2019獨角獸企業重金招聘Python工程師標準>>> 
修改字符集
查看字符集
show variables like 'character%' show variables like '%char%'
上面的兩個命令都可以,我一般使用的下面的,會出來如下幾個字符集設定的選項:
character_set_client:客戶端請求數據的字符集character_set_connection:從客戶端接收到數據,然后傳輸的字符集character_set_database:默認數據庫的字符集,無論默認數據庫如何改變,都是這個字符集;如果沒有默認數據庫,那就使用?character_set_server指定的字符集,
? 這個變量建議由系統自己管理,不要人為定義。character_set_filesystem:把os上文件名轉化成此字符集,即把 character_set_client轉換character_set_filesystem, 默認binary是不做任何轉換的character_set_results:結果集的字符集character_set_server:數據庫服務器的默認字符集character_set_system:這個值總是utf8,不需要設置,是為存儲系統元數據的字符集
修改配置文件
? 修改/etc/my.cnf配置文件
在client下做如下一個選項的修改
[client] default-character-set=utf8 [mysqld] character_set_server=utf8 character_set_client=utf8 collation-server=utf8_general_ci lower_case_table_names=1 max_connections=1000 [mysql] default-character-set=utf8
配置文件
目前整個配置文件內容
[client] default-character-set=utf8 [mysqld] server-id=1 log-bin=mysql-bin datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock user=mysql # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 ? character_set_server=utf8 character_set_client=utf8 collation-server=utf8_general_ci ? [mysqld_safe] log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid ? [mysql] default-character-set=utf8
?
log-bin
? 定義主從復制文件前綴,后面生成的文件在datadir+logbin-filename
如:
? 里面不僅有log-bin文件,還有創建的數據庫對應的目錄等
log-error
? MySql的一些重要的數據信息都會在里面,日常運維監控都需要打開看看,例如將執行時間超過1秒的SQL輸出
datadir
-
frm文件-相當于表的元數據
-
myd文件-表的數據文件
-
myi文件-表的索引文件
SQL性能下降原因
可能問題
1.查詢語句寫的爛
? SQL關聯的表很多,條件很復雜,很多子查詢等,導致生成的執行計劃有問題而無法生成索引
2.索引失效
? 單值索引:索引建立在單列上
? 組合索引:索引建立在多個字段上,如果查詢的條件經常出現多列的同一個組合,那么創建組合索引非常高效
3.關聯查詢太多
? 現在硬件設備都已經起來的,數據庫表設計幾乎都不在嚴格遵循三范式,增加冗余,提高查詢速度,以空間換時間。不過這樣設計也有一些毛病,在做update的時候就必須修改更多的地方,否則會導致數據一致性問題
? 在分布式數據庫中,如果跨主機關聯太多,會導致大量的網絡通信,極大的增加了SQL執行時長
? 如果確實不得不關聯很多表,建議將一個大SQL拆分成小SQL,增強SQL執行計劃的穩定性
4.服務器調優
? 修改排序緩沖和數據緩沖大小,修改線程數大小
關聯查詢
SQL讀取執行順序
SELECT distinct column_list ?FROM taba ?JOIN tabb ON join_condition ?WHERE where-condition ?GROUP BY group-by-list ?HAVING having-condition ?ORDER BY order-by-condition ?LIMIT limit-number
?
Mysql讀取順序

