目錄
require() 加載文件機制
線程和進程
線程
單線程
Nodejs的線程與進程
網絡模型
初識 TCP 協議
三次握手
I/O
I/O 先修知識
阻塞與非阻塞 I/O
同步與異步 I/O
Git
基礎命令
分支操作
修改遠程倉庫地址
遠程分支獲取最新的版本到本地
拉取遠程倉庫指定分支到本地
SEO優化
優化策略
SEO實戰
TDK優化
頁面內容優化
使用html5結構
唯一的H1標題
img設置alt屬性
nofollow
正文
URL優化
URL靜態化
URL規范化
robots
robots.txt
meta robots
sitemap
SEO工具
let、const、class和var的區別
js三大事件(鼠標事件、鍵盤事件、html事件)
鼠標事件
鍵盤事件
HTML事件
JS引擎的執行機制
首先,請牢記2點:
3.JS中的event loop(2)
4. 談談setTimeout
webpack
DOCTYPE
嚴格模式與混雜模式如何區分?它們有何意義?
get和post的區別
h5新特性
語義化標簽
標簽新屬性
細說data-* dataset(IE11,火狐谷歌)
classList(火狐谷歌最新,IE10以上)
HTML5新表單
新的input類型
新的form屬性
新的input屬性
音頻(audio)和視頻(video)
支持的格式和寫法
標簽屬性
方法
事件
事件屬性
css3新特性
過渡
動畫
形狀轉換
選擇器
陰影
邊框
邊框圖片
邊框圓角
background-size
文字
換行
超出省略號
多行超出省略號
顏色
rgba
hsla
漸變
彈性布局——flex
盒模型定義
媒體查詢
?偽類與偽元素
mongodb
為什么要用MongoDB
幾個shell實操
Mongobd的重要模塊–GridFS
GridFS存儲原理
深入淺出mongoose
小程序
響應的數據綁定
頁面管理
基礎組件
豐富的 API
云開發
js 深拷貝 vs 淺拷貝
堆和棧的區別
對象
數組
瀏覽器的兼容性
Web標準以及W3C
主流瀏覽器的內核
?標準模式(Standards Mode)和怪異模式 (Quirks Mode)
CSS盒模型
重置瀏覽器樣式
表現與數據分離
HTML語義化
CSS選擇器優先級
清除浮動
響應式布局和自適應布局詳解
響應式布局概念
響應式設計的步驟
一些注意的
rem是如何實現自適應布局的?
rem是什么?
為什么web?app要使用rem?
1、實現強大的屏幕適配布局:
2.固定寬度做法
3.響應式做法
4.設置viewport進行縮放
rem能等比例適配所有屏幕
REM自適應JS
響應式與自適應的區別
?JavaScript 數據類型知識整理
javascript中有哪些數據類型
基本類型
對象類型
說說你對javascript是弱類型語言的理解?
javascript中強制類型轉換是一個非常易出現bug的點,知道強制轉換時候的規則嗎?
ToPrimitive(轉換為原始值)
toString
valueOf
強制轉換
Number()
String()
Boolean()
js轉換規則不同場景應用
什么時候自動轉換為string類型
什么時候自動轉換為Number類型
什么時候進行布爾轉換
抽象相等
js中的數據類型判斷
typeof
instanceof
NaN相關總結
NaN的概念
什么時候返回NaN (開篇第二道題也得到解決)
對 null 和 undefined 進行比較
奇怪的結果:null vs 0
特立獨行的 undefined
規避錯誤
誤區
toString和String的區別
?
require() 加載文件機制
當 Node 遇到 require(X) 時,按下面的順序處理。
(1)如果 X 是內置模塊(比如 require('http'))
a. 返回該模塊。
b. 不再繼續執行。(2)如果 X 以 "./" 或者 "/" 或者 "../" 開頭
a. 根據 X 所在的父模塊,確定 X 的絕對路徑。
b. 將 X 當成文件,依次查找下面文件,只要其中有一個存在,就返回該文件,不再繼續執行。
- X
- X.js
- X.json
- X.node
c. 將 X 當成目錄,依次查找下面文件,只要其中有一個存在,就返回該文件,不再繼續執行。
- X/package.json(main字段)
- X/index.js
- X/index.json
- X/index.node
(3)如果 X 不帶路徑
a. 根據 X 所在的父模塊,確定 X 可能的安裝目錄。
b. 依次在每個目錄中,將 X 當成文件名或目錄名加載。(4) 拋出 "not found"
請看一個例子。
當前腳本文件 /home/ry/projects/foo.js 執行了 require('bar') ,這屬于上面的第三種情況。Node 內部運行過程如下。
首先,確定 x 的絕對路徑可能是下面這些位置,依次搜索每一個目錄。
/home/ry/projects/node_modules/bar /home/ry/node_modules/bar /home/node_modules/bar /node_modules/bar
搜索時,Node 先將 bar 當成文件名,依次嘗試加載下面這些文件,只要有一個成功就返回。
bar bar.js bar.json bar.node
如果都不成功,說明 bar 可能是目錄名,于是依次嘗試加載下面這些文件。
bar/package.json(main字段) bar/index.js bar/index.json bar/index.node
如果在所有目錄中,都無法找到 bar 對應的文件或目錄,就拋出一個錯誤。
參考:require() 源碼解讀
線程和進程
進程(Process)是計算機中的程序關于某數據集合上的一次運行活動,是系統進行資源分配和調度的基本單位,是操作系統結構的基礎,進程是線程的容器(來自百科)。我們啟動一個服務、運行一個實例,就是開一個服務進程,例如Node.js 里通過?node app.js?開啟一個服務進程,多進程就是進程的復制(fork),fork 出來的每個進程都擁有自己的獨立空間地址、數據棧,一個進程無法訪問另外一個進程里定義的變量、數據結構,只有建立了 IPC 通信,進程之間才可數據共享。
關于進程通過一個簡單的 Node.js Demo 來驗證下,執行以下代碼?
node process.js,開啟一個服務進程
// process.js
const http = require('http');http.createServer().listen(3000, () => {process.title = '測試進程 Node.js' // 進程進行命名console.log(`process.pid: `, process.pid); // process.pid: 20279
});線程
線程是操作系統能夠進行運算調度的最小單位,首先我們要清楚線程是隸屬于進程的,被包含于進程之中。一個線程只能隸屬于一個進程,但是一個進程是可以擁有多個線程的。
同一塊代碼,可以根據系統CPU核心數啟動多個進程,每個進程都有屬于自己的獨立運行空間,進程之間是不相互影響的。同一進程中的多條線程將共享該進程中的全部系統資源,如虛擬地址空間,文件描述符和信號處理等。但同一進程中的多個線程有各自的調用棧(call stack),自己的寄存器環境(register context),自己的線程本地存儲(thread-local storage),線程又有單線程和多線程之分,具有代表性的 JavaScript、Java 語言。
單線程
單線程就是一個進程只開一個線程
Javascript 就是屬于單線程,程序順序執行,可以想象一下隊列,前面一個執行完之后,后面才可以執行,當你在使用單線程語言編碼時切勿有過多耗時的同步操作,否則線程會造成阻塞,導致后續響應無法處理。你如果采用 Javascript 進行編碼時候,請盡可能的使用異步操作。
單線程使用總結
- Node.js 雖然是單線程模型,但是其基于事件驅動、異步非阻塞模式,可以應用于高并發場景,避免了線程創建、線程之間上下文切換所產生的資源開銷。
- 如果你有需要大量計算,CPU 耗時的操作,開發時候要注意。
Nodejs的線程與進程
Node.js 是 Javascript 在服務端的運行環境,構建在 chrome 的 V8 引擎之上,基于事件驅動、非阻塞I/O模型,充分利用操作系統提供的異步 I/O 進行多任務的執行,適合于 I/O 密集型的應用場景,因為異步,程序無需阻塞等待結果返回,而是基于回調通知的機制,原本同步模式等待的時間,則可以用來處理其它任務,在 Web 服務器方面,著名的 Nginx 也是采用此模式(事件驅動),Nginx 采用 C 語言進行編寫,主要用來做高性能的 Web 服務器,不適合做業務。Web業務開發中,如果你有高并發應用場景那么 Node.js 會是你不錯的選擇。
Process
Node.js 中的進程 Process 是一個全局對象,無需 require 直接使用,給我們提供了當前進程中的相關信息。官方文檔提供了詳細的說明,感興趣的可以親自實踐下?Process 文檔。
- process.env:環境變量,例如通過 process.env.NODE_ENV 獲取不同環境項目配置信息
- process.nextTick:這個在談及 Event Loop 時經常為會提到
- process.pid:獲取當前進程id
- process.ppid:當前進程對應的父進程
- process.cwd():獲取當前進程工作目錄
- process.platform:獲取當前進程運行的操作系統平臺
- process.uptime():當前進程已運行時間,例如:pm2 守護進程的 uptime 值
- 進程事件:process.on('uncaughtException', cb) 捕獲異常信息、process.on('exit', cb)進程推出監聽
- 三個標準流:process.stdout 標準輸出、process.stdin 標準輸入、process.stderr 標準錯誤輸出
關于 Node.js 進程的幾點總結
- Javascript 是單線程,但是做為宿主環境的 Node.js 并非是單線程的。
- 由于單線程原故,一些復雜的、消耗 CPU 資源的任務建議不要交給 Node.js 來處理,當你的業務需要一些大量計算、視頻編碼解碼等 CPU 密集型的任務,可以采用 C 語言。
- Node.js 和 Nginx 均采用事件驅動方式,避免了多線程的線程創建、線程上下文切換的開銷。如果你的業務大多是基于 I/O 操作,那么你可以選擇 Node.js 來開發。
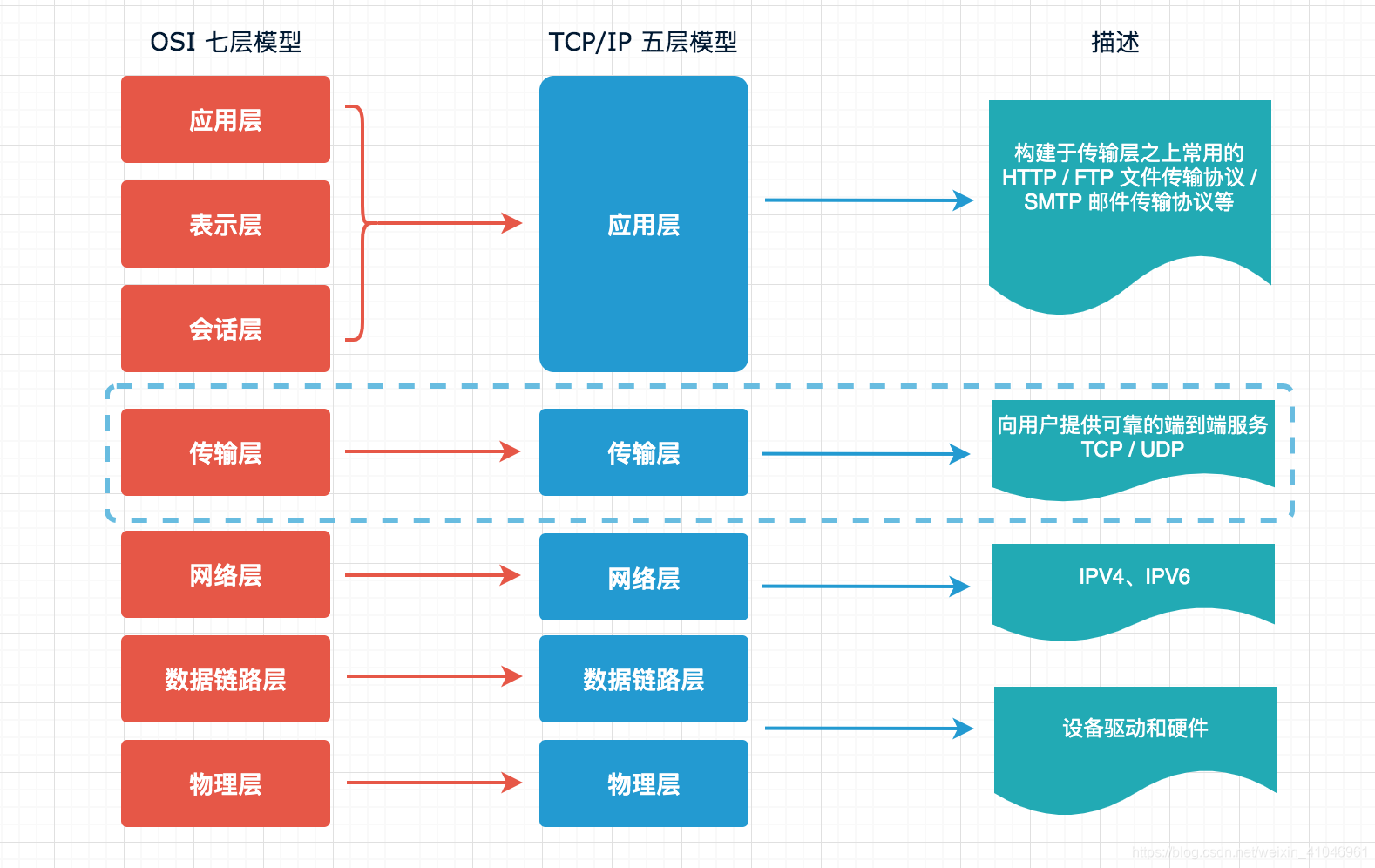
網絡模型
大多數同學對于 HTTP、HTTPS 會很熟悉,通常用于瀏覽器與服務端交互,或者服務端與服務端的交互,另外兩個 Net 與 Dgram 也許會相對陌生,這兩個是基于網絡模型的傳輸層來實現的,分別對應于 TCP、UDP 協議,下面一圖看明白 OSI 七層模型 與 TCP/IP 五層模型之間的關系,中間使用虛線標注了傳輸層,對于上層應用層(HTTP/HTTPS等)也都是基于這一層的 TCP 協議來實現的,所以想使用 Node.js 做服務端開發,Net 模塊也是你必須要掌握的,這也是我們本篇要講解的重點。
初識 TCP 協議
TCP 是傳輸控制協議,大多數情況下我們都會使用這個協議,因為它是一個更可靠的數據傳輸協議,具有如下三個特點:
- 面向鏈接: 需要對方主機在線,并建立鏈接。
- 面向字節流: 你給我一堆字節流的數據,我給你發送出去,但是每次發送多少是我說了算,每次選出一段字節發送的時候,都會帶上一個序號,這個序號就是發送的這段字節中編號最小的字節的編號。
- 可靠: 保證數據有序的到達對方主機,每發送一個數據就會期待收到對方的回復,如果在指定時間內收到了對方的回復,就確認為數據到達,如果超過一定時間沒收到對方回復,就認為對方沒收到,在重新發送一遍。
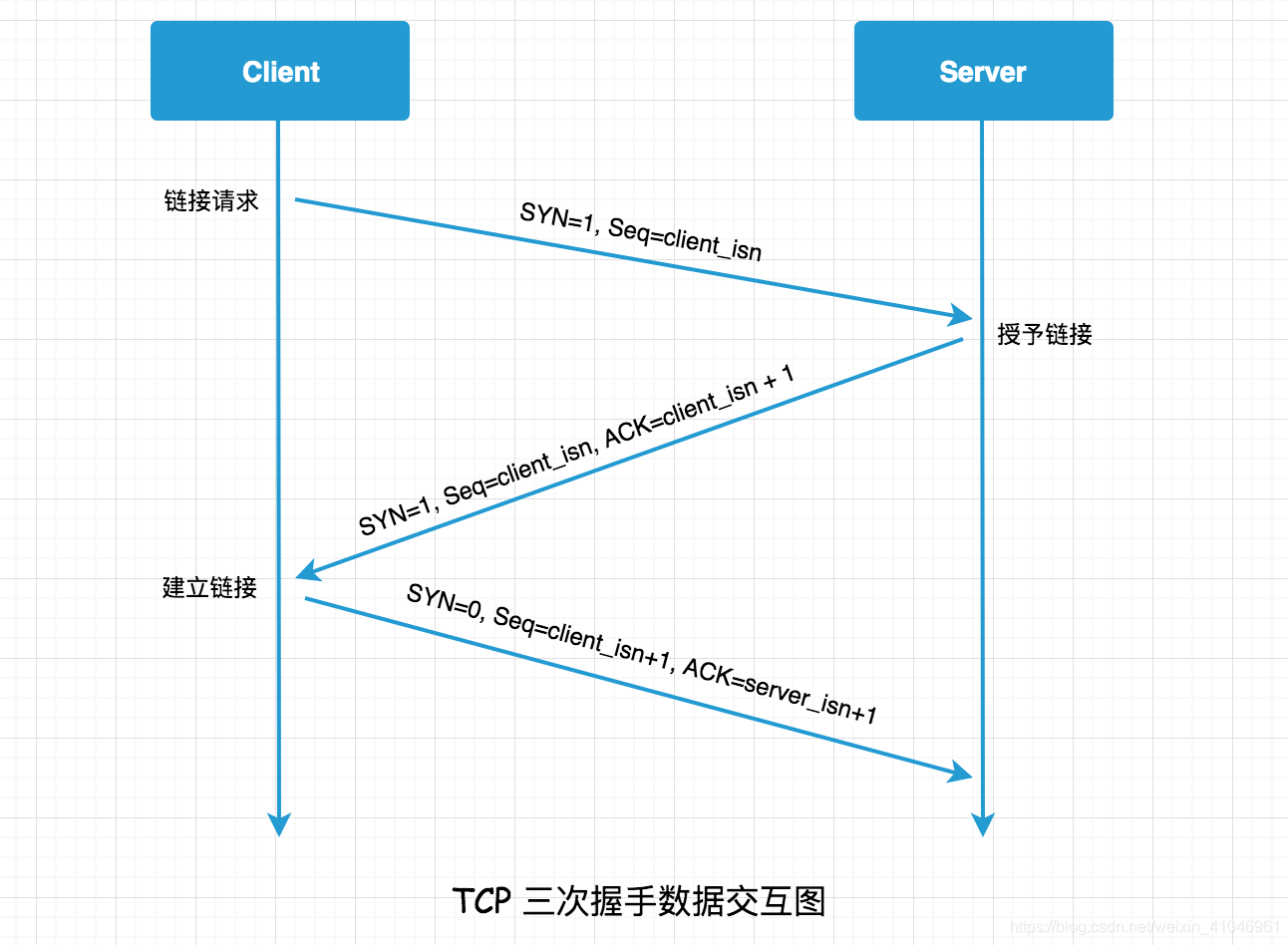
三次握手
上面三個特點說到 TCP 是面向鏈接和可靠的,其一個顯著特征是在傳輸之前會有一個 3 次握手,實現過程如下所示:
?
