文獻來源:Chen H, Chiang R H L, Storey V C. Business intelligence and analytics: From big data to big impact[J]. MIS quarterly, 2012: 1165-1188.
下載鏈接:https://pan.baidu.com/s/1JoHcTbwdc1TPGnwXsL4kIA?
提取碼:a8uy
????????在不同的組織中,與數據和分析相關的機會有助于產生對BI&A的極大興趣,BI&A通常被稱為分析關鍵業務數據的技術、技術、系統、實踐、方法和應用程序,以幫助企業更好地了解其業務和市場,并及時做出業務決策。
????????圖1顯示了本文的關鍵部分,包括BI&A的發展、應用程序和新興的分析研究機會。然后,我們報告了一項基于十多年來相關BI&A學術和行業出版物的重要BI&A出版物、研究人員和研究主題的文獻計量學研究。
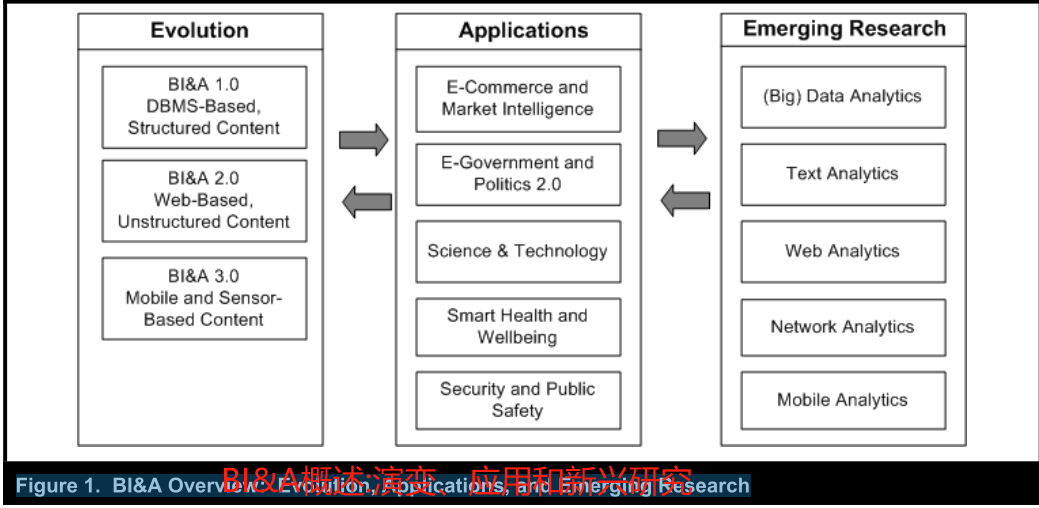
一、BI&A演進:關鍵特征和能力
表1?總結了與Gartner BI平臺核心功能和炒作周期相關的BI&A 1.0、2.0和3.0的關鍵特征
| 關鍵特性 | Gartner BI平臺核心功能 | Gartner炒作周期 | |
| BI&A 1.0 | 基于dbms的結構化內容 ?RDBMS和數據倉庫 ?ETL和OLAP ?儀表板和記分卡 ?數據挖掘和統計分析 | ?基于特別查詢和搜索的商業智能 ?報告、儀表板和記分卡 ?人機交互 ?可視化 ?預測建模和數據挖掘 | ?基于列的DBMS ?內存DBMS ?實時決策 ?數據挖掘工作臺 |
| BI&A 2.0 | 基于Web的非結構化內容 ?信息檢索和提取 ?意見挖掘 問題回答 ?網絡分析和網絡智能 ?社會媒體分析 ?社會網絡分析 ?時空分析 | ?信息語義服務 ?自然語言問答 ?內容和文本分析 | |
| BI&A 3.0 | 移動和基于傳感器的內容 ?位置感知分析 ?以人為中心的分析 ?上下文相關分析 ?移動可視化和HCI | ? Mobile BI |
ps:Gartner BI平臺是指由全球知名科技研究與咨詢公司 Gartner Inc. 評定或推薦的商業智能(Business Intelligence,BI)平臺。Gartner 是一家在科技行業享有盛譽的研究和咨詢公司,其分析報告和市場鑒定具有廣泛的影響力。
(一)BI&A 1.0
