前言
本文將會向你介紹哈希概念,哈希方法,如何解決哈希沖突,以及閉散列與開散列的模擬實現
1. 哈希概念
順序結構以及平衡樹中,元素關鍵碼與其存儲位置之間沒有對應的關系,因此在查找一個元素時,必須要經過關鍵碼的多次比較。順序查找時間復雜度為O(N),平衡樹中為樹的高度,即 O( l o g 2 N log_2N log2?N),搜索的效率取決于搜索過程中元素的比較次數。
理想的搜索方法:可以不經過任何比較,一次直接從表中得到要搜索的元素。
如果構造一種存儲結構,通過某種函數(hashFunc)使元素的存儲位置與它的關鍵碼之間能夠建立一 一映射的關系,那么在查找時通過該函數可以很快找到該元素。 當向該結構中: 插入元素根據待插入元素的關鍵碼,以此函數計算出該元素的存儲位置并按此位置進行存放搜索元素
對元素的關鍵碼進行同樣的計算,把求得的函數值當做元素的存儲位置,在結構中按此位置取元素比較,若關鍵碼相等,則搜索成功
該方式即為哈希方法,哈希方法中使用的轉換函數稱為哈希函數,構造出來的結構稱為哈希表(Hash Table)(或者稱散列表
例如:數據集合{1,7,6,4,5,9};
哈希函數設置為:hash(key) = key % size; size為存儲元素底層空間總的大小。

2. 哈希方法
哈希方法:我們通常對關鍵碼key進行轉換來確定存儲的位置,比如由字符串abc轉換成一個整數作為存儲的位置,這個轉換的方法稱為哈希方法,哈希方法中運用的函數叫做哈希函數
(1)直接定址法
ps:哈希方法是一個廣義的概念,而哈希函數是哈希方法的一種具體實現。
1、直接定址法 值和位置關系唯一關系,每個值都有一個唯一位置,但是值很分散,直接定址會導致空間開很大,導致空間浪費
(此方法運用于關鍵字范圍集中,量不大的情況,關鍵字和存儲位置是一對一的關系,不存在哈希沖突)
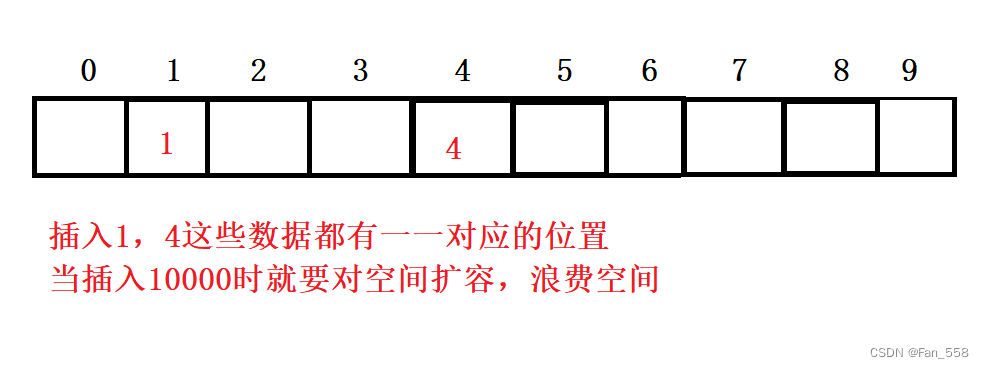
引入哈希沖突
哈希沖突概念:不同關鍵字通過相同的哈希函數計算出相同的哈希存儲位置(不同的值映射到相同的位置上去),這種現象被稱為哈希沖突或哈希碰撞,哈希沖突的發生與哈希函數的設計有關
(2)除留余數法
主要應用于關鍵字可以很分散,量可以很大,關鍵字和存儲位置是多對一的關系的情況,但是存在哈希沖突
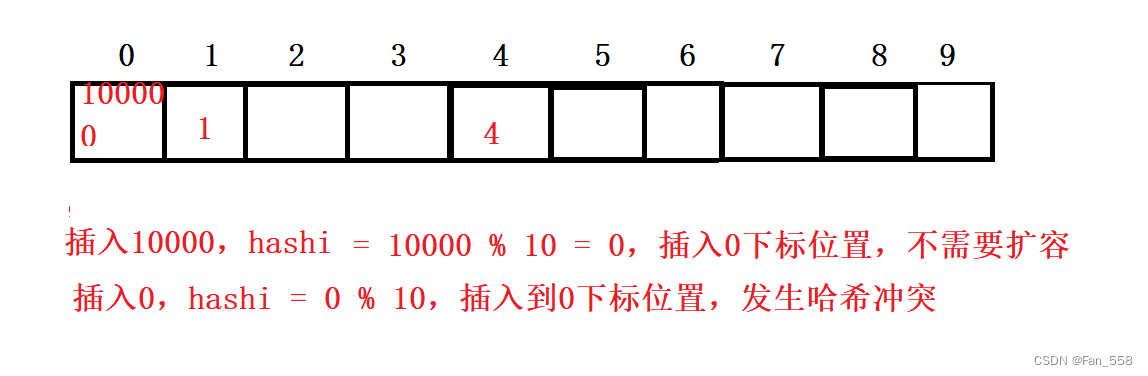
3. 解決哈希沖突
(1)閉散列
概念: 閉散列又稱開放定址法,指當前位置被占用(哈希沖突),開放空間里按照某種規則,找一個沒有被占用的位置存儲
1、線性探測
從發生沖突的位置開始,依次向后探測,直到尋找到下一個空位置為止 Hashi = hashi + i(i>=0)
2、二次探測
探測公式發生變化 hashi + i^2(i>=0)
(2)開散列
