知識點都是搜集各種大佬們的,如有冒犯,請告知!
目錄
原型鏈
New關鍵字的執行過程?
?ES6——class
constructor方法
類的實例對象?
不存在變量提升
super 關鍵字
ES6——...(展開/收集)運算符
?面向對象的理解
關于this對象
箭頭函數
匿名函數?
?閉包
?內存泄露
JavaScript垃圾回收機制
引用計數算法
循環引用
解決方法:
標記清除算法
如何寫出對內存管理友好的JS代碼?
提升性能有關
移動開發
數組方法集合
js小技巧
類型強制轉換
?string 強制轉換為數字
?object強制轉化為string
使用 Boolean 過濾數組中的所有假值?
雙位運算符 ~~
取整?|0
?判斷奇偶數?&1
函數
強制參數
惰性載入函數
一次性函數
精確到指定位數的小數
數組
reduce 方法同時實現 map 和 filter
統計數組中相同項的個數
使用解構來交換參數數值
接收函數返回的多個結果
代碼復用
Object [key]
解讀HTTP/1、HTTP/2、HTTP/3之間的關系
HTTP 協議
HTTP之請求消息Request
HTTP之響應消息Response
HTTP之狀態碼
HTTP/1.x 的缺陷
HTTPS 應聲而出(安全版的http)
SPDY 協議
HTTP2.0 的前世今生
HTTP2.0 的新特性
HTTP2.0 的升級改造
HTTP/2 的缺點
HTTP/3簡介
3.QUIC新功能
七、總結
Session
Token
MVC、MVP和MVVM
MVC:Model+View+Controller
MVP?
MVVM(以VUE.JS來舉例)
# View 層
# Model 層
# ViewModel 層
VUE.JS
vue生命周期(鉤子函數)
computed中的getter和setter
v-for循環key的作用?
$nextTick
$set
組件間的傳值
為什么要是用sass這些css預處理器
優勢
如何防止XSS攻擊?
跨域
什么是同源策略及其限制內容
跨域解決方案
三、總結
web語義化
分為html語義化、css語義化和url語義化
nodeJS?
模塊加載機制
CommonJS
AMD規范與CommonJS規范的兼容性
AMD
原型鏈
(總結:每個實例對象( object )都有一個私有屬性(稱之為 __proto__ )指向它的構造函數的原型對象(prototype?)。該原型對象也有一個自己的原型對象( __proto__ ) ,層層向上直到一個對象的原型對象為?null。根據定義,null?沒有原型,并作為這個原型鏈中的最后一個環節。
而提到原型對象,就涉及到了兩個屬性:_proto_和prototype,前者是實例或者說是對象都會有的屬性,他指向了實例的構造函數上的prototype屬性,也就是:實例._proto_ = 構造函數.prototype,而這個prototype上就保存著需要實例間共享的屬性和方法。
為什么要這樣操作呢,因為js他沒有想java那樣有class類,而ES6上的class更多的是提供語法糖,所以js就利用函數來模擬類
當你創建一個函數(構造函數)的時候,js會自動為該函數添加prototype屬性,他不是一個空對象,他有個constructor屬性,指向了構造函數,而當你new一個實例的時候,該實例就會默認繼承構造函數上的prototype上的所有屬性和方法以達到繼承目的。)??????
- 每個JS對象一定對應一個原型對象,并從原型對象繼承屬性和方法
- 實例.__proto__ = 構造函數.prototype(只有函數才有prototype屬性。)
- 對象(實例)__proto__([[prototype]])屬性的值就是它的構造函數所對應的原型對象(prototype):
var one = {x: 1};
var two = new Object();
one.__proto__ === Object.prototype // true
two.__proto__ === Object.prototype // true
one.toString === one.__proto__.toString // true
JS不像其它面向對象的語言,它沒有類(
class,ES6引進了這個關鍵字,但更多是語法糖)的概念。JS通過函數來模擬類。- 當你創建函數時,JS會為這個函數自動添加
prototype屬性,值是空對象?值是一個有 constructor 屬性(是一個指向prototype屬性所在函數的指針)的對象,不是空對象。- 而一旦你把這個函數當作構造函數(
constructor)調用(即通過new關鍵字調用),那么JS就會幫你創建該構造函數的實例,實例繼承構造函數prototype的所有屬性和方法(實例通過設置自己的__proto__指向構造函數的prototype來實現這種繼承)。
- 構造函數,通過
prototype來存儲要共享的屬性和方法,也可以設置prototype指向現存的對象來繼承該對象。(Object.getPrototypeOf()可以方便的取得一個對象的原型對象)原型最初只包含constructor屬性,而該屬性也是共享的,因此可以通過對象實例訪問,如果原型被覆蓋,屬性查詢就會往之上一直查詢
補充:
·Person.prototype.constructor = person.__proto__.constructor
·Object.prototype(root)<---Function.prototype<---Function|Object|Array...選讀:
Object本身是構造函數,繼承了Function.prototype ;??
Function也是對象,繼承了Object.prototype。這里就有一個_雞和蛋_的問題:
Object instanceof Function // trueFunction instanceof Object // true
Function本身就是函數,Function.__proto__是標準的內置對象Function.prototype。
Function.prototype.__proto__是標準的內置對象Object.prototype。
- Function.prototype和Function.__proto__都指向Function.prototype,這就是雞和蛋的問題怎么出現的。
- Object.prototype.__proto__ === null,說明原型鏈到Object.prototype終止。
最后總結:先有Object.prototype(原型鏈頂端),Function.prototype繼承Object.prototype而產生,最后,Function和Object和其它構造函數繼承Function.prototype而產生。
參考:從__proto__和prototype來深入理解JS對象和原型鏈
New關鍵字的執行過程?
即通過new創建對象經歷4個步驟
- 創建一個新對象;[var o = {};]
- 鏈接該對象(即設置該對象的構造函數)到另一個對象?(構造函數的原型對象上);【更改實例(p)的_proto_指向構造函數(P)的prototype,這個步驟會弄丟構造函數原型對象上的constructor,改正構造函數(P)的在prototype上的constructor指向他自己(P)】
- 將新創建的對象作為this的上下文?,執行構造函數中的代碼(為這個新對象添加屬性);【[Person.apply(o)] [Person原來的this指向的是window]】
- 如果該函數沒有返回對象,則返回this(即使用步驟1創建的對象。)。
創建一個用戶自定義的對象需要兩步:
- 通過編寫函數來定義對象類型。
- 通過?new?來創建對象實例。
function Person(name, age, job) {this.name = name;this.age = age;this.job = job;this.sayName = function () {alert(this.name);};}let New = function (P) {let o = {};let arg = Array.prototype.slice.call(arguments,1);o.__proto__ = P.prototype;P.prototype.constructor = P; // 先將環境配置好_proto_、constructorP.apply(o,arg); // 將參數賦予給新對象return o;};let p1 = New(Person,"Ysir",24,"stu");let p2 = New(Person,"Sun",23,"stus");console.log(p1.name);//Ysirconsole.log(p2.name);//Sunconsole.log(p1.__proto__ === p2.__proto__);//trueconsole.log(p1.__proto__ === Person.prototype);//true
當代碼?new?Foo(...)?執行時,會發生以下事情:
- 一個繼承自?Foo
.prototype?的新對象被創建。- 使用指定的參數調用構造函數?
Foo,并將?this?綁定到新創建的對象(所以new關鍵字可以改變this的指向,將這個this指向實例對象)。new?Foo?等同于?new Foo(),也就是沒有指定參數列表,Foo?不帶任何參數調用的情況。- 由構造函數返回的對象就是?
new?表達式的結果。如果構造函數沒有顯式返回一個對象,則使用步驟1創建的對象。(一般情況下,構造函數不返回值,但是用戶可以選擇主動返回對象,來覆蓋正常的對象創建步驟)
?ES6——class
(總結:ES6的class類其實就是等同于ES5的構造函數,作用都是生成新對象,只不過class在結構形式上會和傳統的面向對象語言如c++,java這些更類似、切合。因為傳統構造方法在方法實現上與面向對象編程差別很大,為了讓對象原型的寫法更加清晰、更像面向對象編程,故引入class(類)這個概念,以作為對象的模板。 Class的內部固定搭配constructor方法,即構造方法,他默認返回實例對象,而直接在內部定義的方法會被綁定到構造函數的prototype對象上。而且不可直接調用class聲明的構造函數,會拋出錯誤,同樣地需要new一個實例里面的方法和屬性才能被調用)
- JavaScript語言的傳統方法是通過構造函數定義來生成新對象。但是構造函數跟傳統的面向對象語言(比如C++和Java)寫法上差異很大,很容易讓新學習這門語言的程序員感到困惑。
- ES6提供了更接近傳統語言的寫法,引入了Class(類)這個概念,作為對象的模板。通過
class關鍵字,可以定義類。基本上,ES6的class可以看作只是一個語法糖,它的絕大部分功能,ES5都可以做到,新的class寫法只是讓對象原型的寫法更加清晰、更像面向對象編程的語法而已。
function Point(x, y) { //構造函數this.x = x;this.y = y;
}Point.prototype.toString = function () {return '(' + this.x + ', ' + this.y + ')';
};var p = new Point(1, 2);
//定義類
class Point {
// ES5的構造函數Point,對應ES6的Point類的構造方法constructor(x, y) { //構造方法this.x = x; // this關鍵字則代表實例對象this.y = y;}toString() {return '(' + this.x + ', ' + this.y + ')';}
}
- ES6的類,完全可以看作構造函數的另一種寫法。
constructor方法是類的默認方法,通過new命令生成對象實例時,自動調用該方法。一個類必須有constructor方法,如果沒有顯式定義,一個空的constructor方法會被默認添加。
constructor方法
constructor 方法是類的構造函數,是一個默認方法,通過 new 命令創建對象實例時,自動調用該方法。一個類必須有 constructor 方法,如果沒有顯式定義,一個默認的 consructor 方法會被默認添加。所以即使你沒有添加構造函數,也是會有一個默認的構造函數的。一般 constructor 方法返回實例對象 this ,但是也可以指定 constructor 方法返回一個全新的對象,讓返回的實例對象不是該類的實例。
class Foo {constructor() {return Object.create(null);}
}new Foo() instanceof Foo
// false
類的構造函數,不使用new是沒法調用的,會報錯。這是它跟普通構造函數的一個主要區別,后者不用new也可以執行。
類的實例對象?
與ES5一樣,實例的屬性除非顯式定義在其本身(即定義在this對象上),否則都是定義在原型上(即定義在class上)。
//定義類
class Point {constructor(x, y) {this.x = x;this.y = y;}toString() {return '(' + this.x + ', ' + this.y + ')';}}var point = new Point(2, 3);point.toString() // (2, 3)point.hasOwnProperty('x') // true
point.hasOwnProperty('y') // true
point.hasOwnProperty('toString') // false
point.__proto__.hasOwnProperty('toString') // true
上面代碼中,x和y都是實例對象point自身的屬性(因為定義在this變量上),所以hasOwnProperty方法返回true,而toString是原型對象的屬性(因為定義在Point類上),所以hasOwnProperty方法返回false。這些都與ES5的行為保持一致。
不存在變量提升
Class不存在變量提升(hoist),這一點與ES5完全不同。
new Foo(); // ReferenceError
class Foo {}
super 關鍵字
super這個關鍵字,既可以當作函數使用,也可以當作對象使用。在這兩種情況下,它的用法完全不同。
第一種情況,super作為函數調用時,代表父類的構造函數。ES6 要求在?constructor?中必須調用?super?方法,因為子類沒有自己的 this 對象,而是繼承父類的 this 對象,然后對其進行加工,而 super 就代表了父類的構造函數。super 雖然代表了父類 A 的構造函數,但是返回的是子類 B 的實例,即 super 內部的 this 指的是 B,因此 super() 在這里相當于 ```A.prototype.constructor.call(this, props)``。
class A {}class B extends A {constructor() {super();}
}
上面代碼中,子類B的構造函數之中的super(),代表調用父類的構造函數。這是必須的,否則 JavaScript 引擎會報錯。
注意,super雖然代表了父類A的構造函數,但是返回的是子類B的實例,即super內部的this指的是B,因此super()在這里相當于A.prototype.constructor.call(this)。
class A {constructor() {console.log(new.target.name);}
}
class B extends A {constructor() {super();}
}
new A() // A
new B() // B
上面代碼中,new.target指向當前正在執行的函數。可以看到,在super()執行時,它指向的是子類B的構造函數,而不是父類A的構造函數。也就是說,super()內部的this指向的是B。
作為函數時,super()只能用在子類的構造函數之中,用在其他地方就會報錯。
參考:理解 es6 class 中 constructor 方法 和 super 的作用
(可忽略!)第二種情況,super作為對象時,指向父類的原型對象。這里需要注意,由于super指向父類的原型對象,所以定義在父類實例上的方法或屬性,是無法通過super調用的。如果屬性定義在父類的原型對象上,super就可以取到。
class A {constructor() {this.a = 'aa'}p() {return 2;}}class B extends A {constructor() {//super === class A//super作為函數調用時,代表父類的構造函數//super雖然代表了父類A的構造函數,但是返回的是子類B的實例,即super內部的this指的是B,//因此super()在這里相當于A.prototype.constructor.call(this)。super(); // super() === constructor A():A === B {a: "aa"}console.log(super.a,'super')//undefined 只有實例才會繼承那些this的自身屬性console.log(super.p()); // 2}}let b = new B();
console.log(b.a,'a')//aaconsole.log(b.p(),'p')//2
?參考:ES6 Class
ES6——...(展開/收集)運算符
簡而言之就是,...?運算符可以展開一個可迭代對象的所有項。
可迭代的對象一般是指可以被循環的,包括:string,?array,?set?等等。
基礎用法 1:?展開
const a = [2, 3, 4]
const b = [1, ...a, 5]
b; // [1, 2, 3, 4, 5]基礎用法 2:?收集
function foo(a, b, ...c) {console.log(a, b, c)
}foo(1, 2, 3, 4, 5); // 1, 2, [3, 4, 5]如果沒有命名參數的話,...?就會收集所有的參數:
function foo(...args) {console.log(args)
}foo(1, 2, 3, 4, 5); // [1, 2, 3, 4, 5]作為收集運算符時候,一定是在最后一個參數的位置,也很好理解,就是“收集前面剩下的參數”。
基礎用法 3: 把?類數組?轉換為?數組
const nodeList = document.getElementsByClassName("test");
const array = [...nodeList];console.log(nodeList); //Result: HTMLCollection [ div.test, div.test ]
console.log(array); //Result: Array [ div.test, div.test ]?基礎用法 5:?合并數組/對象
const baseSquirtle = {name: 'Squirtle',type: 'Water'
};const squirtleDetails = {species: 'Tiny Turtle Pokemon',evolution: 'Wartortle'
};const squirtle = { ...baseSquirtle, ...squirtleDetails };
console.log(squirtle);
//Result: { name: 'Squirtle', type: 'Water', species: 'Tiny Turtle Pokemon', evolution: 'Wartortle' }注意:當對像或者數組中有嵌套引用數據時,用...運算符進行賦值或者合并時屬于淺復制,原數據改了,用到他的地方也會跟著改。
- 淺克隆之所以被稱為淺克隆,是因為對象只會被克隆最外部的一層,至于更深層的對象,則依然是通過引用指向同一塊堆內存.
- 深復制:他會把引用類型指針所指的那塊內存地址復制出一塊新空間,也就是新對象和舊對象所指的內存空間是不一樣的,也就不存在原數據改了,復制對象也會跟著被修改
深復制的方法有:
JSON對象parse方法可以將JSON字符串反序列化成JS對象,stringify方法可以將JS對象序列化成JSON字符串,這兩個方法結合起來就能產生一個便捷的深克隆.
const newObj = JSON.parse(JSON.stringify(oldObj));確實,這個方法雖然可以解決絕大部分是使用場景,但是卻有很多坑.
- 他無法實現對函數 、RegExp等特殊對象的克隆
- 會拋棄對象的constructor,所有的構造函數會指向Object
- 對象有循環引用,會報錯
?詳細請看:面試官:請你實現一個深克隆
補充:
Object.create(proto[, propertiesObject])
===等同于下面
function object(o){function F(){}F.propotype = o return new F()
}
參數
proto——新創建對象的原型對象。
propertiesObject——可選。如果沒有指定為?undefined,則是要添加到新創建對象的可枚舉屬性(即其自身定義的屬性,而不是其原型鏈上的枚舉屬性)對象的屬性描述符以及相應的屬性名稱。這些屬性對應Object.defineProperties()的第二個參數。
返回值
一個新對象,帶著指定的原型對象和屬性。
也就是說,Object.create()方法創建一個新對象,使用現有的對象來提供新創建的對象的__proto__。?
參考:深入了解 ES6 強大的 ... 運算符
?ES6——promise
含義
Promise 是異步編程的一種解決方案,比傳統的解決方案——回調函數和事件——更合理和更強大。它由社區最早提出和實現,ES6 將其寫進了語言標準,統一了用法,原生提供了Promise對象。
所謂Promise,簡單說就是一個容器,里面保存著某個未來才會結束的事件(通常是一個異步操作)的結果。從語法上說,Promise 是一個對象,從它可以獲取異步操作的消息。Promise 提供統一的 API,各種異步操作都可以用同樣的方法進行處理。
有了Promise對象,就可以將異步操作以同步操作的流程表達出來,避免了層層嵌套的回調函數。此外,Promise對象提供統一的接口,使得控制異步操作更加容易。
Promise也有一些缺點。首先,無法取消Promise,一旦新建它就會立即執行,無法中途取消。其次,如果不設置回調函數,Promise內部拋出的錯誤,不會反應到外部。第三,當處于pending狀態時,無法得知目前進展到哪一個階段(剛剛開始還是即將完成)。
如果某些事件不斷地反復發生,一般來說,使用?Stream?模式是比部署Promise更好的選擇。
基本用法
ES6 規定,Promise對象是一個構造函數,用來生成Promise實例。
下面代碼創造了一個Promise實例。
const promise = new Promise(function(resolve, reject) {// ... some codeif (/* 異步操作成功 */){resolve(value);} else {reject(error);}
});
Promise構造函數接受一個函數作為參數,該函數的兩個參數分別是resolve和reject。它們是兩個函數,由 JavaScript 引擎提供,不用自己部署。
romise實例生成以后,可以用then方法分別指定resolved狀態和rejected狀態的回調函數。
promise.then(function(value) {// success
}, function(error) {// failure
});Promise 新建后就會立即執行。
let promise = new Promise(function(resolve, reject) {console.log('Promise');resolve();
});promise.then(function() {console.log('resolved.');
});console.log('Hi!');// Promise
// Hi!
// resolved
上面代碼中,Promise 新建后立即執行,所以首先輸出的是Promise。然后,then方法指定的回調函數,將在當前腳本所有同步任務執行完才會執行,所以resolved最后輸出。
下面是一個用Promise對象實現的 Ajax 操作的例子。
const getJSON = function(url) {const promise = new Promise(function(resolve, reject){const handler = function() {if (this.readyState !== 4) {return;}if (this.status === 200) {resolve(this.response);} else {reject(new Error(this.statusText));}};const client = new XMLHttpRequest();client.open("GET", url);client.onreadystatechange = handler;client.responseType = "json";client.setRequestHeader("Accept", "application/json");client.send();});return promise;
};getJSON("/posts.json").then(function(json) {console.log('Contents: ' + json);
}, function(error) {console.error('出錯了', error);
});resolve函數的參數除了正常的值以外,還可能是另一個 Promise 實例,比如像下面這樣。
const p1 = new Promise(function (resolve, reject) {// ...
