Micro-expression spotting based on optical flow features
基于光流特征的微表情檢測
Abstract
本文提出了一種高精度和可解釋性的自動微表情檢測方法。首先,我們設計了基于鼻尖位置的圖像對齊方法,以消除由頭部晃動引起的全局位移。其次,根據面部編碼系統(FACS)中的動作單元定義,我們選擇了十四個感興趣區域(ROI)來捕捉微妙的面部運動。引入了密集光流來估計ROI的局部運動和時域變化。第三,我們設計了一種峰值檢測方法,用于在時域變化曲線上精確定位運動間隔。最后,我們提出了一個重疊指數來衡量不同器官變化的一致性。在CAS(ME)2和SAMM Long Video數據庫上的評估顯示,我們的微表情檢測方法在相對較低的計算成本下可能實現更高的準確性,并可應用于類似的面部圖像處理應用。
1. Introduction
微表情(ME)檢測是微表情研究的關鍵任務,旨在從長視頻序列中定位微表情間隔[6]。微表情檢測的效果將影響對微表情的后續分析。然而,由于微表情的強度極小,如圖1所示,頭部晃動、眨眼、面部差異等許多因素會降低檢測結果的準確性。因此,微表情檢測的準確性一直較低。因此,準確捕捉微弱的微表情運動并消除不相關的干擾被認為是一項具有挑戰性的任務。本文提出了一種具有高準確性和可解釋性的自動微表情(ME)檢測方法。
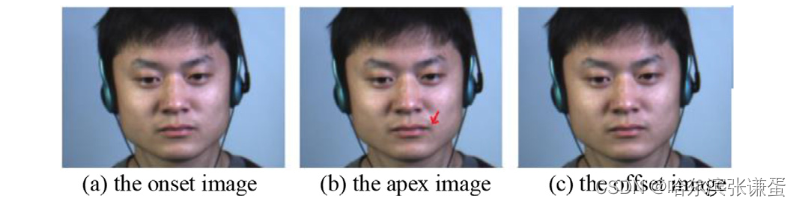
圖1. 微表情起始、頂點和結束圖像的示意圖[6]。頂點幀包含最顯著的微表情運動信息,紅色箭頭指向局部運動發生的區域。
LBP提取紋理特征,Li等人通過劃分區域去提取區域的紋理特征---紋理特征對于檢測面部運動性能較差。
LTP通過提取紋理變形的局部信息來進行微表情檢測,但是LTP可能會受到不同面試者面部紋理信息差異的影響。
光流方法基于時序上的水平和垂直像素的變化尋找兩個圖像之間的變化關系。利用光流特征主方向的最大差異來檢測微表情。由于搖頭會降低光流特征的準確性,因此許多工作都致力于人臉對齊技術。一種常用的人臉對齊方法是在每個視頻圖像中根據面部標志對面部進行對齊和切割 [15,18],這在宏觀表情分析中效果良好。然而,考慮到微表情的微小運動,面部標志的位置算法不夠精確。這種方法無法滿足微表情檢測的要求。張等人 [19] 提出使用鼻部區域的均值光流特征估計全局面部位移,并從局部光流特征中去除全局運動以獲取面部運動。
張等人 [20] 首次使用深度學習方法檢測微表情。他使用卷積神經網絡從微表情圖像中提取特征。
于等人 [22] 提出了基于位置抑制的微表情檢測網絡(LSSNet)來檢測微表情。由于很難收集微表情運動并標記它們,現有ME數據庫的規模較小,無法滿足使用深度學習模型的要求,從而導致過擬合等問題。基于深度學習的ME檢測方法通常缺乏明確的依據,結果也不具有可解釋性。在異常行為檢測和情感監測的應用場景中,沒有明確的證據支持,無法接受微表情檢測和識別的結果。
本文:包括基于鼻尖位置的圖像對齊方法、基于面部動作單元(AU)選擇的十四個感興趣區域(ROI)、使用光流進行特征提取、建立時域變化曲線以及從不同ROI中融合局部運動。
預處理:選用給予鼻尖位置的圖像對齊方法來消除頭部搖晃對光流特征的干擾。
ROI的選取:根據FACS的劃分,選取十四個ROI建立時間域的變化曲線,并使用光流的方法對十四個RIO進行特征提取。
檢測:設計了一種峰值檢測方法,用于在時域變化曲線上精確定位運動間隔。
檢測指標:我們提出了一個重疊指數來衡量不同器官變化的一致性。
總體而言,本文的idea由于光流方法在捕捉面部微妙的動態信息方面表現良好并且具有良好的可解釋性,我們使用光流方法來估計面部運動。為了消除頭部搖晃對光流特征的干擾,我們提出了一種基于鼻尖位置的圖像對齊方法,有效提高了光流特征的準確性。在此基礎上,我們根據面部編碼系統(FACS)[23]中的動作單元(AU)的定義,在面部選擇了十四個感興趣區域(ROI)。我們實施光流方法來提取十四個ROI的特征并建立時間域變化曲線。使用峰值檢測方法可以在時間域變化曲線上精確定位局部運動間隔。最后,有選擇地融合不同ROI的局部運動,以準確計算微表情間隔。
- 我們提出了針對鼻尖位置的圖像對齊方法的偏差度量指標,以確保微表情光流特征的準確性,并提供了一個精確的算法。
- 我們設計并實現了一個宏觀和微觀表情識別方法,并給出了整體方法的框架。
- 在實驗部分,我們添加了面部動作單元(AU)分類的實驗。分類結果進一步證明了偏差度量指標對面部對齊的有效性,光流特征能夠捕捉微小的微表情運動。
- 我們進行了消融實驗來驗證鼻尖位置圖像對齊方法的有效性,并討論了改進識別結果的原因。
- 原始數據庫中添加了包含微表情和宏觀表情長視頻的CAS(ME)2數據集。我們在CAS(ME)2數據庫上進行了微表情和宏觀表情的識別實驗。在CAS(ME)2和SAMM Long Video數據庫上的評估顯示,我們的微表情識別方法在相對較低的計算成本下可能實現更高的準確性,并可應用于類似的面部圖像處理應用。
我們將本文的其余部分組織如下:在第2節中,我們詳細介紹Farneback光流方法[25]、提出的基于鼻尖位置的圖像對齊方法、局部運動檢測和融合方法。在第3節中,我們介紹了這個實驗并討論了我們方法的結果。最后,結論部分總結了本文并討論了未來工作的可能性。
2. Macro- and micro-expression spotting method
