- 項目背景
- SQLite介紹
- SQLite、驅動包下載
- SQLite使用
- SQLite和MySQL區別
- JDBC搭配SQLite
- JDBC原理-創建連接
- JDBC原理-關閉連接
- 添加和發送SQL
- JDBC-事務開啟和提交
- 打包.exe文件
- 線程池線程數量問題
項目背景
需求上:因為Windows的文件搜索工具搜索速度十分的慢;讓大家苦不堪言;是否能利用以前學習的知識實現這樣子的一個功能呢?
項目優點:
1:搜索速度相近于世面眾多文件搜索工具;文件大小只需13.4MB
2:靈動搜索;能支持文件名字拼音進行搜索;只需會讀即可搜索
3:能自主靈活改動;能隨時根據自己和體驗人員的需求進行擴展和升級。
4:無廣告、無會員、更新的選擇權在于用戶;不自主占用過多內存
SQLite介紹
SQLite、驅動包下載

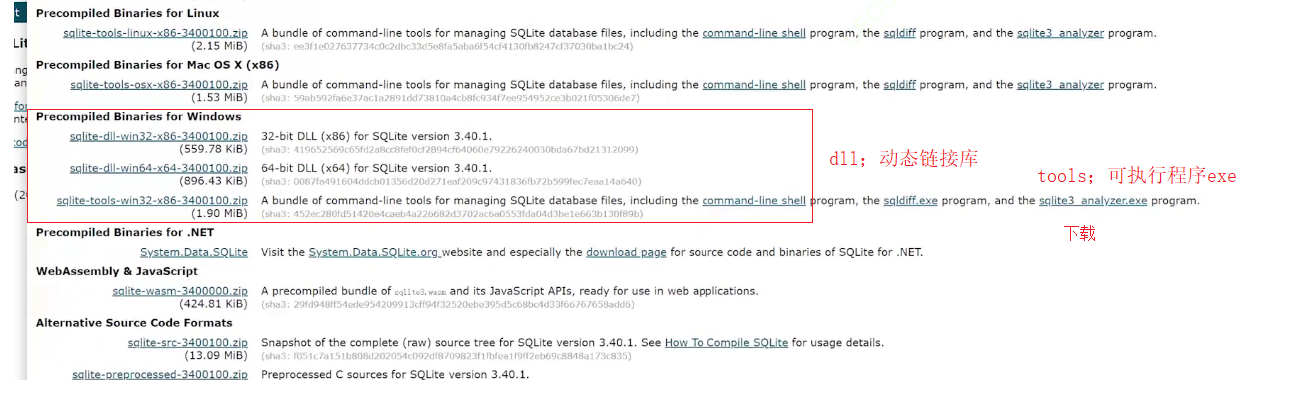
解壓后三個文件:我們只取sqlite3.exe即可
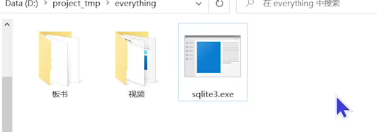
SQLite使用
雙擊打開:它會提升連接到一個臨時內存數據庫;使用.open FILENAME重新打開一個永久數據庫
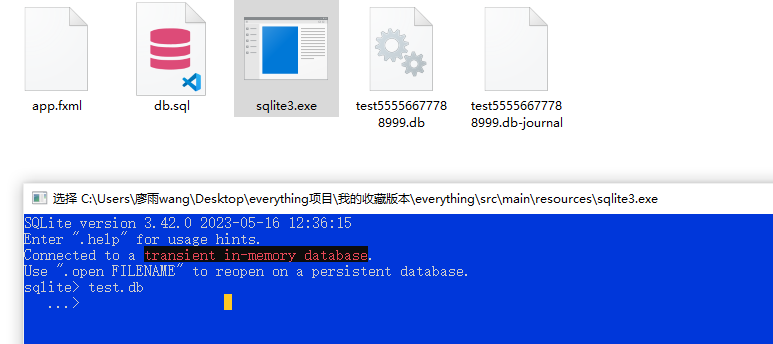
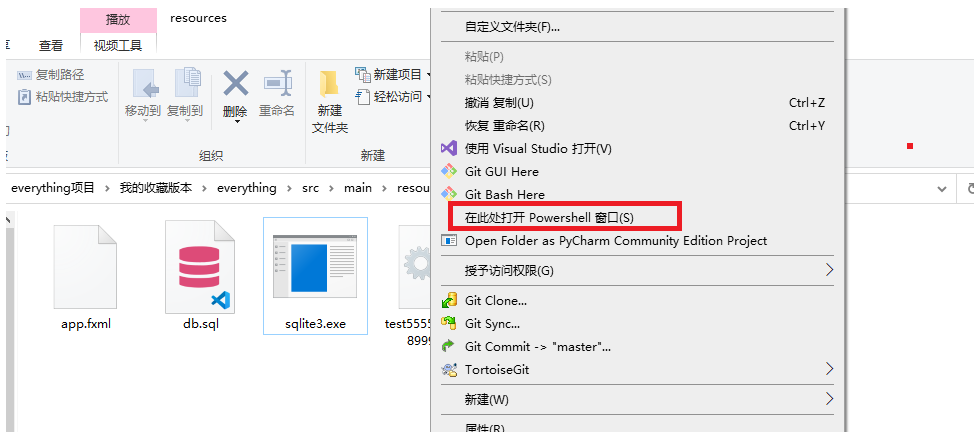
我們回到exe文件里:shift+右鍵空白處

SQLite和MySQL區別
1:它不是客戶端服務器結構;直接就是一個可執行程序;數據庫直接文件的方式表示
2:操作大同小異;但是極個別不一樣;SQLite是不需要create database/use /drop database/show databases……
所以我們要刪除、顯示數據庫直接去文件里操作即可
3:SQLite輕量;一個數據庫只有1M左右;給別人使用總不可能給別人帶個幾百MB的MySQL
4:sqlite中并不需要選中表;直接操作即可因為我們增刪查改都會帶上表名;它會去匹配是哪個表的;這個非常符合我們在用戶電腦中我的帶上的數據庫文件創建表然后就能直接使用。要顯示知道數據庫有哪些表:.tables (MySQL里的show table不適合用)
