本文,我們將了解如何基于 PyTorch 最新的 完全分片數據并行 (Fully Sharded Data Parallel,FSDP) 功能用 Accelerate 庫來訓練大模型。
動機
隨著機器學習 (ML) 模型的規模、大小和參數量的不斷增加,ML 從業者發現在自己的硬件上訓練甚至加載如此大的模型變得越來越難。 一方面,人們發現大模型與較小的模型相比,學習速度更快 (數據和計算效率更高) 且會有顯著的提升 [1]; 另一方面,在大多數硬件上訓練此類模型變得令人望而卻步。
分布式訓練是訓練這些機器學習大模型的關鍵。大規模分布式訓練 領域最近取得了不少重大進展,我們將其中一些最突出的進展總結如下:
-
使用 ZeRO 數據并行 - 零冗余優化器 [2]
-
階段 1: 跨數據并行進程 / GPU 對
優化器狀態進行分片 -
階段 2: 跨數據并行進程/ GPU 對
優化器狀態 + 梯度進行分片 -
階段 3: 跨數據并行進程 / GPU 對
優化器狀態 + 梯度 + 模型參數進行分片 -
CPU 卸載: 進一步將 ZeRO 階段 2 的
優化器狀態 + 梯度卸載到 CPU 上 [3] -
張量并行 [4]: 模型并行的一種形式,通過對各層參數進行精巧的跨加速器 / GPU 分片,在實現并行計算的同時避免了昂貴的通信同步開銷。
-
流水線并行 [5]: 模型并行的另一種形式,其將模型的不同層放在不同的加速器 / GPU 上,并利用流水線來保持所有加速器同時運行。舉個例子,在第 2 個加速器 / GPU 對第 1 個 micro batch 進行計算的同時,第 1 個加速器 / GPU 對第 2 個 micro batch 進行計算。
-
3D 并行 [3]: 采用
ZeRO 數據并行 + 張量并行 + 流水線并行的方式來訓練數百億參數的大模型。例如,BigScience 176B 語言模型就采用了該并行方式 [6]。
本文我們主要關注 ZeRO 數據并行,更具體地講是 PyTorch 最新的 完全分片數據并行 (Fully Sharded Data Parallel,FSDP) 功能。DeepSpeed 和 FairScale 實現了 ZeRO 論文的核心思想。我們已經將其集成到了 transformers 的 Trainer 中,詳見博文 通過 DeepSpeed 和 FairScale 使用 ZeRO 進行更大更快的訓練[10]。最近,PyTorch 已正式將 Fairscale FSDP 整合進其 Distributed 模塊中,并增加了更多的優化。
Accelerate 🚀: 無需更改任何代碼即可使用 PyTorch FSDP
我們以基于 GPT-2 的 Large (762M) 和 XL (1.5B) 模型的因果語言建模任務為例。
以下是預訓練 GPT-2 模型的代碼。其與 此處 的官方因果語言建模示例相似,僅增加了 2 個參數 n_train (2000) 和 n_val (500) 以防止對整個數據集進行預處理/訓練,從而支持更快地進行概念驗證。
run_clm_no_trainer.py
運行 accelerate config 命令后得到的 FSDP 配置示例如下:
compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: FSDP
fsdp_config:min_num_params: 2000offload_params: falsesharding_strategy: 1
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: 'no'
num_machines: 1
num_processes: 2
use_cpu: false
多 GPU FSDP
