導語:前期入門Flink時,可以直接編寫通過idea編寫Flink程序,然后直接運行main方法,無需搭建環境。我碰到許多初次接觸Flink的同學,被各種環境搭建、提交作業、復雜概念給勸退了。前期最好的入門方式就是直接上手寫代碼,main方法跑demo,快速了解概念,等入門之后再去實踐集群環境、各種作業提交、各種復雜概念。
Flink官網:Apache Flink Documentation | Apache Flink
一、Flink實時計算
1.1、Flink定義
Apache Flink 是一個框架和分布式處理引擎,用于在無邊界和有邊界數據流上進行有狀態的計算。Flink 能在所有常見集群環境中運行,并能以內存速度和任意規模進行計算。截止目前2023年12月Flink最新版本為v1.18.0。
說白了,Flink就是個實時處理數據任務的框架,這個框架幫助開發者執行數據處理的任務,讓開發者無需關心高可用、性能等問題。如果你有一些數據任務需要執行,比如數據監控、數據分析、數據同步,那就可以考慮使用Flink。所謂流計算就是對源源不斷的數據進行計算,中間的計算結果存放在內存或者外部存儲,這就是有狀態的流計算。
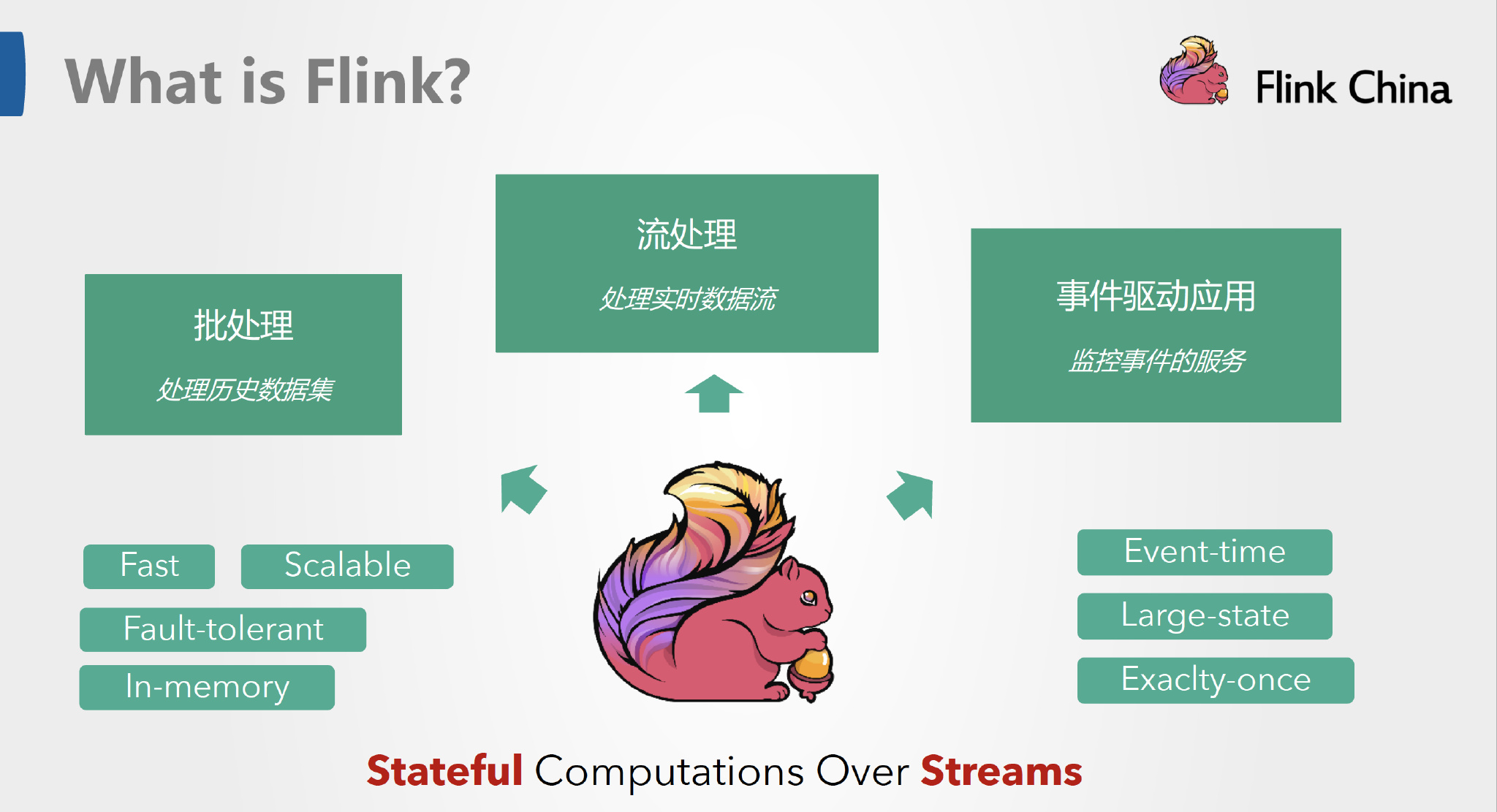
Apache Flink 是一個框架和分布式處理引擎,用于在無邊界和有邊界數據流上進行有狀態的計算。Flink 能在所有常見集群環境中運行,并能以內存速度和任意規模進行計算。
Apache Flink 功能強大,支持開發和運行多種不同種類的應用程序。它的主要特性包括:批流一體化、精密的狀態管理、事件時間支持以及精確一次的狀態一致性保障等。Flink 不僅可以運行在包括 YARN、 Mesos、Kubernetes 在內的多種資源管理框架上,還支持在裸機集群上獨立部署。在啟用高可用選項的情況下,它不存在單點失效問題。事實證明,Flink 已經可以擴展到數千核心,其狀態可以達到 TB 級別,且仍能保持高吞吐、低延遲的特性。世界各地有很多要求嚴苛的流處理應用都運行在 Flink 之上。
1.2、Flink分層API
Flink 根據抽象程度分層,提供了三種不同的 API。每一種 API 在簡潔性和表達力上有著不同的側重,并且針對不同的應用場景。
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-sD2aHoNE-1612775779487)(/Users/bytedance/Desktop/nJou61.jpg)]](https://img-blog.csdnimg.cn/img_convert/090df542e30617dbca744a038763dbbe.jpeg)
Flink分層API
-
ProcessFunction:可以處理一或兩條輸入數據流中的單個事件或者歸入一個特定窗口內的多個事件。它提供了對于時間和狀態的細粒度控制。開發者可以在其中任意地修改狀態,也能夠注冊定時器用以在未來的某一時刻觸發回調函數。因此,你可以利用ProcessFunction實現許多有狀態的事件驅動應用所需要的基于單個事件的復雜業務邏輯。
-
DataStream API:為許多通用的流處理操作提供了處理原語。這些操作包括窗口、逐條記錄的轉換操作,在處理事件時進行外部數據庫查詢等。DataStream API 支持 Java 和 Scala 語言,預先定義了例如