開散列法又叫鏈地址法(開鏈法),首先對關鍵碼集合用散列函數計算散列地址,具有相同地
址的關鍵碼歸于同一子集合,每一個子集合稱為一個桶,各個桶中的元素通過一個單鏈表鏈接起來,各鏈表的頭結點存儲在哈希表中。
如圖可觀察到,val值為44的節點和節點val值為4的節點發生哈希沖突
開散列中每個桶中放大都是發生哈希沖突的元素
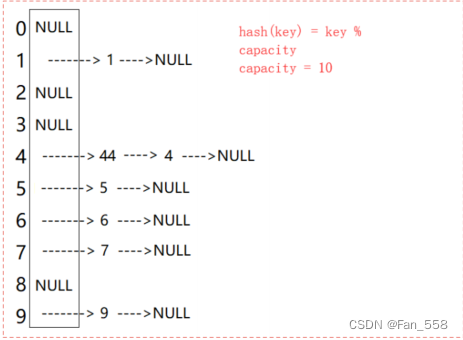
引入負載因子
負載因子:存儲個數/空間的大小(注意這里的空間的大小是size而不是capacity)
由于在哈希表中,operator[]操作會根據已有的元素數量(即size())進行檢查。因此,在計算負載因子時,要使用已有元素的個數除以哈希表的大小(即size())
size()函數返回的是當前哈希表中實際存儲的元素數量,而capacity()函數返回的是哈希表的容量(即內部存儲空間的大小)
負載因子:存儲關鍵字個數/空間大小 負載因子太大,沖突可能會劇增,沖突增加,效率降低 負載因子太小,沖突降低,但是空間利用率就低了
5. 哈希表擴容
擴容的核心是先開辟新空間,然后遍歷舊空間的數據,按照hashi = hashi % Newsize重新建立映射,然后將舊空間的數據拷貝到新空間去,最后交換新舊哈希表,本質上我們還是要對舊哈希表進行擴容,因此最后要swap交換兩表
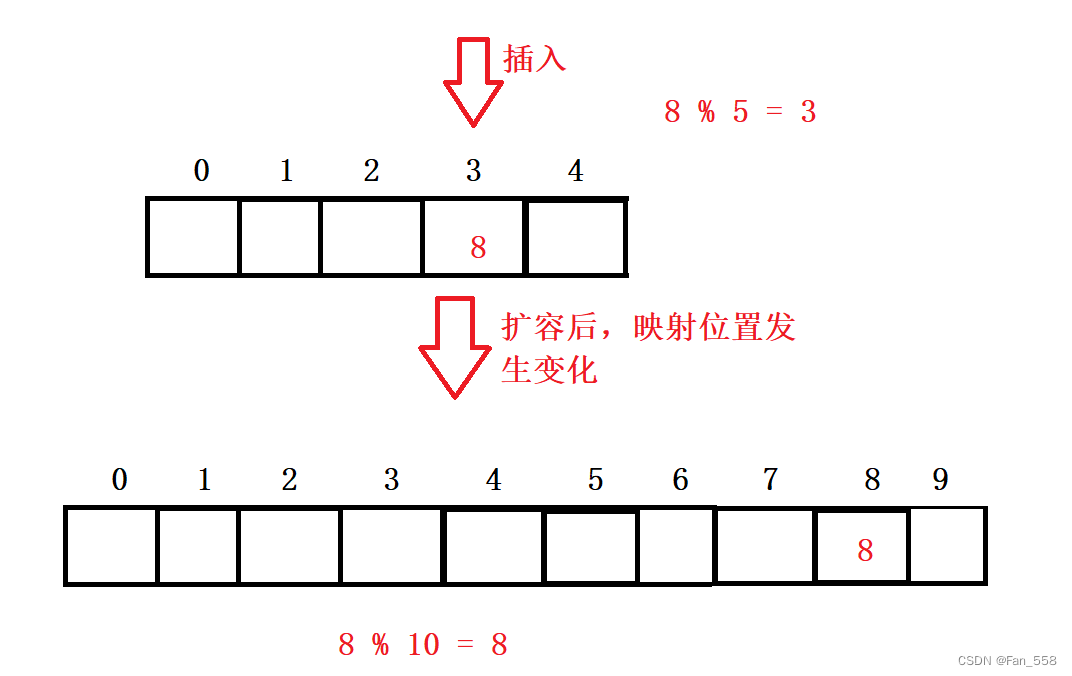
6. 哈希表插入
三種狀態EMPTY、EXIST、DELETE
EMPTY,表示該位置為空。
EXIST,表示該位置被占用了。
DELETE,表示該位置被刪除了。
刪除狀態存在的含義
或許你會有疑問:刪除為什么不能直接設為空狀態,而是將被刪除的狀態設置為DELETE

7. 閉散列模擬實現
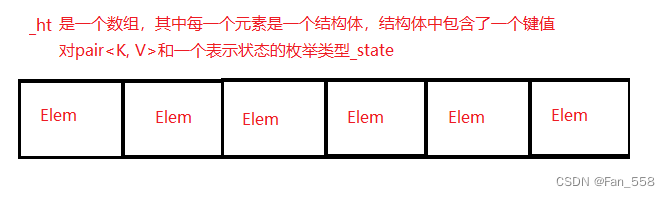
數據結構
struct Elem
{pair<K, V> _val;State _state = EMPTY;
};
vector<Elem<K, V>> _ht;
閉散列插入
閉散列的插入步驟是:判斷是否存在,判斷是否需要擴容(結合負載因子),遍歷舊空間拷貝數據
關于閉散列的模擬實現,核心步驟在上文都有講,這里就不再多作贅述,具體可看下面的代碼與注釋
namespace Close_Hash
{template<class T>struct HashFunc{size_t operator()(const T& key){return (size_t)key;}};//因為字符串做鍵值非常常見,庫里面也特化了一份//BKDR算法,這里不會展開來講template<>struct HashFunc<string>{size_t operator()(const string& key){size_t hashi = 0;for (auto ch : key){hashi = hashi * 31 + ch;}return hashi;}};enum State { EMPTY,EXIST,DELETE};template <class K, class V>struct Elem{pair<K, V> _val;State _state = EMPTY;};template<class K, class V, class Hash = HashFunc<K>>class HashTable{public:HashTable(size_t capacity = 3): _ht(capacity),_size(0), _totalSize(0){for (size_t i = 0; i < capacity; ++i)_ht[i]._state = EMPTY;}// 插入bool Insert(const pair<K, V>& val){Hash hf;_size = _ht.size();//已有if (Find(val.first)){return false;}else{//擴容,負載因子==0.6if ((double)_totalSize / _size >= 0.6){//開辟新空間size_t newsize = _size * 2;HashTable<K, V, Hash> NewHt;NewHt._ht.resize(newsize);//遍歷舊空間for (int i = 0; i < _size; i++){if (_ht[i]._state == EXIST){NewHt.Insert(_ht[i]._val);}}NewHt._ht.swap(_ht);}size_t hashi = hf(val.first) % _size;//不為空,向后查找while (_ht[hashi]._state == EXIST){hashi++;//如果超出數組長度hashi %= _size;}//為空,插入_ht[hashi]._val.first = val.first;_ht[hashi]._val.second = val.second;_ht[hashi]._state = EXIST;++_totalSize;return true;}}// 查找Elem<K, V>* Find(const K& key){Hash hf;//線性探測size_t hashi = hf(key) % _ht.size();while (_ht[hashi]._state != EMPTY){ if (_ht[hashi]._state == EXIST && _ht[hashi]._val.first == key){return &_ht[hashi];}hashi++;//超出數組長度hashi %= _ht.size();}//沒有找到areturn nullptr;}// 刪除bool Erase(const K& key){Elem<K, V>* ret = Find(key);//不為空就說明找到if (ret){ret->_state = DELETE;--_totalSize;return true;}else return false;}private:size_t HashFunc(const K& key){return key % _ht.capacity();}void CheckCapacity();private:vector<Elem<K, V>> _ht;size_t _size;size_t _totalSize; // 哈希表中的所有元素:有效和已刪除, 擴容時候要用到};
}
測試
void Print(){for (int i = 0; i < _ht.size(); i++){if (_ht[i]._state == EXIST){//printf("[%d]->%d\n", i, _tables[i]._kv.first);cout << "[" << i << "]->" << _ht[i]._val.first << ":" << _ht[i]._val.second << endl;}else if (_ht[i]._state == EMPTY){printf("[%d]->\n", i);}else{printf("[%d]->D\n", i);}}void TestHT1()
{Close_Hash::HashTable<int, int> ht;int a[] = { 4,14,24,34,5,7,1 };for (auto e : a){ht.Insert(make_pair(e, e));}ht.Print();ht.Insert(make_pair(3, 3));ht.Insert(make_pair(3, 3));ht.Insert(make_pair(-3, -3));ht.Print();cout << endl;ht.Erase(3);;ht.Print();if (ht.Find(3)){cout << "3存在" << endl;}else{cout << "3不存在" << endl;}ht.Insert(make_pair(23, 3));ht.Insert(make_pair(3, 3));if (ht.Find(3)){cout << "3存在" << endl;}else{cout << "3不存在" << endl;}ht.Print();
}8. 開散列模擬實現
數據結構
