本文作者岳龍廣,現在就職于樂視云計算有限公司,負責IaaS部門的工作。
從開始工作就混在開源世界里,在虛擬化方面做過CloudStack/Ovirt開發,現在是做以OpenStack為基礎的樂視云平臺。所以對虛擬化情有獨鐘,也對虛擬化/云計算的未來充滿了信心。
樂視網的所有服務是跑在樂視云上的,樂視云提供所有的底層支撐,包括IaaS/PaaS/Storage/CDN等等。為了帶給用戶更好的體驗,樂視網的服務到哪,樂視云的底層服務就會跟到哪。
其中虛擬化是必不可少的部分,它的快速提供、按需分配、資源隔離顯得特別重要,但我們會遇到什么問題呢?
今天的主要目的是分享我們在OpenStack項目中做的一部分工作,它們解決了內部的一些需求,也是實際經驗,希望對大家有所啟發。
開始之前 首先感謝肖總、浩宇、victor等朋友給予的大力支持,感謝群友、技術愛好者的圍觀。
很榮幸有這次機會來與大家做這個分享。
提綱:
1. IaaS Architecture
2. OpenStack Deploy & QOS
3. Multiple Regions
4. LeTV LBaaS
5. DEV
樂視云計算IaaS的基本架構
首先就是介紹一下樂視云計算基礎架構,再介紹OpenStack 網絡組件的部署,Multiple Regions是什么樣子的,更方便于使用的LeTV LBaaS,最后是開發/上線流程。
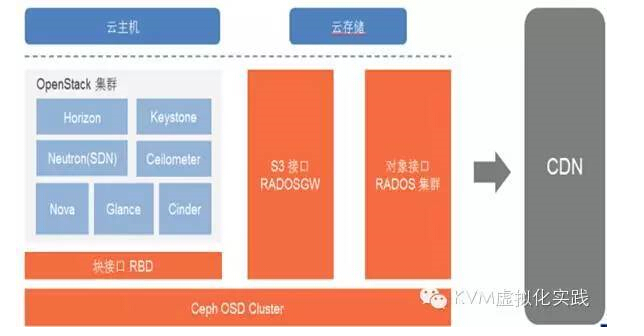
樂視云計算 IaaS 采用了 OpenStack 和 Ceph 的開源方案,為樂視提供了云主機、虛擬網絡、云硬盤和 S3 對象存儲。
?
我們采用了 Ceph RBD 作為 統一存儲,OpenStack使用的Cinder,后端接的是Ceph,Glance也是共享Ceph存儲。
我們同時還提供了 S3 對象存儲,用作于 CND 源站,存儲樂視網的視頻以及客戶需要分發的資源。
S3 也是全國分布式部署,用戶可以就近上傳,再推送到北京。
目前樂視云 OpenStack 規模已達 900 個物理節點,對象存儲的數據達到數PB。
Neutron Deployment & QOS

?