在實際工作中,我們設計并實現了一個宏觀和微觀表情的識別方法。輸入是一個長視頻,輸出是所有識別到的宏觀和微觀表情的時間段。如圖2所示,我們使用一個固定的滑動窗口覆蓋N幀圖像來劃分視頻,然后在滑動窗口中識別宏觀表情和微觀表情。
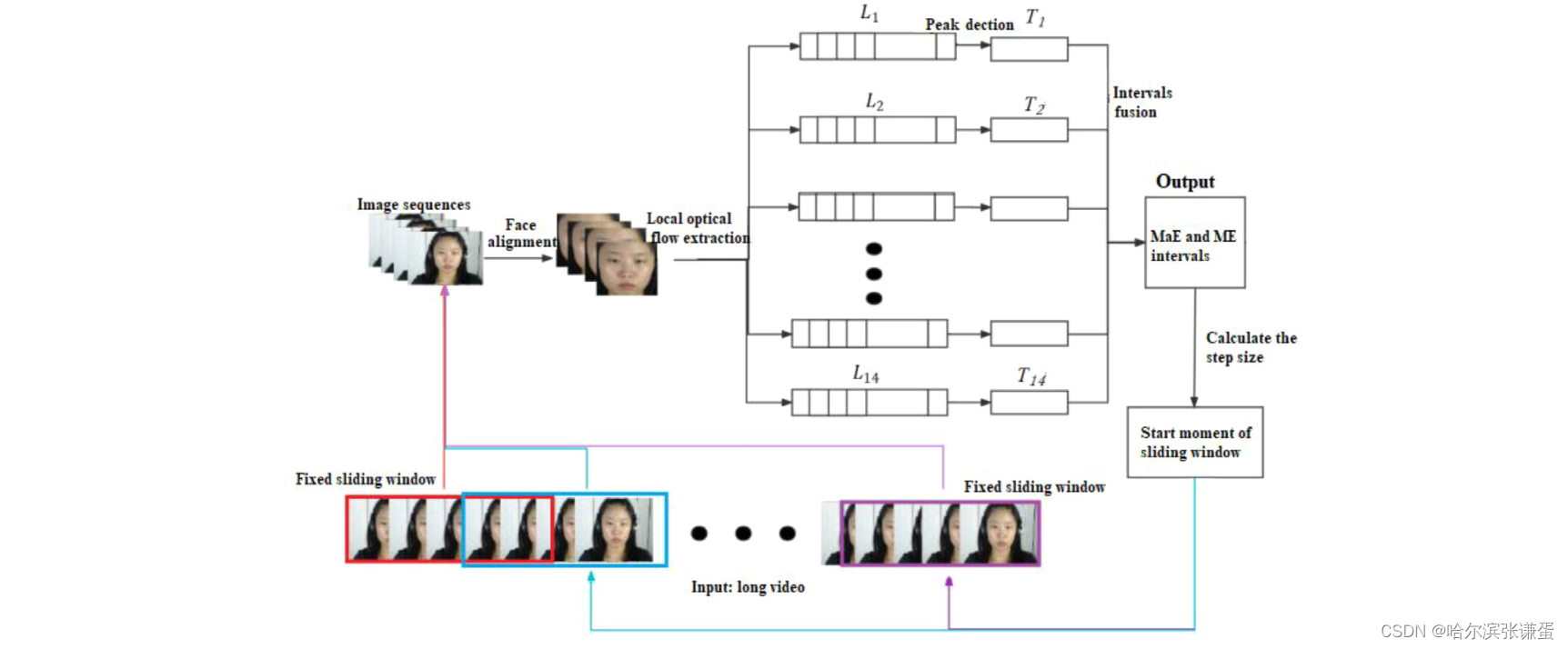
圖二。宏表情和微表情定位方法的框架。
fixed sliding Window:固定滑動窗口;Image sequence:圖像序列;local optical flow extraction:局部光流提取(十四個ROI生成是個局部光流序列);Peak detection:峰值檢測;intervals fusion:間隔融合;MaE and ME intervals:MaE 和 ME 間隔;calculate the step size:計算步長;start moment of sliding windows:滑動窗口的起始時刻
在微表情檢測中,"intervals fusion" 指的是將檢測到的局部運動間隔(intervals)合并,以得到完整的微表情區間。微表情通常包含多個局部面部運動,因此首先檢測這些局部運動,然后將它們融合在一起,形成一個完整的微表情區間。
在上下文中,"intervals" 可能指代一系列在時間軸上的連續圖像幀,這些圖像幀顯示了面部運動的變化。"Fusion" 則表示將這些局部運動間隔整合為一個更全面的表達,以更準確地表示整個微表情的發生和結束。
這個過程有助于綜合考慮多個局部運動,提高微表情檢測的準確性,確保捕捉到完整和一致的微表情。
在滑動窗口中識別圖像序列表情的過程包括四個步驟:面部對齊、局部光流特征提取、局部運動檢測和局部運動間隔融合。然后,得到表情間隔集合T={[start1, end1], [start2, end2], ..., [startlast, endlast]}。滑動窗口的步長(S)根據識別到的表情的位置進行自適應調整。
如果在當前窗口中沒有檢測到微表情。
S = N/ 2 (1)
如果檢測到微表情,
S = endlast + 1 (2)
在接下來的章節中,我們將介紹我們提出的微表情檢測方法中使用的幾種技術。
2.1. Farneback optical flow method ---Farneback光流法
本文使用Farneback光流方法[25]來估計面部運動。在使用光流方法時,必須滿足兩個條件:首先,視頻圖像的亮度保持恒定。其次,物體在時間域內的位置變化不會發生劇烈變化。
如公式(3)和(4)所示,在圖像I1和I2上進行多項式估計:
I1(p)=pTA1p+ bT1p + c1(3)
I2(p) = pTA2p+bT2p+c2(4)
A1和A2是對稱矩陣,bT1和bT2是向量,c1和c2是標量。p = (x, y)表示像素點,x是水平坐標,y是垂直坐標。I1(p)是圖像I1在點p處的灰度值。假設圖像I1和I2之間存在全局位移dis,可以得到第二張圖像的多項式估計:
I2(p) = I1(p?dis) = (p?dis)TA1(p?dis) + bT1(p?1) +c1 (5)
= pTA1p+(b1?2A1dis)Tp +disTA1dis?bT1dis+c1
根據公式(4)和(5),以下三個方程成立:
A2 = A1(6)
b2 = b1 ? 2A1dis(7)
c2 = disT A1dis ? bT1dis + c1(8)
如果A1是非奇異矩陣,全局位移dis可以計算為:
dis =??A?11(b2?b1) (9)
光流方法可以捕捉物體的微小運動信息,并對紋理差異具有魯棒性。
假設 I = {I1, I2, ..., IN} 是一個微表情視頻的圖像序列,并且在序列 {I2, I3, ..., IN} 中的每一幀圖像與第一幀圖像I1之間實施 Farneback 光流方法,以計算密集光流圖序列{F1, F2, ..., FN?1}.。
Fi= Franeback(I1, Ii+1 ), Fi∈Rw×h×2? (10)
Fi表示 Ii+1與第一幀圖像I1之間的密集光流圖,它包含兩個表示:水平和垂直方向光流的矩陣。假設d是圖像I0中點 p = (x, y)的運動。光流方法估計了在點 p = (x, y)處的運動為 u = Fi[x, y]。光流向量u 被認為是微表情相關運動 d和搖頭運動v 的疊加。
u= d + v?? (11)
由于微表情的強度較小,搖頭運動 v 可能會覆蓋微表情運動 d,導致微表情特征的信噪比較低,給微表情分析帶來了困難。因此,面部對齊方法對提高光流特征的準確性至關重要。
2.2. Nose tip location-based image alignment method--基于鼻尖位置的圖像對準方法
面部對齊是確保微表情特征準確性的基本保證。基于鼻尖位置的圖像對齊方法通過在圖像序列中對齊面部來提高微表情識別結果。在這里,我們定義了偏差測量指數 b,它衡量了基于特定器官的圖像序列中面部位置的變化。
我們定義了面部區域內的兩個窗口,即面部裁剪框 Bface? 和鼻尖裁剪框 Bnose?,如圖3所示。面部裁剪框覆蓋了被試的臉部并去除了背景信息。根據當前的微表情研究,鼻尖在表情時不會移動。因此,我們根據鼻尖區域的平均光流來估計全局面部運動。當被試的臉在圖像序列中移動時,我們根據每個圖像的偏差測量指數 b 連續調整這兩個窗口。面部和裁剪框的相對位置在圖像序列中保持穩定。最后,根據鼻尖裁剪框 Bnose? 對每個圖像進行裁剪。