struct HashNode{HashNode* _next;pair<K, V> _val;HashNode(const pair<K, V>& val):_next(nullptr),_val(val){}};typedef HashNode<K, V> Node;vector<Node*> _ht;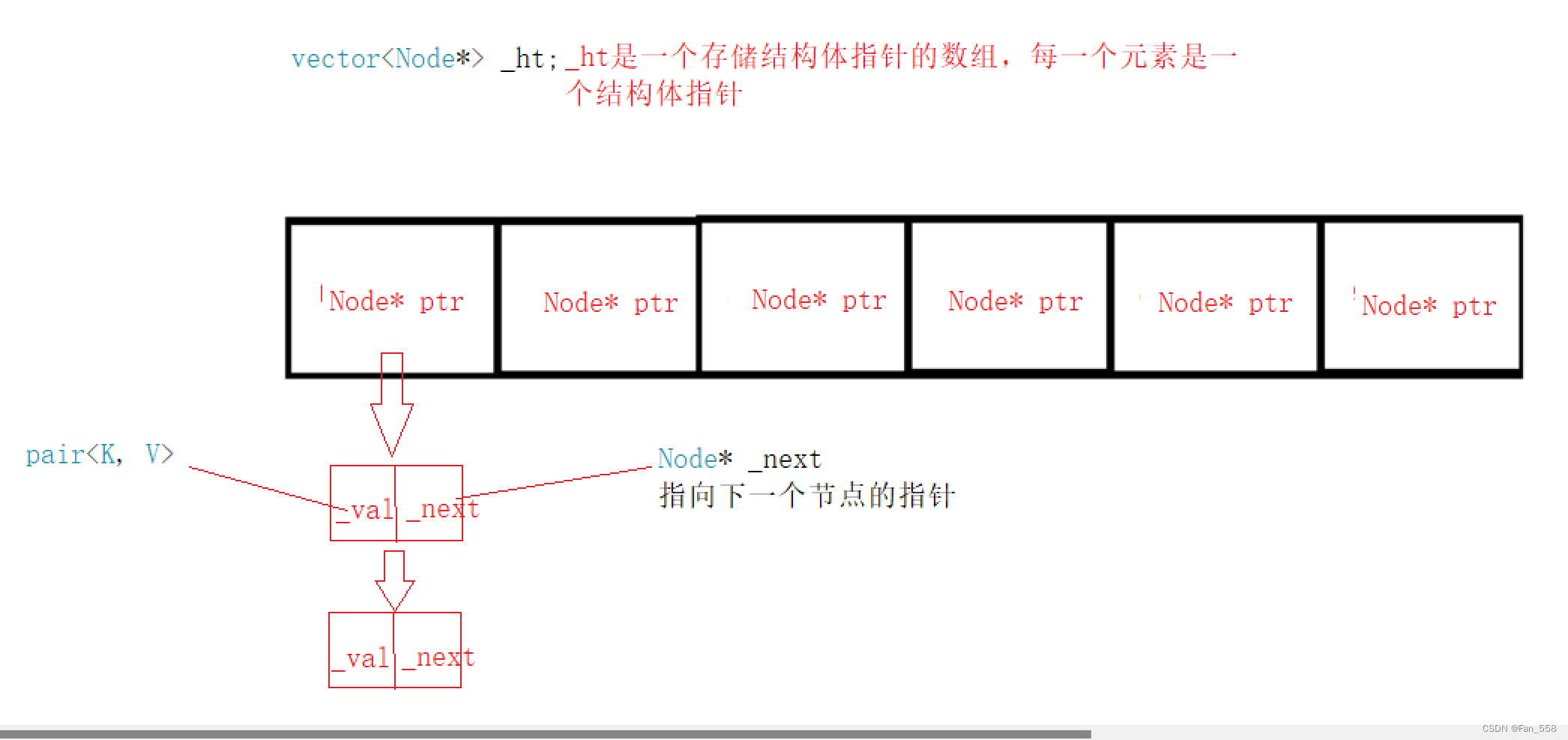
開散列插入
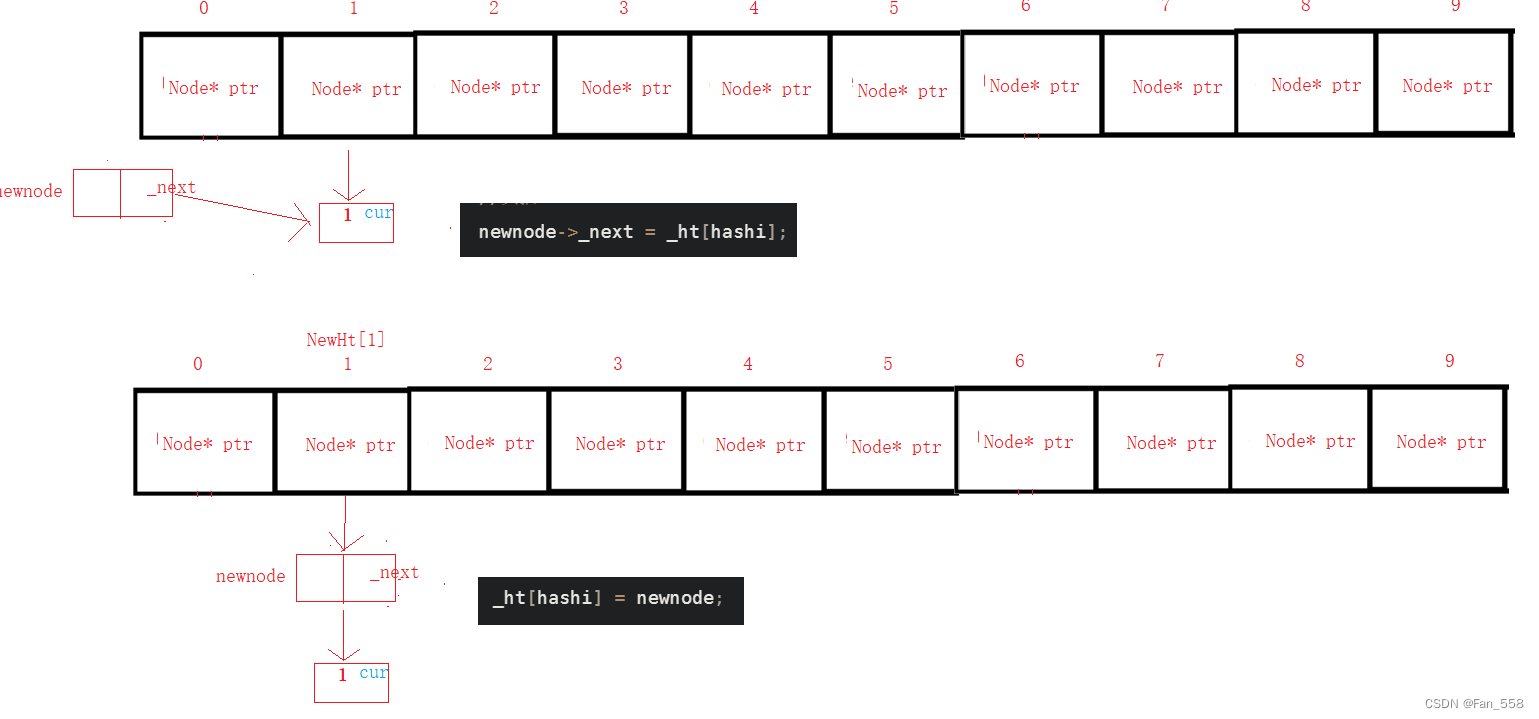
插入的主要邏輯是:先查找是否存在,判斷是否需要擴容(依據平衡因子),開辟新空間然后遍歷舊空間,將舊空間的數據拷貝到新空間上(需要根據新的映射關系,待會會細講),最后插入節點
bool Insert(const pair<K, V>& val)
{Hash hf;//已有if (Find(val.first)){return false;}//擴容,負載因子==1if (_totalSize == _ht.size()){//開辟新空間size_t newsize = _ht.size() * 2;vector<Node*> NewHt;NewHt.resize(newsize);//遍歷舊空間for (int i = 0; i < _ht.size(); i++){Node* cur = _ht[i];while (cur){//保存下一個結構體指針Node* next = cur->_next;size_t hashi = hf(cur->_val.first) % NewHt.size();//將新空間上hashi位置處的哈希桶鏈接到需要處理的當前節點cur->_next = NewHt[hashi];NewHt[hashi] = cur;//處理舊空間上哈希桶的下一個節點cur = next;}//防止出現懸空指針的問題_ht[i] = nullptr;} _ht.swap(NewHt);}//插入節點size_t hashi = hf(val.first) % _ht.size();Node* newnode = new Node(val);//頭插newnode->_next = _ht[hashi];_ht[hashi] = newnode;++_totalSize;return true;
}
以下是遍歷舊空間,拷貝數據的圖解
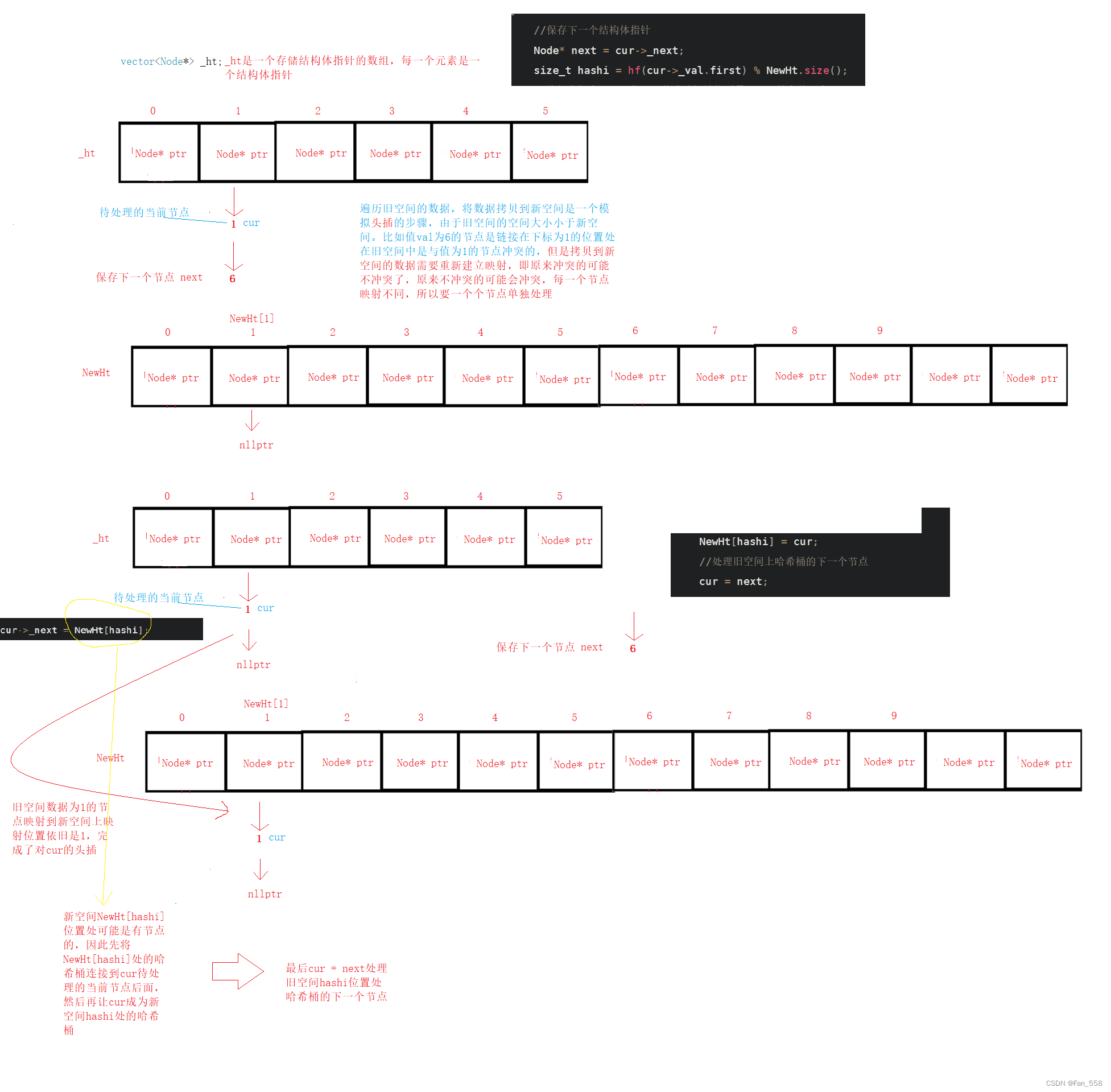
插入過程圖解
全部代碼
namespace Open_Hash
