集合容器概述
什么是集合
**集合框架:**用于存儲數據的容器。
集合框架是為表示和操作集合而規定的一種統一的標準的體系結構。
任何集合框架都包含三大塊內容:對外的接口、接口的實現和對集合運算的算法。
**接口:**表示集合的抽象數據類型。接口允許我們操作集合時不必關注具體實現,從而達到“多態”。在面向對象編程語言中,接口通常用來形成規范。
**實現:**集合接口的具體實現,是重用性很高的數據結構。
**算法:**在一個實現了某個集合框架中的接口的對象身上完成某種有用的計算的方法,例如查找、排序等。這些算法通常是多態的,因為相同的方法可以在同一個接口被多個類實現時有不同的表現。事實上,算法是可復用的函數。它減少了程序設計的辛勞。
集合框架通過提供有用的數據結構和算法使你能集中注意力于你的程序的重要部分上,而不是為了讓程序能正常運轉而將注意力于低層設計上。
通過這些在無關API之間的簡易的互用性,使你免除了為改編對象或轉換代碼以便聯合這些API而去寫大量的代碼。 它提高了程序速度和質量。
集合的特點
集合的特點主要有如下兩點:
- 對象封裝數據,對象多了也需要存儲。集合用于存儲對象。
- 對象的個數確定可以使用數組,對象的個數不確定的可以用集合。因 為集合是可變長度的。
集合和數組的區別
- 數組是固定長度的;集合可變長度的。
- 數組可以存儲基本數據類型,也可以存儲引用數據類型;集合只能存 儲引用數據類型。
- 數組存儲的元素必須是同一個數據類型;集合存儲的對象可以是不同 數據類型。
**數據結構:**就是容器中存儲數據的方式。
對于集合容器,有很多種。因為每一個容器的自身特點不同,其實原理在于每個容器的內部數據結構不同。
集合容器在不斷向上抽取過程中,出現了集合體系。在使用一個體系的原則:參閱頂層內容。建立底層對象。
使用集合框架的好處
- 容量自增長;
- 提供了高性能的數據結構和算法,使編碼更輕松,提高了程序速度和質
量; - 允許不同 API 之間的互操作,API之間可以來回傳遞集合;
- 可以方便地擴展或改寫集合,提高代碼復用性和可操作性。
- 通過使用JDK自帶的集合類,可以降低代碼維護和學習新API成本。
常用的集合類有哪些?
Map接口和Collection接口是所有集合框架的父接口:
- Collection接口的子接口包括:Set接口和List接口
- Map接口的實現類主要有:HashMap、TreeMap、Hashtable、ConcurrentHashMap以及Properties等
- Set接口的實現類主要有:HashSet、TreeSet、LinkedHashSet等
- List接口的實現類主要有:ArrayList、LinkedList、Stack以及Vector等
List,Set,Map三者的區別?List、Set、Map 是否繼承自 Collection 接口?List、Map、Set 三個接口存取元素時,各有什么特點?
