📋 博主簡介
- 💖 作者簡介:大家好,我是wux_labs。😜
熱衷于各種主流技術,熱愛數據科學、機器學習、云計算、人工智能。
通過了TiDB數據庫專員(PCTA)、TiDB數據庫專家(PCTP)、TiDB數據庫認證SQL開發專家(PCSD)認證。
通過了微軟Azure開發人員、Azure數據工程師、Azure解決方案架構師專家認證。
對大數據技術棧Hadoop、Hive、Spark、Kafka等有深入研究,對Databricks的使用有豐富的經驗。- 📝 個人主頁:wux_labs,如果您對我還算滿意,請關注一下吧~🔥
- 📝 個人社區:數據科學社區,如果您是數據科學愛好者,一起來交流吧~🔥
- 🎉 請支持我:歡迎大家 點贊👍+收藏??+吐槽📝,您的支持是我持續創作的動力~🔥
《PySpark大數據分析實戰》-02.了解Hadoop
- 《PySpark大數據分析實戰》-02.了解Hadoop
- 前言
- 了解Hadoop
- 分布式文件系統HDFS
- 分布式計算框架MapReduce
- 資源調度管理框架YARN
- 結束語
《PySpark大數據分析實戰》-02.了解Hadoop
前言
大家好!今天為大家分享的是《PySpark大數據分析實戰》第1章第2節的內容:了解Hadoop。

了解Hadoop
2002年,Hadoop之父Doug Cutting和Mike Cafarella等人決定開創一個優化搜索引擎算法的平臺,重新打造一個網絡搜索引擎,于是一個可以運行的網頁爬取工具和搜索引擎系統Nutch就面世了。Nutch項目是基于Doug Cutting的文本搜索系統Apache Lucene的,Nutch本身也是Lucene的一部分。后來,開發者認為Nutch的靈活性不夠,不足以解決數十億網頁的搜索問題,剛好谷歌于2003年發表的關于GFS的論文以及GFS的架構可以解決他們對于網頁爬取和索引過程中產生的超大文件的需求。2004年他們開始實現開源版本的Nutch分布式文件系統(NDFS)。2005年,Nutch的開發人員基于谷歌關于MapReduce的論文在Nutch上實現了一個MapReduce系統,并且將Nutch的主要算法全部移植,使用NDFS和MapReduce來運行。2006年,開發人員將NDFS和MapReduce移出Nutch形成一個Lucene的子項目,并用Doug Cutting的小孩的毛絨象玩具的名字Hadoop進行命名,至此,Hadoop便誕生了,其核心便是Hadoop分布式文件系統HDFS和分布式計算框架MapReduce,集群資源調度管理框架是YARN。
分布式文件系統HDFS
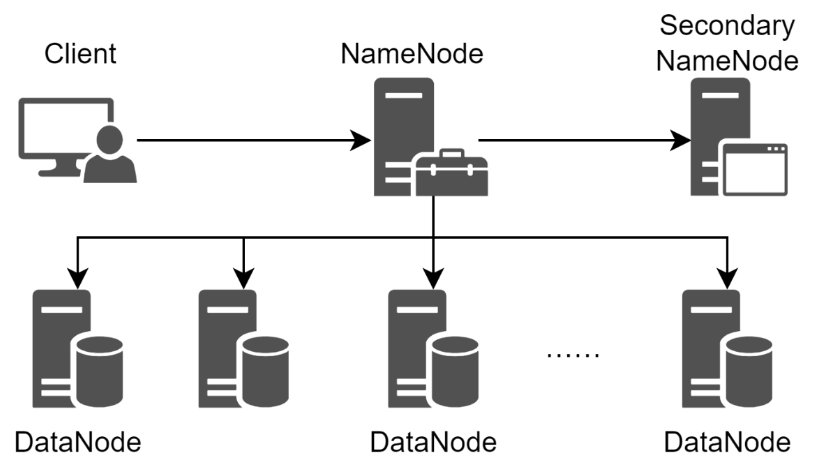
HDFS提供了在廉價服務器集群中進行大規模文件存儲的能力,并且具有很好的容錯能力,還能兼容廉價的硬件設備。HDFS采用了主從模型,一個HDFS集群包括一個NameNode和若干個DataNode,NameNode負責管理文件系統的命名空間和客戶端對文件的訪問,DataNode負責處理文件系統客戶端的讀寫請求,在NameNode的統一調度下進行數據塊(Block)的創建、刪除、復制等操作。HDFS的容錯能力體現在可以對數據塊保存至少3份以上的副本數據,并且同時分布在相同機架和不同機架的節點上,即便一個數據塊損壞,也可以從其他副本中恢復數據。HDFS的體系結構如圖所示。
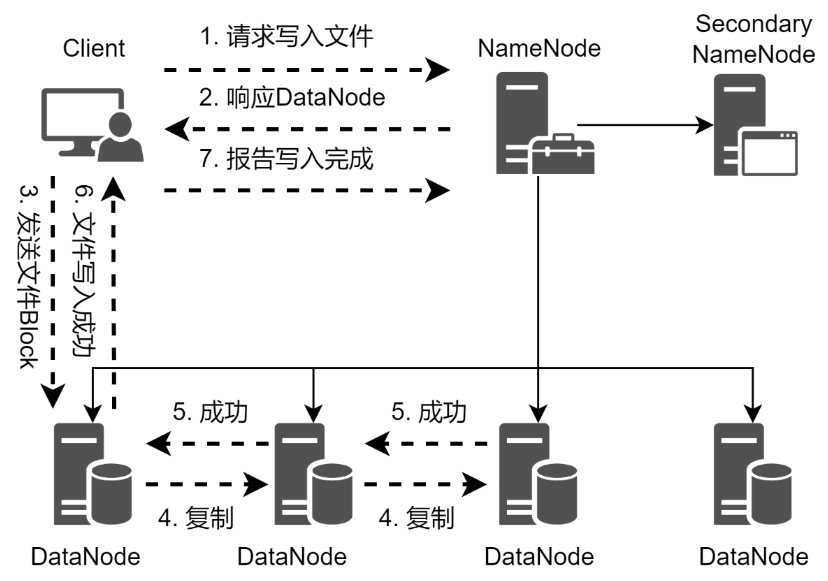
當客戶端需要向HDFS寫入文件的時候,首先需要跟NameNode進行通信,以確認可以寫文件并獲得接收文件的DataNode,然后客戶端按順序將文件按數據塊逐個傳遞給DataNode,由接收到數據塊的DataNode向其他DataNode復制指定副本數的數據塊。HDFS文件的寫入流程如圖所示。