{template<class T>struct HashFunc{size_t operator()(const T& key){if (key >= 0){return (size_t)key;}else{return abs(key);}}};//字符串哈希算法這里不展開講,采用的是BKDR算法template<>struct HashFunc<string>{size_t operator()(const string& key){size_t hashi = 0;for (auto ch : key){hashi = hashi * 31 + ch;}return hashi;}};template <class K, class V>struct HashNode{HashNode* _next;pair<K, V> _val;HashNode(const pair<K, V>& val):_next(nullptr),_val(val){}};template<class K, class V, class Hash = HashFunc<K>>class HashTable{public: HashTable(){_ht.resize(10);}~HashTable(){for (int i = 0; i < _ht.size(); i++){Node* cur = _ht[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}//將當前哈希桶置空_ht[i] = nullptr;}}typedef HashNode<K, V> Node;// 插入bool Insert(const pair<K, V>& val){Hash hf;//已有if (Find(val.first)){return false;}//擴容,負載因子==1if (_totalSize == _ht.size()){//開辟新空間size_t newsize = _ht.size() * 2;vector<Node*> NewHt;NewHt.resize(newsize);//遍歷舊空間for (int i = 0; i < _ht.size(); i++){Node* cur = _ht[i];while (cur){//保存下一個結構體指針Node* next = cur->_next;size_t hashi = hf(cur->_val.first) % NewHt.size();//將新空間上hashi位置處的哈希桶鏈接到需要處理的當前節點cur->_next = NewHt[hashi];NewHt[hashi] = cur;//處理舊空間上哈希桶的下一個節點cur = next;}//防止出現懸空指針的問題_ht[i] = nullptr;}_ht.swap(NewHt);}//插入節點size_t hashi = hf(val.first) % _ht.size();Node* newnode = new Node(val);//頭插newnode->_next = _ht[hashi];_ht[hashi] = newnode;++_totalSize;return