我們 Havana 版本采用了 nova-network 的 FlatDHCP 類型。
Icehouse 版本采用了 Neutron,再做足調研的前提下,我們對 Neutron 做了大量的減法,所用服務僅為 Neutron Server 和 OpenvSwitch Agent,控制節點部署 Neutron Server(with ML2 plugin),計算節點部署 OpenvSwitch Agent。
沒有網絡節點,因而沒有用到DHCP Agent,L3 agent 和 Metadata Agent。 物理網絡使用 VLAN 做隔離。由于 Region 數量較多,每個 region 有不同的物理網絡(對應ml2_conf 中的 physical_network 字段),可以緩解 VLAN 數量的限制。
私有云環境通過 Config Drive 配置虛擬機網卡和 metadata,Public IP 地址直接配在虛擬機網卡上,走物理路由器。無論是 nova-network 還是 neutron,我們都采用了穩定可靠的網絡,由于不存在網絡節點的單點問題,因此集群在滿足私有云的需求前提下,兼顧了可靠性、穩定性和可擴展性。
優點:簡單穩定,性能更好,這也是業務最需要的,線上業務穩定、可用性是最重要的。
缺點:犧牲了靈活性,和物理網絡的耦合度高
為了防止某個虛擬機負載過高而影響其它虛擬機或者宿主機,我們做了了 CPU,Network 和 Disk IO 的 QoS,其中 Cpu 的 QoS 采用 cgroup 實現,虛擬機網卡的 QoS 通過 TC 實現。
一開始我們采用了 cgroup 限制 Disk IO,由于 ceph 采用了 Non-host-block,故 cgroup 無法限制基于 ceph 的 Disk IO, 因此我們采用了 qemu io throttling。和 cgroup 相比,qemu io throttling 不僅僅能支持 non-host-block IO,同時限速的效果也更為出色,限速后,虛擬機的 IO 不會有太大抖動。
此外,如果基于 cgroup 的 Disk IO 設置過小,會導致虛擬機刪除失敗。原因在于 qemu 提交的 Direct IO 必須完成后才能退出,使用過小的磁盤帶寬導致此動作需很長時間才能完成,導致 qemu 進程不能及時響應 libvirt 發出的 SIGTERM 和 SIGKILL 信號。
而如果使用 qemu io throttling,則 io 會現在 qemu block layer 中加入 queue,此時 qemu 可以響應 libvirt 發出的信號而退出 。
使用 qemu io throttling 需要需注意的是,當 Xfs 扇區大小為4k時,qemu 以 cache=none 方式啟動失敗
Multiple Regions
?
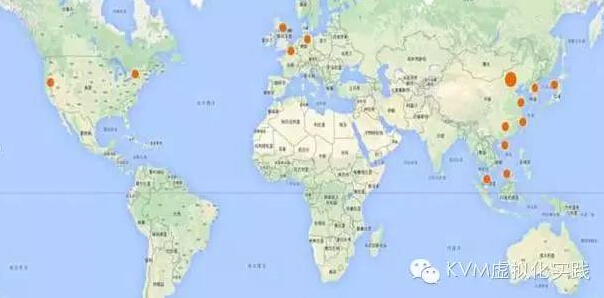
由于樂視網業務的特殊性,為了讓用戶有更好的體驗,服務會分散部署在全球。
樂視網的視頻服務需要 CDN 的支持,對于某些 CDN 節點,特別是國外,需要提供云主機等基礎設施服務。我們在國內外部署了有 20 多個集群,每個集群規模大小不一,其中最大的有上百個物理節點,這種需求也是極罕見的。
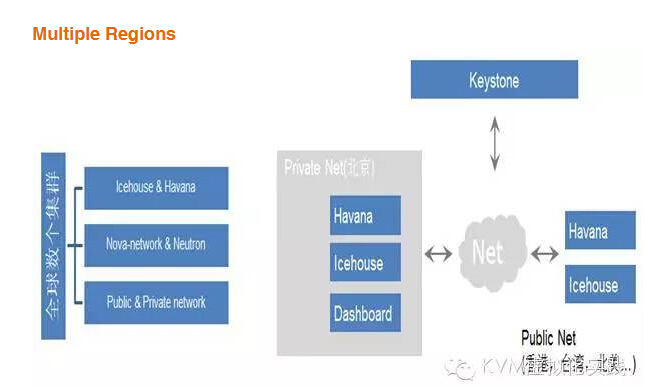
這些節點既有 Havana 版本,又有 Icehouse 版本。每個集群均維護獨自的 Dashboard 和用戶信息,這就造成了以下四個問題:
1. 用戶租戶信息不統一,不同集群的用戶信息不一致,對用戶使用有很大的影響
2. 訪問不同的集群,用戶需要登錄不同的 IP
3. 運維難度增加
4. 維護 H 和 I 版本的 Keystone 和 Horizon
隨著集群數量的不斷增加,上述問題將顯得越發突出,于是我們采用了 Multi-Region 方案,把這些集群做了統一的管理。
部署方面, Keystone 和 Horizon 全局唯一,其中 Keystone 部署在公網,從而能夠被其它服務訪問,Horizon 部署在內網,從而能夠訪問其它集群。這是大概的分布圖:
?