圖3顯示了面部裁剪框和鼻尖區域框的示意圖。綠色框是面部裁剪框,黑色框是鼻尖框。鼻尖區域的放大圖在左下角,其中綠色點表示鼻尖點。
偏移度量指數 b:該指數 b=(m,n)T 用于測量面部和裁剪框的相對位置變化,其中 m表示水平移動, n 表示垂直移動。偏移度量指數b 的計算如公式 (12) 所示。
 在公式 (12) 中, Fnose? 是第一幀圖像和當前圖像之間鼻尖區域的密集光流, Fnose?=Franeback?(NOSE1?,NOSEc?),其中 Fnose?∈Rwn?×hn?×2, wn? 和hn? 是鼻尖區域 NOSEc? 的寬度和高度。我們通過基于 Bnose? 對當前圖像進行切割來獲得 NOSEc?。該過程如算法 1 所示。
在公式 (12) 中, Fnose? 是第一幀圖像和當前圖像之間鼻尖區域的密集光流, Fnose?=Franeback?(NOSE1?,NOSEc?),其中 Fnose?∈Rwn?×hn?×2, wn? 和hn? 是鼻尖區域 NOSEc? 的寬度和高度。我們通過基于 Bnose? 對當前圖像進行切割來獲得 NOSEc?。該過程如算法 1 所示。
2.3.2. Peak detection and fusion method based on time-domain change curves
當發生微表情時,我們可以觀察到 AU 生成區域的時間域變化曲線上出現了峰值。因此,我們通過檢測時間域變化曲線的峰值來估計局部運動區間。我們對每個 ROI 的時間域變化曲線執行峰值檢測方法,得到一組峰值區間Ti = {[start1, end1]i, ......, [startn, endn]i}, i ∈ {1, ..., 14}, i是 ROI 的索引,如算法 2 所示。首先,我們使用閾值 δ對時間域變化曲線 L j應用低通濾波器,以去除高頻噪聲。隨后,我們通過計算滑動窗口中心位置處的曲線值與中心左右區域最小值之間的差異來檢測波峰。r是滑動窗口的半徑。如果差異足夠大,我們認為這個中心點屬于一個波峰,并將該點放入峰值集合中。然后移動滑動窗口以計算新的中心點。最后,將峰值中的相鄰點連接起來形成時間區間[start, end],將其添加到Tj中。