????????作為一種以數據為中心的方法,BI&A植根于長期存在的數據庫管理領域。它在很大程度上依賴于各種數據收集、提取和分析技術。目前在工業中采用的BI&A技術和應用程序可以被視為BI&A 1.0,其中的數據主要是結構化的,由公司通過各種遺留系統收集,并且通常存儲在商業關系數據庫管理系統(RDBMS)中。這些系統中普遍使用的分析技術于1990年代普及,主要基于1970年代發展的統計方法和1980年代發展的數據挖掘技術。
????????數據管理和倉儲被認為是BI&A 1.0的基礎。設計用于提取、轉換和加載(ETL)的數據集市和工具對于轉換和集成特定于企業的數據至關重要。數據庫查詢、在線分析處理(OLAP)和基于直觀但簡單的圖形的報告工具用于探索重要的數據特征。使用記分卡和儀表板的業務性能管理(BPM)有助于分析和可視化各種性能指標。除了這些完善的業務報告功能外,統計分析和數據挖掘技術還用于各種業務應用中的關聯分析、數據分割和聚類、分類和回歸分析、異常檢測和預測建模。這些數據處理和分析技術中的大多數已經被整合到主要IT供應商提供的領先商業BI平臺中,包括微軟、IBM、甲骨文和SAP 。
(二)BI&A 2.0
????????自21世紀初以來,互聯網和Web開始提供獨特的數據收集和分析研究與開發機會。基于http的Web 1.0系統,以Web搜索引擎(如Google和Yahoo)和電子商務業務(如Amazon和eBay)為特征,允許組織在線展示其業務并直接與客戶交互。除了將傳統的基于rdbms的產品信息和業務內容在線移植之外,通過cookie和服務器日志無縫收集的詳細且特定于ip的用戶搜索和交互日志已經成為了解客戶需求和識別新業務機會的新金礦。通過基于Web 2.0的社交和眾包系統收集的網絡智能、網絡分析和用戶生成的內容在2000年代迎來了一個新的和令人興奮的BI&A 2.0研究時代,主要集中在非結構化網絡內容的文本和網絡分析上。
????????大量的公司、行業、產品和客戶信息可以從網絡上收集,并通過各種文本和網絡挖掘技術進行組織和可視化。通過分析客戶點擊流數據日志,像Google analytics這樣的網絡分析工具可以提供用戶在線活動的蹤跡,并揭示用戶的瀏覽和購買模式。網站設計、產品布局優化、客戶交易分析、市場結構分析和產品推薦都可以通過網絡分析來完成。除了捕捉名人聊天、對日常事件的引用以及在這些媒體中表達的社會政治觀點之外,Web 2.0應用程序還可以有效地從不同類型的企業的不同客戶群體中收集大量及時的反饋和意見。
????????與已經集成到商業企業IT系統中的BI&A 1.0技術不同,未來的BI&A 2.0系統將需要在現有的基于dbms的BI&A 1.0系統中集成文本挖掘(例如,信息提取、主題識別、意見挖掘、問答)、web挖掘、社會網絡分析和時空分析等成熟且可擴展的技術。
(三)BI&A 3.0