map()、reduce()、aggregate()等函數。你可以通過擴展實現預定義接口或使用 Java、Scala 的 lambda 表達式實現自定義的函數。 -
SQL & Table API:Flink 支持兩種關系型的 API,Table API 和 SQL。這兩個 API 都是批處理和流處理統一的 API,這意味著在無邊界的實時數據流和有邊界的歷史記錄數據流上,關系型 API 會以相同的語義執行查詢,并產生相同的結果。Table API和SQL借助了 Apache Calcite來進行查詢的解析,校驗以及優化。它們可以與DataStream和DataSet API無縫集成,并支持用戶自定義的標量函數,聚合函數以及表值函數。Flink 的關系型 API 旨在簡化數據分析、數據流水線和 ETL 應用的定義。
1.3、Flink主要組件
存儲層:Flink本身并沒有提供分布式文件系統,因此Flink的分析大多依賴外部存儲。
調度層:Flink自帶一個簡易的資源調度器,稱為獨立調度器(Standalone)。若集群中沒有任何資源管理器,則可以使用自帶的獨立調度器。當然,Flink也支持在其他的集群管理器上運行,包括Hadoop YARN、Apache Mesos等。
計算層:Flink的核心是一個對由很多計算任務組成的、運行在多個工作機器或者一個計算集群上的應用進行調度、分發以及監控的計算引擎,為API工具層提供基礎服務。
工具層:在Flink Runtime的基礎上,Flink提供了面向流處理(DataStream API)和批處理(DataSetAPI)的不同計算接口,并在此接口上抽象出了不同的應用類型組件庫,例如基于流處理的CEP(復雜事件處理庫)、Table&SQL(結構化表處理庫)和基于批處理的Gelly(圖計算庫)、FlinkML(機器學習庫)、Table&SQL(結構化表處理庫)。
1.4、Flink特點
Apache Flink是一個集合眾多具有競爭力特性于一身的第三代流處理引擎,它的以下特點使得它能夠在同類系統中脫穎而出。
-
同時支持高吞吐、低延遲、高性能。
-
Flink是目前開源社區中唯一一套集高吞吐、低延遲、高性能三者于一身的分布式流式處理框架。像Apache Spark也只能兼顧高吞吐和高性能特性,主要因為在Spark Streaming流式計算中無法做到低延遲保障;而流式計算框架Apache Storm只能支持低延遲和高性能特性,但是無法滿足高吞吐的要求。
-
-
同時支持事件時間和處理時間語義。
-
在流式計算領域中,窗口計算的地位舉足輕重,但目前大多數框架窗口計算采用的都是處理時間,也就是事件傳輸到計算框架處理時系統主機的當前時間。Flink能夠支持基于事件時間語義進行窗口計算,也就是使用事件產生的時間,這種基于事件驅動的機制使得事件即使亂序到達,流系統也能夠計算出精確的結果,保證了事件原本的時序性。
-
-
支持有狀態計算,并提供精確一次的狀態一致性保障。
-
所謂狀態就是在流式計算過程中將算子的中間結果數據保存著內存或者文件系統中,等下一個事件進入算子后可以從之前的狀態中獲取中間結果中計算當前的結果,從而不須每次都基于全部的原始數據來統計結果,這種方式極大地提升了系統的性能,并降低了數據計算過程的資源消耗。
-
-
基于輕量級分布式快照實現的容錯機制。
-