本文我們使用單節點多 GPU 上作為實驗平臺。我們比較了分布式數據并行 (DDP) 和 FSDP 在各種不同配置下的性能。我們可以看到,對 GPT-2 Large(762M) 模型而言,DDP 尚能夠支持其中某些 batch size 而不會引起內存不足 (OOM) 錯誤。但當使用 GPT-2 XL (1.5B) 時,即使 batch size 為 1,DDP 也會失敗并出現 OOM 錯誤。同時,我們看到,FSDP 可以支持以更大的 batch size 訓練 GPT-2 Large 模型,同時它還可以使用較大的 batch size 訓練 DDP 訓練不了的 GPT-2 XL 模型。
硬件配置: 2 張 24GB 英偉達 Titan RTX GPU。
GPT-2 Large 模型 (762M 參數) 的訓練命令如下:
export BS=#`try with different batch sizes till you don't get OOM error,
#i.e., start with larger batch size and go on decreasing till it fits on GPU`time accelerate launch run_clm_no_trainer.py \
--model_name_or_path gpt2-large \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size $BS
--per_device_eval_batch_size $BS
--num_train_epochs 1
--block_size 12
FSDP 運行截屏:
FSDP 運行截屏
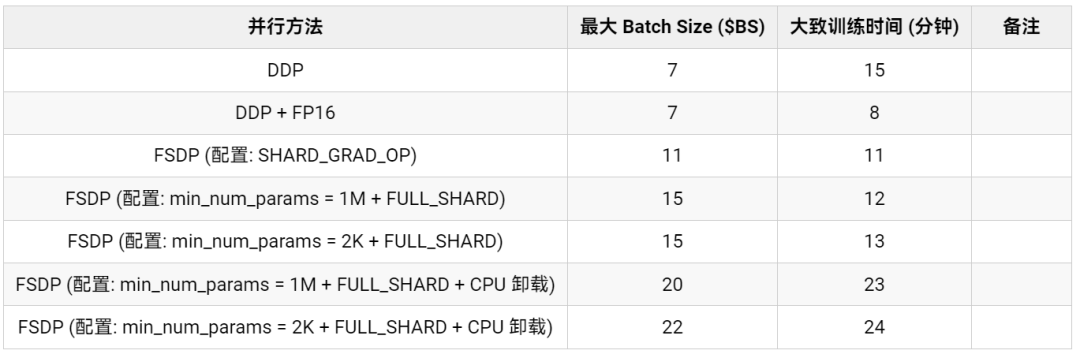
表 1: GPT-2 Large (762M) 模型 FSDP 訓練性能基準測試
從表 1 中我們可以看到,相對于 DDP 而言,FSDP 支持更大的 batch size,在不使用和使用 CPU 卸載設置的情況下 FSDP 支持的最大 batch size 分別可達 DDP 的 2 倍及 3 倍。從訓練時間來看,混合精度的 DDP 最快,其后是分別使用 ZeRO 階段 2 和階段 3 的 FSDP。由于因果語言建模的任務的上下文序列長度 ( --block_size ) 是固定的,因此 FSDP 在訓練時間上加速還不是太高。對于動態 batch size 的應用而言,支持更大 batch size 的 FSDP 可能會在訓練時間方面有更大的加速。目前,FSDP 的混合精度支持在 transformers 上還存在一些 問題。一旦問題解決,訓練時間將會進一步顯著縮短。
使用 CPU 卸載來支持放不進 GPU 顯存的大模型訓練
訓練 GPT-2 XL (1.5B) 模型的命令如下:
export BS=#`try with different batch sizes till you don't get OOM error,
#i.e., start with larger batch size and go on decreasing till it fits on GPU`time accelerate launch run_clm_no_trainer.py \
--model_name_or_path gpt2-xl \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size $BS
--per_device_eval_batch_size $BS
--num_train_epochs 1
--block_size 12
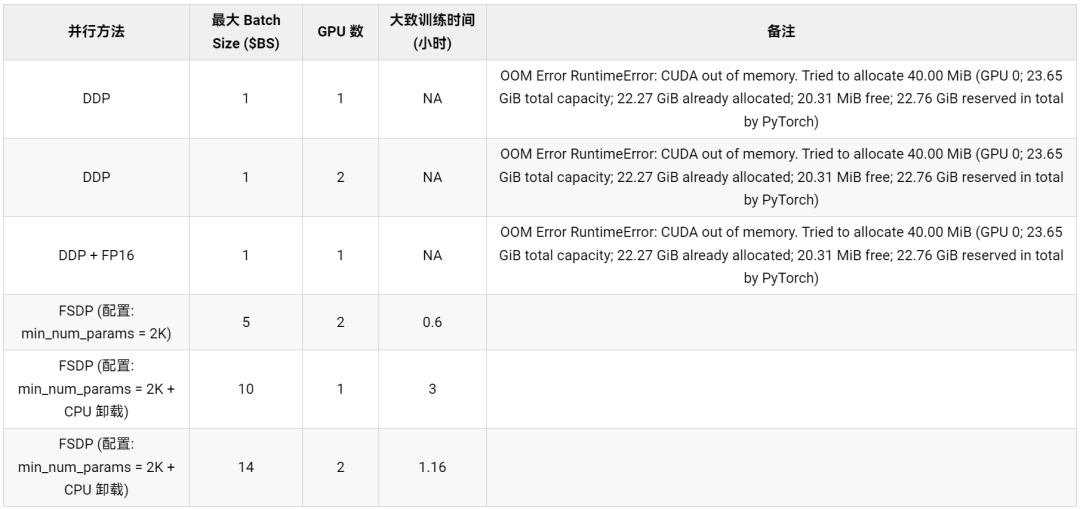
表 2: GPT-2 XL (1.5B) 模型上的 FSDP 基準測試