5:SQLite插入數據會鎖整個表;讀和讀之間無競爭;寫和讀、寫和寫有競爭。MySQL默認隔離級別是可重復讀;使用MVCC和鎖機制保證的隔離性;讀和讀之間使用共享鎖不會鎖競爭;寫使用排它鎖會發生競爭。插入數據時使用行級鎖。
6:SQLite是沒有int類型;但是它為了兼容其它數據庫;使用支持我們寫int;它內部自動進行轉換成Integer;但是你要想使用自增主鍵就必須使用Integer
JDBC搭配SQLite
JDBC原理-創建連接
本質都是通過 Connection 對象才能連接到相應的數據庫;獲取建立連接有兩種方式如下:
1:DriverManager;驅動管理;早期的jdbc版本你是需要顯示加載驅動程序Class.forName(“com.mysql.jdbc.Driver”);4.0以后的版本引入了自動驅動程序加載機制后;你直接創建連接即可
Class.forName("com.mysql.jdbc.Driver");//加載驅動程序
DriverManager.getConnection("jdbc:mysql://localhost:3306/test&user=root&password=root&useUnicode=true&characterEncoding=UTF-8");//或者String url = "jdbc:mysql://localhost:3306/mydatabase";String username = "user";String password = "password";Connection connection = DriverManager.getConnection(url, username, password);
2:DataSoure;可以被視為一個數據源池,其中包含了預先創建的Connection對象,應用程序可以從中獲取連接對象并使用。
((MysqlDataSource)dataSource).setURL("jdbc:mysql://127.0.0.1:3306/liao?characterEncoding=utf8&useSSL=false");((MysqlDataSource)dataSource).setUser("root");((MysqlDataSource)dataSource).setPassword("111111");兩者的區別:
1:相當于一個是直接創建 Connection 對象就需要設置相關連接信息。而另一個是它內部幫你創建好;你通過DataSoure設置相應的連接信息:dataSource.setURL(“jdbc:mysql://127.0.0.1:3306/liao?characterEncoding=utf8&useSSL=false”);。本質都是在設置Connection對象。
2:DataSource是這些Connection對象是它幫你創建好存在那里;你只需要通過dataSource設置相應信息;然后通過這個dataSource對象獲取這個連接即可。相當于一個懶漢模式;一個餓漢模式。
3: Connection.close時候;雖然都是斷開連接;釋放資源;DataSource是把Connection還給這個連接池;就是說我現在用完了;現在你其它人可以復用這個連接了
JDBC原理-關閉連接
使用完成connection、Resultset、statement對象都需要回收
public static void close(Connection connection, Statement statement, ResultSet resultSet) {if (resultSet != null) {try {resultSet.close();} catch (SQLException e) {e.printStackTrace();}}if (statement != null) {try {statement.close();} catch (SQLException e) {e.printStackTrace();}}if (connection != null) {try {connection.close();} catch (SQLException e) {e.printStackTrace();}}}
添加和發送SQL
Statement對象主要是將SQL語句發送到數據庫中;通常使用的是PreparedStatement;PreparedStatement是Statemen子類
如何獲取這個對象:
//建表特殊一點
connection=數據源對象.getConnection();
statement=connection.createStatement();
//
String sql="insert into file_meta values(null,?,?,?,?,?,?,?)";
preparedStatement=connection.prepareStatement(sql);
這個對象有什么好處:
好處1: 預編譯;執行之前,會先將SQL語句預編譯,并緩存編譯后的執行計劃。這樣可以提高性能,尤其是需要多次執行相同或類似的SQL語句時。
好處2:支持使用占位符(?)來表示參數,然后通過調用setXXX()方法為占位符設置具體的參數值。更安全(能防SQL注入)、數據和SQL分開更好閱讀
好處3:對于重復執行相同的SQL語句(如批量插入),由于預編譯的存在,性能通常比Statement更好。就是它會在MySQL這些數據庫服務器緩存的執行計劃和結果。
如何真正將sql發送:
executeQuery() 方法執行后返回Resultset單個結果集的,通常用于select語句。如何遍歷這個結果集:
while (resultSet.next()) {
String name=resultSet.getString("name");
}
executeUpdate()方法返回值是一個整數,指示受影響的行數,通常用于update、insert、delete;create創建表也是用這個提交的;語句
JDBC-事務開啟和提交
connection.setAutoCommit(false);//開啟事務;先關閉自動提交的功能String sql="insert into file_meta values(null,"123")";preparedStatement=connection.prepareStatement(sql);String sql2="insert into file_meta