LeTV LBaaS
LeTV LBaaS,在原生LBaaS基礎上做了定制化,為了區分開來,就叫做LeTV LBaaS。
樂視網的服務需要高可用、擴展性。Neutron LBaaS 看起來是個不錯的選擇,基本框架有了,但是還不能完全滿足業務需要。
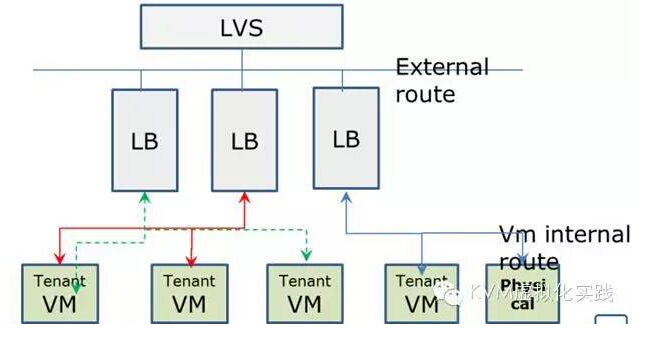
要想滿足業務需要,除了增強已有的接口,還有開發新的功能,比如HaProxy 冗余,本身服務健康檢查,以及與LVS整合。
?
這是實際業務架構,通過域名解析到LVS,LVS把流量負載到LB機器,在通過LB把流量負載到其他機器,實際提供服務的機器可以橫行擴展,不管是虛擬機還是物理機,甚至是容器。
Letv LBaaS 可以輕松滿足業務需求,優勢如下:
1. 不同業務之間的LB,互不干擾。Haproxy跑在各自的namespace里面
2. Haproxy HA 冗余功能,保證服務的高可用
3. 方便動態增加機器
4. 與LVS整合
DevOps & Community
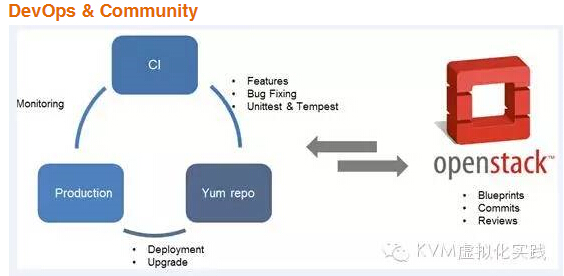
?
開發上線流程,基本和社區一致,是方便、可靠的:
Commit->Review->Auto Testing->Package->Testing->Production
最后總結一點建議:
方案的選取
1. 合適的才是最好的
2. 業務需求優先,穩定性優先
組件的選取
1. 盡量采用主流軟件,遇到問題可以快速解決
版本的選取
1. 成熟度與時新并重
虛擬化,虛擬計算,虛擬網絡,虛擬存儲,我們大多會第一個想到OpenStack,或者由OpenStack帶來的這些功能。
其實這些技術是可以獨立的,可以完美用到其他方面。讓所有的業務都跑在虛擬網絡里,為他們提供虛擬資源,并且可以輕而易舉的控制調整它們,方便管理整個數據中心,希望我們以后可以探討更大的話題。
Q&A
1.為什么沒有使用swift?
答: switft 我不熟悉,但是ceph 數據分布,性能方面都很不錯,crush算法是它的亮點。
2.可否介紹下你們的網絡架構 ,以及你們目前架構下對網絡的要求
答:總體的架構是標準的neutron架構,但是我們沒有部署網絡節點,直接使用物理路由器,這適合穩定性高的場景。
3.監控咱們這邊是怎么做的,是用社區原生的Celimeter還是自己的監控系統
答:是的ceilometer,做過優化,以及換成influxdb,包括對floatingIP的流量監控。
4.iaas層是否提供了nas接口,視頻轉碼,合成等業務軟件訪問存儲是通過S3 接口還是其他接口呢;
答:沒有NAS接口。視頻提供了S3和HTTP接口。
5.選Haproxy有什么優勢嗎?