在一次 TCP 三次握手的過程中,客戶端與服務端會分別提供一個套接字來形成一個鏈接。之后客戶端與服務端通過這個鏈接來互相發送數據。
先清楚一個概念http請求與tcp鏈接之間的關系,在客戶端向服務端請求和返回的過程中,是需要去創建一個TCP connection,因為http是不存在鏈接這樣一個概念的,它只有請求和響應這樣一個概念,請求和響應都是一個數據包,中間要通過一個傳輸通道,這個傳輸通道就是在TCP里面創建了一個從客戶端發起和服務端接收的一個鏈接,TCP鏈接在創建的時候是有一個三次握手(三次網絡傳輸)這樣一個消耗在的。
?
第一次握手:?建立連接,客戶端A發送SYN=1、隨機產生Seq=client_isn的數據包到服務器B,等待服務器確認。
第二次握手:?服務器B收到請求后確認聯機(可以接受數據),發起第二次握手請求,ACK=(A的Seq+1)、SYN=1,隨機產生Seq=client_isn的數據包到A。
第三次握手:?A收到后檢查ACK是否正確,若正確,A會在發送確認包ACK=服務器B的Seq+1、ACK=1,服務器B收到后確認Seq值與ACK值,若正確,則建立連接。
TCP標示:
- SYN(synchronous建立聯機)
- ACK(acknowledgement 確認)
- Sequence number(順序號碼)
總結:?
至于為什么要經過三次握手呢,是為了防止服務端開啟一些無用的鏈接,保證雙方的有效率傳輸。網絡傳輸是有延時的,中間可能隔著非常遠的距離,通過光纖或者中間代理服務器等,客戶端發送一個請求,服務端收到之后如果直接創建一個鏈接,返回內容給到客戶端,因為網絡傳輸原因,這個數據包丟失了,客戶端就一直接收不到服務器返回的這個數據,超過了客戶端設置的時間就關閉了,那么這時候服務端是不知道的,它的端口就會開著等待客戶端發送實際的請求數據,服務這個開銷也就浪費掉了。只有經過三次握手,才能確定雙方的收、發功能都是正常的,那么彼此之間的通訊也就得到保障了,也就不存在上面的開銷浪費了。
I/O
I/O 是 Input/Ouput 的縮寫,即輸入輸出端口,是信息處理系統(例如計算機)與外部世界(可能是人類或另一信息處理系統)之間的通信。輸入是系統接收的信號或數據,輸出則是從其發送的信號或數據。
I/O 先修知識
I/O 也是一個很寬泛的詞,每個設備都會有一個專用的 I/O 地址,用來處理自己的輸入輸出信息。對于服務端研發的童鞋相信?網絡 I/O、磁盤 I/O?這些詞,也需并不陌生,一次 API 接口調用、向磁盤寫入日志信息,其實就是在跟 I/O 打交道。一次 I/O 操作分為等待資源、使用資源兩個階段,以下分別進行介紹。
阻塞與非阻塞 I/O
阻塞與非阻塞 I/O 是對于操作系統內核而言的,發生在等待資源階段,根據發起 I/O 請求是否阻塞來判斷。
阻塞 I/O:這種模式下一個用戶進程在發起一個 I/O 操作之后,只有收到響應或者超時才可進行處理其它事情,否則 I/O 將會一直阻塞。以讀取磁盤上的一段文件為例,系統內核在完成磁盤尋道、讀取數據、復制數據到內存中之后,這個調用才算完成。阻塞的這段時間對 CPU 資源是浪費的。?非阻塞 I/O:這種模式下一個用戶進程發起一個 I/O 操作之后,如果數據沒有就緒,會立刻返回(標志數據資源不可用),此時 CPU 時間片可以用來做一些其它事情。
同步與異步 I/O
同步與異步 I/O 發生在使用資源階段,根據實際 I/O 操作來判斷。
同步 I/O:應用發送或接收數據后,如果不返回,繼續等待(此處發生阻塞),直到數據成功或失敗返回。?異步 I/O:應用發送或接收數據后立刻返回,數據寫入 OS 緩存,由 OS 完成數據發送或接收,并返回成功或失敗的信息給應用。Node.js 就是典型的異步編程例子。
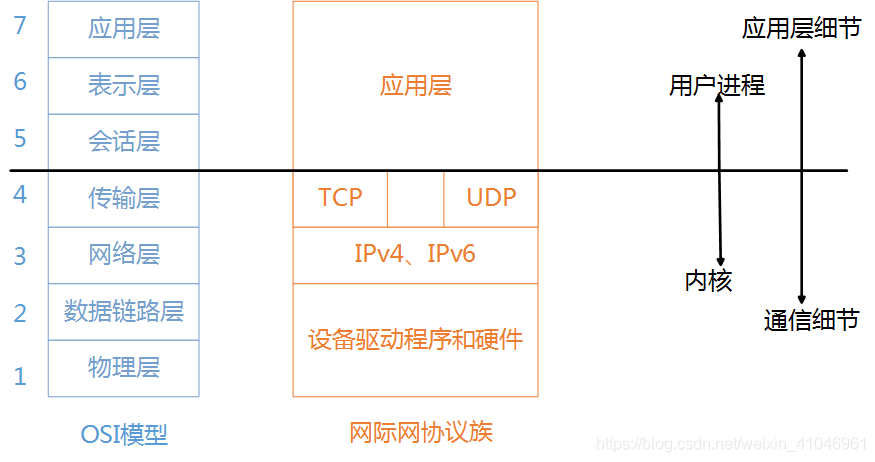
OSI 七層模型與網際網協議族圖
可以看到這里以傳輸層做了邊界劃分,傳輸層之上為用戶空間(Web 客戶端、瀏覽器、FTP 這些都屬于上三層),下四層為內核空間,例如傳輸層的 TCP、UDP 協議就對應到了內核空間。
Git
Git 當下最流行的版本管理工具
基礎命令
git init?初始化本地倉庫git add -A .?來一次添加所有改變的文件git add -A?表示添加所有內容git add .?表示添加新文件和編輯過的文件不包括刪除的文件git add -u?表示添加編輯或者刪除的文件,不包括新添加的文件git commit -m '版本信息'?提交的版本信息描述git status?查看狀態git push -u origin master?推送到遠程倉庫看git pull?拉取遠程倉庫代碼到本地git branch -av?查看每個分支的最新提交記錄git branch -vv?查看每個分支屬于哪個遠程倉庫git reset --hard a3f40baadd5fea57b1b40f23f9a54a644eebd52e?代碼回歸到某個提交記錄
分支操作
- 查看本地都有哪些分支?
git branch -a - 新建分支?
git branch dev - 查看當前分支?
git branch - 切換分支?
git checkout dev - 刪除本地分支?
git branch -d dev - 同步刪除遠程分支?
git push origin :dev
修改遠程倉庫地址
- 方法1,先刪后加:
git remote rm origin?先刪除git remote add origin 倉庫地址?鏈接到到遠程git倉庫
- 方法2,修改命令:
git remote set-url origin 倉庫地址
遠程分支獲取最新的版本到本地
-
執行
git pull命令 -
如果以上命令還是失敗嘗試以下步驟:
-
首先從遠程的origin的master主分支下載最新的版本到origin/master分支上
git fetch origin master -
比較本地的master分支和origin/master分支的差別
git log -p master..origin/master -
進行合并
git merge origin/master
-
拉取遠程倉庫指定分支到本地
-
首先要與origin master建立連接:
git remote add origin git@github.com:XXXX/nothing2.git -
切換到其中某個子分支:
git checkout -b dev origin/dev -
可能會報這種錯誤:
fatal: Cannot update paths and switch to branch 'dev' at the same time.
Did you intend to checkout 'origin/dev' which can not be resolved as commit?-
原因是你本地并沒有dev這個分支,這時你可以用?
git branch -a?命令來查看本地是否具有dev分支 -
我們需要:
git fetch origin dev?命令來把遠程分支拉到本地 -
然后使用:
git checkout -b dev origin/dev?在本地創建分支dev并切換到該分支 -
最后使用:
git pull origin dev?就可以把某個分支上的內容都拉取到本地了
SEO優化
SEO(Search Engine Optimization):漢譯為搜索引擎優化。是一種方式:利用搜索引擎的規則提高網站在有關搜索引擎內的自然排名。目的是讓其在行業內占據領先地位,獲得品牌收益。很大程度上是網站經營者的一種商業行為,將自己或自己公司的排名前移。
優化策略
1.主題要明確,內容要豐富
在設計制作網站之前,要清晰設定網絡的主題、用途和內容,網站主題須明確突出,內容豐富飽滿,以符合用戶體驗為原則。對于一個網站來說,優化網站的主題與實際內容才是最為重要的。一個網站需要有鮮明的主題,豐富的與主題相關的內容,專注于某些領域的變化的,及時更新。
2.引出鏈接要人氣化
搜索引擎判斷網站的好壞的一個標準是外部鏈接的多少以及所鏈接的網站質量。創建有人氣化的、有意義的引出鏈接,提高鏈接廣泛度,既能提高在搜索引擎的排名,同時也可以起到互相宣傳的作用。
3.關鍵詞設定要突出
網站的關鍵詞非常重要,它決定網站是否能被用戶搜索到,因此在關鍵詞的選擇上要特意注意。關鍵詞的選擇必須突出,遵循一定的原則,如:關鍵詞要與網站主題相關,不要一味的追求熱門詞匯;避免使用含義很廣的一般性詞匯;根據產品的種類及特性,盡可能選取具體的詞;選取人們在使用搜索引擎時常用到與網站所需推廣的產品及服務相關的詞。5至10個關鍵詞數量是比較適中的,密度可為2%—8%。要重視在標題(Page Title)、段落標題(Heading)這兩個網頁中最重要最顯眼的位置體現關鍵詞,還須在網頁內容、圖片的alt屬性、META標簽等網頁描述上均可不同的程度設置突出關鍵詞。
4.網站架構層次要清晰
網站結構上盡量避免采用框架結構,導航條盡量不使用FLASH按鈕。首先要重視網站首頁的設計,因為網站的首頁被搜索引擎檢測到的概率要比其他網頁大得多。通常要將網站的首頁文件放在網站的根目錄下,因為根目錄下的檢索速度最快。其次要注意網站的層次(即子目錄)不宜太多,一級目錄不超過兩個層次,詳細目錄也不要超過四個層次。最后,網站的導航盡量使用純文字進行導航,因為文本要比圖片表達的信息更多。
5.頁面容量要合理化
網頁分為靜態網頁與動態網頁兩種,動態網頁即具有交互功能的網頁,也就是通過數據庫搜索返回數據,這樣搜索引擎在搜索時所費的時間較長,而且一旦數據庫中的內容更新,搜索引擎抓取的數據也不再準確,所以搜索引擎很少收錄動態網頁,排名結果也不好。而靜態網頁不具備交互功能,即單純的信息介紹,搜索引擎搜索時所費時間短,而且準確,所以愿意收錄,排名結果比較好。所以網站要盡量使用靜態網頁,減少使用動態網頁。網頁容量越小顯示速度越快,對搜索引擎蜘蛛程序的友好度越高,因而在制作網頁的時候要盡量精簡HTML代碼,通常網頁容量不超過15kB。網頁中的Java.script和CSS盡可能和網頁分離。應該鼓勵遵循W3C的規范使用,更規范的XHTML和XML作為顯示格式。
6.網站導航要清晰化
搜素引擎是通過專有的蜘蛛程序來查找出每一個網頁上的HTML代碼,當網頁上有鏈接時就逐個搜索,直到沒有指向任何頁面的鏈接。蜘蛛程序需要訪問完所有的頁面需要花費很長的時間,所以網站的導航需要便于蜘蛛程序進行索引收錄。可根據自己的網站結構,制作網站地圖simemap.html,在網頁地圖中列出網站所有子欄目的鏈接,并將網站中所有的文件放在網站的根目錄下。網站地圖可增加搜索引擎友好度,可讓蜘蛛程序快速訪問整個站點上的所有網頁和欄目。
7.網站發布要更新
為了更好的實現與搜索引擎對話,將經過優化的企業網站主動提交到各搜索引擎,讓其免費收錄,爭取較好的自然排名。一個網站如果能夠進行有規律的更新,那么搜索引擎更容易收錄。因而合理的更新網站也是搜索引擎優化的一個重要方法。?[1]?
SEO實戰
TDK優化
TDK為title,description,keywords三個的統稱。當然title是最有用的,是非常值得優化的;而keywords因為以前被seo人員過度使用,所以現在對這個進行優化對搜索引擎是沒用的,這里就不說了;description的描述會直接顯示在搜索的介紹中,所以對用戶的判斷是否點擊還是非常有效的
<title>SEO優化實戰 - 騰訊Web前端 IMWeb 團隊社區 | blog | 團隊博客</title><meta name="description" content="Web前端 騰訊IMWeb 團隊社區"><meta name="keywords" content="前端交流,前端社區,前端,iconfont,javascript,html,css,webfront,nodejs, node, express, connect, socket.io, lego.imweb.io">頁面內容優化
使用html5結構
如果條件允許(如移動端,兼容ie9+,如果ie8+就針對ie8引入html5.js吧),是時候開始考慮使用html5語義化標簽。如header,footer,section,aside,nav,article等,這里我們截圖看一個整體布局
更多html5語義化標簽請參考:All HTML5 Tags
唯一的H1標題
每個頁面都應該有個唯一的h1標題,但不是每個頁面的h1標題都是站點名稱。(但html5中h1標題是可以多次出現的,每個具有結構大綱的標簽都可以擁有自己獨立的h1標題,如header,footer,section,aside,article)
首頁的h1標題為站點名稱,內頁的h1標題為各個內頁的標題,如分類頁用分類的名字,詳細頁用詳細頁標題作為h1標題
<!-- 首頁 -->
<h1 class="page-tt">騰訊課堂</h1>
<!-- 分類頁 -->
<h1 class="page-tt">前端開發在線培訓視頻教程</h1>
<!-- 詳細頁 -->
<h1 class="page-tt">html5+CSS3</h1>
img設置alt屬性
img必須設置alt屬性,如果寬度和高度固定請同時設置固定的值
<img src="" alt="seo優化實戰" width="200" height="100" />
nofollow
對不需要跟蹤爬行的鏈接,設置nofollow。可用在博客評論、論壇帖子、社會化網站、留言板等地方,也可用于廣告鏈接,還可用于隱私政策,用戶條款,登錄等。如下代碼表示該鏈接不需要跟蹤爬行,可以阻止蜘蛛爬行及傳遞權重。
<a href="http://example.com" rel="nofollow">no follow 鏈接</a>
正文
內容方面考慮:
- 自然寫作
- 高質量原創內容
- 吸引閱讀的寫作手法
- 突出賣點
- 增強信任感
- 引導進一步行為
用戶體驗方面考慮:
- 排版合理、清晰、美觀、字體、背景易于閱讀
- 實質內容處在頁面最重要位置,用戶一眼就能看到
- 實質內容與廣告能夠清晰區分
- 第一屏就有實質內容,而不是需要下拉頁面才能看到
- 廣告數量不宜過多,位置不應該妨礙用戶閱讀
- 如果圖片、視頻有利于用戶理解頁面內容,盡量制作圖片、視頻等
- 避免過多彈窗
URL優化
URL設計原則:
- 越短越好
- 避免太多參數
- 目錄層次盡量少
- 文件及目錄名具描述性
- URL中包括關鍵詞(中文除外)
- 字母全部小寫
- 連詞符使用
-而不是_ - 目錄形式而非文件形式
URL靜態化
以現在搜索引擎的爬行能力是可以不用做靜態化的,但是從收錄難易度,用戶體驗及社會化分享,靜態簡短的URL都是更有利的。
具體討論可參考:URL靜態化還是不靜態化?
URL規范化
1、統一連接
http://www.domainname.com
http://domainname.com
http://www.domainname.com/index.html
http://domainname.com/index.html
以上四個其實都是首頁,雖然不會給訪客造成什么麻煩,但對于搜索引擎來說就是四條網址,并且內容相同,很可能會被誤認為是作弊手段,而且當搜索引擎要規范化網址時,需要從這些選擇當中挑一個最好的代表,但是挑的這個不一定是你想要的。所以最好自己就規范好。
2、301跳轉
第一種是URL發生改變,一定要把舊的地址301指向新的,不然之前做的一些收錄權重什么的全白搭了。
第二種是一些cms系統,極有可能會造成多個路徑對應同一篇文章。如drupal默認的路徑是以node/nid,但是如果啟用了path token,就可以自己自定義路徑。這樣一來就有兩條路徑對應同一篇文章。所以可以啟用301,最終轉向一個路徑。
3、canonical
這個標簽表示頁面的唯一性(這個標簽以前百度不支持,現在支持),用在平時參數傳遞的時候,如:
//:ke.qq.com/download/app.html
//:ke.qq.com/download/app.html?from=123
//:ke.qq.com/download/app.html?from=456
以上三個表示三個頁面,但其實后兩個只是想表明從哪來的而已,所以為了確保這三個為同一個頁面,我們在head上加上canonical標簽。
<link rel="cononical" href="//:ke.qq.com/download/download/app.html" />
robots
robots.txt
搜索引擎蜘蛛訪問網站時會第一個訪問robots.txt文件,robots.txt用于指導搜索引擎蜘蛛禁止抓取網站某些內容或只允許抓取那些內容,放在站點根目錄。
以騰訊課堂的robots.txt為例:
- User-agent 表示以下規則適用哪個蜘蛛,
*表示所有 #表示注釋- Disallow 表示禁止抓取的文件或目錄,必須每個一行,分開寫
- Allow 表示允許抓取的文件或目錄,必須每個一行,分開寫
- Sitemap 表示站點XML地圖,注意S大寫
下面表示禁止所有搜索引擎蜘蛛抓取任何內容
User-agent: *
Disallow: /
下面表示允許所有搜索引擎蜘蛛抓取任何內容
User-agent: *
Disallow:
注意:被robots禁止抓取的URL還是可能被索引并出現在搜索結果中的。只要有導入鏈接指向這個URL,搜索引擎就知道這個URL的存在,雖然不會抓取頁面內容,但是索引庫還是有這個URL的信息。以淘寶為例:
禁止百度搜索引擎抓取
百度搜索有顯示
更多關于robots.txt請參考:如何使用robots.txt及其詳解
meta robots
如果要想URL完全不出現在搜索結果中,則需設置meta robots
<meta name="robots" content="onindex,nofollow">
上面代碼表示:禁止所有搜索引擎索引本頁,禁止跟蹤本頁上的鏈接。
當然還有其他類型的content,不過各個瀏覽器支持情況不同,所以這里忽略。
sitemap
站點地圖格式分為HTML和XML兩種。
HTML版本的是普通的HTML頁面sitemap.html,用戶可以直接訪問,可以列出站點的所有主要鏈接,建議不超過100條。
XML版本的站點地圖是google在2005年提出的,由XML標簽組成,編碼為utf-8,羅列頁面所有的URL。其格式如下:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"><url><loc>//ke.qq.com</loc><lastmod>2015-12-28</lastmod><changefreq>always</changefreq><priority>1.0</priority></url>...