});const p2 = new Promise(function (resolve, reject) {// ...resolve(p1);
})
上面代碼中,p1和p2都是 Promise 的實例,但是p2的resolve方法將p1作為參數,即一個異步操作的結果是返回另一個異步操作。
注意,這時p1的狀態就會傳遞給p2,也就是說,p1的狀態決定了p2的狀態。如果p1的狀態是pending,那么p2的回調函數就會等待p1的狀態改變;如果p1的狀態已經是resolved或者rejected,那么p2的回調函數將會立刻執行。
const p1 = new Promise(function (resolve, reject) {setTimeout(() => reject(new Error('fail')), 3000)
})const p2 = new Promise(function (resolve, reject) {setTimeout(() => resolve(p1), 1000)
})p2.then(result => console.log(result)).catch(error => console.log(error))
// Error: fail
上面代碼中,p1是一個 Promise,3 秒之后變為rejected。p2的狀態在 1 秒之后改變,resolve方法返回的是p1。由于p2返回的是另一個 Promise,導致p2自己的狀態無效了,由p1的狀態決定p2的狀態。所以,后面的then語句都變成針對后者(p1)。又過了 2 秒,p1變為rejected,導致觸發catch方法指定的回調函數。
注意,調用resolve或reject并不會終結 Promise 的參數函數的執行。
new Promise((resolve, reject) => {resolve(1);console.log(2);
}).then(r => {console.log(r);
});
// 2
// 1
上面代碼中,調用resolve(1)以后,后面的console.log(2)還是會執行,并且會首先打印出來。這是因為立即 resolved 的 Promise 是在本輪事件循環的末尾執行,總是晚于本輪循環的同步任務。
一般來說,調用resolve或reject以后,Promise 的使命就完成了,后繼操作應該放到then方法里面,而不應該直接寫在resolve或reject的后面。所以,最好在它們前面加上return語句,這樣就不會有意外。
new Promise((resolve, reject) => {return resolve(1);// 后面的語句不會執行console.log(2);
})Promise.prototype.then()
Promise 實例具有then方法,也就是說,then方法是定義在原型對象Promise.prototype上的。它的作用是為 Promise 實例添加狀態改變時的回調函數。前面說過,then方法的第一個參數是resolved狀態的回調函數,第二個參數(可選)是rejected狀態的回調函數。
then方法返回的是一個新的Promise實例(注意,不是原來那個Promise實例)。因此可以采用鏈式寫法,即then方法后面再調用另一個then方法。
采用鏈式的then,可以指定一組按照次序調用的回調函數。這時,前一個回調函數,有可能返回的還是一個Promise對象(即有異步操作),這時后一個回調函數,就會等待該Promise對象的狀態發生變化,才會被調用。
getJSON("/post/1.json").then(function(post) {return getJSON(post.commentURL);
}).then(function (comments) {console.log("resolved: ", comments);
}, function (err){console.log("rejected: ", err);
});
上面代碼中,第一個then方法指定的回調函數,返回的是另一個Promise對象。這時,第二個then方法指定的回調函數,就會等待這個新的Promise對象狀態發生變化。如果變為resolved,就調用第一個回調函數,如果狀態變為rejected,就調用第二個回調函數。
如果采用箭頭函數,上面的代碼可以寫得更簡潔。
getJSON("/post/1.json").then(post => getJSON(post.commentURL)
).then(comments => console.log("resolved: ", comments),err => console.log("rejected: ", err)
);Promise.prototype.catch()
Promise.prototype.catch()方法是.then(null, rejection)或.then(undefined, rejection)的別名,用于指定發生錯誤時的回調函數。
如果異步操作拋出錯誤,狀態就會變為rejected,就會調用catch()方法指定的回調函數,處理這個錯誤。另外,then()方法指定的回調函數,如果運行中拋出錯誤,也會被catch()方法捕獲
如果 Promise 狀態已經變成resolved,再拋出錯誤是無效的。所以一般都是直接return (resolve或者是reject回調函數)
const promise = new Promise(function(resolve, reject) {resolve('ok');throw new Error('test');
});
promise.then(function(value) { console.log(value) }).catch(function(error) { console.log(error) });
// okPromise 對象的錯誤具有“冒泡”性質,會一直向后傳遞,直到被捕獲為止。也就是說,錯誤總是會被下一個catch語句捕獲。
getJSON('/post/1.json').then(function(post) {return getJSON(post.commentURL);
}).then(function(comments) {// some code
}).catch(function(error) {// 處理前面三個Promise產生的錯誤
});一般來說,不要在then()方法里面定義 Reject 狀態的回調函數(即then的第二個參數),總是使用catch方法。
跟傳統的try/catch代碼塊不同的是,如果沒有使用catch()方法指定錯誤處理的回調函數,Promise 對象拋出的錯誤不會傳遞到外層代碼,即不會有任何反應。(即錯誤會拋出,但是不影響運行,之后的代碼照常運行)
const someAsyncThing = function() {return new Promise(function(resolve, reject) {// 下面一行會報錯,因為x沒有聲明resolve(x + 2);});
};someAsyncThing().then(function() {console.log('everything is great');
});setTimeout(() => { console.log(123) }, 2000);
// Uncaught (in promise) ReferenceError: x is not defined
// 123?上面代碼中,someAsyncThing()函數產生的 Promise 對象,內部有語法錯誤。瀏覽器運行到這一行,會打印出錯誤提示ReferenceError: x is not defined,但是不會退出進程、終止腳本執行,2 秒之后還是會輸出123。這就是說,Promise 內部的錯誤不會影響到 Promise 外部的代碼,通俗的說法就是“Promise 會吃掉錯誤”。
一般總是建議,Promise 對象后面要跟catch()方法,這樣可以處理 Promise 內部發生的錯誤。catch()方法返回的還是一個 Promise 對象,因此后面還可以接著調用then()方法。
const someAsyncThing = function() {return new Promise(function(resolve, reject) {// 下面一行會報錯,因為x沒有聲明resolve(x + 2);});
};someAsyncThing()
.catch(function(error) {console.log('oh no', error);
})
.then(function() {console.log('carry on');
});
// oh no [ReferenceError: x is not defined]
// carry on
上面代碼運行完catch()方法指定的回調函數,會接著運行后面那個then()方法指定的回調函數。如果沒有報錯,則會跳過catch()方法。
Promise.prototype.finally()
finally()方法用于指定不管 Promise 對象最后狀態如何,都會執行的操作。該方法是 ES2018 引入標準的。
promise
.then(result => {···})
.catch(error => {···})
.finally(() => {···});finally方法的回調函數不接受任何參數,這意味著沒有辦法知道,前面的 Promise 狀態到底是fulfilled還是rejected。這表明,finally方法里面的操作,應該是與狀態無關的,不依賴于 Promise 的執行結果。
它的實現也很簡單。
Promise.prototype.finally = function (callback) {let P = this.constructor;return this.then(value => P.resolve(callback()).then(() => value),reason => P.resolve(callback()).then(() => { throw reason }));
};Promise.all()
Promise.all()方法用于將多個 Promise 實例,包裝成一個新的 Promise 實例。
const p = Promise.all([p1, p2, p3]);
上面代碼中,Promise.all()方法接受一個數組作為參數,p1、p2、p3都是 Promise 實例,如果不是,就會先調用下面講到的Promise.resolve方法,將參數轉為 Promise 實例,再進一步處理。另外,Promise.all()方法的參數可以不是數組,但必須具有 Iterator 接口,且返回的每個成員都是 Promise 實例。
p的狀態由p1、p2、p3決定,分成兩種情況。
(1)只有p1、p2、p3的狀態都變成fulfilled,p的狀態才會變成fulfilled,此時p1、p2、p3的返回值組成一個數組,傳遞給p的回調函數。
(2)只要p1、p2、p3之中有一個被rejected,p的狀態就變成rejected,此時第一個被reject的實例的返回值,會傳遞給p的回調函數。
Promise.race()
Promise.race()方法同樣是將多個 Promise 實例,包裝成一個新的 Promise 實例。
const p = Promise.race([p1, p2, p3]);
上面代碼中,只要p1、p2、p3之中有一個實例率先改變狀態,p的狀態就跟著改變。那個率先改變的 Promise 實例的返回值,就傳遞給p的回調函數。
Promise.race()方法的參數與Promise.all()方法一樣,如果不是 Promise 實例,就會先調用下面講到的Promise.resolve()方法,將參數轉為 Promise 實例,再進一步處理。
!!!!下面是一個例子,如果指定時間內沒有獲得結果,就將 Promise 的狀態變為reject,否則變為resolve。
const p = Promise.race([fetch('/resource-that-may-take-a-while'),new Promise(function (resolve, reject) {setTimeout(() => reject(new Error('request timeout')), 5000)})
]);p
.then(console.log)
.catch(console.error);
上面代碼中,如果 5 秒之內fetch方法無法返回結果,變量p的狀態就會變為rejected,從而觸發catch方法指定的回調函數。
Promise.resolve()
有時需要將現有對象轉為 Promise 對象,Promise.resolve()方法就起到這個作用。
Promise.resolve()等價于下面的寫法。
Promise.resolve('foo')
// 等價于
new Promise(resolve => resolve('foo'))Promise.resolve方法的參數分成四種情況。
(1)參數是一個 Promise 實例
如果參數是 Promise 實例,那么Promise.resolve將不做任何修改、原封不動地返回這個實例。
(2)參數是一個thenable對象
thenable對象指的是具有then方法的對象,比如下面這個對象。
let thenable = {then: function(resolve, reject) {resolve(42);}
};
Promise.resolve方法會將這個對象轉為 Promise 對象,然后就立即執行thenable對象的then方法。
let thenable = {then: function(resolve, reject) {resolve(42);}
};let p1 = Promise.resolve(thenable);
p1.then(function(value) {console.log(value); // 42
});
上面代碼中,thenable對象的then方法執行后,對象p1的狀態就變為resolved,從而立即執行最后那個then方法指定的回調函數,輸出 42。
(3)參數不是具有then方法的對象,或根本就不是對象
如果參數是一個原始值,或者是一個不具有then方法的對象,則Promise.resolve方法返回一個新的 Promise 對象,狀態為resolved。
const p = Promise.resolve('Hello');p.then(function (s){console.log(s)
});
// Hello
上面代碼生成一個新的 Promise 對象的實例p。由于字符串Hello不屬于異步操作(判斷方法是字符串對象不具有 then 方法),返回 Promise 實例的狀態從一生成就是resolved,所以回調函數會立即執行。Promise.resolve方法的參數,會同時傳給回調函數。
(4)不帶有任何參數
Promise.resolve()方法允許調用時不帶參數,直接返回一個resolved狀態的 Promise 對象。
所以,如果希望得到一個 Promise 對象,比較方便的方法就是直接調用Promise.resolve()方法。
const p = Promise.resolve();p.then(function () {// ...
});
上面代碼的變量p就是一個 Promise 對象。
需要注意的是,立即resolve()的 Promise 對象,是在本輪“事件循環”(event loop)的結束時執行,而不是在下一輪“事件循環”的開始時。
setTimeout(function () {console.log('three');
}, 0);Promise.resolve().then(function () {console.log('two');
});console.log('one');// one
// two
// three
上面代碼中,setTimeout(fn, 0)在下一輪“事件循環”開始時執行,Promise.resolve()在本輪“事件循環”結束時執行,console.log('one')則是立即執行,因此最先輸出。
Promise.try()
由于Promise.try為所有操作提供了統一的處理機制,所以如果想用then方法管理流程,最好都用Promise.try包裝一下。這樣有許多好處,其中一點就是可以更好地管理異常。
function getUsername(userId) {return database.users.get({id: userId}).then(function(user) {return user.name;});
}
上面代碼中,database.users.get()返回一個 Promise 對象,如果拋出異步錯誤,可以用catch方法捕獲,就像下面這樣寫。
database.users.get({id: userId})
.then(...)
.catch(...)
但是database.users.get()可能還會拋出同步錯誤(比如數據庫連接錯誤,具體要看實現方法),這時你就不得不用try...catch去捕獲。
try {database.users.get({id: userId}).then(...).catch(...)
} catch (e) {// ...
}
上面這樣的寫法就很笨拙了,這時就可以統一用promise.catch()捕獲所有同步和異步的錯誤。
Promise.try(() => database.users.get({id: userId})).then(...).catch(...)
事實上,Promise.try就是模擬try代碼塊,就像promise.catch模擬的是catch代碼塊。
參考:https://es6.ruanyifeng.com/#docs/promise#Promise-%E7%9A%84%E5%90%AB%E4%B9%89
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
js報錯類型
SyntaxError
SyntaxError?對象代表解析到語法上不合法的代碼的錯誤
// SyntaxError: 語法錯誤
// 1) 變量名不符合規范
var 1 // Uncaught SyntaxError: Unexpected number
var 1a // Uncaught SyntaxError: Invalid or unexpected token
// 2) 給關鍵字賦值
function = 5 // Uncaught SyntaxError: Unexpected token =
// 3) 錯誤寫法
var a = ReferenceError
ReferenceError(引用錯誤)?對象代表當一個不存在的變量被引用時發生的錯誤。(這玩意兒不存在)
// ReferenceError:引用錯誤(要用的變量沒找到)
// 1) 引用了不存在的變量
a() // Uncaught ReferenceError: a is not defined
console.log(b) // Uncaught ReferenceError: b is not defined
// 2) 給一個無法被賦值的對象賦值
console.log("abc") = 1 // Uncaught ReferenceError: Invalid left-hand side in assignment
TypeError
TypeError(類型錯誤)?對象用來表示值的類型非預期類型時發生的錯誤。(瞎幾把調用)
// TypeError: 類型錯誤(調用不存在的方法)
// 變量或參數不是預期類型時發生的錯誤。比如使用new字符串、布爾值等原始類型和調用對象不存在的方法就會拋出這種錯誤,因為new命令的參數應該是一個構造函數。
// 1) 調用不存在的方法
123() // Uncaught TypeError: 123 is not a function
var o = {}
o.run() // Uncaught TypeError: o.run is not a function
// 2) new關鍵字后接基本類型
var p = new 456 // Uncaught TypeError: 456 is not a constructor
RangeError
RangeError對象標明一個錯誤,當一個值不在其所允許的范圍或者集合中。
// RangeError: 范圍錯誤(參數超范圍)
// 主要的有幾種情況,第一是數組長度為負數,第二是Number對象的方法參數超出范圍,以及函數堆棧超過最大值。
// 1) 數組長度為負數
[].length = -5 // Uncaught RangeError: Invalid array length
// 2) Number對象的方法參數超出范圍
var num = new Number(12.34)
console.log(num.toFixed(-1)) // Uncaught RangeError: toFixed() digits argument must be between 0 and 20 at Number.toFixed
// 說明: toFixed方法的作用是將數字四舍五入為指定小數位數的數字,參數是小數點后的位數,范圍為0-20.
EvalError
與eval()相關的錯誤。此異常不再會被JavaScript拋出,但是EvalError對象仍然保持兼容性.
// EvalError: 非法調用 eval()
// 在ES5以下的JavaScript中,當eval()函數沒有被正確執行時,會拋出evalError錯誤。例如下面的情況:
var myEval = eval;
myEval("alert('call eval')");
// 需要注意的是:ES5以上的JavaScript中已經不再拋出該錯誤,但依然可以通過new關鍵字來自定義該類型的錯誤提示。以上的幾種派生錯誤,連同原始的Error對象,都是構造函數。開發者可以使用它們,認為生成錯誤對象的實例。
new Error([message[fileName[lineNumber]]])
// 第一個參數表示錯誤提示信息,第二個是文件名,第三個是行號。
URIError
給 encodeURI或 decodeURl()傳遞的參數無效
// URIError: URI不合法
// 主要是相關函數的參數不正確。
decodeURI("%") // Uncaught URIError: URI malformed at decodeURI
// jzz
面向對象的理解
(總結:面向對象的三大特征就是封裝、繼承和多態。所謂封裝是說你把你需要創建的某一類型對象的特征(屬性和方法)抽象出來封裝成到一個超類中并暴露接口。而繼承就是說與某一超類為模板創造出子類,子類會具有超類的特征,繼承超類的方法和屬性,多態就是子類不僅有超類的屬性和方法,也會有自己特有的屬性和方法,擴展子類的實現。比如說women類和men類,因為他們都是可以屬于people類的,你可以先把people都有的特征抽象成類,women類和門類就可以繼承people類,節約代碼量并提高代碼的復用性,然而就算都屬于women類,每個實例,也就是具體到個人,他們也都會有自己特有的特性,有的人敲代碼特厲害,有的人唱歌特厲害,所以每個對象都可以有自己的可擴展屬性和方法以實現多態性,也就是每個人一樣(整體)又都不一樣(局部),大同小異.)
假設我是女媧,我準備捏一些人,
首先,人應該有哪些基本特征:
- 1.有四肢 2.有大腦 3.有器官 4.有思想 我們就有了第一個模型,這就是抽象。
- 其次,我和西方上帝是好友,我想我的這個想法能夠提供給他用,但是我不想讓他知道里面細節是怎么捏出來的,用的什么材料,他也不用考慮那么多,只要告訴我他要捏什么樣的人就可以了。這就是封裝。
- 然后,我之后創造的人都以剛才的模型做為模板,我創造的人都有我模型的特征 這就是繼承。
- 最后,我覺得為了讓人更豐富多彩,暗合陰陽之原理,可以根據模型進行刪減,某些人上半身器官多突起那么一丟丟,下面少那么一丟丟。某些人,下半身多突起那么一丟丟。這就是多態。
面向對象的三大特征就是封裝,繼承,多態。
- 封裝:就是把一個對象的特征,封裝到一個類中,并暴露接口。
- 繼承:為了代碼的復用性,主要是讓你不用重復造輪子了。
- 多態:就是繼承的一個類,感覺類的特征不全面,可以擴展一些類的實現,實現特有的屬性和方法。
“人”是類。
“人”有姓名、出生日期、身份證號等屬性。
“人”有約會、么么噠、啪啪啪等功能(方法)。
“男人”、“女人”是“人”的子類。繼承“人”的屬性和功能。但也有自己特有的屬性和功能。
你、我是對象。
關于this對象
(總結:this對象是在運行時基于函數的執行環境綁定的,this如果是在全局環境中通常指代的是全局對象,而如果是在函數中,this通常指最后調用this所在函數的那個對象。如果函數中有多個內嵌對象且每一層都有this,那么被調用的函數所指向的this只會是上一級的this對象,而不會像原型鏈一樣層層尋找this值。而且可以使用Function.prototype.call或者apply方法綁定一個對象而達到改變this指向問題;還有一點需要提起:在箭頭函數中this永遠指向封閉詞法環境的this,所謂封閉詞法環境通常就是指函數,函數擁有自己的作用域,在內部定義的變量外環境是無法訪問得到的;而js沒有塊級作用域,所以對象或者想if語句他們都沒有自己的作用域,因此呢,用apply或者call都無法修改this指向,參數通常是對象,無法封住箭頭函數的this,沒有塊級作用域)
- 無論是否在嚴格模式下,在全局執行環境中(在任何函數體外部)
this?都指向全局對象。- 在函數內部,
this的值取決于函數被調用的方式。- this的指向在函數定義的時候是確定不了的,只有函數執行的時候才能確定this到底指向誰,實際上this的最終指向的是那個調用它的對象(this永遠指向的是最后調用它的對象,也就是看它執行的時候是誰調用的)
var j = o.b.fn;j();//不行
?如果函數中包含多個對象,盡管這個函數是被最外層的對象所調用,this指向的也只是它上一級的對象
var a = '33'var o = {a: 10,b: {// a:12,fn: function () {console.log(this.a); //undefined}} }o.b.fn();
當一個函數在其主體中使用?this?關鍵字時,可以通過使用函數繼承自Function.prototype?的?call?或?apply?方法將?this?值綁定到調用中的特定對象。
箭頭函數
在箭頭函數中,this與封閉詞法環境的this保持一致。他不會創建自己的this和arguments。
在全局代碼中,它將被設置為全局對象:
var globalObject = this;var foo = (() => this);console.log(foo() === globalObject); // true
注意:如果將this傳遞給call、bind、或者apply,它將被忽略。不過你仍然可以為調用添加參數,不過第一個參數(thisArg)應該設置為null。
所謂封閉詞法環境是指函數在JavaScript中被解析為一個閉包,從而創建了一個作用域,使其在一個函數內定義的變量不能從函數外訪問或從其他函數內訪問。(js函數沒有塊級作用域)
var fullname = "aaa";
var obj = {fullname: "bbb",getFullName: () => this.fullname,prop: {fullname: "ccc",getFullName: function() {return this.fullname;}}};console.log(obj.prop.getFullName());//ccc,止在上一層作用域console.log(obj.getFullName());//aaavar func1 = obj.prop.getFullName;console.log(func1());//aaavar func2 = obj.getFullName;console.log(func2());//aaa
?只有函數才能創建作用域, 不管是字面量還是 new 出來的對象(塊級作用域)都是無法創建作用域的
匿名函數?
(總結:匿名函數就是沒有函數名、在運行時動態聲明且是通過函數表達式而不是函數聲明法定義的函數。匿名函數作用之一就是他比普通函數更節省內存空間,因為普通函數在定義時就會創建函數對象和作用域對象,即使沒有調用也在占用著空間;而匿名函數僅在調用時候才會臨時創建函數對象和作用域鏈對象;調用完,立即釋放。而且匿名函數還可以構建命名空間和私有作用域,可以減少全局變量的污染,減低網頁的內存壓力和提高安全性;匿名函數如果在外層包圍一個括號可以變成一個函數表達式,直接后面在跟個括號就直接可以調用了)
匿名函數:就是沒有函數名的函數
匿名函數的執行環境具有全局性,因此其this對象通常指向window
var name = "The Window";var object = {name : "My Object",getNameFunc : function(){return function(){return this.name;};}
};alert(object.getNameFunc()()); //"The Window"(在非嚴格模式下)以上代碼先創建了一個全局變量name,又創建了一個包含name屬性的對象。這個對象還包含一個方法——getNameFunc(),它返回一個匿名函數,而匿名函數又返回this.name。由于getNameFunc()返回一個函數,因此調用object.getNameFunc()()就會立即調用它返回的函數,結果就是返回一個字符串。然而,這個例子返回的字符串是"The Window",即全局name變量的值。為什么匿名函數沒有取得其包含作用域(或外部作用域)的this對象呢?