由于微表情包含一個或多個 AU,當發生局部面部運動時,就認為出現了微表情。當多個局部運動在相似的時間出現時,我們需要分析這些局部運動是否屬于同一個微表情。此外,將屬于同一表情的局部運動組合在一起,以獲取完整的微表情區間。

使用重疊指數 μ 判斷兩個不同 ROI 的局部運動([startl, endl] 和 [startr, endr])是否屬于同一微表情。
如果 μ 大于閾值 γ,則認為這兩個局部運動屬于同一微表情,并將它們合并為一個新的區間 [startnew, endnew]。
![]()
計算每兩個局部運動的重疊指數 μ,以獲取微表情的區間 TME = {[start1, end1], ......, [startV, endV]}。
3. Experiments and results
3.1. Databases and metric
我們使用兩個主要的基準數據集進行宏表情(MaE)和微表情(ME)的定位:CAS(ME)2 [11] 和 SAMM 長視頻 [18]。CAS(ME)2 包含 300 個宏表情(MaEs)和 57 個微表情(MEs)。CAS(ME)2-cropped 是 CAS(ME)2 的裁剪版本。SAMM 長視頻數據集包含 343 個宏表情和 159 個微表情。CAS(ME)2-cropped、CAS(ME)2 和 SAMM-LV 的詳細信息總結在表2中。