</urlset>
其中urlset,url,loc三個為必須標簽,lastmod,changefreq,priority為可選標簽。
lastmod表示頁面最后一次更新時間。
changefreq表示文件更新頻率,有以下幾種取值:always, hourly, daily, weekly, monthly, yearly, never。其中always表示一直變動,每次訪問頁面內容都不同;而never表示從來不變。
priority表示URL相對重要程度,取值范圍為0.0-1.0,1.0表示最重要,一般用在網站首頁,對應的0.0就是最不重要的,默認重要程度為0.5。(注意這里的重要度是我們標記的,并不代表搜索引擎真的就完全按照我們設置的重要度來排列)
sitemap.xml不能超過10M,而且每個sitemap文件中url的條數不要超過5萬條,當你的sitemap文件很大的時候,可以分解為多個文件。如下分為兩條,一條為基礎,一條為產品詳細頁。
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"><sitemap><loc>//ke.qq.com/sitemap-basic.xml</loc><lastmod>2015-12-28T02:10Z</lastmod></sitemap><sitemap><loc>//ke.qq.com/sitemap-product.xml</loc><lastmod>2015-12-28T02:10Z</lastmod></sitemap>
</sitemapindex>
SEO工具
- 百度搜索風云榜
- 百度指數
- 百度站長平臺
- meta seo inspector,檢查標簽的,谷歌插件
- seo in china,百度收錄的各種數據,谷歌插件
- check my links,檢查鏈接,谷歌插件
- seo quake,統計各種數據,谷歌插件
最后,本文參考百度搜索引擎優化指南2.0?和zac著作《SEO實戰密碼》(對SEO感興趣的同學,可以買本看看)。
參考:SEO優化實戰
let、const、class和var的區別
頂層對象(瀏覽器環境指 window、Node.js 環境指 Global)的屬性和全局變量屬性的賦值是相等價的,
- 使用 var 和 function 聲明的是頂層對象的屬性,而 let 就屬于 ES6 規范了,但是 ES6 規范中 let、const、class 這些聲明的全局變量,不再屬于頂層對象的屬性。
- let聲明的變量是塊級作用域(所在花括號里),var是函數作用域和全局作用域
- 從代碼的寫法上,let不能聲明同名的變量,var可以。
-
var聲明變量存在變量提升,let和const不存在變量提升
let a = '22' ;(function (){const a = '11'})()// 這里成了一個私有作用域,所以可以//如果這里出現const a = '11';// 則會報錯!const不允許重名變量console.log(a,'a') //22js三大事件(鼠標事件、鍵盤事件、html事件)
鼠標事件
- click:單擊
- dblclick:雙擊
- mousedown:鼠標按下
- mouseup:鼠標抬起
- mouseover:鼠標懸浮
- mouseout:鼠標離開
- mousemove:鼠標移動
- mouseenter:鼠標進入
- mouseleave:鼠標離開
鍵盤事件
- keydown:按鍵按下
- keyup:按鍵抬起
- keypress:按鍵按下抬起
HTML事件
- load:文檔加載完成
- select:被選中的時候
- change:內容被改變
- focus:得到光標
- resize:窗口尺寸變化
- scroll:滾動條移動
JS引擎的執行機制
首先,請牢記2點:
(1) JS是單線程語言
(2) JS的Event Loop是JS的執行機制。深入了解JS的執行,就等于深入了解JS里的event loop
例1,觀察它的執行順序
console.log(1)setTimeout(function(){console.log(2)},0)console.log(3)運行結果是: 1 3 2
也就是說,setTimeout里的函數并沒有立即執行,而是延遲了一段時間,滿足一定條件后,才去執行的,這類代碼,我們叫異步代碼。
所以,這里我們首先知道了JS里的一種分類方式,就是將任務分為: 同步任務和異步任務
按照這種分類方式:JS的執行機制是
- 首先判斷JS是同步還是異步,同步就進入主線程,異步就進入event table
- 異步任務在event table中注冊函數,當滿足觸發條件后,被推入event queue
- 同步任務進入主線程后一直執行,直到主線程空閑時,才會去event queue中查看是否有可執行的異步任務,如果有就推入主線程中
以上三步循環執行,這就是event loop
所以上面的例子,你是否可以描述它的執行順序了呢?
console.log(1) 是同步任務,放入主線程里
setTimeout() 是異步任務,被放入event table, 0秒之后被推入event queue里
console.log(3 是同步任務,放到主線程里當 1、 3在控制條被打印后,主線程去event queue(事件隊列)里查看是否有可執行的函數,執行setTimeout里的函數
3.JS中的event loop(2)
所以,上面關于event loop就是我對JS執行機制的理解,直到我遇到了下面這段代碼
例2:
setTimeout(function(){console.log('定時器開始啦')});new Promise(function(resolve){console.log('馬上執行for循環啦');for(var i = 0; i < 10000; i++){i == 99 && resolve();}}).then(function(){console.log('執行then函數啦')});console.log('代碼執行結束');嘗試按照,上文我們剛學到的JS執行機制去分析
setTimeout 是異步任務,被放到event tablenew Promise 是同步任務,被放到主線程里,直接執行打印 console.log('馬上執行for循環啦').then里的函數是 異步任務,被放到event tableconsole.log('代碼執行結束')是同步代碼,被放到主線程里,直接執行所以,結果是 【馬上執行for循環啦 --- 代碼執行結束 --- 定時器開始啦 --- 執行then函數啦】嗎?
親自執行后,結果居然不是這樣,而是【馬上執行for循環啦 --- 代碼執行結束 --- 執行then函數啦 --- 定時器開始啦】
那么,難道是異步任務的執行順序,不是前后順序,而是另有規定? 事實上,按照異步和同步的劃分方式,并不準確。
而準確的劃分方式是:
- macro-task(宏任務):包括整體代碼script,setTimeout,setInterval
- micro-task(微任務):Promise,process.nextTick
按照這種分類方式:JS的執行機制是
- 執行一個宏任務,過程中如果遇到微任務,就將其放到微任務的【事件隊列】里
- 當前宏任務執行完成后,會查看微任務的【事件隊列】,并將里面全部的微任務依次執行完
重復以上2步驟,結合event loop(1) event loop(2) ,就是更為準確的JS執行機制了。
嘗試按照剛學的執行機制,去分析例2:
首先執行script下的宏任務,遇到setTimeout,將其放到宏任務的【隊列】里遇到 new Promise直接執行,打印"馬上執行for循環啦"遇到then方法,是微任務,將其放到微任務的【隊列里】打印 "代碼執行結束"本輪宏任務執行完畢,查看本輪的微任務,發現有一個then方法里的函數, 打印"執行then函數啦"到此,本輪的event loop 全部完成。下一輪的循環里,先執行一個宏任務,發現宏任務的【隊列】里有一個 setTimeout里的函數,執行打印"定時器開始啦"
所以最后的執行順序是【馬上執行for循環啦 --- 代碼執行結束 --- 執行then函數啦 --- 定時器開始啦】
4. 談談setTimeout
這段setTimeout代碼什么意思? 我們一般說: 3秒后,會執行setTimeout里的那個函數
setTimeout(function(){console.log('執行了')},3000) 但是這種說并不嚴謹,準確的解釋是: 3秒后,setTimeout里的函數被會推入event queue,而event queue(事件隊列)里的任務,只有在主線程空閑時才會執行。
所以只有滿足 (1)3秒后 (2)主線程空閑,同時滿足時,才會3秒后執行該函數
如果主線程執行內容很多,執行時間超過3秒,比如執行了10秒,那么這個函數只能10秒后執行了
webpack
什么是Webpack
WebPack可以看做是模塊打包機:它做的事情是,分析你的項目結構,找到JavaScript模塊以及其它的一些瀏覽器不能直接運行的拓展語言或者高級語言(Scss,TypeScript等),并將其打包為合適的格式以供瀏覽器使用。
為什要使用WebPack
今的很多網頁其實可以看做是功能豐富的應用,它們擁有著復雜的JavaScript代碼和一大堆依賴包。為了簡化開發的復雜度,前端社區涌現出了很多好的實踐方法
a:模塊化,讓我們可以把復雜的程序細化為小的文件;
b:類似于TypeScript這種在JavaScript基礎上拓展的開發語言:使我們能夠實現目前版本的JavaScript不能直接使用的特性,并且之后還能能裝換為JavaScript文件使瀏覽器可以識別;
c:scss,less等CSS預處理器
.........
這些改進確實大大的提高了我們的開發效率,但是利用它們開發的文件往往需要進行額外的處理才能讓瀏覽器識別,而手動處理又是非常繁瑣的,這就為WebPack類的工具的出現提供了需求
Webpack的工作方式是:把你的項目當做一個整體,通過一個給定的主文件(如:index.js),Webpack將從這個文件開始找到你的項目的所有依賴文件,使用loaders處理它們,最后打包為一個(或多個)瀏覽器可識別的JavaScript文件。
參考:入門Webpack,看這篇就夠了
DOCTYPE
DOCTYPE全稱Document Type Declaration(文檔類型聲明,縮寫DTD)
DTD的聲明影響瀏覽器對于CSS代碼及Javascript腳本的解析。
<!DOCTYPE>聲明叫做文件類型定義(DTD),聲明的作用為了告訴瀏覽器該文件的類型。讓瀏覽器解析器知道應該用哪個規范來解析文檔。<!DOCTYPE>聲明必須在 HTML 文檔的第一行,這并不是一個 HTML 標簽。
嚴格模式與混雜模式如何區分?它們有何意義?
嚴格模式:又稱標準模式,是指瀏覽器按照 W3C 標準解析代碼。
混雜模式:又稱怪異模式或兼容模式,是指瀏覽器用自己的方式解析代碼。
如何區分:瀏覽器解析時到底使用嚴格模式還是混雜模式,與網頁中的 DTD 直接相關。
1、如果文檔包含嚴格的 DOCTYPE ,那么它一般以嚴格模式呈現。(嚴格 DTD ——嚴格模式)?
2、包含過渡 DTD 和 URI 的 DOCTYPE ,也以嚴格模式呈現,但有過渡 DTD 而沒有 URI (統一資源標識符,就是聲明最后的地址)會導致頁面以混雜模式呈現。(有 URI 的過渡 DTD ——嚴格模式;沒有 URI 的過渡 DTD ——混雜模式)?
3、DOCTYPE 不存在或形式不正確會導致文檔以混雜模式呈現。(DTD不存在或者格式不正確——混雜模式)
4、HTML5 沒有 DTD ,因此也就沒有嚴格模式與混雜模式的區別,HTML5 有相對寬松的語法,實現時,已經盡可能大的實現了向后兼容。( HTML5 沒有嚴格和混雜之分)
意義:嚴格模式與混雜模式存在的意義與其來源密切相關,如果說只存在嚴格模式,那么許多舊網站必然受到影響,如果只存在混雜模式,那么會回到當時瀏覽器大戰時的混亂,每個瀏覽器都有自己的解析模式。
用JS判斷瀏覽器當前的模式:
- document.compatMode=='CSS1Compat'?'標準模式':'混雜模式';
- IE、Firefox、Opera、Sarari和Chrome都實現了這個屬性;
IE8的特殊情況:
IE8又為document對象引入了一個名為documentMode新屬性,這是因為IE8有3種不同的呈現模式,這個屬性的值如果是5,則表示混雜模式(即IE5模式);如果是7,則表示IE7仿真模式;如果是8,則表示IE8標準模式。
參考:Doctype作用?嚴格模式與混雜模式如何區分?它們有何差異?
get和post的區別
- 最直觀的區別就是GET把參數包含在URL中,POST通過request body傳遞參數。
- get只能傳輸少量數據(url長度限制),而post可傳輸的數據容量會更大
- GET比POST更不安全,因為參數直接暴露在URL上,所以不能用來傳遞敏感信息。
但是,最底層的區別是:GET產生一個TCP數據包;POST產生兩個TCP數據包。
GET和POST是什么?HTTP協議中的兩種發送請求的方法。
HTTP是什么?HTTP是基于TCP/IP的關于數據如何在萬維網中如何通信的協議。
HTTP的底層是TCP/IP。所以GET和POST的底層也是TCP/IP,也就是說,GET/POST都是TCP鏈接。GET和POST能做的事情是一樣一樣的。你要給GET加上request body,給POST帶上url參數,技術上是完全行的通的。?
對于GET方式的請求,瀏覽器會把http header和data一并發送出去,服務器響應200(返回數據)
而對于POST,瀏覽器先發送header,服務器響應100 continue,瀏覽器再發送data,服務器響應200 ok(返回數據)。
也就是說,GET只需要汽車跑一趟就把貨送到了,而POST得跑兩趟,第一趟,先去和服務器打個招呼“嗨,我等下要送一批貨來,你們打開門迎接我”,然后再回頭把貨送過去。
因為POST需要兩步,時間上消耗的要多一點,看起來GET比POST更有效。因此Yahoo團隊有推薦用GET替換POST來優化網站性能。但這是一個坑!跳入需謹慎。為什么?