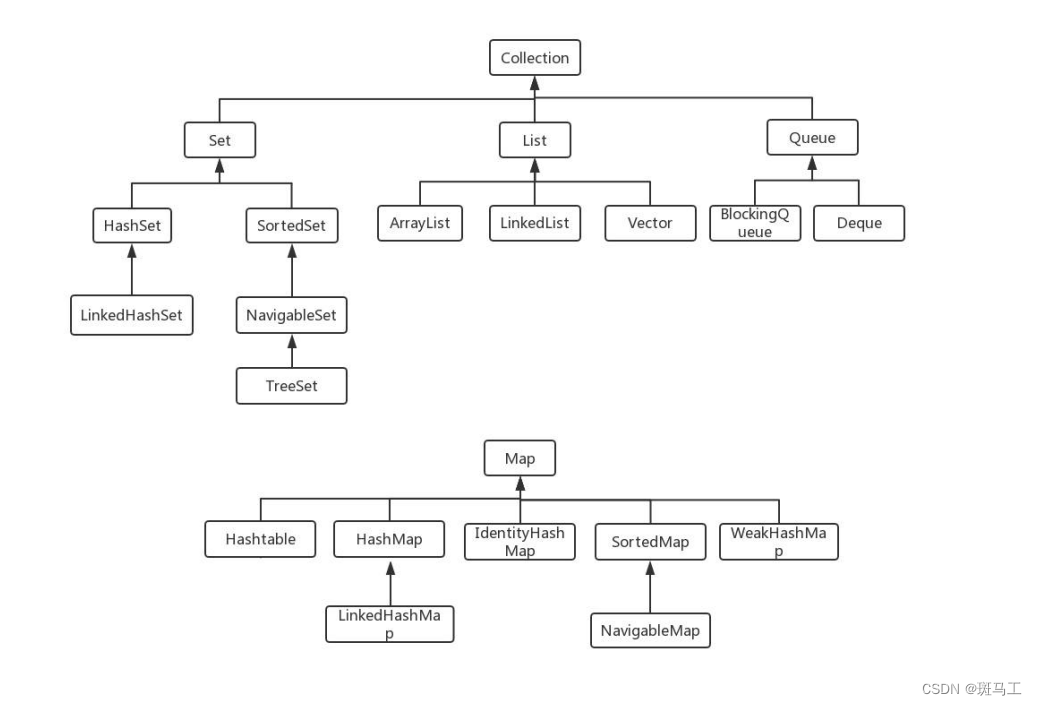
Java 容器分為 Collection 和 Map 兩大類,Collection集合的子接口有Set、List、Queue三種子接口。我們比較常用的是Set、List,Map接口不是collection的子接口。
Collection集合主要有List和Set兩大接口
-
List:一個有序(元素存入集合的順序和取出的順序一致)容器,元素可以重 復,可以插入多個null元素,元素都有索引。常用的實現類有ArrayList、LinkedList 和 Vector。
-
Set:一個無序(存入和取出順序有可能不一致)容器,不可以存儲重復元素,只允許存入一個null元素,必須保證元素唯一性。Set 接口常用實現類是 HashSet、LinkedHashSet 以及 TreeSet。
Map是一個鍵值對集合,存儲鍵、值和之間的映射。 Key無序,唯一;value 不要求有序,允許重復。Map沒有繼承于Collection接口,從Map集合中檢索元素時,只要給出鍵對象,就會返回對應的值對象。
Map 的常用實現類:HashMap、TreeMap、HashTable、LinkedHashMap、ConcurrentHashMap
集合框架底層數據結構
Collection
- List
- Arraylist: Object數組
- Vector: Object數組
- LinkedList: 雙向循環鏈表
- Set
HashSet(無序,唯一):基于 HashMap 實現的,底層采用 HashMap 來保
存元素
- LinkedHashSet: LinkedHashSet 繼承與 HashSet,并且其內部是通過LinkedHashMap 來實現的。有點類似于我們之前說的LinkedHashMap 其內部是基于 Hashmap 實現一樣,不過還是有一點點區別的。
- TreeSet(有序,唯一): 紅黑樹(自平衡的排序二叉樹。)
Map - HashMap: JDK1.8之前HashMap由數組+鏈表組成的,數組是HashMap的主體,鏈表則是主要為了解決哈希沖突而存在的(“拉鏈法”解決沖突).JDK1.8以后在解決哈希沖突時有了較大的變化,當鏈表長度大于閾值(默認為8)時,將鏈表轉化為紅黑樹,以減少搜索時間
- LinkedHashMap:LinkedHashMap 繼承自 HashMap,所以它的底層仍然是基于拉鏈式散列結構即由數組和鏈表或紅黑樹組成。另外,LinkedHashMap 在上面結構的基礎上,增加了一條雙向鏈表,使得上面的結構可以保持鍵值對的插入順序。同時通過對鏈表進行相應的操作,實現了訪問順序相關邏輯。
- HashTable: 數組+鏈表組成的,數組是 HashMap 的主體,鏈表則是主要為了解決哈希沖突而存在的
- TreeMap: 紅黑樹(自平衡的排序二叉樹)
哪些集合類是線程安全的?