答:HaProxy 是專注于負載均衡的功能,提供的算法比較豐富,并發性也更好。
6.你提到有的有集群上百個物理節點,部署這些物理節點時候,采用什么方法的?
答:參照問題2。
7.集群把公網線和心跳線用反了有什么后鍋,我感覺誰當心跳誰當公網,沒什么大不了,求解
答:你說的心跳線是指什么? 公網是收費的,大家不希望浪費購買的帶寬,所有不穩定的因素多。 內網做心跳更好,心跳實時性要求高。
8.交換機上的VLAN全手動配置?交換機也手動配置與虛擬機TC相對應的QoS?
答:是的,這個地方的QOS 主要是限速。
9.高可用如何保證的
答:DNS負載均衡 和 LVS 高可用,共同保證總的高可用。
10.那db性能怎么解決?
答:一般沒問題,如果ceilometer 采樣頻繁,vm多的話,撐不住。我們現在是influxdb,已經對采樣頻率和采樣的內容進行裁剪。
11.對于些開發能力小的公司來說,使用上openstack不?openstack在虛擬機的基礎上做了資源管理,目的是充分利用資源吧?cpu方面的分配很好理解,IO能調配不?有一些場景是,部分機器io很閑,部分IO很忙,可以調整利充分用上?樂視的定制版在這方面有改進呢?
答:如果沒有太多需求,可以用virt-manager,直接管理。 openstack 還是比較復雜的。但是虛擬化可以大量節省成本io就是限制讀寫磁盤的速率iops 或者帶寬 ,qemu 自身可以限制。
12.公網絡這塊,這接把pub ip配置到容器,那平臺的防火墻策略在哪一層做限制?
答:外層防火墻,一般是3,4層. 是否控制 7層,我不能確定。
13.二次開發主要是改了哪些地方
答:社區有我們提交的代碼。
14.底層操作系統是啥?rehl6,7? or ubuntu?
答:centos6.5~。
15.上線往各個節點推送文件,是用什么推的呢
答:是puppet。
16.LVS是什么?會有單點問題嗎?
答:LVS 是linux virtual server, 沒有單點故障,參見問題9。
17.會有一個業務幾個region都有vm,需要互通嗎?
答:部署在幾個region 是為了高可用性。 大家都會訪問同一個數據庫。
18.請問平均一個節點多少虛機?
答:為了保證業務,我們的配比 比較低。沒有超過1:10. 主要看業務和重要程度。
19.每次版本更新需要多長時間,什么范圍內更新呢?
答:我們現在是長期維護一個穩定版本。
20.在問個成本問題,是用的整理柜服務器還是定制的服務器,一個機柜裝幾臺?
答:不好意思,這個問題,我回答不了你,抱歉。
21.華為分布式存儲要求各個機器硬盤配置一樣,ceph有這個要求嗎?
答:沒有強制要求,ceph 可以設置機器的權重。
22.keystone,horizon全局唯一,是放在一個region里面還是怎么做冗余的?
答:主要做好數據庫冗余就好,前端部署LB,提供 高可用和并發。
23.想問下硬件資源cpu,mem,storage的超配比,是怎么調配的
答:這個要根據自己的策略來定,看你的flavor,超配等。
24.請問是否有對云主機安裝agent用做監控來收集信息
答:一般不需要,這個地方只是為了取內存數據。
25. ceph穩定性如何?性能和san或者nas做過對比測試嗎?
答:和本地做過對比, san 和nas 品種很多,看對IO的要求,業務要求,ceph性能和穩定性都不錯。

-Wednesday)
...)


![[OJ] Wildcard Matching (Hard)](http://pic.xiahunao.cn/[OJ] Wildcard Matching (Hard))
)






![[軟件測試airtest軟件安裝]——填坑](http://pic.xiahunao.cn/[軟件測試airtest軟件安裝]——填坑)


右移操作>>)