values(null,"234")";preparedStatement=connection.prepareStatement(sql2);preparedStatement.addBatch();//在這里累計//執行SQL;preparedStatement.executeBatch();//執行完提交事務;使用commit提交事務connection.commit();
使用你得try catch包裹一下;出現異常回滾 connection.rollback(); 最后finally釋放資源
打包.exe文件
對于學習來說興趣是最好的老師;能把一個程序給身邊的親朋好友使用;這無疑能給我們提供很大的學習動力。想要別人能成功的使用你的程序;兩種常見手段
第一種:web項目部署云服務器上;別人能通過網絡使用你的程序
第二種:把你的程序打包成一個.exe可執行文件給別人使用
需要將依賴的資源一起打包成 JAR 文件,可以使用 Maven 插件來實現。常見的 Maven 插件是 maven-assembly-plugin 和 maven-shade-plugin。使用 maven-assembly-plugin如下:
1:添加配置
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.3.0</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>2:
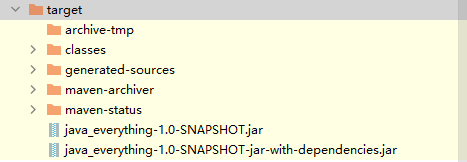
java_everything-1.0-SNAPSHOT.jar:只包含了項目自身的編譯輸出(類文件)和資源文件。不包含任何依賴項或第三方庫,也叫"瘦"JAR。
java_everything-1.0-SNAPSHOT-jar-with-dependencies.jar:這個 JAR 包是使用 maven-assembly-plugin 插件創建的,它將項目及其所有的依賴項一起打包到一個單獨的可執行 JAR 文件中,也叫"胖"JAR。
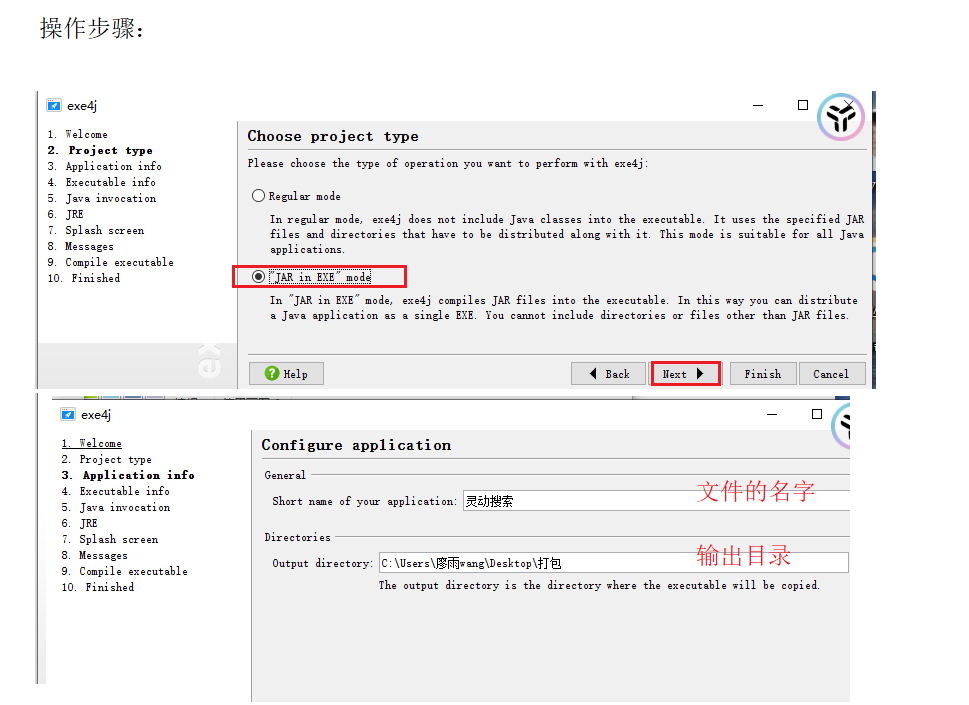
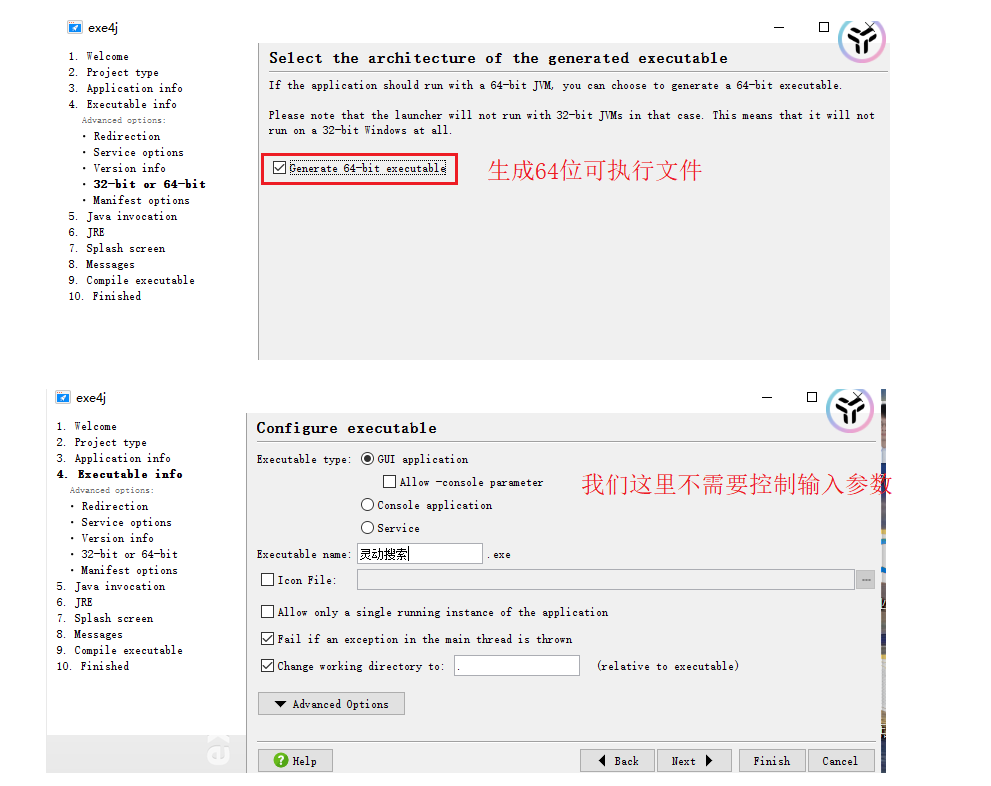
3:打包成.exe文件
