??最近進行大數據處理的時候,發現我以前常用的pandas查詢方法太慢了,太慢了,真是太慢了,查閱資料,遂發現了一種新的加速方法,能助力我飛上天,和太陽肩并肩,所以記錄下來。
1. 場景說明與數據集構建
??首先,闡述一下我們DataFrame查詢應用場景,有兩個csv表格文件;
??表1中有兩列,一列為id號(index),一列為名字(name);
??表2中有兩列,一列為id號(index),一列為名字對應的內容(content);
??此外,表1和表2中的順序是混亂的,每一行的index都不相同。
??此時,你有一個想法,把name和content對應起來,在一張表中,有名字(name)就知道內容(content)了,我們先用下列代碼構建這樣一個數據集:
import pandas as pd
from pandas.core.frame import DataFrame
import random
from tqdm import tqdmname = ["一念關山", "奉上", "立劍"]content = ["一念月落,一念身錯,一念關山難涉過。棋逢過客,執子者不問因果。", "奉上,唯愿去踏破善惡之疊浪,一心并肩赴跌宕。", "刺予我傷口,重生了魂魄,立劍的時候,疾驟的嘶吼。"]result1 = []
result2 = []
for i in tqdm(range(10000000)):temp = random.randint(0, 2)xx1 = name[temp] + "__" + str(i)xx2 = "YNGS" + "__" + str(i)xx3 = content[temp] + "__" + str(i)result1.append([xx2, xx1])result2.append([xx2, xx3])Frame1 = DataFrame(result1, columns=["index", "name"])
Frame1.to_csv("./test01.csv", index=False)Frame2 = DataFrame(result2, columns=["index", "content"])
shuffled_df = Frame2.sample(frac=1, random_state=42) # 打亂數據
shuffled_df.to_csv("./test02.csv", index=False)
??代碼構建了一個1000萬行的數據表,當然了表中數據沒有實際意義,僅供測試使用。
來瞅瞅我們生成的數據表格吧~
test01.csv:

test02.csv:

2. loc加速查詢測試
2.1 原始方法
??有了生成好的數據表,怎么做其實很簡單,常規的做法如下虛線中的代碼所示,對每一行循環,查詢content表中與name表中index相同的行,再取content內容就可以了。
import pandas as pd
from pandas.core.frame import DataFrame
from tqdm import tqdmdata_name = pd.read_csv("./test01.csv", encoding="utf-8")
data_content = pd.read_csv("./test02.csv", encoding="utf-8")name = data_name["name"].values.tolist()
index = data_name["index"].values.tolist()result = []
for i in tqdm(range(len(index))):temp_index = index[i]# -----------------------------------------------------------------------temp_data = data_content[data_content["index"] == temp_index]temp_content = temp_data["content"].values.tolist()[0]# -----------------------------------------------------------------------result.append([temp_index, temp_content])Frame = DataFrame(result, columns=["name", "content"])
Frame.to_csv("./finish.csv", index=False)
??我們來看看運行速度,tqdm顯示為725小時,完成這1000萬行的數據需要那么久啊!這還能忍,人生苦短,python在手,我要加速 /(ㄒoㄒ)/~~