因為每個函數在被調用時都會自動取得兩個特殊變量:this和arguments。內部函數在搜索這兩個變量時,只會搜索到其活動對象為止,因此永遠不可能直接訪問外部函數中的這兩個變量;不過,把外部作用域中的this對象保存在一個閉包能夠訪問到的變量里,就可以讓閉包訪問該對象了,如下所示。
var name = "The Window";var object = {name : "My Object",getNameFunc : function(){var that = this;return function(){return that.name;};}
};alert(object.getNameFunc()()); //"My Object"?
?
匿名函數最大的用途是創建閉包(這是JavaScript語言的特性之一),并且還可以構建命名空間、創建私有作用域,以減少全局變量的使用。
var oEvent = {};
(function(){ var addEvent = function(){ /*代碼的實現省略了*/ };function removeEvent(){}oEvent.addEvent = addEvent;oEvent.removeEvent = removeEvent;
})();
?在這段代碼中函數addEvent和removeEvent都是局部變量,但我們可以通過全局變量oEvent使用它,這就大大減少了全局變量的使用,減少了網頁的內存壓力,增強了網頁的安全性。
var rainman = (function(x , y){return x + y;
})(2 , 3);加上()表示函數表達式
/*** 也可以寫成下面的形式,因為第一個括號只是幫助我們閱讀,但是不推薦使用下面這種書寫格式。* var rainman = function(x , y){* return x + y;* }(2 , 3);//先初始化*/
?在這里我們創建了一個變量rainman,并通過直接調用匿名函數初始化為5,這種小技巧有時十分實用。
function(){console.log(1);
}
// 報錯
- ?因為ECAMScript規定函數的聲明必須要有名字,如果沒有名字的話,我們就沒有辦法找到它了,對于為什么自執行函數為什么就可以不帶名字后面會講。
- 如果沒有名字必須要有一個依附體,如:將這個匿名函數賦值給一個變量。
如果按照上面的說法js報錯也是應該的,那么我們用的下面這種代碼為什么就能夠正常運行?
(function(){console.log(1);
})() //1
之所以可以是因為我們將這個函數包含在了一個小括號中,why?小括號為什么這么神奇?
按照ECAMScript的規定,函數聲明是必須要有名字的,但是我們用括號擴起來那么這個函數就不再是一個函數聲明了,而是一個函數表達式,你可以理解成下面這段代碼。
var a = function(){console.log(1);
}(); //1
將一個匿名函數賦值給一個變量或者對象屬性就是函數表達式,函數表達式是可以不需要名字的,所以我們就可以直接通過這種方式來自動的執行這個函數。
再說一句
(function(){....
})()
?第一個括號是個運算符,它會返回這個匿名函數,然后最后一個小括號會執行這個函數。
隨便出一題:
var a = {n : 1};
var b = a;
a.x = a = {n : 2};
console.log(a.x);
console.log(b.x);解答過程:
var a = {n : 1};
var b = a;
// 此時b = {n:1};a.x = a = {n : 2};
// 從右往左賦值,a = {n:2}; 新對象
// b = {n:2}// a.x 中的a是{n:1}; {n:1}.x = {n:2}; 舊對象
// 因為b和a是引用的關系所以b.x也等于 {n:2}console.log(a.x); undefined
// 此時的a是新對象,新對象上沒有a.x 所以是undefinedconsole.log(b.x); {n:2}
?閉包
閉包的含義:閉包說白了就是函數的嵌套,內層的函數可以使用外層函數的所有變量,即使外層函數已經執行完畢(這點涉及JavaScript作用域鏈)。?所以,在本質上,閉包就是將函數內部和函數外部連接起來的一座橋梁。
閉包可以用在許多地方。它的最大用處有兩個,一個是,另一個就是
1、【封裝變量】—— 閉包可以幫助把一些不需要暴露在全局的變量封裝成“私有變量”。減少全局污染
2、【延續局部變量的壽命】——讓局部變量的值始終保持在內存中。由于函數外部可以讀取或者改動函數內部的變量,只需一次初始化變量。該變量可以長時間地保存函數調用時產生的改變。
參考:https://www.cnblogs.com/shiyou00/p/10598010.html
var outer = null;(function(){var one = 1;function inner (){one += 1;alert(one);}outer = inner;
})();outer(); //2
outer(); //3
outer(); //4
?使得外部可以訪問函數的局部變量。因為內層的函數可以使用外層函數的所有變量,將這個內層函數賦值給一個外部變量便可以在外部訪問。而且函數one變量一直儲存在內存中,并沒有因為函數被調用后而被清除。這段代碼中的變量one是一個局部變量(因為它被定義在一個函數之內),因此外部是不可以訪問的。但是這里我們創建了inner函數,inner函數是可以訪問變量one的;又將全局變量outer引用了inner,所以三次調用outer會彈出遞增的結果。
注意:閉包允許內層函數引用父函數中的變量,但是該變量是最終值,可以用匿名函數傳參來解決,因為js沒有塊級作用域,但函數都擁有自己的作用域,且ECMAScript中所有函數的參數都是按值來傳遞的,所以當變量是原始數據類型值得時候,通過參數傳進去的變量都是獨立的個體,在棧中擁有自己的空間,所以彼此互不干擾。他傳進去的確實是個值,而不是變量名了?
?內存泄露
不再用到的內存,沒有及時釋放,就叫做內存泄漏(memory leak)。
JavaScript垃圾回收機制
JavaScript不需要手動地釋放內存,它使用一種自動垃圾回收機制(garbage collection)。當一個對象無用的時候,即程序中無變量引用這個對象時,就會從內存中釋放掉這個變量。
垃圾回收機制怎么知道,哪些內存不再需要呢?
引用計數算法
最常使用的方法叫做"引用計數"(reference counting):語言引擎有一張"引用表",保存了內存里面所有的資源(通常是各種值)的引用次數。如果一個值的引用次數是0,就表示這個值不再用到了,因此可以將這塊內存釋放。
如果一個值不再需要了,引用數卻不為0,垃圾回收機制無法釋放這塊內存,從而導致內存泄漏。
const arr = [1, 2, 3, 4];
console.log('hello world');
?上面代碼中,數組[1, 2, 3, 4]是一個值,會占用內存。變量arr是僅有的對這個值的引用,因此引用次數為1。盡管后面的代碼沒有用到arr,它還是會持續占用內存。
如果增加一行代碼,解除arr對[1, 2, 3, 4]引用,這塊內存就可以被垃圾回收機制釋放了。
let arr = [1, 2, 3, 4];
console.log('hello world');
arr = null;
?上面代碼中,arr重置為null,就解除了對[1, 2, 3, 4]的引用,引用次數變成了0,內存就可以釋放出來了。
因此,并不是說有了垃圾回收機制,程序員就輕松了。你還是需要關注內存占用:那些很占空間的值,一旦不再用到,你必須檢查是否還存在對它們的引用。如果是的話,就必須手動解除引用。
循環引用
引用計數算法是個簡單有效的算法。但它卻存在一個致命的問題:循環引用。如果兩個對象相互引用,盡管他們已不再使用,垃圾回收器不會進行回收,導致內存泄露。
var a={"name":"zzz"};var b={"name":"vvv"};a.child=b;b.parent=a;
因為有這個嚴重的缺點,這個算法在現代瀏覽器中已經被下面要介紹的標記清除算法所取代了。但絕不可認為該問題已經不再存在了,因為還占有大量市場的IE老祖宗們使用的正是這一算法。在需要照顧兼容性的時候,某些看起來非常普通的寫法也可能造成意想不到的問題:
var div = document.createElement("div");
div.onclick = function() {console.log("click");
};
?上面這種JS寫法再普通不過了,創建一個DOM元素并綁定一個點擊事件。那么這里有什么問題呢?請注意,變量div有事件處理函數的引用,同時事件處理函數也有div的引用!(div變量可在函數內被訪問)。一個循序引用出現了,按上面所講的算法,該部分內存無可避免地泄露哦了。 現在你明白為啥前端程序員都討厭IE了吧?擁有超多BUG并依然占有大量市場的IE是前端開發一生之敵!親,沒有買賣就沒有殺害。
function outer(){var obj = {};function inner(){ //這里引用了obj對象}obj.inner = inner;
}
?這是一種及其隱蔽的循環引用,。當調用一次outer時,就會在其內部創建obj和inner兩個對象,obj的inner屬性引用了inner;同樣inner也引用了obj,這是因為obj仍然在innerFun的封閉環境中,準確的講這是由于JavaScript特有的“作用域鏈”。
因此,閉包非常容易創建循環引用,幸運的是JavaScript能夠很好的處理這種循環引用。
解決方法:
- 置空dom對象
如果我們需要將dom對象返回,可以用如下方法:
- 構造新的context
把function抽到新的context中,這樣,function的context就不包含對el的引用,從而打斷循環引用。
標記清除算法
- 現代的瀏覽器已經不再使用引用計數算法了。現代瀏覽器通用的大多是基于標記清除算法的某些改進算法,總體思想都是一致的。
- 標記清除算法將“不再使用的對象”定義為“無法達到的對象”。簡單來說,就是從根部(在JS中就是全局對象)出發定時掃描內存中的對象。凡是能從根部到達的對象,都是還需要使用的。那些無法由根部出發觸及到的對象被標記為不再使用,稍后進行回收。
- 從這個概念可以看出,無法觸及的對象包含了沒有引用的對象這個概念(沒有任何引用的對象也是無法觸及的對象)。但反之未必成立。因此當div(IE例子)與其時間處理函數不能再從全局對象出發觸及的時候,垃圾回收器就會標記并回收這兩個對象(在匿名函數中調用,div就不會出現在全局環境了)。
如何寫出對內存管理友好的JS代碼?
如果還需要兼容老舊瀏覽器,那么就需要注意代碼中的循環引用問題。或者直接采用保證兼容性的庫來幫助優化代碼。
對現代瀏覽器來說,唯一要注意的就是明確切斷需要回收的對象與根部的聯系。有時候這種聯系并不明顯,且因為標記清除算法的強壯性,這個問題較少出現。最常見的內存泄露一般都與DOM元素綁定有關:
參考:JavaScript 內存泄漏教程、JavaScript 內存機制(前端同學進階必備)
提升性能有關
- 阻塞式腳本:合并文件(減少http請求),將script標簽放在body尾部(減少頁面css,html的下載阻塞,減少界面的空白時間(瀏覽器在解析到script標簽之前,不會渲染頁面的任何部分))
目前流行的構建工具,如webpack,gulp,都有打包、合并文件的功能。
- 延遲腳本:defer和async屬性:都是并行下載,下載過程不阻塞,區別在于執行時機,async是下載完成后立即執行;defer是等頁面加載完成后再執行。defer僅當src屬性聲明時才生效(HTML5的規范)
- 適當將 DOM 元素保存在局部變量中——訪問 DOM 會很慢。如果要多次讀取某元素的內容,最好將其保存在局部變量中。但記住重要的是,如果稍后你會刪除 DOM 的值,則應將變量設置為“null”,不然會導致內存泄漏。
- 減少使用全局變量——因為全局變量總是存在于執行環境作用域鏈的最末端,所以,訪問全局變量是最慢的,訪問局部變量是最快的。且如果全局變量太多,內存壓力會變大,因為這些變量會得不到及時的回收而一直占用內存
- 減少閉包的使用——閉包會影響性能(作用域鏈加深)和可能導致內存泄漏,循環引用(IE中)
- 使用DocumentFragment優化多次append——一旦需要更新較多數量的DOM,請考慮使用文檔碎片來存儲DOM結構,然后再將其添加到現存的文檔中。
-
使用一次innerHTML賦值代替構建dom元素——對于大的DOM更改,使用innerHTML要比使用標準的DOM方法創建同樣的DOM結構快得多。
-
通過模板元素clone,替代createElement——而如果文檔中存在現成的可以復制的樣板節點,應該是用cloneNode()方法,因為使用createElement()方法之后,你需要設置多次元素的屬性,使用cloneNode()則可以減少屬性的設置次數——同樣如果需要創建很多元素,應該先準備一個樣板節點。
-
查詢子元素的html節點時,使用children比childNodes更好——childNodes 屬性,標準的,它返回指定元素的子元素集合,包括HTML節點,所有屬性,文本。而children 屬性,非標準的,它返回指定元素的子元素集合。經測試,它只返回HTML節點,甚至不返回文本節點。且在所有瀏覽器下表現驚人的一致。
-
刪除DOM節點——刪除dom節點之前,一定要刪除注冊在該節點上的事件,不管是用observe方式還是用attachEvent方式注冊的事件,否則將會產生無法回收的內存。另外,在removeChild和innerHTML=’’二者之間,盡量選擇后者. 因為在sIEve(內存泄露監測工具)中監測的結果是用removeChild無法有效地釋放dom節點。
-
優化循環——減值迭代、簡化終止條件(由于每次循環過程都會計算終止條件,所以必須保證它盡可能快,也就是說避免屬性查找或者其它的操作,最好是將循環控制量保存到局部變量中,也就是說對數組或列表對象的遍歷時,提前將length保存到局部變量中,避免在循環的每一步重復取值。)、使用后測試循環(while循環的效率要優于for(;;),最常用的for循環和while循環都是前測試循環,而如do-while這種后測試循環,可以避免最初終止條件的計算,因此運行更快。)
- 減少重繪和重排、事件委托、防抖和節流,動畫用translate3d來加速繪制、window.Unload事件解除引用、switch語句相對if較快、巧用||和&&布爾運算符轉換條件判斷
參考:JS性能優化38條"軍規",2019年嘔心力作
移動開發
<meta name="viewport" content="width=device-width,initial-scale=1.0,maximum-scale=1.0,user-scalable=no" />設備像素比(DPR) = 設備像素個數 / 理想視口像素個數(device-width)rem是相對尺寸單位,相對于html標簽字體大小的單位@media screen and (min-width: 321px) and (max-width:400px) {body {font-size:17px}}
數組方法集合
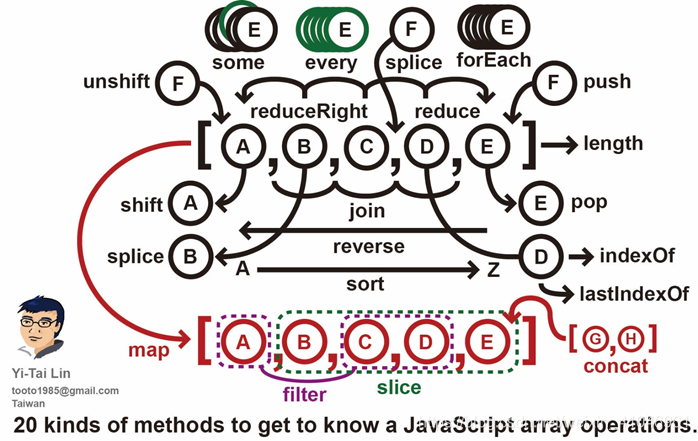
js小技巧
類型強制轉換
?string 強制轉換為數字
- 可以用
*1來轉化為數字(實際上是調用.valueOf方法)

- 也可以使用
+?來轉化字符串為數字。?

?object強制轉化為string
- object->string:JSON.stringify()
- string->object:JSON.parse()
使用 Boolean 過濾數組中的所有假值?
我們知道 JS 中有一些假值:false, null, 0, "", undefined, NaN,怎樣把數組中的假值快速過濾呢?可以使用 Boolean 構造函數來進行一次轉換。
const compact = arr => arr.filter(Boolean)compact([0, 1, false, 2, '', 3, 'a', 'e' * 23, NaN, 's', 34]) // [ 1, 2, 3, 'a', 's', 34 ]雙位運算符 ~~
可以使用雙位操作符來替代正數的 Math.floor(),替代負數的 Math.ceil()。雙否定位操作符的優勢在于它執行相同的操作運行速度更快。
Math.floor(4.9) === 4 //true
// 簡寫為:
~~4.9 === 4 //true~~-4.5 // -4
Math.floor(-4.5) // -5
Math.ceil(-4.5) // -4取整?|0
對一個數字 |0?可以取整,負數也同樣適用, num|0
1.3 | 0 // 1
-1.9 | 0 // -1?判斷奇偶數?&1
const num=3;
!!(num & 1) // true
!!(num % 2) // true函數
強制參數
默認情況下,如果不向函數參數傳值,那么 JS 會將函數參數設置為 undefined。其它一些語言則會發出警告或錯誤。要執行參數分配,可以使用 if?語句拋出未定義的錯誤,或者可以利用 強制參數。
mandatory = ( ) => {
throw new Error('Missing parameter!');
}
foo = (bar = mandatory( )) => { // 這里如果不傳入參數,就會執行manadatory函數報出錯誤
return bar;
}惰性載入函數
在某個場景下我們的函數中有判斷語句,這個判斷依據在整個項目運行期間一般不會變化,所以判斷分支在整個項目運行期間只會運行某個特定分支,那么就可以考慮惰性載入函數。
function foo() {if (a !== b) {console.log('aaa')}else {console.log('bbb')}
}
// 優化后
function foo() {if (a != b) {foo = function () {console.log('aaa')}}else {foo = function () {console.log('bbb')}}return foo();
}那么第一次運行之后就會覆寫這個方法,下一次再運行的時候就不會執行判斷了。當然現在只有一個判斷,如果判斷很多,分支比較復雜,那么節約的資源還是可觀的
一次性函數
跟上面的惰性載入函數同理,可以在函數體里覆寫當前函數,那么可以創建一個一次性的函數,重新賦值之前的代碼相當于只運行了一次,適用于運行一些只需要執行一次的初始化代碼。
var sca = function() {console.log('msg')//做初始化sca = function() {console.log('foo')}
}sca() // msg
sca() // foo
sca() // foo精確到指定位數的小數
numObj.toPrecision(precision)——以定點表示法或指數表示法表示的一個數值對象的字符串表示,四舍五入到?numObj.toPrecision(precision)
precision
可選。一個用來指定有效數個數的整數。var numObj = 5.123456;
console.log("numObj.toPrecision() is " + numObj.toPrecision()); //輸出 5.123456
console.log("numObj.toPrecision(5) is " + numObj.toPrecision(5)); //輸出 5.1235
console.log("numObj.toPrecision(2) is " + numObj.toPrecision(2)); //輸出 5.1
console.log("numObj.toPrecision(1) is " + numObj.toPrecision(1)); //輸出 5// 注意:在某些情況下會以指數表示法返回
console.log((1234.5).toPrecision(2)); // "1.2e+3"數組
reduce 方法同時實現 map 和 filter
假設現在有一個數列,你希望更新它的每一項(map 的功能)然后篩選出一部分(filter 的功能)。如果是先使用 map 然后 filter 的話,你需要遍歷這個數組兩次。
在下面的代碼中,我們將數列中的值翻倍,然后挑選出那些大于 50 的數。

統計數組中相同項的個數
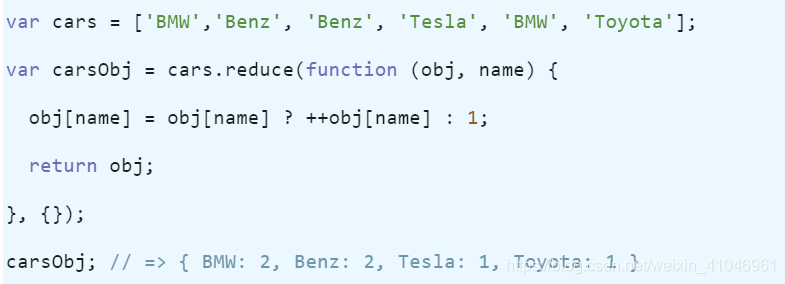
很多時候,你希望統計數組中重復出現項的個數然后用一個對象表示,那么你可以使用 reduce 方法處理這個數組。
下面的代碼將統計每一種車的數目然后把總數用一個對象表示
使用解構來交換參數數值
有時候你會將函數返回的多個值放在一個數組里,我們可以使用數組解構來獲取其中每一個值。
let param1 = 1;
let param2 = 2;
[param1, param2] = [param2, param1];
console.log(param1) // 2
console.log(param2) // 1當然我們關于交換數值有不少其他辦法:
var temp = a; a = b; b = temp
b = [a, a = b][0]
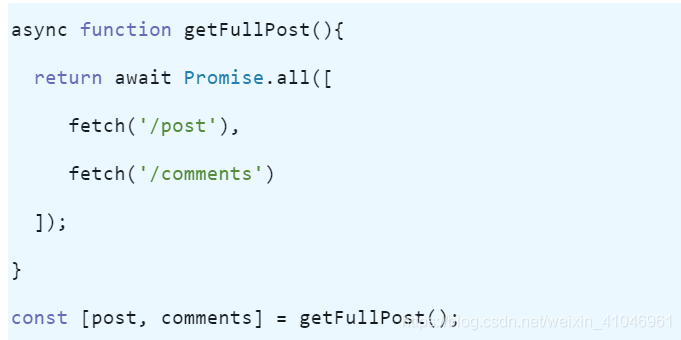
a = a + b; b = a - b; a = a - b接收函數返回的多個結果
在下面的代碼中,我們從 /post 中獲取一個帖子,然后在 /comments 中獲取相關評論。由于我們使用的是 async/await,函數把返回值放在一個數組中,而我們使用數組解構后就可以把返回值直接賦給相應的變量。
fetch(Fetch 是瀏覽器提供的原生 AJAX 接口。使用 window.fetch 函數可以代替以前的 $.ajax、$.get 和 $.post;即Fetch API 就是瀏覽器提供的用來代替 jQuery.ajax 的工具)可轉換成axios(axios是基于promise封裝的網絡請求(http)庫,在多處框架中被使用) 其特點為:
- 支持瀏覽器和node.js
- 支持promise
- 能攔截請求和響應
- 能轉換請求和響應數據
- 能取消請求
- 自動轉換JSON數據
- 瀏覽器端支持防止CSRF(跨站請求偽造)
補充:ajax即“Asynchronous?Javascript?And?XML”(異步?JavaScript?和?XML),ajax技術實現了在無需重新加載整個網頁的情況下刷新局部數據,通過在后臺與服務器進行少量數據交換,ajax可以使網頁實現異步更新。ajax的原則是“按需取數據”,可以最大程度的減少冗余請求和響應對服務器造成的負擔。
var xhttp = new XMLHttpRequest();xhttp.onreadystatechange = function() {if (this.readyState === 4 && this.status === 200) {console.log(this.responseText);}};xhttp.open("GET", "/", true);xhttp.send();參考:ajax、axios、fetch之間的詳細區別以及優缺點
代碼復用
Object [key]
雖然將 foo.bar 寫成 foo['bar'] 是一種常見的做法,但是這種做法構成了編寫可重用代碼的基礎。許多框架使用了這種方法,比如 element 的表單驗證。

上面的函數完美完成驗證工作,但是當有很多表單,則需要應用驗證,此時會有不同的字段和規則。如果可以構建一個在運行時配置的通用驗證函數,會是一個好選擇。
const schema = {first: {required: true},last: {required: true}
}
// universal validation function
const validate = (schema, values) => {for (field in schema) {if (schema[field].required) {if (!values[field]) {return false}}}return true;
}
console.log(validate(schema, {first: 'Bruce'
}));
// false
console.log(validate(schema, {first: 'Bruce',last: 'Wayne'
}));
// true
現在有了這個驗證函數,我們就可以在所有窗體中重用,而無需為每個窗體編寫自定義驗證函數。
參考:JS 中可以提升幸福度的小技巧
解讀HTTP/1、HTTP/2、HTTP/3之間的關系
HTTP 協議
HTTP 協議是 HyperText Transfer Protocol(超文本傳輸協議)的縮寫,它是互聯網上應用最為廣泛的一種網絡協議。所有的 WWW 文件的傳輸都必須遵守這個標準。伴隨著計算機網絡和瀏覽器的誕生,HTTP1.0 也隨之而來,處于計算機網絡中的應用層,HTTP 是建立在 TCP 協議之上,所以HTTP 協議的瓶頸及其優化技巧都是基于 TCP 協議本身的特性,例如 tcp 建立連接的 3 次握手和斷開連接的 4 次揮手以及每次建立連接帶來的 RTT 延遲時間。
HTTP之請求消息Request
客戶端發送一個HTTP請求到服務器的請求消息包括以下格式:
請求行(request line)、請求頭部(header)、空行和請求數據四個部分組成。
Host :請求頭指明了被請求服務器的域名(用于虛擬主機),以及(可選的)服務器監聽的TCP端口號。(Host: <host>:<port>)
Host: developer.cdn.mozilla.net例如:?我們在瀏覽器中輸入:http://www.hzau.edu.cn,瀏覽器發送的請求消息中,就會包含Host請求報頭域,如下:
Host:www.hzau.edu.cn,此處使用缺省端口號80,若指定了端口號,則變成:Host:指定端口號。
(由于一個IP地址可以對應多個域名,比如假設我有這么幾個域名www.qiniu.com,www.taobao.com和www.jd.com然后在域名提供商那通過A記錄或者CNAME記錄的方式最終都和我的虛擬機服務器IP 111.111.111.111關聯起來,那么我通過任何一個域名去訪問最終解析到的都是IP 111.111.111.111。我怎么來區分每次根據域名顯示出不同的網站的內容呢,其實這就要用到請求頭中Host的概念了,每個Host可以看做是我在服務器111.111.111.111上面的一個站點,每次我用那些域名訪問的時候都是會解析同一個虛擬機沒錯,但是我通過不同的Host可以區分出我是訪問這個虛擬機上的哪個站點。
參考:網絡---一篇文章詳解請求頭Host的概念
Referer:包含了當前請求頁面的來源頁面的地址,即表示當前頁面是通過此來源頁面里的鏈接進入的。服務端一般使用?Referer?請求頭識別訪問來源,可能會以此進行統計分析、日志記錄以及緩存優化等。(Referer: <url>)
表示這個請求是從哪個URL過來的,假如你通過google搜索出一個商家的廣告頁面,你對這個廣告頁面感興趣,鼠標一點發送一個請求報文到商家的網站,這個請求報文的Referer報文頭屬性值就是http://www.google.com。?
