編碼回顧
編碼轉換
Python的bytes類型
?
編碼回顧
在備編碼相關的課件時,在知乎上看到一段關于Python編碼的回答
這哥們的這段話說的太對了,搞Python不把編碼徹底搞明白,總有一天它會猝不及防坑你一把。
不過感覺這哥們的答案并沒把編碼問題寫明白,所以只好親自動筆了。?
折騰編碼問題,有很多次,我以為自已明白了,最終發現,那只不過是自圓其說而已,這一次,終于100%確定,動筆即不再改!
?
?
看這篇文章前,你應該已經知道了為什么有編碼,以及編碼的種類情況
- ASCII 占1個字節,只支持英文
- GB2312 占2個字節,支持6700+漢字
- GBK GB2312的升級版,支持21000+漢字
- Shift-JIS 日本字符
- ks_c_5601-1987 韓國編碼
- TIS-620 泰國編碼
由于每個國家都有自己的字符,所以其對應關系也涵蓋了自己國家的字符,但是以上編碼都存在局限性,即:僅涵蓋本國字符,無其他國家字符的對應關系。應運而生出現了萬國碼,他涵蓋了全球所有的文字和二進制的對應關系,
- Unicode 2-4字節 已經收錄136690個字符,并還在一直不斷擴張中...
Unicode 起到了2個作用:
- 直接支持全球所有語言,每個國家都可以不用再使用自己之前的舊編碼了,用unicode就可以了。(就跟英語是全球統一語言一樣)
- unicode包含了跟全球所有國家編碼的映射關系,為什么呢?后面再講
Unicode解決了字符和二進制的對應關系,但是使用unicode表示一個字符,太浪費空間。例如:利用unicode表示“Python”需要12個字節才能表示,比原來ASCII表示增加了1倍。
由于計算機的內存比較大,并且字符串在內容中表示時也不會特別大,所以內容可以使用unicode來處理,但是存儲和網絡傳輸時一般數據都會非常多,那么增加1倍將是無法容忍的!!!
為了解決存儲和網絡傳輸的問題,出現了Unicode Transformation Format,學術名UTF,即:對unicode中的進行轉換,以便于在存儲和網絡傳輸時可以節省空間!
- UTF-8: 使用1、2、3、4個字節表示所有字符;優先使用1個字符、無法滿足則使增加一個字節,最多4個字節。英文占1個字節、歐洲語系占2個、東亞占3個,其它及特殊字符占4個
- UTF-16: 使用2、4個字節表示所有字符;優先使用2個字節,否則使用4個字節表示。
- UTF-32: 使用4個字節表示所有字符;
總結:UTF 是為unicode編碼 設計 的一種 在存儲 和傳輸時節省空間的編碼方案。
?
字符在硬盤上的存儲?
無論以什么編碼在內存里顯示字符,存到硬盤上都是2進制。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | ascii編碼(美國):????l???0b1101100????o???0b1101111????v???0b1110110????e???0b1100101GBK編碼(中國):????老???0b11000000?0b11001111????男???0b11000100?0b11010000????孩???0b10111010?0b10100010Shift_JIS編碼(日本):????私???0b10001110?0b10000100????は???0b10000010?0b11001101ks_c_5601-1987編碼(韓國):????????0b10110011?0b10101010????????0b10110100?0b11000010?????TIS-620編碼(泰國):?????????0b10101001?0b11010001?0b10111001... |
| 1 | 要注意的是,存到硬盤上時是以何種編碼存的,再從硬盤上讀出來時,就必須以何種編碼讀,要不然就亂了。。 |
編碼的轉換?
雖然國際語言是英語 ,但大家在自己的國家依然說自已的語言,不過出了國, 你就得會英語
編碼也一樣,雖然有了unicode and utf-8 , 但是由于歷史問題,各個國家依然在大量使用自己的編碼,比如中國的windows,默認編碼依然是gbk,而不是utf-8?
基于此,如果中國的軟件出口到美國,在美國人的電腦上就會顯示亂碼,因為他們沒有gbk編碼。
若想讓中國的軟件可以正常的在 美國人的電腦上顯示,只有以下2條路可走:
- 讓美國人的電腦上都裝上gbk編碼?
- 把你的軟件編碼以utf-8編碼
第1種方法幾乎不可能實現,第2種方法比較簡單。 但是也只能是針對新開發的軟件。 如果你之前開發的軟件就是以gbk編碼的,上百萬行代碼可能已經寫出去了,重新編碼成utf-8格式也會費很大力氣。
so , 針對已經用gbk開發完畢的項目,以上2種方案都不能輕松的讓項目在美國人電腦上正常顯示,難道沒有別的辦法了么?
有, 還記得我們講unicode其中一個功能是其包含了跟全球所有國家編碼的映射關系,意思就是,你寫的是gbk的“路飛學城”,但是unicode能自動知道它在unicode中的“路飛學城”的編碼是什么,如果這樣的話,那是不是意味著,無論你以什么編碼存儲的數據 ,只要你的軟件在把數據從硬盤讀到內存里,轉成unicode來顯示,就可以了。
由于所有的系統、編程語言都默認支持unicode,那你的gbk軟件放到美國電腦 上,加載到內存里,變成了unicode,中文就可以正常展示啦。
?這個表你自己也可以下載下來?
unicode與gbk的映射表?http://www.unicode.org/charts/?
?
Python3的執行過程
在看實際代碼的例子前,我們來聊聊,python3 執行代碼的過程?