- vector:就比arraylist多了個同步化機制(線程安全),因為效率較低,現在已經不太建議使用。在web應用中,特別是前臺頁面,往往效率(頁面響應速度)是優先考慮的。
- statck:堆棧類,先進后出。
- hashtable:就比hashmap多了個線程安全。
- enumeration:枚舉,相當于迭代器。
Java集合的快速失敗機制 “fail-fast”?
是java集合的一種錯誤檢測機制,當多個線程對集合進行結構上的改變的操作時,有可能會產生 fail-fast 機制。
例如:假設存在兩個線程(線程1、線程2),線程1通過Iterator在遍歷集合A中的元素,在某個時候線程2修改了集合A的結構(是結構上面的修改,而不是簡單的修改集合元素的內容),那么這個時候程序就會拋出ConcurrentModificationException 異常,從而產生fail-fast機制。
原因:迭代器在遍歷時直接訪問集合中的內容,并且在遍歷過程中使用一個modCount 變量。集合在被遍歷期間如果內容發生變化,就會改變modCount的值。每當迭代器使用hashNext()/next()遍歷下一個元素之前,都會檢測modCount變量是否為expectedmodCount值,是的話就返回遍歷;否則拋出
異常,終止遍歷。
解決辦法:
- 在遍歷過程中,所有涉及到改變modCount值得地方全部加上
synchronized。 - 使用CopyOnWriteArrayList來替換ArrayLis
怎么確保一個集合不能被修改?
可以使用 Collections. unmodifiableCollection(Collection c) 方法來創建一個只讀集合,這樣改變集合的任何操作都會拋出 Java. lang.UnsupportedOperationException 異常。
示例代碼如下:
1 List<String> list = new ArrayList<>();
2 list. add("x");
3 Collection<String> clist = Collections. unmodifiableCollection(list);
4 clist. add("y"); // 運行時此行報錯
5 System. out. println(list. size());
Collection接口
List接口
迭代器 Iterator 是什么?
Iterator 接口提供遍歷任何 Collection 的接口。我們可以從一個 Collection 中使用迭代器方法來獲取迭代器實例。迭代器取代了 Java 集合框架中的Enumeration,迭代器允許調用者在迭代過程中移除元素。
Iterator 怎么使用?有什么特點?
Iterator 使用代碼如下:
1 List<String> list = new ArrayList<>();
2 Iterator<String> it = list. iterator();
3 while(it. hasNext()){
4 String obj = it. next();
5 System. out. println(obj);
6 }
Iterator 的特點是只能單向遍歷,但是更加安全,因為它可以確保,在當前遍歷的集合元素被更改的時候,就會拋出 ConcurrentModificationException 異常。
如何邊遍歷邊移除Collection 中的元素?
邊遍歷邊修改 Collection 的唯一正確方式是使用 Iterator.remove() 方法,如下:
1 Iterator<Integer> it = list.iterator();
2 while(it.hasNext()){
3 *// do something*
4 it.remove();
5 }
一種最常見的錯誤代碼如下:
1 for(Integer i : list){
2 list.remove(i)
3 }
運行以上錯誤代碼會報 ConcurrentModificationException 異常。這是因為當使用 foreach(for(Integer i : list)) 語句時,會自動生成一個iterator 來遍歷該list,但同時該 list 正在被 Iterator.remove() 修改。Java 一般不允許一個線程在遍歷 Collection 時另一個線程修改它。
Iterator 和 ListIterator 有什么區別?
- Iterator 可以遍歷 Set 和 List 集合,而 ListIterator 只能遍歷 List。
- Iterator 只能單向遍歷,而 ListIterator 可以雙向遍歷(向前/后遍歷)。
- ListIterator 實現 Iterator 接口,然后添加了一些額外的功能,比如添加一個元素、替換一個元素、獲取前面或后面元素的索引位置。
遍歷一個 List 有哪些不同的方式?每種方法的實現原理是什么?Java 中 List 遍歷的最佳實踐是什么?