從表 2 中,我們可以觀察到 DDP (帶和不帶 fp16) 甚至在 batch size 為 1 的情況下就會出現 CUDA OOM 錯誤,從而無法運行。而開啟了 ZeRO- 階段 3 的 FSDP 能夠以 batch size 為 5 (總 batch size = 10 (5 2) ) 在 2 個 GPU 上運行。當使用 2 個 GPU 時,開啟了 CPU 卸載的 FSDP 還能將最大 batch size 進一步增加到每 GPU 14。開啟了 CPU 卸載的 FSDP 可以在單個 GPU 上訓練 GPT-2 1.5B 模型,batch size 為 10。這使得機器學習從業者能夠用最少的計算資源來訓練大模型,從而助力大模型訓練民主化。
Accelerate 的 FSDP 集成的功能和限制
下面,我們深入了解以下 Accelerate 對 FSDP 的集成中,支持了那些功能,有什么已知的限制。
支持 FSDP 所需的 PyTorch 版本: PyTorch Nightly 或 1.12.0 之后的版本。
命令行支持的配置:
-
分片策略: [1] FULL_SHARD, [2] SHARD_GRAD_OP
-
Min Num Params: FSDP 默認自動包裝的最小參數量。
-
Offload Params: 是否將參數和梯度卸載到 CPU。
如果想要對更多的控制參數進行配置,用戶可以利用 FullyShardedDataParallelPlugin ,其可以指定 auto_wrap_policy 、 backward_prefetch 以及 ignored_modules 。
創建該類的實例后,用戶可以在創建 Accelerator 對象時把該實例傳進去。
有關這些選項的更多信息,請參閱 PyTorch FullyShardedDataParallel 代碼。
接下來,我們體會下 min_num_params 配置的重要性。以下內容摘自 [8],它詳細說明了 FSDP 自動包裝策略的重要性。

FSDP 自動包裝策略的重要性
(圖源: 鏈接)
當使用 default_auto_wrap_policy 時,如果該層的參數量超過 min_num_params ,則該層將被包裝在一個 FSDP 模塊中。官方有一個在 GLUE MRPC 任務上微調 BERT-Large (330M) 模型的示例代碼,其完整地展示了如何正確使用 FSDP 功能,其中還包含了用于跟蹤峰值內存使用情況的代碼。
fsdp_with_peak_mem_tracking.py
我們利用 Accelerate 的跟蹤功能來記錄訓練和評估期間的峰值內存使用情況以及模型準確率指標。下圖展示了 wandb 實驗臺 頁面的截圖。
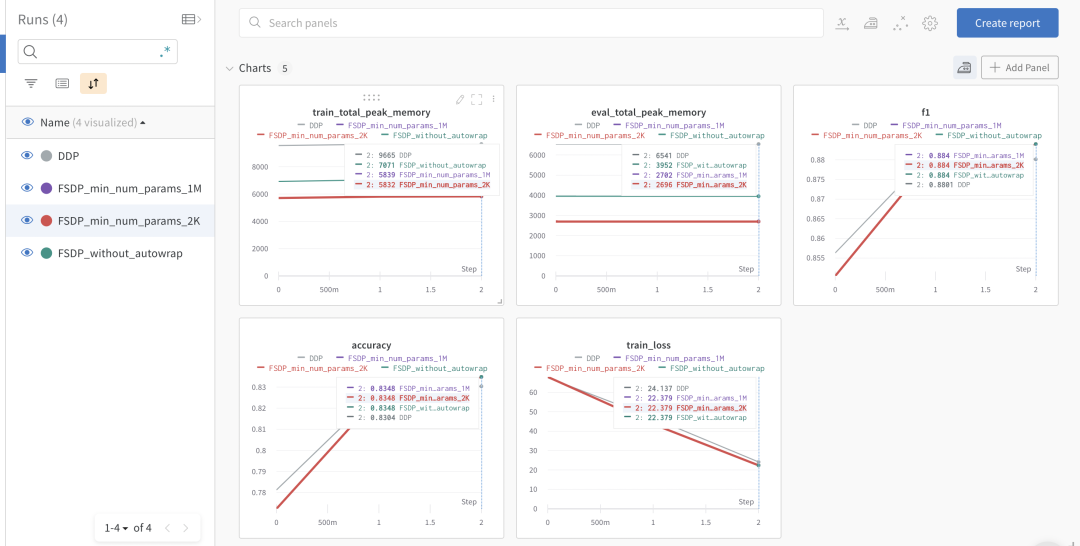
wandb 實驗臺
我們可以看到,DDP 占用的內存是使用了自動模型包裝功能的 FSDP 的兩倍。不帶自動模型包裝的 FSDP 比帶自動模型包裝的 FSDP 的內存占用更多,但比 DDP 少得多。與 min_num_params=1M 時相比, min_num_params=2k 時帶自動模型包裝的 FSDP 占用的內存略少。這凸顯了 FSDP 自動模型包裝策略的重要性,用戶應該調整 min_num_params 以找到能顯著節省內存又不會導致大量通信開銷的設置。如 [8] 中所述,PyTorch 團隊也在為此開發自動配置調優工具。
需要注意的一些事項
-
PyTorch FSDP 會自動對模型子模塊進行包裝、將參數攤平并對其進行原位分片。因此,在模型包裝之前創建的任何優化器都會被破壞并導致更多的內存占用。因此,強烈建議在對模型調用
prepare方法后再創建優化器,這樣效率會更高。對單模型而言,如果沒有按照順序調用的話,Accelerate會拋出以下告警信息,并自動幫你包裝模型并創建優化器。FSDP Warning: When using FSDP, it is efficient and recommended to call prepare for the model before creating the optimizer