- 解釋器找到代碼文件,把代碼字符串按文件頭定義的編碼加載到內存,轉成unicode
- 把代碼字符串按照語法規則進行解釋,
- 所有的變量字符都會以unicode編碼聲明
編碼轉換過程
實際代碼演示,在py3上 把你的代碼以utf-8編寫, 保存,然后在windows上執行,
| 1 2 | s?=?'路飛學城'print(s) |
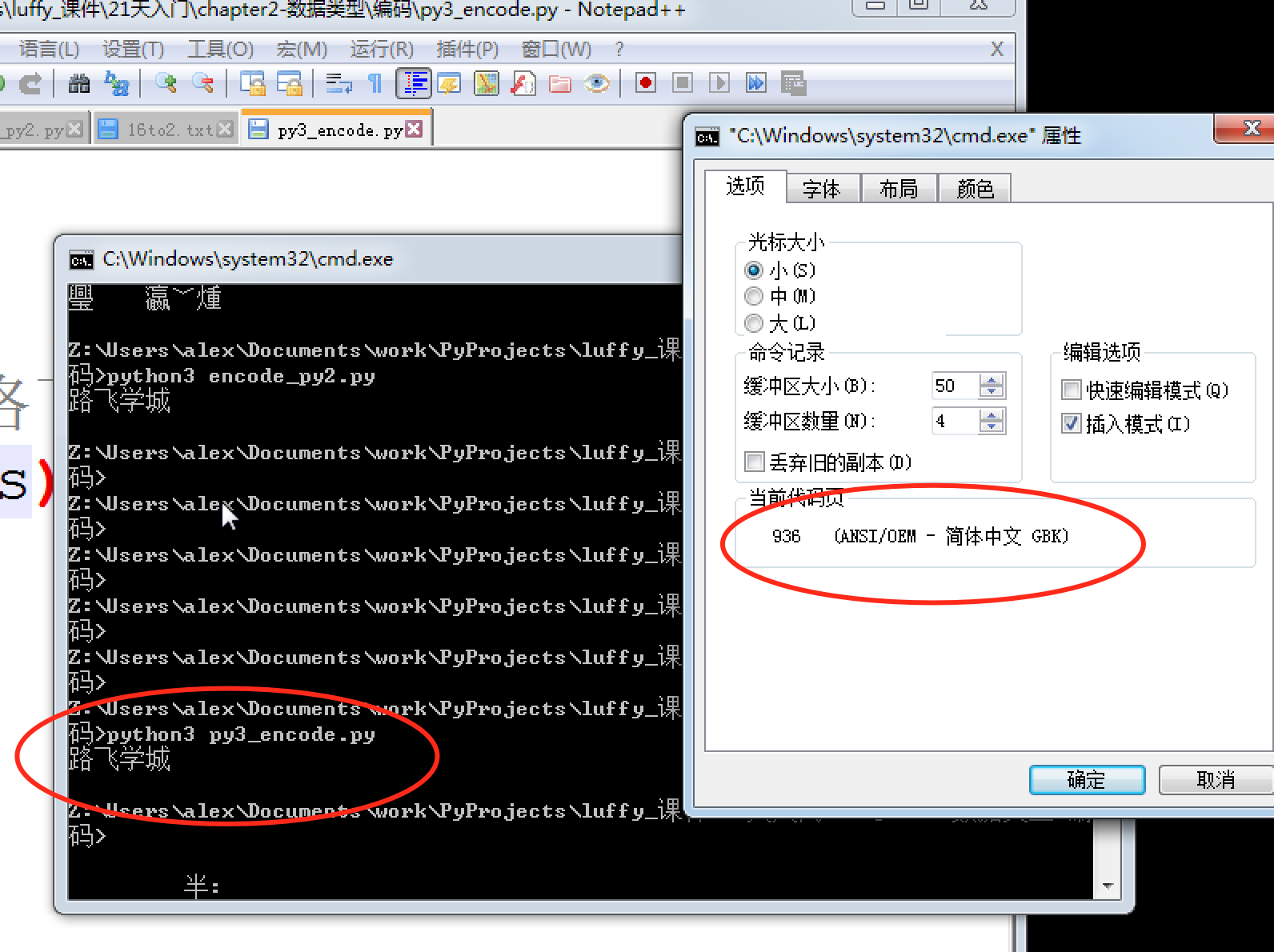
so ,一切都很美好,到這里,我們關于編碼的學習按說就可以結束了。
?
但是,如生活一樣,美好的表面下,總是隱藏著不盡如人意,上面的utf-8編碼之所以能在windows gbk的終端下顯示正常,是因為到了內存里python解釋器把utf-8轉成了unicode , 但是這只是python3, 并不是所有的編程語言在內存里默認編碼都是unicode,比如 萬惡的python2 就不是, 它的默認編碼是ASCII,想寫中文,就必須聲明文件頭的coding為gbk or utf-8, 聲明之后,python2解釋器僅以文件頭聲明的編碼去解釋你的代碼,加載到內存后,并不會主動幫你轉為unicode,也就是說,你的文件編碼是utf-8,加載到內存里,你的變量字符串就也是utf-8, 這意味著什么你知道么?。。。意味著,你以utf-8編碼的文件,在windows是亂碼。?
