寫在前面
你是否曾經困擾于如何從海量的數據中提取有價值的信息?你是否想過如何利用數據來指導你的決策,讓你的決策更加科學和精確?如果你有這樣的困擾和疑問,那么你來對了地方。這篇文章將引導你走進數據科學的世界,探索數據驅動的決策。
1.數據科學的基本原則
在我們深入探討如何實踐數據科學之前,有必要理解一些核心原則。這些原則是我們在處理任何數據問題時都需要遵循的,它們是我們進行有效分析并得出有意義結論的基礎。
-
問題驅動: 數據科學始于一個明確且具體的問題。每個項目開始之處都應該是一個精細定義好的疑問或挑戰,這將引導你決定哪些數據和方法最適合找到答案。例如,如果你正在為電商網站工作,并希望增加用戶參與度,那么你可能會提出如下問題:“哪種類型的產品推薦能夠最大程度地提高用戶參與度?”這樣的問題可以直接轉化為可操作的數據科學任務。
-
數據質量: 無論使用多么復雜、先進的技術和算法,如果輸入的數據質量不佳,則輸出結果也將誤導決策過程。因此,在開始任何形式的分析之前,務必對所用數據進行徹底清洗和審查:檢查是否存在缺失值、異常值、錯誤記錄等,并進行適當處理。
-
方法合理: 數據科學包含廣泛而深奧的統計和機器學習技術庫。選擇正確且適當方法至關重要。例如,在預測銷售額時,線性回歸可能比神經網絡更合適;反之,在圖像識別中,卷積神經網絡可能是首選。
-
結果解釋: 最后但同樣重要——盡管某些模型(如深度學習)可以生成令人驚嘆但難以解釋的結果,但在企業環境中,通常需要能夠解釋模型行為及其預測背后原因。只有通過良好理解模型運作方式才能建立信任并使非技術團隊成員接受由模型做出指導決策。
2.數據科學的步驟
2.1 理解問題
數據科學項目始于一個具體的、明確的問題。這個問題應該是可以通過數據來回答,也就是說,它需要具有可測量性和定量性。例如,“我們的客戶流失率增加了嗎?”或“哪種營銷活動對提高銷售額影響最大?”這些都是很好的問題,因為它們可以轉化為數值,并且可以通過分析數據來得出答案。
在定義問題時,你需要考慮到你所擁有的資源(如時間、人力和技術),以及你能獲取到什么樣的數據。同時,你還需要與利益相關者進行深度溝通以確保理解他們真正關心的核心問題。
2.2 收集數據
一旦確定了要解決的問題,下一步就是找到并收集相關的數據。可能來源包括公司數據庫、公開網站、第三方供應商等。此階段可能涉及到復雜查詢語句編寫、API使用甚至網絡爬蟲設計等任務。
不過需要注意的是,在收集數據時,請始終遵守所有適用法規和道德準則。尤其當處理個人信息時更需注意隱私權保護。
2.3數據清洗
拿到原始數據后,接下來就需要進行預處理和清洗操作。這包括:
- 處理缺失值:根據情況選擇填充方法(例如中位數或平均值填充)或直接刪除含有缺失值行/列。
- 異常值檢測:識別并處理異常值,比如過大或過小值。
- 數據類型轉換:將字符串日期轉化為Python日期對象;將分類變量編碼為數字等。
- 特征工程:基于現有特征創建新特征以捕獲更多信息。
2.4 數據分析
在完成了上述步驟后, 現在已經進入到項目最激動人心部分——模型構建與訓練!以下幾點可能會幫助您:
- 選擇合適模型:根據目標選擇恰當模型類型(如線性回歸、決策樹或神經網絡)。
- 訓練模型:利用已有訓練集訓練選定模型,并調整參數以優化性能。
- 驗證模型:使用交叉驗證或者留出法等方式,評估模型在未見過數據上的表現。
2.5 結果解釋
在分析完成后,最后一步是將復雜的統計和機器學習結果轉化為可以理解并采取行動的洞察。這可能涉及到:
- 可視化:創建圖表以可視化關鍵發現。
- 解釋性:如果可能, 說明每個特征對預測結果的影響。
- 報告撰寫:清晰、準確地描述你的方法、發現和推薦,并向利益相關者進行報告。