????????移動和互聯網設備支持高度移動、位置感知、以人為中心和上下文相關的操作和交易的能力,將在整個2010年繼續為研究提供獨特的挑戰和機遇。移動界面、可視化和HCI(人機交互)設計也是很有前途的研究領域。盡管Web 3.0(基于移動和傳感器的)時代的到來似乎是確定無疑的,但用于收集、處理、分析和可視化此類大規模流動移動和傳感器數據的潛在移動分析、位置和上下文感知技術仍然未知。
二、BI&A應用:從大數據到大影響
????????下面介紹了其中一些有前途和高影響力的BI&A應用,并討論了數據和分析的特征、潛在影響,以及精選的示例或研究:(1)電子商務和市場情報,(2)電子政務和政治2.0,(3)科學技術,(4)智能健康和福祉,以及(5)安全和公共安全。
????????表2總結了有前途的BI&A應用程序、數據特征、分析技術和潛在影響。
| 電子商貿 及市場情報 | 電子政務 與政治2.0 | 科學技術 | 智能健康和醫療 | 公共安全 | |
|---|---|---|---|---|---|
| 應用 | ?推薦系統 ?社交媒體監測和分析 ?眾包系統 ?社交和虛擬游戲 | ?無處不在的政府服務 ?平等的機會和公共服務 ?公民參與 ?政治運動和電子投票 | ?科技創新 ?假設檢驗?知識發現 | ?人類和植物基因組學?醫療保健決策支持 ?患者群體分析 | ?犯罪分析 ?計算犯罪學 ?恐怖主義信息學 ?開源情報 ?網絡安全 |
| 數據安全 | ?客戶交易記錄搜索 ?用戶日志 ?客戶生成內容 | ?政府信息和服務 ?規章制度 ?市民反饋和意見 | ?科技儀器和系統生成的數據 ?傳感器和網絡內容 | ?基因組學和序列數據?電子健康記錄(EHR) ?健康和患者社交媒體 | ?犯罪記錄 ?犯罪地圖 ?犯罪網絡 ?新聞和網絡 目錄 ?恐怖主義事件 數據庫 ?病毒、網絡 攻擊,以及 僵尸網絡 |
| 特點:基于web的結構化,用戶生成的內容,豐富的網絡信息,非結構化的非正式客戶意見 | 特征:碎片化的信息源和遺留系統,豐富的文本內容,非結構化的非正式公民對話 | 特點:基于儀器的高通量數據采集,細粒度多模態和大規模記錄,科技特定數據格式 | 特點:不同但高度關聯的內容,針對個人的內容,HIPAA, IRB和道德問題 | 特點:個人身份信息,內容不完整,具有欺騙性,群體和網絡信息豐富,內容多語種 | |
| 分析 | ?關聯規則挖掘 ?數據庫分割和聚類 ?異常檢測 ?圖挖掘 ?社交網絡分析 ?文本和網絡分析 ?情感和影響分析 | ?信息集成 ?內容和文本分析 ?政府信息語義服務和本體 ?社交媒體監控和分析 ?社交網絡分析 ?情緒和影響分析 | ?基于特定領域的科學技術 ?數學和分析模型 | ?基因組學和序列分析和可視化 ?EHR關聯挖掘和聚類 ?健康社交媒體監測和分析 ?健康文本分析 ?健康本體 ?患者網絡分析 ?不良藥物副作用分析 ?隱私保護數據挖掘 | ?犯罪關聯規則挖掘和聚類 ?犯罪網絡分析 ?時空分析和可視化 ?多語言文本分析 ?情緒和影響分析 ?網絡攻擊分析和歸因 |