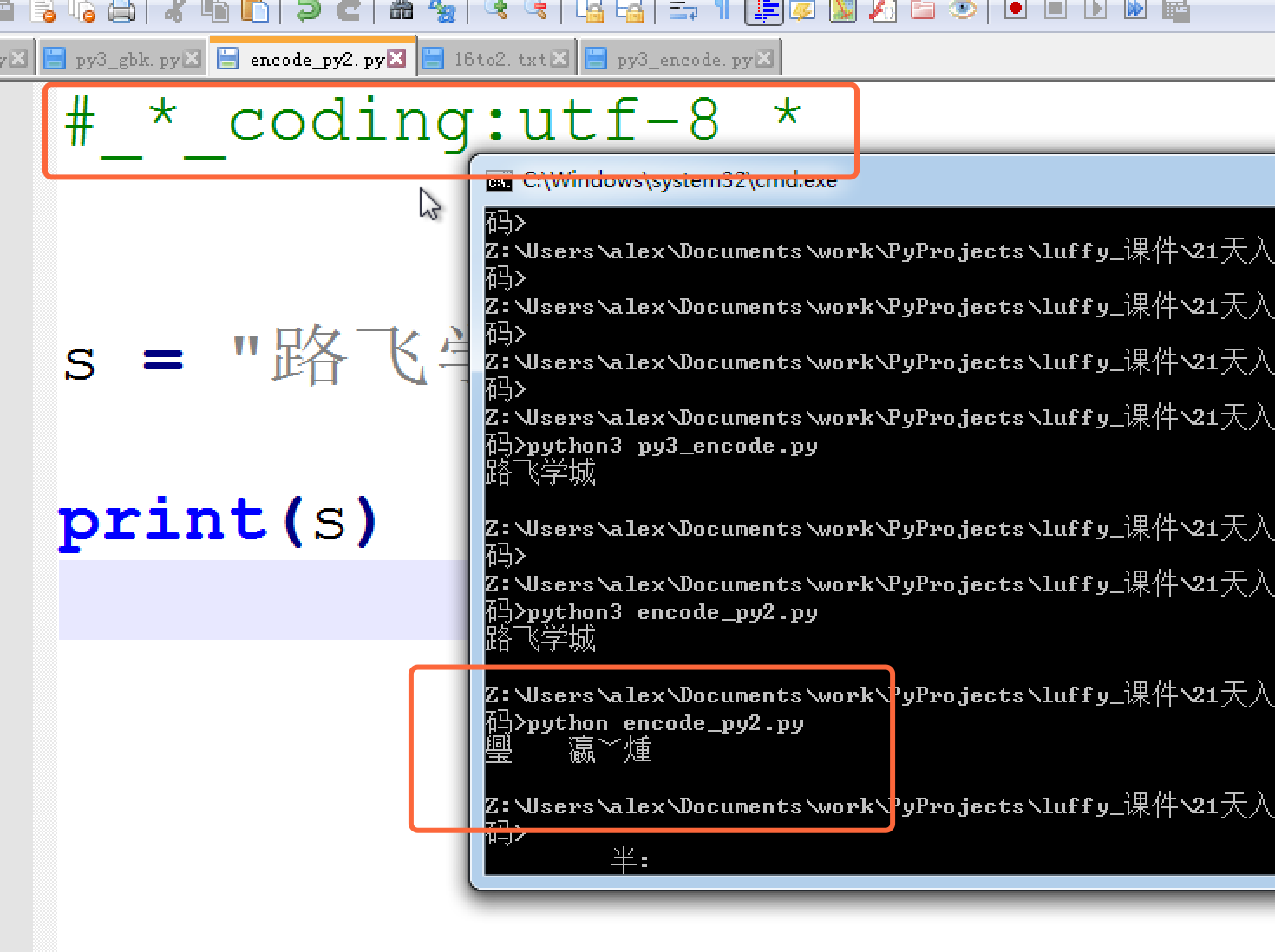
?
亂是正常的,不亂才不正常,因為只有2種情況 ,你的windows上顯示才不會亂
- 字符串以GBK格式顯示
- 字符串是unicode編碼
既然Python2并不會自動的把文件編碼轉為unicode存在內存里, 那就只能使出最后一招了,你自己人肉轉。Py3 自動把文件編碼轉為unicode必定是調用了什么方法,這個方法就是,decode(解碼) 和encode(編碼)
| 1 2 | UTF-8?--> decode 解碼?-->?UnicodeUnicode?--> encode 編碼?--> GBK?/?UTF-8?..? |
?
decode示例

?