1. GET與POST都有自己的語義,不能隨便混用。
2. 據研究,在網絡環境好的情況下,發一次包的時間和發兩次包的時間差別基本可以無視。而在網絡環境差的情況下,兩次包的TCP在驗證數據包完整性上,有非常大的優點。
3. 并不是所有瀏覽器都會在POST中發送兩次包,Firefox就只發送一次。
參考:GET和POST兩種基本請求方法的區別
h5新特性
語義化標簽
用最恰當的HTML元素標記的內容。
優點:
- 提升可訪問性
- SEO
- 結構清晰,利于維護
通用容器:
- div 塊級通用容器
- span 短語內容無語義容器
<title></title>:簡短、描述性、唯一(提升搜索引擎排名)。
搜索引擎會將title作為判斷頁面主要內容的指標,有效的title應該包含幾個與頁面內容密切相關的關鍵字,建議將title核心內容放在前60個字符中。<hn></hn>:h1~h6分級標題,用于創建頁面信息的層級關系。
對于搜索引擎而言,如果標題與搜索詞匹配,這些標題就會被賦予很高的權重,尤其是h1<header></header>:頁眉通常包括網站標志、主導航、全站鏈接以及搜索框。
也適合對頁面內部一組介紹性或導航性內容進行標記。<nav></nav>:標記導航,僅對文檔中重要的鏈接群使用。
Html5規范不推薦對輔助性頁腳鏈接使用nav,除非頁腳再次顯示頂級全局導航、或者包含招聘信息等重要鏈接。<main></main>:頁面主要內容,一個頁面只能使用一次。如果是web應用,則包圍其主要功能。
<article></article>:表示文檔、頁面、應用或一個獨立的容器。
article可以嵌套article,只要里面的article與外面的是部分與整體的關系。<section></section>:具有相似主圖的一組內容,比如網站的主頁可以分成介紹、新聞條目、聯系信息等條塊。
如果只是為了添加樣式,請用div<aside></aside>:指定附注欄,包括引述、側欄、指向文章的一組鏈接、廣告、友情鏈接、相關產品列表等。
如果放在main內,應該與所在內容密切相關。<footer></footer>:頁腳,只有當父級是body時,才是整個頁面的頁腳。
<small></small>:指定細則,輸入免責聲明、注解、署名、版權。
只適用于短語,不要用來不標記“使用條款”,“隱私政策”等長的法律聲明。
不單純的樣式標簽(有意義的,對搜索引擎抓取有強調意義 strong > em > cite)<strong></strong>:表示內容重要性。
<em></em>:標記內容著重點(大量用于提升段落文本語義)(斜體)
<cite></cite>:指明引用或者參考,如圖書的標題,歌曲、電影、等的名稱,演唱會、音樂會、規范、報紙、或法律文件等。(斜體)
<mark></mark>:突出顯示文本(黃色背景顏色),提醒讀者
<figure></figure>:創建圖(默認有40px左右margin)
<figcaption></figcaption>:figure的標題,必須是figure內嵌的第一個或者最后一個元素。
<blockquoto></blockquoto>:引述文本,默認新的一行顯示。
<time></time>:標記事件。datetime屬性遵循特定格式,如果忽略此屬性,文本內容必須是合法的日期或者時間格式。(不再相關的時間用s標簽)
<abbr></abbr>:解釋縮寫詞。使用title屬性可提供全稱,只在第一次出現時使用就可以了
<dfn></dfn>:定義術語元素,與定義必須緊挨著,可以在描述列表dl元素中使用。
<address></address>:作者、相關人士或組織的聯系信息(電子郵件地址、指向聯系信息頁的鏈接)表示一個具體的地址,字體為斜體,會自動換行
<del></del>:移除的內容。?<ins></ins>:添加的內容。
少有的既可以包圍塊級,又可以包圍短語內容的元素。<code></code>:標記代碼。包含示例代碼或者文件名 (< < > >)
<pre></pre>:預格式化文本。保留文本固有的換行和空格。
<meter></meter>:表示分數的值或者已知范圍的測量結果。如投票結果。
例如:<meter?value="0.2"?title=”Miles“>20%completed</meter><progress></progress>:完成進度。可通過js動態更新value。
標簽新屬性
細說data-* dataset(IE11,火狐谷歌)
在HTML5中我們可以使用data-前綴設置我們需要的自定義屬性,來進行一些數據的存放。通過dataset來獲取這些數據。這里的data-前綴就被稱為data屬性,其可以通過腳本進行定義,也可以應用CSS屬性選擇器進行樣式設置。數量不受限制,在控制和渲染數據的時候提供了非常強大的控制。
一個實例教你如何使用data dataset
例如我們要在一個文字按鈕上存放相對應的id下面是元素應用data屬性的一個例子:<div id="food" data-drink="coffee" data-food="sushi" data-meal="lunch">¥20.12</div>
// 要想獲取某個屬性的值,可以像下面這樣使用dataset對象:
var food = document.getElementById('food');
var typeOfDrink = food.dataset.drink;
classList(火狐谷歌最新,IE10以上)
- obj.classList.add() 添加class類
- obj.classList.remove() 移出class類
- obj.classList.contains() 判斷是否包含指定class類
- obj.classList.toggle() 切換class類
- obj.classList.length 獲取class類的個數
HTML5新表單
新的input類型
email 類型用于應該包含 e-mail 地址的輸入域。在提交表單時,會自動驗證 email 域的值。E-mail: <input type="email" name="user_email" />url
url 類型用于應該包含 URL 地址的輸入域。在提交表單時,會自動驗證 url 域的值。Homepage: <input type="url" name="user_url" />number
number 類型用于應該包含數值的輸入域。您還能夠設定對所接受的數字的限定:Points: <input type="number" name="points" min="1" max="10" />range
range 類型用于應該包含一定范圍內數字值的輸入域。range 類型顯示為滑動條。您還能夠設定對所接受的數字的限定:<input type="range" name="points" min="1" max="10" />search
search 類型用于搜索域,比如站點搜索或 Google 搜索。search 域顯示為常規的文本域。新的form屬性
autocomplete
autocomplete 屬性規定 form 或 input 域應該擁有自動完成功能。
注釋:autocomplete 適用于 <form> 標簽,以及以下類型的 <input> 標簽:text, search, url, telephone, email, password, datepickers, range 以及 color。<form action="demo_form.asp" method="get" autocomplete="on">E-mail: <input type="email" name="email" autocomplete="off" />
</form>novalidate
novalidate 屬性規定在提交表單時不應該驗證 form 或 input 域。
注釋:novalidate 屬性適用于 <form> 以及以下類型的 <input> 標簽:text, search, url, telephone, email, password, date pickers, range 以及 color.<form action="demo_form.asp" method="get" novalidate="true">E-mail: <input type="email" name="user_email" /><input type="submit" />
</form>新的input屬性
autocomplete
autocomplete 屬性規定 form 或 input 域應該擁有自動完成功能。
注釋:autocomplete 適用于 <form> 標簽,以及以下類型的 <input> 標簽:text, search, url, telephone, email, password, datepickers, range 以及 color。<form action="demo_form.asp" method="get" autocomplete="on">E-mail: <input type="email" name="email" autocomplete="off" />
</form>autofocus
autofocus 屬性規定在頁面加載時,域自動地獲得焦點。
注釋:autofocus 屬性適用于所有 <input> 標簽的類型。User name: <input type="text" name="user_name" autofocus="autofocus" />form
form 屬性規定輸入域所屬的一個或多個表單。
注釋:form 屬性適用于所有 <input> 標簽的類型。
form 屬性必須引用所屬表單的 id:<form action="demo_form.asp" method="get" id="user_form">First name:<input type="text" name="fname" /><input type="submit" />
</form>
Last name: <input type="text" name="lname" form="user_form" />form overrides (formaction, formenctype, formmethod, formnovalidate, formtarget)
表單重寫屬性(form override attributes)允許您重寫 form 元素的某些屬性設定。
- 表單重寫屬性有:1. formaction - 重寫表單的 action 屬性2. formenctype - 重寫表單的 enctype 屬性3. formmethod - 重寫表單的 method 屬性4. formnovalidate - 重寫表單的 novalidate 屬性5. formtarget - 重寫表單的 target 屬性
注釋:表單重寫屬性適用于以下類型的 <input> 標簽:submit 和 image。<form action="demo_form.asp" method="get" id="user_form">
E-mail: <input type="email" name="userid" /><br />
<input type="submit" value="Submit" />
<br />
<input type="submit" formaction="demo_admin.asp" value="Submit as admin" />
<br />
<input type="submit" formnovalidate="true" value="Submit without validation" />
<br />
</form>height 和 width 屬性
height 和 width 屬性規定用于 image 類型的 input 標簽的圖像高度和寬度。
注釋:height 和 width 屬性只適用于 image 類型的 <input> 標簽。<input type="image" src="img_submit.gif" width="99" height="99" />list 屬性
list 屬性規定輸入域的 datalist。datalist 是輸入域的選項列表。
注釋:list 屬性適用于以下類型的 <input> 標簽:text, search, url, telephone, email, date pickers, number, range 以及 color。Webpage: <input type="url" list="url_list" name="link" /><datalist id="url_list"><option label="W3Schools" value="http://www.w3school.com.cn" /><option label="Google" value="http://www.google.com" /><option label="Microsoft" value="http://www.microsoft.com" />
</datalist>min、max 和 step 屬性
min、max 和 step 屬性用于為包含數字或日期的 input 類型規定限定(約束)。
max 屬性規定輸入域所允許的最大值。
min 屬性規定輸入域所允許的最小值。
step 屬性為輸入域規定合法的數字間隔(如果 step="3",則合法的數是 -3,0,3,6 等)。
注釋:min、max 和 step 屬性適用于以下類型的 <input> 標簽:date pickers、number 以及 range。
下面的例子顯示一個數字域,該域接受介于 0 到 10 之間的值,且步進為 3(即合法的值為 0、3、6 和 9):Points: <input type="number" name="points" min="0" max="10" step="3" />multiple 屬性
multiple 屬性規定輸入域中可選擇多個值。
注釋:multiple 屬性適用于以下類型的 <input> 標簽:email 和 file。Select images: <input type="file" name="img" multiple="multiple" />novalidate 屬性
novalidate 屬性規定在提交表單時不應該驗證 form 或 input 域。
注釋:novalidate 屬性適用于 <form> 以及以下類型的 <input> 標簽:text, search, url, telephone, email, password, date pickers, range 以及 color.<form action="demo_form.asp" method="get" novalidate="true">E-mail: <input type="email" name="user_email" /><input type="submit" />
</form>pattern 屬性
pattern 屬性規定用于驗證 input 域的模式(pattern)。
注釋:pattern 屬性適用于以下類型的 <input> 標簽:text, search, url, telephone, email 以及 password。
下面的例子顯示了一個只能包含三個字母的文本域(不含數字及特殊字符):Country code: <input type="text" name="country_code"
pattern="[A-z]{3}" title="Three letter country code" />placeholder 屬性
placeholder 屬性提供一種提示(hint),描述輸入域所期待的值。
注釋:placeholder 屬性適用于以下類型的 <input> 標簽:text, search, url, telephone, email 以及 password。
提示(hint)會在輸入域為空時顯示出現,會在輸入域獲得焦點時消失:<input type="search" name="user_search" placeholder="Search W3School" />required 屬性
required 屬性規定必須在提交之前填寫輸入域(不能為空)。
注釋:required 屬性適用于以下類型的 <input> 標簽:text, search, url, telephone, email, password, date pickers, number, checkbox, radio 以及 file。Name: <input type="text" name="usr_name" required="required" />
音頻(audio)和視頻(video)
支持的格式和寫法
音頻元素支持的3種格式:Ogg MP3 Wav
<audio controls><source src="horse.ogg" type="audio/ogg"><source src="horse.mp3" type="audio/mpeg">您的瀏覽器不支持 audio 元素。
</audio>
視頻元素支持三種視頻格式:MP4、WebM、Ogg。
<video width="320" height="240" controls><source src="movie.mp4" type="video/mp4"><source src="movie.ogg" type="video/ogg">您的瀏覽器不支持 video 標簽。
</video>
標簽屬性
- 音視頻:autoplay、controls、loop、muted、preload、src
-
視頻:autoplay、controls、loop、muted、width、height、poster、preload、src
方法
- load():重新加載音頻/視頻元素
- play():開始播放音頻/視頻
- pause():暫停當前播放的音頻/視頻
事件
-
durationchange:當音頻/視頻的時長已更改時
-
ended:當目前的播放列表已結束時
-
pause:當音頻/視頻已暫停時
-
play:當音頻/視頻已開始或不再暫停時
-
ratechange:當音頻/視頻的播放速度已更改時
-
timeupdate:當目前的播放位置已更改時
- volumechange:當音量已更改時
事件屬性
-
只讀屬性
- duration:返回當前的總時長
- currentSrc:返回當前URL
- ended:返回是否已結束
- paused:返回是否已暫停
-
獲取并可修改的屬性:
- autoplay:設置或返回是否自動播放
- controls:設置或返回是否顯示控件(比如播放/暫停等)
- loop:設置或返回是否是循環播放
- muted:設置或返回是否靜音
- currentTime:設置或返回當前播放位置(以秒計)
- volume:設置或返回音量(規定音頻/視頻的當前音量。必須是介于 0.0 與 1.0 之間的數字。)
1.0 是最高音量(默認);0.5 是一半音量 (50%); 0.0 是靜音; - playbackRate:設置或返回播放速度
參考:HTML5新特性總結0804?
css3新特性
過渡
transition: CSS屬性,花費時間,效果曲線(默認ease),延遲時間(默認0)動畫
animation:動畫名稱,一個周期花費時間,運動曲線(默認ease),動畫延遲(默認0),播放次數(默認1),是否反向播放動畫(默認normal),是否暫停動畫(默認running)@keyframes logo1 {0%{transform:rotate(180deg);opacity: 0;}100%{transform:rotate(0deg);opacity: 1;}
}.logo-box .logo1{animation: logo1 1s ease-in 2s;animation-fill-mode:backwards;
}形狀轉換
transform:適用于2D或3D轉換的元素
transform-origin:轉換元素的位置(圍繞那個點進行轉換)。默認(x,y,z):(50%,50%,0)transform:rotate(30deg);
transform:translate(30px,30px);
transform:scale(.8);
transform: skew(10deg,10deg);選擇器
陰影
box-shadow: 水平陰影的位置 垂直陰影的位置 模糊距離 陰影的大小 陰影的顏色 陰影開始方向(默認是從里往外,設置inset就是從外往里);邊框
邊框圖片
border-image: 圖片url 圖像邊界向內偏移 圖像邊界的寬度(默認為邊框的寬度) 用于指定在邊框外部繪制偏移的量(默認0) 鋪滿方式--重復(repeat)、拉伸(stretch)或鋪滿(round)(默認:拉伸(stretch));.demo {border: 15px solid transparent;padding: 15px; border-image: url(border.png);border-image-slice: 30;border-image-repeat: round;border-image-outset: 0;
}邊框圓角
border-radius: n1,n2,n3,n4;
border-radius: n1,n2,n3,n4/n1,n2,n3,n4;
/*n1-n4四個值的順序是:左上角,右上角,右下角,左下角。*/background-size
文字
換行
語法:word-break: normal|break-all|keep-all;
語法:word-wrap: normal|break-word;
超出省略號這個,主要講text-overflow這個屬性,我直接講實例的原因是text-overflow的三個寫法,clip|ellipsis|string。clip這個方式處理不美觀,不優雅。string只在火狐兼容。
超出省略號
div
{width:200px; border:1px solid #000000;overflow:hidden;white-space:nowrap; text-overflow:ellipsis;
}多行超出省略號
超出省略號。這個對于大家來說,不難!但是以前如果是多行超出省略號,就只能用js模擬!現在css3提供了多行省略號的方法!遺憾就是這個暫時只支持webkit瀏覽器!
div
{width:400px;margin:0 auto;overflow : hidden;border:1px solid #ccc;text-overflow: ellipsis;display: -webkit-box;-webkit-line-clamp: 2;-webkit-box-orient: vertical;
}顏色
rgba
一個是rgba(rgb為顏色值,a為透明度)
hsla
h:色相”,“s:飽和度”,“l:亮度”,“a:透明度”
漸變
彈性布局——flex
盒模型定義
box-sizing這個屬性,網上說法是:屬性允許您以特定的方式定義匹配某個區域的特定元素。
- box-sizing:border-box的時候,邊框和padding包含在元素的寬高之內!
- box-sizing:content-box的時候,邊框和padding不包含在元素的寬高之內!
媒體查詢
rem布局——rem是根em(root em)的縮寫。rem是和根元素關聯的,不依賴當前元素。不管你在文檔中的什么地方使用這個單位,1.2rem的計算值是相等的,等于1.2倍的根元素的字號大小。
<!--主要I是強制讓文檔的寬度與設備寬度保持1:1,最大寬度1.0,禁止屏幕縮放。-->
<meta content="width=device-width,initial-scale=1.0,maximum-scale=1.0,user-scalable=no" name="viewport">@media screen and (max-width: 960px) {body {background-color: darkgoldenrod;}
}參考:個人總結(css3新特性)
?偽類與偽元素
css 引入偽類和偽元素概念是為了格式化文檔樹以外的信息。也就是說,偽類和偽元素是用來修飾不在文檔樹中的部分
對偽類和偽元素進行解釋:
偽類用于當已有元素處于的某個狀態時,為其添加對應的樣式,這個狀態是根據用戶行為而動態變化的。比如說,當用戶懸停在指定的元素時,我們可以通過:hover 來描述這個元素的狀態。雖然它和普通的 css 類相似,可以為已有的元素添加樣式,但是它只有處于 dom 樹無法描述的狀態下才能為元素添加樣式,所以將其稱為偽類。
偽元素用于創建一些不在文檔樹中的元素,并為其添加樣式。比如說,我們可以通過:before 來在一個元素前增加一些文本,并為這些文本添加樣式。雖然用戶可以看到這些文本,但是這些文本實際上不在文檔樹中。
偽類與偽元素的區別
偽類:
偽類:li:first-child {color: orange
}偽元素:p:first-letter {font-size: 5em;
}偽類的操作對象是文檔樹中已有的元素,而偽元素則創建了一個文檔數外的元素。因此,偽類與偽元素的區別在于:有沒有創建一個文檔樹之外的元素。
?偽元素是使用單冒號還是雙冒號?
