束后,會有一個rpn生成的過程,這時會生成所有訓練圖片的proposals,而這是個巨大的負擔。而使用end2end的方式訓練,一次訓練一張圖片,rpn階段產生一張圖片的proposal,然后送入fast rcnn訓練。顯然這種方法很省時也很省內存。
對于end2end的測試,從網絡配置上基本與交替訓練的相同。在一些小的細節,比如end2end測試時仍然保留了drop層,而對于交替訓練的方式,在訓練階段有,測試時去掉了。
下面給出了個人畫的end2end的訓練網絡圖。
請訪問:鏈接

![[學習總結]7、Android AsyncTask完全解析,帶你從源碼的角度徹底理解](http://pic.xiahunao.cn/[學習總結]7、Android AsyncTask完全解析,帶你從源碼的角度徹底理解)

)





)