即使如此,我們還是推薦用戶在使用 FSDP 時用以下方式顯式準備模型和優化器:
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", return_dict=True)
+ model = accelerator.prepare(model)optimizer = torch.optim.AdamW(params=model.parameters(), lr=lr)- model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(model,
- optimizer, train_dataloader, eval_dataloader, lr_scheduler
- )+ optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
+ optimizer, train_dataloader, eval_dataloader, lr_scheduler
+ )
-
對單模型而言,如果你的模型有多組參數,而你想為它們設置不同優化器超參。此時,如果你對整個模型統一調用
prepare方法,這些參數的組別信息會丟失,你會看到如下告警信息:FSDP Warning: When using FSDP, several parameter groups will be conflated into a single one due to nested module wrapping and parameter flattening.
告警信息表明,在使用 FSDP 對模型進行包裝后,之前創建的參數組信息丟失了。因為 FSDP 會將嵌套式的模塊參數攤平為一維數組 (一個數組可能包含多個子模塊的參數)。舉個例子,下面是 GPU 0 上 FSDP 模型的有名稱的參數 (當使用 2 個 GPU 時,FSDP 會把第一個分片的參數給 GPU 0, 因此其一維數組中大約會有 55M (110M / 2) 個參數)。此時,如果我們在 FSDP 包裝前將 BERT-Base 模型的 [bias, LayerNorm.weight] 參數的權重衰減設為 0,則在模型包裝后,該設置將無效。原因是,你可以看到下面這些字符串中均已不含這倆參數的名字,這倆參數已經被并入了其他層。想要了解更多細節,可參閱本 問題 (其中寫道: 原模型參數沒有 .grads 屬性意味著它們無法單獨被優化器優化 (這就是我們為什么不能支持對多組參數設置不同的優化器超參) )。
{
'_fsdp_wrapped_module.flat_param': torch.Size([494209]),'_fsdp_wrapped_module._fpw_module.bert.embeddings.word_embeddings._fsdp_wrapped_module.flat_param': torch.Size([11720448]),'_fsdp_wrapped_module._fpw_module.bert.encoder._fsdp_wrapped_module.flat_param': torch.Size([42527232])
}
-
如果是多模型情況,須在創建優化器之前調用模型
prepare方法,否則會拋出錯誤。 -
FSDP 目前不支持混合精度,我們正在等待 PyTorch 修復對其的支持。
工作原理 📝
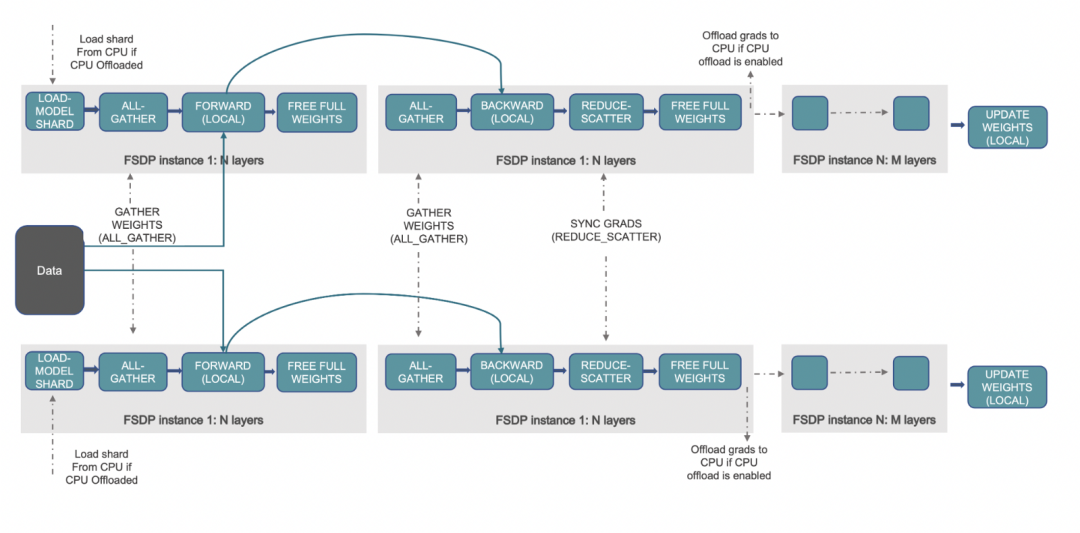
FSDP 工作流
(圖源: 鏈接)
上述工作流概述了 FSDP 的幕后流程。我們先來了解一下 DDP 是如何工作的,然后再看 FSDP 是如何改進它的。在 DDP 中,每個工作進程 (加速器 / GPU) 都會保留一份模型的所有參數、梯度和優化器狀態的副本。每個工作進程會獲取不同的數據,這些數據會經過前向傳播,計算損失,然后再反向傳播以生成梯度。接著,執行 all-reduce 操作,此時每個工作進程從其余工作進程獲取梯度并取平均。這樣一輪下來,每個工作進程上的梯度都是相同的,且都是全局梯度,接著優化器再用這些梯度來更新模型參數。我們可以看到,每個 GPU 上都保留完整副本會消耗大量的顯存,這限制了該方法所能支持的 batch size 以及模型尺寸。