true;}//查找Node* Find(const K& key){Hash hf;//線性探測size_t hashi = hf(key) % _ht.size();Node* cur = _ht[hashi];//遍歷對應hashi位置處的哈希桶while (cur){if (cur->_val.first == key){return cur;}cur = cur->_next;}//沒有找到return nullptr;}// 刪除bool Erase(const K& key){Hash hf;Node* ret = Find(key);size_t hashi = hf(key) % _ht.size();//不為空就說明找到if (ret){Node* cur = _ht[hashi];Node* prev = nullptr;//遍歷當前哈希桶while (cur){if (cur->_val.first == key){//判斷是頭刪還是中間位置處的刪除if (prev == nullptr){_ht[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;return true;}prev = cur;cur = cur->_next;}}//未找到return false;}private:vector<Node*> _ht;Node* _next = nullptr;size_t _totalSize = 0; // 哈希表中的所有元素:有效和已刪除, 擴容時候要用到};
}
測試
//打印void Print1(){for (int i = 0; i < _ht.size(); i++){Node* cur = _ht[i];cout << "[" << i << "]:";//哈希桶不為空while(cur){cout << "(" << cur->_val.first << "," << cur->_val.second << ")" << "->";cur = cur->_next;}cout << endl;}cout << endl;}void Print2(){for (int i = 0; i < _ht.size(); i++){Node* cur = _ht[i];//哈希桶不為空while (cur){cout << cur->_val.first << ":"<< cur->_val.second << " ";cur = cur->_next;}}cout << endl;}