需要用exe4j軟件:操作步驟如下
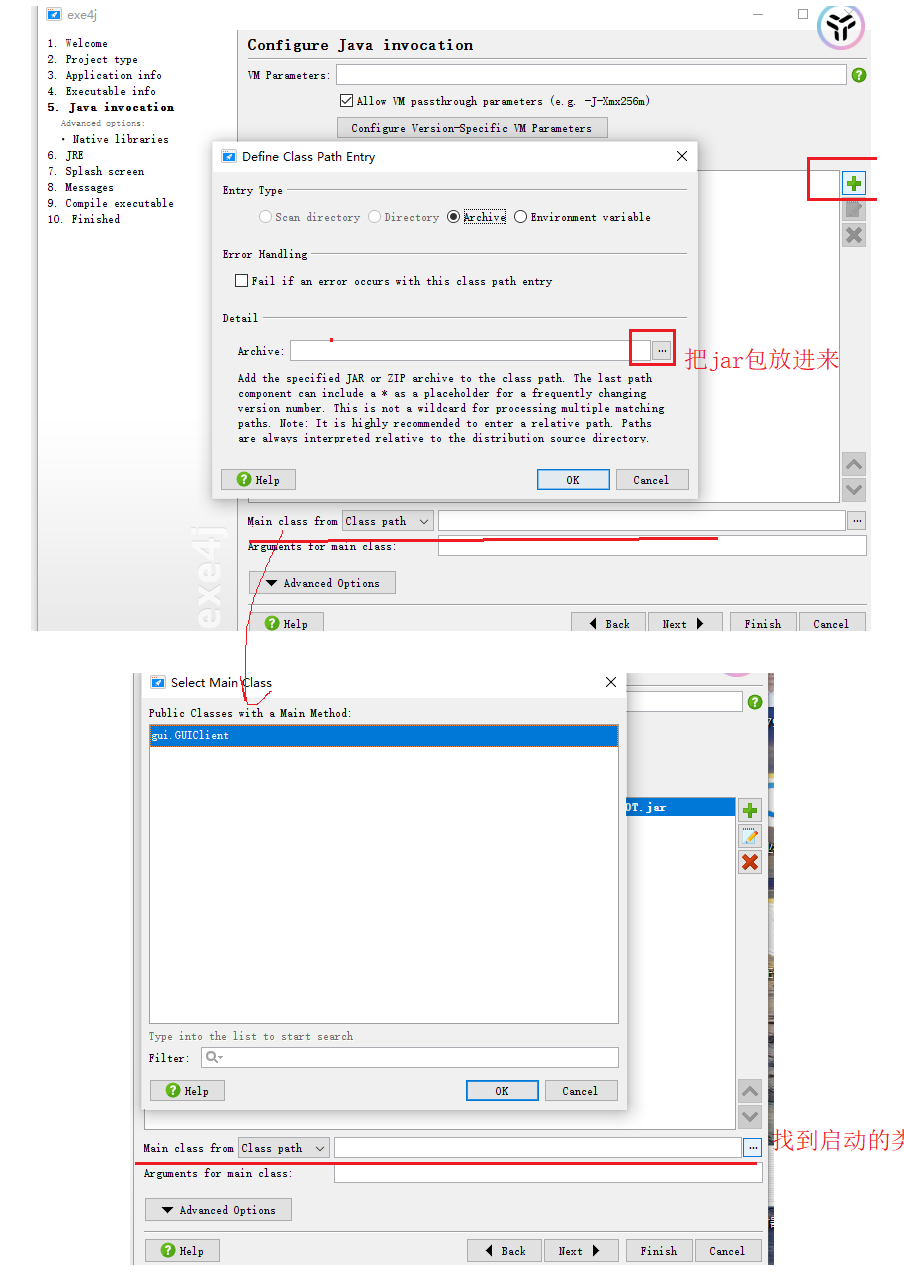
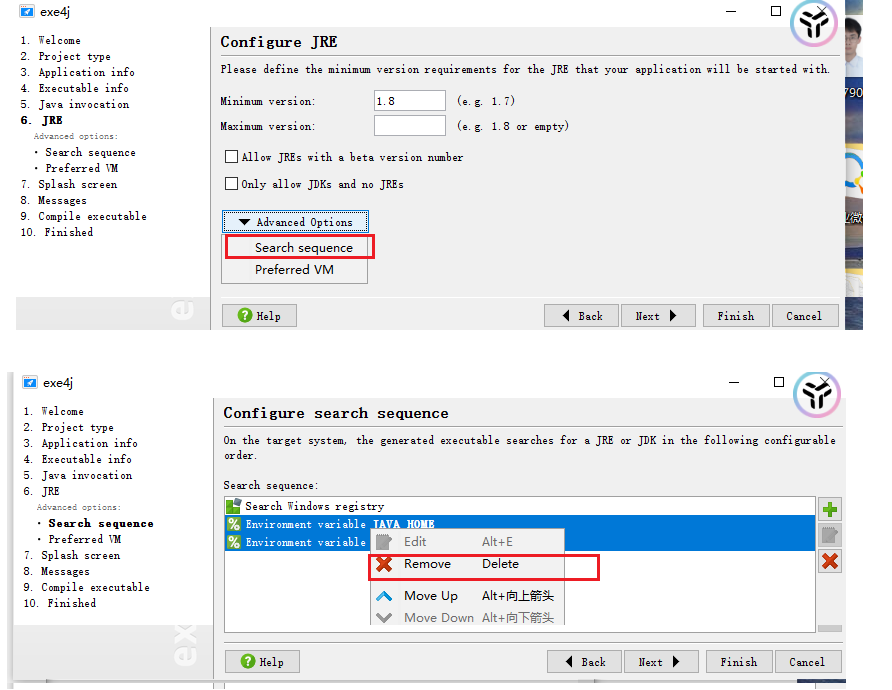
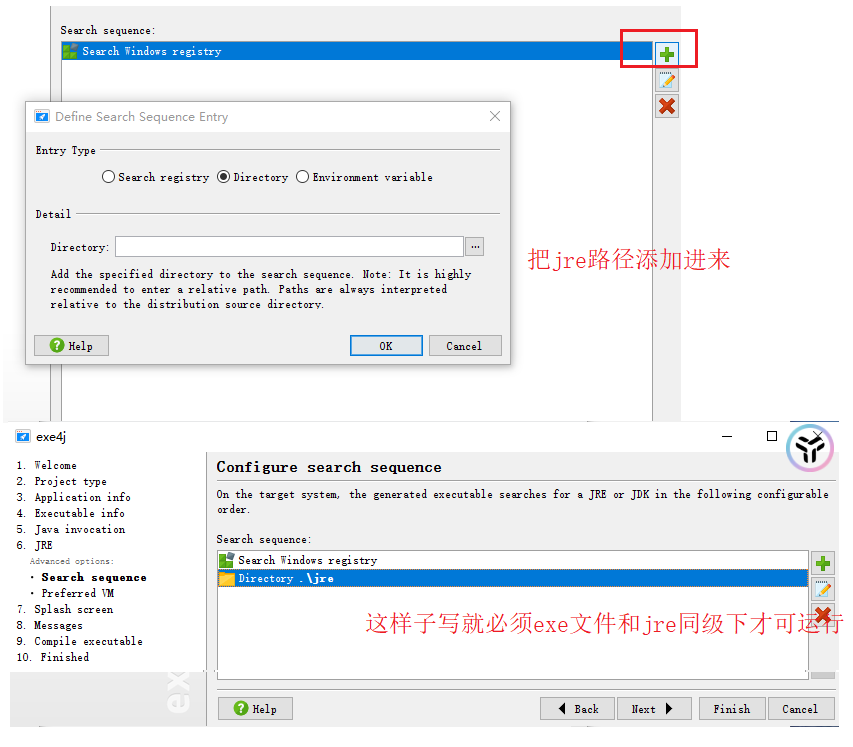
4:測試效果
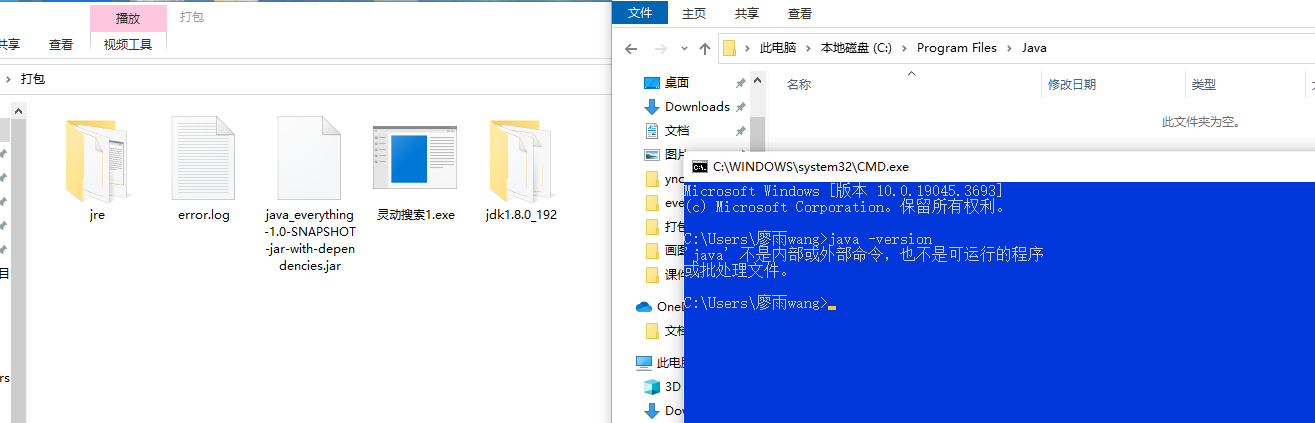
先讓我們本地Java環境失效看看能否執行
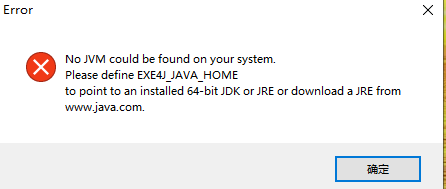
jre一定得是在同級下;因為打包時配置的是同級目錄下;否則會出現
線程池線程數量問題

這里涉及一個問題:使用線程池添加任務;那么線程池的數量應該多少合適?
解決上述問題,可以采用測試的方法來驗證適合的線程池數量,并使用計時方法來測量執行時間。但是會有指令重排序問題;解決這個問題;通過線程之間通信;等添加任務完成再通知它結束計時。但是我怎么知道線程池什么時候執行結束呢?
方法1:
threadPool.getTaskCount() != threadPool.getCompletedTaskCount();//統計已執行的任務和總任務比較。但是不準確;因為任務是一直在變化和添加;所以你需要寫輪詢的方式去判斷。也可能我只想判斷當前這個任務的三個線程是否執行完;中途別人又添加任務了;那就不精準了。方法2:
ExecutorService executor=Executors.newFixedThreadPool(10);
FutureTask<Integer> task=new FutureTask(()->{//任務return -1;
});
executor.submit(task);
int result=task.get();//這個方法就能等待所有任務執行完畢并返回結果方法3:特殊場景;可以使用計數器的方式;因為給線程池添加任務是內存進行非常快;而真正執行更新數據操作硬盤是相對非常慢。所以我們每向線程池添加一個任務就計數器++;線程池執行完一個任務就計數器–。但是這又有一個問題;使用普通計數器會原子性問題。這里能通過使用原子類解決問題。
簡化后代碼:
public class FileManager {Object object=new Object();private AtomicInteger taskCount = new AtomicInteger(0);//計數器public void scanAll(File basePath) {System.out.println("[FileManager] scanAll 開始!");long beg = System.currentTimeMillis();scanAllByThreadPool(basePath);try {synchronized (object){object.wait();}} catch (InterruptedException e) {e.printStackTrace();}long end = System.currentTimeMillis();System.out.println("[FileManager] scanAll 結束! 執行時間: " + (end - beg) + " ms");}private static ExecutorService executorService = Executors.newFixedThreadPool(100);private void scanAllByThreadPool(File basePath) {// 計數器自增taskCount.getAndIncrement(); // taskCount++// 掃描操作, 放到線程池里完成.executorService.submit(new Runnable() {@Overridepublic void run() {try {scan(basePath);//執行任務} finally {//寫在這里防止中間出問題--失敗而永遠計數器達不到0taskCount.getAndDecrement(); // taskCount--if (taskCount.get() == 0) {// 如果計數器為 0 ; 通知主線程結束計時了.synchronized (object){object.notify();}}}}});
}
)

)



用法)
)









)