| 影響 | 長尾營銷,有針對性和個性化的推薦,增加銷售和客戶滿意度 | 改革政府,賦予公民權力,提高透明度,參與和平等 | 科技進步,科學影響 | 改善醫療保健質量,改善長期護理,增強患者能力 | 公共安全保障水平不斷提高 |
三、BI&A研究框架:分析學的基礎技術和新興研究
????????新興的分析研究機會可以分為五個關鍵技術領域——(大)數據分析、文本分析、web分析、網絡分析和移動分析——所有這些都可以為BI&A 1.0、2.0和3.0做出貢獻。這五個主題領域的分類是有意地突出每個區域的主要特征;然而,其中一些領域可能利用類似的底層技術。在每個分析領域中,我們都展示了成熟和發展良好的基礎技術,并建議了一些新興的研究領域(見表3):
| (大)數據分析 | 文本分析 | 網頁分析 | 網絡分析 | 移動分析 | |
|---|---|---|---|---|---|
| 基本的技術 | ?數據挖掘 ?聚類 ?回歸 ?分類 ?關聯分析 ?異常檢測 ?神經網絡 遺傳算法 ?多元統計分析 ?優化 ?啟發式搜索 | ?信息檢索 ?文檔表示 ?查詢處理 ?相關性反饋 ?用戶模型 ?搜索引擎 ?企業搜索系統 | ?信息檢索 ?計算語言學 ?搜索引擎 ?網絡爬網 ?網站排名 ?搜索日志分析 ?推薦系統 ?網絡服務 ?混搭 | ?文獻計量分析 ?引文網絡 ?合著網絡 ?社會網絡理論 ?網絡度量和拓撲 數學網絡模型 ?網絡可視化 | ?網絡服務 ?智能手機平臺 |
| 新興的研究 | ?統計機器學習 ?順序和時間挖掘 ?空間挖掘 ?挖掘高速數據流和傳感器數據 ?過程挖掘 ?隱私保護數據挖掘 網絡挖掘 ?web挖掘 ?基于列的DBMS ?內存DBMS ?并行DBMS、 ?云計算 | ?統計NLP ?信息提取 ?主題模型 ?問答系統 ?意見挖掘 ?情感/影響分析 ?網絡風格分析 ?多語言分析 ?文本可視化 ?多媒體IR ?移動IR ?Hadoop ?MapReduce | ?云服務 ?云計算 ?社交搜索和挖掘 ?聲譽系統 ?社交媒體分析 ?網絡可視化 ?基于網絡的拍賣 ?互聯網貨幣化 ?社交營銷 ?網絡隱私/安全 | ?鏈接挖掘 ?社區檢測 ?動態網絡建模 ?基于代理的建模 ?社會影響和信息擴散模型 ?E R G M s ?虛擬社區 ?犯罪/黑暗網絡 ?社會/政治分析 ?信任和聲譽 | ?移動網絡服務、 移動普及應用、 移動傳感應用、 移動社交創新、 移動社交網絡、 移動可視化/ 人機交互、 個性化和行為建模、 游戲化、 移動廣告和營銷 |