encode 示例
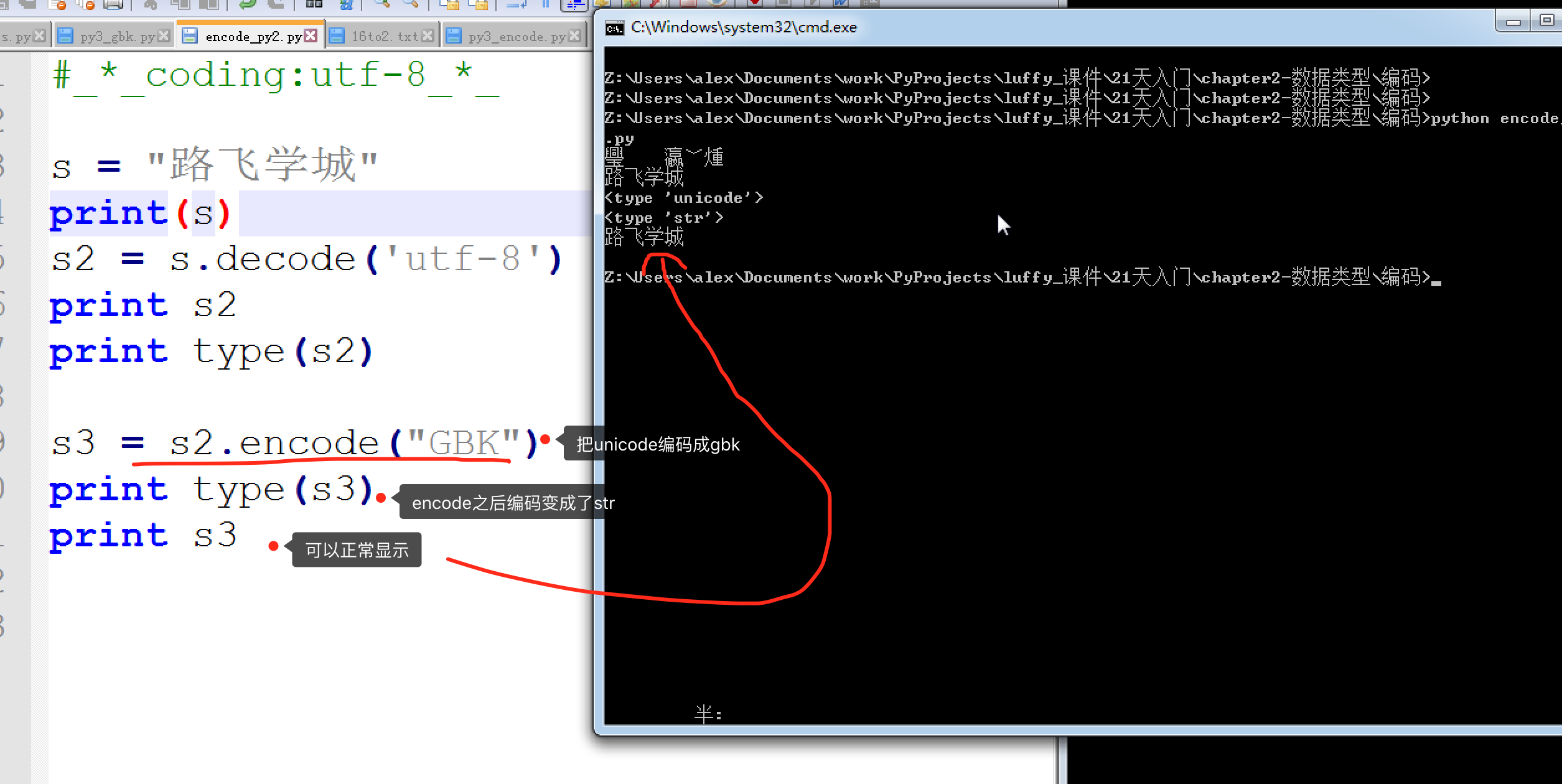
?
記住下圖規則
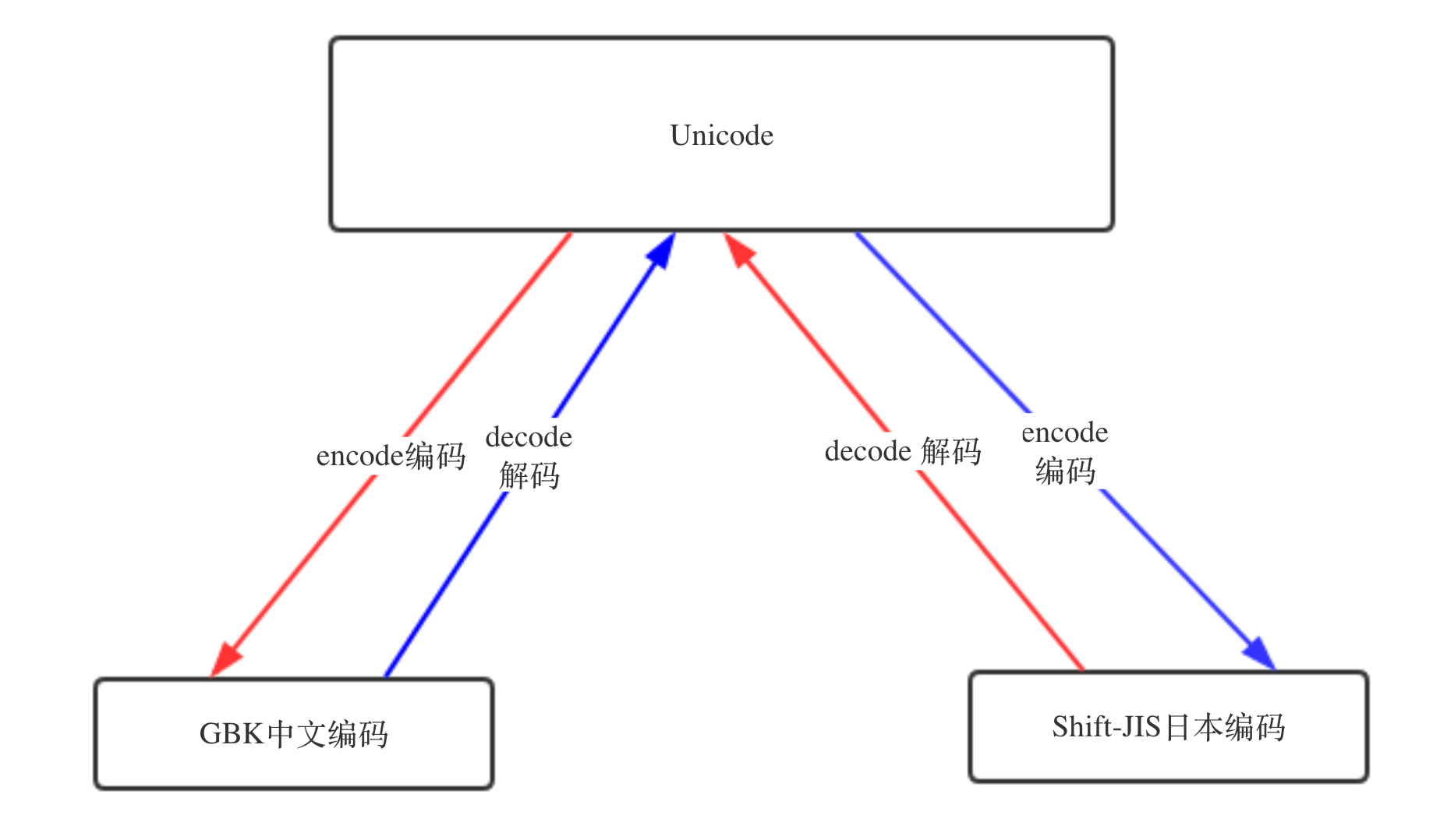
?