Flink能夠分布式運行在上千個節點上,將一個大型計算任務的流程拆解成小的計算過程,然后將Task分布到并行節點上進行處理。在任務執行過程中,能夠自動發現事件處理過程中的錯誤而導致的數據不一致問題,在這種情況下,通過基于分布式快照技術的Checkpoints,將執行過程中的狀態信息進行持久化存儲,一旦任務出現異常終止,Flink就能夠從Checkpoints中進行任務的自動恢復,以確保數據中處理過程中的一致性。
-
-
保證了高可用,動態擴展,實現7 * 24小時全天候運行。
-
支持高可用性配置(無單點失效),和Kubernetes、YARN、Apache Mesos緊密集成,快速故障恢復,動態擴縮容作業等。基于上述特點,它可以7 X 24小時運行流式應用,幾乎無須停機。當需要動態更新或者快速恢復時,Flink通過Savepoints技術將任務執行的快照保存在存儲介質上,當任務重啟的時候可以直接從事先保存的Savepoints恢復原有的計算狀態,使得任務繼續按照停機之前的狀態運行。
-
-
支持高度靈活的窗口操作。
-
Flink將窗口劃分為基于Time、Count、Session,以及Data-driven等類型的窗口操作,窗口可以用靈活的觸發條件定制化來達到對復雜流傳輸模式的支持,用戶可以定義不同的窗口觸發機制來滿足不同的需求。
-
1.5、Flink應用場景
在實際生產的過程中,大量數據在不斷地產生,例如金融交易數據、互聯網訂單數據、GPS定位數據、傳感器信號、移動終端產生的數據、通信信號數據等,以及我們熟悉的網絡流量監控、服務器產生?的日志數據?,這些數據最大的共同點就是實時從不同的數據源中產生,然后再傳輸到下游的分析系統。
針對這些數據類型主要包括以下場景,Flink對這些場景都有非常好的支持。
-
實時智能推薦
利用Flink流計算幫助用戶構建更加實時的智能推薦系統,對用戶行為指標進行實時計算,對模型進行實時更新,對用戶指標進行實時預測,并將預測的信息推送給Web/App端,幫助用戶獲取想要的商品信息,另一方面也幫助企業提高銷售額,創造更大的商業價值。
-
復雜事件處理
例如工業領域的復雜事件處理,這些業務類型的數據量非常大,且對數據的時效性要求較高。我們可以使用Flink提供的CEP(復雜事件處理)進行事件模式的抽取,同時應用Flink的SQL進行事件數據的轉換,在流式系統中構建實時規則引擎。
-
實時欺詐檢測
在金融領域的業務中,常常出現各種類型的欺詐行為。運用Flink流式計算技術能夠在毫秒內就完成對欺詐判斷行為指標的計算,然后實時對交易流水進行規則判斷或者模型預測,這樣一旦檢測出交易中存在欺詐嫌疑,則直接對交易進行實時攔截,避免因為處理不及時而導致的經濟損失
-
實時數倉與ETL
結合離線數倉,通過利用流計算等諸多優勢和SQL靈活的加工能力,對流式數據進行實時清洗、歸并、結構化處理,為離線數倉進行補充和優化。另一方面結合實時數據ETL處理能力,利用有狀態流式計算技術,可以盡可能降低企業由于在離線數據計算過程中調度邏輯的復雜度,高效快速地處理企業需要的統計結果,幫助企業更好的應用實時數據所分析出來的結果。
-
流數據分析
實時計算各類數據指標,并利用實時結果及時調整在線系統相關策略,在各類投放、無線智能推送領域有大量的應用。流式計算技術將數據分析場景實時化,幫助企業做到實時化分析Web應用或者App應用的各種指標。
-
實時報表分析
實時報表分析說近年來很多公司采用的報表統計方案之一,其中最主要的應用便是實時大屏展示。利用流式計算實時得出的結果直接被推送到前段應用,實時顯示出重要的指標變換,最典型的案例就是淘寶的雙十一實時戰報。
二、Flink架構