Referer?請求頭可能暴露用戶的瀏覽歷史,涉及到用戶的隱私問題。
Referer: https://developer.mozilla.org/en-US/docs/Web/JavaScriptOrigin:請求首部字段?Origin?指示了請求來自于哪個站點。該字段僅指示服務器名稱,并不包含任何路徑信息。該首部用于?CORS?請求或者?POST?請求。除了不包含路徑信息,該字段與?Referer?首部字段相似。(<scheme>協議 "://" <host>域名或者IP地址 [ ":" <port> 端口])eg:
Origin: https://developer.mozilla.orgOrigin字段的方式比Referer更人性化,因為它尊重了用戶的隱私。——Origin字段里只包含是誰發起的請求,并沒有其他信息 (通常情況下是方案,主機和活動文檔URL的端口)。跟Referer不一樣的是,Origin字段并沒有包含涉及到用戶隱私的URL路徑和請求內容,這個尤其重要。且Origin字段只存在于POST請求,而Referer則存在于所有類型的請求。
參考:Origin字段
HTTP之響應消息Response
一般情況下,服務器接收并處理客戶端發過來的請求后會返回一個HTTP的響應消息。
HTTP響應也由四個部分組成,分別是:狀態行、消息報頭、空行和響應正文。
HTTP之狀態碼
狀態代碼有三位數字組成,第一個數字定義了響應的類別,共分五種類別:
- 1xx:指示信息--表示請求已接收,繼續處理
- 2xx:成功--表示請求已被成功接收、理解、接受
- 3xx:重定向--要完成請求必須進行更進一步的操作
- 4xx:客戶端錯誤--請求有語法錯誤或請求無法實現
- 5xx:服務器端錯誤--服務器未能實現合法的請求
以下是幾個常見的狀態碼:?
- 200 OK?—— 你最希望看到的,即處理成功!
- 303 See Other —— 我把你redirect到其它的頁面,目標的URL通過響應報文頭的Location告訴你。?
- 304 Not Modified —— 告訴客戶端,你請求的這個資源至你上次取得后,并沒有更改,你直接用你本地的緩存吧,我很忙哦,你能? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 不能少來煩我啊!
- 403 Forbidden —— 服務器收到請求,但是拒絕提供服務
- 404 Not Found?—— 你最不希望看到的,即找不到頁面。如你在google上找到一個頁面,點擊這個鏈接返回404,表示這個頁面已? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 經被網站刪除了,google那邊的記錄只是美好的回憶。?
- 500 Internal Server Error?—— 服務器發生不可預期的錯誤
- 503 Server Unavailable —— 服務器當前不能處理客戶端的請求,一段時間后可能恢復正常
- URI,是uniform resource identifier,統一資源標識符,用來唯一的標識一個資源。
- 而URL是uniform resource locator,統一資源定位器,它是一種具體的URI,即URL可以用來標識一個資源,而且還指明了如何locate這個資源。
- 而URN,uniform resource name,統一資源命名,是通過名字來標識資源,比如mailto:java-net@java.sun.com。
- 也就是說,URI是以一種抽象的,高層次概念定義統一資源標識,而URL和URN則是具體的資源標識的方式。URL和URN都是一種URI。
- 在Java的URI中,一個URI實例可以代表絕對的,也可以是相對的,只要它符合URI的語法規則。而URL類則不僅符合語義,還包含了定位該資源的信息,因此它不能是相對的,schema必須被指定。
- URL是一種具體的URI,它不僅唯一標識資源,而且還提供了定位該資源的信息。URI是一種語義上的抽象概念,可以是絕對的,也可以是相對的,而URL則必須提供足夠的信息來定位,所以,是絕對的,而通常說的relative URL,則是針對另一個absolute URL,本質上還是絕對的。
URI抽象結構 ? ??[scheme:]scheme-specific-part[#fragment]
[scheme:][//authority][path][?query][#fragment]
authority為[user-info@]host[:port]
- URI 屬于父類,而 URL 屬于 URI 的子類。URL 是 URI 的一個子集
- URI 表示請求服務器的路徑,定義這么一個資源。而 URL 同時說明要如何訪問這個資源(http://)。
- URI可以分為URL,URN,或同時具備locators 和names特性的一個東西。URN作用就好像一個人的名字,URL就像一個人的地址。換句話說:URN確定了東西的身份,URL提供了找到它的方式。”
- URL是一種具體的URI,它不僅唯一標識資源,而且還提供了定位該資源的信息。
- URI是一種語義上的抽象概念,可以是絕對的,也可以是相對的,而URL則必須提供足夠的信息來定位(即絕對)。
參考:URI和URL的區別
HTTP/1.x 的缺陷
- 連接無法復用:連接無法復用會導致每次請求都經歷三次握手和慢啟動。三次握手在高延遲的場景下影響較明顯,慢啟動則對大量小文件請求影響較大(沒有達到最大窗口請求就被終止)。
? ? ? ? HTTP/1.0 傳輸數據時,每次都需要重新建立連接,增加延遲。
? ? ? ? HTTP/1.1 雖然加入 keep-alive 可以復用一部分連接,但域名分片等情況下仍然需要建立多個 connection,耗費資源,給服務器帶來性能壓力。
- Head-Of-Line Blocking(HOLB):導致帶寬無法被充分利用,以及后續健康請求被阻塞。HOLB是指一系列包(package)因為第一個包被阻塞;當頁面中需要請求很多資源的時候,HOLB(隊頭阻塞)會導致在達到最大請求數量時,剩余的資源需要等待其他資源請求完成后才能發起請求。
? ? ? ?HTTP 1.0:下個請求必須在前一個請求返回后才能發出,request-response對按序發生。顯然,如果某個請求長時間沒有返回,那么接下來的請求就全部阻塞了。
? ? ? ?HTTP 1.1:嘗試使用 pipeling 來解決,即瀏覽器可以一次性發出多個請求(同個域名,同一條 TCP 鏈接)。但 pipeling 要求返回是按序的,那么前一個請求如果很耗時(比如處理大圖片),那么后面的請求即使服務器已經處理完,仍會等待前面的請求處理完才開始按序返回。所以,pipeling 只部分解決了 HOLB。
如上圖所示,紅色圈出來的請求就因域名鏈接數已超過限制,而被掛起等待了一段時間。
- 協議開銷大: HTTP1.x 在使用時,header 里攜帶的內容過大,在一定程度上增加了傳輸的成本,并且每次請求 header 基本不怎么變化,尤其在移動端增加用戶流量。
- 安全因素:HTTP1.x 在傳輸數據時,所有傳輸的內容都是明文,客戶端和服務器端都無法驗證對方的身份,這在一定程度上無法保證數據的安全性
- 雖然 HTTP1.x 支持了 keep-alive,來彌補多次創建連接產生的延遲,但是 keep-alive 使用多了同樣會給服務端帶來大量的性能壓力,并且對于單個文件被不斷請求的服務 (例如圖片存放網站),keep-alive 可能會極大的影響性能,因為它在文件被請求之后還保持了不必要的連接很長時間。
HTTPS 應聲而出(安全版的http)
- HTTPS 協議需要到 CA 申請證書,一般免費證書很少,需要交費。
- HTTP 協議運行在 TCP 之上,所有傳輸的內容都是明文,HTTPS 運行在 SSL/TLS 之上,SSL/TLS 運行在 TCP 之上,所有傳輸的內容都經過加密的。(HTTPS 是與?SSL?一起使用的;在 SSL 逐漸演變到成TLS?(其實兩個是一個東西,只是名字不同而已的安全傳輸協議))
- HTTP 和 HTTPS 使用的是完全不同的連接方式,用的端口也不一樣,前者是 80,后者是 443。
- HTTPS 可以有效的防止運營商劫持,解決了防劫持的一個大問題。
SPDY 協議
【(讀作“SPeeDY”)是Google開發的基于TCP的會話層 協議,用以最小化網絡延遲,提升網絡速度,優化用戶的網絡使用體驗。?SPDY并不是一種用于替代HTTP的協議,而是對HTTP協議的增強。】
因為 HTTP/1.x 的問題,我們會引入雪碧圖、將小圖內聯、使用多個域名等等的方式來提高性能。不過這些優化都繞開了協議,直到 2009 年,谷歌公開了自行研發的 SPDY 協議,主要解決 HTTP/1.1 效率不高的問題。谷歌推出 SPDY,才算是正式改造 HTTP 協議本身。降低延遲,壓縮 header 等等,SPDY 的實踐證明了這些優化的效果,也最終帶來 HTTP/2 的誕生。
SPDY 協議在 Chrome 瀏覽器上證明可行以后,就被當作 HTTP/2 的基礎,主要特性都在 HTTP/2 之中得到繼承。
SPDY 可以說是綜合了 HTTPS 和 HTTP 兩者有點于一體的傳輸協議,主要解決:
- 降低延遲,針對 HTTP 高延遲的問題,SPDY 優雅的采取了多路復用(multiplexing)。多路復用通過多個請求 stream 共享一個 tcp 連接的方式,解決了 HOL blocking 的問題,降低了延遲同時提高了帶寬的利用率。
- 請求優先級(request prioritization)。多路復用帶來一個新的問題是,在連接共享的基礎之上有可能會導致關鍵請求被阻塞。SPDY 允許給每個 request 設置優先級,這樣重要的請求就會優先得到響應。比如瀏覽器加載首頁,首頁的 html 內容應該優先展示,之后才是各種靜態資源文件,腳本文件等加載,這樣可以保證用戶能第一時間看到網頁內容。
- header 壓縮。前面提到 HTTP1.x 的 header 很多時候都是重復多余的。選擇合適的壓縮算法可以減小包的大小和數量。
- 基于 HTTPS 的加密協議傳輸,大大提高了傳輸數據的可靠性。
- 服務端推送(server push),采用了 SPDY 的網頁,例如我的網頁有一個 sytle.css 的請求,在客戶端收到 sytle.css 數據的同時,服務端會將 sytle.js 的文件推送給客戶端,當客戶端再次嘗試獲取 sytle.js 時就可以直接從緩存中獲取到,不用再發請求了。
SPDY 位于 HTTP 之下,TCP 和 SSL 之上,這樣可以輕松兼容老版本的 HTTP 協議 (將 HTTP1.x 的內容封裝成一種新的 frame 格式),同時可以使用已有的 SSL 功能
HTTP2.0 的前世今生
顧名思義有了 HTTP1.x,那么 HTTP2.0 也就順理成章的出現了。HTTP/2 是現行 HTTP 協議(HTTP/1.x)的替代,但它不是重寫,HTTP 方法/狀態碼/語義都與 HTTP/1.x 一樣。HTTP/2 基于 SPDY3,專注于性能,最大的一個目標是在用戶和網站間只用一個連接(connection)。
HTTP2.0 可以說是 SPDY 的升級版(其實原本也是基于 SPDY 設計的),但是,HTTP2.0? 跟 SPDY 仍有不同的地方,主要是以下兩點:
- HTTP2.0? 支持明文 HTTP 傳輸,而 SPDY 強制使用 HTTPS
- HTTP2.0 消息頭的壓縮算法采用?HPACK,而非 SPDY 采用的?DEFLATE
HTTP2.0 的新特性
- 新的二進制格式(Binary Format),HTTP1.x 的解析是基于文本。基于文本協議的格式解析存在天然缺陷,文本的表現形式有多樣性,要做到健壯性考慮的場景必然很多,二進制則不同,只認 0 和 1 的組合。基于這種考慮 HTTP2.0 的協議解析決定采用二進制格式,實現方便且健壯。
- 多路復用(MultiPlexing),即連接共享,即每一個 request 都是是用作連接共享機制的。一個 request 對應一個 id,這樣一個連接上可以有多個 request,每個連接的 request 可以隨機的混雜在一起,接收方可以根據 request 的 id 將 request 再歸屬到各自不同的服務端請求里面。(單連接+幀、分包傳輸、打散,在客戶端進行重組),1.0是最大6個連接,等連接都完成后再進行下一次的6個連接,即HOLB(隊頭阻塞)會導致在達到最大請求數量時,剩余的資源需要等待其他資源請求完成后才能發起請求。
- header 壓縮,如上文中所言,對前面提到過 HTTP1.x 的 header 帶有大量信息,而且每次都要重復發送,HTTP2.0 使用 encoder 來減少需要傳輸的 header 大小,通訊雙方各自 cache 一份 header fields 表,既避免了重復 header 的傳輸,又減小了需要傳輸的大小。
- 服務端推送(server push),同 SPDY 一樣,HTTP2.0 也具有 server push 功能。目前,有大多數網站已經啟用 HTTP2.0,例如?YouTuBe,淘寶網等網站
HTTP2.0 的升級改造
對比 HTTPS 的升級改造,HTTP2.0 或許會稍微簡單一些,你可能需要關注以下問題:
- 前文說了 HTTP2.0 其實可以支持非 HTTPS 的,但是現在主流的瀏覽器像 chrome,firefox 表示還是只支持基于 TLS 部署的 HTTP2.0 協議,所以要想升級成 HTTP2.0 還是先升級 HTTPS 為好。
- 當你的網站已經升級 HTTPS 之后,那么升級 HTTP2.0 就簡單很多,如果你使用 NGINX,只要在配置文件中啟動相應的協議就可以了,可以參考?NGINX 白皮書,NGINX 配置 HTTP2.0 官方指南。
- 使用了 HTTP2.0 那么,原本的 HTTP1.x 怎么辦,這個問題其實不用擔心,HTTP2.0 完全兼容 HTTP1.x 的語義,對于不支持 HTTP2.0 的瀏覽器,NGINX 會自動向下兼容的。
HTTP/2 的缺點
雖然 HTTP/2 解決了很多之前舊版本的問題,但是它還是存在一個巨大的問題,主要是底層支撐的 TCP 協議造成的。HTTP/2的缺點主要有以下幾點:
TCP 以及 TCP+TLS建立連接的延時:
HTTP/2都是使用TCP協議來傳輸的,而如果使用HTTPS的話,還需要使用TLS協議進行安全傳輸,而使用TLS也需要一個握手過程,這樣就需要有兩個握手延遲過程:
①在建立TCP連接的時候,需要和服務器進行三次握手來確認連接成功,也就是說需要在消耗完1.5個RTT之后才能進行數據傳輸。
②進行TLS連接,TLS有兩個版本——TLS1.2和TLS1.3,每個版本建立連接所花的時間不同,大致是需要1~2個RTT。
總之,在傳輸數據之前,我們需要花掉 3~4 個 RTT。
TCP的隊頭阻塞并沒有徹底解決:
上文我們提到在HTTP/2中,多個請求是跑在一個TCP管道中的。但當出現了丟包時,HTTP/2 的表現反倒不如 HTTP/1 了。因為TCP為了保證可靠傳輸,有個特別的“丟包重傳”機制,丟失的包必須要等待重新傳輸確認,HTTP/2出現丟包時,整個 TCP 都要開始等待重傳,那么就會阻塞該TCP連接中的所有請求(如下圖)。而對于 HTTP/1.1 來說,可以開啟多個 TCP 連接,出現這種情況反到只會影響其中一個連接,剩余的 TCP 連接還可以正常傳輸數據。
HTTP/3簡介
Google 在推SPDY的時候就已經意識到了這些問題,于是就另起爐灶搞了一個基于 UDP 協議的“QUIC”協議,讓HTTP跑在QUIC上而不是TCP上。而這個“HTTP over QUIC”就是HTTP協議的下一個大版本,HTTP/3。它在HTTP/2的基礎上又實現了質的飛躍,真正“完美”地解決了“隊頭阻塞”問題。
QUIC 雖然基于 UDP,但是在原本的基礎上新增了很多功能,接下來我們重點介紹幾個QUIC新功能。不過HTTP/3目前還處于草案階段,正式發布前可能會有變動,所以本文盡量不涉及那些不穩定的細節。
3.QUIC新功能
上面我們提到QUIC基于UDP,而UDP是“無連接”的,根本就不需要“握手”和“揮手”,所以就比TCP來得快。此外QUIC也實現了可靠傳輸,保證數據一定能夠抵達目的地。它還引入了類似HTTP/2的“流”和“多路復用”,單個“流"是有序的,可能會因為丟包而阻塞,但其他“流”不會受到影響。具體來說QUIC協議有以下特點:
-
實現了類似TCP的流量控制、傳輸可靠性的功能。
雖然UDP不提供可靠性的傳輸,但QUIC在UDP的基礎之上增加了一層來保證數據可靠性傳輸。它提供了數據包重傳、擁塞控制以及其他一些TCP中存在的特性。
-
實現了快速握手功能。
由于QUIC是基于UDP的,所以QUIC可以實現使用0-RTT或者1-RTT來建立連接,這意味著QUIC可以用最快的速度來發送和接收數據,這樣可以大大提升首次打開頁面的速度。0RTT 建連可以說是 QUIC 相比 HTTP2 最大的性能優勢。
-
集成了TLS加密功能。
目前QUIC使用的是TLS1.3,相較于早期版本TLS1.3有更多的優點,其中最重要的一點是減少了握手所花費的RTT個數。
-
多路復用,徹底解決TCP中隊頭阻塞的問題
和TCP不同,QUIC實現了在同一物理連接上可以有多個獨立的邏輯數據流(如下圖)。實現了數據流的單獨傳輸,就解決了TCP中隊頭阻塞的問題。
七、總結
-
HTTP/1.1有兩個主要的缺點:安全不足和性能不高。
-
HTTP/2完全兼容HTTP/1,是“更安全的HTTP、更快的HTTPS",頭部壓縮、多路復用等技術可以充分利用帶寬,降低延遲,從而大幅度提高上網體驗;
-
QUIC 基于 UDP 實現,是 HTTP/3 中的底層支撐協議,該協議基于 UDP,又取了 TCP 中的精華,實現了即快又可靠的協議。
參考:HTTP,HTTP2.0,SPDY,HTTPS 你應該知道的一些事、解讀HTTP/2與HTTP/3 的新特性、一文讀懂 HTTP/2 及 HTTP/3 特性
cookie、session、token
cookie 是什么
簡單地說,cookie 就是瀏覽器儲存在用戶電腦上的一小段文本文件。cookie 是純文本格式,不包含任何可執行的代碼。僅僅是瀏覽器實現的一種數據存儲功能。
cookie由服務器生成,發送給瀏覽器,瀏覽器把cookie以kv形式保存到某個目錄下的文本文件內,下一次請求同一網站時會把該cookie發送給服務器。由于cookie是存在客戶端上的,所以瀏覽器加入了一些限制確保cookie不會被惡意使用,同時不會占據太多磁盤空間,所以每個域的cookie數量是有限的。
創建 cookie
Web 服務器通過發送一個稱為?Set-Cookie?的 HTTP 消息頭來創建一個 cookie,Set-Cookie消息頭是一個字符串,其格式如下(中括號中的部分是可選的):
Set-Cookie: value[; expires=date][; domain=domain][; path=path][; secure; HttpOnly]domain,指定了 cookie 將要被發送至哪個或哪些域中。默認情況下,domain會被設置為創建該 cookie 的頁面所在的域名,所以當給相同域名發送請求時該 cookie 會被發送至服務器。例如,本博中 cookie 的默認值將是?bubkoo.com。domain?選項可用來擴充 cookie 可發送域的數量?。domain?選項的值必須是發送?Set-Cookie?消息頭的主機名的一部分- secure,只有當一個請求通過 SSL 或 HTTPS 創建時,包含?