? ? ? ? (1)其中,數據分析是指主要基于數據挖掘和統計分析的BI&A技術。如前所述,這些技術大多依賴于關系DBMS、數據倉庫、ETL、OLAP和BPM等成熟的商業技術(Chaudhuri et al 2011)
????????自20世紀80年代末以來,人工智能、算法和數據庫社區的研究人員開發了各種數據挖掘算法。在IEEE 2006年數據挖掘國際會議(ICDM)上,根據專家提名、引用計數和社區調查確定了10個最具影響力的數據挖掘算法。按排名依次為C4.5、k-means、SVM(支持向量機)、Apriori、EM(期望最大化)、PageRank、AdaBoost、kNN (k-近鄰)、Na?ve貝葉斯和CART (Wu et al . 2007)。這些算法包括分類、聚類、回歸、關聯分析和網絡分析。這些流行的數據挖掘算法中的大多數已被納入商業和開源數據挖掘系統。
????????諸如用于分類/預測和聚類的神經網絡以及用于優化和機器學習的遺傳算法等進步都為數據挖掘在不同應用中的成功做出了貢獻。
????????商學院通常教授的另外兩種數據分析方法對財務分析也至關重要。多元統計分析以統計理論和模型為基礎,涵蓋了回歸、因素分析、聚類和判別分析等分析技術,這些分析技術已成功地應用于各種業務應用中。在管理科學界發展起來的優化技術和啟發式搜索也適用于選定的BI&A問題,如數據庫特征選擇和網絡爬行/蜘蛛爬行。這些技巧大多可以在商學院的課程中找到。?由于數據挖掘和統計分析社區共同取得的成功,數據分析仍然是一個活躍的研究領域。統計機器學習通常基于良好的數學模型和強大的算法,如貝葉斯網絡、隱馬爾可夫模型、支持向量機、強化學習和集成模型等技術,已應用于數據、文本和web分析應用程序。其他新的數據分析技術探索和利用獨特的數據特征,從順序/時間挖掘和空間挖掘,到高速數據流和傳感器數據的數據挖掘。
????????在各種電子商務、電子政務和醫療保健應用中,對隱私的關注日益增加,這使得保護隱私的數據挖掘成為一個新興的研究領域。其中許多方法是數據驅動的,依賴于各種匿名化技術,而其他方法是過程驅動的,定義如何訪問和使用數據。在過去的十年中,過程挖掘也作為一個新的研究領域出現,它側重于使用事件數據分析過程。由于各種行業(例如,醫療保健、供應鏈)中事件日志的可用性以及新的流程發現和一致性檢查技術,流程挖掘已經成為可能。此外,網絡數據和網絡內容有助于在網絡分析和網絡分析方面產生令人興奮的研究,如下所示。
????????除了活躍的數據分析學術研究之外,行業研究和發展也產生了很多興奮,特別是在半結構化內容的大數據分析方面。與可以通過RDBMS重復處理的結構化數據不同,半結構化數據可能需要在可擴展和分布式的MapReduce或Hadoop環境中進行臨時和一次性的提取、解析、處理、索引和分析。MapReduce被譽為大規模、大規模并行數據訪問的革命性新平臺。