2.2 加速方法
??其實 test01.csv 和 test02.csv 有相同的一列,即索引列(index),一般的dataframe的行索引默認為1、2、3…,我們可以設置index列為行索引,采用loc方法查詢給定索引名對應的內容,修改代碼如下虛線中所示:
import pandas as pd
from pandas.core.frame import DataFrame
from tqdm import tqdmdata_name = pd.read_csv("./test01.csv", encoding="utf-8")
data_content = pd.read_csv("./test02.csv", encoding="utf-8")# -----------------------------------------------------------------------
data_content = data_content.set_index("index") # 行索引設置
# -----------------------------------------------------------------------name = data_name["name"].values.tolist()
index = data_name["index"].values.tolist()result = []
for i in tqdm(range(len(index))):temp_index = index[i]# ---------------------------------------------------------temp_data = data_content.loc[temp_index]temp_content = [temp_data["content"]]# ---------------------------------------------------------result.append([temp_index, temp_content])Frame = DataFrame(result, columns=["name", "content"])
Frame.to_csv("./finish.csv", index=False)
??設置“index”列為行索引的dataframe長下面這樣了,其大小為(10000000, 1)
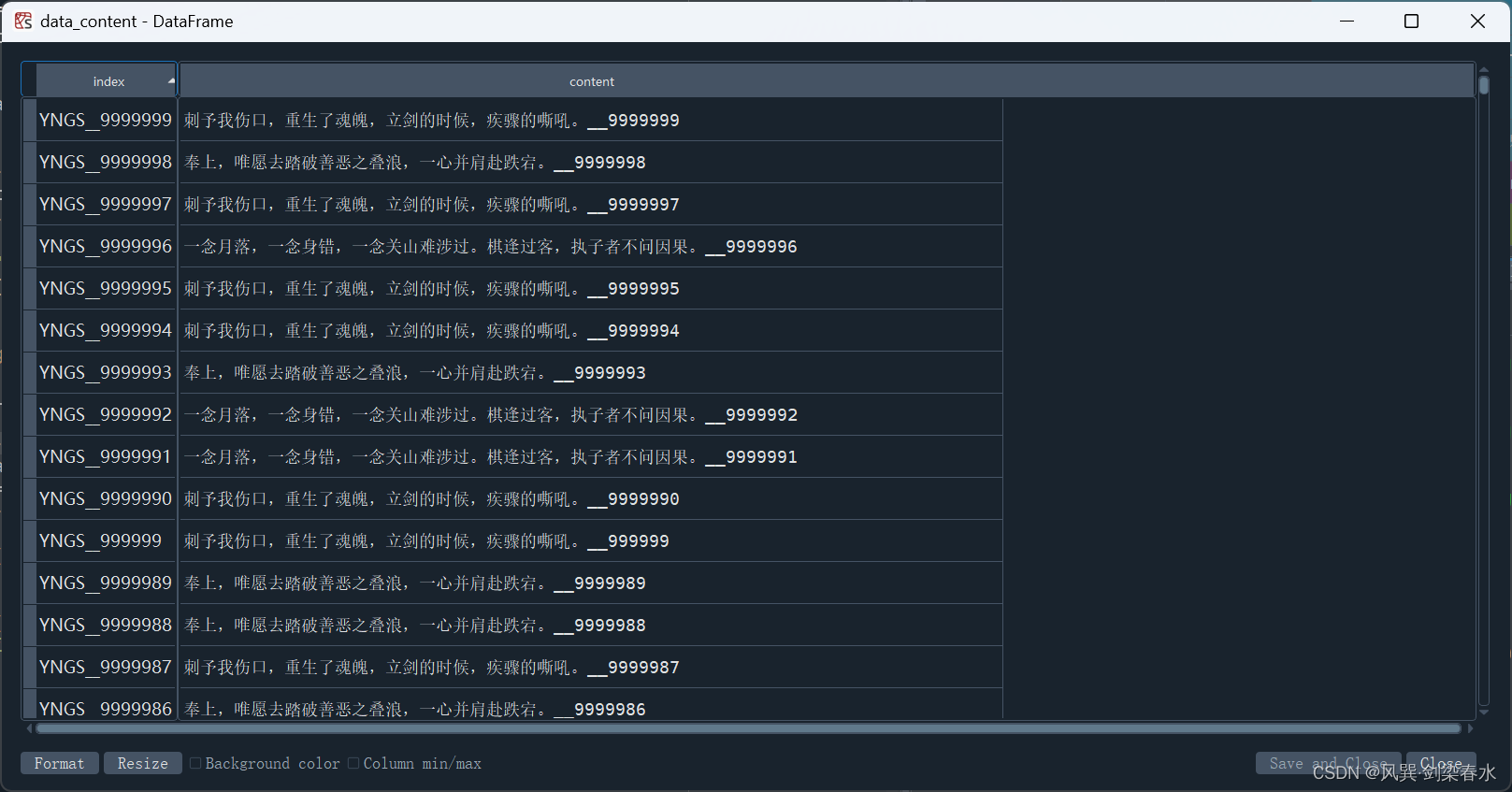
??測試一下運行速度,快看家人們,凌波微步再現,飛一般的感覺啊,9秒就完成了4%了,一共只需要幾分鐘時間即可完成1000萬數據處理~

?? 由此可見,行索引查詢能提速兩百多倍,在處理千萬級數據時,可以采用該方法神行百里,加速執行嗷o( ̄▽ ̄)ブ,學起來~



| 韌性系統的16大指導原則)


)

)



用法)
)