FSDP 通過讓各數據并行工作進程分片存儲優化器狀態、梯度和模型參數來解決這個問題。進一步地,還可以通過將這些張量卸載到 CPU 內存來支持那些 GPU 顯存容納不下的大模型。在具體運行時,與 DDP 類似,FSDP 的每個工作進程獲取不同的數據。在前向傳播過程中,如果啟用了 CPU 卸載,則首先將本地分片的參數搬到 GPU/加速器。然后,每個工作進程對給定的 FSDP 包裝模塊/層執行 all-gather 操作以獲取所需的參數,執行計算,然后釋放/清空其他工作進程的參數分片。在對所有 FSDP 模塊全部執行該操作后就是計算損失,然后是后向傳播。在后向傳播期間,再次執行 all-gather 操作以獲取給定 FSDP 模塊所需的所有參數,執行計算以獲得局部梯度,然后再次釋放其他工作進程的分片。最后,使用 reduce-scatter 操作對局部梯度進行平均并將相應分片給對應的工作進程,該操作使得每個工作進程都可以更新其本地分片的參數。如果啟用了 CPU 卸載的話,梯度會傳給 CPU,以便直接在 CPU 上更新參數。
如欲深入了解 PyTorch FSDP 工作原理以及相關實驗及其結果,請參閱 [7,8,9]。
問題
如果在 accelerate 中使用 PyTorch FSDP 時遇到任何問題,請提交至 accelerate。
但如果你的問題是跟 PyTorch FSDP 配置和部署有關的 - 你需要提交相應的問題至 PyTorch。
參考文獻
[1] Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers
[2] ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
[3] DeepSpeed: Extreme-scale model training for everyone - Microsoft Research
[4] Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
[5] Introducing GPipe, an Open Source Library for Efficiently Training Large-scale Neural Network Models
[6] Which hardware do you need to train a 176B parameters model?
[7] Introducing PyTorch Fully Sharded Data Parallel (FSDP) API | PyTorch
[8] Getting Started with Fully Sharded Data Parallel(FSDP) — PyTorch Tutorials 1.11.0+cu102 documentation
[9] Training a 1 Trillion Parameter Model With PyTorch Fully Sharded Data Parallel on AWS | by PyTorch | PyTorch | Mar, 2022 | Medium
[10] Fit More and Train Faster With ZeRO via DeepSpeed and FairScale
[11] https://huggingface.co/blog/zh/pytorch-fsdp






)



:RK3568底板電路mipi攝像頭接口原理圖分析、mipi攝像頭詳解)