//測試void TestHT1(){HashTable<int, int> ht;int a[] = { 4,14,24,34,5,7,1 };for (auto e : a){ht.Insert(make_pair(e, e));}ht.Insert(make_pair(3, 3));ht.Insert(make_pair(3, 3));ht.Insert(make_pair(-3, -3));ht.Print1();ht.Erase(3);ht.Print1();if (ht.Find(3)){cout << "3存在" << endl;}else{cout << "3不存在" << endl;}ht.Insert(make_pair(3, 3));ht.Insert(make_pair(23, 3));//ht.Insert(make_pair(-9, -9));ht.Insert(make_pair(-1, -1));ht.Print1();}void TestHT2(){string arr[] = { "香蕉", "甜瓜","蘋果", "西瓜", "蘋果", "西瓜", "蘋果", "蘋果", "西瓜", "蘋果", "香蕉", "蘋果", "香蕉" };//HashTable<string, int, HashFuncString> ht;HashTable<string, int> ht;for (auto& e : arr){//auto ret = ht.Find(e);HashNode<string, int>* ret = ht.Find(e);if (ret){ret->_val.second++;}else{ht.Insert(make_pair(e, 1));}}ht.Print2();ht.Insert(make_pair("apple", 1));ht.Insert(make_pair("sort", 1));ht.Insert(make_pair("abc", 1));ht.Insert(make_pair("acb", 1));ht.Insert(make_pair("aad", 1));ht.Print2();}void Some(){const size_t N = 100;vector<int> v;v.reserve(N);srand(time(0));for (size_t i = 0; i < N; ++i){//v.push_back(rand()); // N比較大時,重復值比較多v.push_back(rand()%100+i); // 重復值相對少//v.push_back(i); // 沒有重復,有序}HashTable<int, int> ht;for (auto e : v){ht.Insert(make_pair(e, e));}ht.Print1();}
小結
今日的分享就到這里啦,后續將會向你帶來位圖與布隆過濾器的知識,如果本文存在疏漏或錯誤的地方還請您能夠指出,另外如果你存在疑問,也可以評論留言哦!



