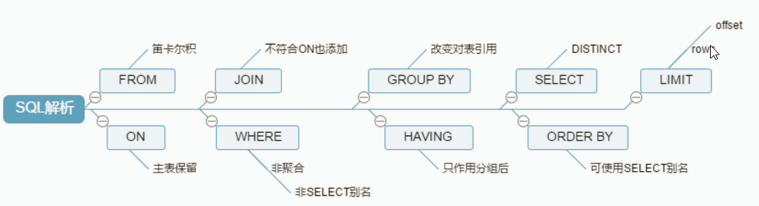
先求關聯表的笛卡爾積——》得到主表結果數據——》做join,不符合on的數據也補充到結果中——》做條件過濾——》分組——》分組過濾——》結果集列篩選——》排序——》限定返回結果集
7中JOIN寫法
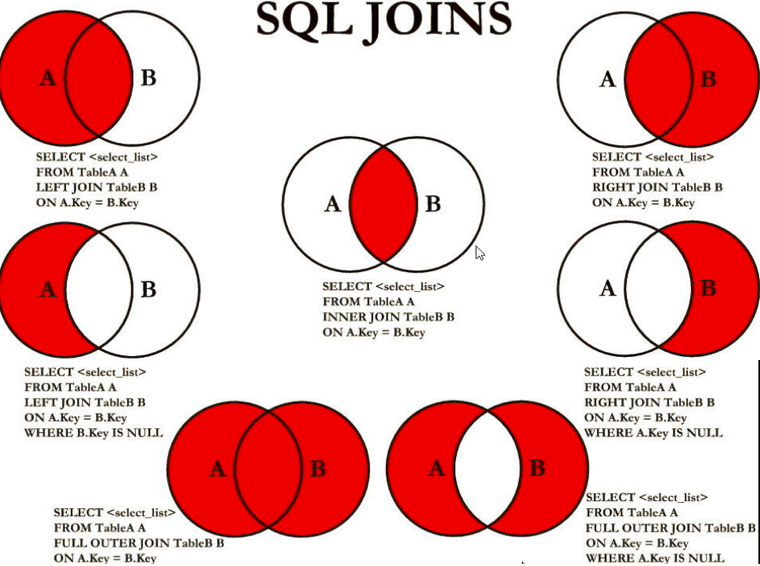
1.INNER JOIN 內連接
? SELECT <select_list>
? FROM taba a
? INNER JOIN tabb b
? ON a.key = b.key
2.LEFT JOIN 左外連接
? SELECT <select_list>
? FROM taba a
? LEFT JOIN tabb b
? ON a.key = b.key
3.RIGHT JOIN 右外連接
? SELECT <select_list>
? FROM taba a
? RIGHT JOIN tabb b
? ON a.key = b.key
4.LEFT JOIN 求差
? SELECT <select_list>
? FROM taba a
? LEFT JOIN tabb b
? ON a.key = b.key
? WHERE b.key is NULL
5.RIGHT JOIN 求差
? SELECT <select_list>
? FROM taba a
? RIGHT JOIN tabb b
? ON a.key = b.key
? WHERE a.key is NULL
6.FULL JOIN 求并集
? SELECT <select_list>
? FROM taba a
? FULL OUTER JOIN tabb b
? ON a.key = b.key
7.FULL JOIN 求非交叉結果集
? SELECT <select_list>
? FROM taba a
? FULL OUTER JOIN tabb b
? ON a.key = b.key
? WEHRE a.key is NULL OR b.key is NULL
索引
什么是索引
? 為了提高數據查詢速度而設計的數據結構,一般情況下這種數據結構都是B+樹(一顆已經排好序的樹)。查詢時,從樹的根節點開始比較,小于根的走左孩子,大于根的走右孩子。
優勢
? 查詢時走索引比全表掃描可以大大降低IO,提高查詢速度
? 索引是已經做完排序的列,拿到的數據是已經有序,減少CPU的時候
? 如果返回的列是索引列,那么都不需要從數據塊從拿數據。
劣勢
? 增加了額外的存儲需求
? 如果表設計有問題,而且查詢條件很多,建很多索引的話,表所對應的索引甚至可能比表占用的空間還大
? 索引的存在會降低DML效率,頻繁的DML操作甚至會影響執行計劃,錯誤的執行計劃會導致SQL執行很慢
? 如果表很大,索引經常可能需要不停的優化,采集表的統計信息,基于更好更全的統計信息才能有更優的執行計劃生成
? 列有大量NULL值不建議創建索引
索引的分類
? 1.單值索引:根據一個列創建索引,然而大多數情況下都是根據查詢條件創建多值索引
? 2.唯一索引:索引列的數據是唯一的
? 3.復合索引:索引的列有多個,比如根據入學時間和學號區間查詢所有學生,那么就可以創建一個符合索引(入學時間+學號)
索引B+樹
?
假設要查詢key=29,根磁盤塊1中的17和35比,下一步應該找磁盤快3中的P2,在與該P2中的26和30比,下一步找磁盤快8,找到29這個索引項,然后拿該索引項的指針去數據區拿真實的數據行
該如何決定是否創建索引
? 1.主鍵會自動創建索引
? 2.頻繁查詢的條件需要建立復合索引
? 3.和其他表有外鍵的列,要創建索引
? 4.頻繁執行DML操作的字段不適合創建索引,原因是DML會導致索引重建
? 5.where 條件用不到的列不適合創建索引
? 6.拋開主鍵和特殊場景,一般都是創建復合索引
? 7.在設計組合索引的時候,應該考慮到查詢字段需求和排序字段需求,盡量保持復合索引字段與查詢排序條件一致,可以提高效率
? 8.查詢中統計或者分組的字段
? 9.表太小完全沒有必要創建索引,因為只需要一次IO就把整表拿了過來
? 10.重復值嚴重的列不適合創建索引,比如100W條記錄,而某一列只有3種重復的值,而且三種值絕大多數都是某一種,那么根據該列查詢時,選擇率非常低,近似于全表掃描。在生產中,主要是表的狀態字段或者性別字段等等
? 有這么多限制,可能創建出來的索引可能會很多,特別是字段特別多的表,這種情況最好和DBA一起協商



)





-簡介)

(源碼)(三)...)






EasyUI使用——datagrid數據表格)