如何驗證編碼轉對了呢?
1. 查看數據類型,python 2 里有專門的unicode 類型
2. 查看unicode編碼映射表
unicode字符是有專門的unicode類型來判斷的,但是utf-8,gbk編碼的字符都是str,你如果分辨出來的當前的字符串數據是何種編碼的呢? 有人說可以通過字節長度判斷,因為utf-8一個中文占3字節,gbk一個占2字節
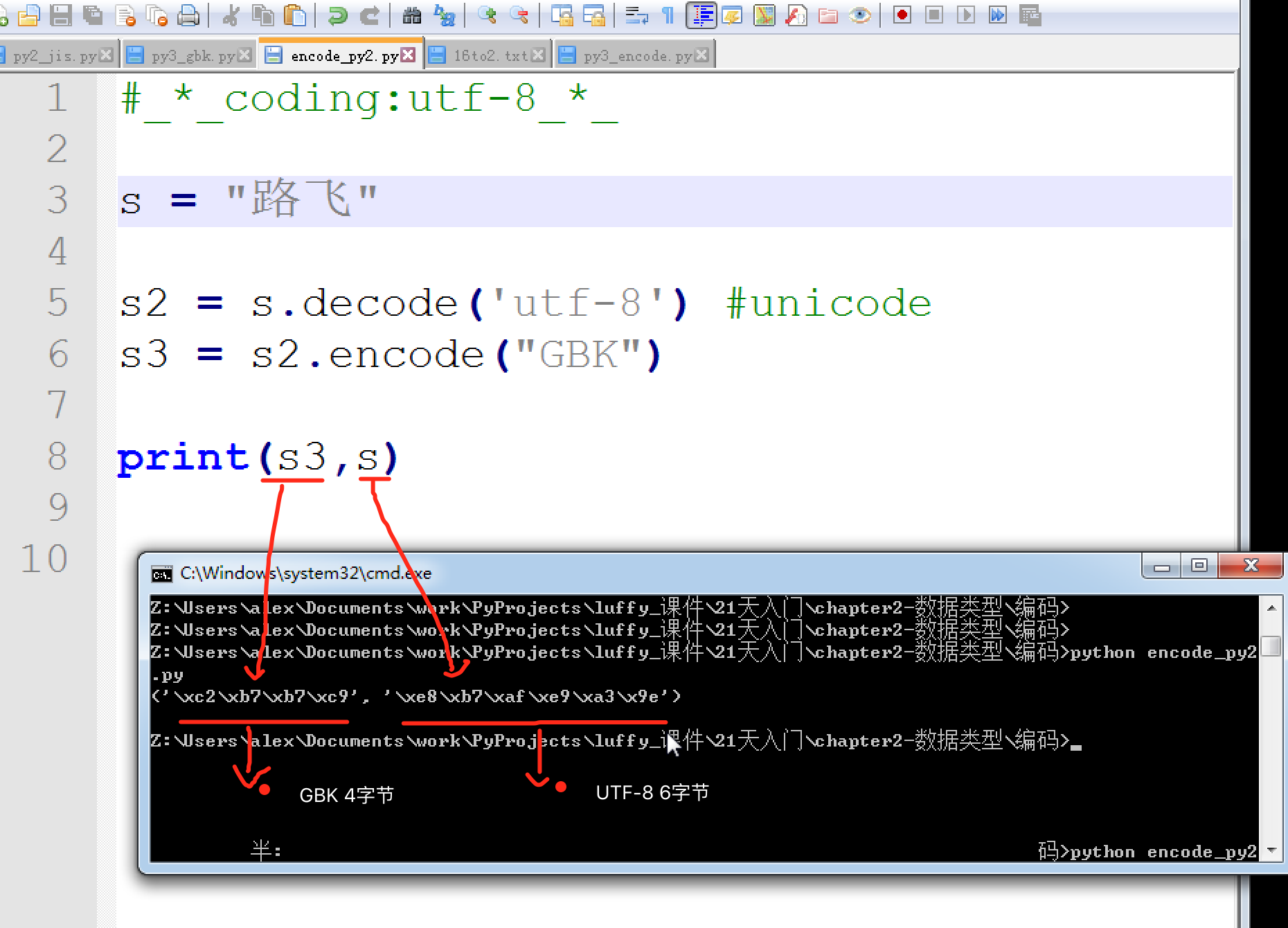
靠上面字節個數,雖然也能大體判斷是什么類型,但總覺得不是很專業。
怎么才能精確的驗證一個字符的編碼呢,就是拿這些16進制的數跟編碼表里去匹配。