我們可以建立一個Flink大體上的框架,助力快速上手Flink。學習Flink最有效的方式是先入門了解框架和概念,然后邊寫代碼邊實踐,然后再把官網看一遍。

Apache Flink 是一個框架和分布式處理引擎,用于在無邊界和有邊界數據流上進行有狀態的計算。Flink 能在所有常見集群環境中運行,并能以內存速度和任意規模進行計算。
接下來,我們來介紹一下 Flink 架構中的重要方面。
2.1、批與流
-
批處理的特點是有界、持久、大量,非常適合需要訪問全套記錄才能完成的計算工作,一般用于離線統計。
-
流處理的特點是無界、實時, 無需針對整個數據集執行操作,而是對通過系統傳輸的每個數據項執行操作,一般用于實時統計。
在Spark的世界觀中,一切都是由批次組成的,離線數據是一個大批次,而實時數據是由一個一個無限的小批次組成的。而在Flink的世界觀中,一切都是由流組成的,離線數據是有界限的流,實時數據是一個沒有界限的流,這就是所謂的有界流和無界流。
2.2、處理無界和有界數據?
任何類型的數據都可以形成一種事件流。信用卡交易、傳感器測量、機器日志、網站或移動應用程序上的用戶交互記錄,所有這些數據都形成一種流。
數據可以被作為?無界?流? 或者?有界?流來處理。
-
無界流?有定義流的開始,但沒有定義流的結束。它們會無休止地產生數據。無界流的數據必須持續處理,即數據被攝取后需要立刻處理。我們不能等到所有數據都到達再處理,因為輸入是無限的,在任何時候輸入都不會完成。處理無界數據通常要求以特定順序攝取事件,例如事件發生的順序,以便能夠推斷結果的完整性。
-
有界流?有定義流的開始,也有定義流的結束。有界流可以在攝取所有數據后再進行計算。有界流所有數據可以被排序,所以并不需要有序攝取。有界流處理通常被稱為批處理。

Apache Flink 擅長處理無界和有界數據集?精確的時間控制和狀態化使得 Flink 的運行時(runtime)能夠運行任何處理無界流的應用。有界流則由一些專為固定大小數據集特殊設計的算法和數據結構進行內部處理,產生了出色的性能。
通過探索 Flink 之上構建的用例來加深理解。
2.3、部署應用到任意地方?
Apache Flink 是一個分布式系統,它需要計算資源來執行應用程序。Flink 集成了所有常見的集群資源管理器,? 例如 Hadoop YARN、 Apache Mesos 和 Kubernetes, ?但同時也可以作為獨立集群運行。
Flink 被設計為能夠很好地工作在上述每個資源管理器中,這是通過資源管理器特定(resource-manager-specific)的部署模式實現的。Flink 可以采用與當前資源管理器相適應的方式進行交互。
部署 Flink 應用程序時,Flink 會根據應用程序配置的并行性自動標識所需的資源,并從資源管理器請求這些資源。在發生故障的情況下,Flink 通過請求新資源來替換發生故障的容器。提交或控制應用程序的所有通信都是通過 REST 調用進行的,這可以簡化 Flink 與各種環境中的集成。
2.3、運行任意規模應用?
Flink 旨在任意規模上運行有狀態流式應用。因此,應用程序被并行化為可能數千個任務,這些任務分布在集群中并發執行。所以應用程序能夠充分利用無盡的 CPU、內存、磁盤和網絡 IO。而且 Flink 很容易維護非常大的應用程序狀態。其異步和增量的檢查點算法對處理延遲產生最小的影響,同時保證精確一次狀態的一致性。
-
處理每天處理數萬億的事件,
-
應用維護幾TB大小的狀態,
-
應用在數千個內核上運行。
2.4、利用內存性能?