CSS3 規范中的要求使用雙冒號 (::) 表示偽元素,以此來區分偽元素和偽類,比如::before 和::after 等偽元素使用雙冒號 (::),:hover 和:active 等偽類使用單冒號 (:)。除了一些低于 IE8 版本的瀏覽器外,大部分瀏覽器都支持偽元素的雙冒號 (::) 表示方法。
參考:偽類和偽元素
mongodb
參考:Mongodb的文件存儲GridFs
MongoDB是一個介于關系數據庫和非關系數據庫之間的產品,是非關系數據庫當中功能最豐富,最像關系數據庫的。它支持的數據結構非常松散,是類似json的bson格式,因此可以存儲比較復雜的數據類型。Mongo最大的特點是它支持的查詢語言非常強大,其語法有點類似于面向對象的查詢語言,幾乎可以實現類似關系數據庫單表查詢的絕大部分功能,而且還支持對數據建立索引。
為什么要用MongoDB
(1)MongoDB提出的是文檔、集合(多條記錄)的概念,使用BSON(類JSON)作為其數據模型結構,其結構是面向對象的而不是二維表,存儲一個用戶在MongoDB中是這樣子的。
{username:'123',password:'123'
}
使用這樣的數據模型,使得MongoDB能在生產環境中提供高讀寫的能力,吞吐量較于mysql等SQL數據庫大大增強。
(2)易伸縮,自動故障轉移。易伸縮指的是提供了分片能力,能對數據集進行分片,數據的存儲壓力分攤給多臺服務器。自動故障轉移是副本集的概念,MongoDB能檢測主節點是否存活,當失活時能自動提升從節點為主節點,達到故障轉移。
(3)數據模型因為是面向對象的,所以可以表示豐富的、有層級的數據結構,比如博客系統中能把“評論”直接懟到“文章“的文檔中,而不必像myqsl一樣創建三張表來描述這樣的關系。
支持嵌套域的查詢
查詢可以深入到嵌套的對象和數組中,如果下面的對象被插入到users集合:{"username" : "bob","address" : {"street" : "123 Main Street","city" : "Springfield","state" : "NY"}}我們可以這樣查詢嵌套在里層的域db.users.find({“address.state”:"NY”})數組元素則可以被這樣查詢:> db.food.insert({"fruit" : ["peach", "plum", "pear"]})> db.food.find({"fruit" : "pear"})幾個shell實操
因為本篇文章不是API手冊,所有這里對shell的使用也是基礎的介紹什么功能可以用什么語句,主要是為了展示使用MongoDB shell的方便性,如果需要知道具體的MongoDB shell語法可以查閱官方文檔。
1、切換數據庫
use dba
創建數據庫并不是必須的操作,數據庫與集合只有在第一次插入文檔時才會被創建,與對數據的動態處理方式是一致的。簡化并加速開發過程,而且有利于動態分配命名空間。如果擔心數據庫或集合被意外創建,可以開啟嚴格模式
2、插入語法
1db.users.insert({username:"smith"})
2db.users.save({username:"smith"})
3、查找語法
1 db.users.find()
2 db.users.count()
4、更新語法
1 db.users.update({username:"smith"},{$set:{country:"Canada"}})2 //把用戶名為smith的用戶的國家改成Canada34 db.users.update({username:"smith"},{$unset:{country:1}})5 //把用戶名為smith的用戶的國家字段給移除67 db.users.update({username:"jones"},{$set:{favorites:{movies:["casablance","rocky"]}}})8 //這里主要體現多值修改,在favorties字段中添加多個值9
10 db.users.update({"favorites.movies":"casablance"},{$addToSet:{favorites.movies:"the maltese"}},false,true)
11 //多項更新
5、刪除語法
1db.foo.remove() //刪除所有數據
2db.foo.remove({favorties.cities:"cheyene"}) //根據條件進行刪除
3db.drop() //刪除整個集合
6、索引相關語法
1db.numbers.ensureIndex({num:1})
2//創建一個升序索引
3db.numbers.getIndexes()
4//獲取全部索引
7、基本管理語法
1 show dbs2 //查詢所有數據庫3 show collections4 //顯示所有表5 db.stats()6 //顯示數據庫狀態信息7 db.numbers.stats()8 //顯示集合表狀態信息9 db,shutdownServer()
10 //停止數據庫
11 db.help()
12 //獲取數據庫操作命令
13 db.foo.help()
14 //獲取表操作命令
15 tab 鍵 //能自動幫我們補全命令Mongobd的重要模塊–GridFS
GridFS是Mongo的一個子模塊,使用GridFS可以基于MongoDB來持久存儲文件。并且支持分布式應用(文件分布存儲和讀取)。作為MongoDB中二進制數據存儲在數據庫中的解決方案,通常用來處理大文件,對于MongoDB的BSON格式的數據(文檔)存儲有尺寸限制,最大為16M。但是在實際系統開發中,上傳的圖片或者文件可能尺寸會很大,此時我們可以借用GridFS來輔助管理這些文件。
GridFS存儲原理
GridFS使用兩個集合(collection)存儲文件。一個集合是chunks, 用于存儲文件內容的二進制數據;一個集合是files,用于存儲文件的元數據。
GridFS會將兩個集合放在一個普通的buket中,并且這兩個集合使用buket的名字作為前綴。MongoDB的GridFs默認使用fs命名的buket存放兩個文件集合。因此存儲文件的兩個集合分別會命名為集合fs.files ,集合fs.chunks。
當把一個文件存儲到GridFS時,如果文件大于chunksize (每個chunk塊大小為256KB),會先將文件按照chunk的大小分割成多個chunk塊,最終將chunk塊的信息存儲在fs.chunks集合的多個文檔中。然后將文件信息存儲在fs.files集合的唯一一份文檔中。其中fs.chunks集合中多個文檔中的file_id字段對應fs.files集中文檔”_id”字段。
讀文件時,先根據查詢條件在files集合中找到對應的文檔,同時得到“_id”字段,再根據“_id”在chunks集合中查詢所有“files_id”等于“_id”的文檔。最后根據“n”字段順序讀取chunk的“data”字段數據,還原文件。
深入淺出mongoose
mongoose是nodeJS提供連接 mongodb的一個庫,類似于jquery和js的關系,對mongodb一些原生方法進行了封裝以及優化。簡單的說,Mongoose就是對node環境中MongoDB數據庫操作的封裝,一個對象模型工具,將數據庫中的數據轉換為JavaScript對象以供我們在應用中使用。
小程序
小程序提供了一個簡單、高效的應用開發框架和豐富的組件及API,幫助開發者在微信中開發具有原生 APP 體驗的服務。
整個小程序框架系統分為兩部分:邏輯層(App Service)和?視圖層(View)。小程序提供了自己的視圖層描述語言?WXML?和?WXSS,以及基于?JavaScript?的邏輯層框架,并在視圖層與邏輯層間提供了數據傳輸和事件系統,讓開發者能夠專注于數據與邏輯。
響應的數據綁定
框架的核心是一個響應的數據綁定系統,可以讓數據與視圖非常簡單地保持同步。當做數據修改的時候,只需要在邏輯層修改數據,視圖層就會做相應的更新。(聲明式渲染{{}})
頁面管理
框架 管理了整個小程序的頁面路由,可以做到頁面間的無縫切換,并給以頁面完整的生命周期。開發者需要做的只是將頁面的數據、方法、生命周期函數注冊到 框架 中,其他的一切復雜的操作都交由 框架 處理。
基礎組件
框架 提供了一套基礎的組件,這些組件自帶微信風格的樣式以及特殊的邏輯,開發者可以通過組合基礎組件,創建出強大的微信小程序?。
豐富的 API
框架 提供豐富的微信原生 API,可以方便的調起微信提供的能力,如獲取用戶信息,本地存儲,支付功能等。
云開發
開發者可以使用云開發開發微信小程序、小游戲,無需搭建服務器,即可使用云端能力。
云開發為開發者提供完整的原生云端支持和微信服務支持,弱化后端和運維概念,無需搭建服務器,使用平臺提供的 API 進行核心業務開發,即可實現快速上線和迭代,同時這一能力,同開發者已經使用的云服務相互兼容,并不互斥。
云開發提供了幾大基礎能力支持:
| 能力 | 作用 | 說明 |
|---|---|---|
| 云函數 | 無需自建服務器 | 在云端運行的代碼,微信私有協議天然鑒權,開發者只需編寫自身業務邏輯代碼 |
| 數據庫 | 無需自建數據庫 | 一個既可在小程序前端操作,也能在云函數中讀寫的 JSON 數據庫 |
| 存儲 | 無需自建存儲和 CDN | 在小程序前端直接上傳/下載云端文件,在云開發控制臺可視化管理 |
| 云調用 | 原生微信服務集成 | 基于云函數免鑒權使用小程序開放接口的能力,包括服務端調用、獲取開放數據等能力 |
js 深拷貝 vs 淺拷貝
堆和棧的區別
其實深拷貝和淺拷貝的主要區別就是其在內存中的存儲類型不同。
堆和棧都是內存中劃分出來用來存儲的區域。
棧(stack)為自動分配的內存空間,它由系統自動釋放;而堆(heap)則是動態分配的內存,大小不定也不會自動釋放。
對象
var obj = {a: 1, b: 2, c: { a: 3 },d: [4, 5]}
var obj1 = obj
var obj3 = {...obj}
var obj4 = Object.assign({},obj)
var obj2 = JSON.parse(JSON.stringify(obj))//深拷貝常用方法obj.a = 999
obj.c.a = -999
obj.d[0] = 123
console.log(obj1) //{a: 999, b: 2, c: { a: -999 },d: [123, 5]}
console.log(obj3) //{a: 1, b: 2, c: { a: -999 },d: [123, 5]}
console.log(obj4) //{a: 1, b: 2, c: { a: -999 },d: [123, 5]}
console.log(obj2) //{a: 1, b: 2, c: { a: 3 },d: [4, 5]}數組
var arr = [1, 2, 3, [4, 5], {a: 6, b: 7}]
var arr2 = arr
var arr3 = [...arr]
var arr4 = Object.assign([],arr)
var arr1 = JSON.parse(JSON.stringify(arr))//深拷貝常用方法console.log(arr === arr1) //false
console.log(arr === arr2) //true
console.log(arr === arr3) //false
console.log(arr === arr4) //false
arr[0]= 999
arr[3][0]= -999
arr[4].a = 123
console.log(arr1) //[1, 2, 3, [4, 5], {a: 6, b: 7}]
console.log(arr2) //[999, 2, 3, [-999, 5], {a: 123, b: 7}]
console.log(arr3) //[1, 2, 3, [-999, 5], {a: 123, b: 7}]
console.log(arr4) //[1, 2, 3, [-999, 5], {a: 123, b: 7}]深拷貝:
思路就是遞歸調用剛剛的淺拷貝,把所有屬于對象的屬性類型都遍歷賦給另一個對象即可。我們直接來看一下 Zepto 中深拷貝的代碼:
// 內部方法:用戶合并一個或多個對象到第一個對象// 參數:// target 目標對象 對象都合并到target里// source 合并對象// deep 是否執行深度合并function extend(target, source, deep) {for (key in source)if (deep && (isPlainObject(source[key]) || isArray(source[key]))) {// source[key] 是對象,而 target[key] 不是對象, 則 target[key] = {} 初始化一下,否則遞歸會出錯的if (isPlainObject(source[key]) && !isPlainObject(target[key]))target[key] = {}// source[key] 是數組,而 target[key] 不是數組,則 target[key] = [] 初始化一下,否則遞歸會出錯的if (isArray(source[key]) && !isArray(target[key]))target[key] = []// 執行遞歸extend(target[key], source[key], deep)}// 不滿足以上條件,說明 source[key] 是一般的值類型,直接賦值給 target 就是了else if (source[key] !== undefined) target[key] = source[key]}// Copy all but undefined properties from one or more// objects to the `target` object.$.extend = function(target){var deep, args = slice.call(arguments, 1);//第一個參數為boolean值時,表示是否深度合并if (typeof target == 'boolean') {deep = target;//target取第二個參數target = args.shift()}// 遍歷后面的參數,都合并到target上args.forEach(function(arg){ extend(target, arg, deep) })return target}在 Zepto 中的 $.extend 方法判斷的第一個參數傳入的是一個布爾值,判斷是否進行深拷貝。
在 $.extend 方法內部,只有一個形參 target,這個設計你真的很巧妙。
因為形參只有一個,所以 target 就是傳入的第一個參數的值,并在函數內部設置一個變量 args 來接收去除第一個參數的其余參數,如果該值是一個布爾類型的值的話,說明要啟用深拷貝,就將 deep 設置為 true,并將 target 賦值為 args 的第一個值(也就是真正的 target)。如果該值不是一個布爾類型的話,那么傳入的第一個值仍為 target 不需要進行處理,只需要遍歷使用 extend 方法就可以。
參考:js 深拷貝 vs 淺拷貝
瀏覽器的兼容性
所謂的瀏覽器兼容性問題,是指因為不同的瀏覽器對同一段代碼有不同的解析,造成頁面顯示效果不統一的情況。
- 漸進增強(progressive enhancement): 針對低版本瀏覽器進行構建頁面,保證最基本的功能,然后再針對高級瀏覽器進行效果、交互等改進和追加功能達到更好的用戶體驗
- 優雅降級`(graceful degradation): 一開始就構建完整的功能,然后再針對低版本瀏覽器進行兼容。
Web標準以及W3C
?Web標準是由萬維網聯盟(W3C)制訂的,WEB標準的產生,網頁內容能被更多的用戶所訪問到,文件下載和頁面顯示速度更快,所有頁面都能提供適合打印的版本,網頁開發人員開發更快捷,代碼更易于維護,提高了搜索引擎的精確性,提高了網站的易用性。
? 我們需要注意的代碼標準有:
拋棄聲明:以后我們將拋棄font標簽,新的頁面中不應該再出現如<font color=”red”></font>,已經存在的老的頁面也應該在修改時盡量替代,替代方法:<span
class=”red_tex”></span>。一個標準XHTML頭信息格式如下:<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="http://www.w3.org/1999/xhtml" lang="gb2312">
<head> <meta charset="utf-8" /> <title>W3Cschool - 學技術查資料,從w3cschool開始!</title><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1" /><meta name="renderer" content="webkit" /><meta name="viewport" content="width=device-width, initial-scale=1" /><meta name="keywords" content="w3cschool,w3cschool在線教程,技術文檔,編程入門教程,W3Cschool,W3C,HTML,HTML5,CSS,Javascript,jQuery,Bootstrap,PHP,Java,Sql" /><meta name="description" content="w3cschool是一個專業的編程入門學習及技術文檔查詢網站,提供包括HTML,CSS,Javascript,jQuery,C,PHP,Java,Python,Sql,Mysql等編程語言和開源技術的在線教程及使用手冊,是類國外W3Cschool的W3C學習社區及菜鳥編程平臺。" />
</head>1、什么是DOCTYPE
DOCTYPE是document type(文檔類型)的簡寫,用來說明你用的XHTML或者HTML是什么版本。其中的DTD(例如xhtml1-transitional.dtd)叫文檔類型定義,里面包含了文檔的規則,瀏覽器就根據你定義的DTD來解釋你頁面的標識,并展現出來。要建立符合標準的網頁,DOCTYPE聲明是必不可少的關鍵組成部分;除非你的XHTML確定了一個正確的DOCTYPE,否則你的標識和CSS都不會生效。
XHTML 1.0 提供了三種DTD聲明可供選擇:
i) 過渡的(Transitional):要求非常寬松的DTD,它允許你繼續使用HTML4.01的標識(但是要符合xhtml的寫法)。
完整代碼如下:<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
ii) 嚴格的(Strict):要求嚴格的DTD,你不能使用任何表現層的標識和屬性,例如<br>。
完整代碼如下:<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
iii) 框架的(Frameset):專門針對框架頁面設計使用的DTD,如果你的頁面中包含有框架,需要采用這種DTD。
完整代碼如下:<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd">
注:DOCTYPE聲明必須放在每一個XHTML文檔最頂部,在所有代碼和標識之上。html5 : 沒有DTD
<!DOCTYPE html>2、名字空間 namespace
<html xmlns="http://www.w3.org/1999/xhtml" lang="gb2312">
通常我們HTML4.0的代碼只是<html>,這里的"xmlns"是什么呢?
這個“xmlns”是XHTML namespace的縮寫,叫做“名字空間”聲明。XHTML是HTML向XML過渡的標識語言,它需要符合XML文檔規則,因此也需要定義名字空間。又因為XHTML1.0不能自定義標識,所以它的名字空間都相同,就是"http://www.w3.org/1999/xhtml"。目前階段我們只要照抄代碼就可以了。3、定義語言編碼
<meta http-equiv=“Content-Type” content=“text/html; charset=gb2312” />
為了被瀏覽器正確解釋和通過W3C代碼校驗,所有的XHTML文檔都必須聲明它們所使用的編碼語言,我們一般使用gb2312(簡體中文),制作多國語言頁面也有可能用Unicode、ISO-8859-1等,根據你的需要定義。
注:如果忘記了定義語言編碼,可能就會出現,你在DW(dreamweaver)做完一個頁面,第二次打開時所有的中文變成了亂碼。<meta charset="utf-8">4、Javascript定義
Js必須要用<script language="javascript" type="text/javascript">來開頭定義,而不是原來的<script language=javascript>或干脆直接<script>,并且需要加個注釋符<!-- -->,以保證不在不支持js的瀏覽器上直接顯示出代碼來。
例如:<script language="javascript" type="text/javascript">
//<![CDATA[
function show_layout(selObj){
var n = selObj.options[selObj.selectedIndex].value;
document.getElementById('stylesheet').href = n;
}
//]]>
</script> 注:具體參考js規范。5、CSS定義
CSS必須要用<style type=“text/css”>開頭來定義,而不是原來的直接<style>,也不建議直接寫在內容代碼里如:<div style=”padding-left:20px;”></div>,并需要加個注釋符<!-- -->
例如:<style type="text/css" media="screen">
<!--
body {margin:0px;padding:0px;font-size:12px;text-align:center}
-->
</style>
為保證各瀏覽器的兼容性,在寫CSS時請都寫上數量單位,例如:錯誤:.space_10{padding-left:10} 正確:.space_10 {padding-left:10px}6、不要在注釋內容中使用“--”
“--”只能發生在XHTML注釋的開頭和結束,也就是說,在內容中它們不再有效。
例如下面的代碼是無效的:<!--這里是注釋-----------這里是注釋-->
正確的應用等號或者空格替換內部的虛線。<!--這里是注釋============這里是注釋-->7、所有標簽的元素和屬性的名字都必須使用小寫
與HTML不一樣,XHTML對大小寫是敏感的,<title>和<TITLE>是不同的標簽。XHTML要求所有的標簽和屬性的名字都必須使用小寫。例如:<BODY>必須寫成<body>。大小寫夾雜也是不被認可的,通常dreamweaver自動生成的屬性名字"onMouseOver"也必須修改成"onmouseover"。8、所有的屬性必須用引號""括起來
在HTML中,你可以不需要給屬性值加引號,但是在XHTML中,它們必須被加引號。
例如:<height=80>必須修改為:<height="80">。
特殊情況,你需要在屬性值里使用雙引號,你可以用",單引號可以使用',例如:<alt="say'hello'">9、把所有<和&特殊符號用編碼表示
任何小于號(<),不是標簽的一部分,都必須被編碼為 <
任何大于號(>),不是標簽的一部分,都必須被編碼為 >
任何與號(&),不是實體的一部分的,都必須被編碼為 &
錯誤:
http://club.china.alibaba.com/forum/thread/search_forum.html?action=SearchForum&doSearchForum=true&main=1&catcount=10&keywords=mp3
正確:
http://club.china.alibaba.com/forum/thread/search_forum.html?action=SearchForum&doSearchForum=true&main=1&catcount=10&keywords=mp310、給所有屬性賦一個值