secure?選項的 cookie 才能被發送至服務器。 HTTP-Only?,背后的意思是告之瀏覽器該 cookie 絕不能通過 JavaScript 的?document.cookie?屬性訪問。設計該特征意在提供一個安全措施來幫助阻止通過 JavaScript 發起的跨站腳本攻擊 (XSS) 竊取 cookie 的行為
參考:HTTP cookies 詳解
Session
session 從字面上講,就是會話。這個就類似于你和一個人交談,你怎么知道當前和你交談的是張三而不是李四呢?對方肯定有某種特征(長相等)表明他就是張三。
session 也是類似的道理,服務器要知道當前發請求給自己的是誰。為了做這種區分,服務器就要給每個客戶端分配不同的“身份標識”,然后客戶端每次向服務器發請求的時候,都帶上這個“身份標識”,服務器就知道這個請求來自于誰了。至于客戶端怎么保存這個“身份標識”,可以有很多種方式,對于瀏覽器客戶端,大家都默認采用 cookie 的方式。
客戶端對服務端請求時,服務端會檢查請求中是否包含一個session標識( 稱為session id ).
- 如果沒有,那么服務端就生成一個隨機的session以及和它匹配的session id,并將session id返回給客戶端.
- 如果有,那么服務器就在存儲中根據session id 查找到對應的session.
當瀏覽器禁止Cookie時,可以有兩種方法繼續傳送session id到服務端:
- 第一種:URL重寫(常用),就是把session id直接附加在URL路徑的后面。
- 第二種:表單隱藏字段,將sid寫在隱藏的表單中。
Cookie和Session的區別:
1、cookie數據存放在客戶的瀏覽器上,session數據放在服務器上。
2、cookie不是很安全,別人可以分析存放在本地的cookie并進行cookie欺騙,考慮到安全應當使用session。
3、session會在一定時間內保存在服務器上。當訪問增多,會比較占用你服務器的性能,考慮到減輕服務器性能方面,應當使用cookie。
4、單個cookie保存的數據不能超過4K,很多瀏覽器都限制一個站點最多保存20個cookie。
5、所以個人建議:
將登陸信息等重要信息存放為session
其他信息如果需要保留,可以放在cookie中
session的缺點:
1.Seesion:每次認證用戶發起請求時,服務器需要去創建一個記錄來存儲信息。當越來越多的用戶發請求時,內存的開銷也會不斷增加。
2.可擴展性:在服務端的內存中使用Seesion存儲登錄信息,伴隨而來的是可擴展性問題。
3.CORS(跨域資源共享):當我們需要讓數據跨多臺移動設備上使用時,跨域資源的共享會是一個讓人頭疼的問題。在使用Ajax抓取另一個域的資源,就可以會出現禁止請求的情況。
4.CSRF(跨站請求偽造):用戶在訪問銀行網站時,他們很容易受到跨站請求偽造的攻擊,并且能夠被利用其訪問其他的網站。
Token
在Web領域基于Token的身份驗證隨處可見。在大多數使用Web API的互聯網公司中,tokens 是多用戶下處理認證的最佳方式。
? ? 1、Token的引入:Token是在客戶端頻繁向服務端請求數據,服務端頻繁的去數據庫查詢用戶名和密碼并進行對比,判斷用戶名和密碼正確與否,并作出相應提示,在這樣的背景下,Token便應運而生。
? ? 2、Token的定義:Token是服務端生成的一串字符串,以作客戶端進行請求的一個令牌,當第一次登錄后,服務器生成一個Token(將用戶數據包裝成token)便將此Token返回給客戶端,以后客戶端只需帶上這個Token前來請求數據即可,無需再次帶上用戶名和密碼。
? ? 3、使用Token的目的:Token的目的是為了減輕服務器的壓力(不需要保存所有人的sessionId,對比起session),減少頻繁的查詢數據庫,使服務器更加健壯。
即基于Token的身份驗證是無狀態的,我們不將用戶信息存在服務器或Session中。
以下幾點特性會讓你在程序中使用基于Token的身份驗證
1.無狀態、可擴展
2.支持移動設備
3.跨程序調用
4.安全(每個請求都有簽名還能防止監聽以及重放攻擊)
那些使用基于Token的身份驗證的大佬們
大部分你見到過的API和Web應用都使用tokens。例如Facebook, Twitter, Google+, GitHub等。
Token是用戶的驗證方式,最簡單的token組成:uid(用戶唯一的身份標識)、time(當前時間的時間戳)、sign(簽名,由token的前幾位+鹽以哈希算法壓縮成一定長的十六進制字符串,可以防止惡意第三方拼接token請求服務器)。
舉例:
##JWT+HA256驗證
實施 Token 驗證的方法挺多的,還有一些標準方法,比如 JWT,讀作:jot ,表示:JSON Web Tokens 。JWT 標準的 Token 有三個部分:
header
payload
signature
中間用點分隔開,并且都會使用 Base64 編碼,所以真正的 Token 看起來像這樣:
?
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJuaW5naGFvLm5ldCIsImV4cCI6IjE0Mzg5NTU0NDUiLCJuYW1lIjoid2FuZ2hhbyIsImFkbWluIjp0cnVlfQ.SwyHTEx_RQppr97g4J5lKXtabJecpejuef8AqKYMAJc
###Header
header 部分主要是兩部分內容,一個是 Token 的類型,另一個是使用的算法,比如下面類型就是 JWT,使用的算法是 HS256,就是SHA-256,和md5一樣是不可逆的散列算法。
{"typ": "JWT","alg": "HS256"
}上面的內容要用 Base64 的形式編碼一下,所以就變成這樣:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9###Payload
Payload 里面是 Token 的具體內容,這些內容里面有一些是標準字段,你也可以添加其它需要的內容。下面是標準字段:
iss:Issuer,發行者
sub:Subject,主題
aud:Audience,觀眾
exp:Expiration time,過期時間
nbf:Not before
iat:Issued at,發行時間
jti:JWT ID
比如下面這個 Payload ,用到了 iss 發行人,還有 exp 過期時間。另外還有兩個自定義的字段,一個是 name ,還有一個是 admin 。
{ "iss": "ninghao.net","exp": "1438955445","name": "wanghao","admin": true
}使用 Base64 編碼以后就變成了這個樣子:
eyJpc3MiOiJuaW5naGFvLm5ldCIsImV4cCI6IjE0Mzg5NTU0NDUiLCJuYW1lIjoid2FuZ2hhbyIsImFkbWluIjp0cnVlfQ###Signature
JWT 的最后一部分是 Signature ,這部分內容有三個部分,先是用 Base64 編碼的 header.payload ,再用加密算法加密一下,加密的時候要放進去一個 Secret ,這個相當于是一個密碼,這個密碼秘密地存儲在服務端。
var encodedString = base64UrlEncode(header) + "." + base64UrlEncode(payload);?
HMACSHA256(encodedString, 'secret');處理完成以后看起來像這樣:
SwyHTEx_RQppr97g4J5lKXtabJecpejuef8AqKYMAJc最后這個在服務端生成并且要發送給客戶端的 Token 看起來像這樣:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJuaW5naGFvLm5ldCIsImV4cCI6IjE0Mzg5NTU0NDUiLCJuYW1lIjoid2FuZ2hhbyIsImFkbWluIjp0cnVlfQ.SwyHTEx_RQppr97g4J5lKXtabJecpejuef8AqKYMAJc客戶端收到這個 Token 以后把它存儲下來,下會向服務端發送請求的時候就帶著這個 Token 。服務端收到這個 Token ,然后進行驗證,通過以后就會返回給客戶端想要的資源。
驗證的過程就是
根據傳過來的token再生成一下第三部分Signature,然后兩個比對一下,一致就驗證通過。
使用基于 Token 的身份驗證方法,在服務端不需要存儲用戶的登錄記錄(有就直接到數據庫查,沒有就直接打回,也就不需要再去查數據庫然后返回無信息)。大概的流程是這樣的:
- 客戶端使用用戶名跟密碼請求登錄
- 服務端收到請求,去驗證用戶名與密碼
- 驗證成功后,服務端會簽發一個 Token,再把這個 Token 發送給客戶端
- 客戶端收到 Token 以后可以把它存儲起來,比如放在 Cookie 里或者 Local Storage 里
- 客戶端每次向服務端請求資源的時候需要帶著服務端簽發的 Token(header里)
- 服務端收到請求,然后去驗證客戶端請求里面帶著的 Token,(利用密匙和數據解出簽名,和token的簽名對比,如果相同則通過)如果驗證成功,就向客戶端返回請求的數據
?

參考:JWT產生和驗證Token、Cookie、Session、Token那點事兒(原創)、徹底理解cookie,session,token(轉)、會話(Cookie,Session,Token)管理知識整理(一)
MVC、MVP和MVVM
MVC:Model+View+Controller
M-Model 模型:數據保存
V-View 視圖: 用戶界面
C-Controller 控制器: 業務邏輯
MVC ,用戶操作> View (負責接受用戶的輸入操作)>Controller(業務邏輯處理)>Model(數據持久化)>View(將結果通過View反饋給用戶)
各部分的通信方式是單向傳遞。
view向controller傳遞指令,controller完成業務邏輯后,要求Model改變狀態,Model將新的數據發送到view,用戶得到反饋。
MVC接受用戶指令時可以通過兩種方式:一種是通過view接收指令,傳遞給controller;一種是直接通過controller接收指令。
在MVC里,View是可以直接訪問Model的!從而,View里會包含Model信息,不可避免的還要包括一些 業務邏輯。 在MVC模型里,更關注的Model的不變,而同時有多個對Model的不同顯示,及View。所以,在MVC模型里,Model不依賴于View,但是 View是依賴于Model的。不僅如此,因為有一些業務邏輯在View里實現了,導致要更改View也是比較困難的,至少那些業務邏輯是無法重用的。
Model層
Model層 是服務端數據在客戶端的映射,是薄薄的一層,完全可以用struct表征。下面看一個實例:
?
可以看到,Model 層通常是服務端傳回的 JSON數據的映射,對應為一個一個的屬性。不過現在也有很多人將網絡層(Service層)歸到Model中,也就是MVC(S)架構。同時,大部分時候數據的持久化操作也會放在Model層中。
總結一下,Model層的職責主要有以下幾項:HTTP請求、進行字段驗證、持久化等。
View層
View層是展示在屏幕上的視圖的封裝,在 iOS 中也就是UIView以及UIView的子類。下面是UIView的繼承層級圖:
?
View層的職責是展示內容和接受用戶的操作與事件。
Controller層
看了Model層和View層如此簡單清晰的定義,如果你以為接下來要講的Controller層的定義也跟這兩層一樣,那你就要失望了。
粗略總結了一下,Controller層的職責包括但不限于:管理根視圖以及其子視圖的生命周期、展示內容和布局、處理用戶行為(如按鈕的點擊和手勢的觸發等)、儲存當前界面的狀態(例如分頁加載的頁數、是否正在進行網絡請求的布爾值等)、處理界面的跳轉、作為UITableView以及其它容器視圖的代理以及數據源、業務邏輯和各種動畫效果等。
按照傳統的MVC定義,分割了小部分到Model層和View層,剩下的代碼都沒有其他地方可以去了,于是被統統的丟到了Controll層中。
龐大的Controller層帶來的問題就是難以維護、難以測試。而且其中充斥著大量的狀態值,一個任務的完成依賴于好幾個狀態值,而一個狀態值又同時參與到多個任務中,這樣復雜的多對多關系帶來的問題就是開發效率低下,需要花費大量的時間周旋在各個狀態值之間,對以后的功能拓展、業務添加也造成了障礙。
MVP?
MVP?是從經典的模式MVC演變而來,它們的基本思想有相通的地方:Controller/Presenter負責邏輯的處理,Model提供數據,View負責顯示。作為一種新的模式,MVP與MVC有著一個重大的區別:在MVP中View并不直接使用Model,它們之間的通信是通過Presenter (MVC中的Controller)來進行的,所有的交互都發生在Presenter內部,而在MVC中View會從直接Model中讀取數據而不是通過 Controller。
在MVP里,Presenter完全把Model和View進行了分離,主要的程序邏輯在Presenter里實現。而且,Presenter與具體的 View是沒有直接關聯的,而是通過定義好的接口進行交互,從而使得在變更View時候可以保持Presenter的不變,即重用!
不僅如此,我們還可以編寫測試用的View,模擬用戶的各種操作,從而實現對Presenter的測試--而不需要使用自動化的測試工具。 我們甚至可以在Model和View都沒有完成時候,就可以通過編寫Mock Object(即實現了Model和View的接口,但沒有具體的內容的)來測試Presenter的邏輯。
在MVP里,應用程序的邏輯主要在Presenter來實現,其中的View是很薄的一層。因此就有人提出了Presenter First的設計模式,就是根據User Story來首先設計和開發Presenter。在這個過程中,View是很簡單的,能夠把信息顯示清楚就可以了。在后面,根據需要再隨便更改View, 而對Presenter沒有任何的影響了。 如果要實現的UI比較復雜,而且相關的顯示邏輯還跟Model有關系,就可以在View和Presenter之間放置一個Adapter。由這個 Adapter來訪問Model和View,避免兩者之間的關聯。而同時,因為Adapter實現了View的接口,從而可以保證與Presenter之 間接口的不變。這樣就可以保證View和Presenter之間接口的簡潔,又不失去UI的靈活性。 在MVP模式里,View只應該有簡單的Set/Get的方法,用戶輸入和設置界面顯示的內容,除此就不應該有更多的內容,絕不容許直接訪問 Model--這就是與MVC很大的不同之處。
目前我們提倡的MVC已經與MVP沒有太大區別,View依然是很薄的一層,不進行與Model的邏輯處理,只進行簡單的頁面顯示的邏輯處理。
MVVM(以VUE.JS來舉例)
MVVM在概念上是真正將頁面與數據邏輯分離的模式,在開發方式上,它是真正將前臺代碼開發者(JS+HTML)與后臺代碼開發者分離的模式(asp,asp.net,php,jsp)。?ViewModel負責連接 View 和 Model,保證視圖和數據的一致性,這種輕量級的架構讓前端開發更加高效、便捷。??
MVVM 的出現促進了 GUI 前端開發與后端業務邏輯的分離,極大地提高了前端開發效率。MVVM 的核心是 ViewModel 層,它就像是一個中轉站(value converter),負責轉換 Model 中的數據對象來讓數據變得更容易管理和使用,該層向上與視圖層進行雙向數據綁定,向下與 Model 層通過接口請求進行數據交互,起呈上啟下作用。如下圖所示:
MVVM模式
MVVM 已經相當成熟了,主要運用但不僅僅在網絡應用程序開發中。KnockoutJS 是最早實現 MVVM 模式的前端框架之一,當下流行的 MVVM 框架有 Vue,Angular 等。
簡單畫了一張圖來說明 MVVM 的各個組成部分:
?
分層設計一直是軟件架構的主流設計思想之一,MVVM 也不例外。
# View 層
View 是視圖層,也就是用戶界面。前端主要由 HTML 和 CSS 來構建,為了更方便地展現 ViewModel 或者 Model 層的數據,已經產生了各種各樣的前后端模板語言,比如 FreeMarker、Marko、Pug、Jinja2等等,各大 MVVM 框架如 KnockoutJS,Vue,Angular 等也都有自己用來構建用戶界面的內置模板語言。
# Model 層
Model 是指數據模型,泛指后端進行的各種業務邏輯處理和數據操控,主要圍繞數據庫系統展開。后端的處理通常會非常復雜:
前后端對比
后端:我們這里的業務邏輯和數據處理會非常復雜!
前端:關我屁事!
后端業務處理再復雜跟我們前端也沒有半毛錢關系,只要后端保證對外接口足夠簡單就行了,我請求api,你把數據返出來,咱倆就這點關系,其他都扯淡。
# ViewModel 層
ViewModel 是由前端開發人員組織生成和維護的視圖數據層。在這一層,前端開發者對從后端獲取的 Model 數據進行轉換處理,做二次封裝,以生成符合 View 層使用預期的視圖數據模型。需要注意的是 ViewModel 所封裝出來的數據模型包括視圖的狀態和行為兩部分,而 Model 層的數據模型是只包含狀態的,比如頁面的這一塊展示什么,那一塊展示什么這些都屬于視圖狀態(展示),而頁面加載進來時發生什么,點擊這一塊發生什么,這一塊滾動時發生什么這些都屬于視圖行為(交互),視圖狀態和行為都封裝在了 ViewModel 里。這樣的封裝使得 ViewModel 可以完整地去描述 View 層。由于實現了雙向綁定,ViewModel 的內容會實時展現在 View 層,這是激動人心的,因為前端開發者再也不必低效又麻煩地通過操縱 DOM 去更新視圖,MVVM 框架已經把最臟最累的一塊做好了,我們開發者只需要處理和維護 ViewModel,更新數據視圖就會自動得到相應更新,真正實現數據驅動開發。看到了吧,View 層展現的不是 Model 層的數據,而是 ViewModel 的數據,由 ViewModel 負責與 Model 層交互,這就完全解耦了 View 層和 Model 層,這個解耦是至關重要的,它是前后端分離方案實施的重要一環。
針對于VUE的MVVM:
- 從 M 到 V 的映射(Data Binding),這樣可以大量節省你人肉來 update View 的代碼(也就是所說的 UI 邏輯)
- 從 V 到 M 的事件監聽(DOM Listeners),這樣你的 Model 會隨著 View 觸發事件而改變
針對上圖,個人更傾向于將VUE文件里的script里export default 對象里的部分規劃為Model層,即Model層可以包含數據模型和頁面交互邏輯,應用邏輯全部是數據操作,雖然上圖描繪Model層是純js對象(即使用Object.prototype.toString.call(data) === '[object Object]')可能讓人覺得是data對象,但是前者同樣是會導出純js對象的。View 代表UI 組件,它負責將數據模型轉化成UI 展現出來,ViewModel 是一個同步View 和 Model的對象。
在MVVM架構下,View 和 Model 之間并沒有直接的聯系,而是通過ViewModel進行交互,Model 和 ViewModel 之間的交互是雙向的, 因此View 數據的變化會同步到Model中,而Model 數據的變化也會立即反應到View 上。
ViewModel 通過雙向數據綁定把 View 層和 Model 層連接了起來,而View 和 Model 之間的同步工作完全是自動的,無需人為干涉,因此開發者只需關注業務邏輯,不需要手動操作DOM, 不需要關注數據狀態的同步問題,復雜的數據狀態維護完全由 MVVM 來統一管理。
針對VUE.JS的MVVM'模式的優點:
- 最主要的雙向綁定技術——核心是提供對View 和 ViewModel 的雙向數據綁定,這使得ViewModel 的狀態改變可以自動傳遞給 View,view層的變化也能及時在VM得到響應,MVVM的設計思想:關注Model(數據)的變化,讓MVVM框架去自動更新DOM的狀態,從而把發者從操作DOM的繁瑣步驟中解脫出來!