有狀態的 Flink 程序針對本地狀態訪問進行了優化。任務的狀態始終保留在內存中,如果狀態大小超過可用內存,則會保存在能高效訪問的磁盤數據結構中。任務通過訪問本地(通常在內存中)狀態來進行所有的計算,從而產生非常低的處理延遲。Flink 通過定期和異步地對本地狀態進行持久化存儲來保證故障場景下精確一次的狀態一致性。
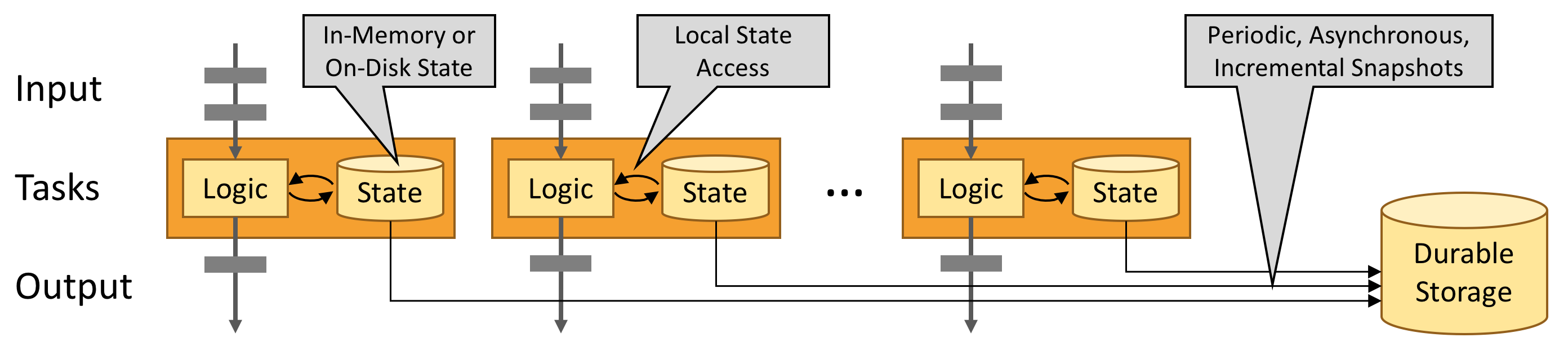
三、Flink VS Spark
3.1、Spark和Flink中的功能集在很多方面都不同,如下表所示:
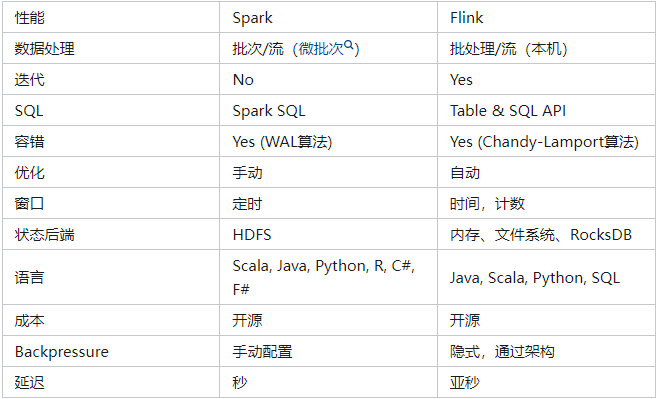
3.2、Flink VS Spark Streaming
-
數據模型
-
Flink基本數據模型是數據流,以及事件序列。
-
Spark采用RDD模型,Spark Streaming的DStream實際上也就是一組組小批 數據RDD的集合。
-
-
運行時架構
-
Flink是標準的流執行模式,一個事件在一個節點處理完后可以直接發往下一個節 點進行處理。
-
Spark是批計算,將DAG劃分為不同的Stage,一個完成后才可以計算下一個。
-
參考鏈接:
10分鐘入門Flink--了解Flink - 知乎
什么是Flink?Flink能用來做什么?[通俗易懂]-騰訊云開發者社區-騰訊云
![[滲透測試學習] CozyHosting - HackTheBox](http://pic.xiahunao.cn/[滲透測試學習] CozyHosting - HackTheBox)
)

)

![[c++]—vector類___基礎版(帶你了解vector熟練掌握運用)](http://pic.xiahunao.cn/[c++]—vector類___基礎版(帶你了解vector熟練掌握運用))



真題解析)

)

)
——如何進行時間序列分析)




:網絡層協議介紹)