XHTML規定所有屬性都必須有一個值,沒有值的就重復本身。例如:
<td nowrap><input type="checkbox" name="shirt" value="medium" checked>必須修改為:
<td nowrap="nowrap"><input type="checkbox" name="shirt" value="medium" checked="checked" />11、所有的標記都必須要有一個相應的結束標記
以前在HTML中,你可以打開許多標簽,例如<p>和<li>而不一定寫對應的</p>和</li>來關閉它們。但在XHTML中這是不合法的。XHTML要求有嚴謹的結構,所有標簽必須關閉。如果是單獨不成對的標簽,在標簽最后加一個"/"來關閉它。
例如:<br />
<img height="80" alt="網頁" title=”網頁” src="logo.gif" width="200" />特殊結束標記
錯誤:
Document.write("<td width=\"300\"><a href=\"1.html\">ok</a></td>");
正確:
Document.write("<td width=\"300\"><a href=\"1.html\">ok<\/a><\/td>");
在js中,原已結束的標簽需要再轉義再結束。12、所有的標記都必須合理嵌套
同樣因為XHTML要求有嚴謹的結構,因此所有的嵌套都必須按順序,以前我們這樣寫的代碼:
<p><b></p></b>必須修改為:<p><b></b></p>
就是說,一層一層的嵌套必須是嚴格對稱。
錯誤:
<table><tr><form><td></td></form></tr></table>
正確:
<form><table><tr><td></td></tr></table></form>13、圖片添加有意義的alt屬性
例如:<img src="logo.gif" width="100" height="100" align="middle" boder="0" alt="w3cschool" />
盡可能的讓作為內容的圖片都帶有屬于自己的alt屬性。
同理:添加文字鏈接的title屬性。
<a href="#" target="_blank" title="新聞新聞新聞新聞">新聞新聞…</a>,在一些限定字數的內容展示尤為重要,幫助顯示不完成的內容顯示完整,而不用考慮頁面會因此而撐大。14、在form表單中增加lable,以增加用戶友好度
例如:<form action="http://somesite.com/prog/adduser" method="post"><label for="firstname">first name: </label><input type="text" id="firstname" /><label for="lastname">last name: </label><input type="text" id="lastname" />
</form>主流瀏覽器的內核
??? 瀏覽器內核主要指的是瀏覽器的渲染引擎,渲染引擎決定了瀏覽器如何加載和顯示網頁的內容以及信息。我們主要用于測試的瀏覽器都有:IE、Chrome、Firefox、Safari、Opera、360瀏覽器。
- IE:trident內核(IE內核)
- Firefox:geoko內核,Mozilla自己開發的一套開放源代碼、以C++編寫的渲染引擎。
- Safari:webkit內核,開源的瀏覽器引擎,源自于Linux平臺上的一個引擎,經過Apple公司的修改可以支持Mac與Windows平臺。
- Chrome:Blink內核,Google和Opera Software共同研發。
- Opera:以前是presto內核,現在改為Blink內核。
- 360瀏覽器: 兼容模式(trident內核)、極速模式(Blink內核)。
?標準模式(Standards Mode)和怪異模式 (Quirks Mode)
??? 在Netscape Navigator和Microsoft Internet Explorer為數不多的瀏覽器盛行時,他們對網頁有不同的實現方式,那個時候的網頁都是針對這兩個瀏覽器寫的。隨著各種瀏覽器的興起,加上Web標準的制定,現在的瀏覽器不能繼續使用以前的頁面了,所以瀏覽器引入了標準模式和怪異模式來解決這一問題。
??? 標準模式就是瀏覽器按照Web標準來渲染頁面;為了解決瀏覽器還是能使用以前寫的頁面,所以怪異模式就產生了。怪異模式在不同的瀏覽器顯示都是不一樣的,因為他們都是按照自己的方式來渲染頁面。
??? 我們知道了標準模式和怪異模式,可是瀏覽器是怎么選擇模式來渲染頁面的呢?我們經常在頁面的開頭看到<!DOCTYPE>聲明,這是告訴瀏覽器選擇哪個版本的HTML,對于渲染模式的選擇,瀏覽器是根據DTD的聲明。如果網頁中有DTD標準文檔的聲明,那瀏覽器會按照標準模式來渲染網頁;如果網頁沒有DTD聲明或者HTML4以下的DTD聲明,那瀏覽器就按照自己的方式渲染頁面,頁面進入怪異模式。
CSS盒模型
??? 如果想要了解詳細解說,請移至:http://www.cnblogs.com/ylliap/p/6119740.html
??? 盒模型指定元素如何顯示,理解它,對我們的布局有很大的幫助。盒模型由內容(content)、內邊距(padding)、邊框(border)、外邊距(margin)組成。
??? 盒模型有兩種:IE盒模型(圖1)、標準的W3C盒模型(圖2)。從圖1和圖2就可以看出,IE盒模型的width包括了border、padding、content,而W3C盒模型的width僅限于content。
??? 在CSS3的屬性中,box-sizing可以設置盒模型類型,默認值為content-box,content-box表示W3C盒模型,border-box表示IE盒模型。
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?圖1. IE盒模型? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?圖2. W3C盒模型
重置瀏覽器樣式
??? 不同的瀏覽器對標簽的默認樣式值不同,所以我們需要有一套樣式表來重置瀏覽器樣式,避免我們寫的網頁在各個瀏覽器中造成的顯示差異。
可以使用Normalize.css只是一個很小的css文件,但它在默認的HTML元素樣式上提供了跨瀏覽器的高度一致性。相比于傳統的css reset,Normalize.css是一種現代的,為HTML5準備的優質替代方案。
Normalize.css只是一個很小的css文件,但它在默認的HTML元素樣式上提供了跨瀏覽器的高度一致性。相比于傳統的css reset,Normalize.css是一種現代的,為HTML5準備的優質替代方案。
表現與數據分離
也可以說是界面與數據分離,要體現在代碼上,操作數據的代碼和操作界面的代碼,要分開寫。
優勢:當頁面需求發生改變,只需要改寫界面的代碼,并且修改的代碼不能影響到操作數據訪問的代碼。
如MVVM框架,就是視圖與數據分離,具體為:數據模型以及業務邏輯為model,保存具體數據以及操作數據行為(增刪改查更新等)的方法。操作DOM視圖的方法分為view
參考:【web前端面試題整理07】我不理解表現與數據分離。。。、
各主流瀏覽器之間的兼容性-JS篇
HTML語義化
??? HTML語義化就是頁面去掉樣式或者加載失敗的時候能夠讓頁面呈現出清晰的結構。HTML5新增了好多標簽,例如:header、footer、nav、menu、section、article等等,我們單單從字面上理解,就知道標簽的含義。在寫頁面的時候,我們可以直接引用這些標簽,不需要再用沒有任何含義的div標簽了,對于機器可以識別,對于開發人員,很容易明白,這就是HTML語義化。
??? HTML語義化的好處有:有利于SEO優化,利于被搜索引擎收錄,更便于搜索引擎的爬蟲程序來識別;便于項目的開發及維護,使HTML代碼更具有可讀性,便于其他設備解析。
CSS選擇器優先級
??? 掌握選擇器優先級,再也不用!important來到處打補丁。
??? CSS的基本選擇器:
- id選擇器(用DOM的id申明)
- 類選擇器(用一個樣式類名申明)和偽類
- 屬性選擇器(用DOM的屬性申明)
- 標簽選擇器(用HTML標簽申明)和偽元素
??? 還有一種添加樣式可以在標簽上直接添加,屬于行內樣式。
??? 在這里,我們只做簡單說明,以上面幾種選擇器來排序:行內元素 < id選擇器 < 類選擇器/屬性選擇器 < 標簽選擇器。
通配選擇符(universal selector)(*)關系選擇符(combinators)(+,?>,?~,?'?',?||)和?否定偽類(negation pseudo-class)(:not())對優先級沒有影響。(但是,在?:not()?內部聲明的選擇器會影響優先級)。
清除浮動
??? 如果容器中有浮動的元素,容器的高度不能自動延長適應內容的高度,使得內容溢出到容器外而影響頁面布局,為了避免這種情況的發生,我們需要用CSS來清除元素的浮動。
??? 一般常用的方法有三種:
??? A. 在浮動元素后面添加帶有clear屬性的空元素
<div><div style="float: left;">left</div><div style="float: right;">right</div><div style="clear: both;"></div>
</div>??? B. 給容器添加屬性overflow: hidden或者overflow: auto,在IE6中還需觸發haslayout,所以還需添加zoom: 1。
<div style="overflow: auto;*zoom: 1;"><div style="float: left;">left</div><div style="float: right;">right</div>
</div>??? C. 使用:after偽元素
<style>.clearfix {*zoom: 1;}.clearfix:after {content: ".";display: block;height: 0;visibility: hidden;clear: both;}
</style><div class="clearfix"><div style="float: left;">left</div><div style="float: right;">right</div>
</div>參與:各大瀏覽器兼容性問題總結
響應式布局和自適應布局詳解
響應式布局等于流動網格布局,而自適應布局等于使用固定分割點來進行布局。
自適應布局給了你更多設計的空間,因為你只用考慮幾種不同的狀態。而在響應式布局中你卻得考慮上百種不同的狀態。雖然絕大部分狀態差異較小,但仍然也算做差異。它使得把握設計最終效果變得更難,同樣讓響應式布局更加的難以測試和預測。
響應式布局概念
Responsive design,意在實現不同屏幕分辨率的終端上瀏覽網頁的不同展示方式。通過響應式設計能使網站在手機和平板電腦上有更好的瀏覽閱讀體驗。
響應式設計的步驟
1. 設置 Meta 標簽
多數移動瀏覽器將HTML頁面放大為寬的視圖(viewport)以符合屏幕分辨率。你可以使用視圖的meta標簽來進行重置。下面的視圖標簽告訴瀏覽器,使用設備的寬度作為視圖寬度并禁止初始的縮放。在<head>標簽里加入這個meta標簽。
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1, user-scalable=no">[1](user-scalable = no 屬性能夠解決 iPad 切換橫屏之后觸摸才能回到具體尺寸的問題。?)
3. 通過媒介查詢來設置樣式 Media Queries
原文鏈接:http://caibaojian.com/356.html
Media Queries 是響應式設計的核心。·
它根據條件告訴瀏覽器如何為指定視圖寬度渲染頁面。假如一個終端的分辨率小于 980px,那么可以這樣寫:
//code from http://caibaojian.com/356.html
@media screen and (max-width: 980px) {#head { … }#content { … }#footer { … }
}這里的樣式就會覆蓋上面已經定義好的樣式。
原文鏈接:http://caibaojian.com/356.html
4. 設置多種試圖寬度
假如我們要設定兼容 iPad 和 iphone 的視圖,那么可以這樣設置:·
//code from http://caibaojian.com/356.html
/** iPad **/
@media only screen and (min-width: 768px) and (max-width: 1024px) {}
/** iPhone **/
@media only screen and (min-width: 320px) and (max-width: 767px) {}一些注意的
例如這樣:
#head { width: 100% }
#content { width: 50%; }- 簡單的解決方法可以使用百分比,但這樣不友好,會放大或者縮小圖片。那么可以嘗試給圖片指定的最大寬度為百分比。假如圖片超過了,就縮小。假如圖片小了,就原尺寸輸出。
img { width: auto; max-width: 100%; }- 用
::before和::after偽元素 +content 屬性來動態顯示一些內容或者做其它很酷的事情,在?css3?中,任何元素都可以使用 content 屬性了,這個方法就是結合 css3 的 attr 屬性和?HTML?自定義屬性的功能: HTML 結構:
<img src="image.jpg"data-src-600px="image-600px.jpg"data-src-800px="image-800px.jpg"alt="">CSS?控制:
@media (min-device-width:600px) {img[data-src-600px] {content: attr(data-src-600px, url);}
}@media (min-device-width:800px) {img[data-src-800px] {content: attr(data-src-800px, url);}
}例如?pre?,iframe,video?等,都需要和img一樣控制好寬度。對于table,建議不要增加 padding 屬性,低分辨率下使用內容居中:
table?th, table?td { padding: 0 0; text-align: center; }
以上內容和代碼來自:掌心,感謝,歡迎查看我之前做過的響應式設計:查看演示打造布局結構
我們可以監測頁面布局隨著不同的瀏覽環境而產生的變化,如果它們變的過窄過短或是過寬過長,則通過一個子級樣式表來繼承主樣式表的設定,并專門針對某些布局結構進行樣式覆寫。我們來看下代碼示例:
/* Default styles that will carry to the child style sheet */
html,body{background...font...color...
}
h1,h2,h3{}
p, blockquote, pre, code, ol, ul{}
/* Structural elements */
#wrapper{width: 80%;margin: 0 auto;background: #fff;padding: 20px;
}
#content{width: 54%;float: left;margin-right: 3%;
}
#sidebar-left{width: 20%;float: left;margin-right: 3%;
}
#sidebar-right{width: 20%;float: left;
}下面的代碼可以放在子級樣式表Mobile.css中,專門針對移動設備進行樣式覆寫:
#wrapper{width: 90%;
}
#content{width: 100%;
}
#sidebar-left{width: 100%;clear: both;/* Additional styling for our new layout */border-top: 1px solid #ccc;margin-top: 20px;
}
#sidebar-right{width: 100%;clear: both;/* Additional styling for our new layout */border-top: 1px solid #ccc;margin-top: 20px;
}大致的視覺效果如下圖所示:
橫屏與豎屏的區別
?
圖中上半部分是大屏幕設備所顯示的完整頁面,下面的則是該頁面在小屏幕設備的呈現方式。頁面HTML代碼如下:
Ethan的文章中的“Meet the media query”部分有更多的范例及解釋。更有效率的做法是,將多個media queries整合在一個樣式表文件中
/* Smartphones (portrait and landscape) ----------- */
@media only screen
and (min-device-width : 320px)
and (max-device-width : 480px) {
/* Styles */
}
/* Smartphones (landscape) ----------- */
@media only screen
and (min-width : 321px) {
/* Styles */
}
/* Smartphones (portrait) ----------- */
@media only screen
and (max-width : 320px) {
/* Styles */
}譯文:流動網格
rem是如何實現自適應布局的?
rem是什么?
rem(font?size?of?the?root?element)是指相對于根元素的字體大小的單位。簡單的說它就是一個相對單位。看到rem大家一定會想起em單位,em(font?size?of?the?element)是指相對于父元素的字體大小的單位。它們之間其實很相似,只不過一個計算的規則是依賴根元素一個是依賴父元素計算。·
為什么web?app要使用rem?
這里我特別強調web?app,web?page就不能使用rem嗎,其實也當然可以,不過出于兼容性的考慮在web?app下使用更加能突顯這個單位的價值和能力,接下來我們來看看目前一些企業的web app是怎么做屏幕適配的。·
1、實現強大的屏幕適配布局:
最近iphone6一下出了兩款尺寸的手機,導致的移動端的屏幕種類更加的混亂,記得一兩年前做web?app有一種做法是以320寬度為標準去做適配,超過320的大小還是以320的規格去展示,這種實現方式以淘寶web?app為代表作,但是近期手機淘寶首頁進行了改版,采用了rem這個單位,首頁以內依舊是和以前一樣各種混亂,有定死寬度的頁面,也有那種流式布局的頁面。
我們現在在切頁面布局的使用常用的單位是px,這是一個絕對單位,web?app的屏幕適配有很多中做法,例如:流式布局、限死寬度,還有就是通過響應式來做,但是這些方案都不是最佳的解決方法。
例如流式布局的解決方案有不少弊端,它雖然可以讓各種屏幕都適配,但是顯示的效果極其的不好,因為只有幾個尺寸的手機能夠完美的顯示出視覺設計師和交互最想要的效果,但是目前行業里用流式布局切web?app的公司還是挺多的
上面的網站都是采用的流式布局的技術實現的,他們在頁面布局的時候都是通過百分比來定義寬度,但是高度大都是用px來固定住,所以在大屏幕的手機下顯示效果會變成有些頁面元素寬度被拉的很長,但是高度還是和原來一樣,實際顯示非常的不協調,這就是流式布局的最致命的缺點,往往只有幾個尺寸的手機下看到的效果是令人滿意的,其實很多視覺設計師應該無法接受這種效果,因為他們的設計圖在大屏幕手機下看到的效果相當于是被橫向拉長來一樣。
流式布局并不是最理想的實現方式,通過大量的百分比布局,會經常出現許多兼容性的問題,還有就是對設計有很多的限制,因為他們在設計之初就需要考慮流式布局對元素造成的影響,只能設計橫向拉伸的元素布局,設計的時候存在很多局限性。·
2.固定寬度做法
還有一種是固定頁面寬度的做法,早期有些網站把頁面設置成320的寬度,超出部分留白,這樣做視覺,前端都挺開心,視覺在也不用被流式布局限制自己的設計靈感了,前端也不用在搞坑爹的流式布局。但是這種解決方案也是存在一些問題,例如在大屏幕手機下兩邊是留白的,還有一個就是大屏幕手機下看起來頁面會特別小,操作的按鈕也很小,手機淘寶首頁起初是這么做的,但近期改版了,采用了rem。
3.響應式做法
響應式這種方式在國內很少有大型企業的復雜性的網站在移動端用這種方法去做,主要原因是工作大,維護性難,所以一般都是中小型的門戶或者博客類站點會采用響應式的方法從web page到web app直接一步到位,因為這樣反而可以節約成本,不用再專門為自己的網站做一個web app的版本。
4.設置viewport進行縮放
天貓的web app的首頁就是采用這種方式去做的,以320寬度為基準,進行縮放,最大縮放為320*1.3 = 416,基本縮放到416都就可以兼容iphone6 plus的屏幕了,這個方法簡單粗暴,又高效。說實話我覺得他和用接下去我們要講的rem都非常高效,不過有部分同學使用過程中反應縮放會導致有些頁面元素會糊的情況。
<meta name="viewport" content="width=320,maximum-scale=1.3,user-scalable=no">rem能等比例適配所有屏幕
上面講了一大堆目前大部分公司主流的一些web app的適配解決方案,接下來講下rem是如何工作的。
上面說過rem是通過根元素進行適配的,網頁中的根元素指的是html我們通過設置html的字體大小就可以控制rem的大小。舉個例子:
//code from http://caibaojian.com/web-app-rem.html
html{font-size:20px;
}
.btn {width: 6rem;height: 3rem;line-height: 3rem;font-size: 1.2rem;display: inline-block;background: #06c;color: #fff;border-radius: .5rem;text-decoration: none;text-align: center;
}Demo 上面代碼結果按鈕大小如下圖:
小button
?
我把html設置成10px是為了方便我們計算,為什么6rem等于60px。如果這個時候我們的.btn的樣式不變,我們再改變html的font-size的值,看看按鈕發生上面變化:
html{font-size:40px;
}Demo
按鈕大小結果如下:
2倍小button
?
上面的width,height變成了上面結果的兩倍,我們只改變了html的font-size,但.btn樣式的width,height的rem設置的屬性不變的情況下就改變了按鈕在web中的大小。
其實從上面兩個案例中我們就可以計算出1px多少rem:
第一個例子:
120px = 6rem * 20px(根元素設置大值)
第二個例子:
240px = 6rem * 40px(根元素設置大值)
推算出:
10px ?= 1rem 在根元素(font-size = 10px的時候);
20px ?= 1rem 在根元素(font-size = 20px的時候);
40px ?= 1rem 在根元素(font-size = 40px的時候);
在上面兩個例子中我們發現第一個案例按鈕是等比例放大到第二個按鈕,html font-size的改變就會導致按鈕的大小發生改變,我們并不需要改變先前給按鈕設置的寬度和高度,其實這就是我們最想看到的,為什么這么說?接下來我們再來看一個例子:
?
由上面兩個的demo中我們知道改變html的font-size可以等比改變所有用了rem單位的元素,所以大家可以通過chrome瀏覽器的調試工具去切換第三個的demo在不同設備下的展示效果,或者通過縮放瀏覽器的寬度來查看效果,我們可以看到不管在任何分辨率下,頁面的排版都是按照等比例進行切換,并且布局沒有亂。我只是通過一段js根據瀏覽器當前的分辨率改變font-size的值,就簡單的實現了上面的效果,頁面的所有元素都不需要進行任何改變。
到這里肯定有很多人會問我是怎么計算出不同分辨率下font-size的值?