- 低耦合(不是無耦合)。由于View 和 Model 之間并沒有直接的聯系,視圖(View)可以獨立于Model變化和修改,一個ViewModel可以綁定到不同的"View"上,當View變化的時候Model可以不變,當Model變化的時候View也可以不變。
- 可重用性。你可以把一些視圖邏輯放在一個ViewModel里面,讓很多view重用這段視圖邏輯。
- 獨立開發。開發人員可以專注于業務邏輯和數據的開發(ViewModel),設計人員可以專注于頁面設計
- 可測試。界面素來是比較難于測試的,而現在測試可以針對ViewModel來寫易用靈活高效
參考:前后端分手大師——MVVM 模式、MVVM架構~mvc,mvp,mvvm大話開篇、MVC與MVVM的區別、響應式編程與MVVM架構—理論篇、Vue.js 和 MVVM 小細節、MVVM實現原理
?
VUE.JS
Vue (讀音 /vju?/,類似于 view) 是一套用于構建用戶界面的漸進式JavaScript框架。與其它大型框架不同的是,Vue 被設計為可以自底向上逐層應用。Vue 的核心庫只關注視圖層,方便與第三方庫或既有項目整合。
如下圖所示,在具有響應式系統的Vue實例中,DOM狀態只是數據狀態的一個映射 即 UI=VM(State) ,當等式右邊State改變了,頁面展示部分UI就會發生相應改變。很多人初次上手Vue時,覺得很好用,原因就是這個。不過需要注意的是,Vue的核心定位并不是一個框架[3],設計上也沒有完全遵循MVVM模式,可以看到在圖中只有State和View兩部分, Vue的核心功能強調的是狀態到界面的映射,對于代碼的結構組織并不重視, 所以單純只使用其核心功能時,它并不是一個框架,而更像一個視圖模板引擎,這也是為什么Vue開發者把其命名成讀音類似于view的原因。
所謂“漸進式”
上文提到,Vue的核心的功能,是一個視圖模板引擎,但這不是說Vue就不能成為一個框架。如下圖所示,這里包含了Vue的所有部件,在聲明式渲染(視圖模板引擎)的基礎上,我們可以通過添加組件系統、客戶端路由、大規模狀態管理來構建一個完整的框架。更重要的是,這些功能相互獨立,你可以在核心功能的基礎上任意選用其他的部件,不一定要全部整合在一起。可以看到,所說的“漸進式”,其實就是Vue的使用方式,它可能有些方面是不如React,不如Angular,但它是漸進的,沒有強主張,你可以在原有大系統的上面,把一兩個組件改用它實現,當jQuery用;也可以整個用它全家桶開發,當Angular用;還可以用它的視圖,搭配你自己設計的整個下層用。你可以在底層數據邏輯的地方用OO和設計模式的那套理念,也可以函數式,都可以,它只是個輕量視圖而已,只做了自己該做的事,沒有做不該做的事,僅此而已。不干擾開發者的業務邏輯的思考方式。
漸進式的含義,我的理解是:沒有多做職責之外的事,主張最少。也就是“Progressive”——這個詞在英文中定義是漸進,一步一步,不是說你必須一竿子把所有的東西都用上。
有自己的配套工具,核心雖然只解決一個很小的問題(非常專注的只做狀態到界面映射,以及組件),但它們有生態圈及配套的可選工具,當你把他們一個一個加進來的時候,就可以組合成非常強大的棧,就可以涵蓋其他的這些更完整的框架所涵蓋的問題。
這樣的一個配置方案,使得在你構建技術棧的時候有可彈性伸縮的工具復雜度:當所要解決的問題內在復雜度很低的時候,可以只用核心的這些很簡單的功能;當需要做一個更復雜的應用時,再增添相應的工具。例如做一個單頁應用的時候才需要用路由;做一個相當龐大的應用,涉及到多組件狀態共享以及多個開發者共同協作時,才可能需要大規模狀態管理方案。
Vue.js 的優勢
- Vue.js 在可讀性、可維護性和趣味性之間做到了很好的平衡。Vue.js 處在 React 和 Angular 1 之間,而且如果你有仔細看 Vue 的指南,就會發現 Vue.js 從其它框架借鑒了很多設計理念。
- Vue.js 從 React 那里借鑒了組件化、prop、單向數據流、性能、虛擬渲染,并意識到狀態管理的重要性。
- Vue.js 從 Angular 那里借鑒了模板,并賦予了更好的語法,以及雙向數據綁定(在單個組件里)。
- 從我們團隊使用 Vue.js 的情況來看,Vue.js 使用起來很簡單。它不強制使用某種編譯器,所以你完全可以在遺留代碼里使用 Vue,并對之前亂糟糟的 jQuery 代碼進行改造。
vue特點:
- 核心只關注視圖(view)
- 易學,輕量,靈活
- 適用于移動端項目
- 漸進式框架
兩個核心點:?
1.響應的數據變化當數據發生變化----視圖自動更新2.組合的視圖組件UI頁面映射為組件樹劃分組件可維護、可復用、可測試虛擬DOM
Vue.js(2.0版本)使用了一種叫'Virtual DOM'的東西。所謂的Virtual DOM基本上說就是它名字的意思:虛擬DOM,DOM樹的虛擬表現。它的誕生是基于這么一個概念:改變真實的DOM狀態遠比改變一個JavaScript對象的花銷要大得多。
Virtual DOM是一個映射真實DOM的JavaScript對象,如果需要改變任何元素的狀態,那么是先在Virtual DOM上進行改變,而不是直接改變真實的DOM。當有變化產生時,一個新的Virtual DOM對象會被創建并計算新舊Virtual DOM之間的差別。之后這些差別會應用在真實的DOM上。·
例子如下,我們可以看看下面這個列表在HTML中的代碼是如何寫的:
<ul class="list"><li>item 1</li><li>item 2</li>
</ul>
而在JavaScript中,我們可以用對象簡單地創造一個針對上面例子的映射:
//code from http://caibaojian.com/vue-vs-react.html
{type: 'ul', props: {'class': 'list'}, children: [{ type: 'li', props: {}, children: ['item 1'] },{ type: 'li', props: {}, children: ['item 2'] }]
}真實的Virtual DOM會比上面的例子更復雜,但它本質上是一個嵌套著數組的原生對象。
當新一項被加進去這個JavaScript對象時,一個函數會計算新舊Virtual DOM之間的差異并反應在真實的DOM上。計算差異的算法是高性能框架的秘密所在,React和Vue在實現上有點不同。
Vue宣稱可以更快地計算出Virtual DOM的差異,這是由于它在渲染過程中,會跟蹤每一個組件的依賴關系,不需要重新渲染整個組件樹。
小結:如果你的應用中,交互復雜,需要處理大量的UI變化,那么使用Virtual DOM是一個好主意。如果你更新元素并不頻繁,那么Virtual DOM并不一定適用,性能很可能還不如直接操控DOM。
在學習中,我們沒必要一上來就搞懂Vue的每一個部件和功能,先從核心功能開始學習,逐漸擴展。 同時,在使用中,我們也沒有必要把全部件能都拿出來,需要什么用什么就是了,而且也可以把Vue很方便的與其它已有項目或框架相結合。
vue生命周期(鉤子函數)
beforeCreate、created(此時需說明可以在created中首次拿到data中定義的數據)、beforeMount、mounted(此時需說明dom樹渲染結束,可訪問dom結構)、beforeUpdate、updated、beforeDestroy、destroyed
computed中的getter和setter
很多情況,我問到這個問題的時候對方的回答都是vue的getter和setter、訂閱者模式之類的回答,我就會直接說問的并不是這個,而是computed,直接讓對方說computed平時怎么使用,很多時候得到的回答是computed的默認方式,只使用了其中的getter,就會繼續追問如果想要再把這個值設置回去要怎么做,當然一般會讓問到這個程度的這個問題他都答不上來了。
<!--直接復制的官網示例-->
computed: {fullName: {// getterget: function () {return this.firstName + ' ' + this.lastName},// setterset: function (newValue) {var names = newValue.split(' ')this.firstName = names[0]this.lastName = names[names.length - 1]}}
}v-for循環key的作用?
key的作用就可以給他一個標識,讓狀態跟著數據渲染。
所以一句話,key的作用主要是為了高效的更新虛擬DOM。另外vue中在使用相同標簽名元素的過渡切換時,也會使用到key屬性,其目的也是為了讓vue可以區分它們,否則vue只會替換其內部屬性而不會觸發過渡效果。
$nextTick
在下次 DOM 更新循環 結束之后執行延遲回調。在修改數據之后立即使用這個方法,獲取更新后的 DOM。(官網解釋)
解決的問題:有些時候在改變數據后立即要對dom進行操作,此時獲取到的dom仍是獲取到的是數據刷新前的dom,無法滿足需要,這個時候就用到了$nextTick。
$set
向響應式對象中添加一個屬性,并確保這個新屬性同樣是響應式的,且觸發視圖更新。它必須用于向響應式對象上添加新屬性,因為 Vue 無法探測普通的新增屬性 (比如 this.myObject.newProperty = 'hi')(官方示例)
我自己的理解就是,在vue中對一個對象內部進行一些修改時,vue沒有監聽到變化無法觸發視圖的更新,此時來使用$set來觸發更新,使視圖更新為最新的數據。
組件間的傳值
- provide / inject
這對選項需要一起使用,以允許一個祖先組件向其所有子孫后代注入一個依賴,不論組件層次有多深,并在起上下游關系成立的時間里始終生效。
- Vue.observable
讓一個對象可響應。Vue 內部會用它來處理 data 函數返回的對象。
返回的對象可以直接用于渲染函數和計算屬性內,并且會在發生改變時觸發相應的更新。也可以作為最小化的跨組件狀態存儲器,用于簡單的場景:
const state = Vue.observable({ count: 0 })const Demo = {render(h) {return h('button', {on: { click: () => { state.count++ }}}, `count is: ${state.count}`)}
}- $attrs
包含了父作用域中不作為 prop 被識別 (且獲取) 的特性綁定 (class 和 style 除外)。當一個組件沒有聲明任何 prop 時,這里會包含所有父作用域的綁定 (class 和 style 除外),并且可以通過 v-bind="$attrs" 傳入內部組件——在創建高級別的組件時非常有用。
- $listeners
包含了父作用域中的 (不含 .native 修飾器的) v-on 事件監聽器。它可以通過 v-on="$listeners" 傳入內部組件——在創建更高層次的組件時非常有用。
- props
- $emit
- eventbus
- vuex
- $parent / $children / ref
參考:Vue學習看這篇就夠?、Vue 2.0,漸進式前端解決方案-尤雨溪、?Vue2.0 中,“漸進式框架”和“自底向上增量開發的設計”這兩個概念是什么?-徐飛、一句話理解Vue核心內容、Vue與React兩個框架的區別和優勢對比、Vue2.0 v-for 中 :key 到底有什么用?
為什么要是用sass這些css預處理器
Sass(Syntactically Awesome Style Sheets)是一個相對新的編程語言,Sass為web前端開發而生,可以用它來定義一套新的語法規則和函數,以加強和提升CSS。通過這種新的編程語言,你可以使用最高效的方式,以少量的代碼創建復雜的設計。它改進并增強了CSS的能力,增加了變量,局部和函數這些特性。
優勢
- 易維護,更方便的定制?
- 對于一個大型或者稍微有規模的UI來說,如果需要替換下整體風格,或者是某個字體的像素值,比如我們經常會遇到panel,window以及portal共用一個背景色,這個時候按照常規的方式,我們需要一個個定位到元素使用的class,然后逐個替換,SASS提供了變量的方式,你可以把某個樣式作為一個變量,然后各個class引用這個變量即可,修改時,我們只需修改對應的變量。?
- 對于編程人員的友好?
- 對于一個沒有前端基礎的編程人員,寫css樣式是一件非常痛苦的事情,他們會感覺到各種約束,為什么我不能定一個變量來避免那些類似“變量”的重復書寫?為什么我不能繼承上個class的樣式定義?。。。SASS/SCSS正是幫編程人員解開了這些疑惑,讓css看起來更像是一門編程語言。?
- 效率的提升?
- 對于一個前端開發人員來說,我不熟悉編程,也不關注css是否具有的一些編程語言特性,但這不是你放棄他的理由,css3的發展,加之主流瀏覽器的兼容性不一,很多瀏覽器都有自己的兼容hack,很多時候我們需要針對不同的瀏覽器寫一堆的hack,這種浪費時間的重復勞動就交給SASS處理去吧!
如何防止XSS攻擊?
什么是XSS?
“XSS是跨站腳本攻擊(Cross Site Scripting),為不和層疊樣式表(Cascading Style Sheets, CSS)的縮寫混淆,故將跨站腳本攻擊縮寫為XSS。惡意攻擊者往Web頁面里插入惡意Script代碼,當用戶瀏覽該頁之時,嵌入其中Web里面的Script代碼會被執行,從而達到惡意攻擊用戶的目的(攻擊者可獲取用戶的敏感信息如 Cookie、SessionID、劫持流量實現惡意跳轉 等)。”(即頁面被注入了惡意代碼)
XSS 的本質是:惡意代碼未經過濾,與網站正常的代碼混在一起;瀏覽器無法分辨哪些腳本是可信的,導致惡意腳本被執行。
危害:
而由于直接在用戶的終端執行,惡意代碼能夠直接獲取用戶的信息,或者利用這些信息冒充用戶向網站發起攻擊者定義的請求。
XSS 有哪些注入的方法:
- 在 HTML 中內嵌的文本中,惡意內容以 script 標簽形成注入。
- 在內聯的 JavaScript 中,拼接的數據突破了原本的限制(字符串,變量,方法名等)。
- 在標簽屬性中,惡意內容包含引號,從而突破屬性值的限制,注入其他屬性或者標簽。
- 在標簽的 href、src 等屬性中,包含?
javascript:?等可執行代碼。 - 在 onload、onerror、onclick 等事件中,注入不受控制代碼。
- 在 style 屬性和標簽中,包含類似?
background-image:url("javascript:...");?的代碼(新版本瀏覽器已經可以防范)。 - 在 style 屬性和標簽中,包含類似?
expression(...)?的 CSS 表達式代碼(新版本瀏覽器已經可以防范)。
總之,如果開發者沒有將用戶輸入的文本進行合適的過濾,就貿然插入到 HTML 中,這很容易造成注入漏洞。攻擊者可以利用漏洞,構造出惡意的代碼指令,進而利用惡意代碼危害數據安全。(輸入過濾)
用戶是通過哪種方法“注入”惡意腳本的呢?
不僅僅是業務上的“用戶的 UGC 內容”可以進行注入,包括 URL 上的參數等都可以是攻擊的來源。在處理輸入時,以下內容都不可信:
- 來自用戶的 UGC 信息
- 來自第三方的鏈接
- URL 參數
- POST 參數
- Referer (可能來自不可信的來源)
- Cookie (可能來自其他子域注入)
XSS 分類
根據攻擊的來源,XSS 攻擊可分為存儲型、反射型和 DOM 型三種。
|類型|存儲區|插入點| |-|-|
|存儲型 XSS|后端數據庫|HTML|
|反射型 XSS|URL|HTML|
|DOM 型 XSS|后端數據庫/前端存儲/URL|前端 JavaScript|
- 存儲區:惡意代碼存放的位置。
- 插入點:由誰取得惡意代碼,并插入到網頁上。
存儲型 XSS
存儲型 XSS 的攻擊步驟:
- 攻擊者將惡意代碼提交到目標網站的數據庫中。
- 用戶打開目標網站時,網站服務端將惡意代碼從數據庫取出,拼接在 HTML 中返回給瀏覽器。
- 用戶瀏覽器接收到響應后解析執行,混在其中的惡意代碼也被執行。
- 惡意代碼竊取用戶數據并發送到攻擊者的網站,或者冒充用戶的行為,調用目標網站接口執行攻擊者指定的操作。
這種攻擊常見于帶有用戶保存數據的網站功能,如論壇發帖、商品評論、用戶私信等。
反射型 XSS
反射型 XSS 的攻擊步驟:
- 攻擊者構造出特殊的 URL,其中包含惡意代碼。
- 用戶打開帶有惡意代碼的 URL 時,網站服務端將惡意代碼從 URL 中取出,拼接在 HTML 中返回給瀏覽器。(郵件發送)
- 用戶瀏覽器接收到響應后解析執行,混在其中的惡意代碼也被執行。
- 惡意代碼竊取用戶數據并發送到攻擊者的網站,或者冒充用戶的行為,調用目標網站接口執行攻擊者指定的操作。
反射型 XSS 跟存儲型 XSS 的區別是:存儲型 XSS 的惡意代碼存在數據庫里,反射型 XSS 的惡意代碼存在 URL 里。
反射型 XSS 漏洞常見于通過 URL 傳遞參數的功能,如網站搜索、跳轉等。
由于需要用戶主動打開惡意的 URL 才能生效,攻擊者往往會結合多種手段誘導用戶點擊。
POST 的內容也可以觸發反射型 XSS,只不過其觸發條件比較苛刻(需要構造表單提交頁面,并引導用戶點擊),所以非常少見。
DOM 型 XSS
DOM 型 XSS 的攻擊步驟:
- 攻擊者構造出特殊的 URL,其中包含惡意代碼。
- 用戶打開帶有惡意代碼的 URL。
- 用戶瀏覽器接收到響應后解析執行,前端 JavaScript 取出 URL 中的惡意代碼并執行。(直接插入到頁面中)
- 惡意代碼竊取用戶數據并發送到攻擊者的網站,或者冒充用戶的行為,調用目標網站接口執行攻擊者指定的操作。
DOM 型 XSS 跟前兩種 XSS 的區別:DOM 型 XSS 攻擊中,取出和執行惡意代碼由瀏覽器端完成,屬于前端 JavaScript 自身的安全漏洞,而其他兩種 XSS 都屬于服務端的安全漏洞。
XSS 攻擊的預防
通過前面的介紹可以得知,XSS 攻擊有兩大要素:
- 攻擊者提交惡意代碼。
- 瀏覽器執行惡意代碼。
輸入過濾
在用戶提交時,由前端過濾輸入,然后提交到后端。這樣做是否可行呢?
答案是不可行。一旦攻擊者繞過前端過濾,直接構造請求,就可以提交惡意代碼了。
那么,換一個過濾時機:后端在寫入數據庫前,對輸入進行過濾,然后把“安全的”內容,返回給前端。這樣是否可行呢?