計算定位到的區間 Qspotted 與真實區間 QgroundTruth 之間的 IoU,以區分 Qspotted 是否是正確的檢測,如公式(18)所示。

如果 IoU 大于閾值 k(k 設為 0.5),則 Qspotted 是真正的陽性結果(TP)。相反,它是假正結果(FP)。使用 F1 分數來評估提出的方法。我們通過公式(19)-(21)計算宏表情、微表情和整體的 F1 分數。

AME 和 AMaE 是真正陽性結果的數量;MME 和 MMaE 是所有 ME 和 MaE 區間的數量;NME 和 NMaE 是被發現的 ME 和 MaE 區間的數量。
3.2. Experiment configuration
在實驗中,滑動窗口的長度 N 被設置為包含在七秒視頻間隔內的圖像數。我們使用相同的方法來檢測宏表情和微表情。持續時間小于 0.5 秒的表情被視為微表情。我們使用 Dlib 工具 [26] 來定位臉部的 68 個關鍵點。原始圖像在面部切割后被規范化為 240 × 240。ROI 的大小被設置為 10×10 像素。在峰值檢測方法中,搜索半徑 m 被設置為視頻中包含的一秒間隔內的圖像數。上述參數都是經驗值。在峰值檢測方法中,眼睛區域 ROI 的閾值 θeye 為 2.4 像素,嘴巴區域 ROI 的閾值 θmouth 為 2.2 像素,鼻翼區域 ROI 的閾值 θnose 為 2.0 像素。局部運動融合方法中的閾值 γ 為 0.1。
3.3. Analysis of experimental results
3.3.1. AUs classification result
AU(面部動作單元)分類被認為是分析微表情的強大工具 [27,28]。我們使用在第一張圖像和表情達到最高點的圖像之間的十四個 ROI 的平均光流向量 diapex= (miapex, niapex )T ,其中 i ∈ {1, 2, ..., 14} 進行 AU 分類。如圖 4 所示,ME 的最高點圖像可以從時間域曲線的最高點搜索到。同時,在我們提出的 ME 檢測方法中計算了 diapex= (miapex, niapex )T。使用 SVM 作為分類器,輸入是十四個 ROI 的平均光流向量。
![]()
并且輸出是 One-Hot 編碼,表示 AU 的存在或不存在。

圖4. 十四個感興趣區域(ROI)的示意圖 [12]。
我們使用精確度(PRE)和 F1 分數來評估提出的 AU 分類方法。我們采用了5折交叉驗證策略,并計算了5折分類結果的平均值作為最終結果。CASME II [6] 中的 AU 分類結果如表3所示。分類結果進一步證明了基于面部對齊的偏差測量指數以及所提出的局部特征能夠捕捉微妙的微表情運動。

3.3.2. Macro- and micro-expression spotting results of databases
參數分析。我們分析了峰值檢測方法和局部運動融合方法中參數的影響,如圖7所示。使用 F1 分數評估了宏表情(MaE)和微表情(ME)的檢測性能。