首先假設我上面的頁面設計稿給我時候是按照640的標準尺寸給我的前提下,(當然這個尺寸肯定不一定是640,可以是320,或者480,又或是375)來看一組表格。
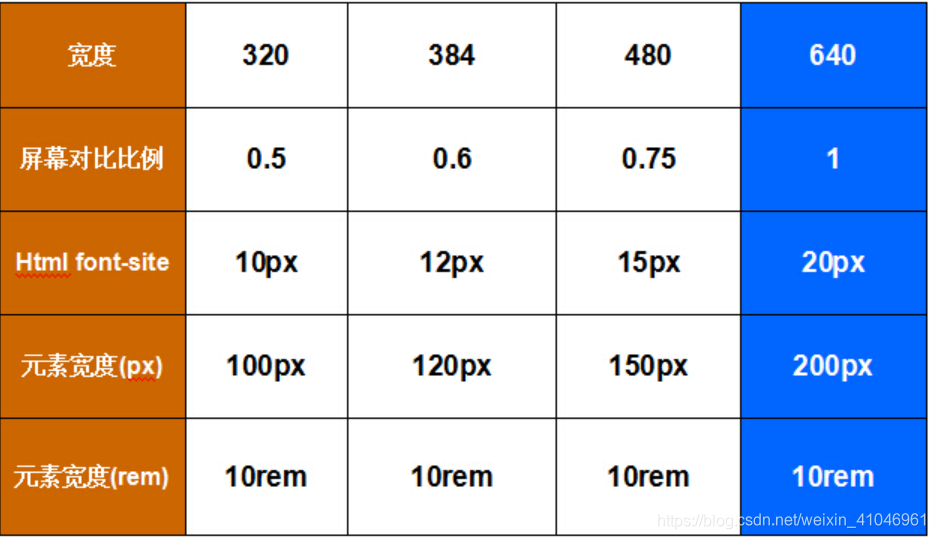
上面的表格藍色一列是Demo3中頁面的尺寸,頁面是以640的寬度去切的,怎么計算不同寬度下font-site的值,大家看表格上面的數值變化應該能明白。舉個例子:384/640 = 0.6,384是640的0.6倍,所以384頁面寬度下的font-size也等于它的0.6倍,這時384的font-size就等于12px。在不同設備的寬度計算方式以此類推。·
Demo3中我是通過JS去動態計算根元素的font-size,這樣的好處是所有設備分辨率都能兼容適配,淘寶首頁目前就是用的JS計算。但其實不用JS我們也可以做適配,一般我們在做web app都會先統計自己網站有哪些主流的屏幕設備,然后去針對那些設備去做media query設置也可以實現適配,例如下面這樣:
//code from http://caibaojian.com/web-app-rem.html
html {font-size : 20px;
}
@media only screen and (min-width: 401px){html {font-size: 25px !important;}
}
@media only screen and (min-width: 428px){html {font-size: 26.75px !important;}
}
@media only screen and (min-width: 481px){html {font-size: 30px !important; }
}
@media only screen and (min-width: 569px){html {font-size: 35px !important; }
}
@media only screen and (min-width: 641px){html {font-size: 40px !important; }
}上面的做的設置當然是不能所有設備全適配,但是用JS是可以實現全適配。具體用哪個就要根據自己的實際工作場景去定了。
下面推薦兩個國內用了rem技術的移動站,大家可以上去參考看看他們的做法,手機淘寶目前只有首頁用了rem,淘寶native app的首頁是內嵌的web app首頁。
淘寶首頁:m.taobao.com
D X:m.dx.com
原文鏈接:http://caibaojian.com/web-app-rem.html
REM自適應JS
具體使用方法請參考這篇文章:Rem精簡版實現自適應-優化flexible.js·
//code from http://caibaojian.com/web-app-rem.html
//designWidth:設計稿的實際寬度值,需要根據實際設置
//maxWidth:制作稿的最大寬度值,需要根據實際設置
//這段js的最后面有兩個參數記得要設置,一個為設計稿實際寬度,一個為制作稿最大寬度,例如設計稿為750,最大寬度為750,則為(750,750)
;(function(designWidth, maxWidth) {var doc = document,win = window,docEl = doc.documentElement,remStyle = document.createElement("style"),tid;function refreshRem() {var width = docEl.getBoundingClientRect().width;maxWidth = maxWidth || 540;width>maxWidth && (width=maxWidth);var rem = width * 100 / designWidth;remStyle.innerHTML = 'html{font-size:' + rem + 'px;}';}if (docEl.firstElementChild) {docEl.firstElementChild.appendChild(remStyle);} else {var wrap = doc.createElement("div");wrap.appendChild(remStyle);doc.write(wrap.innerHTML);wrap = null;}//要等 wiewport 設置好后才能執行 refreshRem,不然 refreshRem 會執行2次;refreshRem();win.addEventListener("resize", function() {clearTimeout(tid); //防止執行兩次tid = setTimeout(refreshRem, 300);}, false);win.addEventListener("pageshow", function(e) {if (e.persisted) { // 瀏覽器后退的時候重新計算clearTimeout(tid);tid = setTimeout(refreshRem, 300);}}, false);if (doc.readyState === "complete") {doc.body.style.fontSize = "16px";} else {doc.addEventListener("DOMContentLoaded", function(e) {doc.body.style.fontSize = "16px";}, false);}
})(750, 750);部分文章參考:web app變革之rem
響應式與自適應的區別
- 1.自適應布局通過檢測視口分辨率,來判斷當前訪問的設備是:pc端、平板、手機,從而請求服務層,返回不同的頁面;響應式布局通過檢測視口分辨率,針對不同客戶端在客戶端做代碼處理,來展現不同的布局和內容。
- 2.自適應布局需要開發多套界面,而響應式布局只需要開發一套界面就可以了。
- 3.自適應對頁面做的屏幕適配是在一定范圍:比如pc端一般要大于1024像素,手機端要小于768像素。而響應式布局是一套頁面全部適應。
- 4.自適應布局如果屏幕太小會發生內容過于擁擠。而響應式布局正是為了解決這個問題而衍生出的概念,它可以自動識別屏幕寬度并做出相應調整的網頁設計。
總之,響應式布局還是要比自適應布局要好一點,但是自適應布局更加貼切實際,因為你只需要考慮幾種狀態就可以了而不是像響應式布局需要考慮非常多狀態。所以的說無論哪種設計都有它們各自的特點,我們要根據項目的需求來選擇適合的布局方式。
參考:?響應式布局與自適應式布局有什么不同
?JavaScript 數據類型知識整理
先給出兩道題目:
javascript中有哪些數據類型
JavaScript 中共有七種內置數據類型,包括基本類型和對象類型。
基本類型
基本類型分為以下六種:
-
string(字符串)
-
boolean(布爾值)
-
number(數字)
-
symbol(符號)
-
null(空值)
-
undefined(未定義)
注意:
-
string 、number 、boolean 和 null ?undefined 這五種類型統稱為原始類型(Primitive),表示不能再細分下去的基本類型
-
symbol是ES6中新增的數據類型,symbol 表示獨一無二的值,通過 Symbol 函數調用生成,由于生成的 symbol 值為原始類型,所以 Symbol 函數不能使用 new 調用;
-
null 和 undefined 通常被認為是特殊值,這兩種類型的值唯一,就是其本身。
對象類型
對象類型也叫引用類型,array和function是對象的子類型。對象在邏輯上是屬性的無序集合,是存放各種值的容器。對象值存儲的是引用地址,所以和基本類型值不可變的特性不同,對象值是可變的。
說說你對javascript是弱類型語言的理解?
JavaScript 是弱類型語言,而且JavaScript 聲明變量的時候并沒有預先確定的類型, 變量的類型就是其值的類型,也就是說變量當前的類型由其值所決定,夸張點說上一秒種的String,下一秒可能就是個Number類型了,這個過程可能就進行了某些操作發生了強制類型轉換。雖然弱類型的這種不需要預先確定類型的特性給我們帶來了便利,同時也會給我們帶來困擾。為了能充分利用該特性就必須掌握類型轉換的原理
javascript中強制類型轉換是一個非常易出現bug的點,知道強制轉換時候的規則嗎?
-
ToPrimitive(轉換為原始值)
ToPrimitive對原始類型不發生轉換處理,只針對引用類型(object)的,其目的是將引用類型(object)轉換為非對象類型,也就是原始類型。
ToPrimitive 運算符接受一個值,和一個可選的 期望類型作參數。ToPrimitive 運算符將值轉換為非對象類型,如果對象有能力被轉換為不止一種原語類型,可以使用可選的?期望類型?來暗示那個類型。
轉換后的結果原始類型是由期望類型決定的,期望類型其實就是我們傳遞的type。直接看下面比較清楚。?ToPrimitive方法大概長這么個樣子具體如下。
/**
* @obj 需要轉換的對象
* @type 期望轉換為的原始數據類型,可選
*/
ToPrimitive(obj,type)
type不同值的說明
-
type為string:
-
先調用obj的toString方法,如果為原始值,則return,否則第2步
-
調用obj的valueOf方法,如果為原始值,則return,否則第3步
-
拋出TypeError 異常
-
type為number:
-
調用obj的valueOf方法,如果為原始值,則返回,否則下第2步
-
調用obj的toString方法,如果為原始值,則return,否則第3步
-
拋出TypeError 異常
-
type參數為空
-
該對象為Date,則type被設置為String
-
否則,type被設置為Number,即會首先檢查該值是否有valueOf()方法,如果有并且返回基本類型值,就使用該值進行強制類型轉換;如果沒有就使用toString()的返回值(如果存在)來進行強制類型轉換
Date數據類型特殊說明:
對于Date數據類型,我們更多期望獲得的是其轉為時間后的字符串,而非毫秒值(時間戳),如果為number,則會取到對應的毫秒值,顯然字符串使用更多。?其他類型對象按照取值的類型操作即可。
ToPrimitive總結
ToPrimitive轉成何種原始類型,取決于type,type參數可選,若指定,則按照指定類型轉換,若不指定,默認根據實用情況分兩種情況,Date為string,其余對象為number。那么什么時候會指定type類型呢,那就要看下面兩種轉換方式了。
toString
Object.prototype.toString()
toString() 方法返回一個表示該對象的字符串。參考:Object.prototype.toString()
每個對象都有一個 toString() 方法,當對象被表示為文本值時或者當以期望字符串的方式引用對象時,該方法被自動調用。對普通對象來說,除非自行定義,否則toString()返回內部屬性[[Class]]的值,如"[object Object]"。
數組的默認toString()方法經過了重新定義,將所有單元字符串化以后再用","連接起來:
var a = [1,2,3]
a.toString() //"1,2,3"如果是原始類型,抽象操作ToString則負責處理非字符串到字符串的強制類型轉換。
基本類型值的字符串化規則為:
null轉換為"null",
undefined轉換為"undefined",
true轉換為""true"。
數字的字符串化遵循通用規則,那些極小和極大的數字使用指數形式:
var a = 1.07*1000*1000*1000*1000*1000*1000*1000
a.toString() //"1.07e21"valueOf
Object.prototype.valueOf()方法返回指定對象的原始值。
JavaScript 調用 valueOf() 方法用來把對象轉換成原始類型的值(數值、字符串和布爾值)。但是我們很少需要自己調用此函數,valueOf 方法一般都會被 JavaScript 自動調用。
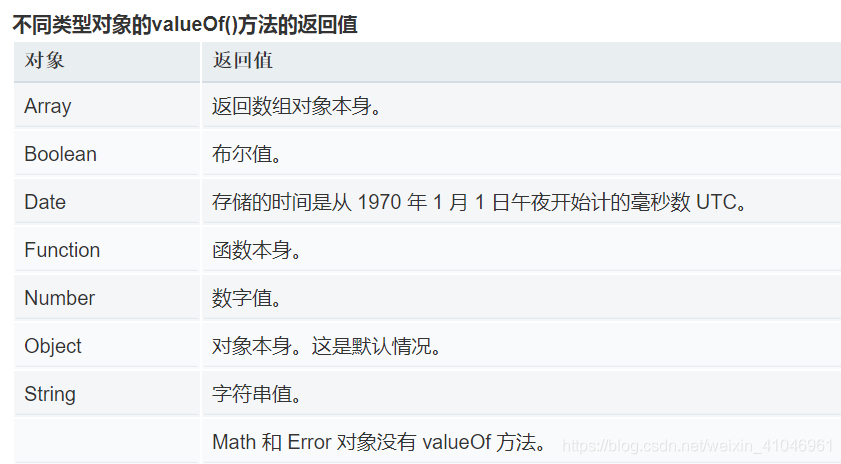
// Array:返回數組對象本身
var array = ["ABC", true, 12, -5];
console.log(array.valueOf() === array); // true// Date:當前時間距1970年1月1日午夜的毫秒數
var date = new Date(2013, 7, 18, 23, 11, 59, 230);
console.log(date.valueOf()); // 1376838719230// Number:返回數字值
var num = 15.26540;
console.log(num.valueOf()); // 15.2654// 布爾:返回布爾值true或false
var bool = true;
console.log(bool.valueOf() === bool); // true// new一個Boolean對象
var newBool = new Boolean(true);
// valueOf()返回的是true,兩者的值相等
console.log(newBool.valueOf() == newBool); // true
// 但是不全等,兩者類型不相等,前者是boolean類型,后者是object類型
console.log(newBool.valueOf() === newBool); // false// Function:返回函數本身
function foo(){}
console.log( foo.valueOf() === foo ); // true
var foo2 = new Function("x", "y", "return x + y;");
console.log( foo2.valueOf() );
/*
? anonymous(x,y
) {
return x + y;
}
*/// Object:返回對象本身
var obj = {name: "張三", age: 18};
console.log( obj.valueOf() === obj ); // true// String:返回字符串值
var str = "http://www.xyz.com";
console.log( str.valueOf() === str ); // true// new一個字符串對象
var str2 = new String("http://www.xyz.com");
// 兩者的值相等,但不全等,因為類型不同,前者為string類型,后者為object類型
console.log( str2.valueOf() === str2 ); // false
console.log(typeof str2.valueOf(),'str2.valueOf()'); // string參考:?Object.prototype.valueOf()
強制轉換
強制轉換主要指使用Number、String和Boolean三個函數,手動將各種類型的值,分布轉換成數字、字符串或者布爾值。
Number()
使用Number函數,可以將任意類型的值轉化成數值。
下面分成兩種情況討論,一種是參數是原始類型的值,另一種是參數是對象。
(1)原始類型值
原始類型值的轉換規則如下。
// 數值:轉換后還是原來的值
Number(324) // 324// 字符串:如果可以被解析為數值,則轉換為相應的數值
Number('324') // 324// 字符串:如果不可以被解析為數值,返回 NaN
Number('324abc') // NaN// 空字符串轉為0
Number('') // 0// 布爾值:true 轉成 1,false 轉成 0
Number(true) // 1
Number(false) // 0// undefined:轉成 NaN
Number(undefined) // NaN// null:轉成0
Number(null) // 0
Number函數將字符串轉為數值,要比parseInt函數嚴格很多。基本上,只要有一個字符無法轉成數值,整個字符串就會被轉為NaN。
parseInt('42 cats') // 42
Number('42 cats') // NaN
上面代碼中,parseInt逐個解析字符,而Number函數整體轉換字符串的類型。
另外,parseInt和Number函數都會自動過濾一個字符串前導和后綴的空格。
parseInt('\t\v\r12.34\n') // 12
Number('\t\v\r12.34\n') // 12.34
(2)對象
簡單的規則是,Number方法的參數是對象時,將返回NaN,除非是包含單個數值的數組。
Number({a: 1}) // NaN
Number([1, 2, 3]) // NaN
Number([5]) // 5
之所以會這樣,是因為Number背后的轉換規則比較復雜。
第一步,調用對象自身的valueOf方法。如果返回原始類型的值,則直接對該值使用Number函數,不再進行后續步驟。
第二步,如果valueOf方法返回的還是對象,則改為調用對象自身的toString方法。如果toString方法返回原始類型的值,則對該值使用Number函數,不再進行后續步驟。
第三步,如果toString方法返回的是對象,就報錯。
請看下面的例子。
var obj = {x: 1};
Number(obj) // NaN// 等同于
if (typeof obj.valueOf() === 'object') {Number(obj.toString());
} else {Number(obj.valueOf());
}
上面代碼中,Number函數將obj對象轉為數值。背后發生了一連串的操作,首先調用obj.valueOf方法, 結果返回對象本身;于是,繼續調用obj.toString方法,這時返回字符串[object Object],對這個字符串使用Number函數,得到NaN。
默認情況下,對象的valueOf方法返回對象本身,所以一般總是會調用toString方法,而toString方法返回對象的類型字符串(比如[object Object])。所以,會有下面的結果。
Number({}) // NaN
如果toString方法返回的不是原始類型的值,結果就會報錯。
var obj = {valueOf: function () {return {};},toString: function () {return {};}
};Number(obj)
// TypeError: Cannot convert object to primitive value
上面代碼的valueOf和toString方法,返回的都是對象,所以轉成數值時會報錯。
從上例還可以看到,valueOf和toString方法,都是可以自定義的。
Number({valueOf: function () {return 2;}
})
// 2Number({toString: function () {return 3;}
})
// 3Number({valueOf: function () {return 2;},toString: function () {return 3;}
})
// 2
上面代碼對三個對象使用Number函數。第一個對象返回valueOf方法的值,第二個對象返回toString方法的值,第三個對象表示valueOf方法先于toString方法執行。
String()
String函數可以將任意類型的值轉化成字符串,轉換規則如下。
(1)原始類型值
- 數值:轉為相應的字符串。
- 字符串:轉換后還是原來的值。
- 布爾值:
true轉為字符串"true",false轉為字符串"false"。 - undefined:轉為字符串
"undefined"。 - null:轉為字符串
"null"。
String(123) // "123"
String('abc') // "abc"
String(true) // "true"
String(undefined) // "undefined"
String(null) // "null"
(2)對象
String方法的參數如果是對象,返回一個類型字符串;如果是數組,返回該數組的字符串形式。
String({a: 1}) // "[object Object]"
String([1, 2, 3]) // "1,2,3"var b = [1, 2, [3, 4, [5, 6]]]
console.log(b.toString(), 'b.toString') //"1,2,3,4,5,6"
console.log([b.toString()], '[b.toString]') //["1,2,3,4,5,6"]
//再也不怕多重數組拆解成一個數組啦哈哈 String方法背后的轉換規則,與Number方法基本相同,只是互換了valueOf方法和toString方法的執行順序。
-
先調用對象自身的
toString方法。如果返回原始類型的值,則對該值使用String函數,不再進行以下步驟。 -
如果
toString方法返回的是對象,再調用原對象的valueOf方法。如果valueOf方法返回原始類型的值,則對該值使用String函數,不再進行以下步驟。 -
如果
valueOf方法返回的是對象,就報錯。
下面是一個例子。
String({a: 1})
// "[object Object]"// 等同于
String({a: 1}.toString())
// "[object Object]"
上面代碼先調用對象的toString方法,發現返回的是字符串[object Object],就不再調用valueOf方法了。
如果toString法和valueOf方法,返回的都是對象,就會報錯。
var obj = {valueOf: function () {return {};},toString: function () {return {};}
};String(obj)
// TypeError: Cannot convert object to primitive value
下面是通過自定義toString方法,改變返回值的例子。
String({toString: function () {return 3;}
})
// "3"String({valueOf: function () {return 2;}
})
// "[object Object]"String({valueOf: function () {return 2;},toString: function () {return 3;}
})
// "3"
上面代碼對三個對象使用String函數。第一個對象返回toString方法的值(數值3),第二個對象返回的還是toString方法的值([object Object]),第三個對象表示toString方法先于valueOf方法執行。
Boolean()
Boolean函數可以將任意類型的值轉為布爾值。
它的轉換規則相對簡單:除了以下五個值的轉換結果為false,其他的值全部為true。
undefinednull-0或+0NaN''(空字符串)
Boolean(undefined) // false
Boolean(null) // false
Boolean(0) // false
Boolean(NaN) // false