遍歷方式有以下幾種:
- for 循環遍歷,基于計數器。在集合外部維護一個計數器,然后依次讀取每一個位置的元素,當讀取到最后一個元素后停止。
- 迭代器遍歷,Iterator。Iterator 是面向對象的一個設計模式,目的是屏蔽不同數據集合的特點,統一遍歷集合的接口。Java 在 Collections 中支持了 Iterator 模式。
- foreach 循環遍歷。foreach 內部也是采用了 Iterator 的方式實現,使用時不需要顯式聲明 Iterator 或計數器。優點是代碼簡潔,不易出錯;缺點是只能做簡單的遍歷,不能在遍歷過程中操作數據集合,例如刪除、替換。
最佳實踐:Java Collections 框架中提供了一個 RandomAccess 接口,用來標記 List 實現是否支持 Random Access。
- 如果一個數據集合實現了該接口,就意味著它支持 Random Access,按位置讀 取元素的平均時間復雜度為O(1),如ArrayList。
- 如果沒有實現該接口,表示不支持 Random Access,如LinkedList。
推薦的做法就是,支持 Random Access 的列表可用 for 循環遍歷,否則建議用 Iterator 或 foreach 遍歷。
說一下 ArrayList 的優缺點
ArrayList的優點如下:
- ArrayList 底層以數組實現,是一種隨機訪問模式。ArrayList 實現了 RandomAccess 接口,因此查找的時候非常快。
- ArrayList 在順序添加一個元素的時候非常方便。 ArrayList 的缺點如下:
- 刪除元素的時候,需要做一次元素復制操作。如果要復制的元素很多,那么就會 比較耗費性能。
- 插入元素的時候,也需要做一次元素復制操作,缺點同上。 ArrayList 比較適合順序添加、隨機訪問的場景。
如何實現數組和 List 之間的轉換?
- 數組轉 List:使用 Arrays. asList(array) 進行轉換。
- List 轉數組:使用 List 自帶的 toArray() 方法。
代碼示例:
1 // list to array
2 List<String> list = new ArrayList<String>();
3 list.add("123");
4 list.add("456");
5 list.toArray();
6
7 // array to list
8 String[] array = new String[]{"123","456"};
9 Arrays.asList(array);
ArrayList 和 LinkedList 的區別是什么?
- 數據結構實現:ArrayList 是動態數組的數據結構實現,而 LinkedList 是雙向鏈表的數據結構實現。
- 隨機訪問效率:ArrayList 比 LinkedList 在隨機訪問的時候效率要高,因為LinkedList 是線性的數據存儲方式,所以需要移動指針從前往后依次查找。
- 增加和刪除效率:在非首尾的增加和刪除操作,LinkedList 要比 ArrayList 效率要高,因為 ArrayList 增刪操作要影響數組內的其他數據的下標。
- 內存空間占用:LinkedList 比 ArrayList 更占內存,因為 LinkedList 的節點除了存儲數據,還存儲了兩個引用,一個指向前一個元素,一個指向后一個元素。
- 線程安全:ArrayList 和 LinkedList 都是不同步的,也就是不保證線程安全;
綜合來說,在需要頻繁讀取集合中的元素時,更推薦使用 ArrayList,而在插入和刪除操作較多時,更推薦使用 LinkedList。
補充:數據結構基礎之雙向鏈表
雙向鏈表也叫雙鏈表,是鏈表的一種,它的每個數據結點中都有兩個指針,分別指向直接后繼和直接前驅。所以,從雙向鏈表中的任意一個結點開始,都可以很方便地訪問它的前驅結點和后繼結點。
ArrayList 和 Vector 的區別是什么?