4.數據驅動決策的實踐應用
作為一家電商公司的運營經理,我想知道哪些因素會影響用戶的購買行為。這是一個典型的數據科學問題,我們可以按照以下步驟進行探索:
4.1 理解問題
首先,我們需要明確化問題。在這個案例中,“影響用戶購買行為的因素”可能有很多種,例如產品價格、折扣、商品描述、用戶評價等。我們需要決定關注那些具體因素,并將其量化以便于分析。
4.2 收集數據
現在我們已經定義了問題,接下來就是尋找相關數據。大多數電商平臺都有詳細記錄每次交易和用戶行為的系統,在這個階段我們需要與IT部門合作提取到所需數據。
要注意的是,不僅僅是銷售數據對此類分析有幫助,還包括用戶瀏覽歷史、搜索記錄、點擊率等也非常重要。同時別忘了考慮外部因素如季節性變化(比如“雙十一”或者“雙十二”)等。
4.3 清洗數據
獲得原始數據后, 我們需要對其進行處理以適應模型需求。可能遇到缺失值、異常值或錯誤輸入等情況,在處理時要盡量保證不改變原始信息意義且符合統計假設。
特別地,在處理文本類特征(如商品描述)時可能會涉及到自然語言處理技術(NLP),例如詞袋模型或TF-IDF等方法轉換成可用于模型訓練的形式。
4.4 分析數據
此階段開始構建并訓練機器學習模型來預測購買行為并挖掘影響因素。選擇模型類型取決于你關心什么樣結果:
- 如果只關心“是否購買”,那么可以使用分類算法如邏輯回歸或隨機森林。
- 如果關心“購買多少”,那么可以使用回歸算法如線性回歸或梯度提升樹。
- 如果旨在發現隱藏規則和模式,則聚類或關聯規則挖掘算法更加適合。
無論采用何種方式,都需要在訓練過程中持續評估模型性能并調整參數優化結果。
4.5 解釋結果
最后一步是將分析結果轉化為可執行的策略。這可能包括創建圖表以可視化關鍵發現、解釋每個特征對預測結果的影響等。
例如, 如果我們發現“商品描述”的情感色彩與用戶購買行為強相關,那么我們可以建議市場部門使用更積極、吸引人的語言來描述產品。如果發現某些特定折扣促銷顯著提高了購買率,那么就可以考慮未來更多運用此類營銷手段。
總之, 數據科學不僅幫助我們理解了哪些因素影響用戶購買行為,而且還指導我們如何根據這些洞察進行更好決策。
5. 一個demo
下面我將給出一個例子,演示我進行分析數據和解釋結果的過程,此處默認已經對數據進行收集和清洗。
5.1 構建演示數據
import pandas as pd
import numpy as np# 為了復現結果, 設置隨機種子
np.random.seed(12)# 創建1000個用戶樣本
n_samples = 1000# 假設有以下特征:年齡、性別(男=1,女=0)、瀏覽次數、是否點擊廣告(是=1,否=0)
age = np.random.randint(18, 70, n_samples)
gender = np.random.randint(2, size=n_samples)
view_count = np.random.poisson(lam=10.0, size=n_samples)
clicked_ad = np.random.randint(2, size=n_samples)# 用戶購買行為受以上特征影響,這里假設購買率與年齡、性別和是否點擊廣告正相關,與瀏覽次數負相關。
buy_probability = age * 0.1 + gender * 0.35 - view_count * 0.05 + clicked_ad * 0.55
buy_action = (buy_probability + np.random.normal(size=n_samples)) > 4 # 設定閾值決定是否購買df = pd.DataFrame({'Age': age,'Gender': gender,'ViewCount': view_count,'ClickedAd': clicked_ad,'BuyAction': buy_action.astype(int) # 轉換成整型