????????受到MapReduce的部分啟發,Hadoop提供了一個基于java的軟件框架,用于分布式處理數據密集型轉換和分析。前三大商業數據庫供應商——oracle、IBM和Microsoft——都采用了Hadoop,其中一些采用了云基礎設施。
(2)組織收集的非結構化內容中有很大一部分是文本格式的,從電子郵件通信和公司文檔到網頁和社交媒體內容。文本分析的學術根源在于信息檢索和計算語言學。在信息檢索中,文檔表示和查詢處理是發展向量空間模型、布爾檢索模型和概率檢索模型的基礎,進而成為現代數字圖書館、搜索引擎和企業搜索系統的基礎(Salton 1989)。在計算語言學中,用于詞匯習得、詞義消歧、詞性標注(POST)和概率上下文無關語法的統計自然語言處理(NLP)技術對于表示文本也變得非常重要。除了文檔和查詢表示之外,用戶模型和相關反饋在增強搜索性能方面也很重要.
四、繪制BI&A知識景觀:學術和行業出版物的文獻計量學研究
????????為了更好地了解BI&A相關研究的現狀并確定未來的知識來源,我們進行了文獻計量學研究,分析了相關文獻、主要BI&A學者、學科和出版物以及重點研究課題。本研究遵循了收集、轉換和分析過程,這與其他應用程序中采用的典型的BI&A過程非常相似

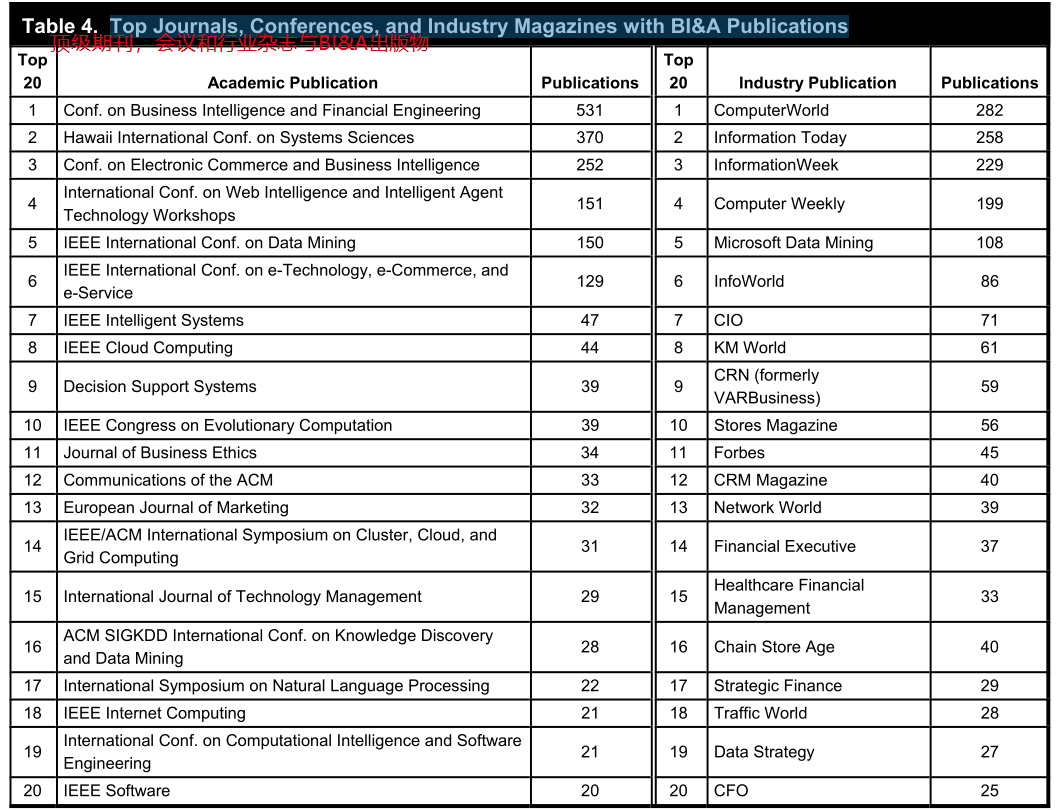
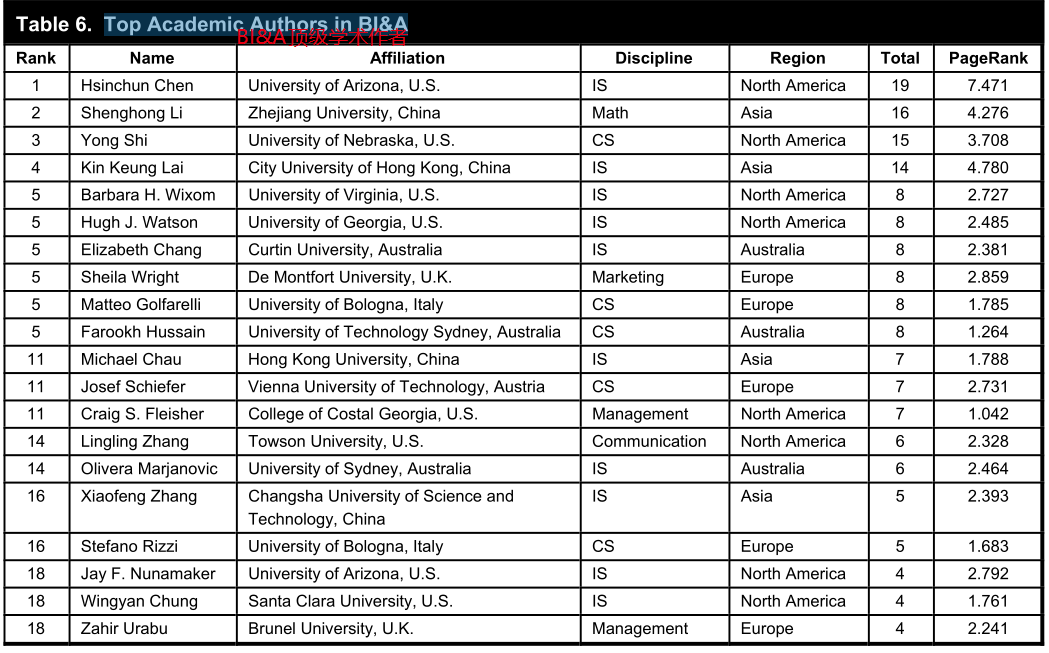
五、BI&A教育和項目發展
????????BI&A研究框架內的特刊論文摘要
| 作者和書名 | 演變 | 應用 | 數據 | 分析或研究介紹 | 影響 |
| Chau and Xu, “Business Intelligence in Blogs: ?Under- standing Consumer Inter- actions and Communities | 社交媒體和網絡分析的BI&A 2.0 | 消費者和社區的市場情報 | 從博客中提取的用戶生成內容 | ?文本和網絡分析 ?社區檢測 ?網絡可視化 | 提高了銷售額和客戶滿意度 |
| Park et al., “A Social Network-Based Inference Model for Validating Customer Profile Data | BI&A 1.0 & 2.0社會網絡分析和統計分析 | 預測客戶資料的市場情報 | 自報用戶資料和手機通話記錄 | ?網絡分析 ?異常檢測 ?預測分析 | 個性化推薦,提高客戶滿意度 |