這兩個類都實現了 List 接口(List 接口繼承了 Collection 接口),他們都是有序集合
- 線程安全:Vector 使用了 Synchronized 來實現線程同步,是線程安全的,而ArrayList 是非線程安全的。
- 性能:ArrayList 在性能方面要優于 Vector。
- 擴容:ArrayList 和 Vector 都會根據實際的需要動態的調整容量,只不過在Vector 擴容每次會增加 1 倍,而 ArrayList 只會增加 50%。
Vector類的所有方法都是同步的。可以由兩個線程安全地訪問一個Vector對象、但是一個線程訪問Vector的話代碼要在同步操作上耗費大量的時間。
Arraylist不是同步的,所以在不需要保證線程安全時時建議使用Arraylist。
插入數據時,ArrayList、LinkedList、Vector誰速度較快?闡述 ArrayList、Vector、LinkedList 的存儲性能和特性?
ArrayList、LinkedList、Vector 底層的實現都是使用數組方式存儲數據。數組元素數大于實際存儲的數據以便增加和插入元素,它們都允許直接按序號索引元素,但是插入元素要涉及數組元素移動等內存操作,所以索引數據快而插入數據慢。
Vector 中的方法由于加了 synchronized 修飾,因此 Vector是線程安全容器,但性能上較ArrayList差。
LinkedList 使用雙向鏈表實現存儲,按序號索引數據需要進行前向或后向遍歷,但插入數據時只需要記錄當前項的前后項即可,所以 LinkedList插入速度較快。
多線程場景下如何使用ArrayList?
ArrayList 不是線程安全的,如果遇到多線程場景,可以通過 Collections 的synchronizedList 方法將其轉換成線程安全的容器后再使用。例如像下面這樣:
1 List<String> synchronizedList = Collections.synchronizedList(list);
2 synchronizedList.add("aaa");
3 synchronizedList.add("bbb");
4
5 for (int i = 0; i < synchronizedList.size(); i++) {
6 System.out.println(synchronizedList.get(i));
7 }
為什么 ArrayList 的elementData 加上 transient 修飾?
ArrayList 中的數組定義如下:
1 private transient Object[] elementData;
可以看到 ArrayList 實現了 Serializable 接口,這意味著 ArrayList 支持序列化。transient 的作用是說不希望 elementData 數組被序列化,重寫了writeObject 實現:
1 private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOE
xception{
2 *// Write out element count, and any hidden stuff*
3 int expectedModCount = modCount;
4 s.defaultWriteObject();
5 *// Write out array length*
6 s.writeInt(elementData.length);
7 *// Write out all elements in the proper order.*
8 for (int i=0; i<size; i++)
9 s.writeObject(elementData[i]);
10 if (modCount != expectedModCount) {
11 throw new ConcurrentModificationException();
12 }
每次序列化時,先調用 defaultWriteObject() 方法序列化 ArrayList 中的非transient 元素,然后遍歷 elementData,只序列化已存入的元素,這樣既加快了序列化的速度,又減小了序列化之后的文件大小。
List 和 Set 的區別
List , Set 都是繼承自Collection 接口
List 特點:一個有序(元素存入集合的順序和取出的順序一致)容器,元素可以重復,可以插入多個null元素,元素都有索引。常用的實現類有 ArrayList、LinkedList 和 Vector。
Set 特點:一個無序(存入和取出順序有可能不一致)容器,不可以存儲重復元素,只允許存入一個null元素,必須保證元素唯一性。Set 接口常用實現類是HashSet、LinkedHashSet 以及 TreeSet。
另外 List 支持for循環,也就是通過下標來遍歷,也可以用迭代器,但是set只能用迭代,因為他無序,無法用下標來取得想要的值。
Set和List對比
Set:檢索元素效率低下,刪除和插入效率高,插入和刪除不會引起元素位置改變。
List:和數組類似,List可以動態增長,查找元素效率高,插入刪除元素效率低,因為會引起其他元素位置改變

![[c++]—vector類___基礎版(帶你了解vector熟練掌握運用)](http://pic.xiahunao.cn/[c++]—vector類___基礎版(帶你了解vector熟練掌握運用))



真題解析)

)

)
——如何進行時間序列分析)




:網絡層協議介紹)



Docker存儲)