})#查看數據開頭
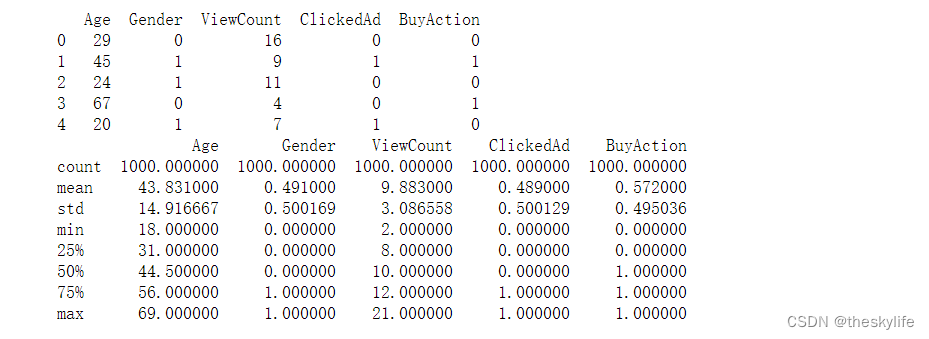
print(df.head())
#對數據進行初步分析
print(df.describe())運行后,結果如下:
5.2 進行邏輯回歸建模分析
邏輯回歸有多種構建方法,這里采用sklearn進行構建,代碼如下:
# 將數據劃分為訓練集和測試集,并用邏輯回歸模型進行訓練
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegressionX_train, X_test, y_train, y_test = train_test_split(df.drop('BuyAction', axis=1), df['BuyAction'], test_size=0.2,random_state=40)#構建模型
model = LogisticRegression(max_iter=1000,random_state=12)
model.fit(X_train,y_train)#評估模型并查看每個特征的重要性
from sklearn.metrics import classification_report,confusion_matrix# 預測并進行分類
y_pred=model.predict(X_test)
print(classification_report(y_test,y_pred))# 生成混淆矩陣
conf_matrix = confusion_matrix(y_test,y_pred)
print("\nConfusion Matrix:")
print(conf_matrix)# 查看參數重要性
feature_importance=pd.DataFrame({"Feature":df.columns[:-1],"Importance":model.coef_[0]})
print("\nParameters Importance:")
print(feature_importance.sort_values("Importance",ascending=False))運行上述代碼后,結果如下:
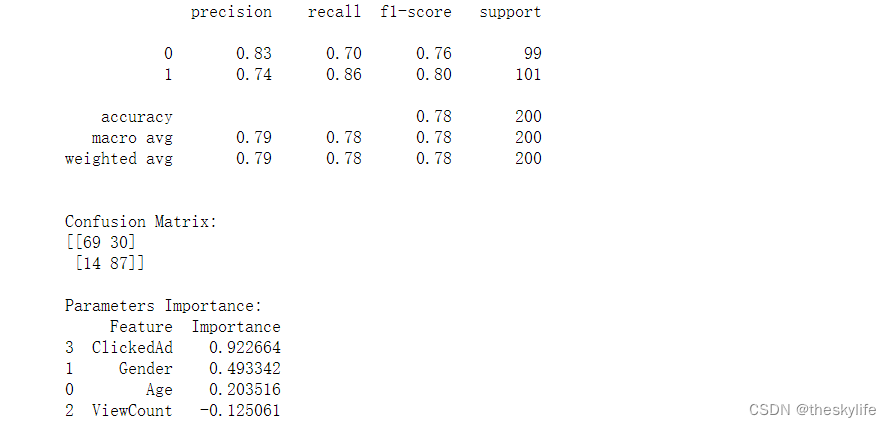
從上述結果中,可以看出下面的結論:
| 預測為負類別 (0) | 預測為正類別 (1) | |
|---|---|---|
| 實際負類別 (0) | 69 | 30 |
| 實際正類別 (1) | 14 | 87 |
解釋:
-
True Positives (TP,真正例): 87。實際為正類別且被正確分類為正類別的樣本數量。
-
True Negatives (TN,真負例): 69。實際為負類別且被正確分類為負類別的樣本數量。
-
False Positives (FP,假正例): 30。實際為負類別但被錯誤分類為正類別的樣本數量。
-
False Negatives (FN,假負例): 14。實際為正類別但被錯誤分類為負類別的樣本數量。
在二元分類問題中,我們可以使用混淆矩陣的元素計算多個性能指標。補充常見的二元分類指標及其計算公式:
-
準確度(A
)


:spu管理頁面的sku的新增和修改)

![排序算法:【選擇排序]](http://pic.xiahunao.cn/排序算法:【選擇排序])




實現原理)
)







