這里寫目錄標題
- 對比代碼
- 結果圖
- 代碼解析
對比代碼
from glob import glob
from tqdm import tqdm
import time
path_list=glob("E:/sky_150b/任務組_20231207_2023/*.jsonl")
# for two in tqdm(path_list):
one=path_list[0]with open(one,"r",encoding="utf-8") as f:data=f.readlines()
start=time.time()
data_list={}
for i in tqdm(data):if data_list.get(i,False)==False:data_list[i]="1"
print(time.time()-start)
start=time.time()
data_list = set()for i in tqdm(data):data_list|=set(i)
print(time.time() - start)# with open(one, "w", encoding="utf-8") as f:# f.writelines([i for i in data_list.keys()])#結果圖
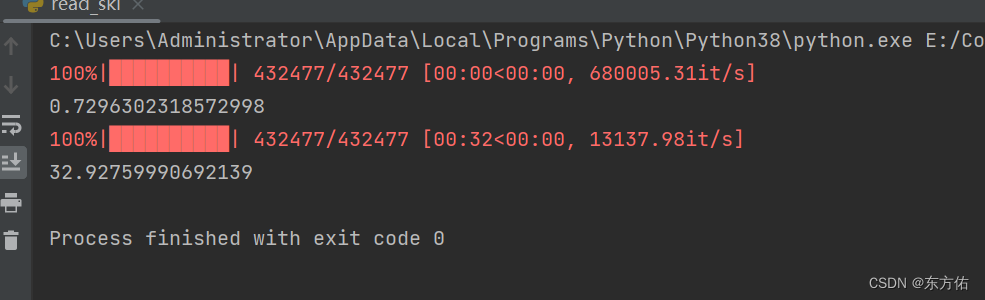
代碼解析
這段代碼的作用是比較兩種方法分別用于處理一個文件中的數據重復項的時間效率。
具體流程如下:
-
導入需要用到的模塊:
from glob import glob from tqdm import tqdm import timeglob模塊用于查找匹配特定模式的文件路徑名,它返回所有符合條件的文件路徑列表。tqdm模塊是一個用于在 Python 迭代器中添加進度條的庫。 -
使用 glob 模塊獲取所有符合條件的文件路徑名:
path_list=glob("E:/sky_150b/任務組_20231207_2023/*.jsonl")
這里使用了 glob() 函數獲取了所有以 .jsonl 結尾文件的路徑名,存儲在 path_list 列表中。
-
對于每個文件路徑名循環處理重復項:
one=path_list[0]with open(one,"r",encoding="utf-8") as f:data=f.readlines() start=time.time() data_list={} for i in tqdm(data):if data_list.get(i,False)==False:data_list[i]="1" print(time.time()-start) start=time.time() data_list = set()for i in tqdm(data):data_list|=set(i) print(time.time() - start)分別使用兩種不同的方法處理文件中的重復項并計算時間。其中第一個循環使用了字典的鍵值對特性,通過判斷鍵是否存在來去重,第二個循環則使用了 Python 內置的
set數據結構實現去重。time.time()函數用于獲取當前時間戳,兩次獲取的時間戳相減即為整個循環處理時間。tqdm模塊的作用是在循環時顯示進度條,使得處理結果更加直觀。
最終輸出兩種處理方法的時間。
:Poco::Util::Application(應用程序框架))

容器技術發展史)











![[python]利用whl輪子文件python3.12安裝talib](http://pic.xiahunao.cn/[python]利用whl輪子文件python3.12安裝talib)