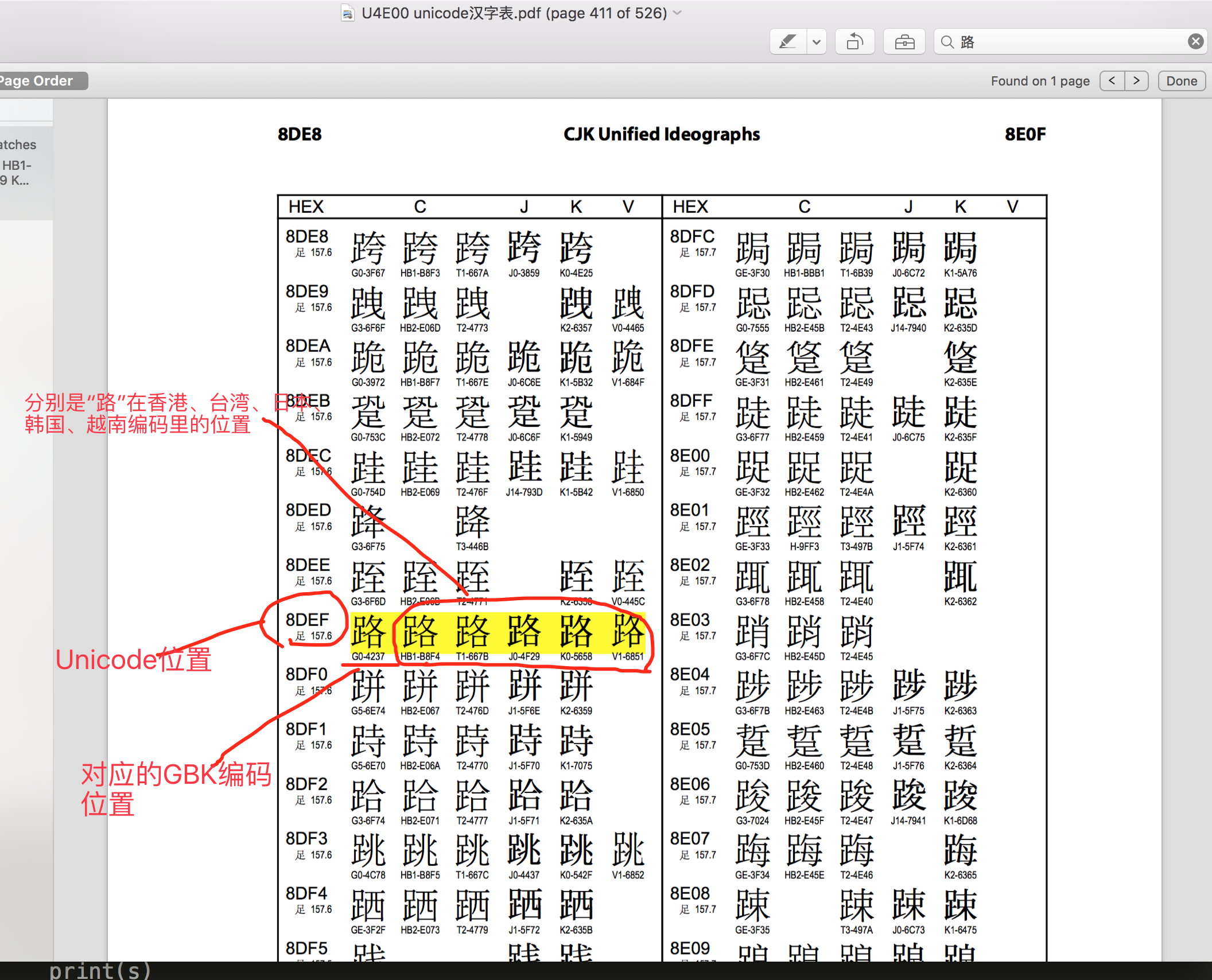
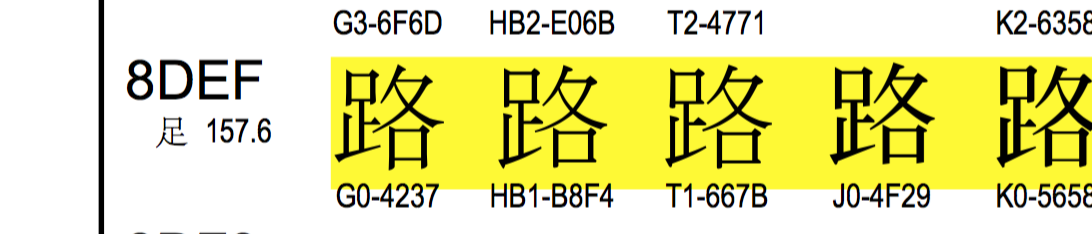
“路飛學城”的unicode編碼的映射位置是 u'\u8def\u98de\u5b66\u57ce' ,‘\u8def’ 就是‘路’,到表里搜一下。
“路飛學城”對應的GBK編碼是'\xc2\xb7\xb7\xc9\xd1\xa7\xb3\xc7' ,2個字節一個中文,"路" 的二進制 "\xc2\xb7"是4個16進制,正好2字節,拿它到unicode映射表里對一下, 發現是G0-4237,并不是\xc2\xb7呀。。。擦。演砸了吧。。
? ??