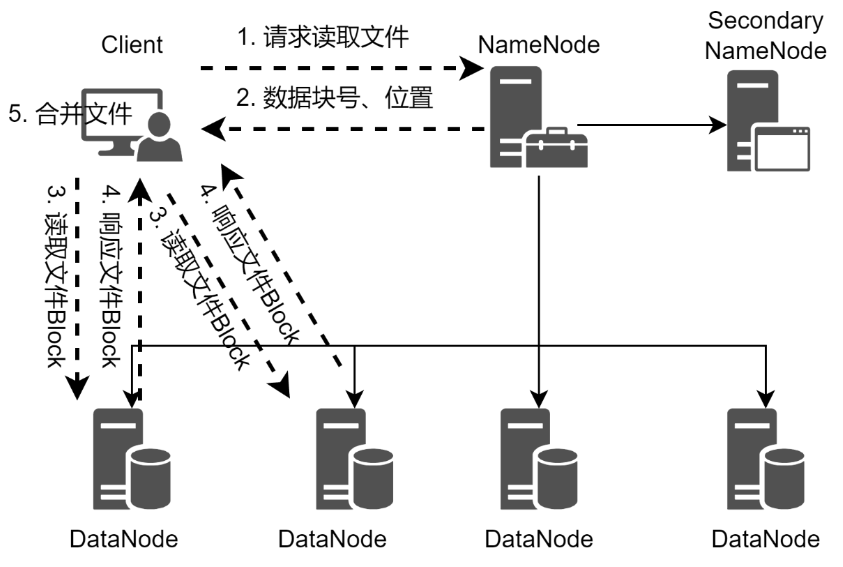
當客戶端需要從HDFS讀取文件的時候,客戶端需要將文件的路徑發送給NameNode,由NameNode返回文件的元數據信息給客戶端,客戶端根據元數據信息中的數據塊號、數據塊位置等找到相應的DataNode逐個獲取文件的數據塊并完成合并從而獲得整個文件。從HDFS讀取文件的流程如圖所示。
分布式計算框架MapReduce
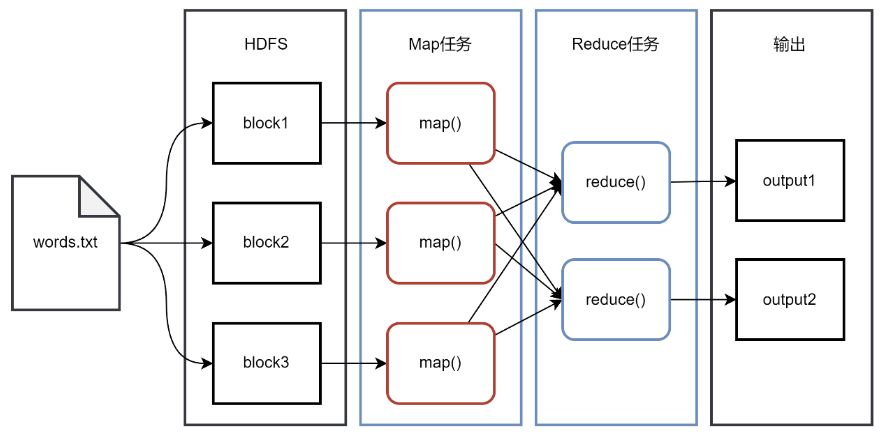
一個存儲在HDFS的大規模數據集,會被切分成許多獨立的小數據塊,并分布在HDFS的不同的DataNode上,這些小數據塊可以被MapReduce中的多個Map任務并行處理。MapReduce框架會為每個Map任務輸入一個數據子集,通常是一個數據塊,并且在數據塊所在的DataNode節點上啟動Map任務,Map任務生成的結果會繼續作為Reduce任務的輸入,最終由Reduce任務輸出最后的結果到HDFS。MapReduce的設計理念是移動計算而不是移動數據,也就是說,數據在哪個節點就將在哪個節點上執行計算任務,而不是將一個節點的數據復制到另一個計算節點上,因為移動數據需要大量的網絡傳輸開銷,在大規模數據的環境下,這種開銷太大,移動計算比移動數據要經濟實惠。
使用MapReduce框架編程,簡單實現一些接口就可以完成一個分布式程序,這個分布式程序就可以分布到大量廉價的PC機器運行。以經典的WordCount程序為例,統計一個文件中每個單詞出現的次數,準備一個文本文件words.txt。文件內容如下:
Hello Python
Hello Spark You
Hello Python Spark
You know PySpark
Map任務對讀取的文件進行單詞拆分,StringTokenizer按照空格、制表符、換行符等將文本拆分成一個一個的單詞,循環迭代對拆分的每個單詞賦予初始計數為1,并將結果以鍵值對的形式組織用于Map任務的輸出。Map任務的代碼如下:
public class WordMapper extendsMapper<Object, Text, Text, IntWritable>{private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, one);}}
}
經過對Map輸出的鍵值對按照鍵分組,相同鍵的數據在同一個分組。Reduce任務對分組后的數據進行迭代,取出Map任務中賦予的初始值1進行累加,最終得到單詞出現的次數。Reduce任務代碼如下:
public class WordReducer extendsReducer<Text,IntWritable,Text,IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}
}
在主任務中,需要將Map任務和Reduce任務串聯起來,并指定Map任務的輸入文件和Reduce任務的輸出,主任務代碼如下:
public class WordCount {public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf, "WordCount");job.setJarByClass(WordCount.class);job.setMapperClass(WordMapper.class);job.setReducerClass(WordReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path("words.txt"));FileOutputFormat.setOutputPath(job, new Path("count"));System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