我們舉一個例子,一個正常的用戶輸入了?5 < 7?這個內容,在寫入數據庫前,被轉義,變成了?5 < 7。
問題是:在提交階段,我們并不確定內容要輸出到哪里。
這里的“并不確定內容要輸出到哪里”有兩層含義:
- 用戶的輸入內容可能同時提供給前端和客戶端,而一旦經過了?
escapeHTML(),客戶端顯示的內容就變成了亂碼(?5 < 7?)。 -
在前端中,不同的位置所需的編碼也不同。
? ? 當?<div title="comment">5 < 7</div>5 < 7?作為 HTML 拼接頁面時,可以正常顯示:
? ? ? ? ? ? ?當?5 < 7?通過 Ajax 返回,然后賦值給 JavaScript 的變量時,前端得到的字符串就是轉義后的字符。這個內容不能直接用于? ? ? ? ? ? ? ? ? ?Vue 等模板的展示,也不能直接用于內容長度計算。不能用于標題、alert 等。
所以,輸入側過濾能夠在某些情況下解決特定的 XSS 問題,但會引入很大的不確定性和亂碼問題。在防范 XSS 攻擊時應避免此類方法。
當然,對于明確的輸入類型,例如數字、URL、電話號碼、郵件地址等等內容,進行輸入過濾還是必要的。
既然輸入過濾并非完全可靠,我們就要通過“防止瀏覽器執行惡意代碼”來防范 XSS。這部分分為兩類:
- 防止 HTML 中出現注入。
- 防止 JavaScript 執行時,執行惡意代碼。(輸出轉義,HTML 的編碼是十分復雜的,在不同的上下文里要使用相應的轉義規則。)
預防存儲型和反射型 XSS 攻擊
存儲型和反射型 XSS 都是在服務端取出惡意代碼后,插入到響應 HTML 里的,攻擊者刻意編寫的“數據”被內嵌到“代碼”中,被瀏覽器所執行。
預防這兩種漏洞,有兩種常見做法:
- 改成純前端渲染,把代碼和數據分隔開。
- 對 HTML 做充分轉義。
純前端渲染
純前端渲染的過程:
- 瀏覽器先加載一個靜態 HTML,此 HTML 中不包含任何跟業務相關的數據。
- 然后瀏覽器執行 HTML 中的 JavaScript。
- JavaScript 通過 Ajax 加載業務數據,調用 DOM API 更新到頁面上。
在純前端渲染中,我們會明確的告訴瀏覽器:下面要設置的內容是文本(.innerText),還是屬性(.setAttribute),還是樣式(.style)等等。瀏覽器不會被輕易的被欺騙,執行預期外的代碼了。
但純前端渲染還需注意避免 DOM 型 XSS 漏洞(例如?onload?事件和?href?中的?javascript:xxx?等,請參考下文”預防 DOM 型 XSS 攻擊“部分)。
在很多內部、管理系統中,采用純前端渲染是非常合適的。但對于性能要求高,或有 SEO 需求的頁面,我們仍然要面對拼接 HTML 的問題。
轉義 HTML
如果拼接 HTML 是必要的,就需要采用合適的轉義庫,對 HTML 模板各處插入點進行充分的轉義。
常用的模板引擎,如 doT.js、ejs、FreeMarker 等,對于 HTML 轉義通常只有一個規則,就是把?& < > " ' /?這幾個字符轉義掉,確實能起到一定的 XSS 防護作用,但并不完善:
|XSS 安全漏洞|簡單轉義是否有防護作用| |-|-| |HTML 標簽文字內容|有| |HTML 屬性值|有| |CSS 內聯樣式|無| |內聯 JavaScript|無| |內聯 JSON|無| |跳轉鏈接|無|
所以要完善 XSS 防護措施,我們要使用更完善更細致的轉義策略。
預防 DOM 型 XSS 攻擊
DOM 型 XSS 攻擊,實際上就是網站前端 JavaScript 代碼本身不夠嚴謹,把不可信的數據當作代碼執行了。
在使用?.innerHTML、.outerHTML、document.write()?時要特別小心,不要把不可信的數據作為 HTML 插到頁面上,而應盡量使用?.textContent、.setAttribute()?等。
如果用 Vue/React 技術棧,并且不使用?v-html/dangerouslySetInnerHTML?功能,就在前端 render 階段避免?innerHTML、outerHTML?的 XSS 隱患。
DOM 中的內聯事件監聽器,如?location、onclick、onerror、onload、onmouseover?等,<a>?標簽的?href?屬性,JavaScript 的?eval()、setTimeout()、setInterval()?等,都能把字符串作為代碼運行。如果不可信的數據拼接到字符串中傳遞給這些 API,很容易產生安全隱患,請務必避免。
注意:
- 防范存儲型和反射型 XSS 是后端 RD 的責任。而 DOM 型 XSS 攻擊不發生在后端,是前端 RD 的責任。防范 XSS 是需要后端 RD 和前端 RD 共同參與的系統工程。 * 轉義應該在輸出 HTML 時進行,而不是在提交用戶輸入時。
- 不同的上下文,如 HTML 屬性、HTML 文字內容、HTML 注釋、跳轉鏈接、內聯 JavaScript 字符串、內聯 CSS 樣式表等,所需要的轉義規則不一致。 業務 RD 需要選取合適的轉義庫,并針對不同的上下文調用不同的轉義規則。
雖然很難通過技術手段完全避免 XSS,但我們可以總結以下原則減少漏洞的產生:
- 利用模板引擎?開啟模板引擎自帶的 HTML 轉義功能。例如: 在 ejs 中,盡量使用?
<%= data %>?而不是?<%- data %>; 在 doT.js 中,盡量使用?{{! data }?而不是?{{= data }; 在 FreeMarker 中,確保引擎版本高于 2.3.24,并且選擇正確的?freemarker.core.OutputFormat。 - 避免內聯事件?盡量不要使用?
onLoad="onload('{{data}}')"、onClick="go('{{action}}')"?這種拼接內聯事件的寫法。在 JavaScript 中通過?.addEventlistener()?事件綁定會更安全。 - 避免拼接 HTML?前端采用拼接 HTML 的方法比較危險,如果框架允許,使用?
createElement、setAttribute?之類的方法實現。或者采用比較成熟的渲染框架,如 Vue/React 等。 - 時刻保持警惕?在插入位置為 DOM 屬性、鏈接等位置時,要打起精神,嚴加防范。
- 增加攻擊難度,降低攻擊后果?通過 CSP、輸入長度配置、接口安全措施等方法,增加攻擊的難度,降低攻擊的后果。
- 主動檢測和發現?可使用 XSS 攻擊字符串和自動掃描工具尋找潛在的 XSS 漏洞
參考:前端安全系列(一):如何防止XSS攻擊?、實現基于 Nuxt.js 的 SSR 應用(SEO、SPA、SSR、首屏渲染、Nuxt.js)
跨域
什么是同源策略及其限制內容
同源策略是一種約定,它是瀏覽器最核心也最基本的安全功能,如果缺少了同源策略,瀏覽器很容易受到XSS、CSRF等攻擊。所謂同源是指"協議+域名+端口"三者相同,即便兩個不同的域名指向同一個ip地址,也非同源。
同源策略限制內容有:
- Cookie、LocalStorage、IndexedDB 等存儲性內容
- DOM 節點
- AJAX 請求發送后,結果被瀏覽器攔截了
但是有三個標簽是允許跨域加載資源:
<img src=XXX><link href=XXX><script src=XXX>
當協議、子域名、主域名、端口號中任意一個不相同時,都算作不同域。
跨域解決方案
1.jsonp
1) JSONP原理
利用 <script> 標簽沒有跨域限制的漏洞,網頁可以得到從其他來源動態產生的 JSON 數據。JSONP請求一定需要對方的服務器做支持才可以。
2) JSONP和AJAX對比
JSONP和AJAX相同,都是客戶端向服務器端發送請求,從服務器端獲取數據的方式。但AJAX屬于同源策略,JSONP屬于非同源策略(跨域請求)
3) JSONP優缺點
JSONP優點是簡單兼容性好,可用于解決主流瀏覽器的跨域數據訪問的問題。缺點是僅支持get方法具有局限性,不安全可能會遭受XSS攻擊。
4) JSONP的實現流程
- 聲明一個回調函數,其函數名(如show)當做參數值,要傳遞給跨域請求數據的服務器,函數形參為要獲取目標數據(服務器返回的data)。
- 創建一個
<script>標簽,把那個跨域的API數據接口地址,賦值給script的src,還要在這個地址中向服務器傳遞該函數名(可以通過問號傳參:?callback=show)。 - 服務器接收到請求后,需要進行特殊的處理:把傳遞進來的函數名和它需要給你的數據拼接成一個字符串,例如:傳遞進去的函數名是show,它準備好的數據是
show('我不愛你')。 - 最后服務器把準備的數據通過HTTP協議返回給客戶端,客戶端再調用執行之前聲明的回調函數(show),對返回的數據進行操作。
在開發中可能會遇到多個 JSONP 請求的回調函數名是相同的,這時候就需要自己封裝一個 JSONP函數。
// index.html
function jsonp({ url, params, callback }) {return new Promise((resolve, reject) => {let script = document.createElement('script')window[callback] = function(data) {resolve(data)document.body.removeChild(script)}params = { ...params, callback } // wd=b&callback=showlet arrs = []for (let key in params) {arrs.push(`${key}=${params[key]}`)}script.src = `${url}?${arrs.join('&')}`document.body.appendChild(script)})
}
jsonp({url: 'http://localhost:3000/say',params: { wd: 'Iloveyou' },callback: 'show'
}).then(data => {console.log(data)
})
復制代碼上面這段代碼相當于向http://localhost:3000/say?wd=Iloveyou&callback=show這個地址請求數據,然后后臺返回show('我不愛你'),最后會運行show()這個函數,打印出'我不愛你'
// server.js
let express = require('express')
let app = express()
app.get('/say', function(req, res) {let { wd, callback } = req.queryconsole.log(wd) // Iloveyouconsole.log(callback) // showres.end(`${callback}('我不愛你')`)
})
app.listen(3000)2.CORS?
全稱是"跨域資源共享"(Cross-origin resource sharing)。它允許瀏覽器向跨源服務器,發出XMLHttpRequest請求,從而克服了AJAX只能同源使用的限制。
CORS 需要瀏覽器和后端同時支持。IE 8 和 9 需要通過 XDomainRequest 來實現。
CORS需要瀏覽器和服務器同時支持。目前,所有瀏覽器都支持該功能,IE瀏覽器不能低于IE10。
整個CORS通信過程,都是瀏覽器自動完成,不需要用戶參與。對于開發者來說,CORS通信與同源的AJAX通信沒有差別,代碼完全一樣。瀏覽器一旦發現AJAX請求跨源,就會自動添加一些附加的頭信息,有時還會多出一次附加的請求,但用戶不會有感覺。
因此,實現CORS通信的關鍵是服務器。只要服務器實現了CORS接口,就可以跨源通信。
兩種請求
瀏覽器將CORS請求分成兩類:簡單請求(simple request)和非簡單請求(not-so-simple request)。
只要同時滿足以下兩大條件,就屬于簡單請求。
(1) 請求方法是以下三種方法之一:
- HEAD
- GET
- POST
(2)HTTP的頭信息不超出以下幾種字段:
- Accept
- Accept-Language
- Content-Language
- Last-Event-ID
- Content-Type:只限于三個值
application/x-www-form-urlencoded、multipart/form-data、text/plain
凡是不同時滿足上面兩個條件,就屬于非簡單請求。
瀏覽器對這兩種請求的處理,是不一樣的。
簡單請求
對于簡單請求,瀏覽器直接發出CORS請求。具體來說,就是在頭信息之中,增加一個Origin字段。
下面是一個例子,瀏覽器發現這次跨源AJAX請求是簡單請求,就自動在頭信息之中,添加一個Origin字段。
GET /cors HTTP/1.1 Origin: http://api.bob.com Host: api.alice.com Accept-Language: en-US Connection: keep-alive User-Agent: Mozilla/5.0...
上面的頭信息中,Origin字段用來說明,本次請求來自哪個源(協議 + 域名 + 端口)。服務器根據這個值,決定是否同意這次請求。
如果Origin指定的源,不在許可范圍內,服務器會返回一個正常的HTTP回應。瀏覽器發現,這個回應的頭信息沒有包含Access-Control-Allow-Origin字段(詳見下文),就知道出錯了,從而拋出一個錯誤,被XMLHttpRequest的onerror回調函數捕獲。注意,這種錯誤無法通過狀態碼識別,因為HTTP回應的狀態碼有可能是200。
如果Origin指定的域名在許可范圍內,服務器返回的響應,會多出幾個頭信息字段。
Access-Control-Allow-Origin: http://api.bob.com Access-Control-Allow-Credentials: true Access-Control-Expose-Headers: FooBar Content-Type: text/html; charset=utf-8
上面的頭信息之中,有三個與CORS請求相關的字段,都以Access-Control-開頭。
(1)Access-Control-Allow-Origin
該字段是必須的。它的值要么是請求時Origin字段的值,要么是一個*,表示接受任意域名的請求。
(2)Access-Control-Allow-Credentials
該字段可選。它的值是一個布爾值,表示是否允許發送Cookie。默認情況下,Cookie不包括在CORS請求之中。設為true,即表示服務器明確許可,Cookie可以包含在請求中,一起發給服務器。這個值也只能設為true,如果服務器不要瀏覽器發送Cookie,刪除該字段即可。
(3)Access-Control-Expose-Headers
該字段可選。CORS請求時,XMLHttpRequest對象的getResponseHeader()方法只能拿到6個基本字段:Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma。如果想拿到其他字段,就必須在Access-Control-Expose-Headers里面指定。上面的例子指定,getResponseHeader('FooBar')可以返回FooBar字段的值。
CORS請求默認不發送Cookie和HTTP認證信息。如果要把Cookie發到服務器,一方面要服務器同意,指定Access-Control-Allow-Credentials字段。
Access-Control-Allow-Credentials: true
另一方面,開發者必須在AJAX請求中打開withCredentials屬性。
var xhr = new XMLHttpRequest(); xhr.withCredentials = true;
否則,即使服務器同意發送Cookie,瀏覽器也不會發送。或者,服務器要求設置Cookie,瀏覽器也不會處理。
但是,如果省略withCredentials設置,有的瀏覽器還是會一起發送Cookie。這時,可以顯式關閉withCredentials。
xhr.withCredentials = false;
需要注意的是,如果要發送Cookie,Access-Control-Allow-Origin就不能設為星號,必須指定明確的、與請求網頁一致的域名。同時,Cookie依然遵循同源政策,只有用服務器域名設置的Cookie才會上傳,其他域名的Cookie并不會上傳,且(跨源)原網頁代碼中的document.cookie也無法讀取服務器域名下的Cookie。
非簡單請求
預檢請求
非簡單請求是那種對服務器有特殊要求的請求,比如請求方法是PUT或DELETE,或者Content-Type字段的類型是application/json。
非簡單請求的CORS請求,會在正式通信之前,增加一次HTTP查詢請求,稱為"預檢"請求(preflight)。
瀏覽器先詢問服務器,當前網頁所在的域名是否在服務器的許可名單之中,以及可以使用哪些HTTP動詞和頭信息字段。只有得到肯定答復,瀏覽器才會發出正式的XMLHttpRequest請求,否則就報錯。
下面是一段瀏覽器的JavaScript腳本。
var url = 'http://api.alice.com/cors'; var xhr = new XMLHttpRequest(); xhr.open('PUT', url, true); xhr.setRequestHeader('X-Custom-Header', 'value'); xhr.send();
上面代碼中,HTTP請求的方法是PUT,并且發送一個自定義頭信息X-Custom-Header。
瀏覽器發現,這是一個非簡單請求,就自動發出一個"預檢"請求,要求服務器確認可以這樣請求。下面是這個"預檢"請求的HTTP頭信息。
OPTIONS /cors HTTP/1.1 Origin: http://api.bob.com Access-Control-Request-Method: PUT Access-Control-Request-Headers: X-Custom-Header Host: api.alice.com Accept-Language: en-US Connection: keep-alive User-Agent: Mozilla/5.0...
"預檢"請求用的請求方法是OPTIONS,表示這個請求是用來詢問的。頭信息里面,關鍵字段是Origin,表示請求來自哪個源。
除了Origin字段,"預檢"請求的頭信息包括兩個特殊字段。
(1)Access-Control-Request-Method
該字段是必須的,用來列出瀏覽器的CORS請求會用到哪些HTTP方法,上例是PUT。
(2)Access-Control-Request-Headers
該字段是一個逗號分隔的字符串,指定瀏覽器CORS請求會額外發送的頭信息字段,上例是X-Custom-Header
服務器收到"預檢"請求以后,檢查了Origin、Access-Control-Request-Method和Access-Control-Request-Headers字段以后,確認允許跨源請求,就可以做出回應。
HTTP/1.1 200 OK Date: Mon, 01 Dec 2008 01:15:39 GMT Server: Apache/2.0.61 (Unix) Access-Control-Allow-Origin: http://api.bob.com Access-Control-Allow-Methods: GET, POST, PUT Access-Control-Allow-Headers: X-Custom-Header Content-Type: text/html; charset=utf-8 Content-Encoding: gzip Content-Length: 0 Keep-Alive: timeout=2, max=100 Connection: Keep-Alive Content-Type: text/plain
上面的HTTP回應中,關鍵的是Access-Control-Allow-Origin字段,表示http://api.bob.com可以請求數據。該字段也可以設為星號,表示同意任意跨源請求。
Access-Control-Allow-Origin: *
如果瀏覽器否定了"預檢"請求,會返回一個正常的HTTP回應,但是沒有任何CORS相關的頭信息字段。這時,瀏覽器就會認定,服務器不同意預檢請求,因此觸發一個錯誤,被XMLHttpRequest對象的onerror回調函數捕獲。控制臺會打印出如下的報錯信息。
XMLHttpRequest cannot load http://api.alice.com. Origin http://api.bob.com is not allowed by Access-Control-Allow-Origin.
服務器回應的其他CORS相關字段如下。
Access-Control-Allow-Methods: GET, POST, PUT Access-Control-Allow-Headers: X-Custom-Header Access-Control-Allow-Credentials: true Access-Control-Max-Age: 1728000
(1)Access-Control-Allow-Methods
該字段必需,它的值是逗號分隔的一個字符串,表明服務器支持的所有跨域請求的方法。注意,返回的是所有支持的方法,而不單是瀏覽器請求的那個方法。這是為了避免多次"預檢"請求。
(2)Access-Control-Allow-Headers
如果瀏覽器請求包括Access-Control-Request-Headers字段,則Access-Control-Allow-Headers字段是必需的。它也是一個逗號分隔的字符串,表明服務器支持的所有頭信息字段,不限于瀏覽器在"預檢"中請求的字段。
(3)Access-Control-Allow-Credentials
該字段與簡單請求時的含義相同。
(4)Access-Control-Max-Age
該字段可選,用來指定本次預檢請求的有效期,單位為秒。上面結果中,有效期是20天(1728000秒),即允許緩存該條回應1728000秒(即20天),在此期間,不用發出另一條預檢請求。
瀏覽器的正常請求和回應
一旦服務器通過了"預檢"請求,以后每次瀏覽器正常的CORS請求,就都跟簡單請求一樣,會有一個Origin頭信息字段。服務器的回應,也都會有一個Access-Control-Allow-Origin頭信息字段。
下面是"預檢"請求之后,瀏覽器的正常CORS請求。
PUT /cors HTTP/1.1 Origin: http://api.bob.com Host: api.alice.com X-Custom-Header: value Accept-Language: en-US Connection: keep-alive User-Agent: Mozilla/5.0...