| Lau et al., “Web 2.0 Environmental Scanning and Adaptive Decision Support for Business Mergers and? Acquisitions | 關于記分卡和網絡分析的BI&A 1.0和2.0 | 環境掃描市場情報 | 從互聯網和專有財務信息中提取的業務信息 | ?文本和網絡分析 ?情感和影響分析 ?關系挖掘 | 并購中的戰略決策 |
| Hu et al., “Network-Based Modeling and Analysis of Systemic Risk in Banking Systems” | 關于統計分析的BI&A 1.0 | 銀行系統的系統性風險分析與管理 | 美國銀行信息提取自FDIC和聯邦儲備銀行網絡 | ?網絡和數據分析 ?描述性和預測性建模?離散事件模擬 | 監測和減輕傳染性銀行倒閉 |
| Abbasi et al., “MetaFraud: ?A Meta-Learning Framework for Detecting Financial Fraud” | 關于數據挖掘和元學習的BI&A 1.0 | 欺詐檢測 | 財務比率,以及組織和行業層面的背景特征 | ?數據分析 ?分類與泛化 ?自適應學習 | 財務欺詐偵查 |
| Sahoo et al., “A Hidden Markov Model for Col- laborative Filtering | 關于統計分析的BI&A 1.0 | 不斷改變用戶偏好的推薦系統 | 博客閱讀數據、Netflix獎勵數據集和Last。調頻數據 | ?數據和網絡分析 ?統計動態模型 ?協同過濾 | 個性化推薦 |
六、總結與討論
????????通過BI&A 1.0計劃,來自所有部門的企業和組織開始從通過各種企業系統收集并由商業關系數據庫管理系統分析的結構化數據中獲得關鍵見解。在過去的幾年里,網絡智能、網絡分析、web 2.0以及挖掘非結構化用戶生成內容的能力引領了一個新的、令人興奮的BI&A 2.0研究時代,帶來了前所未有的關于消費者意見、客戶需求和識別新商業機會的智能。現在,在這個大數據時代,即使會計與審計2.0仍在成熟,我們發現自己正處于會計與審計3.0的邊緣,伴隨著所有新的和潛在的革命性技術帶來的不確定性。學術信息系統課程如何繼續滿足傳統學生的需求,同時也滿足需要新的分析技能的在職IT專業人員的需求?這是一個值得我們深思的問題。
????????通過強調電子商務、市場情報、電子政務、醫療保健和安全等幾個應用,以及繪制當前BI&A知識格局的重要方面,我們希望為未來的知識來源做出貢獻,并加強當前關于(相關)學術研究重要性的討論。



















)