圖7. 參數對檢測性能的影響。 (a) 參數θeye的影響。橫軸表示θeye的值。 (b) 參數γ的影響。橫軸表示γ的值。 (a) 和 (b) 中的縱軸表示在CAS(ME)2上的MaE和ME檢測的F1分數。
如圖7(a)所示,當θeye為2.4像素時(紅線),檢測性能最佳。根據峰值檢測方法,當θeye變小時,將檢測到幅度較小的表情,真正陽性結果的數量會提高。然而,較小的θeye也會帶來更多噪聲,假正例的數量也會增加。因此,當假正例顯著增加時,F1分數開始下降。θmonth和θnose的值的確定方式與θeye相同。參數γ表示兩個局部運動之間的重疊指數的閾值。從圖7(b)中可以看出,當閾值γ為0.1時,檢測性能最佳。
MaE和ME的檢測性能。在兩個數據庫CAS(ME)2和SAMM Long Videos中進行了實驗,結果如表4和表5所示。對于CAS(ME)2,精度為0.2634,召回率為0.5350,F1分數為0.3530。對于SAMM Long Videos,精度為0.3824,召回率為0.3565,F1分數為0.3690。由于MaE的強度大于ME,因此MaE的檢測結果顯著高于ME。
消融實驗分析。我們通過比較提出的方法和去除調整切割框步驟的方法進行了消融實驗。通過執行光學特征u與全局運動向量v之間的差分運算來計算運動d。表6中的結果表明,通過調整切割框步驟,檢測結果顯著改善,這表明了所提出的面部矯正方法的重要性。當頭部晃動較大時,如圖8(a)所示,u和v是基于兩個大位移估計的,這不符合光流方法的條件。通過光流方法估計全局運動v和局部運動u將產生顯著的誤差。因此,結果d也是不準確的。通過調整切割框,面部與切割框在后續圖像中的相對位置保持穩定,降低了全局運動v的振幅,如圖8(b)所示。此時,u和v都反映出最小的位移,符合光流方法的要求,u和v將更加準確。然后,通過公式(11)獲得運動d。


圖8. 在面部對齊前后局部區域的光流向量示意圖。
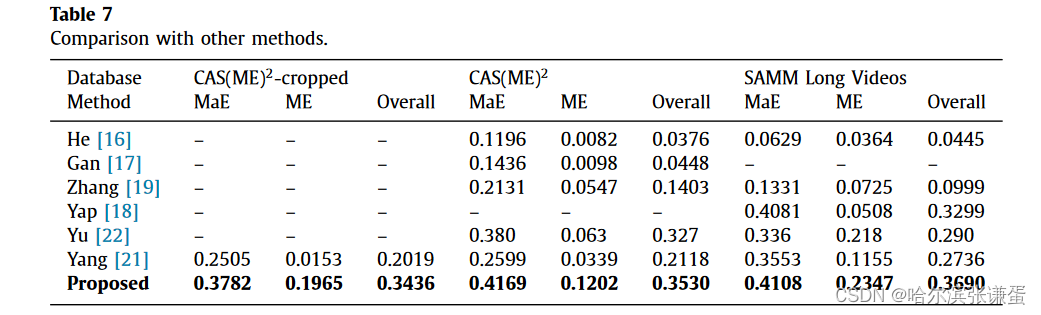
與其他方法的比較。表7比較了不同方法在檢測宏表達、微表達和總體方面的效果。所提出的方法在微表達、宏表達和總體數據庫的F1分數顯著高于其他研究。
4. Conclusion
本文提出了一種自動微表情(ME)檢測方法。首先,為了在長視頻中對齊面部,我們設計了一種基于鼻尖位置的圖像對齊方法,該方法基于面部表情和肌肉運動的特征。其次,我們實現了密集的光流方法,以捕捉臉部十四個感興趣區域的微小運動并構建時域變化曲線。第三
所提出的方法在CAS(ME)2和SAMM Long Videos數據庫上進行了評估。對于CAS(ME)2數據庫,F1分數為0.3530。對于SAMM數據庫,F1分數為0.3682。與其他微表情檢測方法相比,該方法的檢測結果得到了很大的改善。所提出的特征不僅可用于微表情檢測,而且在AU分類中也表現良好。在未來的工作中,我們將嘗試構建一個基于多特征融合的微表情檢測和識別系統。
Declaration of Competing Interest
作者聲明他們沒有已知的可能影響本文報告的競爭性財務利益或個人關系。Haifeng Li 報告稱其得到了黑龍江省科技廳的資助。Lin Ma 報告稱其得到了中華人民共和國科學技術部社會發展科技司的資助。
Data Availability
已經使用的數據是保密的。
Acknowledgments
這篇論文的早期版本[24]曾在2021年ACM多媒體國際會議上報告。該工作得到了中國國家重點研發計劃(2020YFC0833204)和黑龍江省重點研發計劃(GY2021ZB0206)的部分支持。



)









求解23個測試函數(python代碼))