??
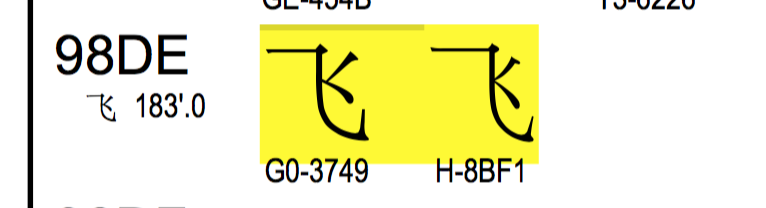
再查下“飛” \u98de ,對應的是G0-3749, 跟\xb7\xc9也對不上。
?
?
雖然對不上, 但好\xc2\xb7 和G0-4237中的第2位的2和第4位的7對上了,“飛”字也是一樣,莫非巧合??
把他們都轉成2進制顯示試試?
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | 路C???????????????28???4???2???1???8???4???2???1<strong>1???1???0???0???0???0???1???0</strong>B???????????????78???4???2???1???8???4???2???1<strong>1???0???1???1???0???1???1???1</strong>飛B???????????????78???4???2???1???8???4???2???11???0???1???1???0???1???1???1C???????????????98???4???2???1???8???4???2???11???1???0???0???1???0???0???1 |
這個“路”還是跟G0-4237對不上呀,沒錯, 但如果你把路\xc2\xb7的每個二進制字節的左邊第一個bit變成0試試呢, 我擦,加起來就真的是4237了呀。。難道又是巧合????
?
必然不是,是因為,GBK的編碼表示形式決定的。。因為GBK編碼在設計初期就考慮到了要兼容ASCII,即如果是英文,就用一個字節表示,2個字節就是中文,但如何區別連在一起的2個字節是代表2個英文字母,還是一個中文漢字呢? 中國人如此聰明,決定,2個字節連在一起,如果每個字節的第1位(也就是相當于128的那個2進制位)如果是1,就代表這是個中文,這個首位是128的字節被稱為高字節。 也就是2個高字節連在一起,必然就是一個中文。 你怎么如此篤定?因為0-127已經表示了英文的絕大部分字符,128-255是ASCII的擴展表,表示的都是極特殊的字符,一般沒什么用。所以中國人就直接拿來用了。?
?
問:那為什么上面?"\xc2\xb7"的2進制要把128所在的位去掉才能與unicode編碼表里的G0-4237匹配上呢?
這只能說是unicode在映射表的表達上直接忽略了高字節,但真正映射的時候 ,肯定還是需要用高字節的哈。
?
Python bytes類型
在python 2 上寫字符串
| 1 2 3 4 5 | >>> s?=?"路飛">>>?print?s路飛>>> s'\xe8\xb7\xaf\xe9\xa3\x9e' |
雖說打印的是路飛,但直接調用變量s,看到的卻是一個個的16進制表示的二進制字節,我們怎么稱呼這樣的數據呢?直接叫二進制么?也可以, 但相比于010101,這個數據串在表示形式上又把2進制轉成了16進制來表示,這是為什么呢? 哈,為的就是讓人們看起來更可讀。我們稱之為bytes類型,即字節類型, 它把8個二進制一組稱為一個byte,用16進制來表示。?
說這個有什么意思呢?
想告訴你一個事實, 就是,python2的字符串其實更應該稱為字節串。 通過存儲方式就能看出來, 但python2里還有一個類型是bytes呀,難道又叫bytes又叫字符串? 嗯 ,是的,在python2里,bytes == str , 其實就是一回事
除此之外呢, python2里還有個單獨的類型是unicode , 把字符串解碼后,就會變成unicode
| 1 2 3 4 5 6 | >>> s'\xe8\xb7\xaf\xe9\xa3\x9e'?#utf-8>>> s.decode('utf-8')u'\u8def\u98de'?#unicode 在unicode編碼表里對應的位置?>>>?print(s.decode('utf-8'))?路飛?#unicode 格式的字符 |
由于Python創始人在開發初期認知的局限性,其并未預料到python能發展成一個全球流行的語言,導致其開發初期并沒有把支持全球各國語言當做重要的事情來做,所以就輕佻的把ASCII當做了默認編碼。 當后來大家對支持漢字、日文、法語等語言的呼聲越來越高時,Python于是準備引入unicode,但若直接把默認編碼改成unicode的話是不現實的, 因為很多軟件就是基于之前的默認編碼ASCII開發的,編碼一換,那些軟件的編碼就都亂了。所以Python 2 就直接 搞了一個新的字符類型,就叫unicode類型,比如你想讓你的中文在全球所有電腦上正常顯示,在內存里就得把字符串存成unicode類型
| 1 2 3 4 5 6 7 8 | >>> s?=?"路飛">>> s'\xe8\xb7\xaf\xe9\xa3\x9e'>>> s2?=?s.decode("utf-8")>>> s2u'\u8def\u98de'>>>?type(s2)<type?'unicode'> |
時間來到2008年,python發展已近20年,創始人龜叔越來越覺得python里的好多東西已發展的不像他的初衷那樣,開始變得臃腫、不簡潔、且有些設計讓人摸不到頭腦,比如unicode 與str類型,str 與bytes類型的關系,這給很多python程序員造成了困擾。
龜叔再也忍不了,像之前一樣的修修補補已不能讓Python變的更好,于是來了個大變革,Python3橫空出世,不兼容python2,python3比python2做了非常多的改進,其中一個就是終于把字符串變成了unicode,文件默認編碼變成了utf-8,這意味著,只要用python3,無論你的程序是以哪種編碼開發的,都可以在全球各國電腦上正常顯示,真是太棒啦!