將程序打包、提交運行,運行結束后在count目錄下生成最終的結果,結果如下:
Hello 3
Python 2
Spark 2
You 2
know 1
PySpark 1
MapReduce的工作流程如圖所示。
資源調度管理框架YARN
Hadoop的兩個組件HDFS和MapReduce是由批量處理驅動的,JobTracker必須處理任務調度和資源管理,這容易導致資源利用率低或者作業失敗等問題。由于數據處理是分批完成的,因此獲得結果的等待時間通常會比較長。為了滿足更快速、更準確的處理數據的需求,YARN誕生了。YARN代表的是Yet Another Resource Negotiator,最初被命名為MapReduce2,是Hadoop的主要組件之一,用于分配和管理資源。YARN整體上屬于Master/Slave模型,采用3個主要組件來實現功能,第1個是ResourceManager,是整個集群資源的管理者,負責對整個集群資源進行管理;第2個是NodeManager,集群中的每個節點都運行著1個NodeManager,負責管理當前節點的資源,并向ResourceManager報告節點的資源信息、運行狀態、健康信息等;第3個是ApplicationMaster,是用戶應用生命周期的管理者,負責向ResourceManager申請資源并和NodeManager交互來執行和監控具體的Task。YARN不僅做資源管理,還提供作業調度,用戶的應用在YARN中的執行過程如圖所示。

 :在YARN集群中,NodeManager定期向ResourceManager匯報節點的資源信息、任務運行狀態、健康信息等。
:在YARN集群中,NodeManager定期向ResourceManager匯報節點的資源信息、任務運行狀態、健康信息等。
1:客戶端程序向ResourceManager提交應用并請求一個ApplicationMaster實例。
2:ResourceManager根據集群的資源情況,找到一個可用的節點,在節點上啟動一個Container,在Container中啟動ApplicationMaster。
3:ApplicationMaster啟動之后,反向向ResourceManager進行注冊,注冊之后客戶端通過ResourceManager就可以獲得ApplicationMaster的信息。
4:ResourceManager根據客戶端提交的應用的情況,為ApplicationMaster分配Container。
5:Container分配成功并啟動后,可以與ApplicationMaster交互,ApplicationMaster可以檢查它們的狀態,并分配Task,Container運行Task并把運行進度、狀態等信息匯報給ApplicationMaster。
6:在應用程序運行期間,客戶端可以和ApplicationMaster交流獲得應用的運行狀態、進度信息等。
7:一旦應用程序執行完成,ApplicationMaster向ResourceManager取消注冊然后關閉,ResourceManager會通知NodeManager進行Container資源的回收、日志清理等。
結束語
好了,感謝大家的關注,今天就分享到這里了,更多詳細內容,請閱讀原書或持續關注專欄。












)




)(位操作符))