Boolean('') // false
注意,所有對象(包括空對象)的轉換結果都是true,甚至連false對應的布爾對象new Boolean(false)也是true(詳見《原始類型值的包裝對象》一章)。
Boolean({}) // true
Boolean([]) // true
Boolean(new Boolean(false)) // true
所有對象的布爾值都是true,這是因為 JavaScript 語言設計的時候,出于性能的考慮,如果對象需要計算才能得到布爾值,對于obj1 && obj2這樣的場景,可能會需要較多的計算。為了保證性能,就統一規定,對象的布爾值為true。
js轉換規則不同場景應用
什么時候自動轉換為string類型
-
在沒有對象的前提下
字符串的自動轉換,主要發生在字符串的加法運算時。當一個值為字符串,另一個值為非字符串,則后者轉為字符串。
'2' + 1 // '21'
'2' + true // "2true"
'2' + false // "2false"
'2' + undefined // "2undefined"
'2' + null // "2null"
-
當有對象且與對象+時候
//toString的對象
var obj2 = {toString:function(){return 'a'}
}
console.log('2'+obj2)
//輸出結果2a//常規對象
var obj1 = {a:1,b:2
}
console.log('2'+obj1);
//輸出結果 2[object Object]//幾種特殊對象
'2' + {} // "2[object Object]"
'2' + [] // "2"
'2' + function (){} // "2function (){}"
'2' + ['koala',1] // 2koala,1
對下面'2'+obj2詳細舉例說明如下:
-
左邊為string,ToPrimitive原始值轉換后不發生變化
-
右邊轉化時同樣按照ToPrimitive進行原始值轉換,由于指定的type是number,進行ToPrimitive轉化調用obj2.valueof(),得到的不是原始值,進行第三步
-
調用toString() return 'a'
-
符號兩邊存在string,而且是+號運算符則都采用String規則轉換為string類型進行拼接
-
輸出結果2a
對下面'2'+obj1詳細舉例說明如下:
-
左邊為string,ToPrimitive轉換為原始值后不發生變化
-
右邊轉化時同樣按照ToPrimitive進行原始值轉換,由于指定的type是number,進行ToPrimitive轉化調用obj2.valueof(),得到{ a: 1, b: 2}
-
調用toString() return [object Object]
-
符號兩邊存在string,而且是+號運算符則都采用String規則轉換為string類型進行拼接
-
輸出結果2[object Object]
代碼中幾種特殊對象的轉換規則基本相同,就不一一說明,大家可以想一下流程。
注意:不管是對象還不是對象,都有一個轉換為原始值的過程,也就是ToPrimitive轉換,只不過原始類型轉換后不發生變化,對象類型才會發生具體轉換。
什么時候自動轉換為Number類型
-
有加法運算符,但是無String類型的時候,都會優先轉換為Number類型
例子:
true + 0 // 1 true + true // 2 true + false //1 -
除了加法運算符,其他運算符都會把運算自動轉成數值。例子:
'5' - '2' // 3 '5' * '2' // 10 true - 1 // 0 false - 1 // -1 '1' - 1 // 0 '5' * [] // 0 false / '5' // 0 'abc' - 1 // NaN null + 1 // 1 undefined + 1 // NaN//一元運算符(注意點) +'abc' // NaN -'abc' // NaN +true // 1 -false // 0
注意:null轉為數值時為0,而undefined轉為數值時為NaN。
判斷等號也放在Number里面特殊說明
== 抽象相等比較與+運算符不同,不再是String優先,而是Nuber優先。?下面列舉x == y的例子
-
如果x,y均為number,直接比較 沒什么可解釋的了
1 == 2 //false
-
如果存在對象,ToPrimitive() type為number進行轉換,再進行后面比較
var obj1 = {valueOf:function(){return '1'}
}
1 == obj1 //true
//obj1轉為原始值,調用obj1.valueOf()
//返回原始值'1'
//'1'toNumber得到 1 然后比較 1 == 1[] == ![] //true
//[]作為對象ToPrimitive得到 ''
//![] 首先[]是一個空數組,與{}空對象一樣返回true,所以![]便返回false,toNumber后轉換得到0
//'' == 0
//轉換為 0==0 //true
-
存在boolean,按照ToNumber將boolean轉換為1或者0,再進行后面比較
//boolean 先轉成number,按照上面的規則得到1
//3 == 1 false
//0 == 0 true
3 == true // false
'0' == false //true
4.如果x為string,y為number,x轉成number進行比較
//'0' toNumber()得到 0
//0 == 0 true
'0' == 0 //true
什么時候進行布爾轉換
-
布爾比較時
-
if(obj) , while(obj) 等判斷時或者 三元運算符只能夠包含布爾值
條件部分的每個值都相當于false,使用否定運算符后,就變成了true
if ( !undefined&& !null&& !0&& !NaN&& !''
) {console.log('true');
} // true//下面兩種情況也會轉成布爾類型
expression ? true : false
!! expression
抽象相等
ES5規范11.9.3節的“抽象相等比較算法”定義了==運算符的行為。該算法簡單而又全面,涵蓋了所有可能出現的類型組合,以及它們進行強制類型轉換的方式。
比較運算x==y, 其中x和?y是值,產生true或者false。這樣的比較按如下方式進行:1. 若Type(x)與Type(y)相同, 則a. 若Type(x)為Undefined, 返回true。 undefined == undefined // trueb. 若Type(x)為Null, 返回true。// null == null // truec. 若Type(x)為Number, 則i. 若x為NaN, 返回false。即 NaN == NaN //falseii. 若y為NaN, 返回false。 NaN == undefined // falseiii. 若x與y為相等數值, 返回true。iv. 若x 為 +0 且 y為?0, 返回true。v. 若x 為 ?0 且 y為+0, 返回true。vi. 返回false。d. 若Type(x)為String, 則當x和y為完全相同的字符序列(長度相等且相同字符在相同位置)時返回true。 否則, 返回false。e. 若Type(x)為Boolean, 當x和y為同為true或者同為false時返回true。 否則, 返回false。f. 當x和y為引用同一對象時返回true。否則,返回false。2. 若x為null且y為undefined, 返回true。 undefined == null // true3. 若x為undefined且y為null, 返回true。4. 若Type(x) 為 Number 且 Type(y)為String, 返回comparison x == ToNumber(y)的結果。5. 若Type(x) 為 String 且 Type(y)為Number,返回比較ToNumber(x) == y的結果。6. 若Type(x)為Boolean, 返回比較ToNumber(x) == y的結果。7. 若Type(y)為Boolean, 返回比較x == ToNumber(y)的結果。8. 若Type(x)為String或Number,且Type(y)為Object,返回比較x == ToPrimitive(y)的結果。9. 若Type(x)為Object且Type(y)為String或Number, 返回比較ToPrimitive(x) == y的結果。10. 返回false。也就是說,當對不同類型的值進行比較時,JavaScript 會首先將其轉化為數字(number)再判定大小。
其他類型和布爾類型之間的相等比較
==最容易出錯的一個地方是true和false與其他類型之間的相等比較。
var a = '42'
var b = true
a == b //false
復制代碼結果是false,這讓人很容易掉坑里。如果嚴格按照“抽象相等比較算法”,這個結果也就是意料之中的。
根據第7條規則,若Type(y)為Boolean, 返回比較x == ToNumber(y)的結果,即返回'42' == 1,結果為false。
很奇怪吧?所以無論什么情況下都不要使用== true和== false。
還有一個坑常常被提到:
0 == '\n' //true
復制代碼""、"\n"(或者" "等其他空格組合)等空字符串被ToNumber強制類型轉換為0。
再來看看那些“短”的地方:
"0" == false // true
false == 0 // true
false == "" // true
false == [] // true
"" == 0 // true
"" == [] // true
0 == [] // true
其中有4種情況涉及== false,之前我們說過應該避免,所以還剩下后面3種。
這些特殊情況會導致各種問題,使用中要多加小心。我們要對==兩邊的值認真推敲,以下兩個原則可以讓我們有效地避免出錯。
- 如果兩邊的值中有true或者false,千萬不要使用==
- 如果兩邊的值中有[]、""、或者0,盡量不要使用==
隱式強制轉換在部分情況下確實很危險,為了安全起見就要使用===
js中的數據類型判斷
面試官問:如何判斷數據類型?怎么判斷一個值到底是數組類型還是對象?
三種方式,分別為 typeof、instanceof 和 Object.prototype.toString()
typeof
通過 typeof操作符來判斷一個值屬于哪種基本類型。
typeof 'seymoe' // 'string'
typeof true // 'boolean'
typeof 10 // 'number'
typeof Symbol() // 'symbol'
typeof null // 'object' 無法判定是否為 null
typeof undefined // 'undefined'typeof {} // 'object'
typeof [] // 'object'
typeof(() => {}) // 'function'
上面代碼的輸出結果可以看出,
-
null 的判定有誤差,得到的結果 如果使用 typeof,null得到的結果是object
-
操作符對對象類型及其子類型,例如函數(可調用對象)、數組(有序索引對象)等進行判定,則除了函數都會得到 object 的結果。
綜上可以看出typeOf對于判斷類型還有一些不足,在對象的子類型和null情況下。
instanceof
通過 instanceof 操作符也可以對對象類型進行判定,其原理就是測試構造函數的 ?prototype 是否出現在被檢測對象的原型鏈上。
[] instanceof Array // true
({}) instanceof Object // true
(()=>{}) instanceof Function // true
復制代碼注意:instanceof 也不是萬能的。?舉個例子:
let arr = []
let obj = {}
arr instanceof Array // true
arr instanceof Object // true
obj instanceof Object // true
在這個例子中,arr 數組相當于 new Array() 出的一個實例,所以 arr.proto?=== Array.prototype,又因為 Array 屬于 Object 子類型,即 Array.prototype.proto?=== Object.prototype,所以 Object 構造函數在 arr 的原型鏈上。所以 instanceof 仍然無法優雅的判斷一個值到底屬于數組還是普通對象。
還有一點需要說明下,有些開發者會說 Object.prototype.proto?=== null,豈不是說 arr instanceof null 也應該為 true,這個語句其實會報錯提示右側參數應該為對象,這也印證 typeof null 的結果為 object 真的只是javascript中的一個 bug 。
Object.prototype.toString() 可以說是判定 JavaScript 中數據類型的終極解決方法了,具體用法請看以下代碼:
Object.prototype.toString.call({}) // '[object Object]'
Object.prototype.toString.call([]) // '[object Array]'
Object.prototype.toString.call(() => {}) // '[object Function]'
Object.prototype.toString.call('seymoe') // '[object String]'
Object.prototype.toString.call(1) // '[object Number]'
Object.prototype.toString.call(true) // '[object Boolean]'
Object.prototype.toString.call(Symbol()) // '[object Symbol]'
Object.prototype.toString.call(null) // '[object Null]'
Object.prototype.toString.call(undefined) // '[object Undefined]'Object.prototype.toString.call(new Date()) // '[object Date]'
Object.prototype.toString.call(Math) // '[object Math]'
Object.prototype.toString.call(new Set()) // '[object Set]'
Object.prototype.toString.call(new WeakSet()) // '[object WeakSet]'
Object.prototype.toString.call(new Map()) // '[object Map]'
Object.prototype.toString.call(new WeakMap()) // '[object WeakMap]'
我們可以發現該方法在傳入任何類型的值都能返回對應準確的對象類型。用法雖簡單明了,但其中有幾個點需要理解清楚:
-
該方法本質就是依托Object.prototype.toString() 方法得到對象內部屬性 [[Class]]
-
傳入原始類型卻能夠判定出結果是因為對值進行了包裝
-
null 和 undefined 能夠輸出結果是內部實現有做處理
NaN相關總結
NaN的概念
NaN 是一個全局對象的屬性,NaN 是一個全局對象的屬性,NaN是一種特殊的Number類型。
什么時候返回NaN (開篇第二道題也得到解決)
-
無窮大除以無窮大
-
給任意負數做開方運算
-
算數運算符與不是數字或無法轉換為數字的操作數一起使用
-
字符串解析成數字
一些例子:
Infinity / Infinity; // 無窮大除以無窮大
Math.sqrt(-1); // 給任意負數做開方運算
'a' - 1; // 算數運算符與不是數字或無法轉換為數字的操作數一起使用
'a' * 1;
'a' / 1;
parseInt('a'); // 字符串解析成數字
parseFloat('a');Number('a'); //NaN
'abc' - 1 // NaN
undefined + 1 // NaN
//一元運算符(注意點)
+'abc' // NaN
-'abc' // NaN
對 null 和 undefined 進行比較
當使用?null?或?undefined?與其他值進行比較時,其返回結果常常出乎你的意料。
當使用嚴格相等?===?比較二者時
它們不相等,因為它們屬于不同的類型。

當使用非嚴格相等?==?比較二者時
JavaScript 存在一個特殊的規則,會判定它們相等。他們倆就像“一對戀人”,僅僅等于對方而不等于其他任何的值(只在非嚴格相等下成立)。
![]()
當使用數學式或其他比較方法?< > <= >=?時:
null/undefined?會被轉化為數字:null?被轉化為?0,undefined?被轉化為?NaN。
下面讓我們看看,這些規則會帶來什么有趣的現象。同時更重要的是,我們需要從中學會如何遠離這些特性帶來的“陷阱”。
奇怪的結果:null vs 0
通過比較?null?和 0 可得:

是的,上面的結果完全打破了你對數學的認識。在最后一行代碼顯示“null?大于等于 0”的情況下,前兩行代碼中一定會有一個是正確的,然而事實表明它們的結果都是 false。
為什么會出現這種反常結果,這是因為相等性檢測?==?和普通比較符?> < >= <=?的代碼邏輯是相互獨立的。進行值的比較時,null?會被轉化為數字,因此它被轉化為了?0。這就是為什么(3)中?null >= 0?返回值是 true,(1)中?null > 0?返回值是 false。
另一方面,undefined?和?null?在相等性檢測?==?中不會進行任何的類型轉換,它們有自己獨立的比較規則,所以除了它們之間互等以及與本身相等外,不會等于任何其他的值。這就解釋了為什么(2)中?null == 0?會返回 false。
特立獨行的 undefined
undefined?不應該被與其他值進行比較:

為何它看起來如此厭惡 0?返回值都是 false!
原因如下:
(1)?和?(2)?都返回?false?是因為?undefined?在比較中被轉換為了?NaN,而?NaN?是一個特殊的數值型值,它與任何值進行比較都會返回?false。(3)?返回?false?是因為這是一個相等性檢測,而?undefined?只與?null?和自己相等,不會與其他值相等。
規避錯誤
我們為何要研究上述示例?我們需要時刻記得這些古怪的規則嗎?不,其實不需要。雖然隨著代碼寫得越來越多,我們對這些規則也都會爛熟于胸,但是我們需要更為可靠的方法來避免潛在的問題:
除了嚴格相等?===?外,其他凡是有?undefined/null?參與的比較,我們都需要額外小心。
除非你非常清楚自己在做什么,否則永遠不要使用?>= > < <=?去比較一個可能為?null/undefined?的變量。對于取值可能是?null/undefined?的變量,請按需要分別檢查它的取值情況。
誤區
toString和String的區別
-
toString
-
toString()可以將數據都轉為字符串,但是null和undefined不可以轉換。
console.log(null.toString()) //報錯 TypeError: Cannot read property 'toString' of nullconsole.log(undefined.toString()) //報錯 TypeError: Cannot read property 'toString' of undefined -
toString()括號中可以寫數字,代表進制
二進制:.toString(2);
八進制:.toString(8);
十進制:.toString(10);
十六進制:.toString(16);
-
String
-
String()可以將null和undefined轉換為字符串,但是沒法轉進制字符串
console.log(String(null)); // null console.log(String(undefined)); // undefined
插個小片段?
console.log(NaN == NaN, 'NaN == NaN') // falseconsole.log(NaN == undefined, 'NaN == undefined') // falseconsole.log(undefined == undefined, 'undefined == undefined') // trueconsole.log(null == null, 'null == null') // trueconsole.log(undefined == null, 'undefined == null') // true 非嚴格模式下console.log(0 == null, '0 == null') // false 非嚴格模式下console.log([] == [], '[]') // falseconsole.log(!![], '!![]') // trueconsole.log([], '[]') // length: 0__proto__: Array(0)console.log(typeof [], 'typeof []') // objectconsole.log(false == [], 'false == []') // trueconsole.log(-["1"], '- ["1"]') // -1console.log(-["1", "2"], '- ["1", "2"]') // NaNvar a = 1.07 * 1000 * 1000 * 1000 * 1000 * 1000 * 1000 * 1000console.log(a.toString(), 'a.toString()') //"1.07e21"var b = [1, 2, [3, 4, [5, 6]]]console.log(b.toString(), 'b.toString') //"1,2,3,4,5,6" console.log([b.toString()], '[b.toString]') //["1,2,3,4,5,6"]// new一個字符串對象var str2 = new String("http://www.xyz.com");// 兩者的值相等,但不全等,因為類型不同,前者為string類型,后者為object類型console.log(str2.valueOf() === str2); // falseconsole.log(typeof str2.valueOf(),'str2.valueOf()'); // string參考:數據類型轉換、經常被面試官考的 JavaScript 數據類型知識你真的懂嗎?、JavaScript中的強制類型轉換、值的比較
?
?
?
?
?
?
?
?
?
?
?













)

![[轉載]dbms_lob用法小結](http://pic.xiahunao.cn/[轉載]dbms_lob用法小結)


不定時更新~)
)