PY3 除了把字符串的編碼改成了unicode, 還把str 和bytes 做了明確區分, str 就是unicode格式的字符, bytes就是單純二進制啦。
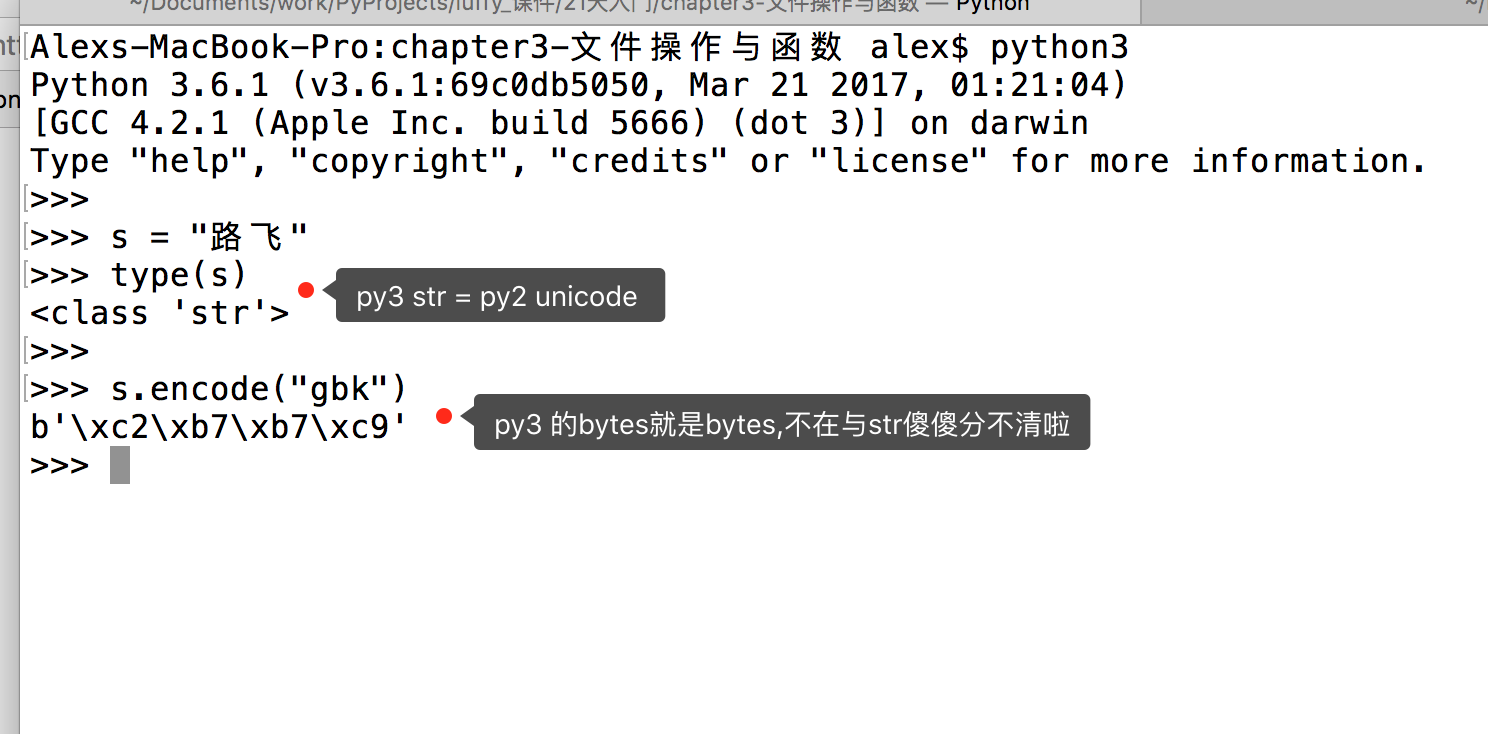
最后一個問題,為什么在py3里,把unicode編碼后,字符串就變成了bytes格式? 你直接給我直接打印成gbk的字符展示不好么?我想其實py3的設計真是煞費苦心,就是想通過這樣的方式明確的告訴你,想在py3里看字符,必須得是unicode編碼,其它編碼一律按bytes格式展示。?
?
好吧,就說這么多吧。?
?
?
最后再提示一下,Python只要出現各種編碼問題,無非是哪里的編碼設置出錯了
常見編碼錯誤的原因有:
- Python解釋器的默認編碼
- Python源文件文件編碼
- Terminal使用的編碼
- 操作系統的語言設置
掌握了編碼之前的關系后,挨個排錯就好啦
?更多詳見:http://www.cnblogs.com/alex3714/articles/7550940.html
http://www.cnblogs.com/skynet/archive/2011/05/03/2035105.html


)
)



)