上面頭信息的Origin字段是瀏覽器自動添加的。
下面是服務器正常的回應。
Access-Control-Allow-Origin: http://api.bob.com Content-Type: text/html; charset=utf-8
上面頭信息中,Access-Control-Allow-Origin字段是每次回應都必定包含的。
與JSONP的比較
CORS與JSONP的使用目的相同,但是比JSONP更強大。
JSONP只支持GET請求,CORS支持所有類型的HTTP請求。JSONP的優勢在于支持老式瀏覽器,以及可以向不支持CORS的網站請求數據。
參考:跨域資源共享 CORS 詳解
3.postMessage
postMessage是HTML5 XMLHttpRequest Level 2中的API,且是為數不多可以跨域操作的window屬性之一(所以雙方都需要在瀏覽器端才能相互跨域連接?),它可用于解決以下方面的問題:
- 頁面和其打開的新窗口的數據傳遞
- 多窗口之間消息傳遞
- 頁面與嵌套的iframe消息傳遞
- 上面三個場景的跨域數據傳遞
postMessage()方法允許來自不同源的腳本采用異步方式進行有限的通信,可以實現跨文本檔、多窗口、跨域消息傳遞。
otherWindow.postMessage(message, targetOrigin, [transfer]);
- message: 將要發送到其他 window的數據。
- targetOrigin:通過窗口的origin屬性來指定哪些窗口能接收到消息事件,其值可以是字符串"*"(表示無限制)或者一個URI。在發送消息的時候,如果目標窗口的協議、主機地址或端口這三者的任意一項不匹配targetOrigin提供的值,那么消息就不會被發送;只有三者完全匹配,消息才會被發送。
- transfer(可選):是一串和message 同時傳遞的 Transferable 對象. 這些對象的所有權將被轉移給消息的接收方,而發送一方將不再保有所有權。
接下來我們看個例子: http://localhost:3000/a.html頁面向http://localhost:4000/b.html傳遞“我愛你”,然后后者傳回"我不愛你"。
// a.html<iframe src="http://localhost:4000/b.html" frameborder="0" id="frame" onload="load()"></iframe> //等它加載完觸發一個事件//內嵌在http://localhost:3000/a.html<script>function load() {let frame = document.getElementById('frame')frame.contentWindow.postMessage('我愛你', 'http://localhost:4000') //發送數據window.onmessage = function(e) { //接受返回數據console.log(e.data) //我不愛你}}</script>
復制代碼// b.htmlwindow.onmessage = function(e) {console.log(e.data) //我愛你e.source.postMessage('我不愛你', e.origin)}
復制代碼4.websocket
Websocket是HTML5的一個持久化的協議,它實現了瀏覽器與服務器的全雙工通信,同時也是跨域的一種解決方案。WebSocket和HTTP都是應用層協議,都基于 TCP 協議。但是 WebSocket 是一種雙向通信協議,在建立連接之后,WebSocket 的 server 與 client 都能主動向對方發送或接收數據。同時,WebSocket 在建立連接時需要借助 HTTP 協議,連接建立好了之后 client 與 server 之間的雙向通信就與 HTTP 無關了。
原生WebSocket API使用起來不太方便,我們使用Socket.io,它很好地封裝了webSocket接口,提供了更簡單、靈活的接口,也對不支持webSocket的瀏覽器提供了向下兼容。
我們先來看個例子:本地文件socket.html向localhost:3000發生數據和接受數據
// socket.html
<script>let socket = new WebSocket('ws://localhost:3000');socket.onopen = function () {socket.send('我愛你');//向服務器發送數據}socket.onmessage = function (e) {console.log(e.data);//接收服務器返回的數據}
</script>
復制代碼// server.js
let express = require('express');
let app = express();
let WebSocket = require('ws');//記得安裝ws
let wss = new WebSocket.Server({port:3000});
wss.on('connection',function(ws) {ws.on('message', function (data) {console.log(data);ws.send('我不愛你')});
})
復制代碼5. Node中間件代理(兩次跨域)
實現原理:同源策略是瀏覽器需要遵循的標準,而如果是服務器向服務器請求就無需遵循同源策略。代理服務器,需要做以下幾個步驟:
- 接受客戶端請求 。
- 將請求 轉發給服務器。
- 拿到服務器 響應 數據。
- 將響應轉發給客戶端。
我們先來看個例子:本地文件index.html文件,通過代理服務器http://localhost:3000向目標服務器http://localhost:4000請求數據。
// index.html(http://127.0.0.1:5500)<script src="https://cdn.bootcss.com/jquery/3.3.1/jquery.min.js"></script><script>$.ajax({url: 'http://localhost:3000',type: 'post',data: { name: 'xiamen', password: '123456' },contentType: 'application/json;charset=utf-8',success: function(result) {console.log(result) // {"title":"fontend","password":"123456"}},error: function(msg) {console.log(msg)}})</script>
復制代碼// server1.js 代理服務器(http://localhost:3000)
const http = require('http')
// 第一步:接受客戶端請求
const server = http.createServer((request, response) => {// 代理服務器,直接和瀏覽器直接交互,需要設置CORS 的首部字段response.writeHead(200, {'Access-Control-Allow-Origin': '*','Access-Control-Allow-Methods': '*','Access-Control-Allow-Headers': 'Content-Type'})// 第二步:將請求轉發給服務器const proxyRequest = http.request({host: '127.0.0.1',port: 4000,url: '/',method: request.method,headers: request.headers},serverResponse => {// 第三步:收到服務器的響應var body = ''serverResponse.on('data', chunk => {body += chunk})serverResponse.on('end', () => {console.log('The data is ' + body)// 第四步:將響應結果轉發給瀏覽器response.end(body)})}).end()
})
server.listen(3000, () => {console.log('The proxyServer is running at http://localhost:3000')
})
復制代碼// server2.js(http://localhost:4000)
const http = require('http')
const data = { title: 'fontend', password: '123456' }
const server = http.createServer((request, response) => {if (request.url === '/') {response.end(JSON.stringify(data))}
})
server.listen(4000, () => {console.log('The server is running at http://localhost:4000')
})
復制代碼上述代碼經過兩次跨域,值得注意的是瀏覽器向代理服務器發送請求,也遵循同源策略,最后在index.html文件打印出{"title":"fontend","password":"123456"}
6.nginx反向代理
實現原理類似于Node中間件代理,需要你搭建一個中轉nginx服務器,用于轉發請求。
使用nginx反向代理實現跨域,是最簡單的跨域方式。只需要修改nginx的配置即可解決跨域問題,支持所有瀏覽器,支持session,不需要修改任何代碼,并且不會影響服務器性能。
實現思路:通過nginx配置一個代理服務器(域名與domain1相同,端口不同)做跳板機,反向代理訪問domain2接口,并且可以順便修改cookie中domain信息,方便當前域cookie寫入,實現跨域登錄。
7.window.name + iframe
window.name屬性的獨特之處:name值在不同的頁面(甚至不同域名)加載后依舊存在,并且可以支持非常長的 name 值(2MB)。
其中a.html和b.html是同域的,都是http://localhost:3000;而c.html是http://localhost:4000
// a.html(http://localhost:3000/b.html)<iframe src="http://localhost:4000/c.html" frameborder="0" onload="load()" id="iframe"></iframe><script>let first = true// onload事件會觸發2次,第1次加載跨域頁,并留存數據于window.namefunction load() {if(first){// 第1次onload(跨域頁)成功后,切換到同域代理頁面let iframe = document.getElementById('iframe');iframe.src = 'http://localhost:3000/b.html';first = false;}else{// 第2次onload(同域b.html頁)成功后,讀取同域window.name中數據console.log(iframe.contentWindow.name);}}</script>
復制代碼b.html為中間代理頁,與a.html同域,內容為空。
// c.html(http://localhost:4000/c.html)<script>window.name = '我不愛你' </script>
復制代碼總結:通過iframe的src屬性由外域轉向本地域,跨域數據即由iframe的window.name從外域傳遞到本地域。這個就巧妙地繞過了瀏覽器的跨域訪問限制,但同時它又是安全操作。
8.location.hash + iframe
實現原理: a.html欲與c.html跨域相互通信,通過中間頁b.html來實現。 三個頁面,不同域之間利用iframe的location.hash傳值,相同域之間直接js訪問來通信。
具體實現步驟:一開始a.html給c.html傳一個hash值,然后c.html收到hash值后,再把hash值傳遞給b.html,最后b.html將結果放到a.html的hash值中。 同樣的,a.html和b.html是同域的,都是http://localhost:3000;而c.html是http://localhost:4000
// a.html<iframe src="http://localhost:4000/c.html#iloveyou"></iframe><script>window.onhashchange = function () { //檢測hash的變化console.log(location.hash);}</script>
復制代碼 // b.html<script>window.parent.parent.location.hash = location.hash //b.html將結果放到a.html的hash值中,b.html可通過parent.parent訪問a.html頁面</script>
復制代碼 // c.htmlconsole.log(location.hash);let iframe = document.createElement('iframe');iframe.src = 'http://localhost:3000/b.html#idontloveyou';document.body.appendChild(iframe);
復制代碼9.document.domain + iframe
該方式只能用于二級域名相同的情況下,比如 a.test.com 和 b.test.com 適用于該方式。 只需要給頁面添加 document.domain ='test.com' 表示二級域名都相同就可以實現跨域。
實現原理:兩個頁面都通過js強制設置document.domain為基礎主域,就實現了同域。
我們看個例子:頁面a.zf1.cn:3000/a.html獲取頁面b.zf1.cn:3000/b.html中a的值
// a.html
<body>helloa<iframe src="http://b.zf1.cn:3000/b.html" frameborder="0" onload="load()" id="frame"></iframe><script>document.domain = 'zf1.cn'function load() {console.log(frame.contentWindow.a);}</script>
</body>
復制代碼// b.html
<body>hellob<script>document.domain = 'zf1.cn'var a = 100;</script>
</body>
復制代碼三、總結
- CORS支持所有類型的HTTP請求,是跨域HTTP請求的根本解決方案
- JSONP只支持GET請求,JSONP的優勢在于支持老式瀏覽器,以及可以向不支持CORS的網站請求數據。
- 不管是Node中間件代理還是nginx反向代理,主要是通過同源策略對服務器不加限制。
- 日常工作中,用得比較多的跨域方案是cors和nginx反向代理
參考:九種跨域方式實現原理(完整版)?
web語義化
分為html語義化、css語義化和url語義化
1)HTML語義化——使用恰當的標簽結構來規范內容,使有利于開發人員以及屏幕閱讀器(訪客有視障)以及SEO讀懂和識別
<html><body><article><header><h1>h1 - WEB 語義化</h1></header><nav><ul><li>nav1 - HTML語義化</li><li>nav2 - CSS語義化</li></ul></nav><section>section1 - HTML語義化</section><section>section2 - CSS語義化</section><time datetime="2018-03-23" pubdate>time - 2018年03月23日</time><footer> footer - by 小維</footer></article></body>
</html>
- header代表“網頁”或者“section”的頁眉,通常包含h1-h6 元素或者 hgroup, 作為整個頁面或者一個內容快的標題。
hgroup?元素代表“網頁”或“section”的標題組,當元素有多個層級時,該元素可以將h1到h6元素放在其內,譬如文章的主標題和副標題組合footer元素代表“網頁”或任意“section”的頁腳- nav 元素代表頁面的導航鏈接區域。用于定義頁面的主要導航部分。
- article 代表一個在文檔,頁面或者網站中自成一體的內容,其目的是為了讓開發者獨立開發或重用。
文章內section是獨立的部分,但是它們只能算是組成整體的一部分,從屬關系,article是大主體,section是構成這個大主體的一個部分。
注意事項:
·自身獨立情況下:用article
·是相關內容: 用section
·沒有語義的: 用div
section?元素代表文檔中的“節”或“段”,“段”可以是指一片文章里按照主題的分段;“節”可以是指一個頁面里的分組。section通常還帶標題,雖然html5中section會自動給標題h1-h6降級,但是最好手動給他們降級。aside?元素被包含在article元素中作為主要內容的附屬信息部分,其中的內容可以是與當前文章有關的相關資料,標簽,名詞解釋等。
在article元素之外使用作為頁面或站點全局的附屬信息部分。最典型的是側邊欄,其中的內容可以是日志串連,其他組的導航,甚至廣告,這些內容相關的頁面。
aside 在 article 內表示主要內容的附屬信息。
在article之外側可以做側邊欄,沒有article與之對應,最好不用
如果是廣告,其他日志鏈接或者其他分類導航也可以用。
- figure元素包含圖像、圖表和照片。figure標記可以包含figcaption,figcaption表示圖像對應的描述文字,與圖片產生對應關系。
<figure><img src="/figure.jpg" width="304" height="228" alt="Picture"><figcaption>Caption for the figure</figcaption>
</figure>
- 一些常用的媒體元素包含:audio/video/source/embed
<audio id="audioPlay"><source src="../h5/music/act/iphonewx/shakeshake.mp3" type="audio/mpeg">您的瀏覽器不支持 audio 標簽。
</audio>
總之,HTML語義化是反對大篇幅使用無語義化的div+span+class,而鼓勵使用HTML定義好的語義化標簽。
當然,如果需要兼容低版本的IE瀏覽器,比如說IE8以及以下,那就需要考慮一些HTML5標簽兼容性解決方案了。
2)css語義化——就是class和id命名的規范,如果說HTML語義化標簽是給機器看的,那么CSS命名的語義化就是給人看的。良好的CSS命名方式減少溝通調試成本,易于理解。
- 看到這里,問題來了。既然CSS class和ID命名的語義化可以便于閱讀理解和減少溝通調試成本,那么我們是不是可以用div 結合class和ID語義化命名的方式來代替html的語義化?
- 從代碼的層面上來看,使用CSS class語義化的命名也是能夠便于閱讀和維護的,但是這樣子并不利于SEO和屏幕閱讀器識別
3)URL語義化——可以使得搜索引擎或者爬蟲更好的理解·當前URL所在目錄所要表達的意思,而對于用戶來說,通過url也可以判斷上一級目錄或者下一級目錄想要表示的內容,可以提高用戶體驗。
例如我司的搜索品類的url:
url語義化可以從以下標準來衡量:
- url簡化,規范化:url里的名詞如果包含兩個單詞,那么就用下劃線_ 連接。
- 結構化,語義化:此處的品類搜索我們用語義化單詞category表示
- 采用技術無關的url:第一個鏈接中的index.php這種就不應該出現在用戶側的url里。
參考:如何理解Web語義化、HTML 5的革新之一:語義化標簽一節元素標簽
HTML 5的革新——語義化標簽(二)
nodeJS
什么是nodeJS
三個特性:
- 服務器端JavaScript處理:server-side JavaScript execution
- 非阻斷/異步I/O:non-blocking or asynchronous I/O
- 事件驅動:Event-driven
簡單的說 Node.js 就是運行在服務端的 JavaScript。
Node.js是一個基于ChromeV8引擎的JavaScript運行環境。Node.js使用了一個事件驅動、非阻塞式I/O的模型,使其輕量又高效。
為什么是js
JavaScript 是一個單線程的語言,單線程的優點是不會像 Java 這些多線程語言在編程時出現線程同步、線程鎖問題同時也避免了上下文切換帶來的性能開銷問題,那么其實在瀏覽器環境也只能是單線程,可以想象一下多線程對同一個 DOM 進行操作是什么場景?不是亂套了嗎?那么單線程可能你會想到的一個問題是,前面一個執行不完,后面不就卡住了嗎?當然不能這樣子的,JavaScript 是一種采用了事件驅動、異步回調的模式,另外 JavaScript 在服務端不存在什么歷史包袱,在虛擬機上由于又有了 Chrome V8 的支持,使得 JavaScript 成為了 Node.js 的首選語言。
Node.js 架構
Node.js 由 Libuv、Chrome V8、一些核心 API 構成,如下圖所示:
以上展示了 Node.js 的構成,下面做下簡單說明:
- Node Standard Library:Node.js 標準庫,對外提供的 JavaScript 接口,例如模塊 http、buffer、fs、stream 等
- Node bindings:這里就是 JavaScript 與 C++ 連接的橋梁,對下層模塊進行封裝,向上層提供基礎的 API 接口。
- V8:Google 開源的高性能 JavaScript 引擎,使用 C++ 開發,并且應用于谷歌瀏覽器。如果您感興趣想學習更多的 V8 引擎知識,請訪問?What is V8?
- Libuv:是一個跨平臺的支持事件驅動的 I/O 庫。它是使用 C 和 C++ 語言為 Node.js 所開發的,同時也是 I/O 操作的核心部分,例如讀取文件和 OS 交互。來自一份?Libuv 的中文教程
- C-ares:C-ares 是一個異步 DNS 解析庫
- Low-Level Components:提供了 http 解析、OpenSSL、數據壓縮(zlib)等功能。
Node.js 特點
在這之前不知道您有沒有聽說過,Node.js 很擅長 I/O 密集型任務,應對一些 I/O 密集型的高并發場景還是很有優勢的,事實也如此,這也是它的定位:提供一種簡單安全的方法在 JavaScript 中構建高性能和可擴展的網絡應用程序。
- 單線程
Node.js 使用單線程來運行,而不是向 Apache HTTP 之類的其它服務器,每個請求將生產一個線程,這種方法避免了 CPU 上下文切換和內存中的大量執行堆棧,這也是 Nginx 和其它服務器為解決 “上一個 10 年,著名的 C10K 并發連接問題” 而采用的方法。
- 非阻塞 I/O
Node.js 避免了由于需要等待輸入或者輸出(數據庫、文件系統、Web服務器…)響應而造成的 CPU 時間損失,這得益于 Libuv 強大的異步 I/O。
- 事件驅動編程
事件與回調在 JavaScript 中已是屢見不鮮,同時這種編程對于習慣同步思路的同學來說可能一時很難理解,但是這種編程模式,確是一種高性能的服務模型。Node.js 與 Nginx 均是基于事件驅動的方式實現,不同之處在于 Nginx 采用純 C 進行編寫,僅適用于 Web 服務器,在業務處理方面 Node.js 則是一個可擴展、高性能的平臺。
- 跨平臺
起初 Node.js 只能運行于 Linux 平臺,在 v0.6.0 版本后得益于 Libuv 的支持可以在 Windows 平臺運行。
Node.js 的優勢主要在于事件循環,非阻塞異步 I/O,只開一個線程,不會每個請求過來我都去創建一個線程,從而產生資源開銷。
模塊加載機制
面試中可能會問到能說下 require 的加載機制嗎?
在 Node.js 中模塊加載一般會經歷 3 個步驟,路徑分析、文件定位、編譯執行。
按照模塊的分類,按照以下順序進行優先加載:
- 系統緩存:模塊被執行之后會會進行緩存,首先是先進行緩存加載,判斷緩存中是否有值。
- 系統模塊:也就是原生模塊,這個優先級僅次于緩存加載,部分核心模塊已經被編譯成二進制,省略了?
路徑分析、文件定位,直接加載到了內存中,系統模塊定義在 Node.js 源碼的 lib 目錄下,可以去查看。 - 文件模塊:優先加載?
.、..、/?開頭的,如果文件沒有加上擴展名,會依次按照?.js、.json、.node進行擴展名補足嘗試,那么在嘗試的過程中也是以同步阻塞模式來判斷文件是否存在,從性能優化的角度來看待,.json、.node最好還是加上文件的擴展名。 - 目錄做為模塊:這種情況發生在文件模塊加載過程中,也沒有找到,但是發現是一個目錄的情況,這個時候會將這個目錄當作一個?
包?來處理,Node 這塊采用了 Commonjs 規范,先會在項目根目錄查找 package.json 文件,取出文件中定義的 main 屬性?("main": "lib/hello.js")?描述的入口文件進行加載,也沒加載到,則會拋出默認錯誤: Error: Cannot find module 'lib/hello.js' - node_modules 目錄加載:對于系統模塊、路徑文件模塊都找不到,Node.js 會從當前模塊的父目錄進行查找,直到系統的根目錄
require 模塊加載時序圖
參考:Node.js 是什么?我為什么選擇它?、淺談 Node.js 模塊機制及常見面試問題解答
CommonJS
我們知道Node.js的實現讓js也可以成為后端開發語言,
但在早先Node.js開發過程中,它的作者發現在js中并沒有像其他后端語言一樣有包引入和模塊系統的機制。
這就意味著js的所有變量,函數都在全局中定義。這樣不但會污染全局變量,更會導致暴露函數內部細節等問題。
CommonJS組織也意識到了同樣的問題,于是 CommonJS組織創造了一套js模塊系統的規范。我們現在所說的CommonJS指的就是這個規范。
Node 應用由模塊組成,采用 CommonJS 模塊規范。
每個文件就是一個模塊,有自己的作用域。在一個文件里面定義的變量、函數、類,都是私有的,對其他文件不可見。
CommonJS使用?require 來加載代碼,而 exports 和 module.exports 則用來導出代碼。
- module.exports 初始值為一個空對象 {}
- exports 是指向的 module.exports 的引用
- require() 默認返回的是 module.exports 而不是 exports
exports 相當于 module.exports 的快捷方式如下所示:
const exports = modules.exports;但是要注意不能改變 exports 的指向,我們可以通過?exports.test = 'a'?這樣來導出一個對象, 但是不能向下面示例直接賦值,這樣會改變 exports 的指向
// 錯誤的寫法 將會得到 undefined
exports = {'a': 1,'b': 2
}// 正確的寫法
modules.exports = {'a': 1,'b': 2
}CommonJS模塊的特點如下。
- 所有代碼都運行在模塊作用域,不會污染全局作用域。
- 模塊可以多次加載,但是只會在第一次加載時運行一次,然后運行結果就被緩存了,以后再加載,就直接讀取緩存結果。要想讓模塊再次運行,必須清除緩存。
- 模塊加載的順序,按照其在代碼中出現的順序。(同步)
AMD規范與CommonJS規范的兼容性
CommonJS規范加載模塊是同步的,也就是說,只有加載完成,才能執行后面的操作。AMD規范則是非同步加載模塊,允許指定回調函數。由于Node.js主要用于服務器編程,模塊文件一般都已經存在于本地硬盤,所以加載起來比較快,不用考慮非同步加載的方式,所以CommonJS規范比較適用。但是,如果是瀏覽器環境,要從服務器端加載模塊,這時就必須采用非同步模式,因此瀏覽器端一般采用AMD規范。
AMD規范使用define方法定義模塊,下面就是一個例子:
define(['package/lib'], function(lib){function foo(){lib.log('hello world!');}return {foo: foo};
});
AMD規范允許輸出的模塊兼容CommonJS規范,這時define方法需要寫成下面這樣:
define(function (require, exports, module){var someModule = require("someModule");var anotherModule = require("anotherModule");someModule.doTehAwesome();anotherModule.doMoarAwesome();exports.asplode = function (){someModule.doTehAwesome();anotherModule.doMoarAwesome();};
});AMD
AMD是"Asynchronous Module Definition"的縮寫,意思就是"異步模塊定義"。它采用異步方式加載模塊,模塊的加載不影響它后面語句的運行。所有依賴這個模塊的語句,都定義在一個回調函數中,等到加載完成之后,這個回調函數才會運行。
AMD也采用require()語句加載模塊,但是不同于CommonJS,它要求兩個參數:
require([module], callback);
第一個參數[module],是一個數組,里面的成員就是要加載的模塊;第二個參數callback,則是加載成功之后的回調函數。如果將前面的代碼改寫成AMD形式,就是下面這樣:
require(['math'], function (math) {
math.add(2, 3);
});
math.add()與math模塊加載不是同步的,瀏覽器不會發生假死。所以很顯然,AMD比較適合瀏覽器環境。
我們經常看到這樣的寫法:
exports = module.exports = somethings上面的代碼等價于:
module.exports = somethings
exports = module.exports原理很簡單,即 module.exports 指向新的對象時,exports 斷開了與 module.exports 的引用,那么通過 exports = module.exports 讓 exports 重新指向 module.exports 即可。
參考:CommonJS規范、?exports 和 module.exports 的區別
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?


初步理解_1)



![[樹形dp] Jzoj P1046 尋寶之旅](http://pic.xiahunao.cn/[樹形dp] Jzoj P1046 尋寶之旅)

二)










